| 5 1 月, 2023 |
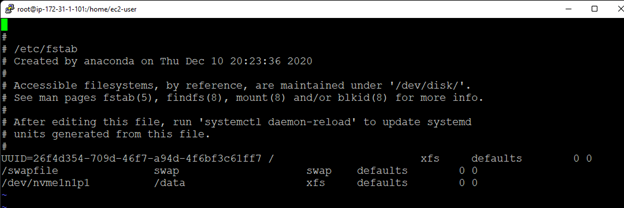
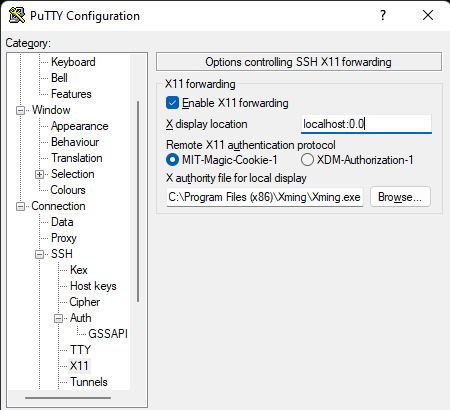
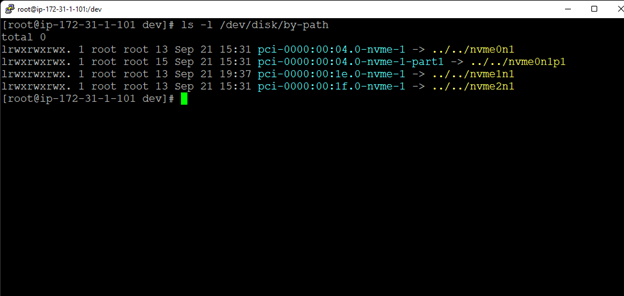
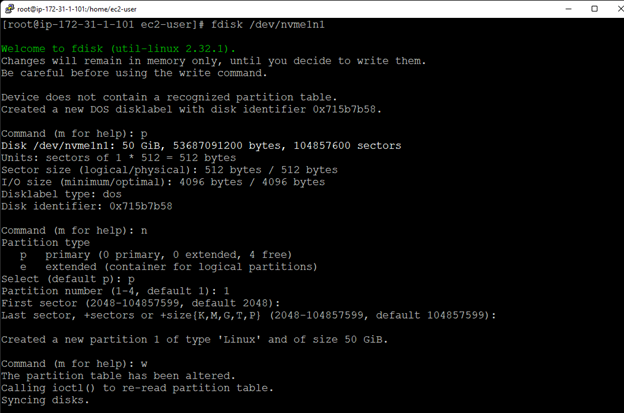
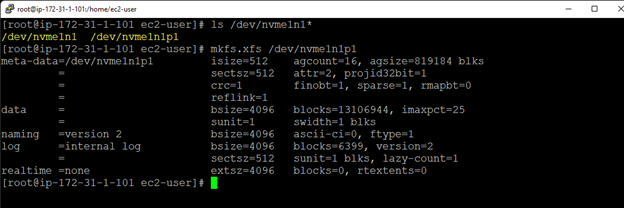
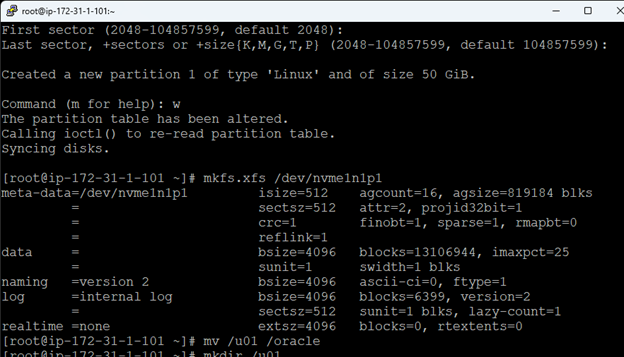
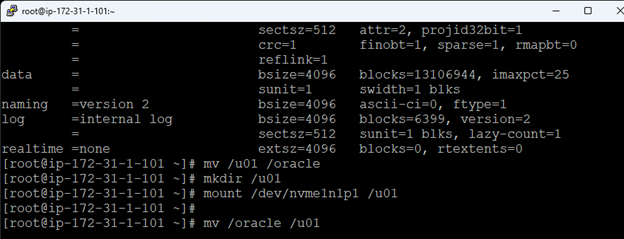
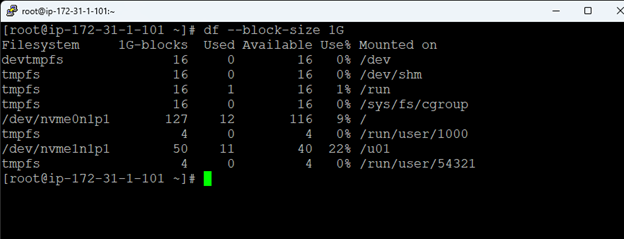
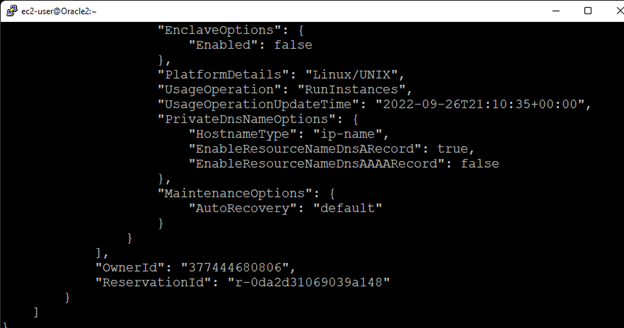
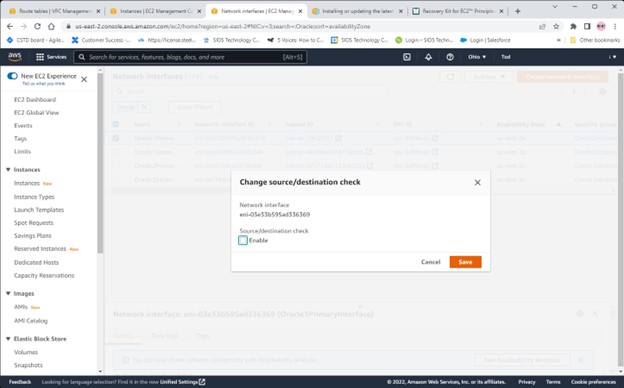
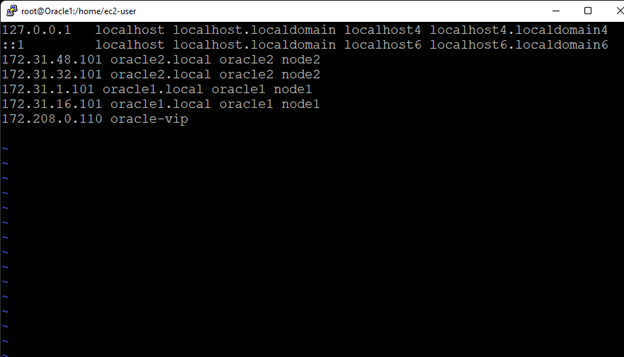
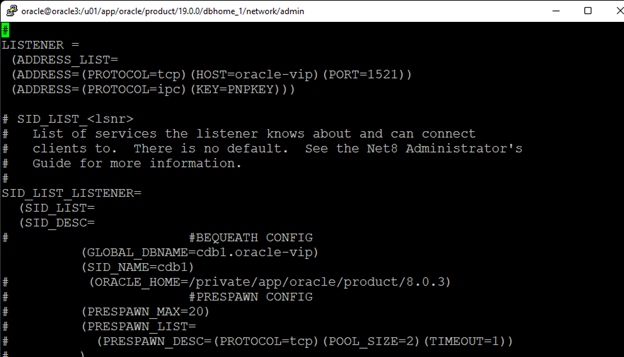
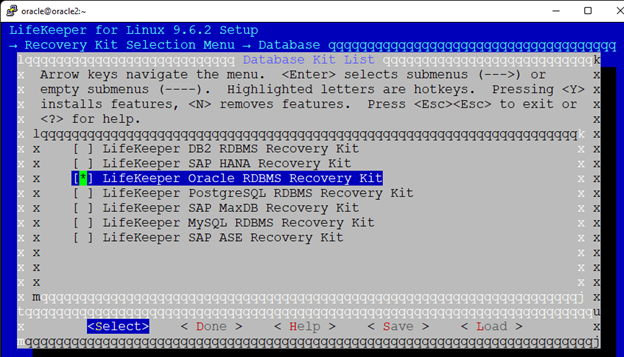
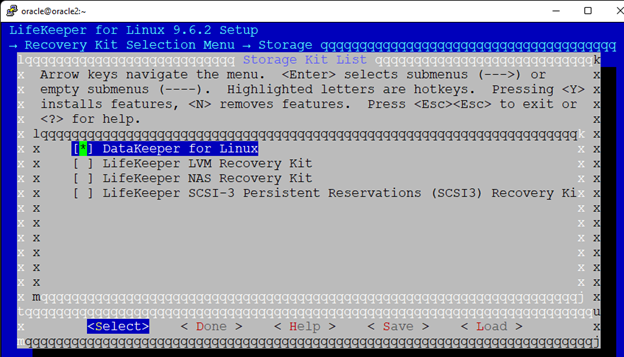
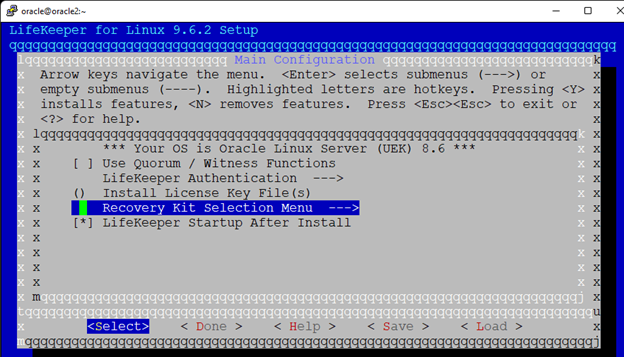
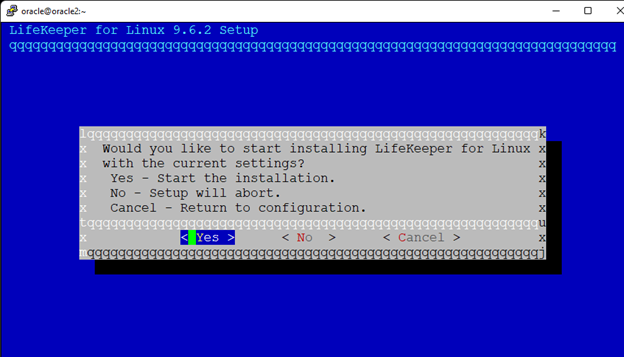
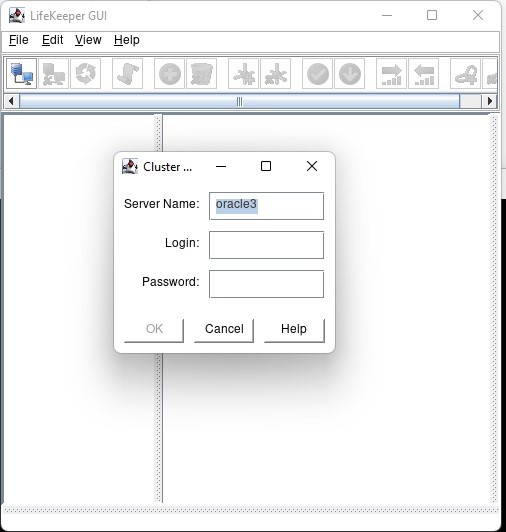
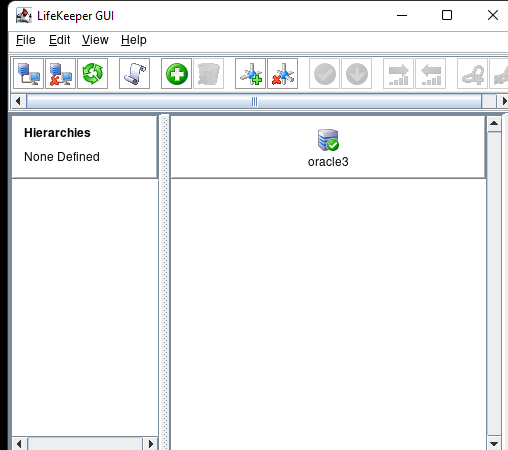
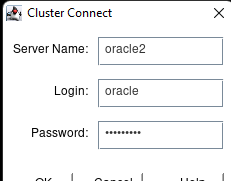
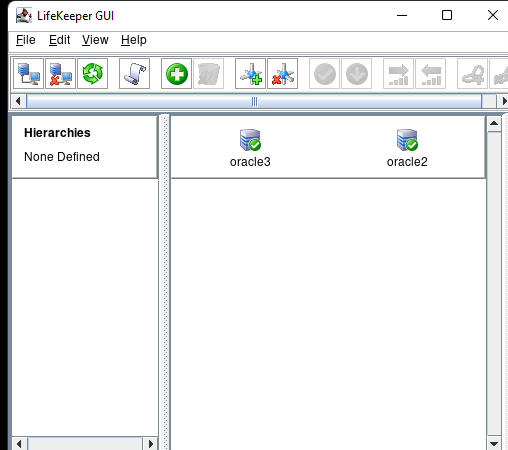
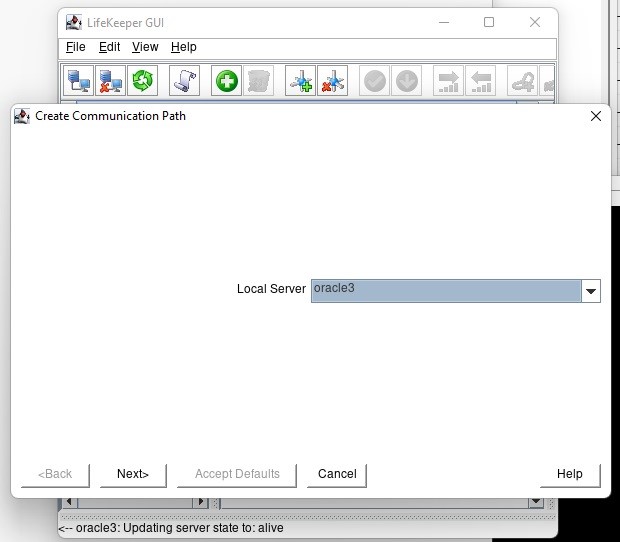
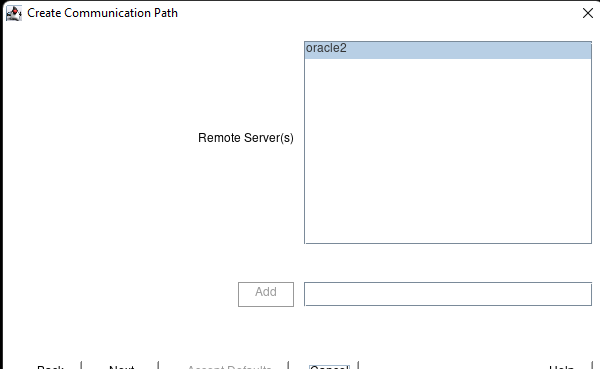
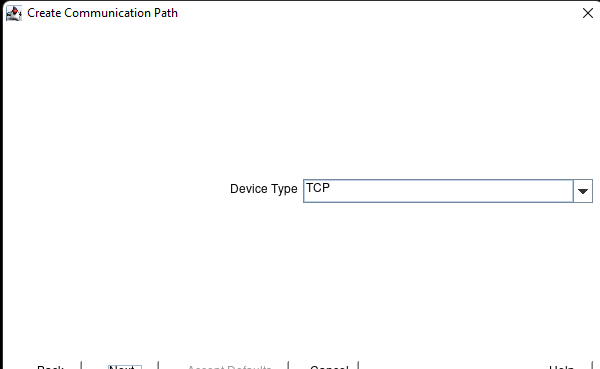
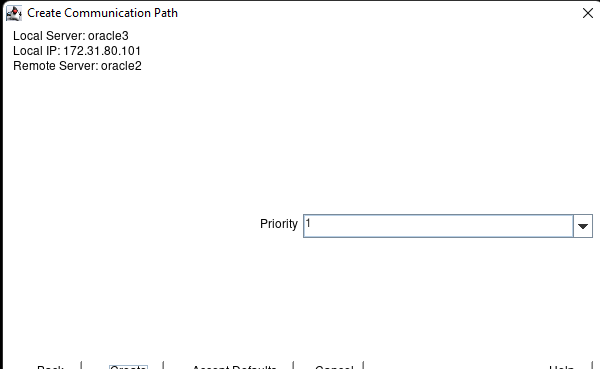
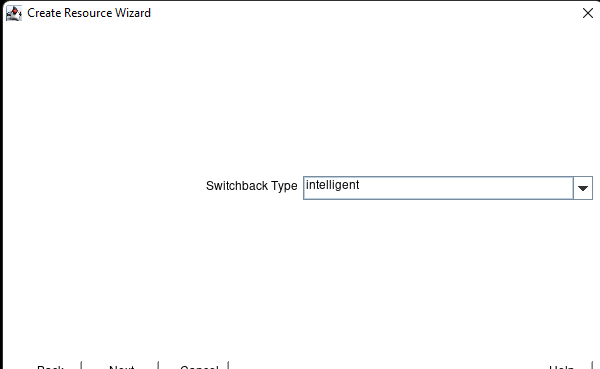
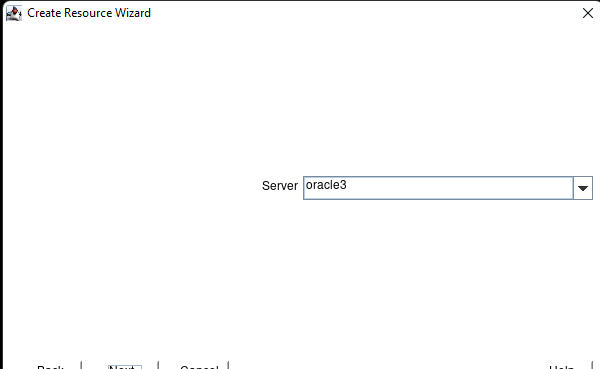
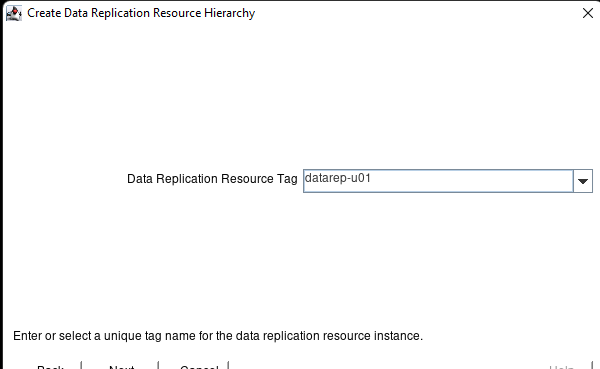
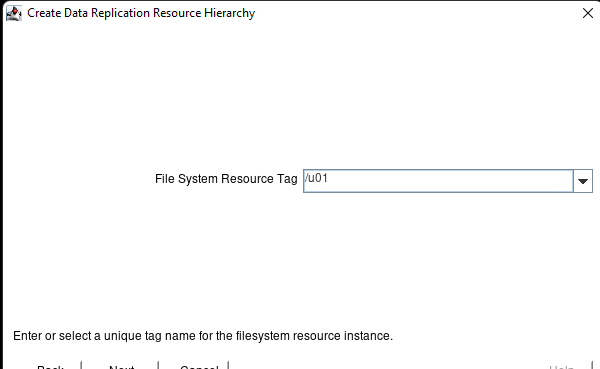
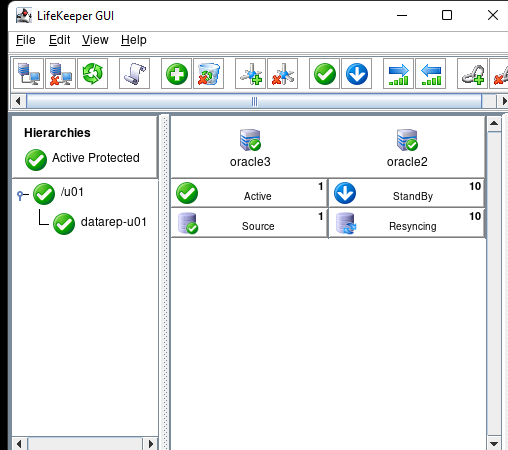
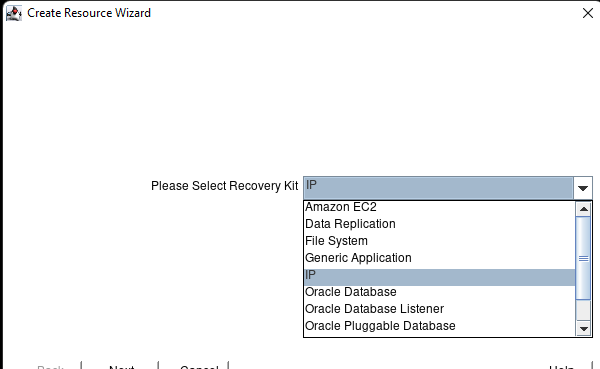
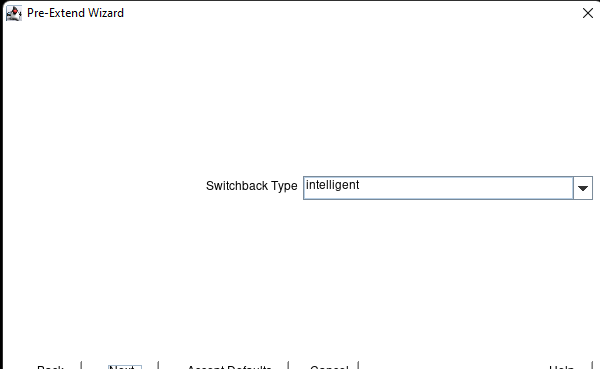
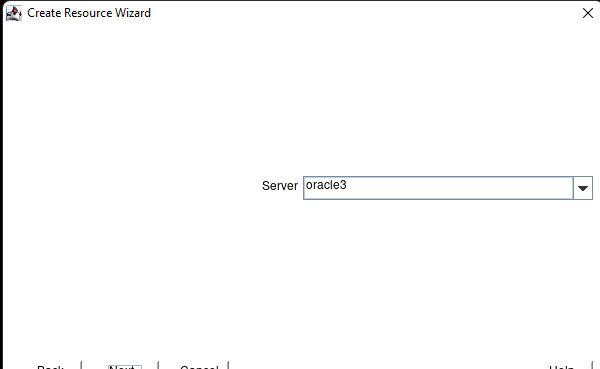
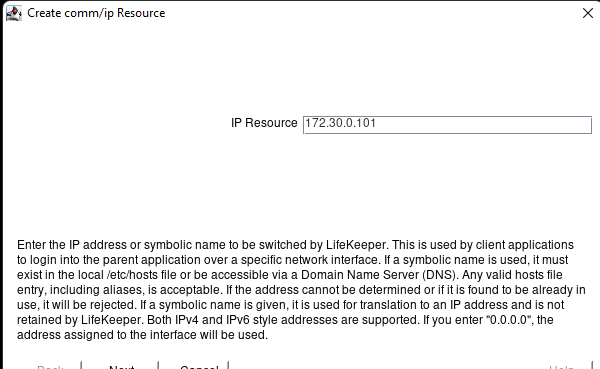
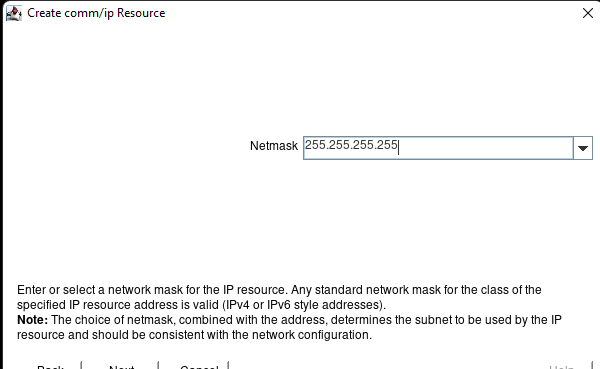
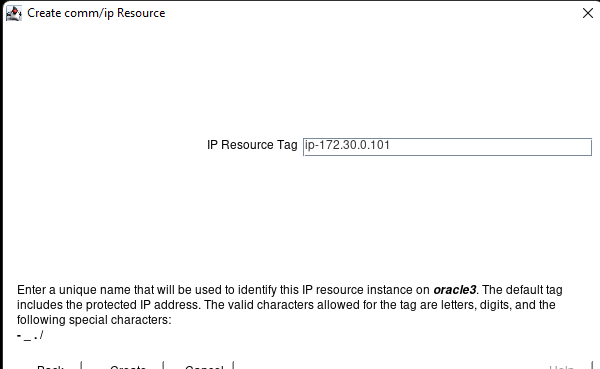
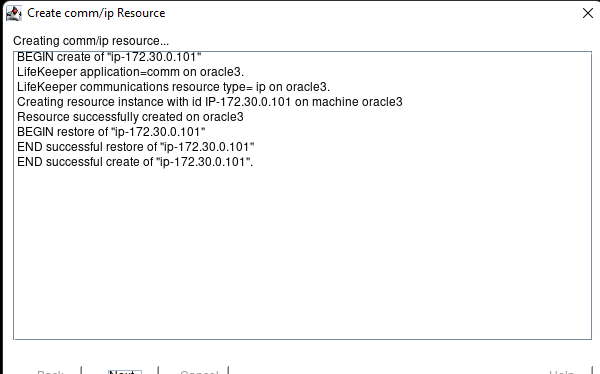
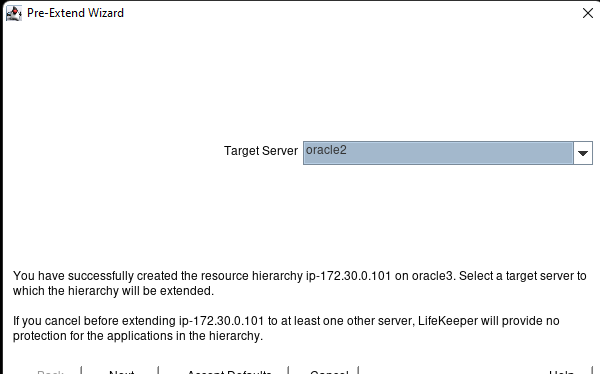
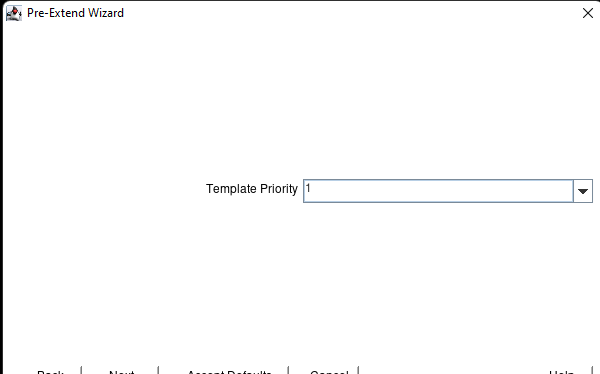
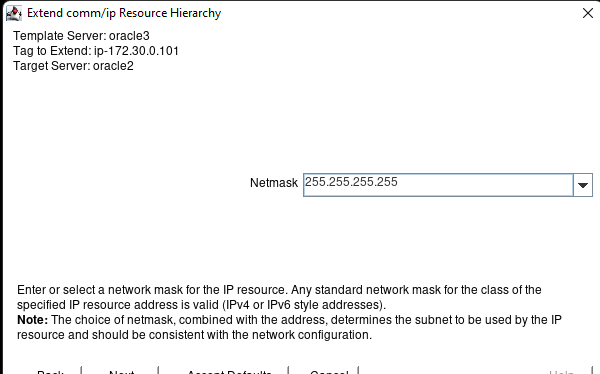
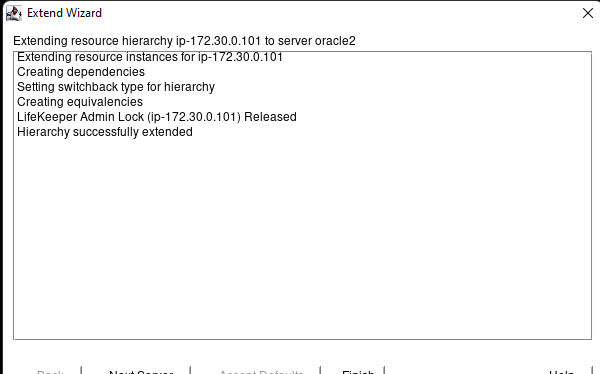
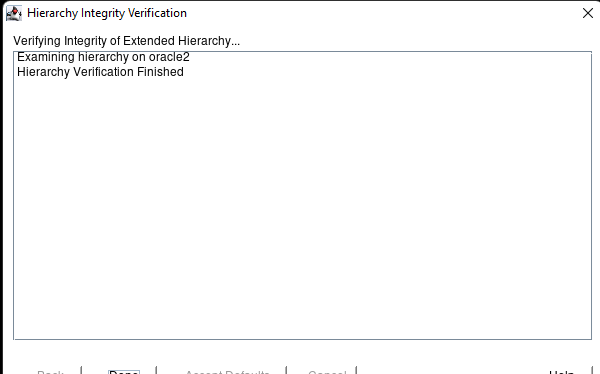
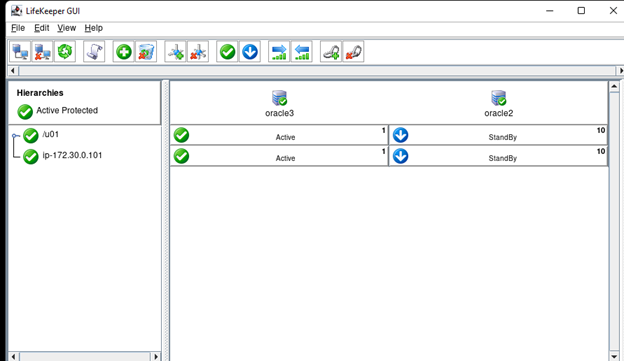
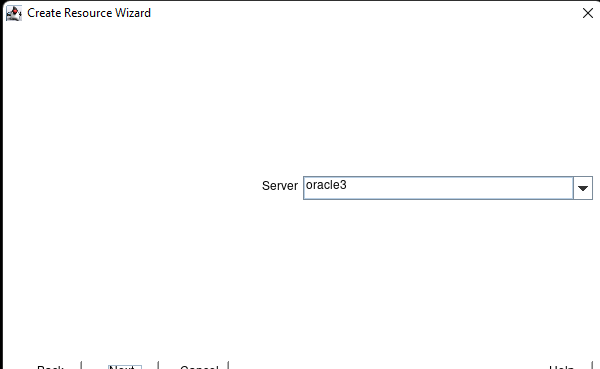
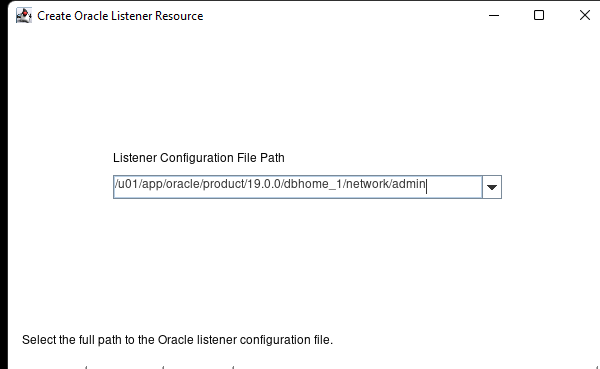
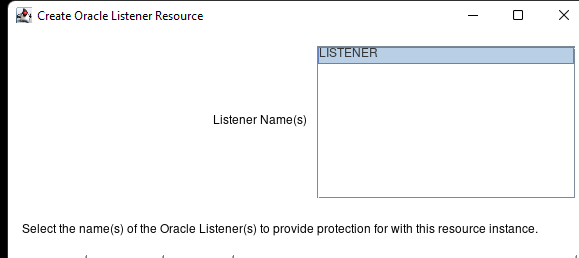
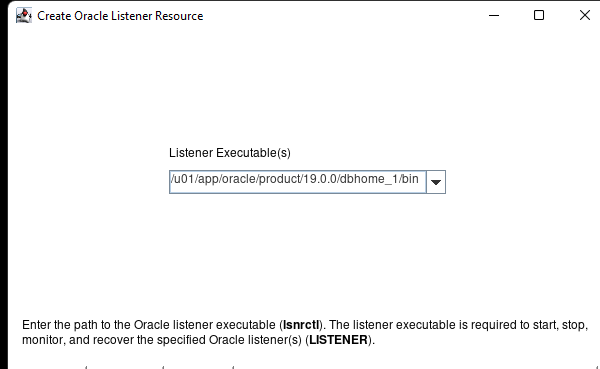
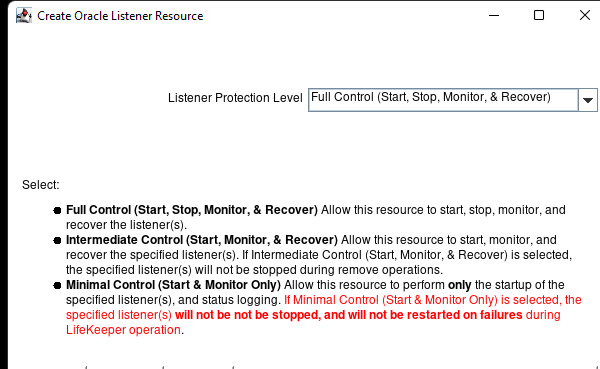
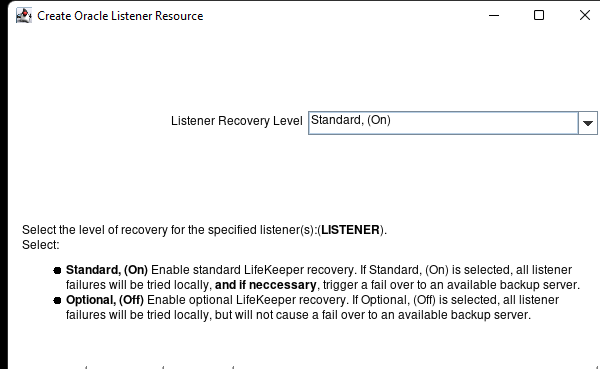
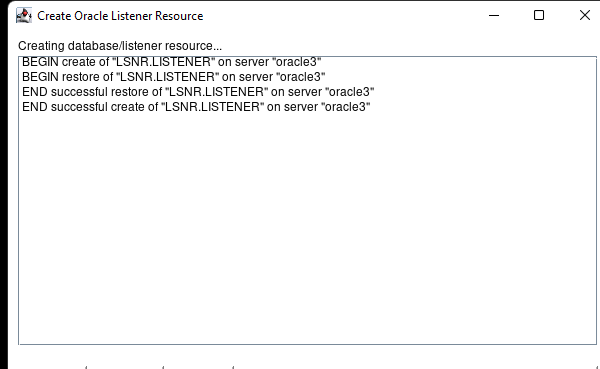
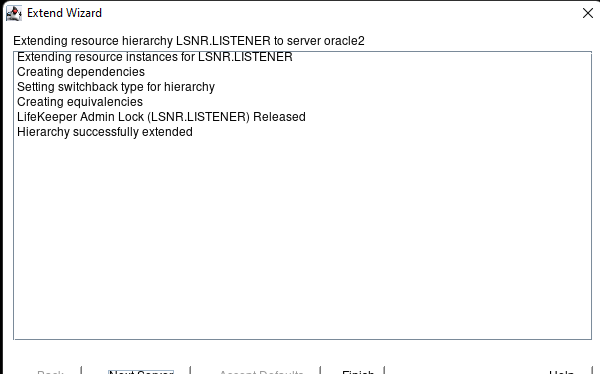
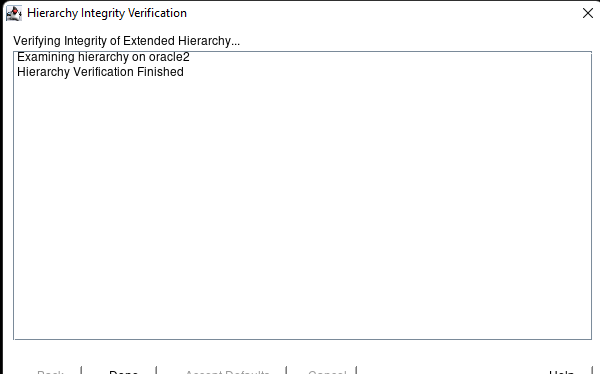
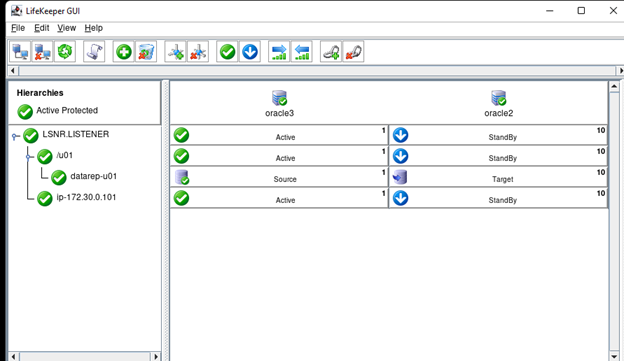
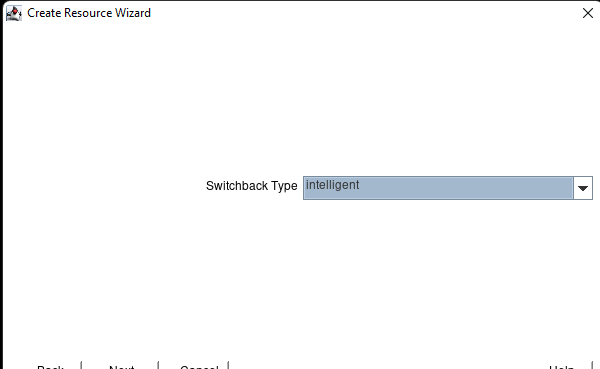
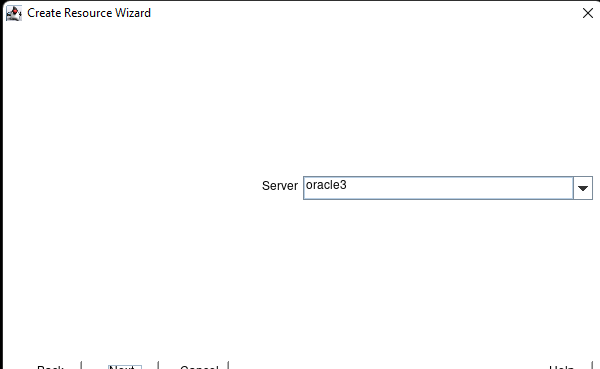
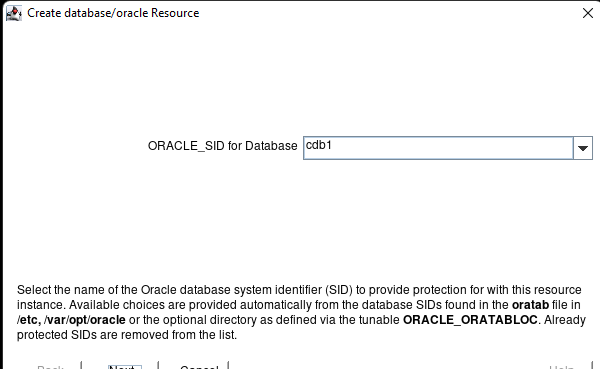
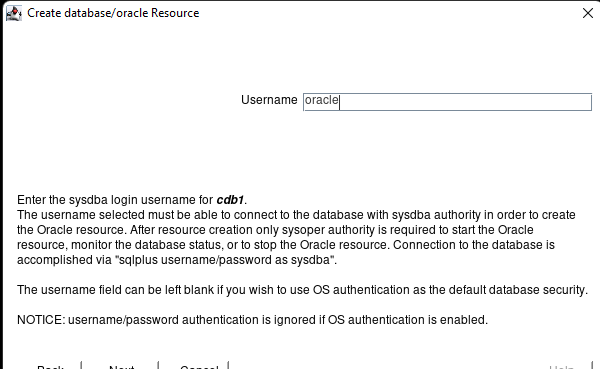
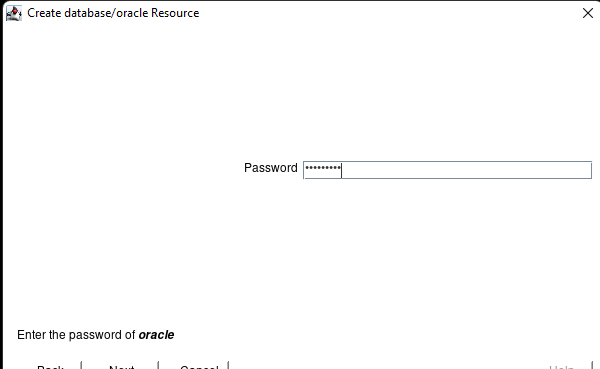
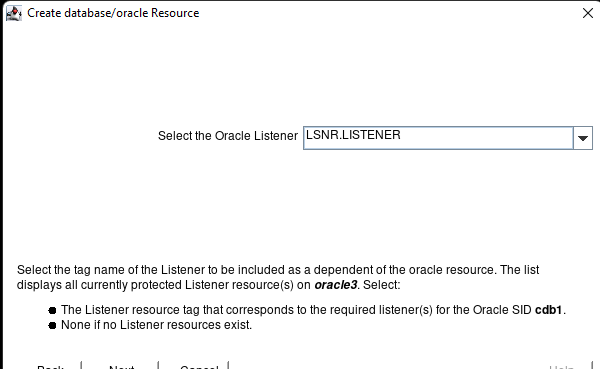
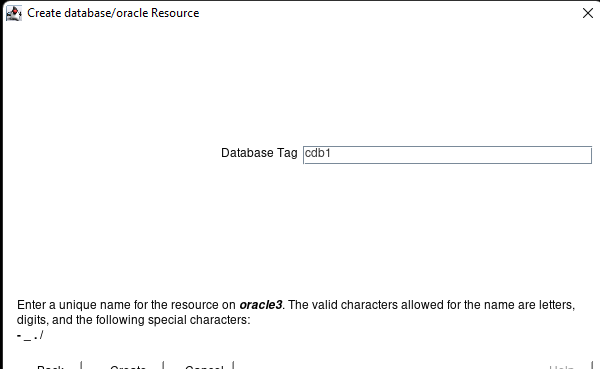
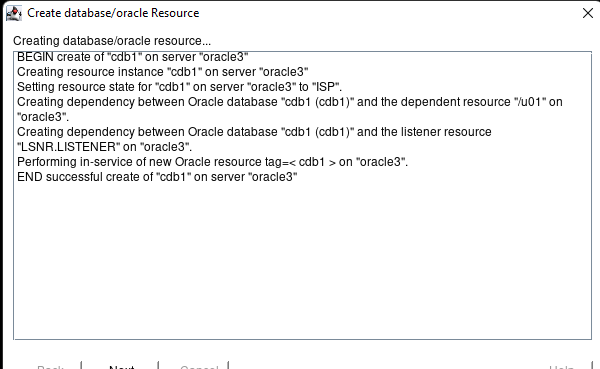
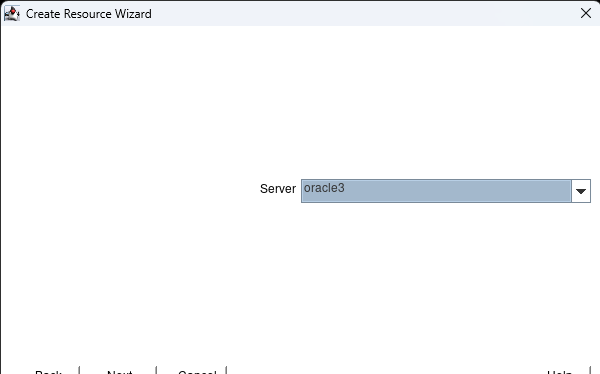
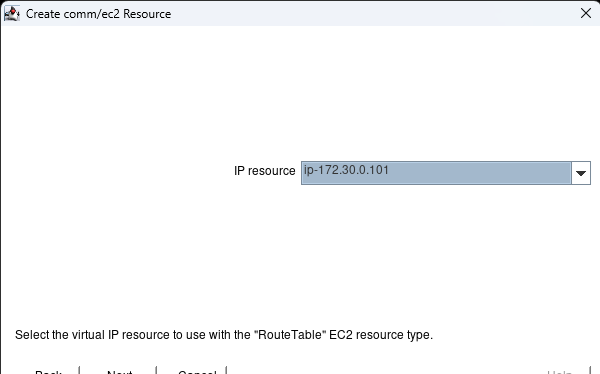
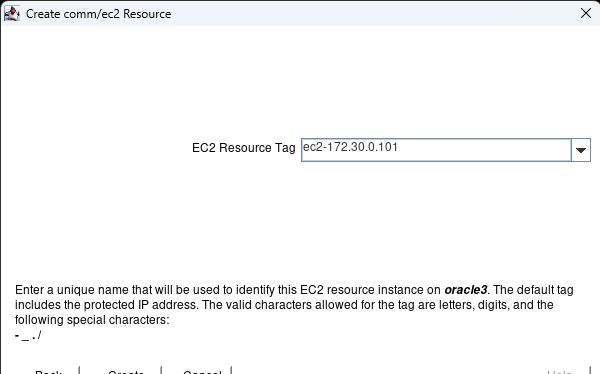
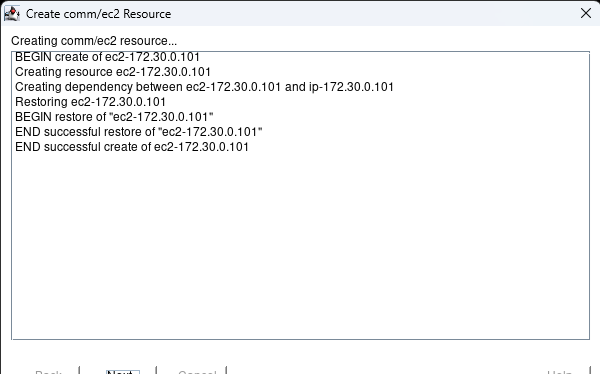
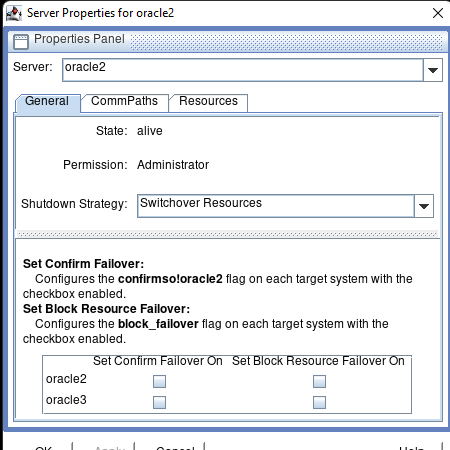
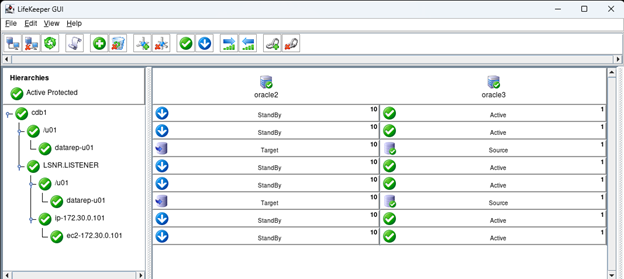
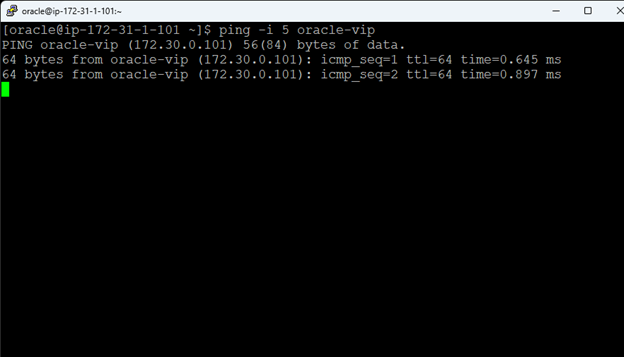
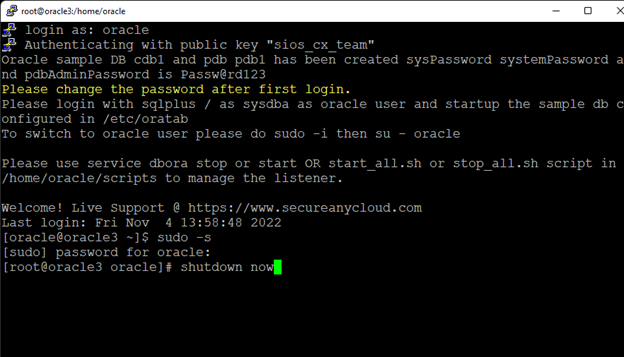
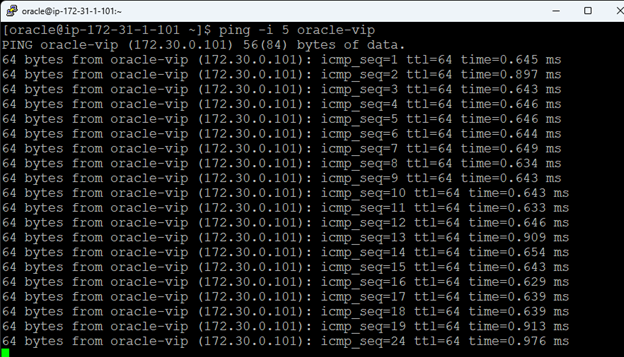
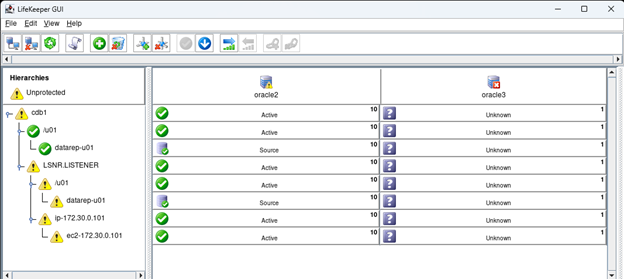
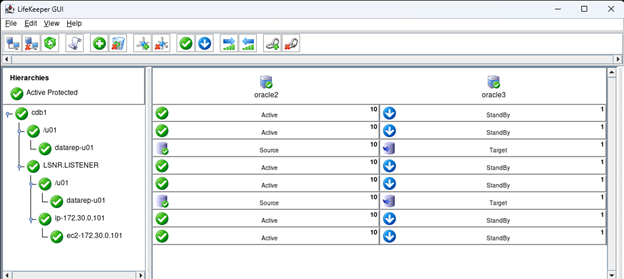
在 AWS 中創建 HA Oracle 數據庫服務器集群 |
| 30 12 月, 2022 |
領先的飲料製造商保護 AWS EC2 雲中的關鍵 SAP ERP |
| 26 12 月, 2022 |
視頻:SIOS 如何確保金融服務行業的高可用性視頻:SIOS 如何確保金融服務行業的高可用性 在這個關於各個行業的高可用性 (HA) 和災難恢復 (DR) 的持續系列中,格雷格·塔克, 高級產品 (Windows) 支持工程師賽奧斯科技, 與我們一起分享他對公司如何保護金融業免受停機和故障轉移影響的見解。 SIOS 在金融行業擁有全球業務,客戶包括商業銀行、各種經紀公司、財富管理、註冊會計師事務所等。 沒有哪個行業比金融行業更關鍵,對停機和故障更敏感,因為客戶的在線銀行系統、ATM 和支付系統都依賴關鍵應用程序。 “我們提供故障或集群軟件,以保護他們的關鍵應用程序和數據免受停機和/或災難性事件的影響,”塔克說。 Tucker 解釋說,本質上,關鍵應用程序部署在主服務器上,無論是本地還是雲端,因為它與輔助服務器或多台服務器集群在一起。 “如果集群軟件檢測到故障,它會將所有資源轉移到輔助節點並自動為最終用戶恢復服務;沒有數據丟失,沒有中斷,”他補充道。 查看上面的整個採訪以了解更多信息。 討論要點:
解決方案 與格雷格塔克聯繫(領英) 經許可轉載自信息系統 |
| 18 12 月, 2022 |
視頻:樓宇管理和安全的高可用性 |
| 14 12 月, 2022 |
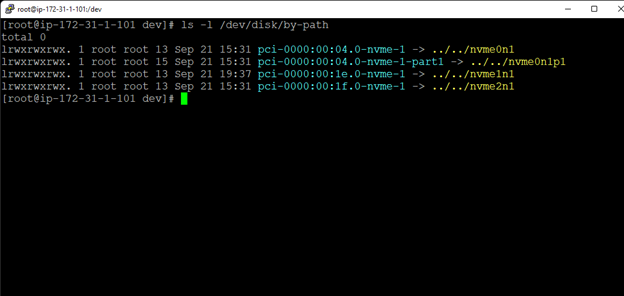
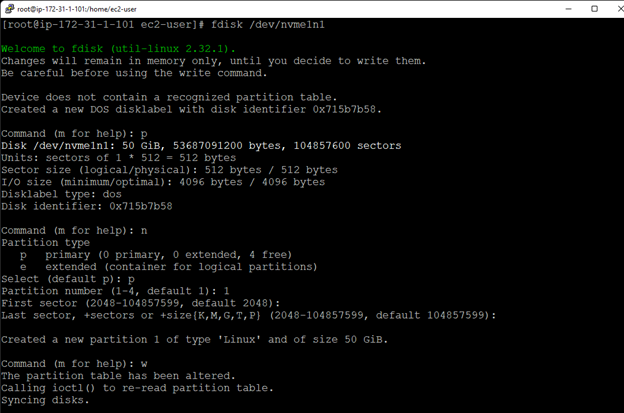
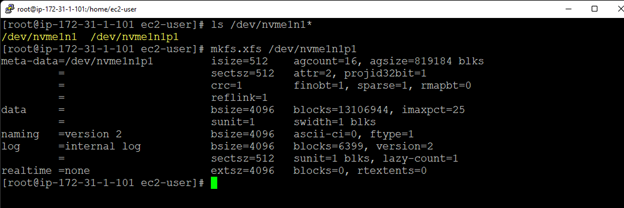
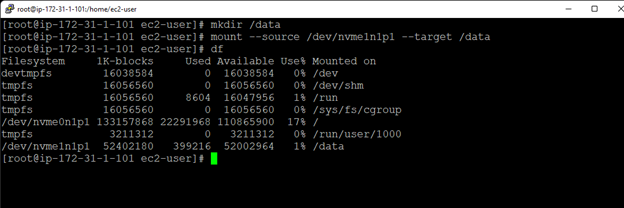
SIOS LifeKeeper 與 SUSE HAE
SIOS LifeKeeper 與 SUSE HAE在眾多企業中,樹液系統對於核心企業業務運營的運作至關重要,即使是短暫的停機時間也會造成毀滅性的後果。 然而,基於 Linux 的解決方案可能很複雜且容易出錯。 即使是 SUSE HAE 和其他開源集群選項,也是高度手動的,並且只能保護單個組件。 閱讀白皮書,了解 SUSE HAE 和SIOS 保護套件找出最快、最準確的方法來管理和優化 Linux 環境。 下載白皮書這裡
|