SIOS DataKeeper 集群軟件使 Gulliver International 能夠將內部 IT 系統安全地遷移到 Amazon Web Services
SIOS 軟件在 AWS 環境中提供高可用性,使領先的二手車公司能夠將所有 IT 系統遷移到雲端。
Gulliver International 是一家領先的二手車公司,總部位於東京,在日本各地擁有 420 家門店。 在接下來的四年裡,該公司計劃擴展到全球業務,在全球擁有 1600 家門店。 為確保其 IT 基礎設施能夠適應這種快速增長,該公司正在將其所有內部系統遷移到 AWS,並在全公司範圍內推廣針對所有新應用程序的“雲優先”政策。
Gulliver International 的 IT 經理月島學 (Manabu Tsukishima) 表示:“將我們的系統遷移到雲端將為我們提供快速和經濟高效增長所需的靈活性和可擴展性,同時持續為我們的客戶提供優質服務。”
挑戰
為了確保他們的雲優先計劃取得成功,Gulliver 需要保護他們的關鍵業務應用程序在雲環境中免受停機,而傳統的故障轉移集群是不可能的。
“如果沒有高效、易於實施的高可用性解決方案,我們不會考慮將我們的應用程序遷移到雲端,”Tsukishima 說。 Gulliver 選擇使用 SIOS DataKeeper 軟件,該軟件由 SIOS Technology, Inc. 在日本銷售。
解決方案
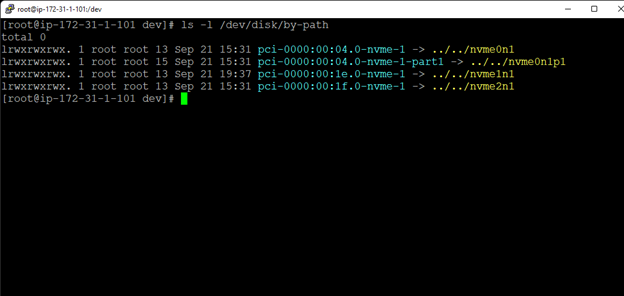
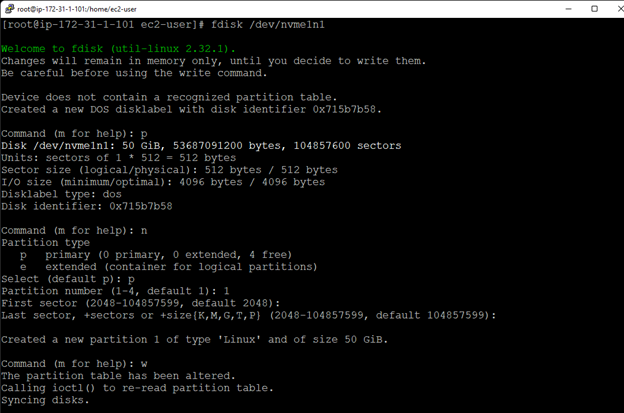
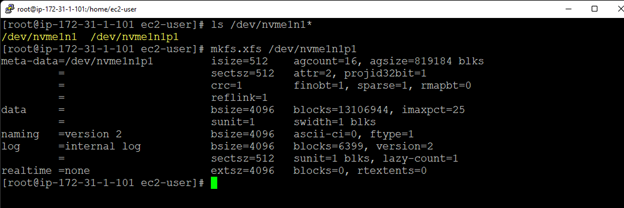
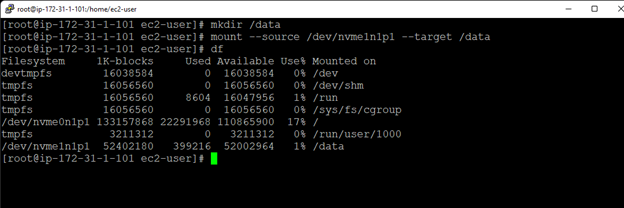
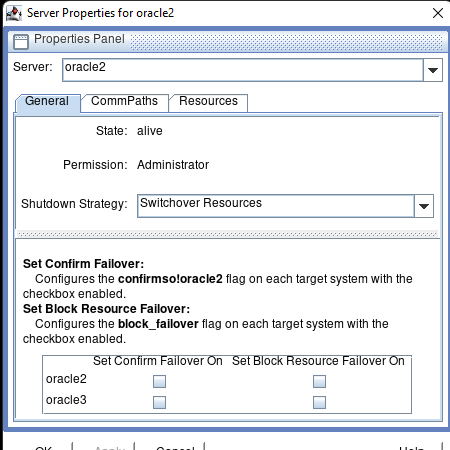
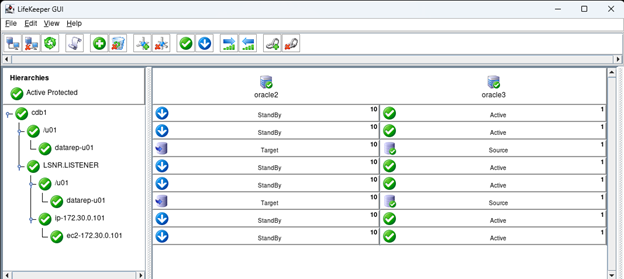
SIOS DataKeeper 軟件使 Gulliver 能夠使用 Windows Server 故障轉移集群 (WSFC) 在雲環境中構建故障轉移集群,而傳統的共享存儲集群是不可能的。
SIOS 軟件使用高效、實時的複制來同步在 AWS 環境中作為 WSFC 集群運行的服務器之間的存儲。
使用 SIOS 軟件,Gulliver 可以將兩台服務器配置為跨不同的 Amazon 可用區作為集群運行。
就像在傳統的物理環境中一樣,如果一個可用區內的AWS雲中的主服務器發生故障,WSFC將應用程序移動到位於另一個亞馬遜可用區的第二台服務器上,提供完全的雲容災和恢復.
結果
“我們對 SIOS DataKeeper 軟件為我們公司的雲優先計劃帶來的價值感到非常高興,”Tsukishima 說。 借助 SIOS DataKeeper 軟件,Gulliver 可以遷移到雲端,而不會增加現有操作的複雜性或中斷。
“通過使我們能夠以與在物理環境中相同的方式在雲中使用集群配置,SIOS DataKeeper 軟件使我們能夠遷移到 AWS,而不會犧牲應用程序保護或完全改變我們現有系統的配置。 ” Gulliver 大約 30% 的現有本地系統已遷移到 AWS,而沒有對公司的系統管理進行任何更改或增加複雜性。
隨著 Gulliver 繼續執行其擴展計劃,它很快將需要保護更大量的數據和更廣泛的應用程序。 為了滿足這一需求,它將在將系統遷移到雲端時繼續使用 SIOS DataKeeper 軟件。 作為 APN(AWS 合作夥伴網絡)的標準諮詢合作夥伴,SIOS 致力於繼續提供在 AWS 上運行的高可用性系統。”