使用Msdtc #Sql #Azure #Msdtc在Azure虛擬機上配置SQL Server故障轉移群集實例
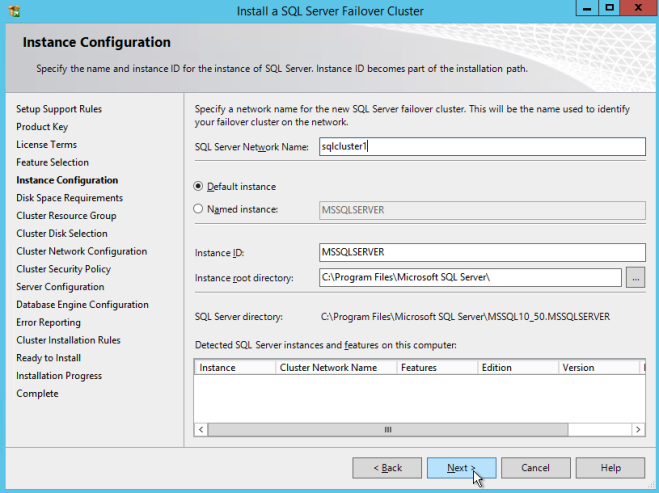
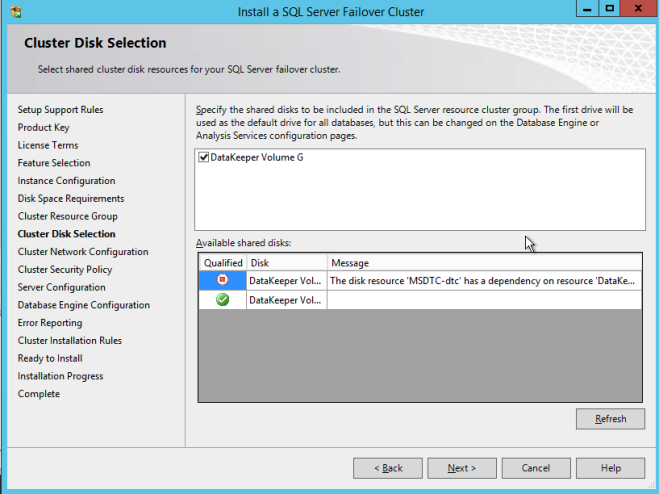
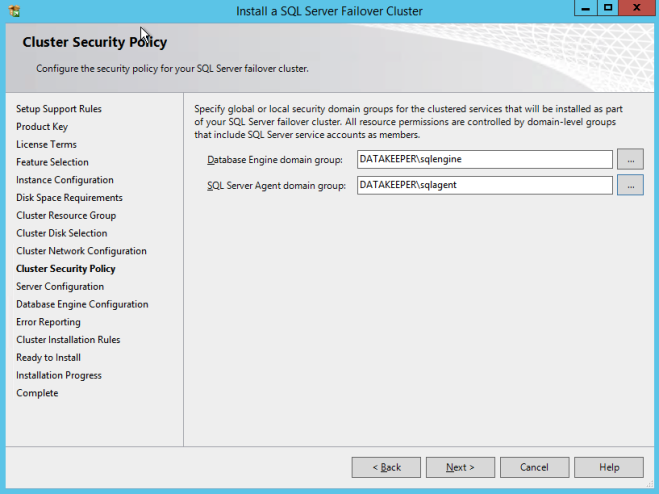
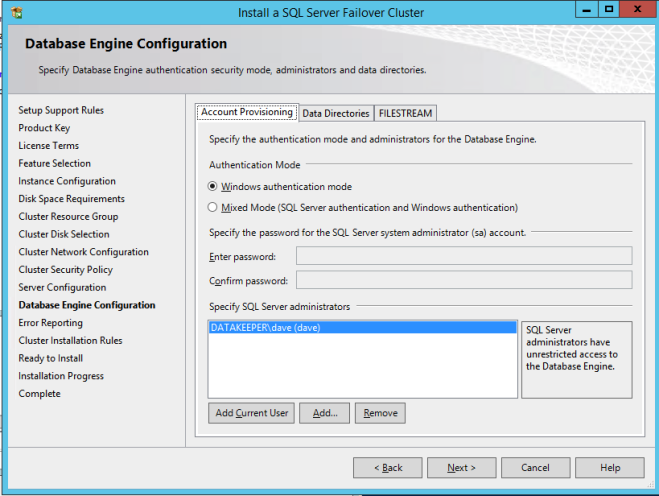
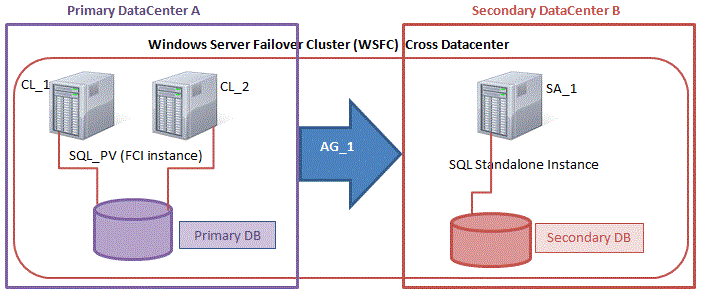
您可能知道我們已經包含了大量有關在Azure上構建SQL Server故障轉移群集實例(FCI)的分步指南,從SQL Server 2008到最新版本。這裡有一些鏈接可以幫助您入門。但實際上,不同版本的Windows和SQL Server之間的配置差別很小。所以我認為無論你使用什麼版本,你都能弄明白。循序漸進:如何配置MICROSOFT AZURE IAAS中的SQL SERVER FAILOVER CLUSTER INSTANCE(FCI)#SQLSERVER #AZURE #SANLESS逐步:如何配置SQL SERVER 2008 R2故障群集在AZURE中的實例我擁有什麼沒有解決的是如何處理MSDTC。微軟在這篇文章中發表了這篇文章。https://blogs.msdn.microsoft.com/sql_pfe_blog/2018/07/05/configure-sql-server-failover-cluster-instance-on-azure-virtual-machines-with-msdtc但是,僅限該文章/視頻解決SQL Server 2016及更高版本的問題。好消息是,大部分指南都可以應用於SQL Server 2008/2012/2014。在我有時間做一個正確的分步指導之前,我想記下一些基本的筆記,更多的是提醒自己。但是,您可能會發現此信息在此期間也很有用。以下步驟假定您已在Azure中創建了SQL Server FCI並對DTC資源進行了群集。有關這些步驟的詳細信息,請參閱上面的指南。以下步驟實際上只是詳細說明了Azure中所需的負載均衡器配置。
為MSDTC創建負載均衡器
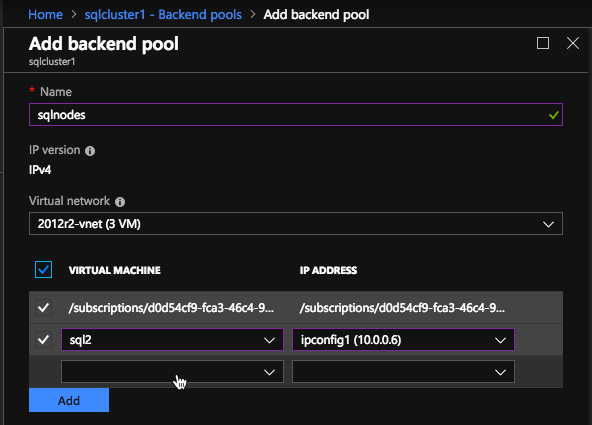
MSDTC資源將需要其自己的負載均衡器。我們將向負載均衡器添加一個新的前端,而不是創建新的負載均衡器,該前端應該已經為SQL Server FCI配置。當然,此前端IP地址應與與群集MSDTC資源關聯的群集IP地址匹配。對於後端池,只需重用您創建的包含SQL集群節點的現有池。您需要創建一個專用於MSDTC資源的新健康探針。您使用的端口必須與您用於SQL資源的端口不同。不要使用59999。也許使用像49999這樣的東西。最後一步是為MSDTC創建負載平衡規則。創建一個新規則並引用我們剛剛創建的MSDTC前端和現有的後端。接下來,我們需要創建一個新的負載平衡規則。MSDTC使用臨時端口,這是一個很大的端口範圍。在創建規則時,必須選擇“HA Ports”框。最後,確保啟用了直接服務器返回。
更新MSDTC群集IP資源
像SQL Server群集IP地址一樣工作。我們需要運行一個Powershell命令,該命令將使MSDTC集群IP資源響應我們剛剛創建的探測端口49999的運行狀況探測。它還將該MSDTC群集IP地址的子網掩碼設置為255.255.255.255,以避免與我們設置的共享相同地址的負載均衡器前端發生IP地址衝突。
#define variables $ ClusterNetworkName =“”
#群集網絡名稱(使用Get-ClusterNetwork)
更高的Windows Server 2012查找MSDTC資源的名稱)
$ IPResourceName =“”
#MSDTC資源的IP地址資源名稱$ ILBIP =“”
#內部負載均衡器(ILB)和MSDTC資源的IP地址
導入模塊FailoverClusters
#如果您使用的是Windows Server 2012或更高版本:
Get-ClusterResource $ IPResourceName | SET-ClusterParameter
-Multiple @ {Address = $ ILBIP; ProbePort = 49999; SubnetMask =“255.255.255.255”;
網絡= $ ClusterNetworkName; EnableDHCP時= 0}
#如果您使用的是Windows Server 2008 R2,請使用以下命令:
#cluster res $ IPResourceName / priv enabledhcp = 0 address = $ ILBIP probeport = 59999
子網掩碼= 255.255.255.255確認它正在工作!
您可以使用DTCPing或進入組件服務,並查看計算機>我的計算機>分佈式事務處理協調器,您應在其中看到本地DTC和群集DTC。任何分佈式事務都應出現在群集DTC中,而不是本地DTC中。查看此視頻,了解如何創建分佈式事務以進行測試的示例。
下一步
這是一個快速而骯髒的指南。對於有經驗的用戶,它應該在Azure中啟動並運行MSDTC資源。我將在不久的將來發布詳細的分步指南。在此期間,如果您遇到困難,請不要猶豫,在Twitter @daveberm上與我聯繫