| 8月 20, 2022 |
白皮书:了解关键业务应用程序高可用性的复杂性
|
| 8月 18, 2022 |
介绍适用于 SIOS LifeKeeper 和 Google Cloud 的通用负载平衡器套件 |
| 8月 12, 2022 |
如何减少 SAP 的停机时间
如何减少 SAP 的停机时间想着怎么做减少 SAP 的停机时间是在初始解决方案设计期间应该访问的一个重要主题。 可以对现有的 SAP 环境进行更改,但在现有的生产环境中,这些可能会更加棘手,停机时间会成为问题。 SAP 环境中有几个典型的组件可以被视为单点故障; ASCS(中央服务)、HANA DB、NFS 节点和 SAP 应用程序服务器。 理想情况下,应该通过在高可用性配置中使用冗余服务器来保护这些。 SAP 的 HA/DR 目标为 SAP 设计高可用性/灾难恢复组件时的核心目标应该是:● 最大限度地减少停机时间 ● 消除数据丢失 ● 保持数据完整性 ● 支持灵活配置 在当今的现代云环境中,底层硬件的基础架构通常通过使用多个冗余 NIC、冗余存储和硬件可用区得到很好的保护,避免出现故障——然而,这仍然没有'不保证您的 SAP 应用程序将运行并响应请求。 用一个高可用性SIOS 保护套件等解决方案引入了智能高可用性以及本地磁盘复制,以确保您的 SAP 应用程序和服务受到持续监控和保护,并能够在检测到故障时自动切换到冗余硬件。 现在让我们考虑一个不受 HA 保护的 SAP 配置的简单示例,它可能看起来像这样(图 1): 现在让我们假设这个销售处理环境(如上图)是在没有 HA 的情况下在云中配置的,因为架构师认为云环境中的高度冗余硬件足以防止故障。如果该 HANA 数据库遇到问题并关闭,让我们看看使数据库恢复正常运行所需的典型步骤: ● 即使HANA 配置了HANA 系统复制,故障转移到辅助HANA 数据库系统也不会自动进行。 这将需要知道 HANA 的人在检测到故障并通知他们中断后进行纠正。 IBM 的这份报告表明每小时的平均停机成本为 1 万美元 扩大客户规模,很可能任何系统停机情况都会开始花费数十万美元并消耗大量人力资源来解决。 其他IBM 报告表明惊人的 44% 的受访者每两个月进行一次计划外停机,另有 35% 的受访者每月进行一次计划外停机。 计划中断本身是另一个潜在问题,46% 的受访者报告每月计划中断,另有 29% 报告年度计划中断。 让应用程序和服务受 HA 软件保护还可以通过允许在维护活动期间将服务转移到正在运行的系统来缓解这些计划内的中断。 学习更多关于SAP 和 S/4HANA 的高可用性. |
| 8月 8, 2022 |
白皮书:探索受监管行业中的高可用性用例 |
|
|


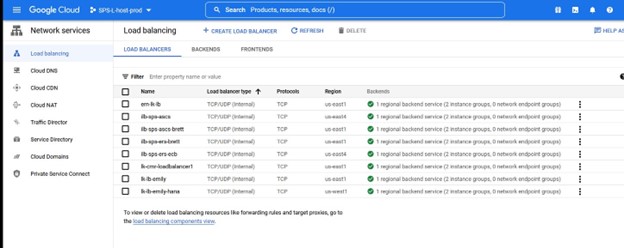
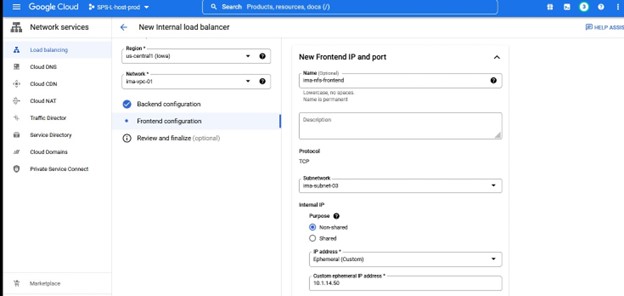
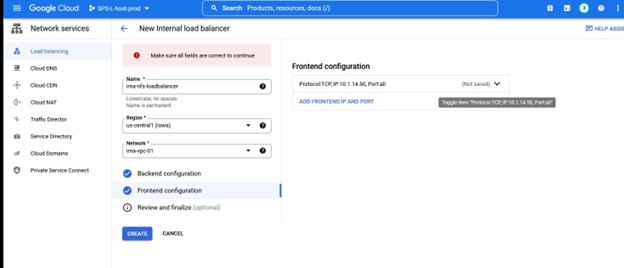
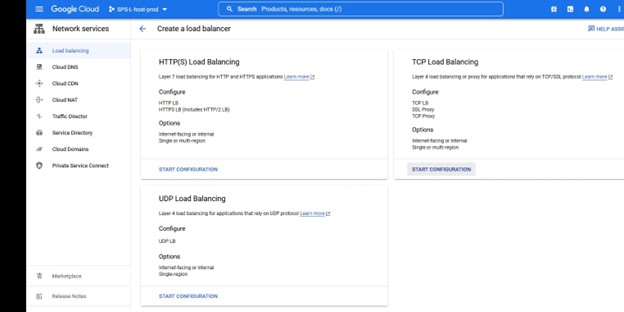 在这种情况下,我们需要 TCP 负载平衡 创建一个负载平衡器,您将选择要部署它的资源组以及名称,我喜欢使用与我的集群类型一致的名称将负载平衡器与例如 IMA-NFS-LB 一起使用将位于两个 IMA-NFS 节点的前面。
在这种情况下,我们需要 TCP 负载平衡 创建一个负载平衡器,您将选择要部署它的资源组以及名称,我喜欢使用与我的集群类型一致的名称将负载平衡器与例如 IMA-NFS-LB 一起使用将位于两个 IMA-NFS 节点的前面。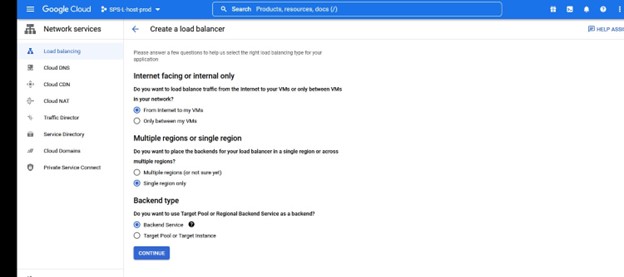
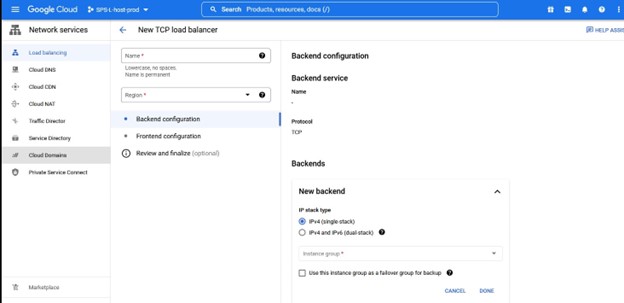
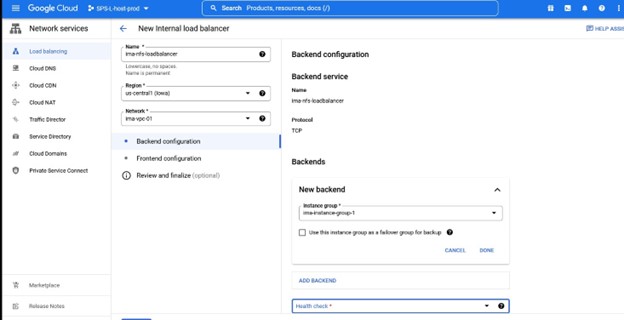
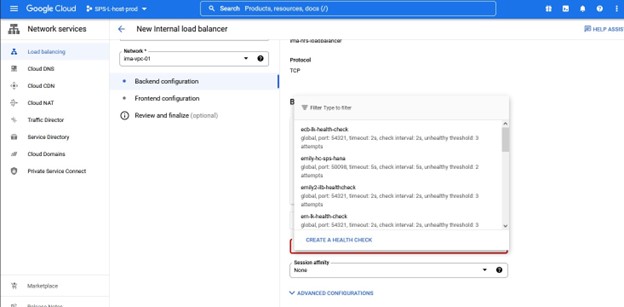
 同样,请注意端口号,因为这将与 Lifekeeper 一起使用。
同样,请注意端口号,因为这将与 Lifekeeper 一起使用。
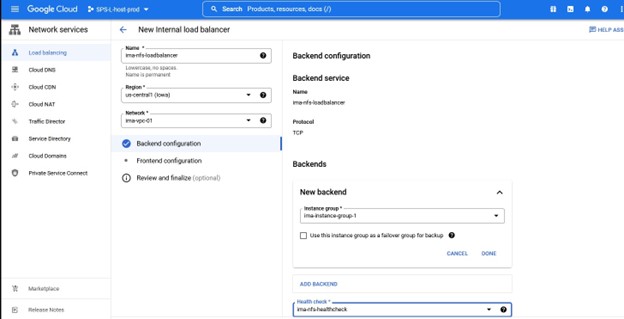
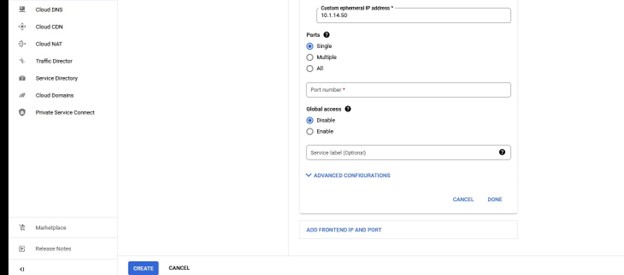
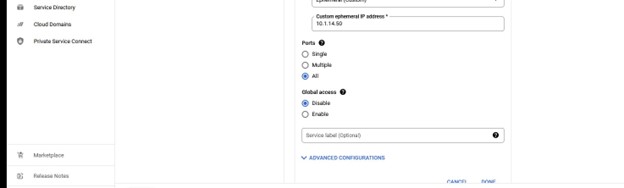
 我们需要在
我们需要在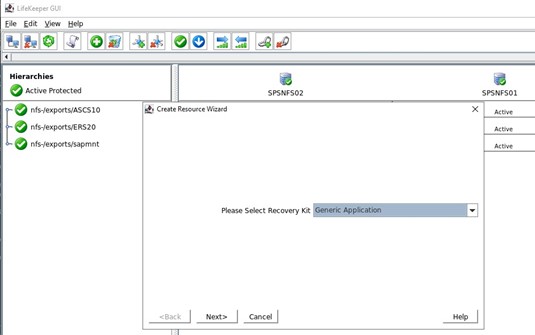
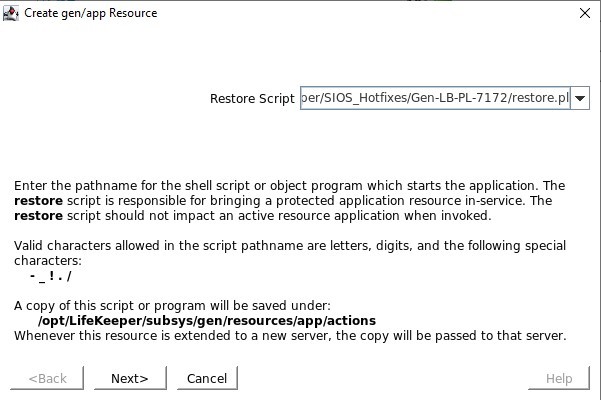 定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 restore.pl 脚本
定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 restore.pl 脚本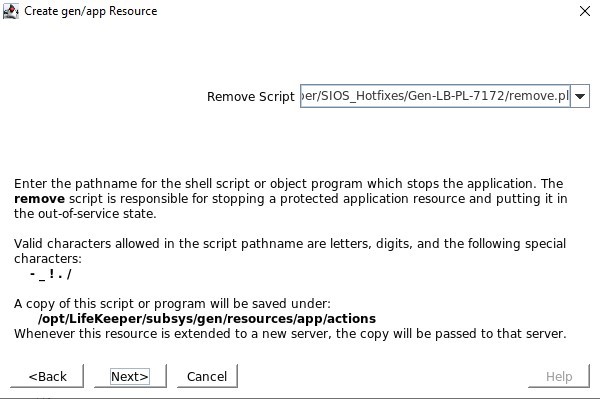 定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 remove.pl 脚本
定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 remove.pl 脚本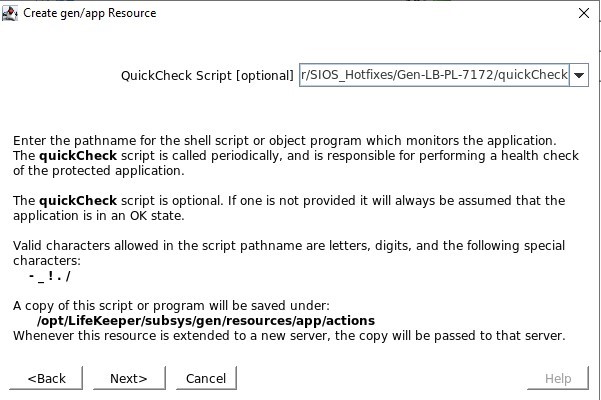 定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 quickCheck 脚本
定义位于 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/ 中的 quickCheck 脚本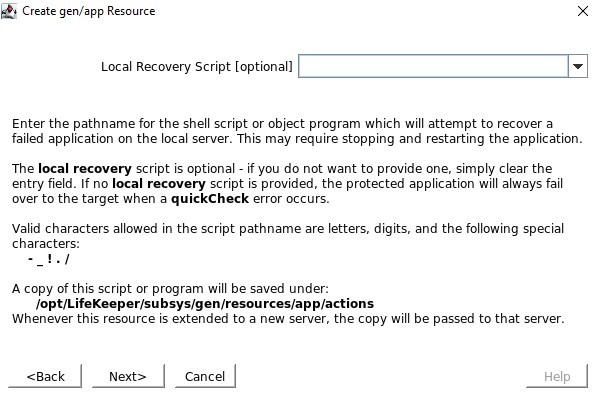 没有本地恢复脚本,因此请确保清除此输入
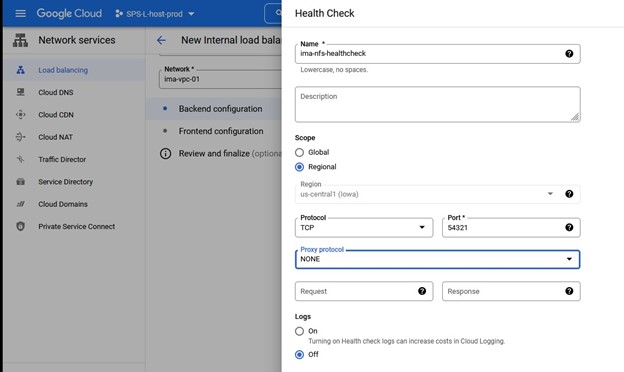
没有本地恢复脚本,因此请确保清除此输入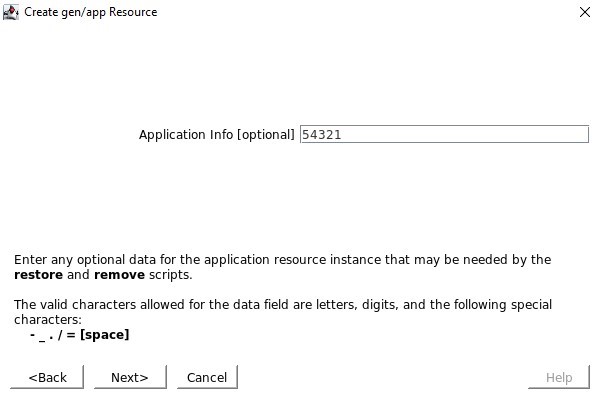 当询问应用程序信息时,我们希望输入与在 Healthcheck 端口中配置的端口号相同的端口号,例如 54321
当询问应用程序信息时,我们希望输入与在 Healthcheck 端口中配置的端口号相同的端口号,例如 54321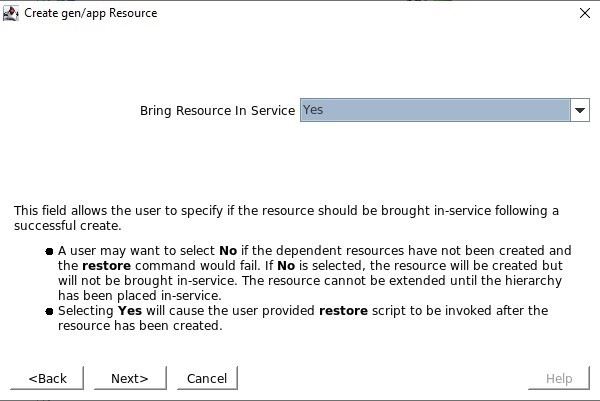 我们将选择在服务创建后将其投入使用
我们将选择在服务创建后将其投入使用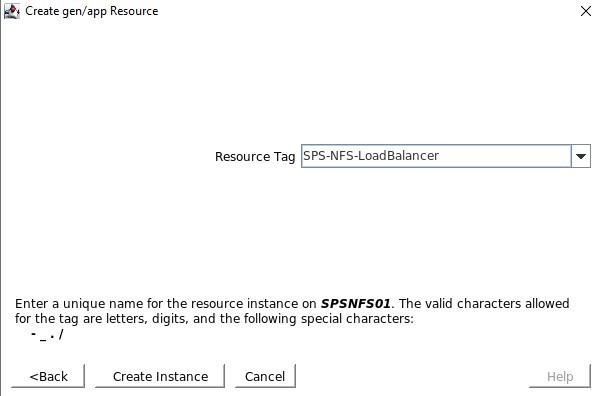 Resource Tag 是我们将在 SPS-L GUI 中看到的名称,我喜欢使用易于识别的名称
Resource Tag 是我们将在 SPS-L GUI 中看到的名称,我喜欢使用易于识别的名称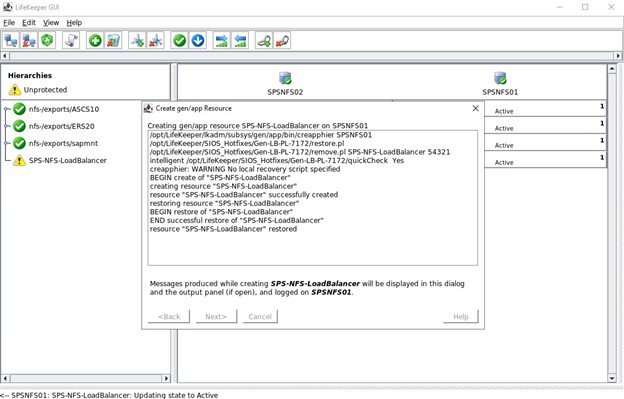 如果一切配置正确,您将看到“结束成功还原”,然后我们可以将其扩展到另一个节点,以便资源可以托管在任一节点上。
如果一切配置正确,您将看到“结束成功还原”,然后我们可以将其扩展到另一个节点,以便资源可以托管在任一节点上。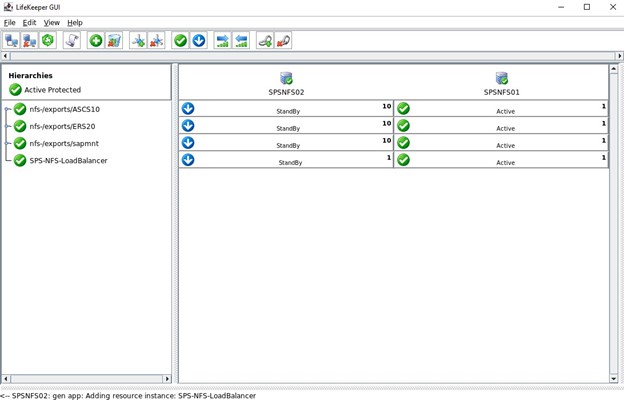
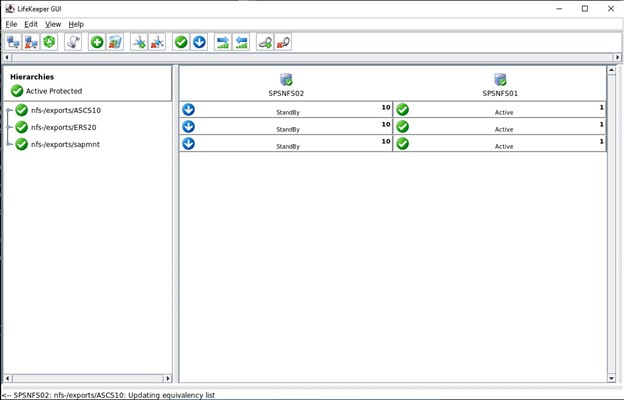
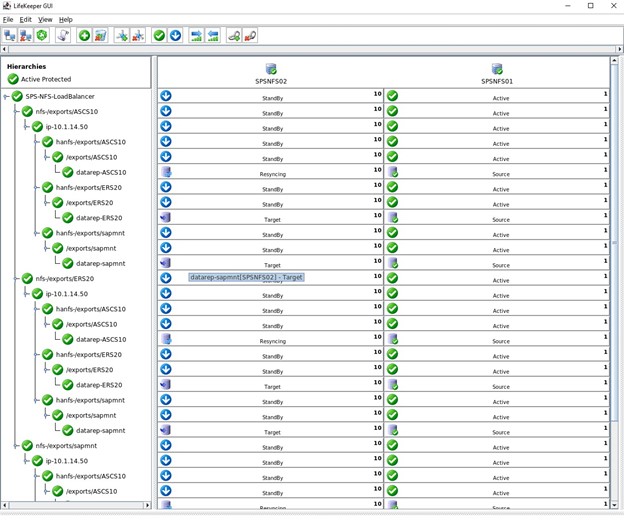
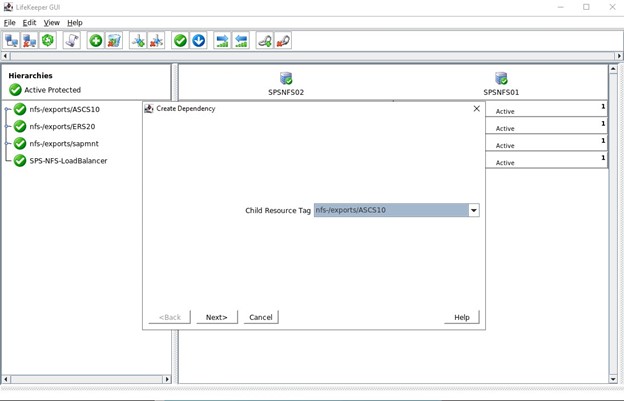 该集群的最后一步是为三个 NFS 导出创建子依赖项,这意味着所有带有 Datakeeper 镜像和 IP 的 NFS 导出都将依赖于负载均衡器。 如果活动节点上出现严重问题,那么所有这些资源都将故障转移到其他正常运行的节点。
该集群的最后一步是为三个 NFS 导出创建子依赖项,这意味着所有带有 Datakeeper 镜像和 IP 的 NFS 导出都将依赖于负载均衡器。 如果活动节点上出现严重问题,那么所有这些资源都将故障转移到其他正常运行的节点。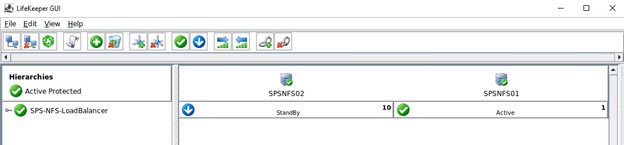

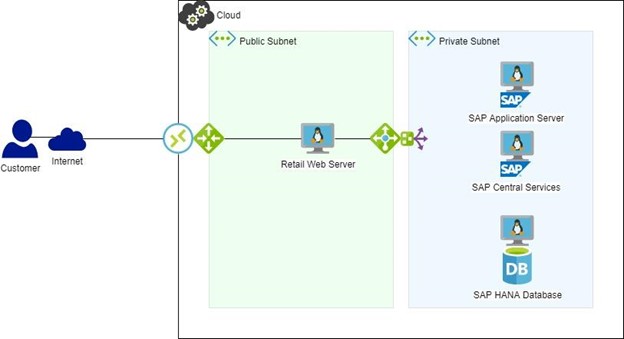 如果此环境用于处理来自用于向客户销售服装的 Web 服务器的交易,那么 SAP 将用于处理销售、跟踪订单、跟踪库存并基于这些交易提供多个自动订购等。
如果此环境用于处理来自用于向客户销售服装的 Web 服务器的交易,那么 SAP 将用于处理销售、跟踪订单、跟踪库存并基于这些交易提供多个自动订购等。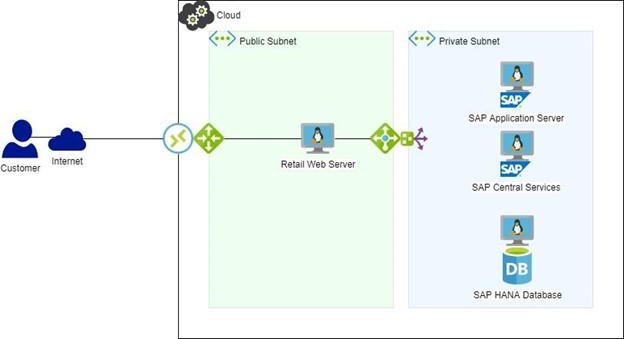
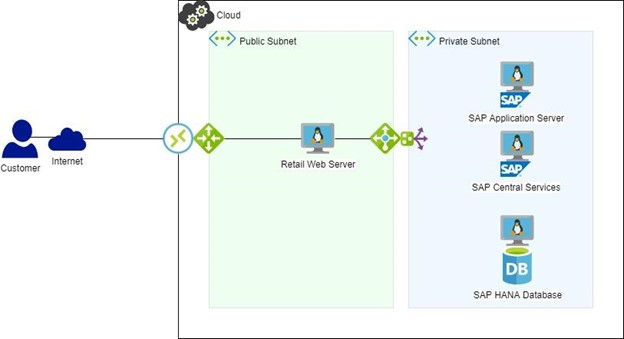
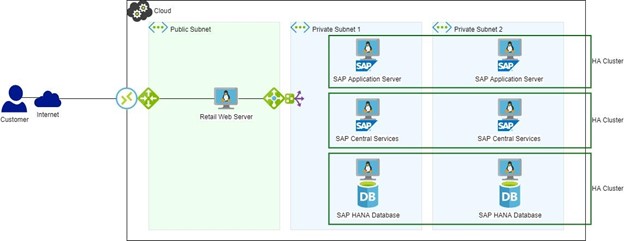 图 2:具有 HA/DR 的 SAP 环境如果 HA 软件一直在使用中(图 2),HANA DB 故障转移将是自动的,并且 Web 服务器的中断将在配置的超时范围内,并且绝对不会有任何销售损失。 将生成警报,并且可以比系统停机情况更轻松地查看和诊断原因。
图 2:具有 HA/DR 的 SAP 环境如果 HA 软件一直在使用中(图 2),HANA DB 故障转移将是自动的,并且 Web 服务器的中断将在配置的超时范围内,并且绝对不会有任何销售损失。 将生成警报,并且可以比系统停机情况更轻松地查看和诊断原因。