Date: 1月 29, 2022

通过高可用性最大限度地减少停机时间
对于现代企业来说,停机时间变得比以往任何时候都更加昂贵。 ITIC 2021 年每小时停机成本调查发现,在 91% 的组织中,关键业务系统、数据库或应用程序停机一小时的平均成本超过 300,000 美元,而对于 18% 的大型企业来说,一小时的停机时间超过 500 万美元。
高可用性(HA) 是系统、数据库或应用程序的属性,旨在长时间连续可靠地运行。 HA 的目标是减少或消除关键应用程序的计划外停机时间。 这是通过在关键业务系统、数据库或应用程序的设计中结合冗余组件和其他技术来消除单点故障来实现的。
SLA 和 HA 指标
服务提供商使用服务级别协议 (SLA) 来保证客户的关键业务系统、数据库或应用程序在业务需要时启动并运行。
IDC 创建了一个 SLA 模型,该模型定义了以下五个级别的正常运行时间要求:
- AL4(持续可用性 – 系统容错):每年不超过 5 分 15 秒的计划内和计划外停机时间(99.999% 或“五个九”的可用性)
- AL3(高可用性 – 传统集群):每年计划内和计划外停机时间不超过 52 分 35 秒(99.99% 或“四个九”的可用性)
- AL2(恢复 – 数据复制和备份):每年计划和计划外停机时间不超过 8 小时 45 分 56 秒(99.9% 或“三个九”的可用性)
- AL1(可靠性 – 可热插拔组件):每年计划和计划外停机时间不超过 87 小时 39 分 29 秒(99% 或“两个九”的可用性)
- AL0(未受保护的服务器):没有可用性或正常运行时间保证
据 ITIC 称,89% 的受访组织现在要求其关键业务系统、数据库和应用程序具有“四个九”的可用性,其中 35% 的组织进一步努力实现“五个九”的可用性。
除了正常运行时间和可用性之外,另外两个重要的 HA 指标是恢复时间目标(RTO)和恢复点目标(RPO)。 RTO 是任何中断的最大可容忍持续时间,RPO 是发生故障时可以容忍的最大数据丢失量。 与通常以小时和天定义的灾难恢复 RTO 和 RPO 指标不同,关键业务系统、数据库和应用程序的 RTO 和 RPO 指标通常只有几秒钟 (RTO) 和零 (RPO)。
高可用性集群
HA 集群通常由服务器节点、存储和集群软件组成。
传统聚类
传统的本地 HA 集群是一组连接到共享存储(通常是存储区域网络或 SAN)的两个或多个服务器节点,这些节点配置有相同的操作系统、数据库和应用程序(请参阅图1 )。
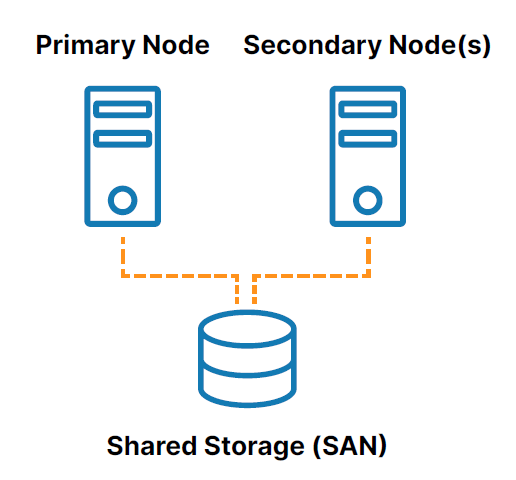
其中一个节点被指定为主(或活动)节点,其他(或多个)被指定为辅助(或备用)节点。 如果主节点发生故障,集群允许系统、数据库或应用程序自动故障转移到一个或多个辅助节点,并以最小的中断继续运行。 由于辅助节点连接到同一个存储,因此操作继续进行,数据丢失为零。
然而,在传统集群模型中使用共享存储带来了一些挑战,包括:
- 共享存储本身是一个单点故障,可能会使集群中所有连接的节点脱机。
- SAN 存储的拥有和管理成本高且复杂。
- 云中的共享存储会增加大量不必要的成本和复杂性,一些云提供商甚至不提供共享存储选项。
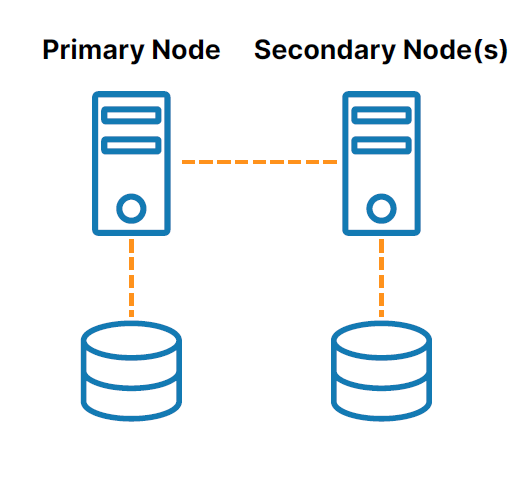
SANless 集群
无 SAN 或“无共享”集群(请参阅图 2 ) 解决与共享存储相关的挑战。 在这些配置中,每个集群节点都有自己的本地存储。 高效的基于主机的块级复制用于同步集群节点上的存储,保持它们相同。 如果发生故障转移,辅助节点会访问主节点使用的存储的相同副本。
集群软件
集群软件允许您将服务器配置为集群,以便多台服务器可以协同工作以提供 HA 并防止数据丢失。 各种集群软件解决方案可用于 Windows、Linux 发行版和各种虚拟机管理程序。 但是,这些解决方案中的每一个都限制了您的灵活性和部署选项,并带来了各种挑战,例如技术复杂性和昂贵的许可费用。
不要等待灾难来袭
HA 对于关键业务系统、数据库和应用程序至关重要。 但是随着无数平台的可用,复杂性显着增加。 这就是为什么应用程序感知解决方案如此有意义的原因。 您需要的是一个在高可用性方面拥有丰富专业知识的值得信赖的合作伙伴——像 SIOS 这样的合作伙伴,它拥有确保您的业务保持正常运行的技术知识。
不要等待中断或灾难来确定您是否具备业务所需的弹性。 立即在以下位置安排个性化演示https://us.sios.com了解 SIOS 可以为您的业务做些什么。
转载自西欧