| 4月 24, 2024 |
SIOS 技术加入 Nutanix Elevate 合作伙伴计划 |
||||||||||||||||||||||||||||
| 4月 22, 2024 |
分步操作 – OCI 中的 SQL Server 2019 故障转移群集实例 (FCI) |
||||||||||||||||||||||||||||


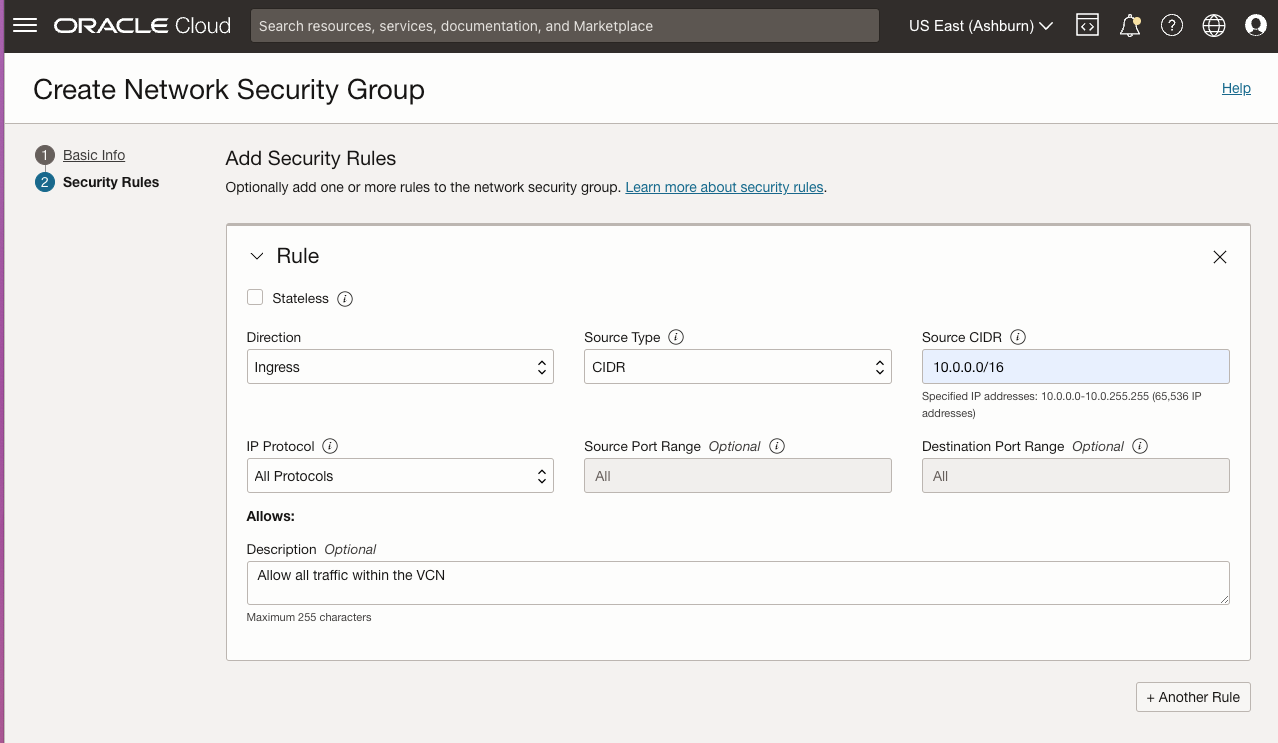
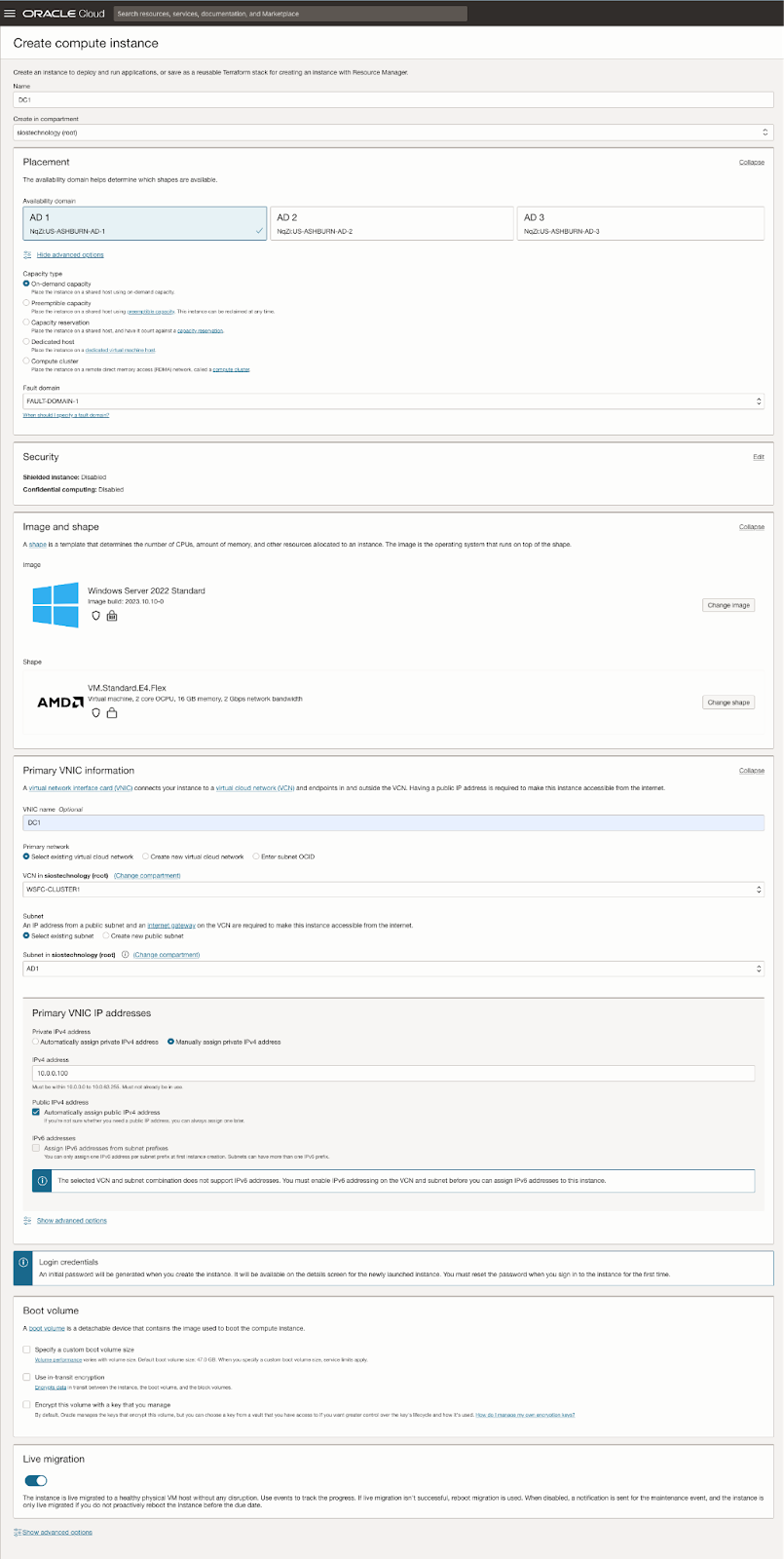
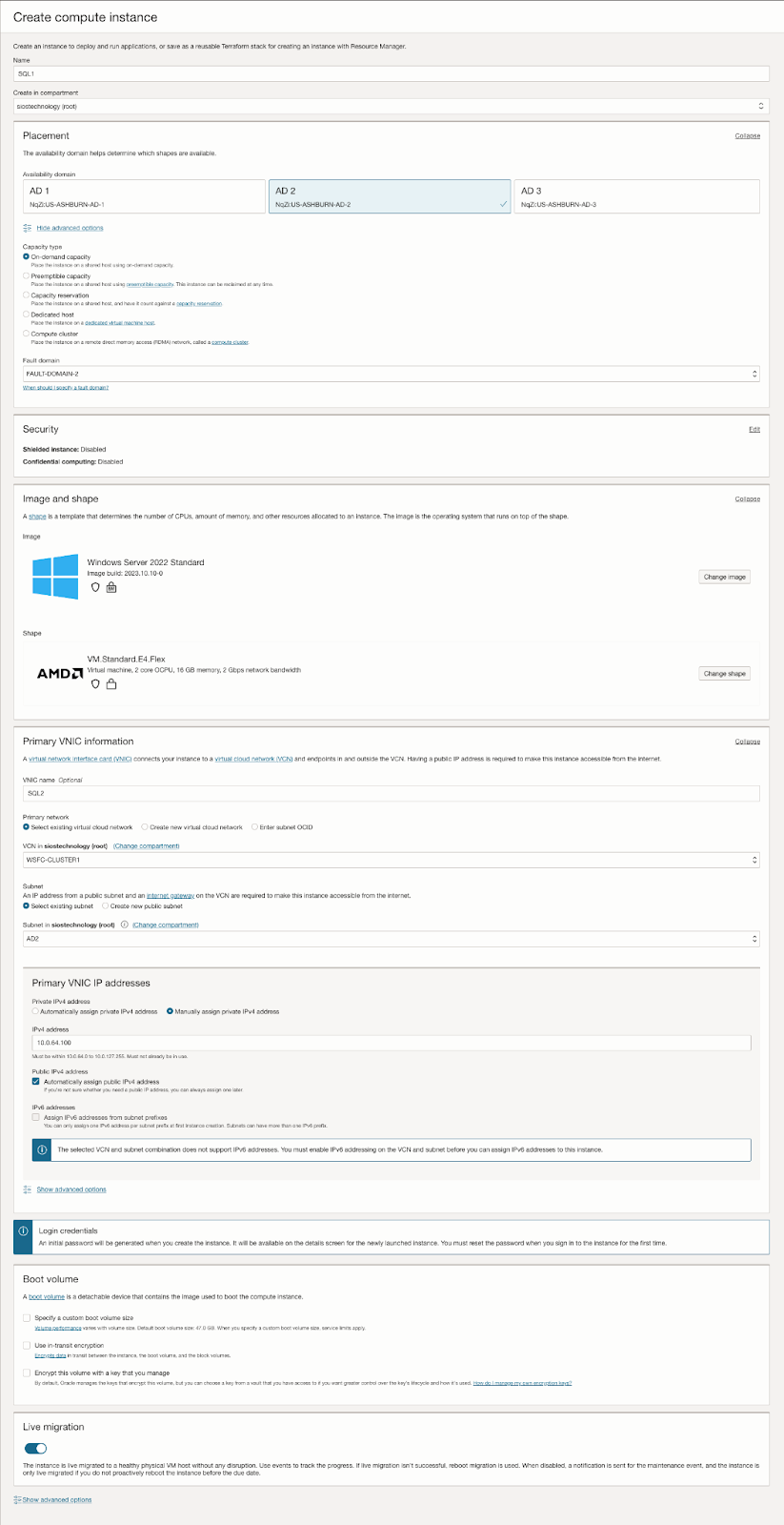
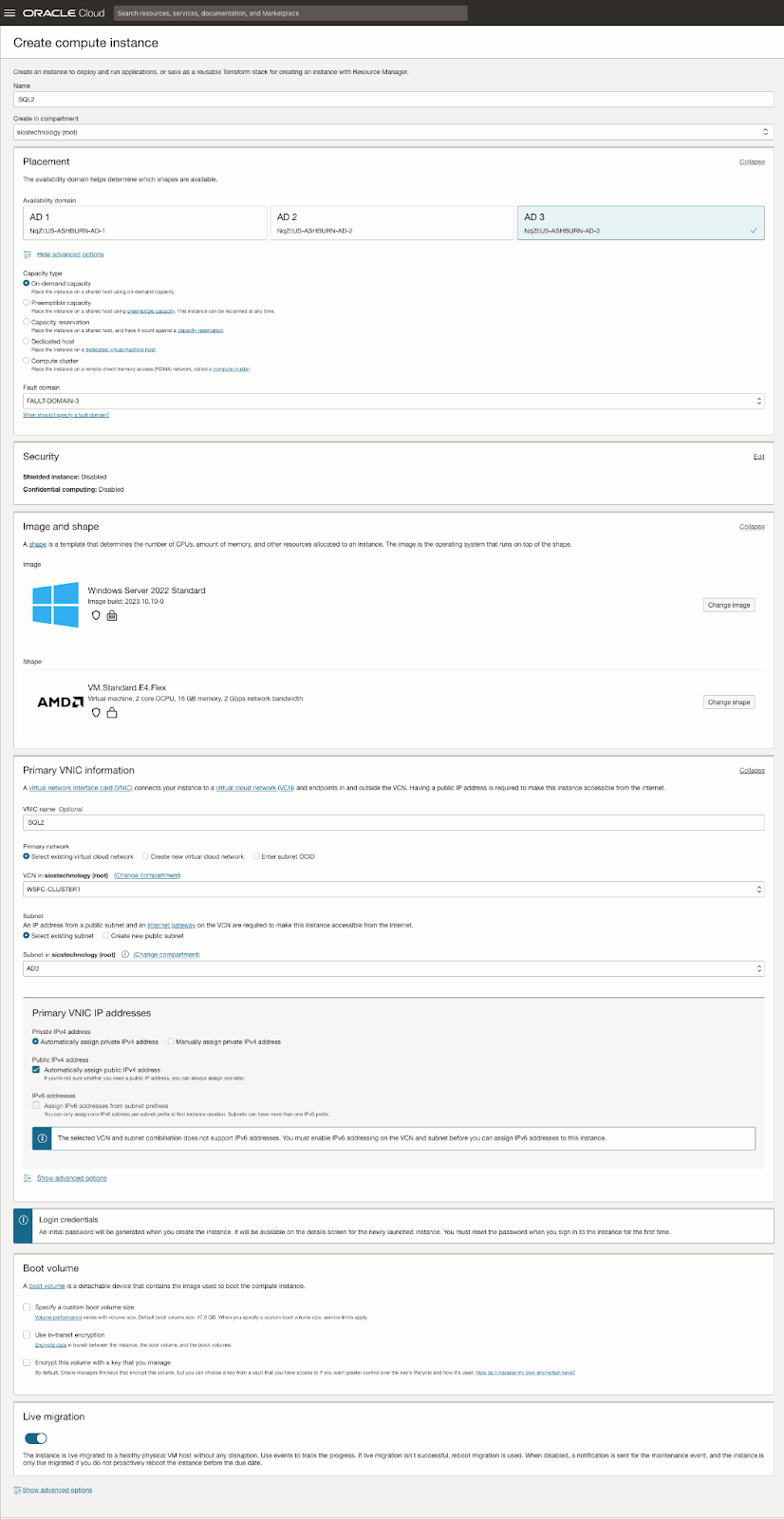
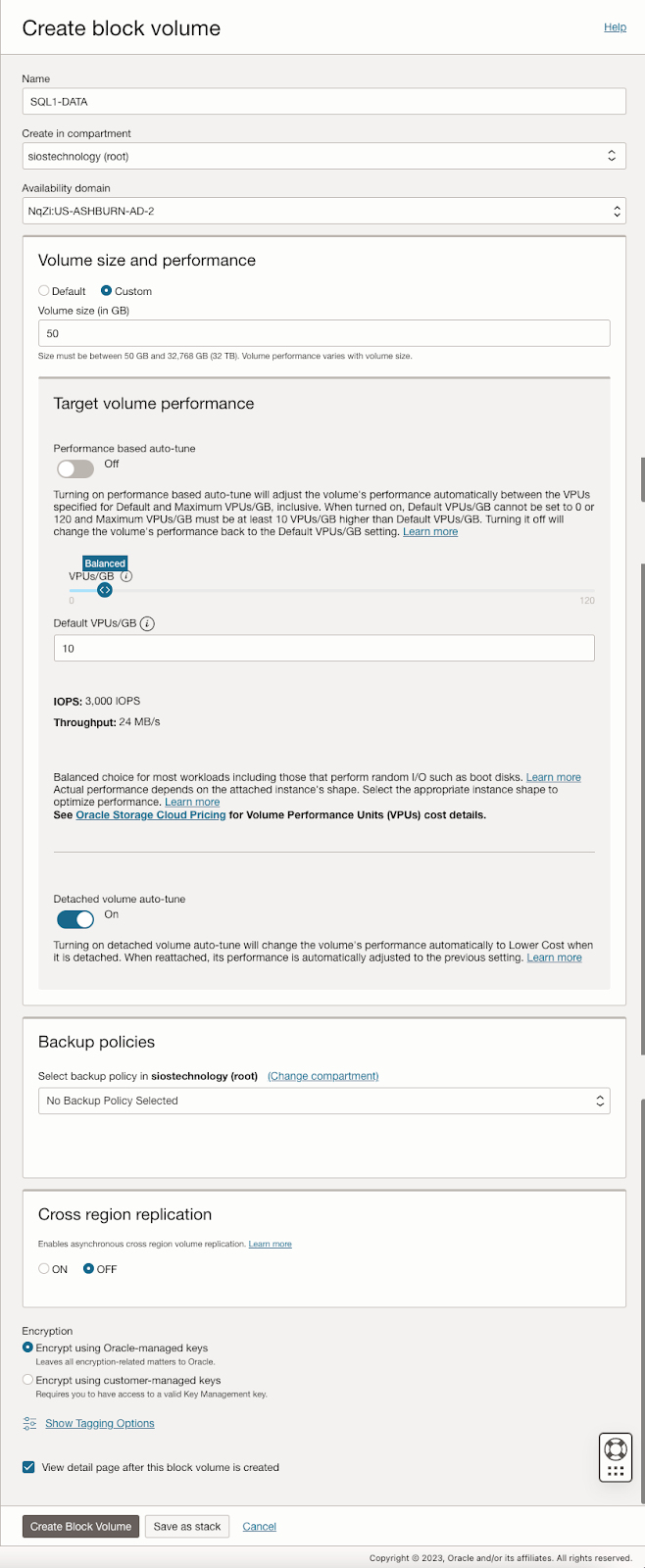
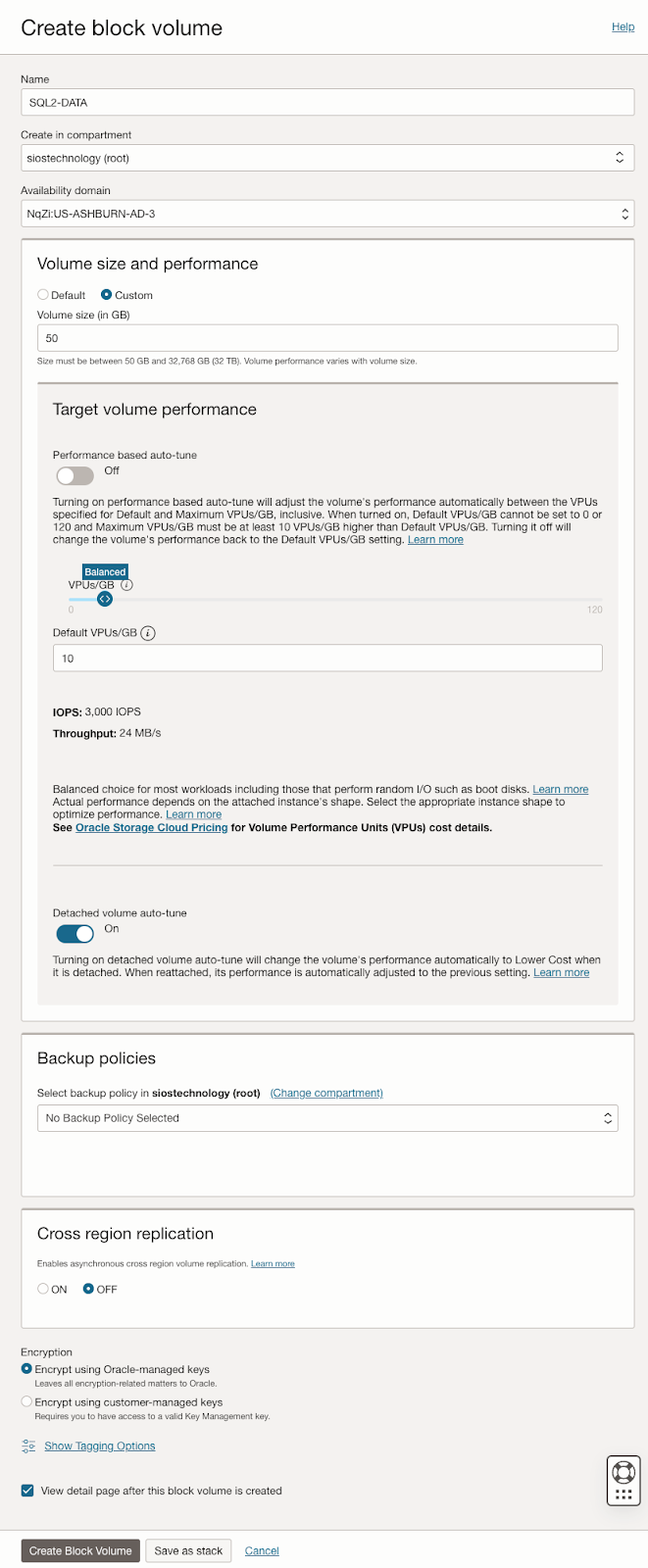
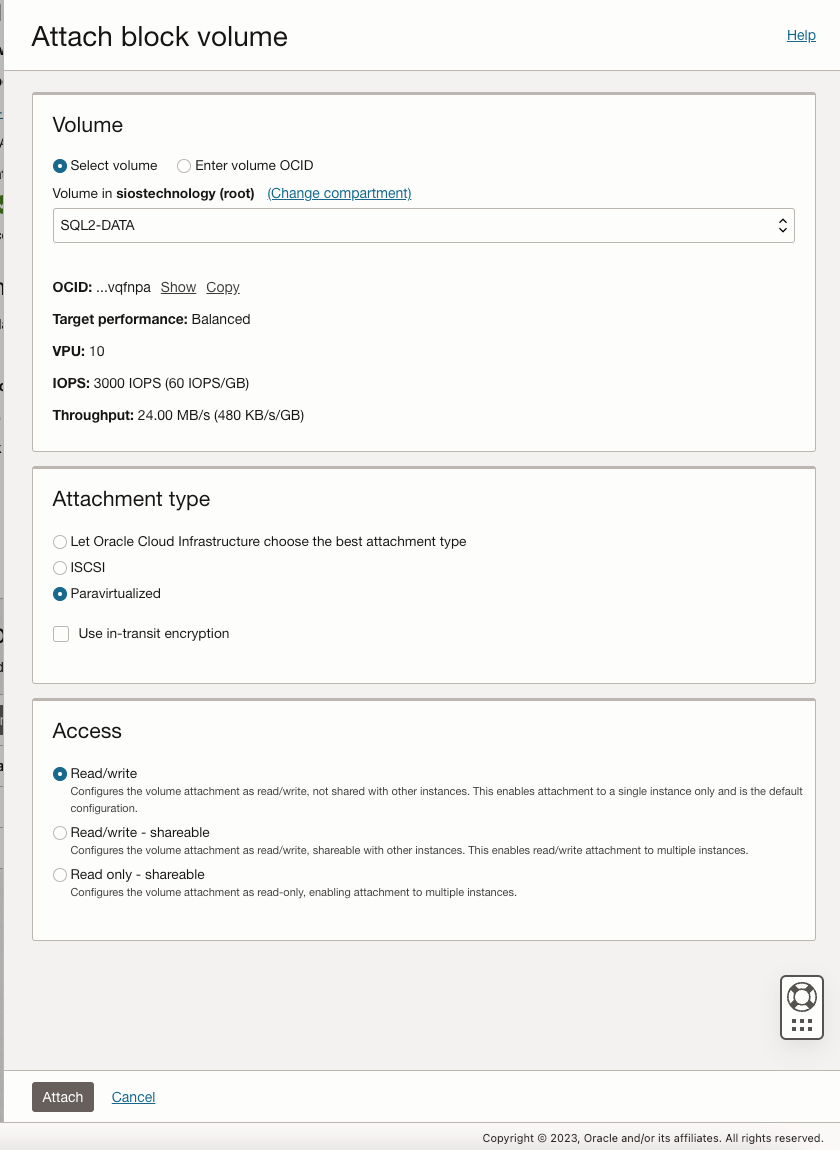
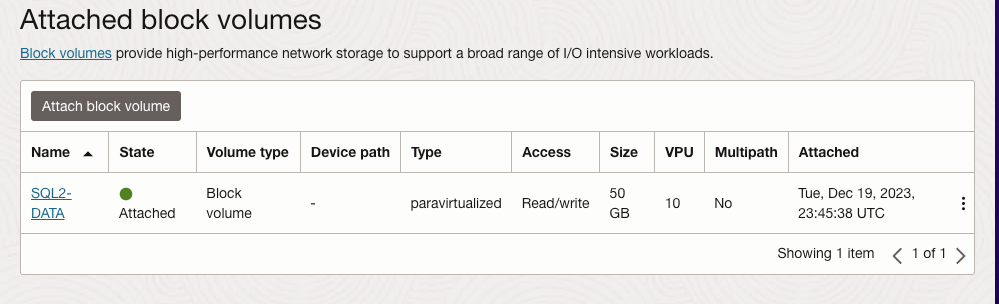
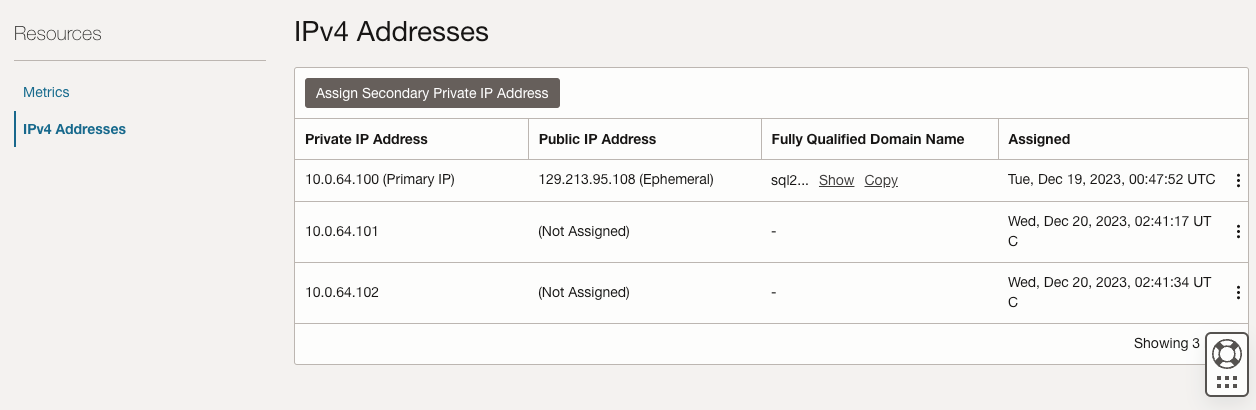
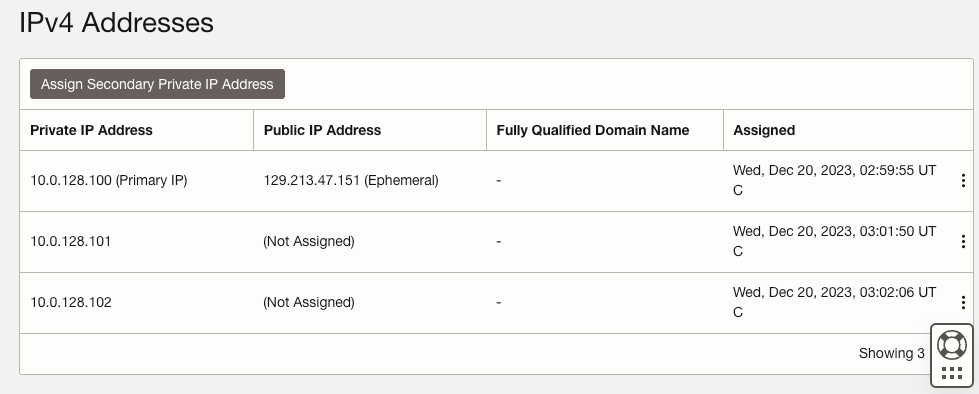
| SQL1 | SQL2 | |
| 主要地址 | 10.0.64.100 | 10.0.128.100 |
| 集群IP 1(核心集群资源) | 10.0.64.101 | 10.0.128.101 |
| 集群IP 2(SQL Server集群IP) | 10.0.64.102 | 10.0.128.102 |
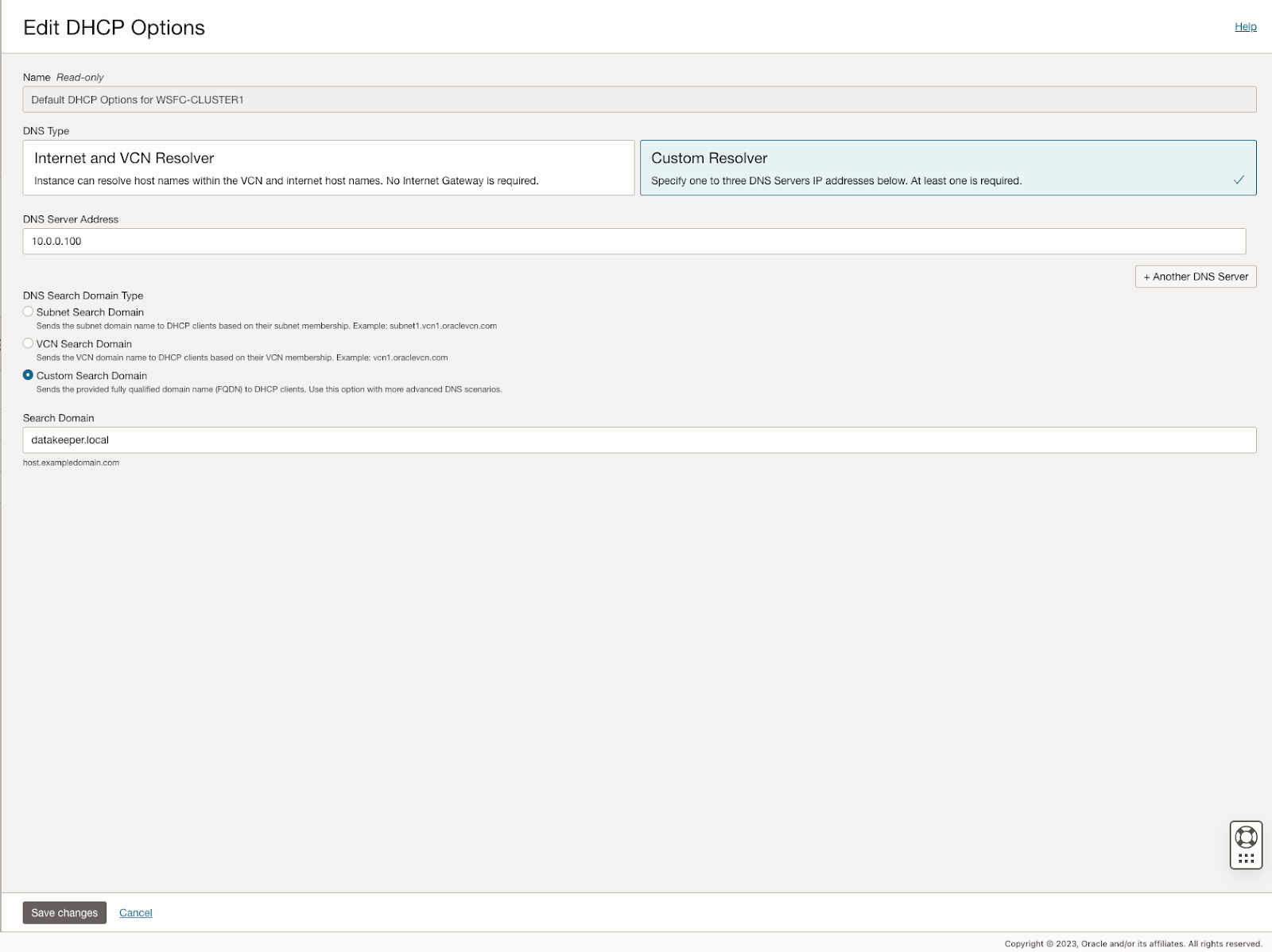
在 SQL1 和 SQL2 上,编辑附加的 VNIC 以添加辅助地址。
创建域
为了实现弹性,您应该跨不同的可用区配置多个 AD 控制器,但出于本指南的目的,我们将仅配置一个 AD 控制器。按照下面的屏幕截图在 DC1 上配置 AD。
使用实例详细信息部分中列出的凭据登录。系统将提示您重置密码。
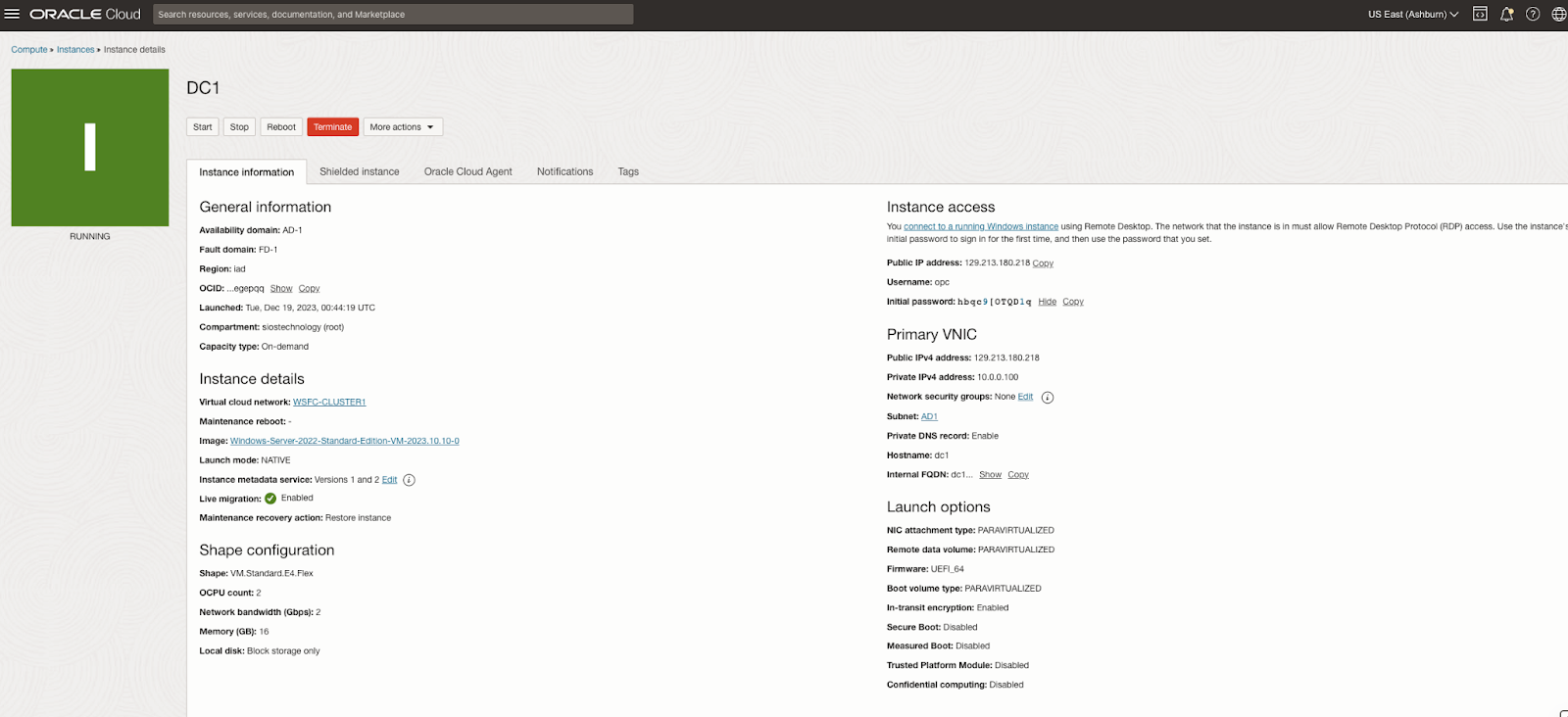
启用 Active Directory 域服务
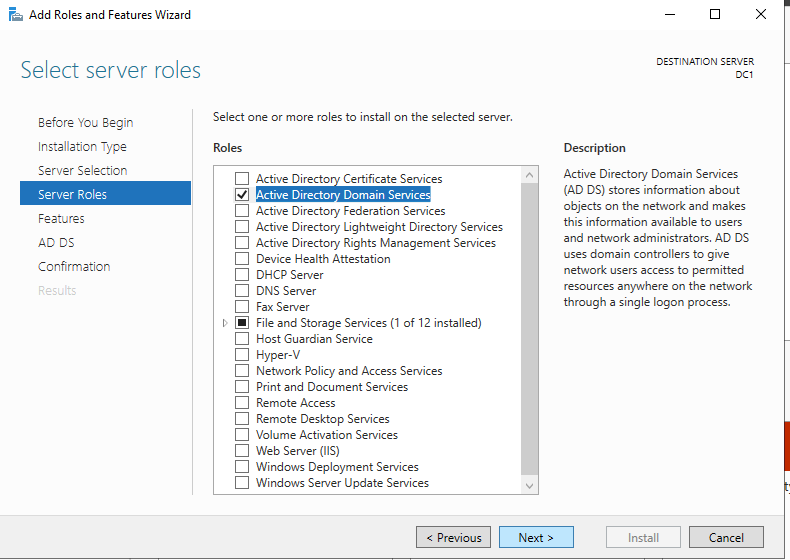
将服务器升级为域控制器
在开始此过程之前,请在服务器上启用本地管理员帐户并设置密码。如果不这样做,当您尝试升级域控制器时,您将收到此消息。
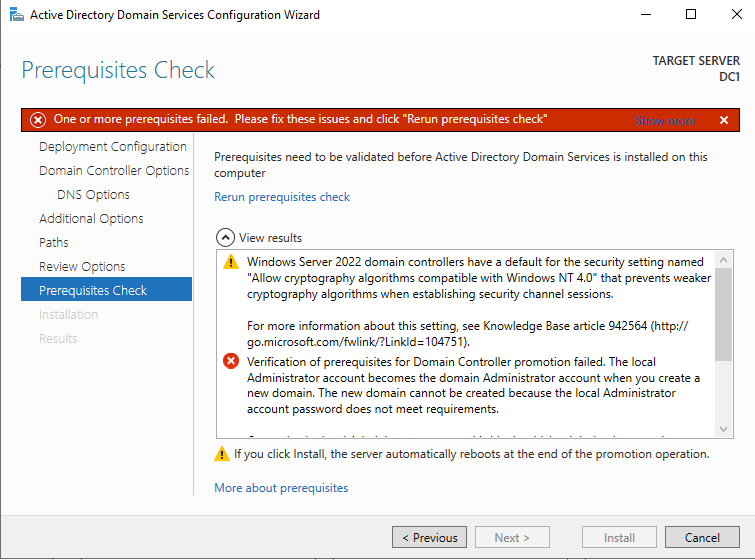
启用管理员帐户并设置密码后,继续进行部署后配置
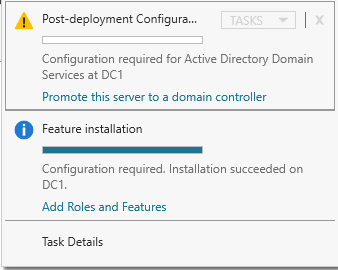
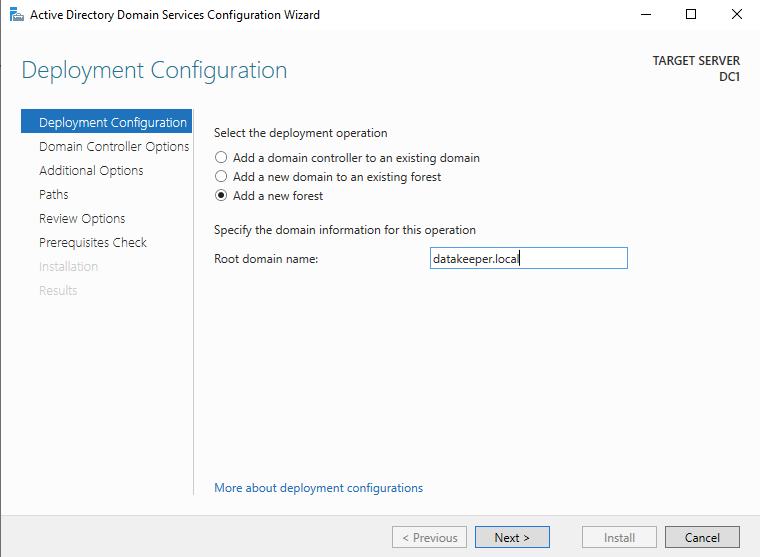
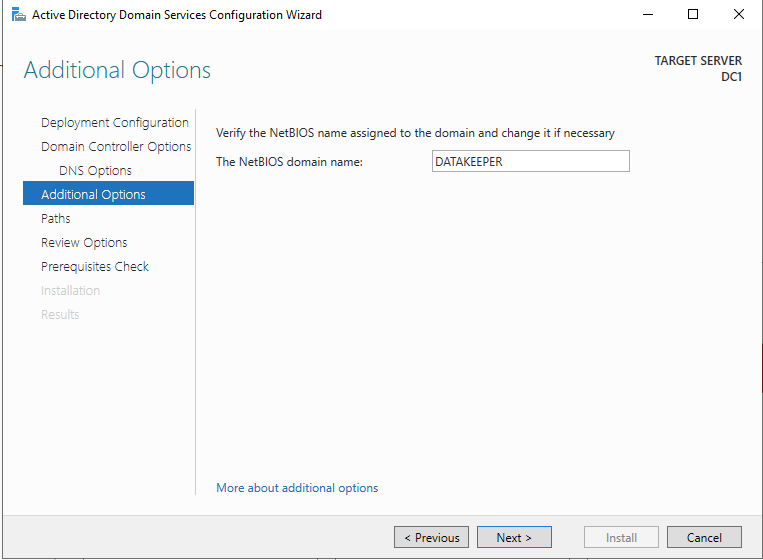
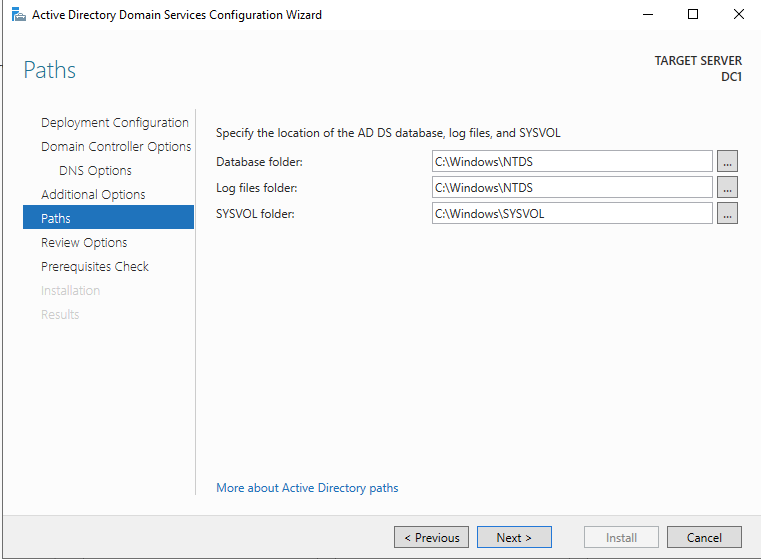
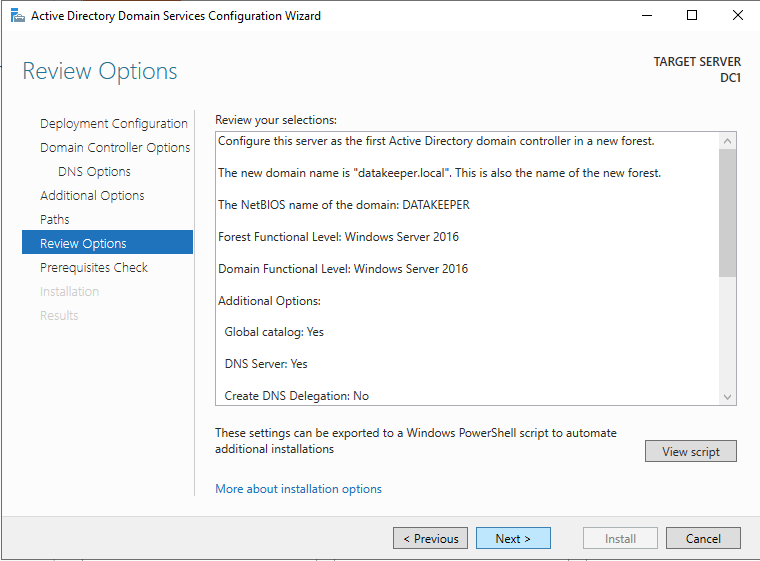
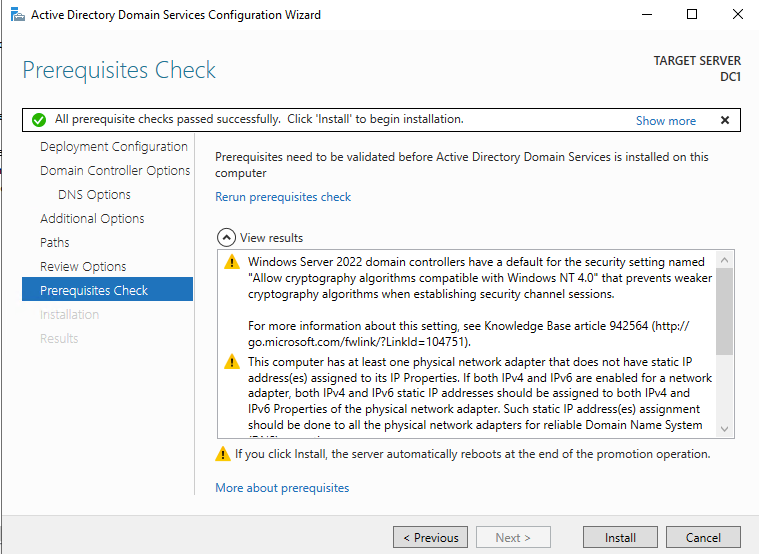
在启用 Active Directory 域服务之前,您必须启用本地管理员帐户并使用该帐户登录。
使用您最喜欢的 RDP 程序,使用与实例关联的公共 IP 地址连接到 DC1。添加 Active Directory 域服务角色。
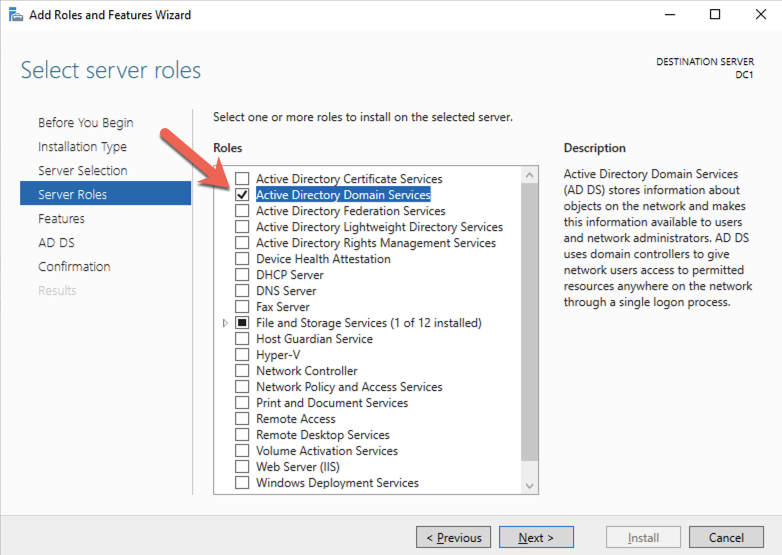
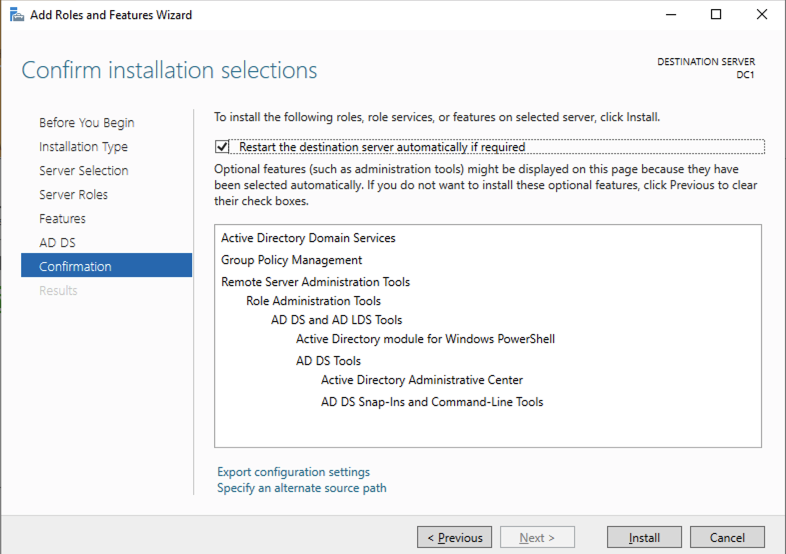
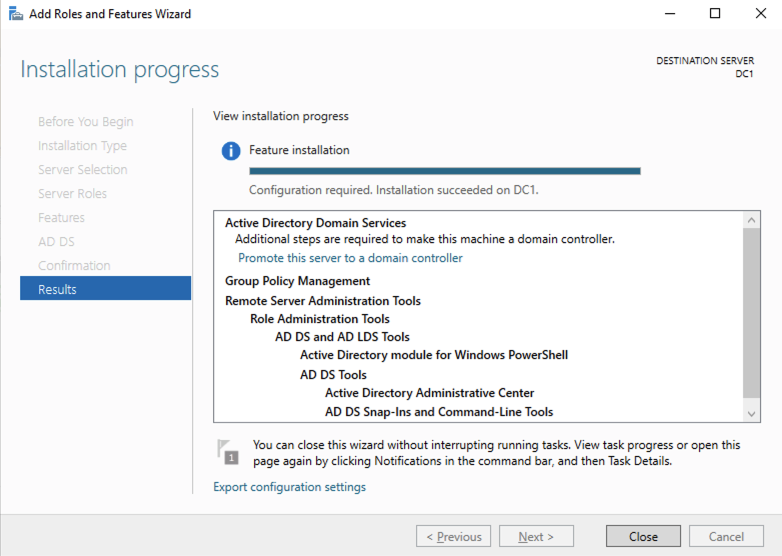
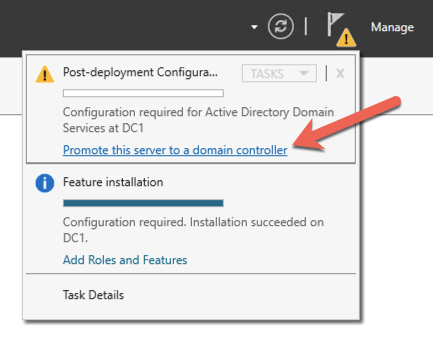
安装完成后,将此服务器提升为域控制器。
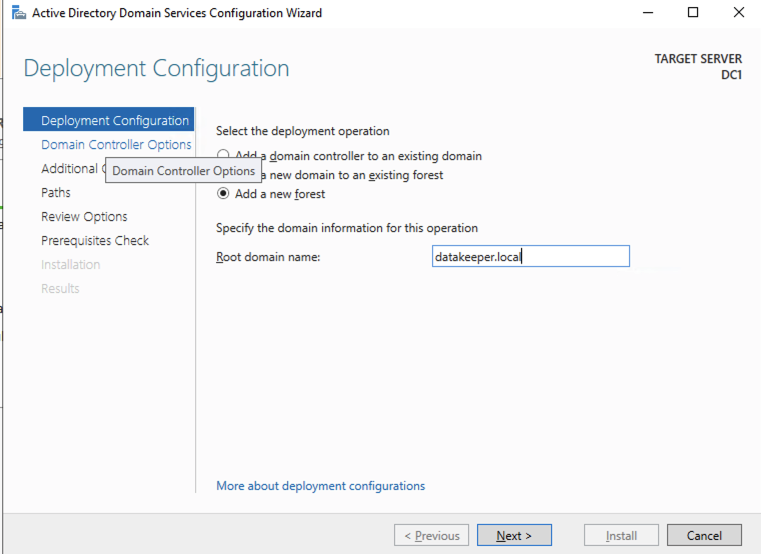
出于我们的目的,我们将创建一个新域。
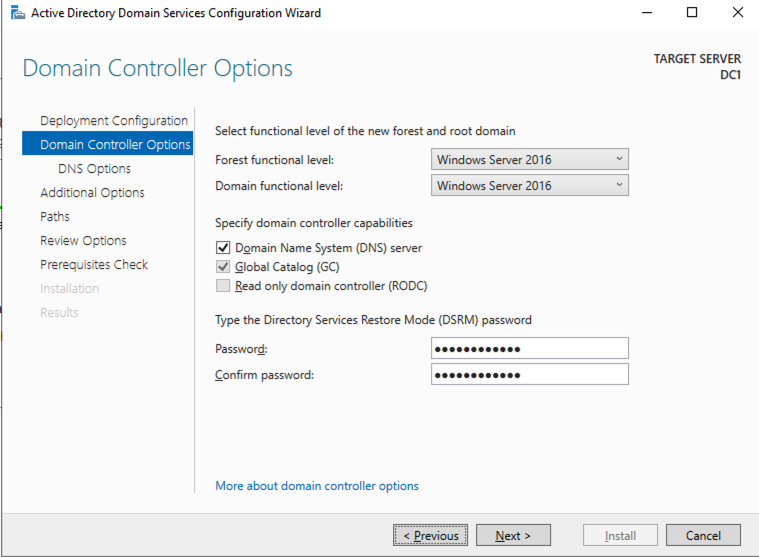
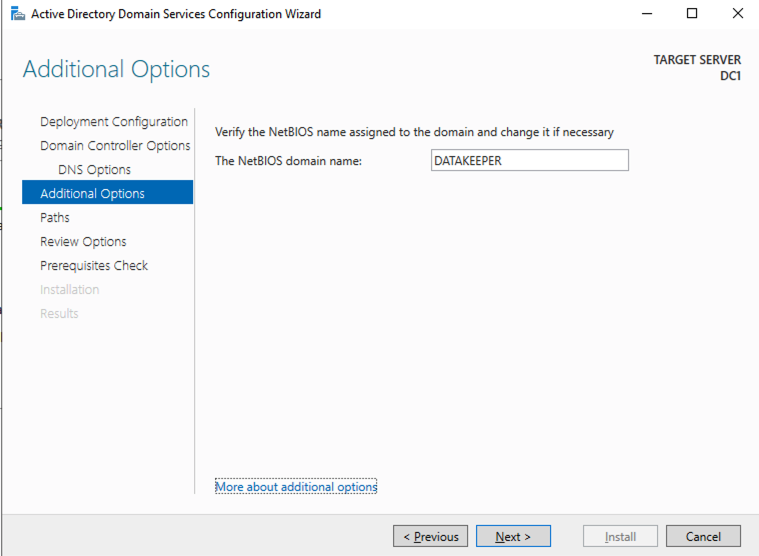
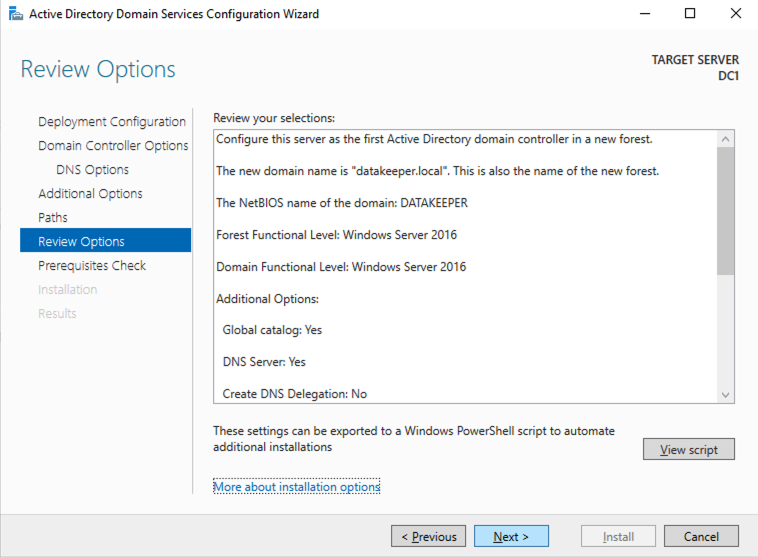
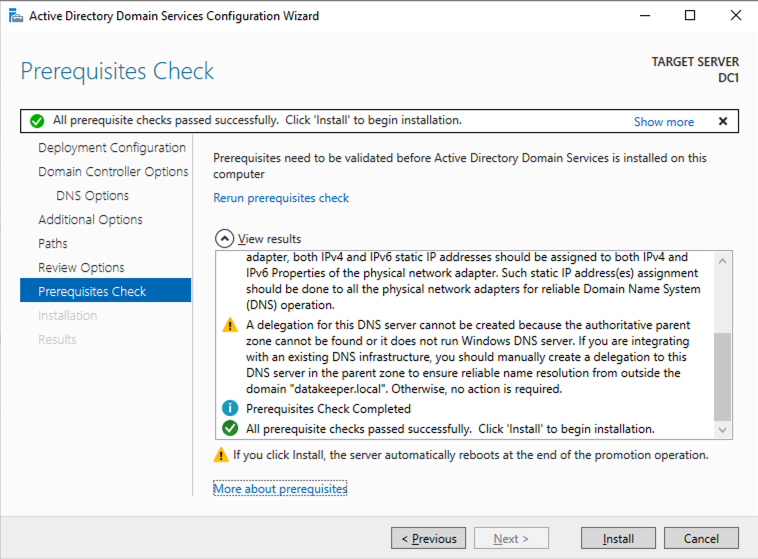
重新启动 DC1 并继续下一部分。
将 SQL1 和 SQL2 添加到域
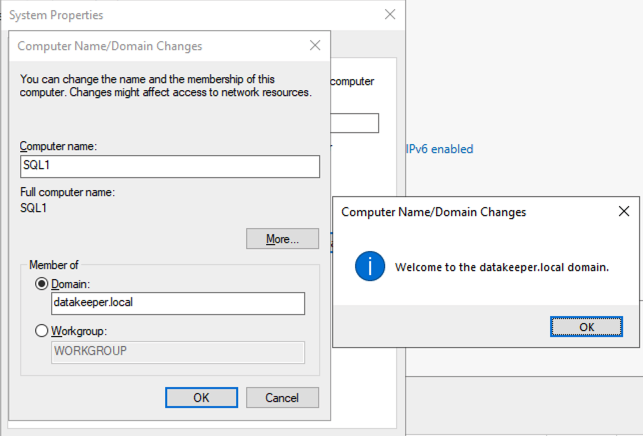
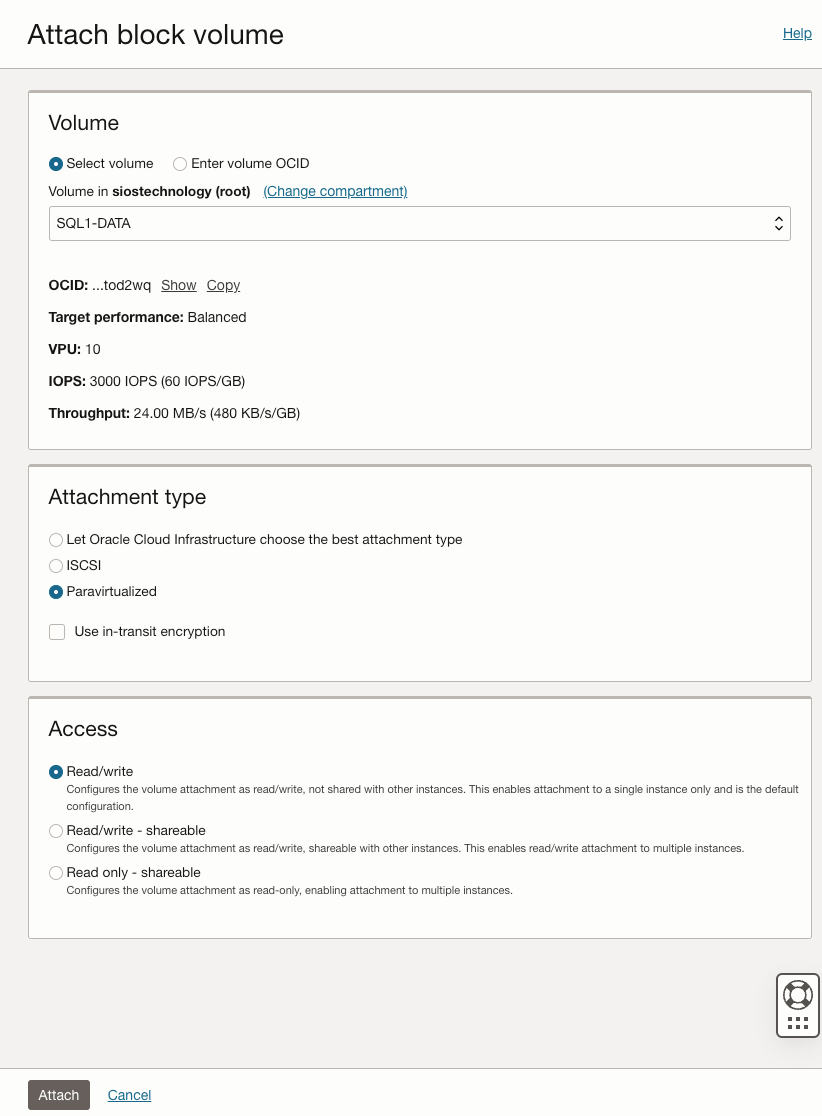
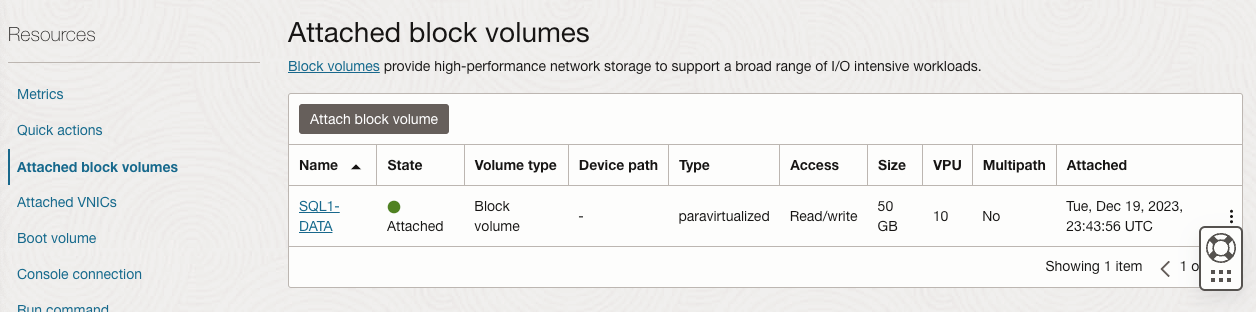
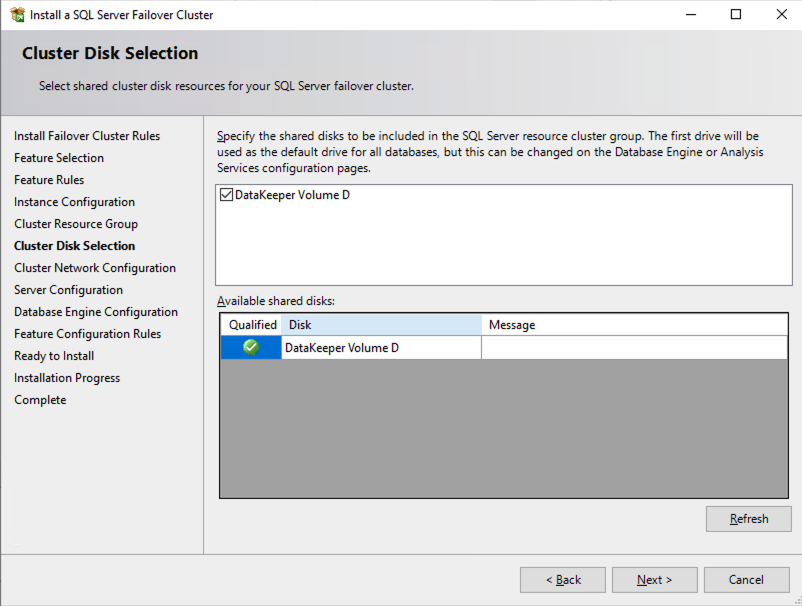
准备存储
将 SQL1 和 SQL2 添加到域后,使用您创建的域管理员帐户连接到实例以完成其余的配置步骤。您需要做的第一件事是附加并格式化我们添加到 SQL1 和 SQL2 的 EBS 卷,如下所示。
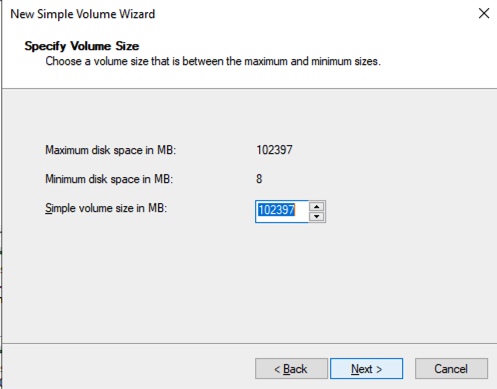
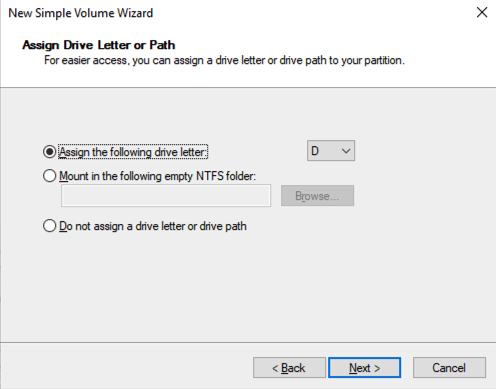
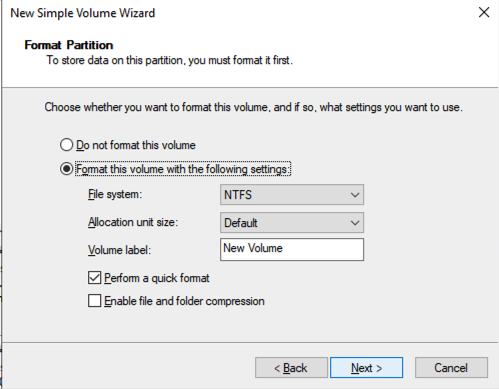
配置故障转移集群功能
在 SQL1 和 SQL2 上启用故障转移群集功能。
在 SQL1 和 SQL2 上运行此 PowerShell 命令
安装-WindowsFeature-名称故障转移群集-IncludeManagementTools
验证您的集群
从 SQL1 或 SQL2 运行此 PowerShell 命令
测试集群-节点 sql1,sql2
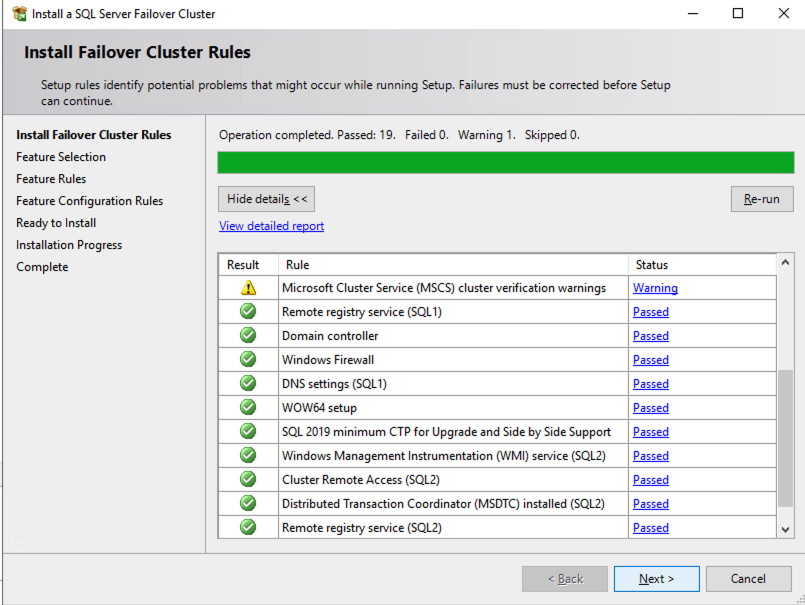
根据您使用的 Windows Server 版本,您将看到一些有关网络和可能存储的警告。网络警告可能会告诉您每个集群节点都可以通过单个接口访问。早期版本的 Windows 会警告您缺少共享存储。
您可以忽略这两个错误,因为它们在 OCI 托管的集群中是预期的。只要您没有收到错误,就可以继续下一部分。如果您收到任何错误,请修复它们,然后再次运行验证并继续下一部分。
创建集群
接下来,您将创建集群。在下面的示例中,您会注意到我使用了我们计划使用的两个 IP 地址:10.0.64.101 和 10.0.128.101。您可以从任一群集节点运行此 Powershell。
新建集群 -名称 cluster1 -节点 sql1,sql2 -静态地址 10.0.64.101, 10.0.128.101
请注意:
不要尝试通过 WSFC GUI 创建集群。您会发现,由于实例使用 DHCP,GUI 不会为您提供为集群分配 IP 地址的选项,而是会分发重复的 IP 地址。
添加文件共享见证
为了维持集群仲裁,您需要添加见证人。在 OCI 中,您要使用的见证类型是文件共享见证。文件共享见证必须驻留在与两个群集节点不同的故障域中的服务器上。
在下面的示例中,将在驻留在 FD1 中的 DC1 上创建文件共享见证。
在 DC1 上,创建文件共享并分配集群名称对象 (CNO) 对该文件夹的读写权限。在您创建的文件夹的“共享”和“安全”选项卡上添加 CNO 的权限,在下面的示例中,我创建了一个名为“见证”的文件夹。
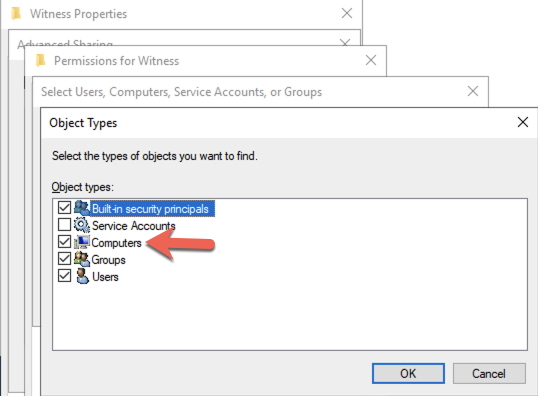
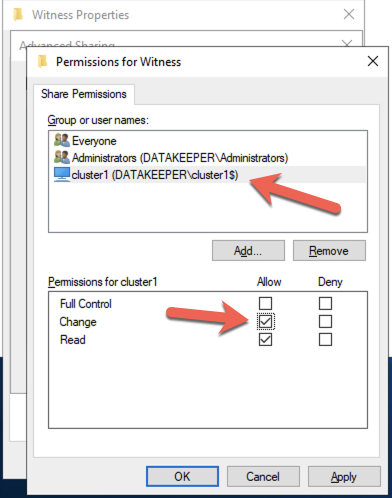
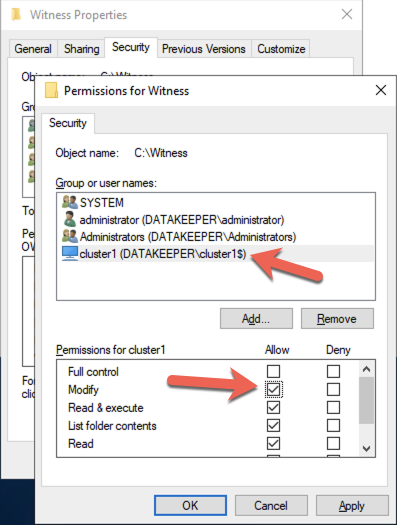
创建文件夹并向 CNO 分配适当的权限后,请在 SQL1 或 SQL2 上运行以下 PowerShell 命令。
设置 ClusterQuorum -Cluster cluster1 -FileShareWitness \\dc1\Witness
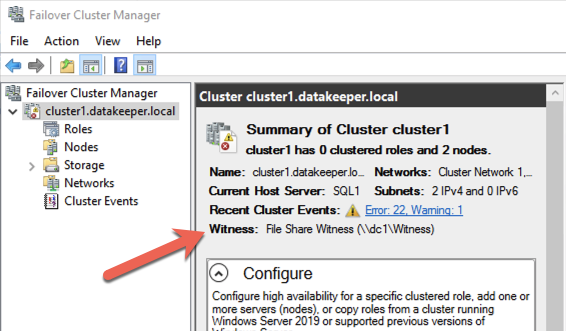
当您在 SQL1 或 SQL2 上启动故障转移群集管理器时,您的群集现在应如下所示。
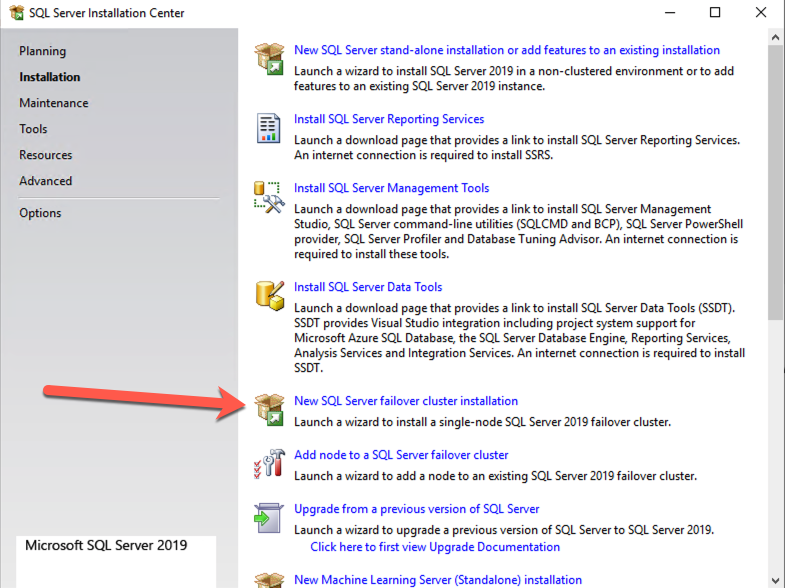
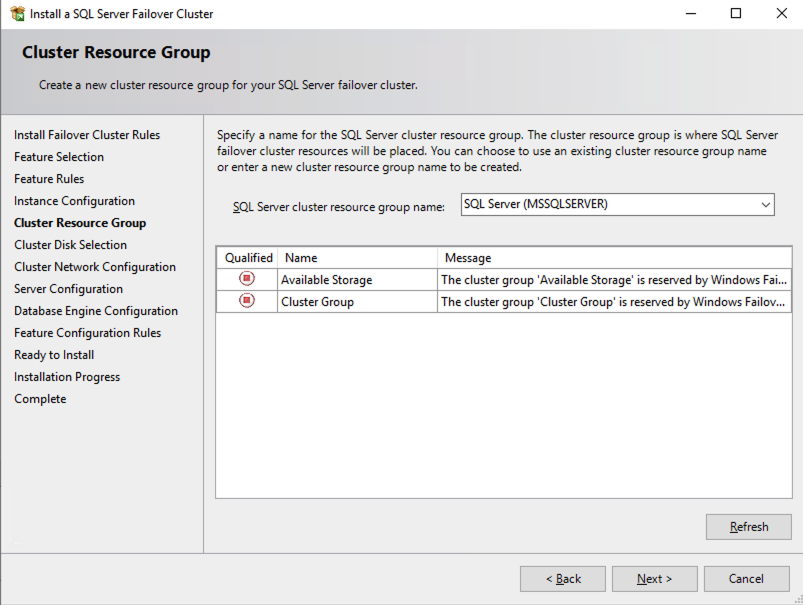
创建 SQL Server FCI
安装DataKeeper集群版
在继续执行后续步骤之前,您需要在 SQL1 和 SQL2 上安装 DataKeeper Cluster Edition。下载安装可执行文件并在两个节点上运行 DataKeeper 安装程序。请参阅SIOS文档有关安装的具体指导。
创建 DataKeeper 卷资源
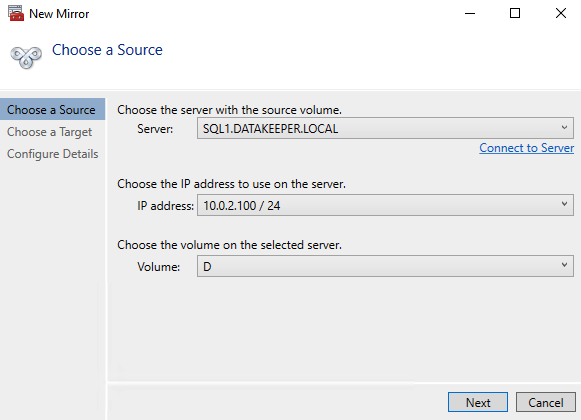
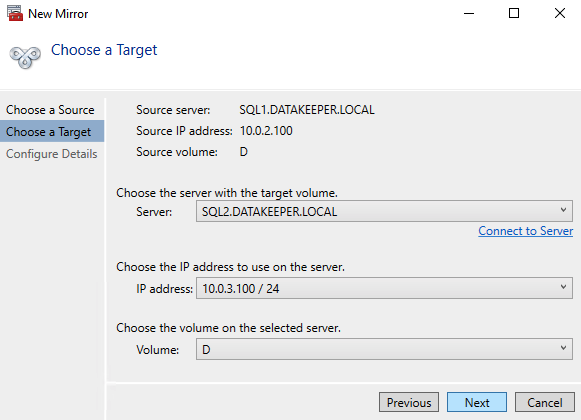
在任一集群节点上启动 DataKeeper UI 并创建 DataKeeper 卷资源,如下所示。
连接到两台服务器,首先是 SQL1,然后是 SQL2
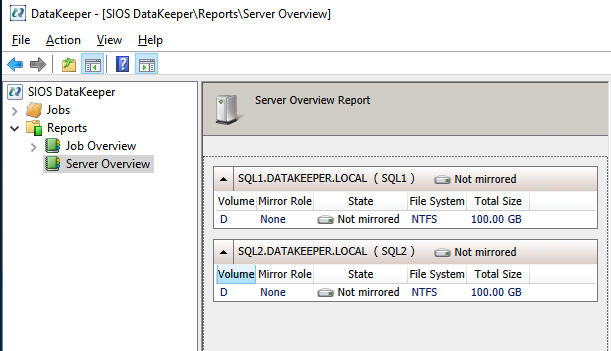
如果您已连接到两台服务器并且存储配置正确,则服务器概述报告应如下所示。
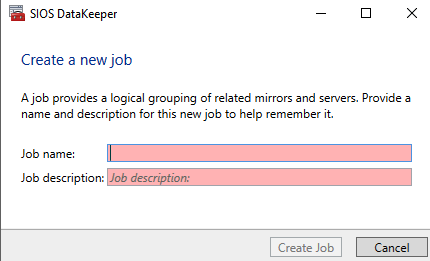
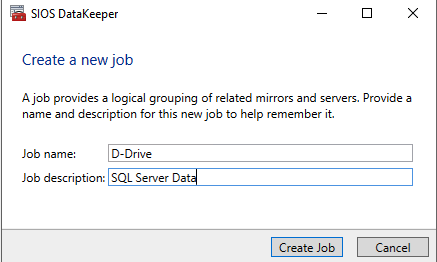
单击创建作业以启动作业创建向导
DataKeeper 支持同步和异步复制。对于同一区域内的可用区之间的复制,请选择同步。如果您想跨区域甚至跨云提供商复制,请选择异步
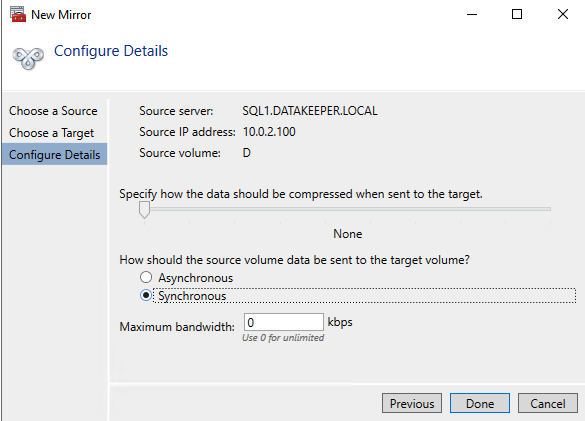
这里点击“是”,将DataKeeper Volume资源注册到集群的Available Storage中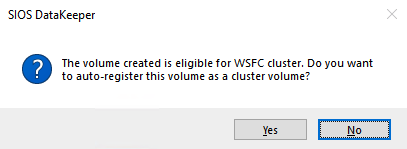
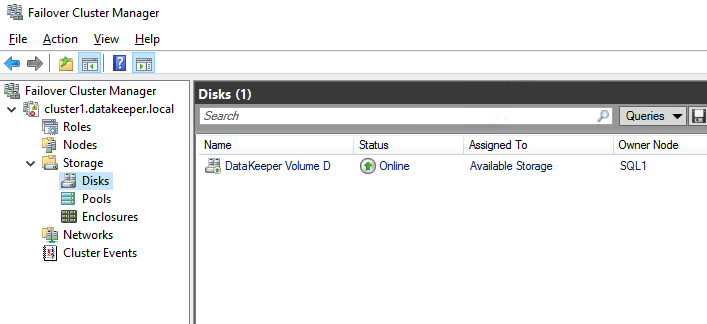
DataKeeper 卷 D 现在显示在故障转移群集管理器的可用存储中。
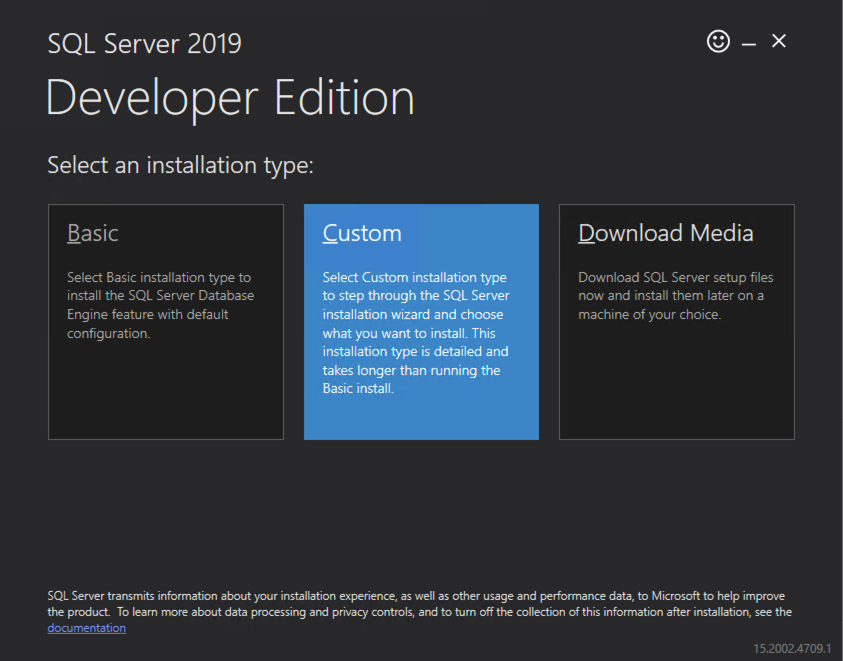
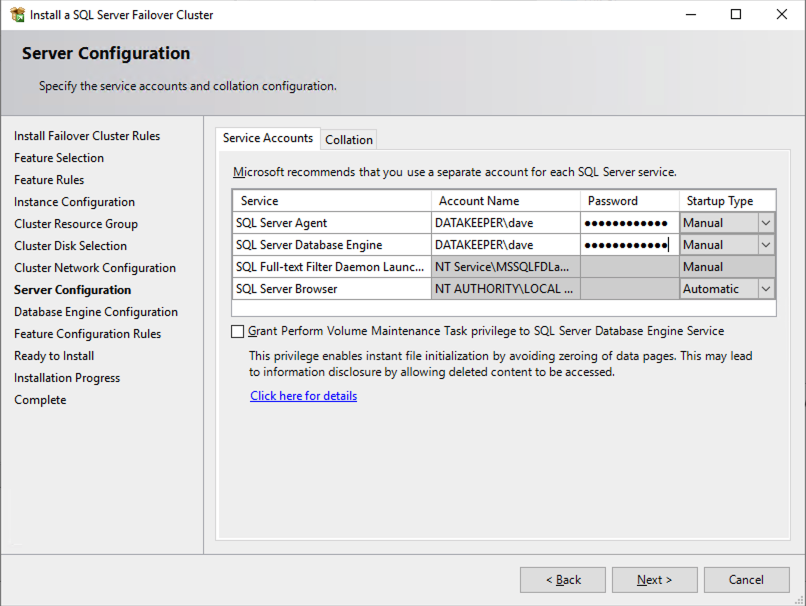
在 SQL1 上安装 SQL Server FCI 的第一个节点
现在核心集群已创建,并且 DataKeeper 卷资源位于可用存储中,是时候在第一个集群节点上安装 SQL Server 了。如前所述,此处的示例说明了使用 SQL 2019 和 Windows 2022 的群集配置,但无论您尝试部署哪个版本的 Windows Server 或 SQL Server,此示例中描述的所有步骤实际上都是相同的。
按照下面的示例在 SQL1 上安装 SQL Server
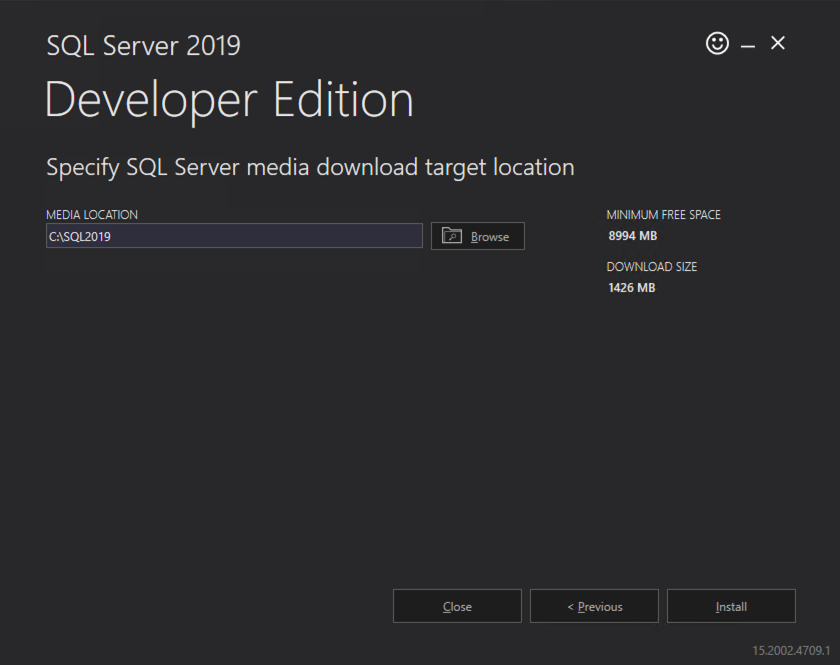
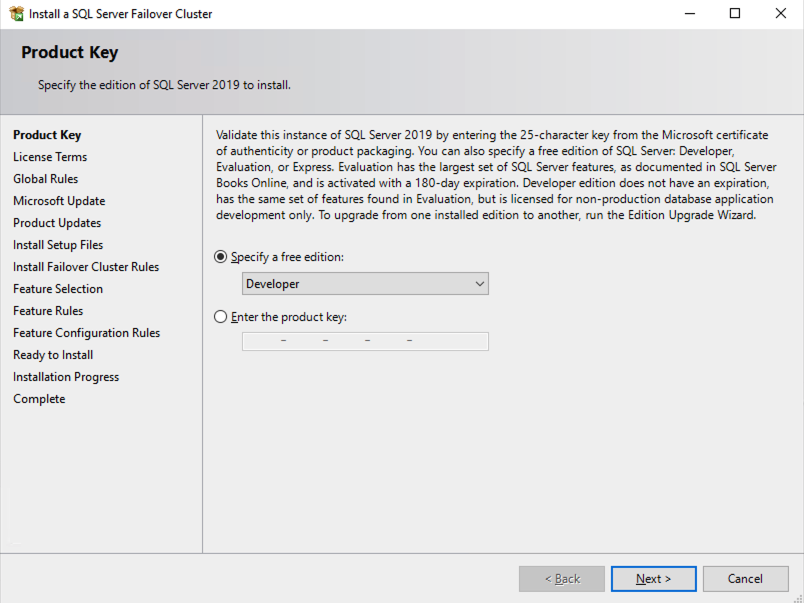
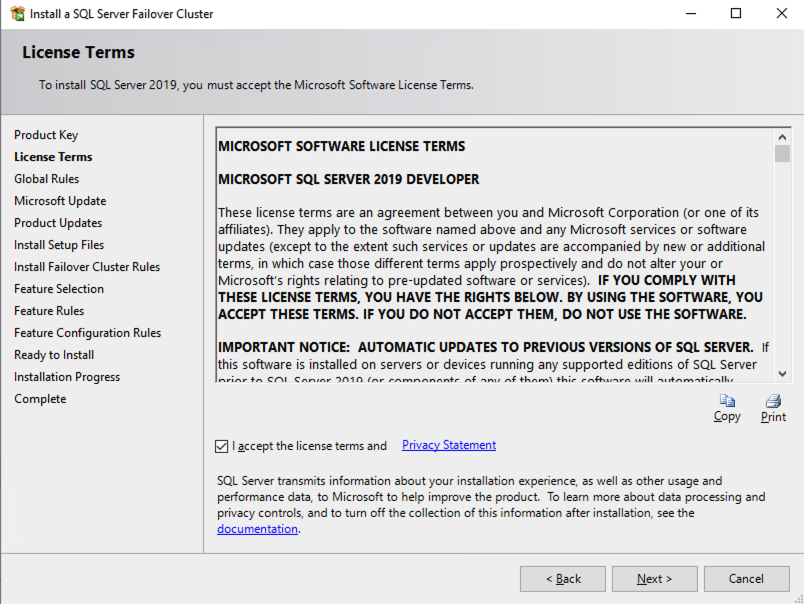
您在下面指定的名称是客户端访问点。这是应用程序服务器想要连接到 SQL Server FCI 时将使用的名称。
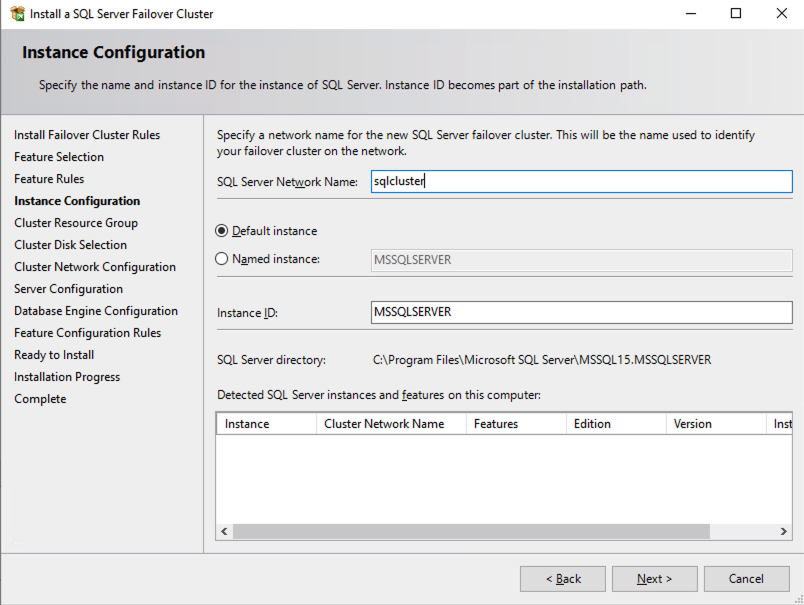
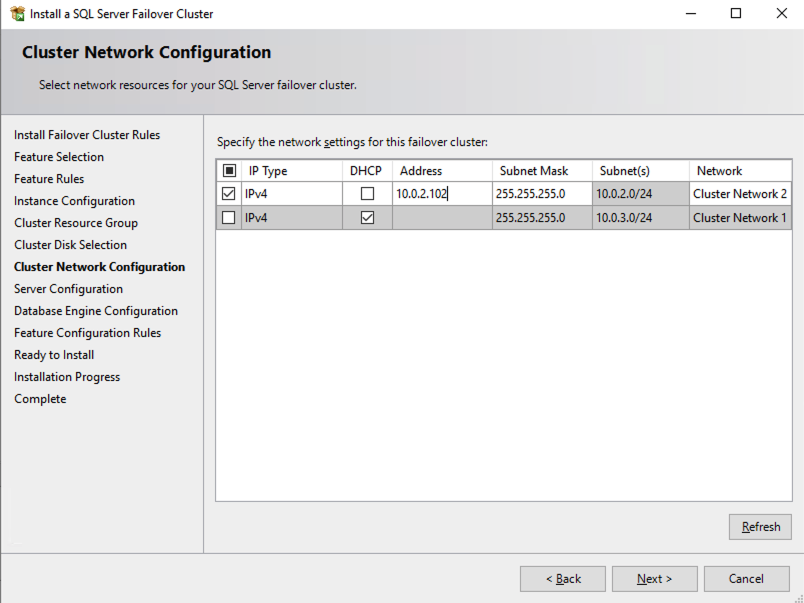
在此屏幕上,您将添加我们之前在规划部分中确定的 SQL1 辅助 IP 地址第1部分这个系列的。
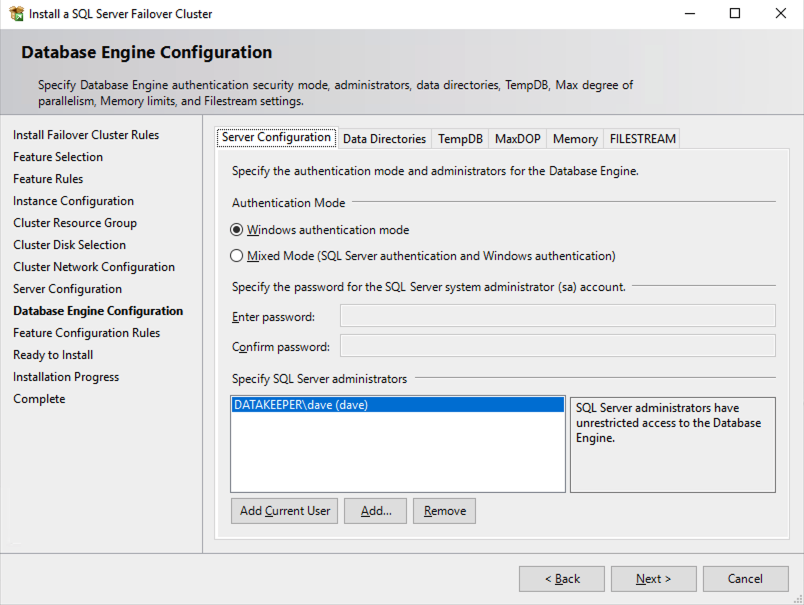
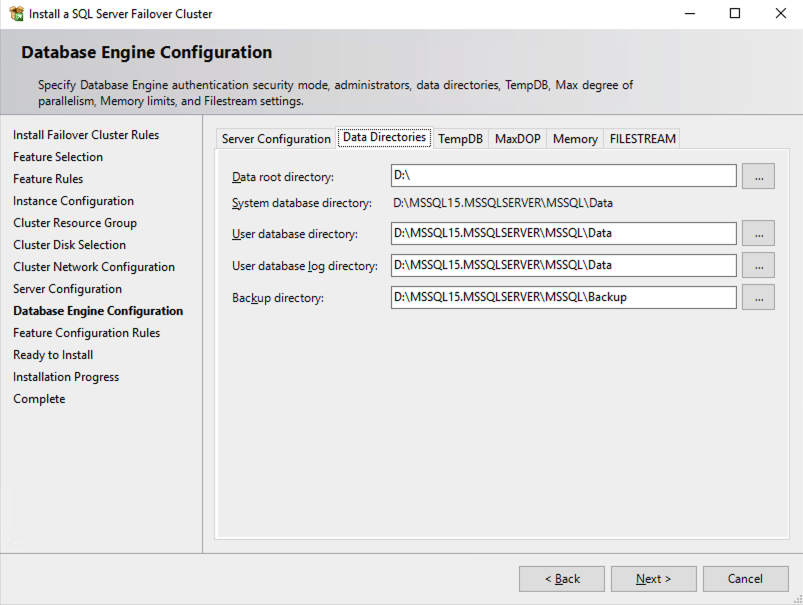
在此示例中,我们将 tempdb 保留在 D 驱动器上。但是,为了获得最佳性能,建议您将 tempdb 放置在非复制卷上。
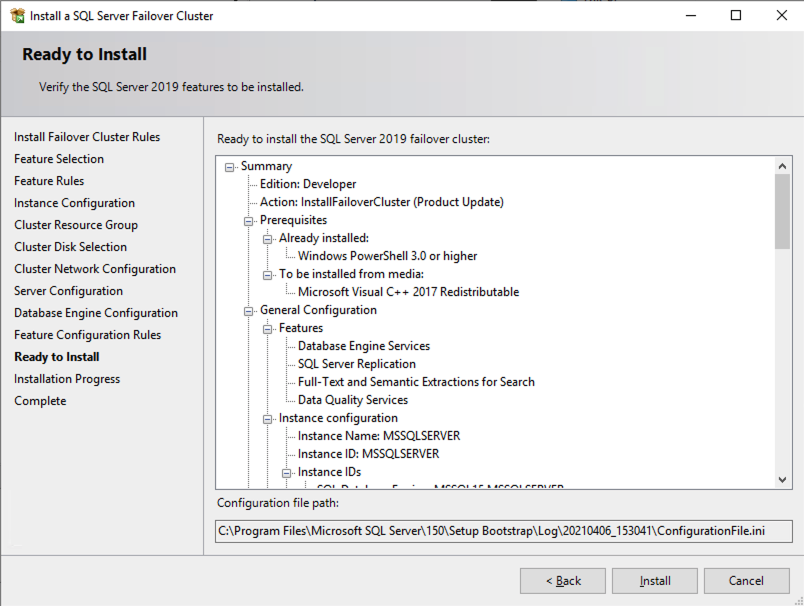
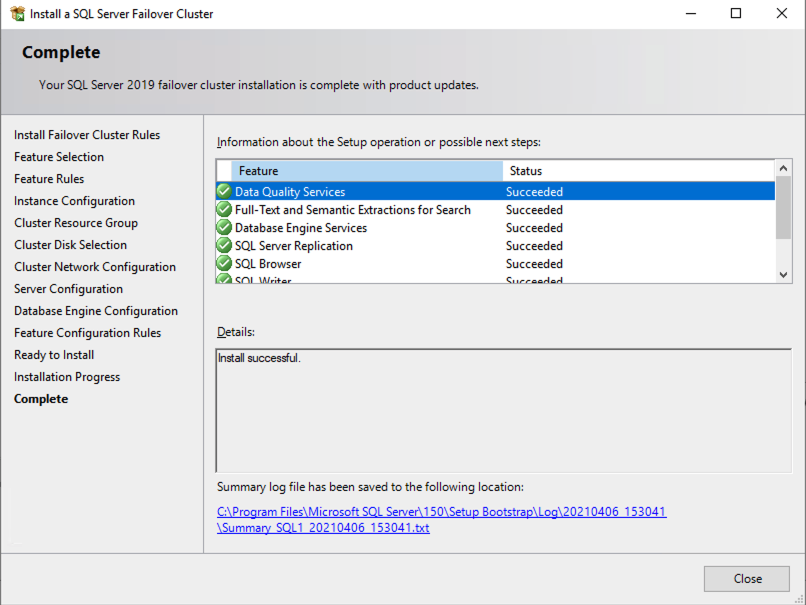
在 SQL2 上安装 SQL Server FCI 的第二个节点
现在是在 SQL2 上安装 SQL Server 的时候了。
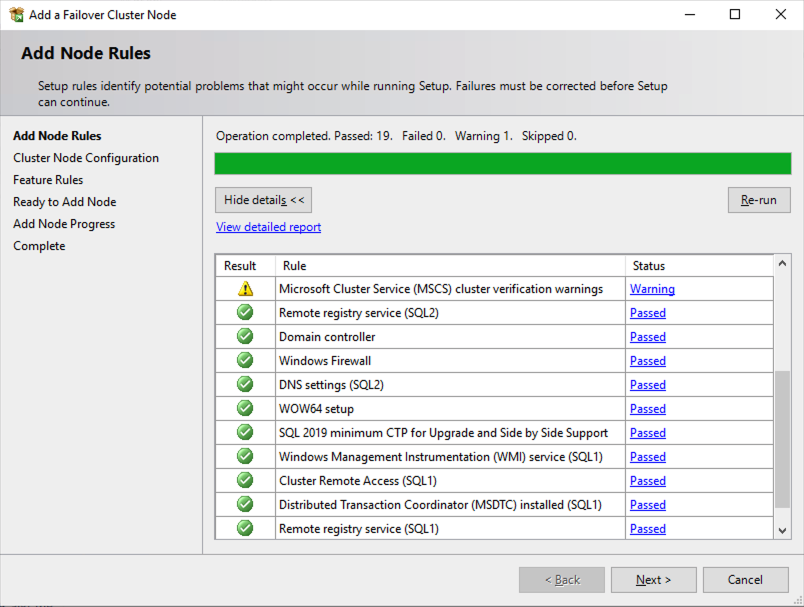
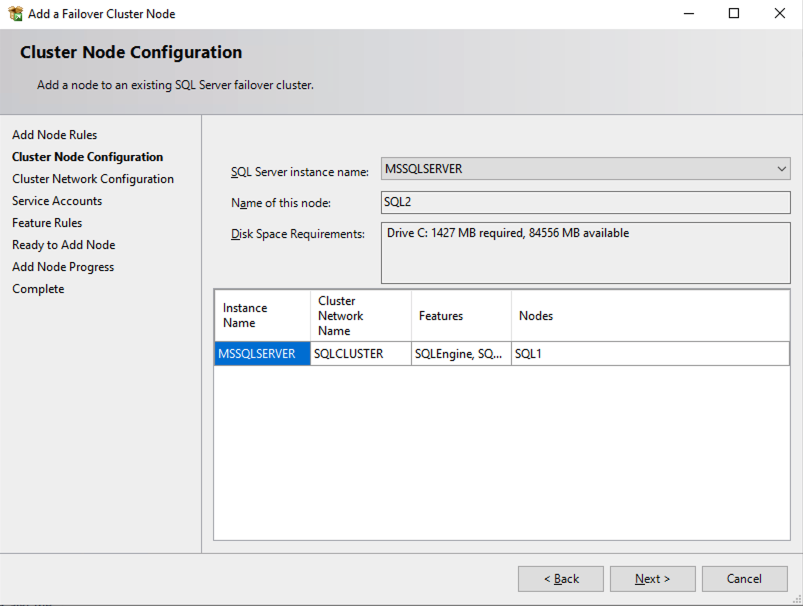
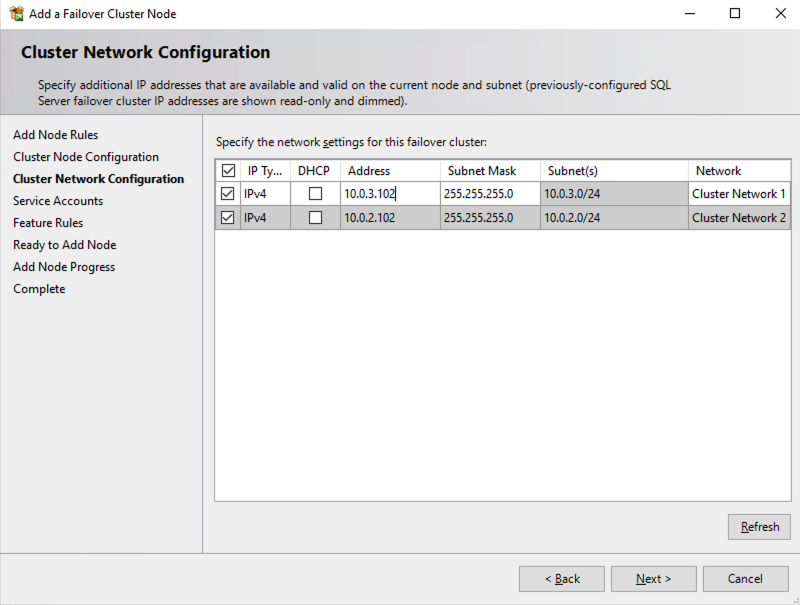
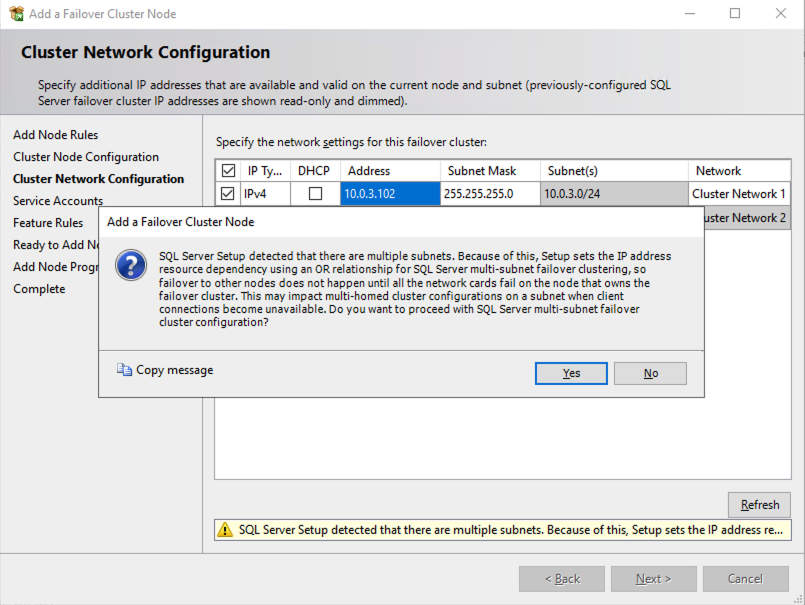
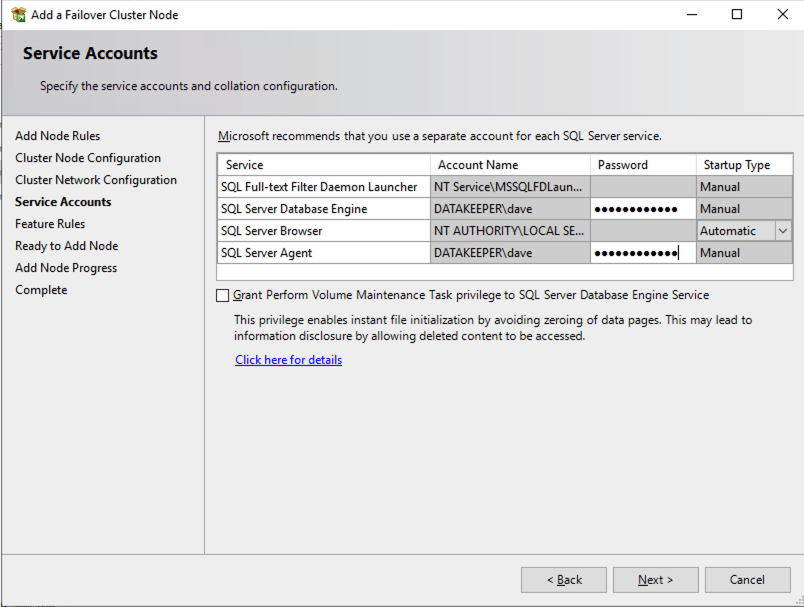
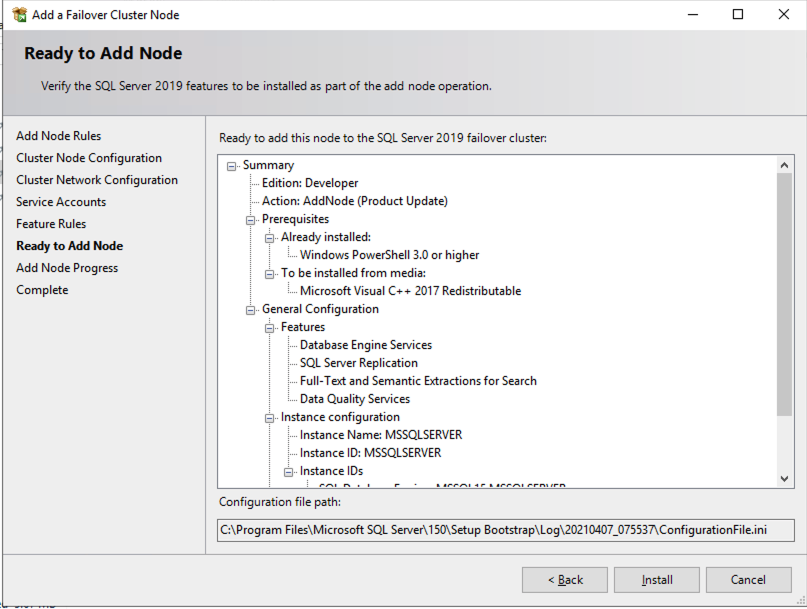
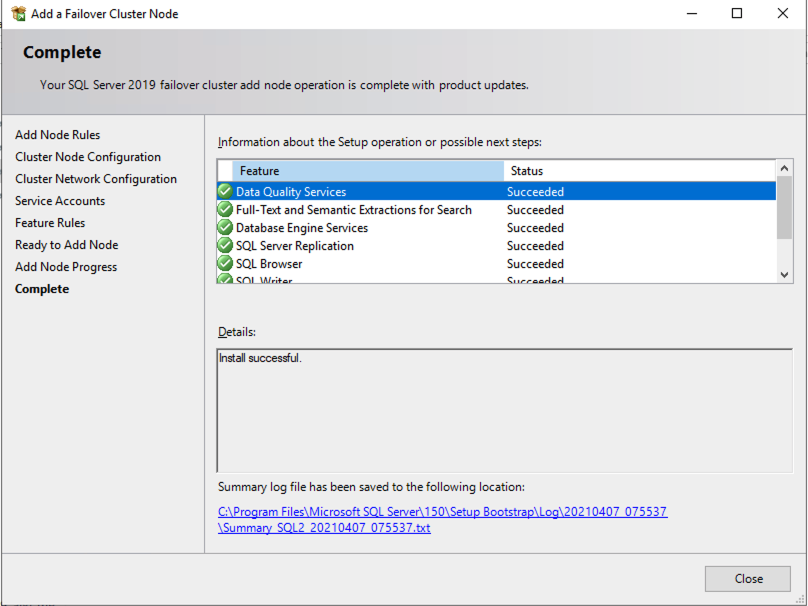
在两个群集节点上安装 SQL Server 后,故障转移群集管理器应如下所示。
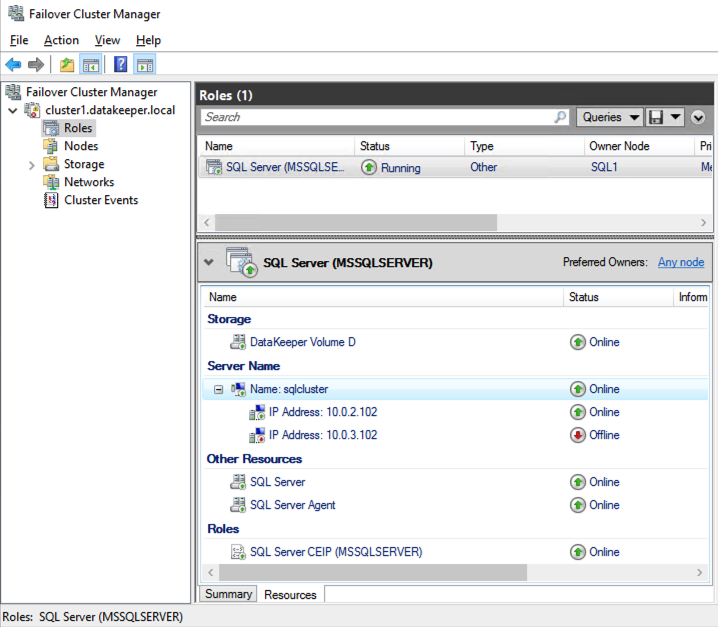
安装 SQL Server Management Studio
在 SQL Server 版本 2016 及更高版本上,您必须作为单独的选项下载并安装 SSMS,如下所示。注意:在 SQL Server 的早期版本中,SQL Server Management Studio (SSMS) 是您可以在 SQL 安装期间选择安装的一个选项。

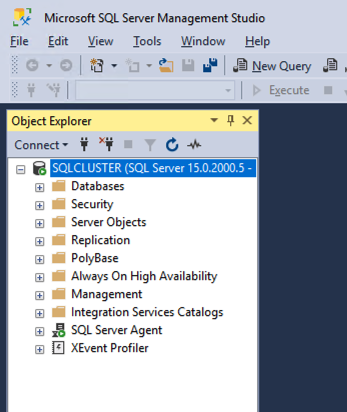
安装 SSMS 后,通过客户端访问点连接到集群。您的 SQL Server FCI 应该如下所示。
多子网注意事项
在 OCI 中运行 SQL Server FCI 的最大考虑因素之一是群集节点驻留在不同的子网中。 Microsoft 开始通过在 Windows Server 2008 R2 中添加“OR”功能来考虑群集节点可能驻留在不同子网中的事实,如 Microsoft文档。
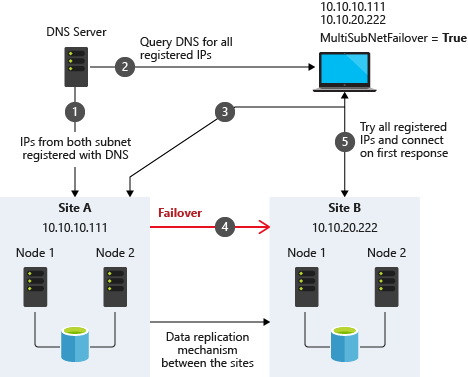
取自SQL Server 多子网集群 (SQL Server)
文档中描述的重要内容是网络名称资源上的 RegisterAllProvidersIP 概念,在创建 SQL Server FCI 时默认启用该概念。如上所述,启用此功能后,将在 DNS 中使用网络名称资源注册两条 A 记录,每个 IP 地址对应一条记录。
使用“OR”功能,只有与活动子网关联的 IP 地址才会在线,而另一个将显示为离线。如果您的客户端支持将 multisubnetfailover=true 添加到连接字符串,则将同时尝试两个 IP 地址,并且客户端将自动连接到活动节点。这是最简单的,也是多子网集群中客户端重定向的默认方法。
该文档接着说,如果您的客户端不支持 multisubnetfailover=true 功能,则您应该“尝试将每个附加 IP 地址的客户端连接字符串中的连接超时调整为 21 秒。这可确保客户端的重新连接尝试在能够循环访问多子网 FCI 中的所有 IP 地址之前不会超时。”
禁用 RegisterAllProvidersIP 是另一个可行的选项。通过禁用 RegisterAllProvidersIP,您在 DNS 中将只有一条 A 记录。每次集群故障转移时,DNS A 记录都会更新为与名称资源关联的活动集群 IP 地址。
此方案配置的缺点是您的客户端将缓存旧 IP 地址,直到生存时间 (TTL) 到期。为了最大限度地减少重新连接的延迟,建议您更改名称资源上的 TTL。描述了这个过程这里下面显示了将 TTL 设置为 5 分钟的示例。
获取 ClusterResource -名称 sqlcluster |设置 ClusterParameter -名称 HostRecordTTL -值 300
请记住,对 AD 集成 DNS 服务器的更改也可能需要一些时间才能传播到整个林。
概括
本技术指南全面概述了在 Oracle 云基础设施 (OCI) 中设置 SQL Server 2019 故障转移集群实例 (FCI)。首先强调了解 OCI 可用性 SLA 的重要性,该 SLA 根据部署策略而有所不同:跨可用性域部署为 99.99%,跨故障域部署为 99.95%,单个虚拟机部署为 99.9%。该指南强调,SLA 涵盖虚拟机可用性,而不是其上运行的应用程序或服务,因此需要采取额外的措施来确保应用程序可用性。
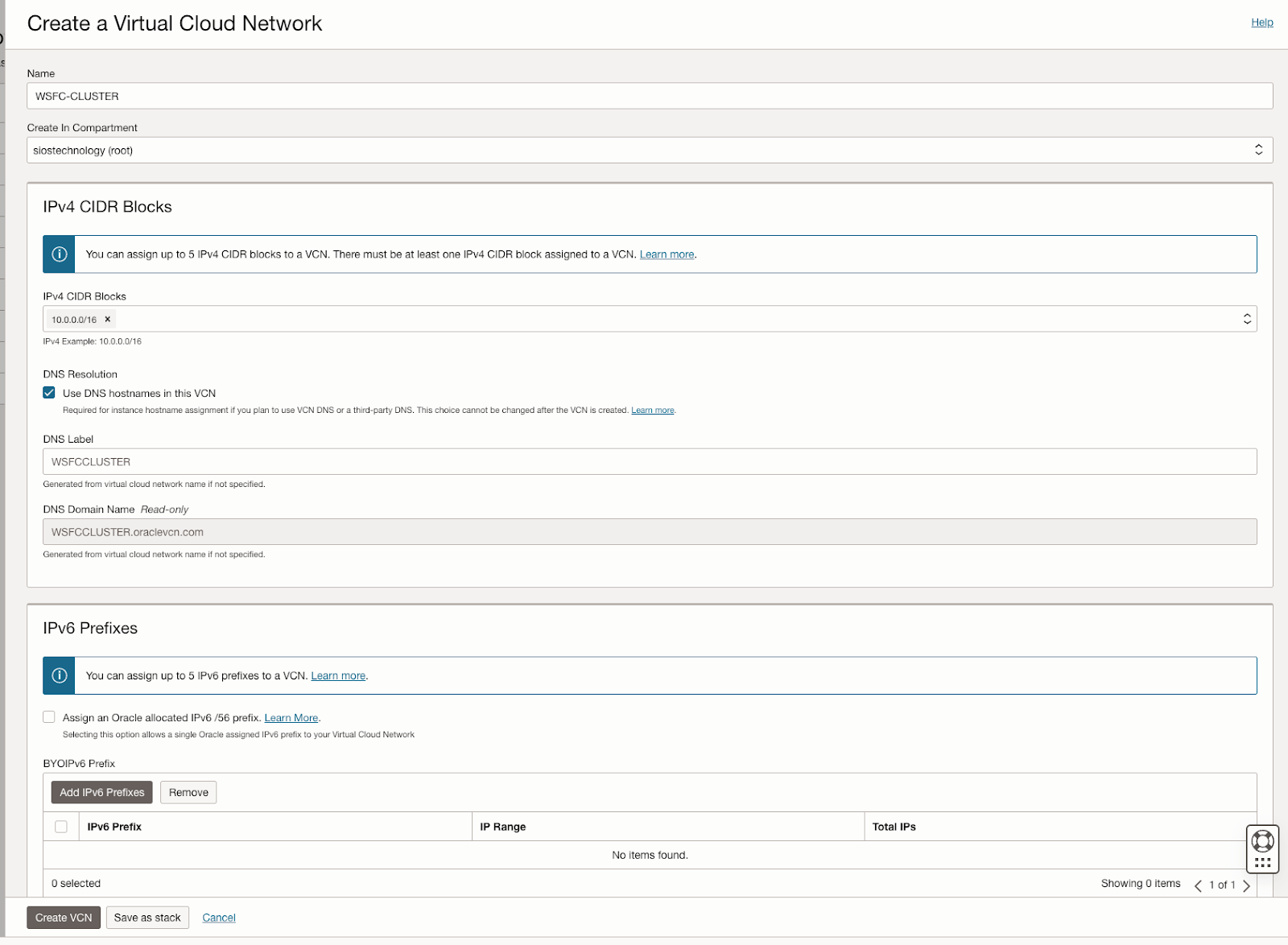
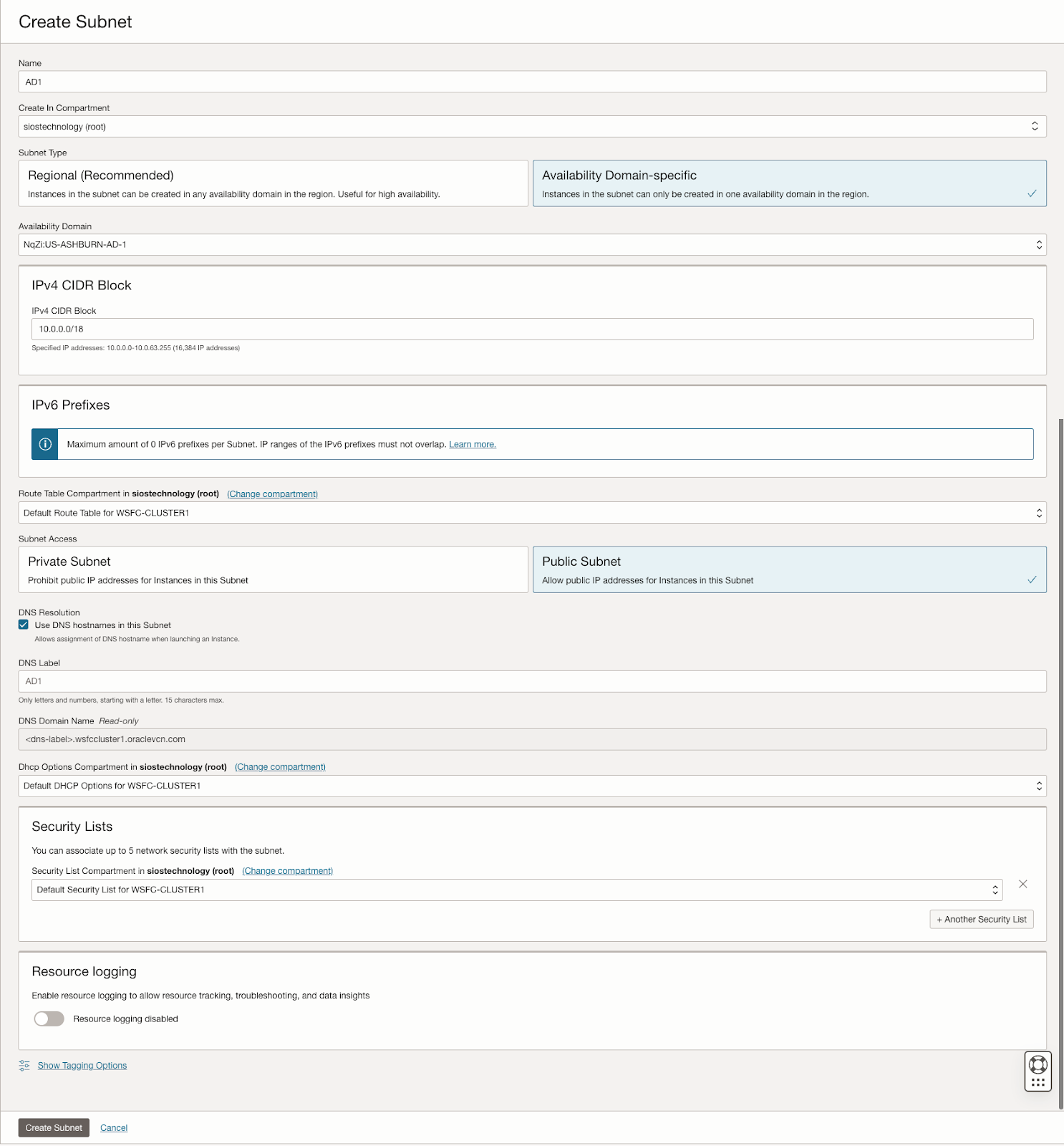
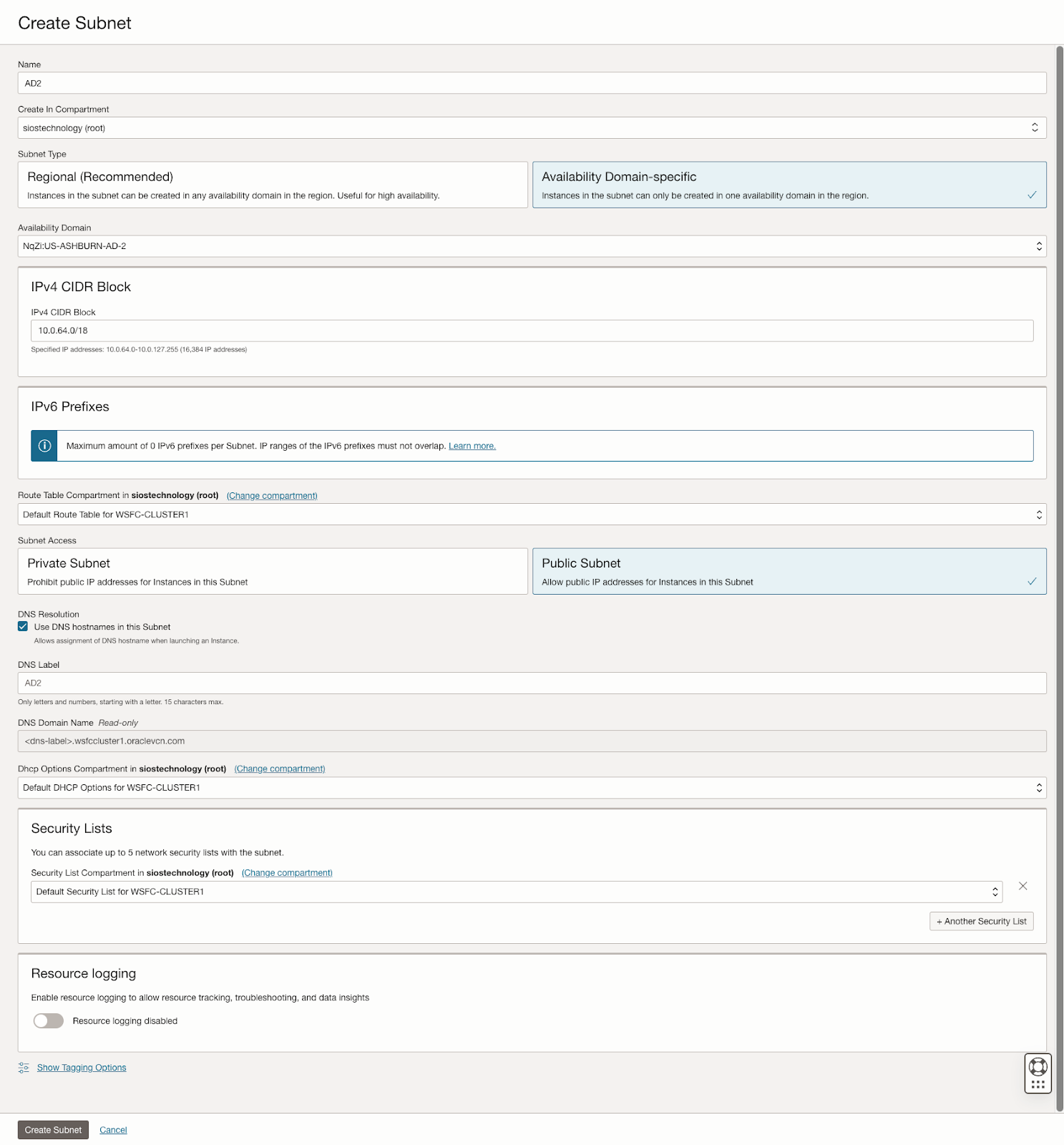
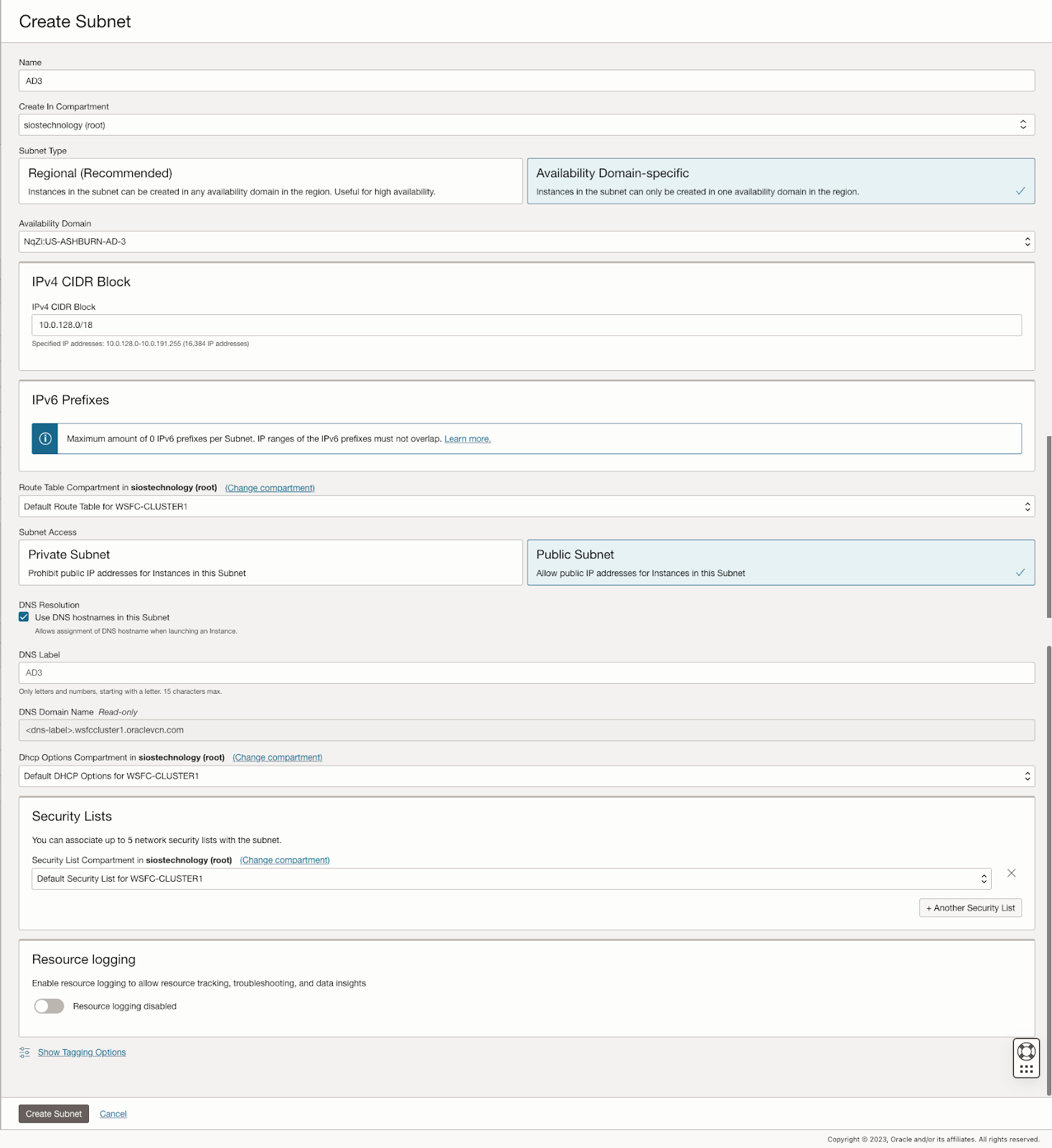
该指南详细介绍了在 OCI 中创建虚拟云网络 (VCN) 和子网的初始步骤,强调需要一个能够容纳至少三个可用性域以实现集群目的的网络规划。每个可用性域必须位于不同的子网中,这一要求也适用于跨故障域的集群。它提供了用于在单个 VCN 内跨不同可用性域设置三个子网的特定配置。
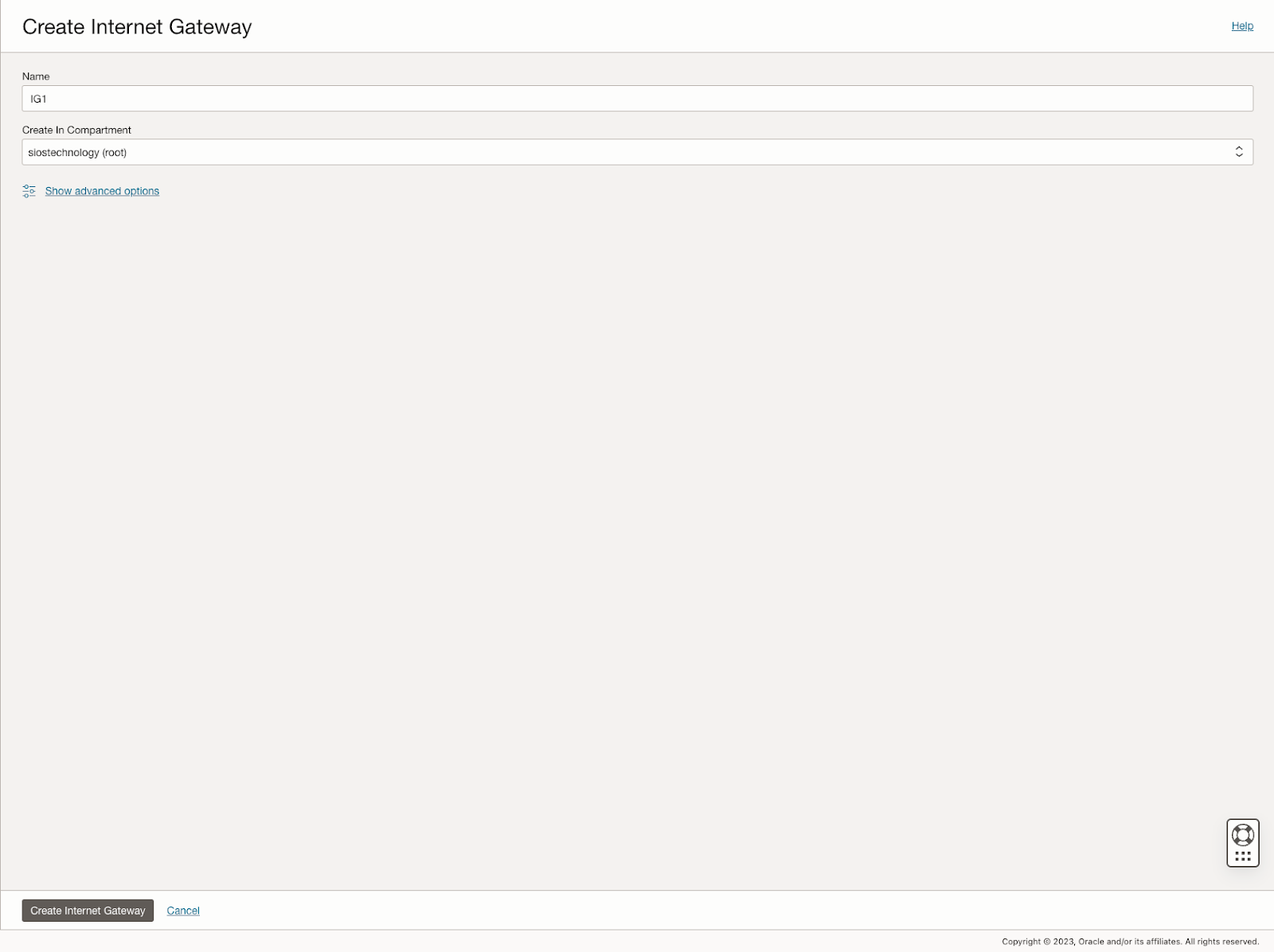
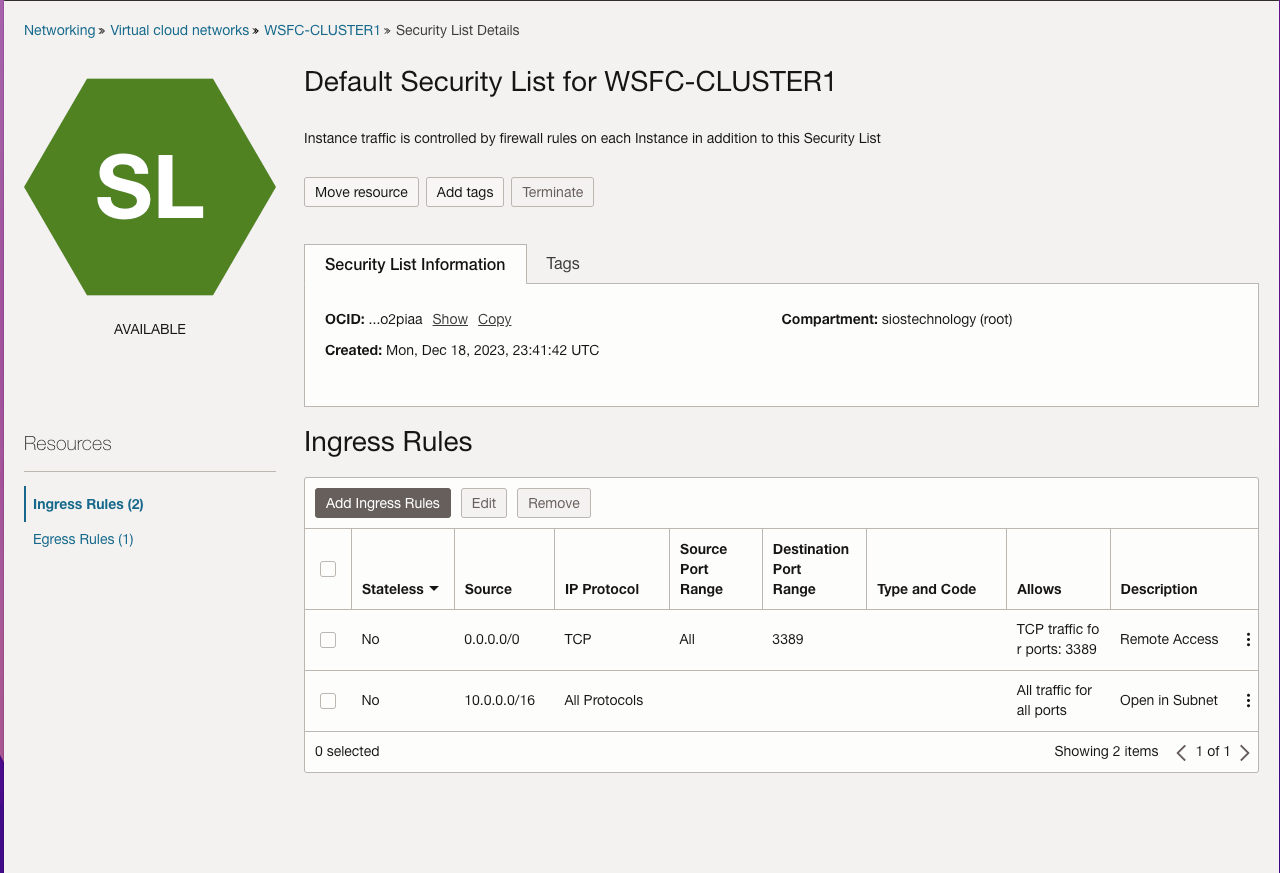
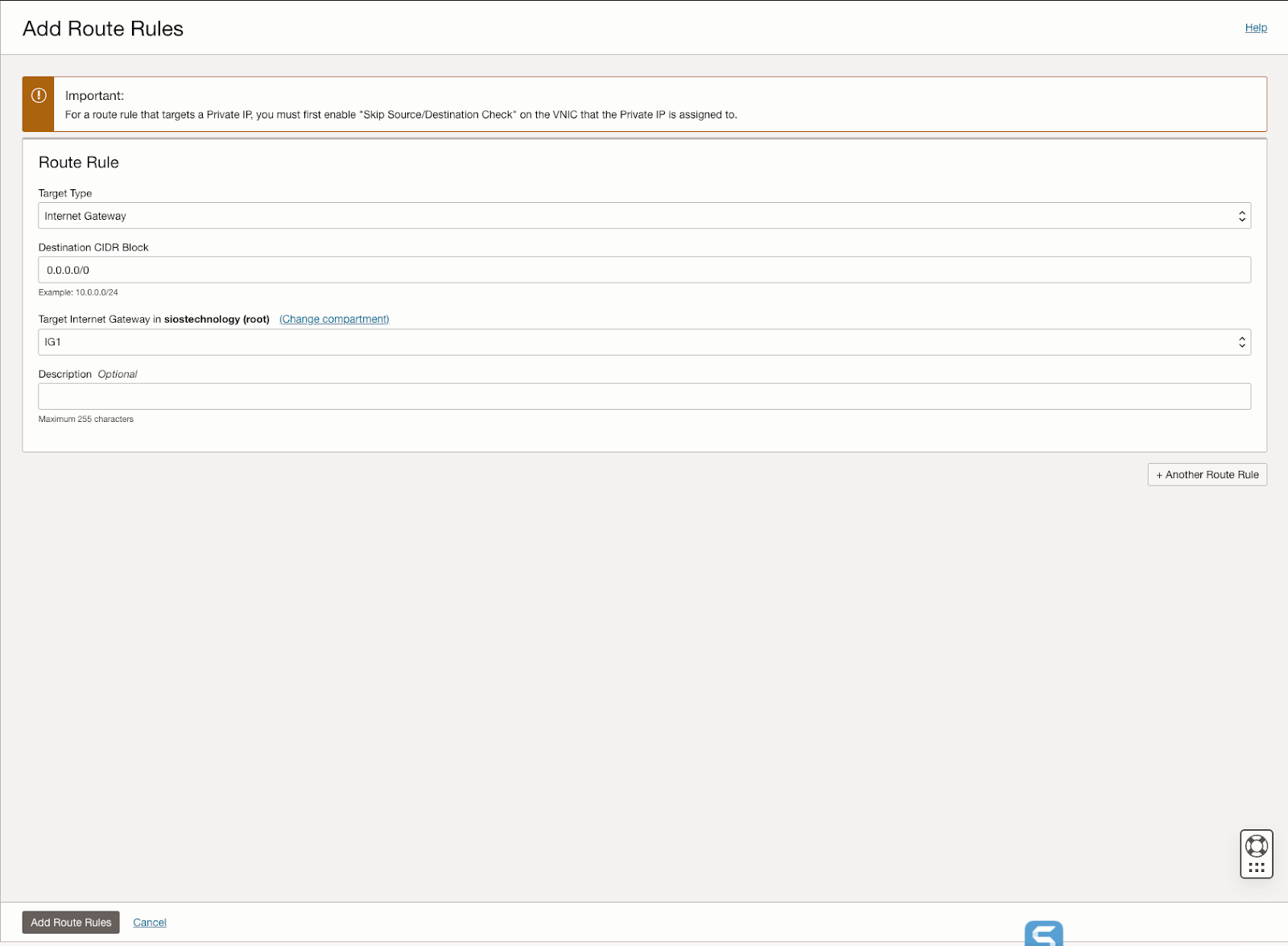
此外,该指南还描述了创建互联网网关以及编辑默认安全列表和路由表以促进跨可用性域的访问和安全的过程。它还介绍了用于 Active Directory 兼容性的 DHCP 选项配置,并概述了使用 Windows Server 2022 和 SQL Server 2019 配置虚拟机的步骤,强调了规划服务器名称、IP 地址和可用区放置的重要性。
然后,该指南深入研究了添加额外卷以满足 SQL Server FCI 存储需求,详细介绍了创建块卷并将其附加到实例的过程。它还指导如何在 OCI 中配置 Windows Server 故障转移群集的辅助 IP 地址。
接下来,本指南介绍了域控制器设置,包括启用 Active Directory 域服务以及将服务器升级为域控制器。它逐步介绍了在 SQL1 和 SQL2 上准备存储和启用故障转移群集功能,以及群集验证和创建过程。
该指南进一步讨论了添加文件共享见证以维护集群仲裁以及安装 DataKeeper Cluster Edition 以进行卷复制。它提供了在群集节点和 SQL Server Management Studio 上安装 SQL Server 的分步方法,以及多子网部署的注意事项。
总之,本指南提供了在 OCI 中部署和配置 SQL Server 2019 FCI 的详细蓝图,涵盖从网络设置和 VM 配置到集群、存储配置和域控制设置等各个方面,确保关键业务应用程序的正常运行时间和可靠性最大化。
经许可转载安全操作系统
选择正确的高可用性解决方案的四个技巧

选择正确的高可用性解决方案的四个技巧
高可用性和勒布朗是有史以来最伟大的 (GOAT) 争论
我在黑桃牌上输了。我在卡胡特输了。我在一场篮球比赛中输给了同一个友好的竞争对手布兰登。因此,为了分散他的注意力,我又开始辩论——“勒布朗是有史以来最伟大的!”接下来的紧张气氛充满了来回的咆哮,其中夹杂着一些篮球巨星的名字:迈克尔·乔丹、朱利叶斯·欧文、威尔特·张伯伦、鲍勃·库西、沙克、比尔·拉塞尔、杰里·韦斯特、斯蒂芬·库里、凯文·杜兰特、科比·布莱恩特、魔术师和值得,以及勒布朗。他争辩说:“你怎么能说勒布朗是最伟大的,科比有杀手本能!”我们的口头争论将扩大到有什么要求,是什么让某人成为伟大对话的一部分,甚至是讨论的一部分的候选人。他们是否需要长寿、得分记录、防守能力、其他荣誉和荣誉?他们至少应该获得多少个最有价值球员奖?他们时代的超越又如何呢?怎么样这个或那个,当然,我的朋友布兰登总是很快就添加标题!
如何选择最佳的高可用性解决方案
但是,这有什么关系高可用性?很高兴你问了。您多久被要求从众多竞争者中提供或选择最佳可用性或更高可用性的解决方案?您已经确定,因意外应用程序崩溃或生产服务器停机而毁掉的最后一个周末,也是因缺乏自动监控和恢复而毁掉的最后一个周末。但是,在 Microsoft 故障转移集群、SuSE High Availability Extensions、PaceMaker、NEC ClusterPro、vWare HA、SIOS Protection Suite 和 SIOS AppKeeper 等众多知名解决方案中,哪种解决方案最好?我在与史上最伟大的比赛中学到的四件事将帮助您解决高可用性的困境。
医管局的要求
首先,有什么要求?如果我想要有史以来最好的纯射手,我会很容易地把斯蒂芬·库里包括在内。如果我想要最令人生畏的身体存在,我会和沙克这样的人一起去。如果我需要最好的队友、助攻王或者全能的优秀球员,那么我认为勒布朗·詹姆斯、魔术师约翰逊、杰里·韦斯特、拉里·伯德都在讨论之中。同样,在开始构建 HA 解决方案之前,请先了解您的需求。是数据复制必需的还是可选的?你需要SQL或者您同样倾向于使用其他数据库?还需要哪些其他应用程序和软件包?您是否需要一个可以引导您进入云的解决方案,但首先它必须驯服遗留系统、vmWare 和物理系统?您是一家全 Windows 应用程序商店,还是两者的混合体?也试着想想你的团队。您的人员流动率是否很高,导致管理多个解决方案变得困难,培训课程是否必不可少,以及现实生活中的人们在支持批判的?您需要易用性还是只注重坚固性?产品、产品和公司的寿命和稳定性在哪里?
其次,你如何确定你的需求的优先级?您将如何根据既定要求优先考虑优秀者?我的朋友布兰登总是很快就给出标题。他总是反驳,勒布朗有多少个冠军?在他的辩论中,头衔才是王道。我通常会讽刺地反驳说,即使是替补席上的第 12 个人也能获得戒指。我要强调的是,罗伯特·霍里是一位出色的大前锋,他拥有的头衔比勒布朗和乔丹还要多。就需求的优先级进行坦率和诚实的对话。当您选择 HA 解决方案时,与 RTO/RPO 相比,易用性、操作系统支持和应用程序支持范围有多重要?哪些功能和要求被认为是必须具备的、应该具备的以及最好拥有的。作为客户体验副总裁,我们曾经遇到过一位客户,他坚持集群软件支持32个节点,尽管他们并没有计划构建超过2个或3个节点的集群。确定列表的优先顺序。
测量灾难恢复的 RPO 和 RTO
第三,您如何衡量这些要求?您将如何根据既定要求来衡量伟大人物?篮球统计数据很有趣、信息丰富,但常常具有误导性。布兰登经常提醒我检查得分冠军是如何赢得的,就像我教赢得了多少个冠军一样。我们经常对谁能更好地开始或结束比赛以及如何真正衡量动力、强度和获胜意愿进行讽刺。同样,当您梳理文献时,请仔细研究概念验证细节,确定并定义如何衡量 RPO 和 RTO 等内容。 RTO 是基于客户端重新连接时间还是应用程序重新启动时间?您是否正在测量 RTO故障转移(服务器崩溃)恢复(应用程序崩溃)、手动切换(管理操作),或以上全部?如果应用程序性能对您很重要,那么该衡量标准是什么样的?是读取性能、写入性能还是基于客户端的实际或特征工作负载?想想基准适合什么地方,或者适合吗?另外,请诚实地说明您将数字与什么进行比较。在正常操作和恢复期间测量更快的数据库查询时间很重要,但如果解决方案的其余部分产生了用户体验更高的滞后怎么办?
评估高可用性和灾难恢复
最后,继续评价。从朱利叶斯在底线摇晃婴儿入睡,到乔丹从罚球线起跳,再到斯蒂芬·库里在半场线内迈出一步,篮球比赛一直在演变。 “乔丹规则”和“坏小子时代”的狂妄已经被一套有利于并强调技巧、力量和技巧结合的规则所取代。同样,技术格局也在不断变化。当 Solaris 和 MP-RAS 服务器占据主导地位时,进入前十名的解决方案可能无法适应 Linux、Windows 或其他变体的灵活性。利用光纤通道功能的基于 SAN 的解决方案可能已过时云端和无SAN世界。所以,不断评估伟大。持续关注前十名的解决方案如何顺应趋势,或者更好的是,仍然在制造它们。
虽然我与 Brandon 的争论仍在继续,而且很可能在几代人之后,甚至我们的孩子也不会选出赢家,但您可以选择正确的 HA 解决方案来满足您的企业可用性需求。联系 SIOS 代表帮助您了解、确定优先顺序并衡量 SIOS 保护套件超出您要求的能力。
经许可转载安全操作系统
灾难恢复解决方案:如何处理“建议”与“要求”

灾难恢复解决方案:如何处理“建议”与“要求”
假设您遇到问题云集群环境,并且您必须联系您的应用程序供应商之一才能解决该问题。他们为您提供了解决方案,但他们在回复中指出,“不建议”配置这些系统的方式。您如何处理这些信息?毕竟,到目前为止,一切都运行良好,并且可能需要大量时间和资源才能以“推荐”方式重新配置它们。另一方面,供应商推荐它肯定是有原因的,对吧?如果它会导致其他并发症怎么办?让我们看一下建议的具体构成,以及从接受的任何一方处理建议的方法。
容灾方案推荐配置
您应该开始考虑如何处理建议,从字面上理解它,定义为“关于最佳行动方案的建议或提议”。我们已经可以在这里看到一些提示,说明我们如何使用“建议”和“提案”一词来识别它们。从这个角度来看,很容易拒绝供应商的推荐,因为它不方便,或者可能被认为是不必要的。
然而,在对建议采取任何行动之前,请确保更务实地审视它。毕竟,供应商建议这种特殊的配置是有原因的。他们对你的成功就像你对持续关系的一部分一样感兴趣,所以它肯定会带来某种积极的好处。如果没有推荐的配置,您可能更容易出现某些类型的错误。这也可能是性能下降的情况,一切正常,但可能会工作得更好或更快。考虑到这一点,现在投入时间和精力来满足这些建议,而不是在您受到不遵循建议的缺点的影响后才开始这样做,不是更好吗?
如何处理建议之外的灾难恢复解决方案配置
现在,我们可以通过汇集讨论的两端来构建我们对建议的全面看法。总结的版本是:“不遵循供应商的建议也没关系,只要您知道为什么建议这样做并接受这样做的潜在缺点”。关键的第一步始终是与供应商交谈。向他们询问为什么推荐它、拥有它与不拥有它的影响、他们是否有任何方法或程序可以轻松过渡到推荐的环境,以及您能想到的任何其他可以帮助您更好地了解自己和内部团队的信息。一旦您了解了影响,如果您有适当的理由,您就可以拒绝它。拒绝建议的一个很好的理由是出于安全目的。也许推荐的环境会关闭或规避您已采取的某些安全措施,因此使用该环境不仅会让您更容易受到攻击,而且还可能导致违反SLA、合作伙伴协议或您必须遵守的标准。在这种情况下,您可以告知供应商您不遵循推荐配置的原因。这对供应商也非常有利,因为他们可以接受此反馈,并在未来实施改进,从而同时实现推荐的配置和安全措施。如前所述,他们也为您的成功进行了投资,因此这对每个人来说都是双赢。
灾难恢复解决方案要求
但有时,对供应商告诉您的内容说“不”并不那么容易。这就是从供应商“建议”到供应商“要求”的跨越边界,这是不可避免的。当它作为一项要求呈现给您时,您就无法拒绝遵循它。尽管如此,与建议一样,重要的是要了解为什么它是一项要求,以及它实际上是什么要求。作为您与供应商商定的 SLA 或产品、应用程序或服务的 TSA 的一部分,可能需要某些实践。在这些情况下,确实必须做出满足此要求所需的更改。需求通常也属于技术方面。例如,磁盘大小、I/O 容量或可用计算机资源的规范,仅举几例。这些往往是应用程序按预期工作所必需的,因此确保满足这些要求的价值是显而易见的。
灾难恢复解决方案的灵活性
仅仅因为您必须遵守要求并不意味着您必须简单地辞职。理解为什么要制定这一要求仍然具有很大的价值。与推荐一样,与您的供应商交谈至关重要。也许您不喜欢该要求的原因源于误解,与您的供应商讨论原因可以揭示这一点并消除一些担忧。同样,您对这些要求的反馈对于您的供应商改进产品或服务非常重要,并帮助他们了解您所看到的以不同方式做某事的价值。所需要的只是启动一个对话框。
SIOS 高可用性和灾难恢复
SIOS科技公司提供高可用性和灾难恢复通过针对最重要应用程序的集群管理来保护和优化 IT 基础设施的产品。今天联系我们有关我们的服务和专业支持的更多信息。
经许可转载安全操作系统
在 Linux 上使用 SIOS LifeKeeper 设置 NFS 文件见证的分步指南

在 Linux 上使用 SIOS LifeKeeper 设置 NFS 文件见证的分步指南
SIOS Lifekeeper 和基于 NFS 的文件见证入门
在高可用集群,见证人对于保证集群的完整性和可靠性起着至关重要的作用。没有第三个节点,可能很难达到法定人数,因为没有数据可以帮助打破两个节点都认为应该上线的平局(这称为裂脑)。您可以通过多种方式解决此问题,例如,通过提供专用见证服务器、整个集群可见的共享存储路径,或者简单地通过在集群本身中拥有更多节点(至少 3 个!)。值得庆幸的是,SIOS 生命守护者为在 Linux 环境中设置高可用性集群提供了强大的解决方案,并且配置见证以提高仲裁是一项重要功能。
在本指南中,我们将引导您完成在 Linux 上使用 SIOS LifeKeeper 设置基于 NFS 的文件见证的步骤,帮助您增强集群应用程序的可用性和弹性。
目标:
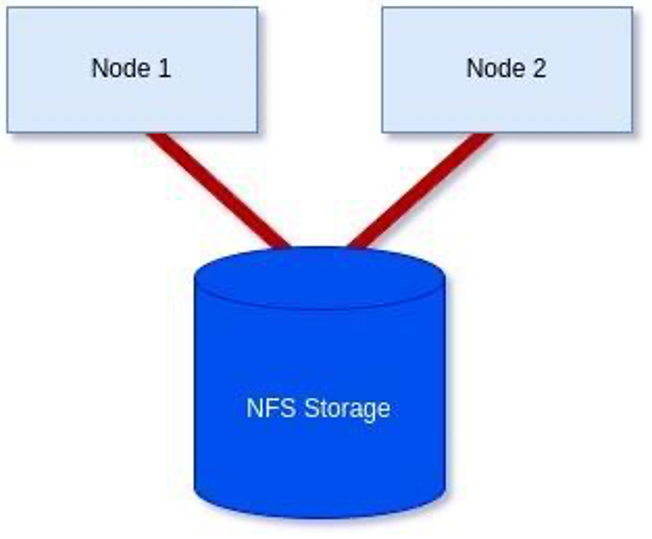
使用基于 NFS 的存储见证实现 2 节点集群,如下图所示:
先决条件:开始之前,请确保您具备以下条件:
- Linux 服务器是使用管理权限(即根访问权限)进行配置和连接的。
- SIOS LifeKeeper 已安装或下载并准备安装在每台服务器上。
- NFS 共享可供集群中的所有服务器访问。
步骤 1:安装/修改 SIOS LifeKeeper:
我们需要在此阶段安装 LifeKeeper 或重新运行安装程序以添加 Witness 功能,除非您之前已包含它。
就我而言,我使用的是 RHEL8.8,因此我将在使用 RHEL8.8 所需的补充包运行安装之前安装 ISO。
[root@server1-LK ~]# mount /root/sps.img /mnt/loop -t iso9660 -o 循环
[root@server1-LK ~]# cd /mnt/loop/
[root@server1-LK 循环]# ./setup –addHADR /root/HADR-RHAS-4.18.0-477.10.1.el8_8.x86_64.rpm
这里,我们目的的重要部分是启用见证功能,如下面的屏幕截图所示。但是,您还需要一个额外的许可证文件,您可以在此处添加该文件,也可以稍后通过命令行添加:
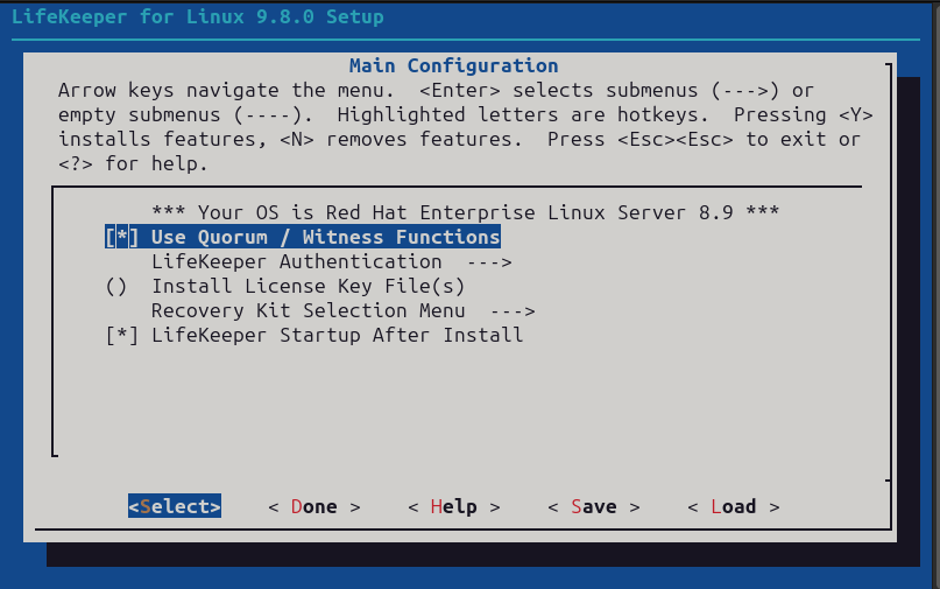
否则,根据您的目的配置 LifeKeeper,或者如果已经配置,只需在包含“使用仲裁/见证功能”选项后继续完成设置即可。
如果您决定通过命令行添加许可证,请在集群中的每个节点上运行以下命令,并使用许可证文件的正确路径:
[root@server1-LK ~]# /opt/LifeKeeper/bin/lkkeyins /<许可证文件路径>l/quorum-disk.lic
步骤 2:设置并挂载共享存储:
确保集群中的所有服务器都可以访问共享存储。您可以使用“mount”命令或“findmnt”检查每个服务器,以验证是否已在本地安装:
[root@server1-LK 循环]# mount | grep NFS
/var/lib/nfs/rpc_pipefs 上的 sunrpc 类型 rpc_pipefs (rw,relatime)
172.16.200.254:/var/nfs/general on /nfs/general 类型 nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans= 2、sec=sys、clientaddr=172.16.205.151、local_lock=none、addr=172.16.200.254)
或者
[root@server1-LK ~]# findmnt -l /nfs/general
目标源 FSTYPE 选项
/nfs/general 172.16.200.254:/var/nfs/general nfs4 rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec =sys,clientaddr=172.16.205.151,local_lock=无,addr=172.16.200.254
如果您仍需要自行挂载共享,请按照以下步骤操作:
首先,确认您可以在主机服务器上看到 NFS 共享。
[root@server1-LK ~]# showmount -e 172.16.200.254
172.16.200.254 的导出列表:
/首页172.16.205.244,172.16.205.151
/var/nfs/一般 172.16.205.244,172.16.205.151
就我而言,我想挂载“/var/nfs/general”共享。
要挂载此共享,首先请确保您计划挂载的目录存在。如果没有,请创建它:
[root@server1-LK ~]# mkdir -p /nfs/general
现在,您可以使用以下命令手动挂载共享以确认可以连接,并且它可以工作:
[root@server1-LK ~]# mount 172.16.200.254:/var/nfs/general /nfs/general
最后,一旦满意,将挂载点添加到您的 /etc/fstab 文件中,以便它将在启动时挂载:
[root@server1-LK ~]# cat /etc/fstab
#
# /etc/fstab
# 由 anaconda 创建于 2024 年 1 月 25 日星期四 12:07:15
#
# 通过引用,可访问的文件系统维护在“/dev/disk/”下。
# 有关更多信息,请参阅手册页 fstab(5)、findfs(8)、mount(8) 和/或 blkid(8)。
#
# 编辑此文件后,运行 ‘systemctl daemon-reload’ 来更新 systemd
从该文件生成的 # 个单位。
#
/dev/mapper/rhel-root/xfs 默认 0 0
UUID=6b22cebf-8f1c-405b-8fa8-8f12e1b6b56c /boot xfs 默认 0 0
/dev/mapper/rhel-swap 无 交换默认值 0 0
#为 NFS 共享添加
172.16.200.254:/var/nfs/general /nfs/general nfs4 默认 0 0
现在,您可以使用 mount 命令确认它已安装:
[root@server1-LK ~]# mount -l | grep NFS
/var/lib/nfs/rpc_pipefs 上的 sunrpc 类型 rpc_pipefs (rw,relatime)
172.16.200.254:/var/nfs/general on /nfs/general 类型 nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans= 2、sec=sys、clientaddr=172.16.205.151、local_lock=none、addr=172.16.200.254)
从上面突出显示的文本可以看到,现在已经成功安装了。在所有服务器上重复此操作,直到确定所有服务器都已安装共享,然后再继续。
步骤 4:检查您的主机名并配置 /etc/default/LifeKeeper 设置:
您可以通过在每个节点上运行以下命令来查看 LifeKeeper 所知道的每个服务器的主机名:
/opt/LifeKeeper/bin/lcduname
您需要添加到 /etc/default/LifeKeeper 文件的设置示例:
WITNESS_MODE=存储
QWK_STORAGE_TYPE=文件
QWK_STORAGE_HBEATTIME=6
QWK_STORAGE_NUMHBEATS=9
QWK_STORAGE_OBJECT_server1_LK_localdomain=/nfs/general/nodeA
QWK_STORAGE_OBJECT_server2_LK_localdomain=/nfs/general/nodeB
对于“QWK_STORAGE_OBJECT_<server-name>”,您需要为每个节点声明它,它是使用您的主机名、路径以及见证文件本身的所需位置形成的。
需要注意的是,如果主机名包含“-”或“.”,请将其替换为下划线“_”(例如 lksios-1 → lksios_1 或 lksios-1.localdomain → lksios_1_localdomain )。
在我的示例中,我有以下主机名:
server1-LK.localdomain
server2-LK.localdomain
这意味着添加以下“QWK_STORAGE_OBJECT_”定义:
QWK_STORAGE_OBJECT_server1_LK_localdomain=/nfs/general/nodeA
QWK_STORAGE_OBJECT_server2_LK_localdomain=/nfs/general/nodeB
此外,我们需要调整 /etc/default/LifeKeeper 中的现有设置之一:
QUORUM_MODE=存储
为了帮助理解为什么我们将 WITNESS_MODE 和 QUORUM_MODE 设置为存储,请查看下表:
支持仲裁模式和见证模式的组合
LifeKeeper 支持以下组合。
| 法定模式 | |||||
| 多数 | tcp_远程 | 贮存 | 无/关 | ||
| 见证模式 | 远程验证 | 支持3个或更多节点 | 支持3个或更多节点 | 不支持 | 支持3个或更多节点 |
| 贮存 | 不支持 | 不支持 | 支持2到4个节点之间 | 不支持 | |
| 无/关 | 支持3个或更多节点 | 支持2个或更多节点 | 不支持 | 支持的 | |
我们有一个双节点集群,想要使用外部存储来进行仲裁,因此唯一支持的组合是两个值的“存储”。但是,您可以从表中看到,当您需要更多节点时,这可以非常灵活,提供多种方式来实现通信并提供法定人数。
第四步:初始化见证文件:
要初始化见证文件并启用其使用,您必须在每个节点上运行以下命令:
[root@server1-LK ~]# /opt/LifeKeeper/bin/qwk_storage_init
运行时它将暂停,直到每个节点完成,因此在集群中的第一个节点上执行命令,然后在第二个节点上执行命令,依此类推,然后返回检查命令是否完成且没有错误。
例子:
[root@server1-LK ~]# /opt/LifeKeeper/bin/qwk_storage_init
好的:LifeKeeper 正在运行。
ok:LifeKeeper 许可证密钥已成功安装。
ok:QWK 参数有效。
/nfs/general/nodeA 的 QWK 对象尚不可用。
/nfs/general/nodeA 已存在,但不存在 QWK_STORAGE_OBJECT:覆盖? (是/否):是
ok:QWK对象的路径有效。
好的:向下:/opt/LifeKeeper/etc/service/qwk-storage:1377s
ok:本节点QWK对象初始化完成。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
/nfs/general/nodeB 的 QWK 对象尚不可用。
ok:仲裁系统已准备就绪。
ok: 运行: /opt/LifeKeeper/etc/service/qwk-storage: (pid 14705) 1s, 正常down
成功的。
第 5 步:验证配置:
可以通过运行以下命令来验证配置:
/opt/LifeKeeper/bin/lktest
如果发现任何错误,它们将被打印到终端上。在下面的示例中,我没有替换主机名中的特殊字符,因此它突出显示无法找到存储。
[root@server1-LK ~]# /opt/LifeKeeper/bin/lktest
/opt/LifeKeeper/bin/lktest: /etc/default/LifeKeeper[308]: QWK_STORAGE_OBJECT_server1_LK.localdomain=/nfs/general/nodeA: 未找到
/opt/LifeKeeper/bin/lktest: /etc/default/LifeKeeper[309]: QWK_STORAGE_OBJECT_server2_LK.localdomain=/nfs/general/nodeB: 未找到
FS UID PID PPID C CLS PRI NI SZ STIME TIME CMD
4 S 根 2348 873 0 TS 39 -20 7656 15:49 00:00:00 lcm
4 S 根 2388 882 0 TS 39 -20 59959 15:49 00:00:00 ttymonlcm
4 S 根 2392 872 0 TS 29 -10 10330 15:49 00:00:00 液晶
4 S 根 8591 8476 0 TS 19 0 7670 15:58 00:00:00 lcdremexec -d server2-LK.localdomain -e — cat /proc/mdstat
您还可以通过命令行确认见证文件正在更新,如下所示:
[root@server1-LK ~]# cat /nfs/general/nodeA
签名=lifekeeper_qwk_object
local_node=server1-LK.localdomain
时间=2024年2月15日星期四14:10:56
序列=157
节点=server2-LK.localdomain
通讯状态=UP
校验和=13903688106811808601
使用 NFS 的成功文件共享见证
使用 NFS 设置文件共享见证非常简单!如果您仅限于两个节点,但需要更好地应对脑裂事件,那么它可能会很强大,特别是在云中,您可以利用 AWS 的 EFS 之类的东西……另一个重要部分可以是利用更多的通信路径,但这是一个不同的博客。但是,通过遵循本指南中概述的步骤,您可以增强集群应用程序的弹性并最大限度地降低停机风险。请始终参考SIOS文档以及进一步指导和优化高可用性设置的最佳实践。它是公开的并且非常全面!
SIOS 高可用性和灾难恢复
SIOS科技公司提供高可用性和灾难恢复通过针对最重要应用程序的集群管理来保护和优化 IT 基础设施的产品。今天联系我们有关我们的服务和专业支持的更多信息。
经许可转载安全操作系统