Date: 29 1 月, 2022

通過高可用性最大限度地減少停機時間
對於現代企業來說,停機時間變得比以往任何時候都更加昂貴。 ITIC 2021 年每小時停機成本調查發現,在 91% 的組織中,關鍵業務系統、數據庫或應用程序停機一小時的平均成本超過 300,000 美元,而對於 18% 的大型企業來說,一小時的停機時間超過 500 萬美元。
高可用性(HA) 是系統、數據庫或應用程序的屬性,旨在長時間連續可靠地運行。 HA 的目標是減少或消除關鍵應用程序的計劃外停機時間。 這是通過在關鍵業務系統、數據庫或應用程序的設計中結合冗餘組件和其他技術來消除單點故障來實現的。
SLA 和 HA 指標
服務提供商使用服務級別協議 (SLA) 來保證客戶的關鍵業務系統、數據庫或應用程序在業務需要時啟動並運行。
IDC 創建了一個 SLA 模型,該模型定義了以下五個級別的正常運行時間要求:
- AL4(持續可用性 – 系統容錯):每年不超過 5 分 15 秒的計劃內和計劃外停機時間(99.999% 或“五個九”的可用性)
- AL3(高可用性 – 傳統集群):每年計劃內和計劃外停機時間不超過 52 分 35 秒(99.99% 或“四個九”的可用性)
- AL2(恢復 – 數據複製和備份):每年計劃和計劃外停機時間不超過 8 小時 45 分 56 秒(99.9% 或“三個九”的可用性)
- AL1(可靠性 – 可熱插拔組件):每年計劃和計劃外停機時間不超過 87 小時 39 分 29 秒(99% 或“兩個九”的可用性)
- AL0(未受保護的服務器):沒有可用性或正常運行時間保證
據 ITIC 稱,89% 的受訪組織現在要求其關鍵業務系統、數據庫和應用程序具有“四個九”的可用性,其中 35% 的組織進一步努力實現“五個九”的可用性。
除了正常運行時間和可用性之外,另外兩個重要的 HA 指標是恢復時間目標(RTO)和恢復點目標(RPO)。 RTO 是任何中斷的最大可容忍持續時間,RPO 是發生故障時可以容忍的最大數據丟失量。 與通常以小時和天定義的災難恢復 RTO 和 RPO 指標不同,關鍵業務系統、數據庫和應用程序的 RTO 和 RPO 指標通常只有幾秒鐘 (RTO) 和零 (RPO)。
高可用性集群
HA 集群通常由服務器節點、存儲和集群軟件組成。
傳統聚類
傳統的本地 HA 集群是一組連接到共享存儲(通常是存儲區域網絡或 SAN)的兩個或多個服務器節點,這些節點配置有相同的操作系統、數據庫和應用程序(請參閱圖1 )。
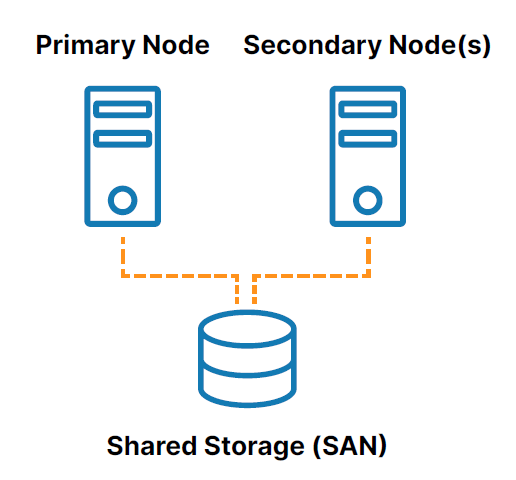
其中一個節點被指定為主(或活動)節點,其他(或多個)被指定為輔助(或備用)節點。 如果主節點發生故障,集群允許系統、數據庫或應用程序自動故障轉移到一個或多個輔助節點,並以最小的中斷繼續運行。 由於輔助節點連接到同一個存儲,因此操作繼續進行,數據丟失為零。
然而,在傳統集群模型中使用共享存儲帶來了一些挑戰,包括:
- 共享存儲本身是一個單點故障,可能會使集群中所有連接的節點脫機。
- SAN 存儲的擁有和管理成本高且複雜。
- 雲中的共享存儲會增加大量不必要的成本和復雜性,一些雲提供商甚至不提供共享存儲選項。
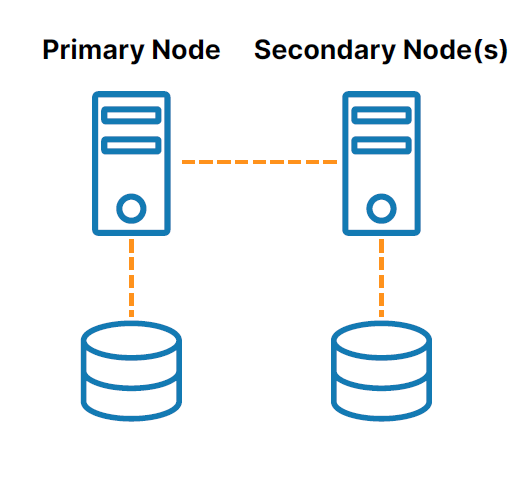
SANless 集群
無 SAN 或“無共享”集群(請參閱圖 2 ) 解決與共享存儲相關的挑戰。 在這些配置中,每個集群節點都有自己的本地存儲。 高效的基於主機的塊級複製用於同步集群節點上的存儲,保持它們相同。 如果發生故障轉移,輔助節點會訪問主節點使用的存儲的相同副本。
集群軟件
集群軟件允許您將服務器配置為集群,以便多台服務器可以協同工作以提供 HA 並防止數據丟失。 各種集群軟件解決方案可用於 Windows、Linux 發行版和各種虛擬機管理程序。 但是,這些解決方案中的每一個都限制了您的靈活性和部署選項,並帶來了各種挑戰,例如技術複雜性和昂貴的許可費用。
不要等待災難來襲
HA 對於關鍵業務系統、數據庫和應用程序至關重要。 但是隨著無數平台的可用,複雜性顯著增加。 這就是為什麼應用程序感知解決方案如此有意義的原因。 您需要的是一個在高可用性方面擁有豐富專業知識的值得信賴的合作夥伴——像 SIOS 這樣的合作夥伴,它擁有確保您的業務保持正常運行的技術知識。
不要等待中斷或災難來確定您是否具備業務所需的彈性。 立即在以下位置安排個性化演示https://us.sios.com了解 SIOS 可以為您的業務做些什麼。
轉載自西歐