Major Cloud Outage ส่งผลกระทบต่อ Google Compute Engine – คุณเตรียมไว้หรือยัง
Google รายงาน "ปัญหา" ครั้งแรกเมื่อวันที่ 2 มิถุนายน 2019 เวลา 12:25 PDT ตามที่พบเห็นได้ทั่วไปในภัยพิบัติประเภทใดรายงานของไฟดับนี้ปรากฏขึ้นครั้งแรกบนโซเชียลมีเดีย โซเชียลมีเดียดูเหมือนจะเป็นสถานที่ที่น่าเชื่อถือที่สุดในการรับข้อมูลทุกประเภทตั้งแต่เกิดภัยพิบัติตอนนี้
บริการหลายอย่างที่ต้องพึ่งพา Google Compute Engine ได้รับผลกระทบ ฉันมีลูกวัยรุ่นสามคนที่บ้าน มีบางอย่างเกิดขึ้นเมื่อเด็กทั้งสามคนโผล่ออกมาจากถ้ำอาคานอนในเวลาเดียวกันพร้อมกับดูใบหน้าที่เป็นกังวล Snapchat, Youtube และ Discord ล้วน แต่ออฟไลน์! พวกเขาต้องคิดว่านี่เป็นสัญญาณแรกของการเปิดเผย ฉันให้ความมั่นใจกับพวกเขาว่านี่ไม่ใช่จุดเริ่มต้นของยุคมืดใหม่ และพวกเขาควรออกไปข้างนอกเพื่อทำงานที่บ้าน นั่นทำให้พวกเขากลัวกลับสู่ความเป็นจริงและพวกเขาก็รีบออกไปหาสิ่งอื่นเพื่อใช้เวลาของพวกเขา ทั้งหมดล้อเล่นกันมีการบริการจำนวนมากถูกรายงานว่าเป็นลงหรือมีให้เฉพาะในบางพื้นที่ ฝุ่นยังคงตั้งอยู่บนสาเหตุความกว้างและขอบเขตของไฟดับ แต่ดูเหมือนว่าการหยุดทำงานนั้นค่อนข้างสำคัญในด้านขนาดและขอบเขตซึ่งส่งผลกระทบต่อลูกค้าและบริการจำนวนมากรวมถึง Gmail และบริการ G-Suite อื่น ๆ Vimeo และอีกมากมาย
ในขณะที่เรากำลังรอการวิเคราะห์สาเหตุอย่างเป็นทางการเกี่ยวกับการหยุดทำงานของ Google Compute Engine ล่าสุดนี้ Google รายงาน“ ความแออัดของเครือข่ายในระดับสูงในภาคตะวันออกของสหรัฐอเมริกา” ทำให้เกิดการหยุดทำงาน เราจะต้องรอดูสิ่งที่พวกเขาระบุว่าก่อให้เกิดปัญหาเครือข่าย มันเป็นข้อผิดพลาดของมนุษย์การโจมตีทางไซเบอร์ความล้มเหลวของฮาร์ดแวร์หรืออย่างอื่นหรือไม่?
คุณเตรียมพร้อมสำหรับการหยุดทำงานของคลาวด์นี้หรือไม่?
ฉันเขียนในช่วงที่ระบบคลาวด์หยุดทำงาน หากคุณกำลังใช้งานปริมาณงานทางธุรกิจที่สำคัญในระบบคลาวด์ไม่ว่าจะเป็นผู้ให้บริการคลาวด์หรือไม่ก็ตามคุณจะต้องวางแผนสำหรับการหยุดทำงานที่แน่นอน การหยุดทำงานของ Azure หลายวันเมื่อวันที่ 4 กันยายน 2018 นั้นเกี่ยวข้องกับความล้มเหลวของระบบ HVAC สำรองที่จะเตะในช่วงที่เกิดไฟกระชากที่เกี่ยวข้องกับพายุไฟฟ้า ในขณะที่ความล้มเหลวเป็นเพียงภายในดาต้าเซ็นเตอร์เดียว แต่การหยุดทำงานทำให้เกิดบริการหลายอย่างที่ต้องพึ่งพาดาต้าเซ็นเตอร์เดี่ยวนี้ สิ่งนี้ทำให้ดาต้าเซ็นเตอร์เป็นเพียงจุดเดียวของความล้มเหลว
มีแผนกู้คืนภัยพิบัติทางเสียง
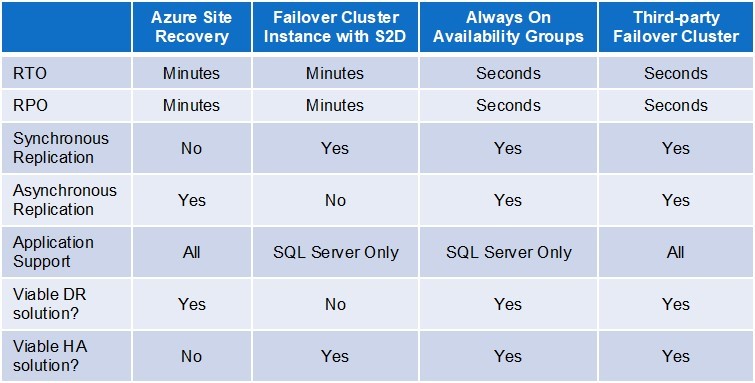
ใช้ประโยชน์จากโครงสร้างพื้นฐานของคลาวด์ลดความเสี่ยงด้วยการจำลองข้อมูลที่สำคัญอย่างต่อเนื่องระหว่างโซนความพร้อมใช้งานภูมิภาคหรือแม้แต่ผู้ให้บริการคลาวด์ นอกเหนือจากการปกป้องข้อมูลแล้วการมีกระบวนการในการกู้คืนแอปพลิเคชันที่สำคัญทางธุรกิจอย่างรวดเร็วเป็นส่วนสำคัญของแผนการกู้คืนความเสียหายใด ๆ มีตัวเลือกการจำลองแบบและการกู้คืนที่หลากหลาย ซึ่งรวมถึงบริการที่จัดทำโดยผู้จำหน่ายคลาวด์เองเช่น Azure Site Recovery สำหรับโซลูชันเฉพาะแอปพลิเคชันเช่น SQL Server Always On Availability Group ไปยังโซลูชันของบุคคลที่สามเช่น SIOS DataKeeper ที่ปกป้องแอปพลิเคชันหลากหลาย การมีกลยุทธ์การกู้คืนความเสียหายที่ขึ้นอยู่กับผู้ให้บริการคลาวด์ทั้งหมดทำให้คุณไวต่อสถานการณ์ที่อาจส่งผลกระทบหลายภูมิภาคภายในคลาวด์เดียว ภัยพิบัติหลายดาต้าเซ็นเตอร์หรือหลายภูมิภาคไม่น่าจะเกิดขึ้น อย่างไรก็ตามอย่างที่เราเห็นเมื่อไม่นานมานี้และการล่มสลายของ Azure เมื่อฤดูใบไม้ร่วงที่ผ่านมาแม้ว่าความล้มเหลวจะเกิดขึ้นภายในดาต้าเซ็นเตอร์เดียวผลกระทบก็สามารถเข้าถึงได้กว้างในศูนย์ข้อมูลหลายแห่งหรือภูมิภาคภายในคลาวด์ ในการลดความเสี่ยงให้พิจารณาสถานการณ์สมมติหลายคลาวด์หรือไฮบริดคลาวด์ซึ่งไซต์การกู้คืนความเสียหายอยู่นอกแพลตฟอร์มคลาวด์หลักของคุณ คลาวด์นั้นไวต่อการหยุดชะงักเช่นเดียวกับดาต้าเซ็นเตอร์ของคุณ คุณต้องทำตามขั้นตอนเพื่อเตรียมการสำหรับภัยพิบัติ ฉันขอแนะนำให้คุณเริ่มต้นด้วยการดูแอพที่สำคัญที่สุดทางธุรกิจของคุณก่อน คุณจะทำอย่างไรถ้าพวกเขาออฟไลน์และพอร์ทัลคลาวด์ในการจัดการพวกเขายังไม่สามารถใช้ได้ คุณสามารถกู้คืนได้หรือไม่ คุณจะบรรลุวัตถุประสงค์ RTO และ RPO ของคุณหรือไม่ มิฉะนั้นอาจถึงเวลาที่ต้องประเมินกลยุทธ์การกู้คืนความเสียหาย
“ การไม่เตรียมตัวคุณกำลังเตรียมตัวล้มเหลว” – เบนจามินแฟรงคลิน