ทีละขั้นตอน: SQL Server v.Next Linux ความพร้อมใช้งานสูง – การแสดงตัวอย่างสาธารณะ #azure #sql #sanless
เมื่อต้นปีนี้ Microsoft ประกาศว่าพวกเขาจะเปิดตัว SQL Server สำหรับ Linux รุ่นหนึ่ง วันนี้ฉันรู้สึกตื่นเต้นที่ได้ทราบว่าในที่สุดไมโครซอฟท์ได้ประกาศตัวอย่างสาธารณะของสิ่งที่พวกเขากำลังเรียกใช้ SQL Server v.Next และมันพร้อมใช้งานสำหรับทั้งระบบปฏิบัติการ Linux และ Windows ข้อมูลเพิ่มเติมพร้อมกับลิงค์ดาวน์โหลดและเอกสารประกอบอยู่ที่นี่:
https://www.microsoft.com/en-us/sql-server/sql-server-vnext-including-Linux
SQL Server สำหรับ Linux
ในบทความนี้ฉันจะไม่เพียงแสดงวิธีการปรับใช้ Linux VM ใน Azure ที่ใช้ SQL Server แต่ยังรวมถึงวิธีการกำหนดค่าคลัสเตอร์ล้มเหลว 2 โหนดเพื่อให้พร้อมใช้งานสูง! และไม่มีการใช้ที่เก็บข้อมูลที่ใช้ร่วมกัน (หรือที่รู้จักว่ากลุ่ม "ไร้สาระ" หรือ "ไม่มีการแบ่งปัน") ผลลัพธ์ที่ได้จะเป็น SQL Server 2 โหนดสำหรับคลัสเตอร์ Linux (รวมถึงเซิร์ฟเวอร์พยาน) ใน Microsoft Azure IaaS (โครงสร้างพื้นฐานเป็นบริการ) คำแนะนำประกอบด้วยภาพหน้าจอคำสั่งเชลล์และตัวอย่างโค้ดตามความเหมาะสม ฉันคิดว่าคุณค่อนข้างคุ้นเคยกับ Microsoft Azure และมีบัญชี Azure ที่มีการสมัครรับข้อมูลที่เกี่ยวข้องอยู่แล้ว ถ้าไม่คุณสามารถสมัครใช้งานบัญชีฟรีวันนี้ ฉันจะสมมติว่าคุณมีทักษะการบริหารระบบพื้นฐานของ linux เช่นเดียวกับเข้าใจแนวคิดการทำคลัสเตอร์ failover พื้นฐานเช่น IP เสมือนจริงเป็นต้น คำเตือน: สีฟ้าเป็นเป้าหมายที่เคลื่อนไหวอย่างรวดเร็ว และที่นี่ฉันกำลังทำงานกับรุ่นตัวอย่างสาธารณะของ SQL Server สำหรับ Linux ดังนั้นคุณสมบัติ / หน้าจอ / ปุ่มจะถูกเปลี่ยนแปลงก่อนที่จะมีการเปิดตัว SQL v.Next อย่างเป็นทางการดังนั้นประสบการณ์ของคุณอาจแตกต่างจากที่คุณเห็นด้านล่างเล็กน้อย ในขณะที่คู่มือนี้จะแสดงวิธีทำให้ฐานข้อมูล SQL Server สำหรับ Linux พร้อมใช้งานสูงคุณสามารถปรับข้อมูลและกระบวนการนี้เพื่อปกป้องแอปพลิเคชันหรือฐานข้อมูลอื่น ๆ อย่างที่ฉันได้เขียนไว้ก่อนหน้านี้ (ตัวอย่าง MySQL) นี่เป็นขั้นตอนระดับสูงในการสร้างฐานข้อมูล MySQL ที่มีอยู่ภายใน Microsoft Azure IaaS:
- สร้างกลุ่มทรัพยากร
- สร้างเครือข่ายเสมือน
- สร้างบัญชีหน่วยเก็บข้อมูล
- สร้างเครื่องเสมือนในชุดความพร้อมใช้งาน
- ตั้งค่า VM Static IP Addresses
- เพิ่มดิสก์ข้อมูลลงในโหนดคลัสเตอร์
- สร้างกฎความปลอดภัยขาเข้าเพื่ออนุญาตการเข้าถึง VNC
- การกำหนดค่า Linux OS
- ติดตั้งและกำหนดค่าเซิร์ฟเวอร์ SQL
- ติดตั้งและกำหนดค่าคลัสเตอร์
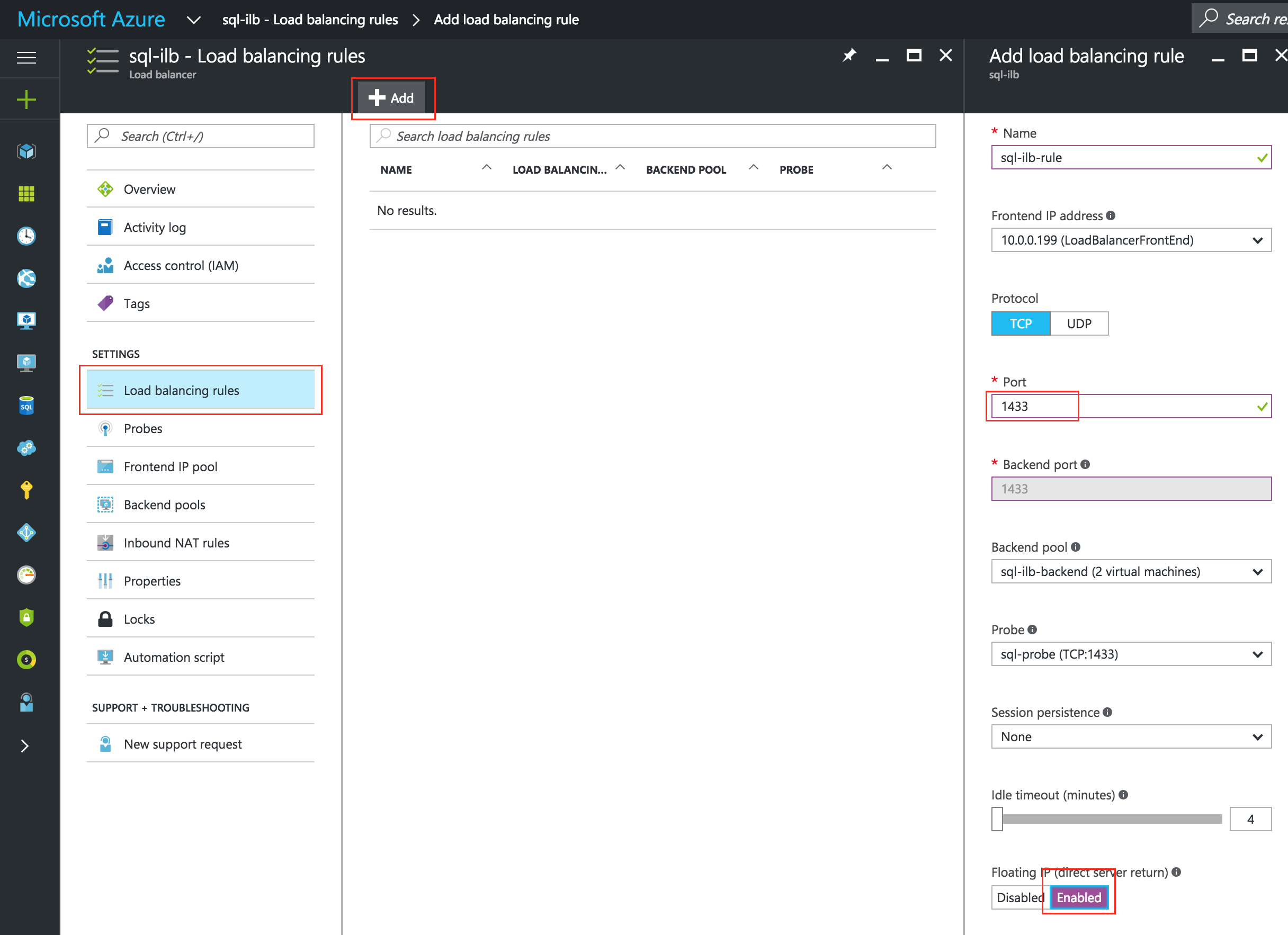
- สร้างเครื่องมือสร้างสมดุลภายใน
- ทดสอบการเชื่อมต่อของคลัสเตอร์
ภาพรวม
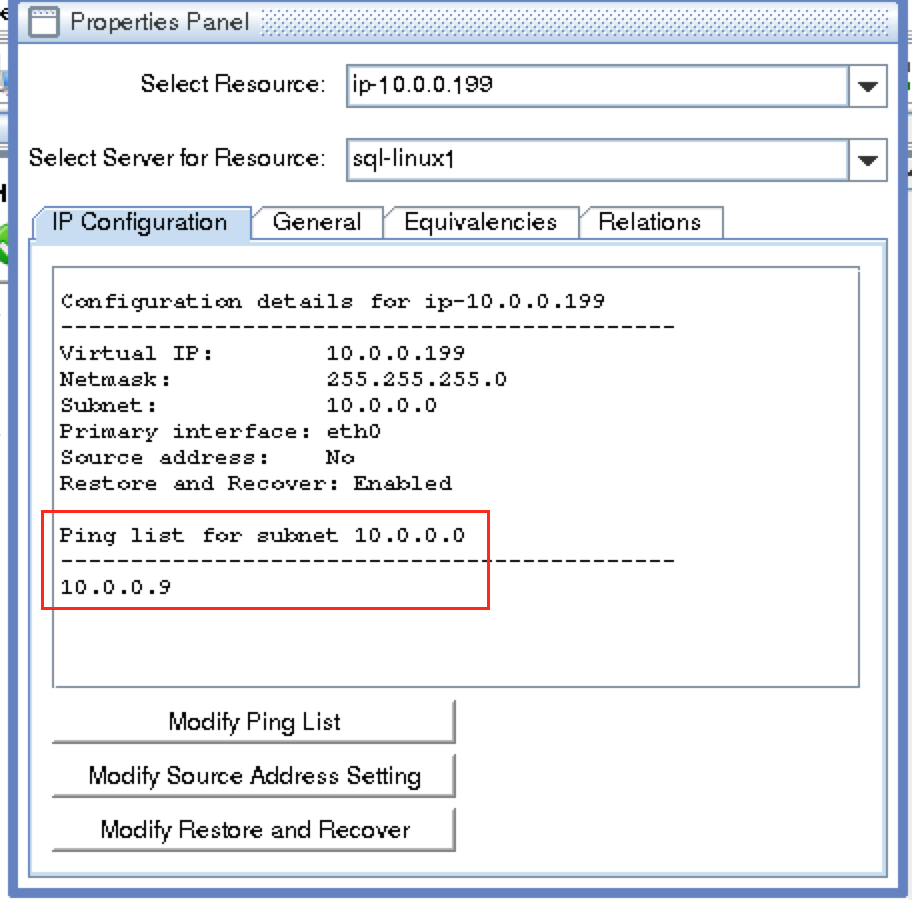
บทความนี้จะอธิบายวิธีการสร้างคลัสเตอร์ภายในภูมิภาค Azure เดียว โหนดคลัสเตอร์ (sql-linux1, sql-linux2 และเซิร์ฟเวอร์พยาน) จะอยู่ในชุดความพร้อมใช้งาน (Fault Domains ที่แตกต่างกัน 3 รายการและอัปเดตโดเมน) ขอบคุณ Azure Resource Manager (ARM) ใหม่ เราจะสร้างทรัพยากรทั้งหมดโดยใช้ Azure Resource Manager ใหม่ การกำหนดค่าจะมีลักษณะดังนี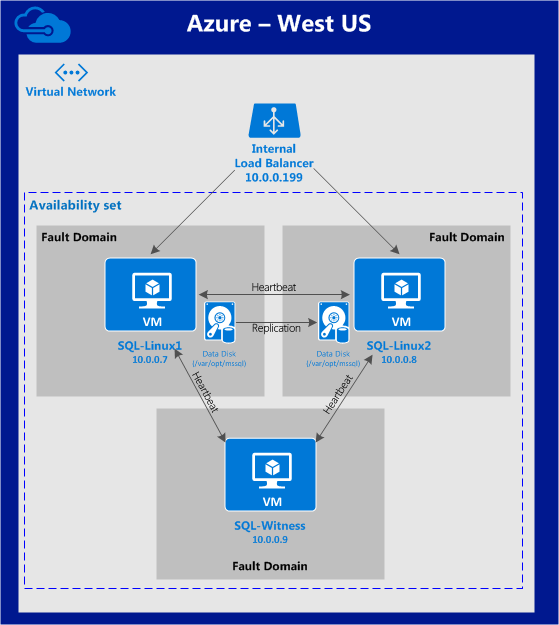 ้: จะใช้ที่อยู่ IP ต่อไปนี้:
้: จะใช้ที่อยู่ IP ต่อไปนี้:
- sql-linux1: 10.0.0.7
- sql-linux2: 10.0.0.8
- sql -itness: 10.0.0.9
- เสมือน /” ลอย” IP: 10.0.0.199
- พอร์ต SQL Server: 1433
สร้างกลุ่มทรัพยากร
ขั้นแรกสร้างกลุ่มทรัพยากร กลุ่มทรัพยากรของคุณจะจบลงด้วยการมีวัตถุต่าง ๆ ที่เกี่ยวข้องกับการปรับใช้คลัสเตอร์ของเรา: เครื่องเสมือนบัญชีจัดเก็บข้อมูล ฯลฯ ที่นี่เราจะเรียกกลุ่มทรัพยากร "sql-cluster" ที่สร้างขึ้นใหม่ของเรา  ระวังเมื่อเลือกภูมิภาคของคุณ ทรัพยากรทั้งหมดของคุณจะต้องอยู่ในภูมิภาคเดียวกัน ที่นี่เราจะปรับใช้ทุกอย่างในภูมิภาค "West US":
ระวังเมื่อเลือกภูมิภาคของคุณ ทรัพยากรทั้งหมดของคุณจะต้องอยู่ในภูมิภาคเดียวกัน ที่นี่เราจะปรับใช้ทุกอย่างในภูมิภาค "West US": 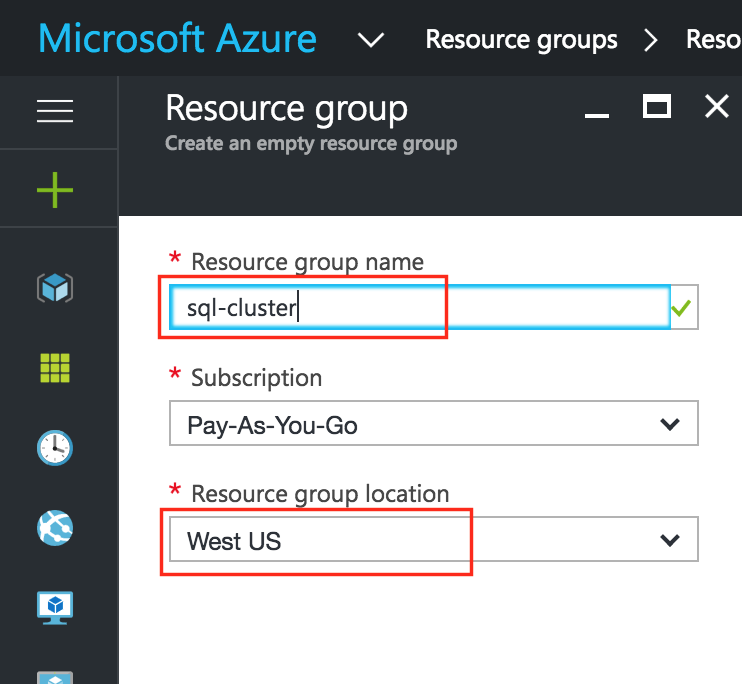
สร้างเครือข่ายเสมือน (VNet)
ถัดไปหากคุณยังไม่มีให้สร้างเครือข่ายเสมือน เครือข่ายเสมือนเป็นเครือข่ายแยกภายในคลาวด์ Azure ที่ทุ่มเทให้กับคุณ คุณสามารถควบคุมสิ่งต่าง ๆ เช่นบล็อกที่อยู่ IP และซับเน็ตการกำหนดเส้นทางนโยบายความปลอดภัย (เช่นไฟร์วอลล์) การตั้งค่า DNS และอื่น ๆ คุณจะเปิดตัวเครื่องเสมือน Azure Iaas (VMs) ในเครือข่ายเสมือนของคุณ บัญชี Azure ของฉันมี VNet (10.0.0.0/16) ที่มีอยู่ชื่อ "เครือข่ายคลัสเตอร์" ที่ฉันจะใช้ในคู่มือนี้ การสร้าง VNet นั้นตรงไปตรงมาและฉันได้กล่าวถึงการสร้างไว้ที่นี่หากคุณต้องการทบทวน
สร้างบัญชีหน่วยเก็บข้อมูล
ก่อนที่คุณจะจัดเตรียมเครื่องเสมือนใด ๆ คุณจะต้องมีบัญชีที่เก็บข้อมูลเพื่อจัดเก็บ 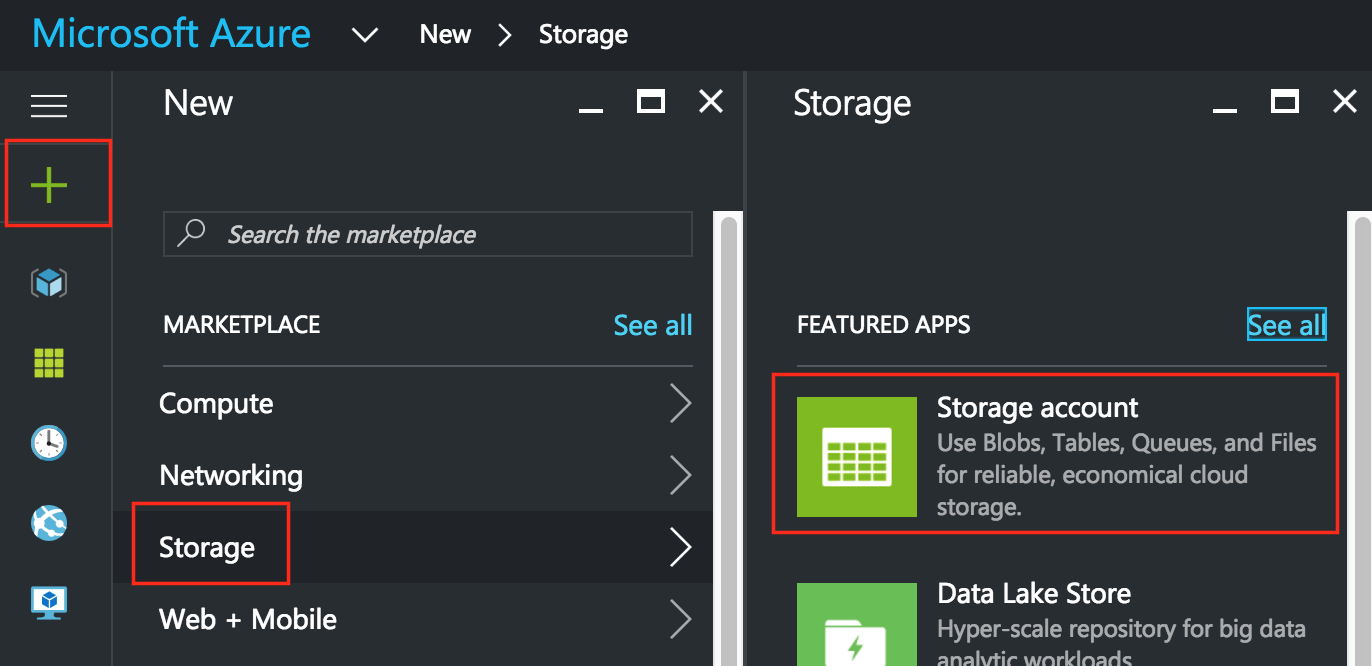 ถัดไปตั้งชื่อบัญชีที่เก็บข้อมูลใหม่ของคุณ ชื่อบัญชีที่จัดเก็บข้อมูลต้องไม่ซ้ำกันใน * ALL * ของ Azure (ทุกวัตถุที่คุณจัดเก็บใน Azure Storage มีที่อยู่ URL ที่ไม่ซ้ำกัน ชื่อบัญชีพื้นที่เก็บข้อมูลเป็นโดเมนย่อยของที่อยู่นั้น) ในตัวอย่างนี้ฉันเรียกบัญชีเก็บข้อมูลของฉัน“ sqllinuxcluster” แต่คุณจะต้องเลือกสิ่งที่แตกต่างเมื่อคุณตั้งค่าของคุณเอง เลือกประเภทการจัดเก็บตามความต้องการและงบประมาณของคุณ สำหรับวัตถุประสงค์ของคู่มือนี้ฉันเลือก“ Standard-LRS” (เช่น ซ้ำซ้อนในพื้นที่) เพื่อลดต้นทุน ตรวจสอบให้แน่ใจว่าบัญชีหน่วยเก็บข้อมูลใหม่ของคุณถูกเพิ่มไปยังกลุ่มทรัพยากรที่คุณสร้างในขั้นตอนที่ 1 (“ sql-cluster”) ในตำแหน่งเดียวกัน (“ West US” ในตัวอย่างนี้):
ถัดไปตั้งชื่อบัญชีที่เก็บข้อมูลใหม่ของคุณ ชื่อบัญชีที่จัดเก็บข้อมูลต้องไม่ซ้ำกันใน * ALL * ของ Azure (ทุกวัตถุที่คุณจัดเก็บใน Azure Storage มีที่อยู่ URL ที่ไม่ซ้ำกัน ชื่อบัญชีพื้นที่เก็บข้อมูลเป็นโดเมนย่อยของที่อยู่นั้น) ในตัวอย่างนี้ฉันเรียกบัญชีเก็บข้อมูลของฉัน“ sqllinuxcluster” แต่คุณจะต้องเลือกสิ่งที่แตกต่างเมื่อคุณตั้งค่าของคุณเอง เลือกประเภทการจัดเก็บตามความต้องการและงบประมาณของคุณ สำหรับวัตถุประสงค์ของคู่มือนี้ฉันเลือก“ Standard-LRS” (เช่น ซ้ำซ้อนในพื้นที่) เพื่อลดต้นทุน ตรวจสอบให้แน่ใจว่าบัญชีหน่วยเก็บข้อมูลใหม่ของคุณถูกเพิ่มไปยังกลุ่มทรัพยากรที่คุณสร้างในขั้นตอนที่ 1 (“ sql-cluster”) ในตำแหน่งเดียวกัน (“ West US” ในตัวอย่างนี้): 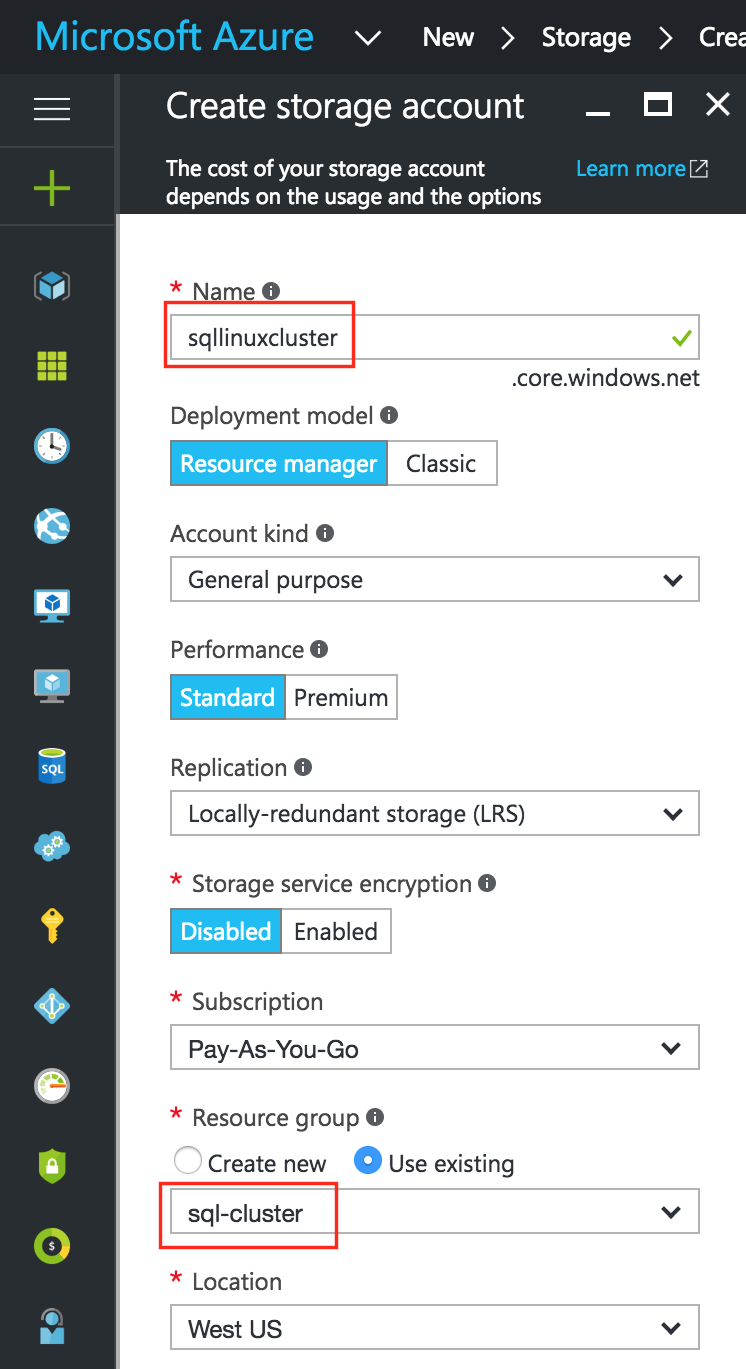
สร้างเครื่องเสมือนในชุดความพร้อมใช้งาน
เราจะทำการจัดเตรียม 3 เครื่องเสมือนในคู่มือนี้ VMs สองตัวแรก (ฉันจะเรียกพวกเขาว่า "sql-linux1" และ "sql-linux2") จะทำหน้าที่เป็นโหนดคลัสเตอร์ที่มีความสามารถในการนำฐานข้อมูล SQL Server และทรัพยากรที่เกี่ยวข้องออนไลน์ VM ที่ 3 จะทำหน้าที่เป็นเซิร์ฟเวอร์พยานของคลัสเตอร์สำหรับการป้องกันเพิ่มเติมจากสมองแยก เพื่อให้แน่ใจว่ามีความพร้อมใช้งานสูงสุด VM ทั้งหมด 3 เครื่องจะถูกเพิ่มไปยังชุดความพร้อมใช้งานเดียวกันเพื่อให้แน่ใจว่าพวกเขาจะลงเอยด้วย Fault Domains และ Update Domains ที่แตกต่างกัน Azure Marketplace มีเทมเพลต VM ชื่อ“ SQL Server vNext บน Red Hat Enterprise Linux 7.2” ที่มีรุ่นทดลองใช้สาธารณะตัวอย่าง SQL Server v.Next สำหรับ Linux ที่ติดตั้งไว้ล่วงหน้าซึ่งจะช่วยให้คุณประหยัดเวลาได้ไม่กี่ขั้นตอน หากคุณต้องการเริ่มต้นด้วย VM ที่ว่างเปล่าและติดตั้ง SQL ด้วยตนเองคุณสามารถดูคำแนะนำการติดตั้งได้ที่นี่
สร้าง VM“ sql-linux1”
สร้าง VM แรกของคุณ (“ sql-linux1”) และเลือกภาพตลาดดังกล่าวข้างต้น 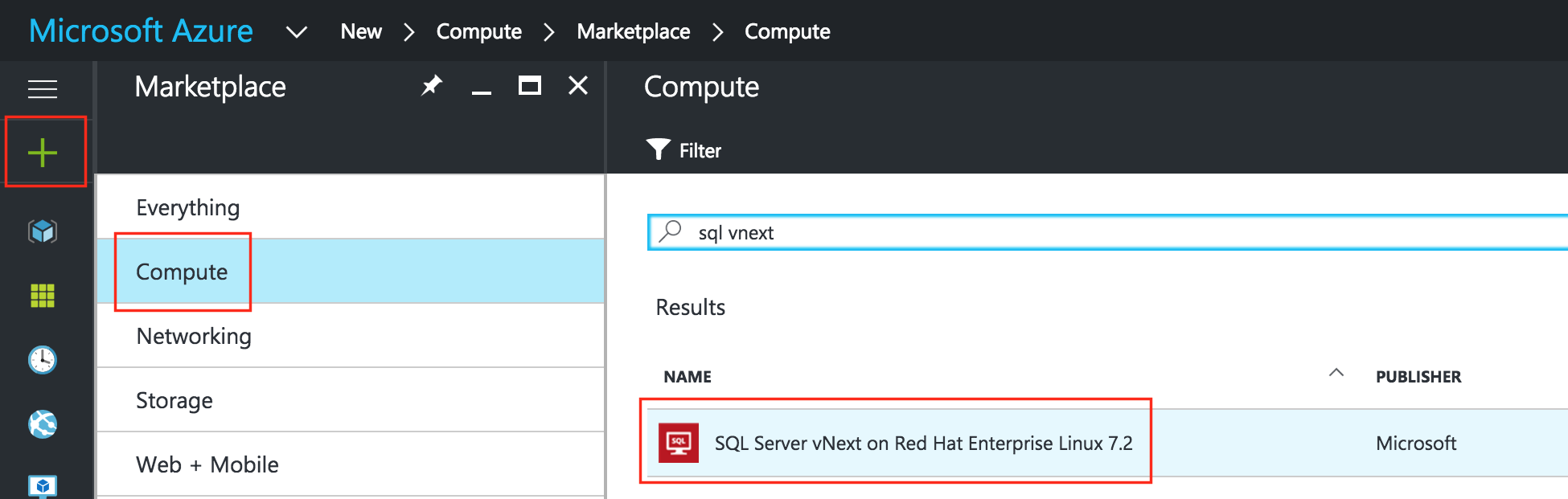 ตั้งชื่อโฮสต์ VM (“ sql-linux1”) และชื่อผู้ใช้ / รหัสผ่านที่จะใช้ในภายหลังเพื่อ SSH เข้าสู่ระบบ ตรวจสอบให้แน่ใจว่าคุณเพิ่ม VM นี้ในกลุ่มทรัพยากรของคุณ (“ sql-cluster”) และอยู่ในภูมิภาคเดียวกับทรัพยากรอื่น ๆ ทั้งหมดของคุณ
ตั้งชื่อโฮสต์ VM (“ sql-linux1”) และชื่อผู้ใช้ / รหัสผ่านที่จะใช้ในภายหลังเพื่อ SSH เข้าสู่ระบบ ตรวจสอบให้แน่ใจว่าคุณเพิ่ม VM นี้ในกลุ่มทรัพยากรของคุณ (“ sql-cluster”) และอยู่ในภูมิภาคเดียวกับทรัพยากรอื่น ๆ ทั้งหมดของคุณ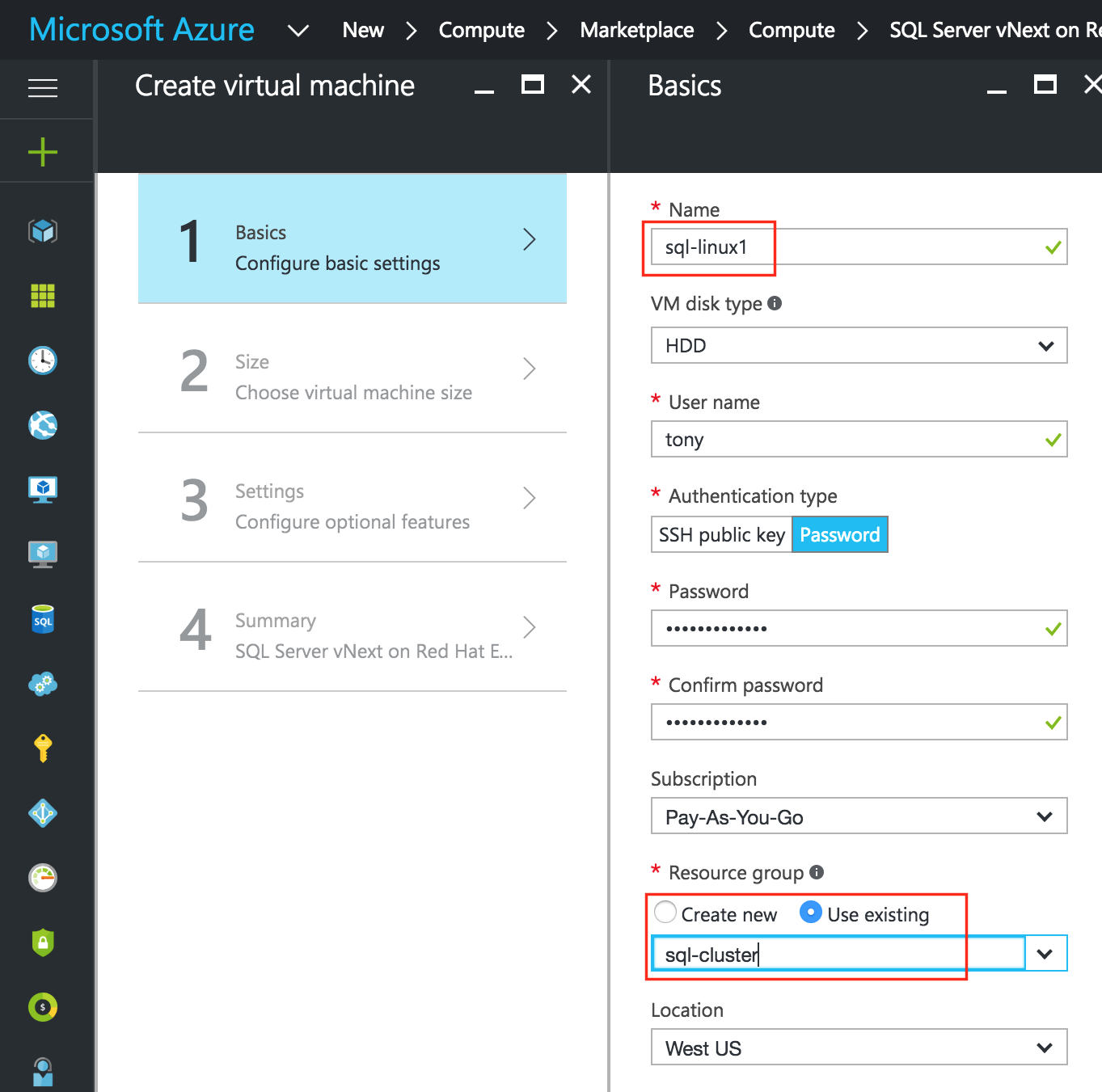 : ถัดไปเลือกขนาดอินสแตนซ์ของคุณ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับขนาดอินสแตนซ์ต่าง ๆ ที่มีให้คลิกที่นี่ สำหรับวัตถุประสงค์ของคู่มือนี้ฉันเลือกขนาดที่เล็กที่สุด / ราคาถูกที่สุดเท่าที่จะทำได้ในกรณีนี้คือ "DS1_V2 มาตรฐาน" เพื่อลดค่าใช้จ่ายให้น้อยที่สุดเนื่องจากสิ่งนี้จะไม่ทำงานเป็นจำนวนมาก เลือกขนาดอินสแตนซ์ที่เหมาะสมที่สุดตามสิ่งที่คุณต้องการทดสอบ: สำคัญ:
: ถัดไปเลือกขนาดอินสแตนซ์ของคุณ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับขนาดอินสแตนซ์ต่าง ๆ ที่มีให้คลิกที่นี่ สำหรับวัตถุประสงค์ของคู่มือนี้ฉันเลือกขนาดที่เล็กที่สุด / ราคาถูกที่สุดเท่าที่จะทำได้ในกรณีนี้คือ "DS1_V2 มาตรฐาน" เพื่อลดค่าใช้จ่ายให้น้อยที่สุดเนื่องจากสิ่งนี้จะไม่ทำงานเป็นจำนวนมาก เลือกขนาดอินสแตนซ์ที่เหมาะสมที่สุดตามสิ่งที่คุณต้องการทดสอบ: สำคัญ: 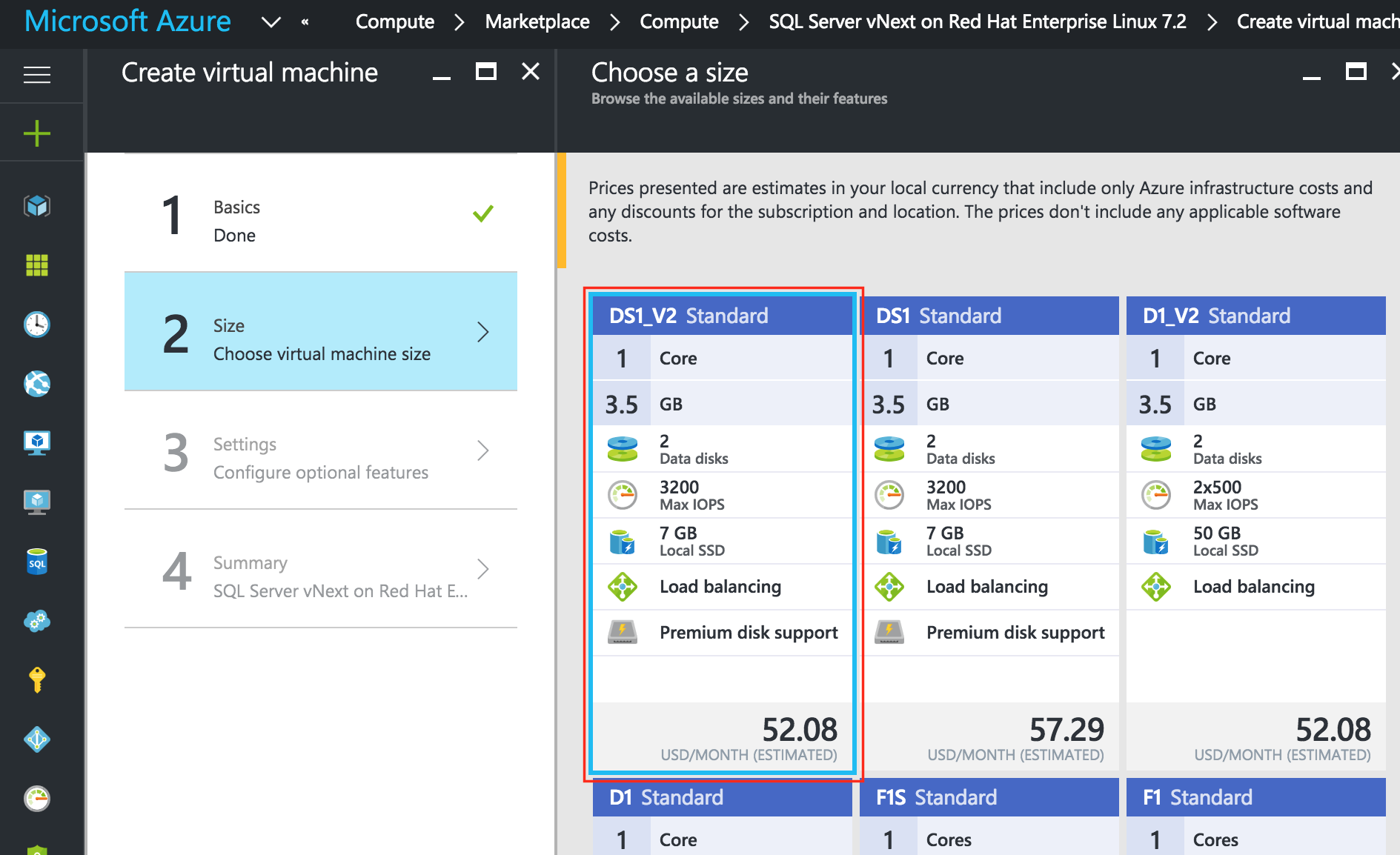 ตามค่าเริ่มต้น VM ของคุณจะไม่ถูกเพิ่มในชุดความพร้อมใช้งาน ในหน้าจอการตั้งค่าระหว่างตรวจสอบให้แน่ใจว่าคุณสร้างชุดความพร้อมใช้งานใหม่เราจะเรียกว่า "sql-Availability-set" Azure Resource Manager (ARM) อนุญาตให้คุณสร้างชุดความพร้อมใช้งานด้วย 3 Fault Domains ค่าเริ่มต้นที่นี่ใช้ได้: ในหน้า
ตามค่าเริ่มต้น VM ของคุณจะไม่ถูกเพิ่มในชุดความพร้อมใช้งาน ในหน้าจอการตั้งค่าระหว่างตรวจสอบให้แน่ใจว่าคุณสร้างชุดความพร้อมใช้งานใหม่เราจะเรียกว่า "sql-Availability-set" Azure Resource Manager (ARM) อนุญาตให้คุณสร้างชุดความพร้อมใช้งานด้วย 3 Fault Domains ค่าเริ่มต้นที่นี่ใช้ได้: ในหน้า จอถัดไปให้ตรวจสอบคุณสมบัติ VM ของคุณและคลิกตกลงเพื่อสร้าง VM เครื่องแรกของคุณ
จอถัดไปให้ตรวจสอบคุณสมบัติ VM ของคุณและคลิกตกลงเพื่อสร้าง VM เครื่องแรกของคุณ
สร้าง VMs“ sql-linux2” และ“ sql -itness”
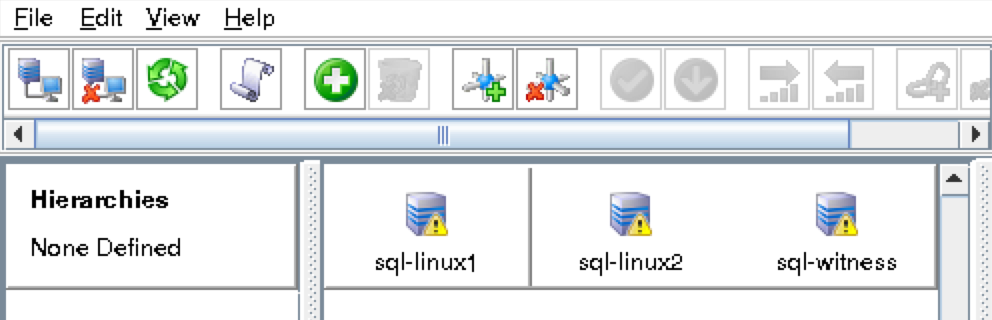
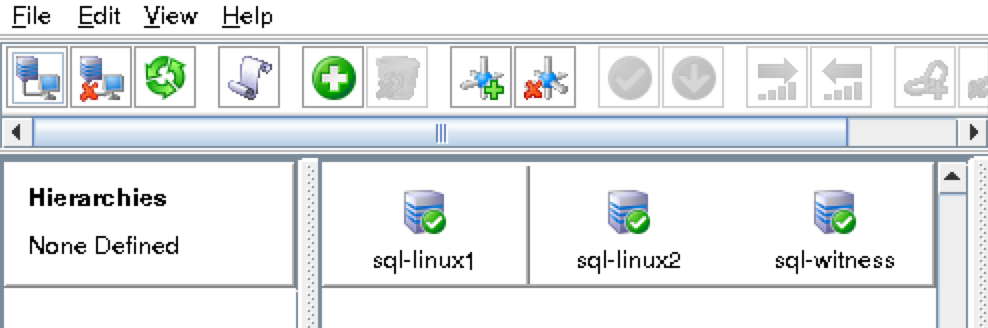
ทำซ้ำขั้นตอนด้านบนสองครั้งเพื่อสร้าง VM เพิ่มเติมอีกสองรายการ ข้อแตกต่างเพียงอย่างเดียวที่นี่คือคุณจะเพิ่ม VM เหล่านี้ไปยังชุดความพร้อมใช้งาน (“ sql-Availability-set”) ที่เราเพิ่งสร้างขึ้น อาจใช้เวลาสักครู่สำหรับการเตรียม VM 3 ของคุณ เมื่อเสร็จแล้วคุณจะเห็น VM ของคุณ (sql-linux1, sql-linux2 และ sql -itness) อยู่ในรายการบนหน้าจอ Virtual Machines ภายใน Azure Portal ของคุณ
ตั้งค่า VM Static IP Addresses
VMs จะถูกตั้งค่าด้วยที่อยู่ IP ต่อไปนี้:
- sql-linux1: 10.0.0.7
- sql-linux2: 10.0.0.8
- sql -itness: 10.0.0.9
ทำซ้ำขั้นตอนนี้สำหรับแต่ละ VM เลือก VM ของคุณและแก้ไขการเชื่อมต่อเครือ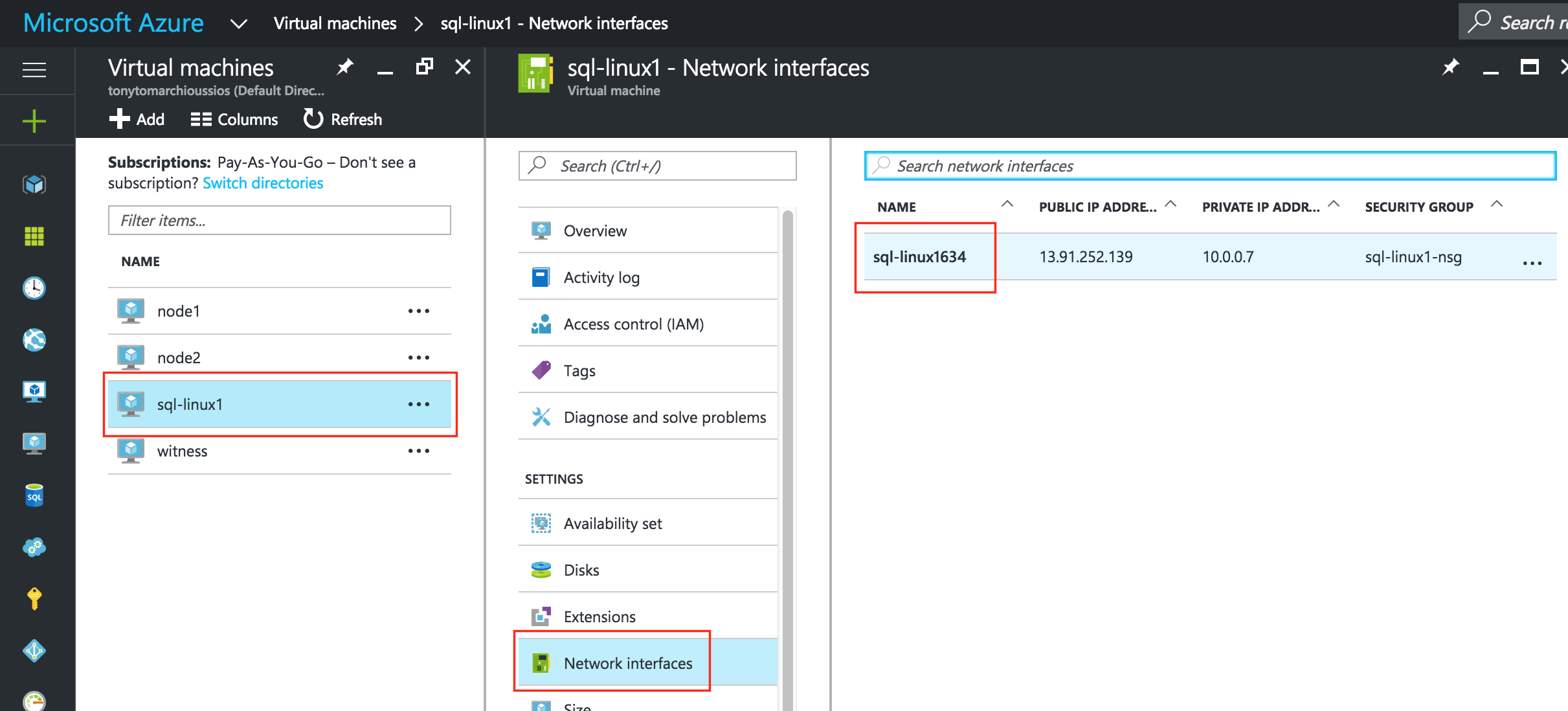 ข่ายเลือกอินเทอร์เฟซเครือข่ายที่เกี่ยวข้องกับ VM และแก้ไขการกำหนดค่า IP เลือก“ คงที่” และระบุที่อยู่ IP ที่ต้องการ:
ข่ายเลือกอินเทอร์เฟซเครือข่ายที่เกี่ยวข้องกับ VM และแก้ไขการกำหนดค่า IP เลือก“ คงที่” และระบุที่อยู่ IP ที่ต้องการ: 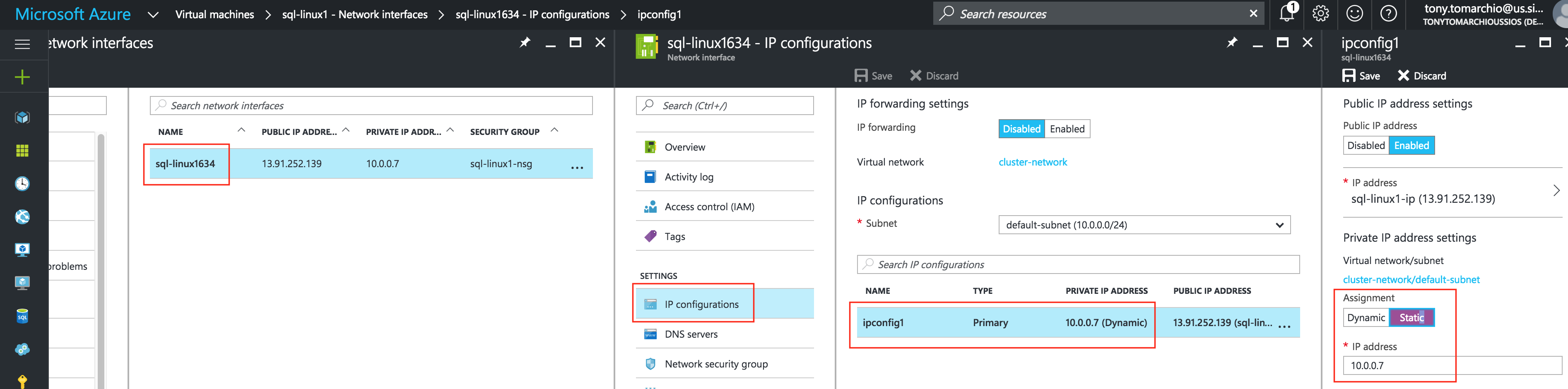
เพิ่มดิสก์ข้อมูลลงในโหนดคลัสเตอร์
ต่อไปเราจะต้องเพิ่มดิสก์พิเศษลงในโหนดคลัสเตอร์ของเรา (“ sql-linux1” และ“ sql-linux2”) ดิสก์นี้จะเก็บฐานข้อมูล SQL ของเราและจะถูกจำลองแบบในภายหลังระหว่างโหนด หมายเหตุ: คุณไม่จำเป็นต้องเพิ่มดิสก์เพิ่มเติมในโหนด“ sql -itness” เฉพาะ“ sql-linux1” และ“ sql-linux2” แก้ไข VM ของคุณเลือกดิสก์แล้วแนบดิสก์ใหม่ เลือกประเภทดิสก์ (Standard หรือ Premium SSD) และขนาดตามภาระงานของคุณ ที่นี่ฉันสร้างดิสก์ 10GB Standard บนโหนดคลัสเตอร์ทั้งสองของฉัน เท่าที่การแคชโฮสต์ดำเนินต่อไปการแคช“ ไม่มี” หรือ“ อ่านอย่างเดียว” ก็ถือว่าใช้ได้ ฉันไม่แนะนำให้ใช้“ อ่าน / เขียน” เนื่องจากมีโอกาสที่ข้อมูลจะสูญหาย: 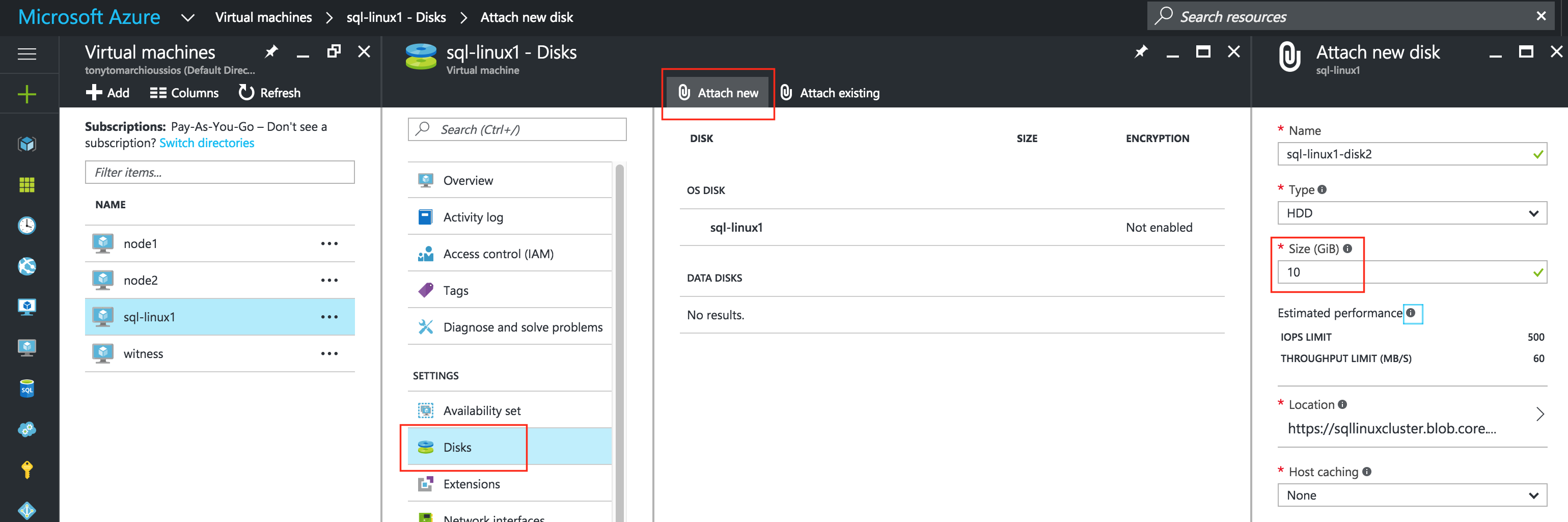
สร้างกฎความปลอดภัยขาเข้าเพื่ออนุญาตการเข้าถึง VNC
หาก VM ของคุณเป็นส่วนหนึ่งของกลุ่มความปลอดภัยเครือข่าย (NSG) ซึ่งโดยค่าเริ่มต้นเป็นไปได้ว่าหากคุณไม่ได้ปิดใช้งานในระหว่างการสร้าง VM จะมีเพียงพอร์ตเดียวที่เปิดใน“ ไฟร์วอลล์ Azure” คือ SSH (พอร์ต 22) ต่อมาในคำแนะนำฉันจะใช้ VNC เพื่อเข้าถึงเดสก์ท็อปของ“ sql-linux1” และกำหนดค่าคลัสเตอร์โดยใช้ GUI สร้างกฎความปลอดภัยขาเข้าเพื่อเปิดการเข้าถึง VNC ในคู่มือนี้มีการใช้พอร์ต 5902 ปรับสิ่งนี้ตามการกำหนดค่า VNC ของคุณ เครื่องเสมือน -> (เลือก sql-linux1) -> อินเตอร์เฟสเครือข่าย -> (เลือก NIC) -> กลุ่มความปลอดภัยเครือข่าย -> (เลือก NSG) -> กฎความปลอดภัยขาเข้า -> เพิ่ม 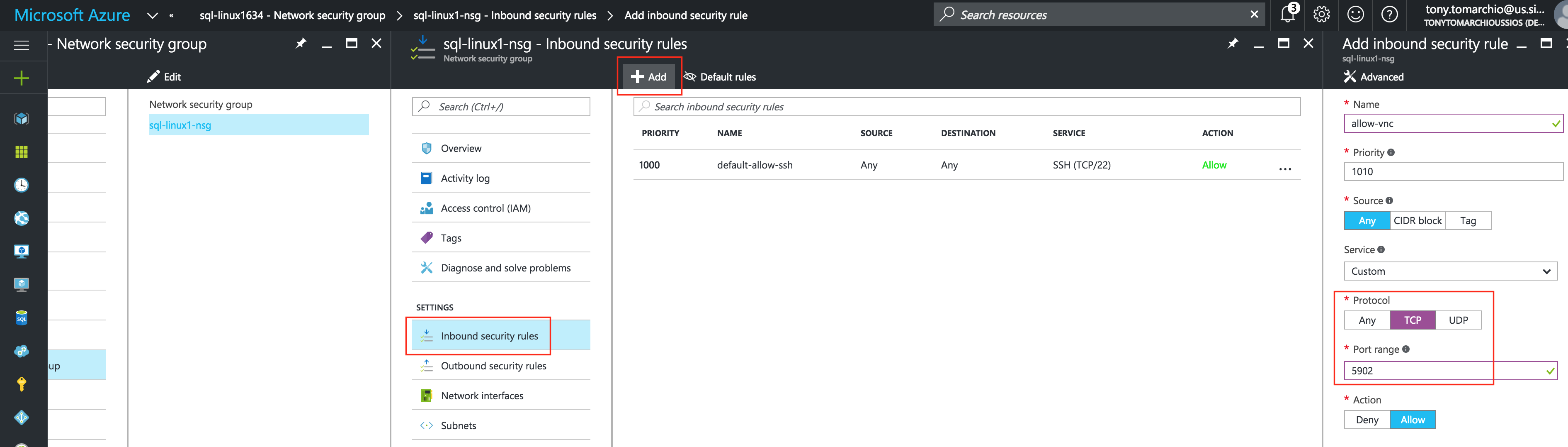
การกำหนดค่า Linux OS
ที่นี่คือที่ที่เราจะออกจาก Azure Portal สักครู่และทำให้มือของเราสกปรกในบรรทัดคำสั่งซึ่งในฐานะผู้ดูแลระบบ Linux ที่คุณควรใช้ในตอนนี้ คุณไม่ได้รับรหัสผ่านรูทแก่ Linux VM ของคุณใน Azure ดังนั้นเมื่อคุณลงชื่อเข้าใช้ในฐานะผู้ใช้ที่ระบุระหว่างการสร้าง VM ให้ใช้คำสั่ง“ sudo” เพื่อรับสิทธิ์รูต:
$ sudo su -
แก้ไข / etc / hosts
นอกจากว่าคุณมีการตั้งค่าเซิร์ฟเวอร์ DNS อยู่แล้วคุณจะต้องการสร้างรายการไฟล์โฮสต์บนเซิร์ฟเวอร์ทั้ง 3 แห่งเพื่อให้พวกเขาสามารถแก้ไขซึ่งกันและกันได้อย่างถูกต้องด้วยชื่อเพิ่มบรรทัดต่อไปนี้ที่ท้ายไฟล์ / etc / hosts
10.0.0.7 sql-linux1 10.0.0.8 sql-linux2 10.0.0.9 ตารางพยาน 10.0.0.199 sql-vip
ปิดการใช้งาน SELinux
แก้ไข / etc / sysconfig / linux และตั้งค่า“ SELINUX = ปิดใช้งาน”:
# vi / etc / sysconfig / selinux # ไฟล์นี้ควบคุมสถานะของ SELinux บนระบบ # SELINUX = สามารถใช้หนึ่งในสามค่าต่อไปนี้: # enforcing - บังคับใช้นโยบายความปลอดภัยของ SELinux # permissive - SELinux พิมพ์คำเตือนแทนที่จะบังคับใช้ # disabled - ไม่มีการโหลดนโยบาย SELinux SELINUX = คนพิการ # SELINUXTYPE = สามารถรับหนึ่งในสองค่าต่อไปนี้: # เป้าหมาย - กระบวนการเป้าหมายได้รับการคุ้มครอง # mls - การป้องกันความปลอดภัยหลายระดับ SELINUXTYPE = การกำหนดเป้าหมาย
กำหนดค่า iptables เพื่อให้คลัสเตอร์ IP เสมือนทำงานได้
ในการรับการเชื่อมต่อกับ IP เสมือนของคลัสเตอร์ให้ทำงานและตรวจสอบทรัพยากร IP กฎ iptables บางอย่างจำเป็นต้องติดตั้ง หมายเหตุ: 10.0.0.199 เป็น IP เสมือนจริงที่เราจะใช้ในคลัสเตอร์ของเราและ 1433 เป็นพอร์ตเริ่มต้นที่ใช้ SQL Server ของฉัน หมายเหตุ: RHEL7 เปลี่ยนไฟร์วอลล์เริ่มต้นเป็น FirewallD แทน iptables ยังไม่ได้ใช้เวลากับ firewalld ดังนั้นในตอนนี้คู่มือนี้จะปิดการใช้งาน firewalld และใช้ iptables แทน คุณจะต้องติดตั้งแพคเกจ“ iptables-services” เพื่อให้คำสั่งบริการและ chkconfig ด้านล่างใช้งานได้
# systemctl หยุดการไฟร์วอลล์ # systemctl ปิดใช้งานไฟร์วอลล์
บน sql-linux1 (10.0.0.7) ให้รันคำสั่งต่อไปนี้:
# yum ติดตั้ง iptables-services # iptables - ล้างข้อมูล # iptables -t nat -A การเตรียมความพร้อม -p tcp - พอร์ต 1433 -j DNAT - ไปยังปลายทาง 10.0.0.199:1433 # iptables -t nat -A การเตรียมความพร้อม -p tcp - พอร์ต 1434 -j DNAT - ไปยังปลายทาง 10.0.0.199:1434 # iptables -t nat -A การนำเสนอ -p icmp -s 10.0.0.199 -j SNAT - ไปยังแหล่ง 10.0.0.7 # บริการ iptables บันทึก # chkconfig iptables เปิดอยู่
บน sql-linux2 (10.0.0.8) ให้รันคำสั่งต่อไปนี้:
# yum ติดตั้ง iptables-services # iptables - ล้างข้อมูล # iptables -t nat -A การเตรียมความพร้อม -p tcp - พอร์ต 1433 -j DNAT - ไปยังปลายทาง 10.0.0.199:1433 # iptables -t nat -A การเตรียมความพร้อม -p tcp - พอร์ต 1434 -j DNAT - ไปยังปลายทาง 10.0.0.199:1434 # iptables -t nat -A POSTROUTING -p icmp -s 10.0.0.199 -j SNAT - ไปยังซอร์ส 10.0.0.8 # บริการ iptables บันทึก # chkconfig iptables เปิดอยู่
ติดตั้งและกำหนดค่า VNC (และแพ็คเกจที่เกี่ยวข้อง)
เพื่อเข้าถึง GUI ของเซิร์ฟเวอร์ linux ของเราและเพื่อติดตั้งและกำหนดค่าคลัสเตอร์ของเราในภายหลังติดตั้งเซิร์ฟเวอร์ VNC รวมถึงแพ็คเกจอื่น ๆ ที่จำเป็น (ซอฟต์แวร์คลัสเตอร์ต้องการ redhat-lsb และ patch rpms)
# yum ติดตั้ง tigervnc-server xterm รับการคลายซิปแพทช์ redhat-lsb
# vncpasswd
URL ต่อไปนี้เป็นแนวทางที่ดีในการเรียกใช้เซิร์ฟเวอร์ VNC บน RHEL 7 / CentOS 7: https://www.digitalocean.com/community/tutorials/how-to-install-and-configure-vnc-remote-access-for -the-gnome-desktop-on-centos-7 หมายเหตุ: การกำหนดค่าตัวอย่างนี้รัน VNC บนจอแสดงผล 2 (: 2, aka พอร์ต 5902) และเป็นรูท (ไม่ปลอดภัย) ปรับตาม!
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:2.service # vi /etc/systemd/system/vncserver@:2.service [บริการ] type = ฟอร์ก # ล้างไฟล์ที่มีอยู่ในสภาพแวดล้อม /tmp/.X11-unix ExecStartPre = / bin / sh -c '/ usr / bin / vncserver -kill% i> / dev / null 2> & 1 | | :' ExecStart = / sbin / runuser -l root -c "/ usr / bin / vncserver% i -geometry 1024x768" PIDFile = / ราก / .vnc / H%% i.pid ExecStop = / bin / sh -c '/ usr / bin / vncserver -kill% i> / dev / null 2> & 1 | | :' # systemctl daemon-reload # systemctl เปิดใช้งาน vncserver @: 2.service # vncserver: 2 -geometry 1024x768
รีบูตคลัสเตอร์โหนด
รีบูตโหนดคลัสเตอร์ของคุณเพื่อให้ SELinux ถูกปิดใช้งานและตรวจพบดิสก์ที่สองที่คุณเพิ่มก่อนหน้านี้
การแบ่งพาร์ติชันและฟอร์แมตดิสก์“ data”
ในขั้นตอนที่ 6 ของคู่มือนี้ (“ เพิ่มดิสก์ข้อมูลไปยังโหนดคลัสเตอร์”) เราทำแค่นั้น…. เพิ่มดิสก์พิเศษให้กับแต่ละโหนดคลัสเตอร์เพื่อเก็บข้อมูลแอปพลิเคชันที่เราจะปกป้อง ในกรณีนี้มันเป็นฐานข้อมูล MySQL ใน Azure IaaS, Linux Virtual Machines ใช้การจัดเรียงต่อไปนี้สำหรับดิสก์:
- / dev / sda – ดิสก์ระบบปฏิบัติการ
- / dev / sdb – ดิสก์ชั่วคราว
- / dev / sdc – ดิสก์ข้อมูลที่ 1
- / dev / sdd – ดิสก์ข้อมูลลำดับที่สอง
- …
- / dev / sdj – ดิสก์ข้อมูลที่ 8
ดิสก์ที่เราเพิ่มในขั้นตอนที่ 6 ของคู่มือนี้ควรปรากฏเป็น / dev / sdc คุณสามารถเรียกใช้คำสั่ง“ fdisk -l” เพื่อตรวจสอบ คุณจะเห็นว่า / dev / sda (OS) และ / dev / sdb (ชั่วคราว) มีพาร์ติชั่นดิสก์อยู่แล้วและกำลังใช้งานอยู่
# fdisk -l ดิสก์ / dev / sda: 31.5 GB, 31457280000 ไบต์, 61440000 ภาค หน่วย = ส่วนของ 1 * 512 = 512 ไบต์ ขนาดเซกเตอร์ (ตรรกะ / กายภาพ): 512 ไบต์ / 4096 ไบต์ ขนาด I / O (ต่ำสุด / เหมาะสมที่สุด): 4096 ไบต์ / 4096 ไบต์ ประเภทฉลากดิสก์: dos ตัวระบุดิสก์: 0x000c46d3 การบูตอุปกรณ์เริ่มต้น End Ids Id System / dev / sda1 * 2048 1026047 512000 83 Linux / dev / sda2 1026048 61439999 30206976 83 Linux ดิสก์ / dev / sdb: 7516 MB, 7516192768 ไบต์, 14680064 เซกเตอร์ หน่วย = ส่วนของ 1 * 512 = 512 ไบต์ ขนาดเซกเตอร์ (ตรรกะ / กายภาพ): 512 ไบต์ / 4096 ไบต์ ขนาด I / O (ต่ำสุด / เหมาะสมที่สุด): 4096 ไบต์ / 4096 ไบต์ ประเภทฉลากดิสก์: dos ตัวระบุดิสก์: 0x7cd70e11 การบูตอุปกรณ์เริ่มต้น End Ids Id System / dev / sdb1 128 14678015 7338944 83 Linux ดิสก์ / dev / sdc: 10.7 GB, 10737418240 ไบต์, 20971520 ภาค หน่วย = ส่วนของ 1 * 512 = 512 ไบต์ ขนาดเซกเตอร์ (ตรรกะ / กายภาพ): 512 ไบต์ / 4096 ไบต์ ขนาด I / O (ต่ำสุด / เหมาะสมที่สุด): 4096 ไบต์ / 4096 ไบต์
ที่นี่ฉันจะสร้างพาร์ติชัน (/ dev / sdc1) จัดรูปแบบและเมาต์ที่ตำแหน่งเริ่มต้นสำหรับ SQL ซึ่งเป็น / var / opt / mssql ทำตามขั้นตอนต่อไปนี้บนทั้ง“ sql-linux1” และ“ sql-linux2”:
# fdisk / dev / sdc
คำสั่ง (m สำหรับความช่วยเหลือ): n
การกระทำคำสั่ง
e ขยาย
p พาร์ติชันหลัก (1-4)
พี
หมายเลขพาร์ติชัน (1-4): 1
กระบอกแรก (1-1305 ค่าเริ่มต้น 1): <enter>
ใช้ค่าเริ่มต้น 1
ไส้กุญแจทรงกระบอกกระบอกสูบหรือขนาด {K, M, G} (1-1305, ค่าเริ่มต้น 1305): <enter>
ใช้ค่าเริ่มต้น 1305
คำสั่ง (m สำหรับความช่วยเหลือ): w
มีการเปลี่ยนแปลงตารางพาร์ติชัน!
การเรียก ioctl () เพื่ออ่านตารางพาร์ติชันอีกครั้ง
กำลังซิงค์ดิสก์
[root @ sql-linux1 ~] #
# mkfs.ext4 / dev / sdc1 # mkdir / var / opt / mssql # chmod 770 / var / opt / mssql
เมานต์ระบบไฟล์:
# mount / dev / sdc1 / var / opt / mssql
ติดตั้งและกำหนดค่าเซิร์ฟเวอร์ SQL
หากคุณเริ่มต้นด้วยระบบ linux ที่ใหม่คำแนะนำการติดตั้งแบบสมบูรณ์สามารถดูได้ที่นี่ หากคุณสร้าง VM ของคุณโดยใช้“ SQL Server vNext บน Red Hat Enterprise Linux 7.2” เทมเพลต Azure ดังที่ฉันได้ทำในคู่มือนี้แล้ว SQL Server จะถูกติดตั้งแล้ว สิ่งที่คุณต้องทำตอนนี้คือเรียกใช้สคริปต์การตั้งค่า:
# / opt / mssql / bin / sqlservr-setup การตั้งค่าเซิร์ฟเวอร์ Microsoft (R) SQL (R) คุณสามารถยกเลิกการตั้งค่าได้ตลอดเวลาโดยกด Ctrl-C เริ่มโปรแกรมนี้ ด้วยตัวเลือก - ช่วยสำหรับข้อมูลเกี่ยวกับการเรียกใช้ในแบบอัตโนมัติ โหมด. สามารถดาวน์โหลดข้อกำหนดสิทธิการใช้งานสำหรับผลิตภัณฑ์นี้ได้ http://go.microsoft.com/fwlink/?LinkId=746388 และพบ ใน /usr/share/doc/mssql-server/LICENSE.TXT คุณยอมรับข้อกำหนดสิทธิการใช้งานหรือไม่ ถ้าเป็นเช่นนั้นโปรดพิมพ์ "YES": ใช่ โปรดป้อนรหัสผ่านสำหรับบัญชีผู้ดูแลระบบ (SA): <ป้อนรหัสผ่านที่ต้องการ> โปรดยืนยันรหัสผ่านสำหรับบัญชีผู้ดูแลระบบ (SA): <ป้อนรหัสผ่านที่ต้องการ> ตั้งค่ารหัสผ่านบัญชีผู้ดูแลระบบ (SA) ... คุณต้องการเริ่มบริการ SQL Server ทันทีหรือไม่ [y / n]: y คุณต้องการเปิดใช้งาน SQL Server เพื่อเริ่มระบบหรือไม่ [y / n]: n คุณสามารถใช้ sqlservr-setup --enable-service เพื่อเปิดใช้งาน SQL Server เพื่อเริ่มต้น ตอนบูต การตั้งค่าเสร็จสมบูรณ์
ตรวจสอบว่าบริการกำลังทำงานอยู่:
# systemctl status mssql-server
หยุด SQL Server บนทั้งสองโหนด ซอฟต์แวร์คลัสเตอร์จะต้องรับผิดชอบในการเริ่มต้นใช้งานในภายหลัง:
# systemctl หยุด mssql-server # systemctl หยุด mssql-server-telemetry
ติดตั้งและกำหนดค่าคลัสเตอร์
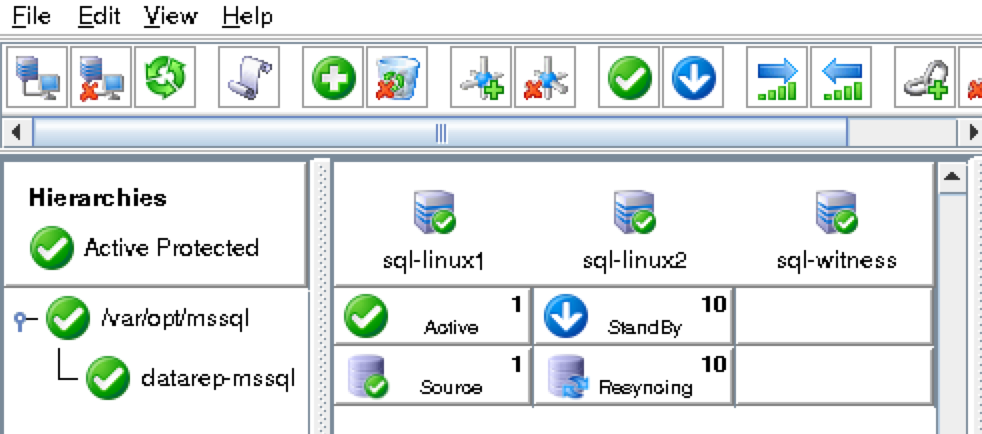
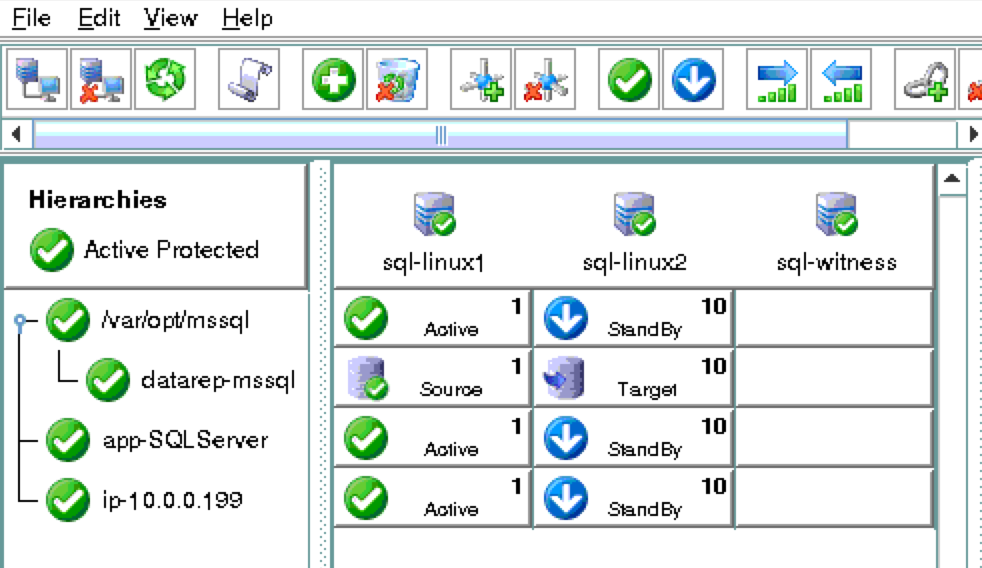
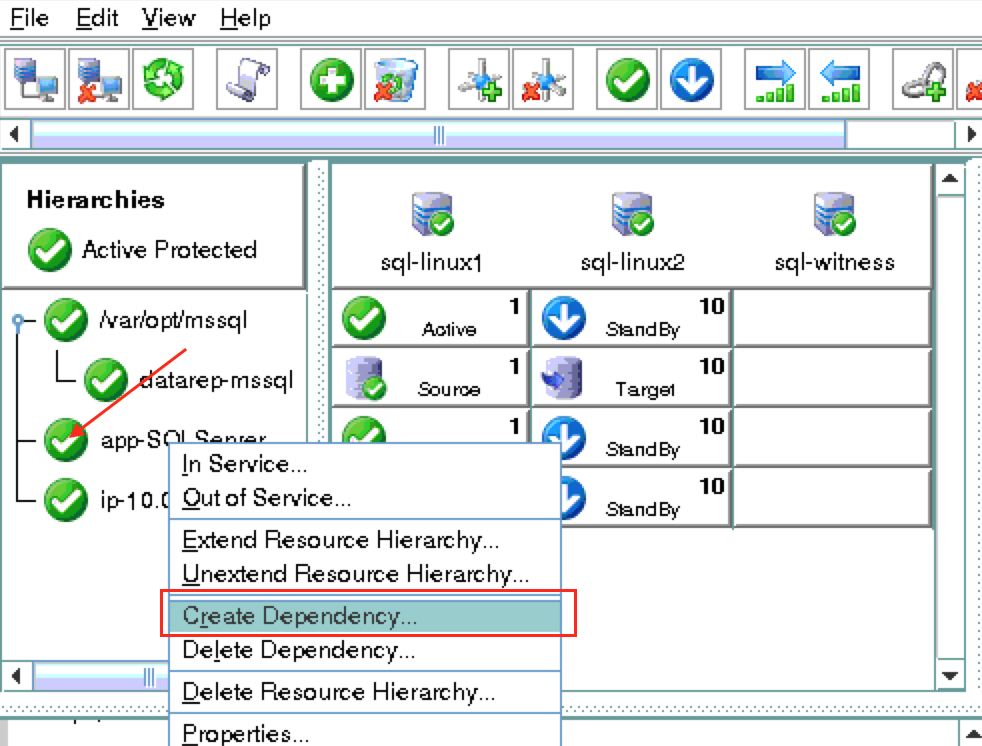
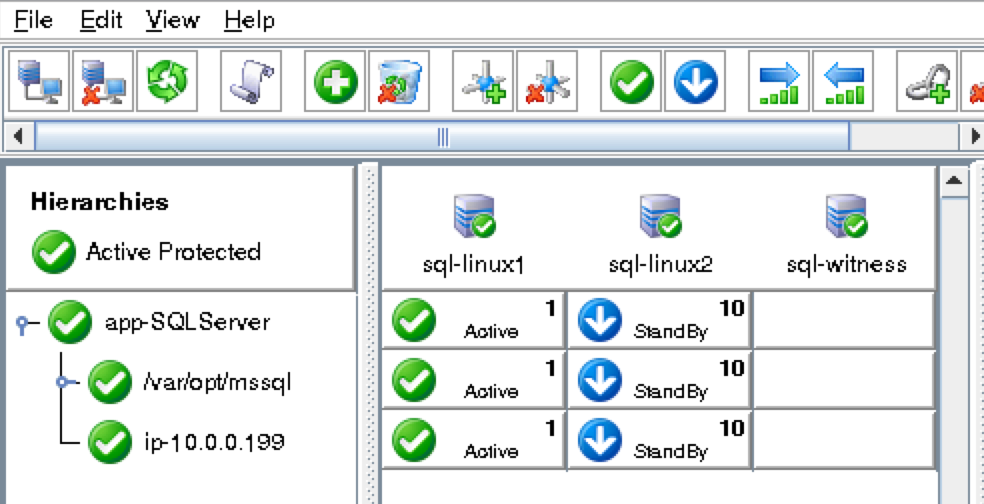
ณ จุดนี้เราพร้อมที่จะติดตั้งและกำหนดค่าคลัสเตอร์ของเรา SIOS Protection Suite สำหรับ Linux (aka SPS-Linux) จะใช้ในคู่มือนี้เป็นเทคโนโลยีการทำคลัสเตอร์ มันมีทั้งฟีเจอร์การคลัสเตอร์ล้มเหลวที่มีความพร้อมใช้งานสูง (LifeKeeper) รวมถึงการจำลองข้อมูลระดับบล็อกแบบเรียลไทม์ (DataKeeper) ในโซลูชันเดียวที่รวมเข้าด้วยกัน SPS-Linux ช่วยให้คุณสามารถปรับใช้คลัสเตอร์“ SANLess” หรือที่เรียกว่าคลัสเตอร์“ ไม่มีอะไรที่ใช้ร่วมกัน” ซึ่งหมายความว่าโหนดคลัสเตอร์ไม่มีที่เก็บข้อมูลใด ๆ ที่ใช้ร่วมกันเช่นเดียวกับ Azure VM
ติดตั้ง SIOS Protection Suite สำหรับ Linux
ทำตามขั้นตอนต่อไปนี้บน VM ทั้ง 3 (sql-linux1, sql-linux2, sql -itness): ดาวน์โหลดไฟล์อิมเมจการติดตั้ง SPS-Linux (sps.img) และขอรับใบอนุญาตทดลองใช้งานหรือซื้อใบอนุญาตถาวร ติดต่อ SIOS เพื่อรับข้อมูลเพิ่มเติม คุณจะวนลูปติดตั้งและรันสคริปต์“ ตั้งค่า” ด้านในในฐานะรูท (หรือ“ sudo su -” เป็นครั้งแรกเพื่อรับรูตเชลล์ถ้าคุณยังไม่ได้ทำ) ตัวอย่างเช่น:
# mkdir / tmp / install # mount -o loop sps.img / tmp / install # cd / tmp / install # ./ติดตั้ง
ระหว่างสคริปต์การติดตั้งคุณจะได้รับแจ้งให้ตอบคำถามจำนวนหนึ่ง คุณจะกด Enter บนเกือบทุกหน้าจอเพื่อยอมรับค่าเริ่มต้น สังเกตข้อยกเว้นต่อไปนี้:
- บนหน้าจอชื่อ“ High Availability NFS” คุณอาจเลือก“ n” เนื่องจากเราจะไม่สร้างเซิร์ฟเวอร์ NFS ที่มีความพร้อมใช้งานสูง
- ในตอนท้ายของสคริปต์การตั้งค่าคุณสามารถเลือกที่จะติดตั้งรหัสสัญญาอนุญาตรุ่นทดลองใช้ทันทีหรือใหม่กว่า เราจะติดตั้งรหัสลิขสิทธิ์ในภายหลังเพื่อให้คุณสามารถเลือก“ n” ได้อย่างปลอดภัยในจุดนี้
- ในหน้าจอสุดท้ายของ“ การตั้งค่า” เลือก ARKs (ชุดกู้คืนแอพพลิเคชั่นเช่น "ตัวแทนตัวแทน") ที่คุณต้องการติดตั้งจากรายการที่แสดงบนหน้าจอ
- ARK จำเป็นต้องใช้กับ "sql-linux1" และ "sql-linux2" เท่านั้น คุณไม่จำเป็นต้องติดตั้งบน“ sql -itness”
- นำทางรายการด้วยลูกศรขึ้น / ลงและกด SPACEBAR เพื่อเลือกรายการต่อไปนี้:
- lkDR – DataKeeper สำหรับ Linux
- ซึ่งจะส่งผลให้มีการติดตั้ง RPM เพิ่มเติมต่อไปนี้ใน“ sql-linux1” และ“ sql-linux2”:
- Steeleye-lkDR-9.0.2-6513.noarch.rpm
ติดตั้งแพ็คเกจ Witness / Quorum
แพคเกจการสนับสนุน Quorum / Witness Server สำหรับ LifeKeeper (steeleye-lkQWK) รวมกับกระบวนการ failover ที่มีอยู่ของแกน LifeKeeper ช่วยให้การล้มเหลวของระบบเกิดขึ้นพร้อมความมั่นใจในสถานการณ์ที่เครือข่ายล้มเหลวทั้งหมด สิ่งนี้มีประสิทธิภาพหมายถึงการล้มเหลวสามารถทำได้ในขณะที่ลดความเสี่ยงของสถานการณ์ "สมองแตก" อย่างมาก ติดตั้ง Witness / Quorum rpm บนทั้ง 3 โหนด (sql-linux1, sql-linux2, sql -itness):
# cd / tmp / install / quorum # rpm -Uvh steeleye-lkQWK-9.0.2-6513.noarch.rpm