
在重大云中断中管理实时恢复
灾难发生,突然停工成为现实。但是,所有客户都可以做的事情是在几乎任何云中断中存活下来。东西发生了。失败 – 无论大小 – 都是不可避免的。不可避免的是延长的停机时间。考虑美国中南部地区的微软Azure云遭遇灾难性失败的那一天。一场严重的雷暴导致了一连串的问题,最终导致整个数据中心崩溃。在一些人称之为“天空中的Azure云天”中,大多数客户都处于离线状态,不仅仅是几秒钟或几分钟,而是一整天。有些人离线超过两天。虽然微软已经解决了导致停电的许多问题,但IT专业人员将长期记住这一事件。这是坏消息。好消息是:Azure客户可以做的事情几乎可以在任何中断中存活。它可能来自单个服务器,无法使整个数据中心脱机。实际上,实现强大的高可用性和/或灾难恢复规定的Azure客户,无论是实时数据复制还是快速自动故障转移,都可以避免数据丢失,并且每当发生灾难时都很少或没有停机时间。另请参阅:Nutanix认为企业云赢得了云计算竞赛
管理云中断
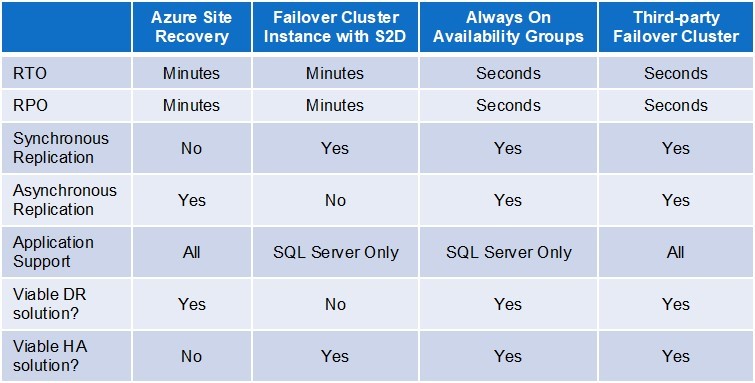
本文介绍了在混合和纯Azure云配置中提供灾难恢复(DR)和高可用性(HA)保护的四个选项。其中两个选项特定于Microsoft SQL Server数据库,这是Azure云中的一个流行应用程序;另外两个选项是与应用程序无关的。这四个选项也可用于各种组合,在表格中进行了比较,包括:
- Azure站点恢复(ASR)服务
- 具有存储空间直接的SQL Server故障转移群集实例
- SQL Server始终在可用性组
- 第三方故障转移群集软件
RTO和RPO 101
在描述这四个选项之前,有必要对用于评估DR和HA规定的有效性的两个指标有一个基本的了解:恢复时间目标和恢复点目标。熟悉RTO和RPO的人可以跳过本节。RTO是中断的最大可容忍持续时间。在线事务处理应用程序通常具有最低的RTO,而关键任务应用程序通常具有仅几秒的RTO。RPO是可以容忍数据丢失的最长期限。如果不能容忍数据丢失,则RPO为零。RTO通常会确定所需的HA和/或DR保护的类型。低恢复时间通常需要强大的HA规定来防止日常系统和软件故障,而较长的RTO可以满足基本DR规定,旨在防范更广泛但更不频繁的灾难。与HA和DR规定一起使用的数据复制可能需要在RTO和RPO之间进行潜在的权衡。在低延迟LAN环境中,复制可以是同步的,可以同时更新主数据集和辅助数据集。这使得完全恢复能够自动且实时地发生,从而可以满足最苛刻的恢复时间和恢复点目标(分别为几秒和零),无需权衡。相反,在整个WAN中,强制主要服务器等待辅助服务器确认每个事务的更新完成将对性能产生负面影响。因此,WAN中的数据复制通常是异步的。这可以在容纳RTO和RPO之间进行权衡,这通常会导致恢复时间的增加。原因如下:为了满足零RPO,需要手动过程以确保在故障转移发生之前所有数据(例如来自事务日志)已在辅助设备上完全复制这种额外的工作会延长恢复时间,这就是为什么这样的配置通常用于DR而不是HA。
Azure站点恢复(ASR)服务
ASR是Azure的DR-as-a-service(DRaaS)产品。ASR将物理机和虚拟机复制到其他Azure站点,可能在其他区域,或从本地实例复制到Azure云。该服务可以从系统和站点中断中快速恢复,并通过消除滚动软件升级期间的停机时间来促进计划内维护。与所有DRaaS产品一样,ASR有一些限制,最严重的是无法自动检测和故障转移导致应用程序级停机的许多故障。当然,这就是为什么该服务被定性为DR而不是HA的原因。使用ASR,恢复时间通常为3-4分钟,当然,这取决于管理员能够以多快的速度手动检测和响应问题。如上所述,跨WAN的异步数据复制的需求可以进一步增加RPO为零的应用程序的恢复时间。
具有存储空间直接的SQL Server故障转移群集实例
SQL Server提供了两个自己的HA / DR选项:故障转移群集实例(此处讨论)和Always On Availability Groups(下面讨论)。FCI提供两个优点:该功能可以在较便宜的SQL Server标准版中使用,并且它不依赖于像传统HA集群那样的共享存储。后一个优势很重要,因为云中的共享存储根本不可用 – 来自Microsoft或任何其他云服务提供商。Azure云存储的一个流行选择是Storage Spaces Direct(S2D),它支持广泛的应用程序,它对SQL Server的支持保护整个实例而不仅仅是数据库。S2D的一个主要缺点是服务器必须位于单个数据中心内,这使得该选项适用于某些HA需求,但不适用于DR。对于多站点HA和DR保护,需要通过日志传送或第三方故障转移群集解决方案提供必需的数据复制。
SQL Server始终在可用性组
虽然Always On Availability Groups是SQL Server为HA和DR提供的最强大的产品,但它需要许可更昂贵的Enterprise Edition。此选项可以提供5-10秒的恢复时间和几秒或更短的恢复点。它还提供可读的辅助数据库,用于查询数据库(具有适当的许可),并且不对数据库的大小或辅助实例的数量进行限制。提供HA和DR保护的Always On Availability Groups配置包括三个节点的安排,在单个可用性集或区域中有两个节点,第三个在单独的Azure区域中。一个值得注意的限制是只复制数据库,而不是整个SQL实例,必须通过其他方式进行保护。除了对某些数据库应用程序成本过高之外,这种方法还有另一个缺点。特定于应用程序需要IT部门为所有其他应用程序实施其他HA和DR规定。使用多个HA / DR解决方案可能会大大增加复杂性和成本(用于许可,培训,实施和持续运营),这也是组织越来越倾向于使用与应用程序无关的第三方解决方案的另一个原因。
第三方故障转移群集软件
凭借其与应用程序无关且与平台无关的设计,故障转移群集软件能够为私有,公共和混合云环境中的几乎所有应用程序提供完整的HA和DR解决方案。这包括Windows和Linux。与应用程序无关,无需为不同的应用程序提供不同的HA / DR规定。与平台无关,可以利用Azure云中的各种功能和服务,包括故障域,可用性集和区域,区域对和Azure站点恢复。作为完整的解决方案,该软件至少包括实时数据复制,能够检测应用程序级故障的连续监视,以及用于故障转移和故障恢复的可配置策略。大多数解决方案还提供各种增值功能,使故障转移群集能够在几乎没有数据丢失的情况下提供低于20秒的恢复时间,从而满足几乎所有HA / DR需求。
让它真实
无论是单独运行还是一致运行,所有这四个选项都可以发挥作用,使DR和HA保护的连续性对于各种企业应用程序更有效和更实惠。这包括那些能够容忍一些数据丢失和延长的停机时间的系统,以及那些需要实时恢复以实现5到9个正常运行时间且数据丢失很少或没有数据丢失的系统。为了在现实世界中实现下一次云中断,请确保您选择的任何DR和/或HA规定配置为至少两个节点分布在两个站点上。还要确保了解条款满足每个应用程序的恢复时间和恢复点目标的程度。以及可能存在的任何限制,包括检测所有可能的故障所需的手动过程,以及确保应用程序连续性和数据完整性的方式触发故障转移。
关于Jonathan Meltzer
Jonathan Meltzer是SIOS Technology的产品管理总监。他在软件和SaaS产品的产品管理和营销方面拥有20多年的经验,可帮助客户管理,转换和优化其人力资本和IT资源。从RTinsights转载