| พฤษภาคม 9, 2019 |
การสัมมนาผ่านเว็บ: การทำคลัสเตอร์ 101: Windows Server 10 แสดงตัวอย่างความพร้อมใช้งานสูง |
| พฤษภาคม 8, 2019 |
การสัมมนาผ่านเว็บ: ทำความเข้าใจกับตัวเลือกการกู้คืนความเสียหายสำหรับ SQL Server
การสัมมนาผ่านเว็บ: ทำความเข้าใจกับตัวเลือกการกู้คืนความเสียหายสำหรับ SQL Serverเรียนรู้ความแตกต่างระหว่างการกู้คืนภัยพิบัติความต่อเนื่องทางธุรกิจและความพร้อมใช้งานสูงและสาเหตุที่แต่ละองค์ประกอบสำคัญสำหรับความอยู่รอดของธุรกิจ ใช่ – คุณต้องมีแผนกู้คืนความเสียหาย! ข้อมูล SQL Server ของคุณขึ้นอยู่กับมัน ในการสัมมนาทางเว็บนี้ Dave Bermingham, Microsoft Datacenter และ Cloud MVP อธิบายถึงความแตกต่างระหว่างการกู้คืนภัยพิบัติความต่อเนื่องทางธุรกิจและความพร้อมใช้งานสูงและสาเหตุที่แต่ละองค์ประกอบสำคัญสำหรับความอยู่รอดของธุรกิจ ค้นพบองค์ประกอบสำคัญที่ควรรวมอยู่ในแผนกู้คืนภัยพิบัติ / ความต่อเนื่องทางธุรกิจของคุณและสำรวจเครื่องมือบางอย่างที่มีอยู่เพื่อช่วยให้บรรลุเป้าหมายในการกู้คืนภัยพิบัติ / เป้าหมายความต่อเนื่องทางธุรกิจของคุณ มีความกังวลเกี่ยวกับการสิ้นสุดการสนับสนุนสำหรับ SQL Server 2008 หรือไม่ ดูว่า SIOS ช่วยให้ลูกค้าเตรียมพร้อมสำหรับ SQL Server 2008 EOS อย่างไร ลงทะเบียนเพื่อรับการสัมมนาทางเว็บ SIOS OnDemand เพื่อทำความเข้าใจกับตัวเลือกการกู้คืนความเสียหายสำหรับ SQL Server |
เอกสารไวท์เปเปอร์: 10 วิธีในการประหยัด – AlwaysOn vs. การทำคลัสเตอร์ล้มเหลว |
|
ข้อควรพิจารณาในการเก็บข้อมูลสำหรับการเรียกใช้ SQL Server ใน Azureข้อควรพิจารณาในการเก็บข้อมูลสำหรับการเรียกใช้ SQL Server ใน Azureการปรับใช้ SQL Server ใน Azure หรือแพลตฟอร์มคลาวด์ใด ๆ แทนที่จะเป็นเพียงแค่การจัดสรรพื้นที่เก็บข้อมูลเช่นเดียวกับที่คุณทำสำหรับการปรับใช้งานในสถานที่ของคุณเป็นเวลาหลายปีการพิจารณาพื้นที่เก็บข้อมูลใน Azure ไม่เหมือนกับที่เก็บข้อมูลที่คุณมีสิทธิ์เข้าถึงในสถานที่ "แนวทางปฏิบัติที่ดีที่สุด" แบบดั้งเดิมบางอย่างอาจทำให้คุณต้องเสียเงินเพิ่มและให้ประสิทธิภาพที่ดีที่สุด ถึงกระนั้นก็ตามในขณะที่ไม่ได้ให้สิทธิประโยชน์ใด ๆ แก่คุณ สิ่งที่ฉันกำลังจะพูดคุยส่วนใหญ่ยังอธิบายไว้ในแนวทางปฏิบัติสำหรับ Azure ในเครื่องเสมือนเซิร์ฟเวอร์ SQL ประเภทของดิสก์ฉันไม่ได้มาที่นี่เพื่อบอกคุณว่าคุณต้องใช้ UltraSSD, ที่เก็บข้อมูลพรีเมียมหรือดิสก์ประเภทอื่น คุณเพียงแค่ต้องระวังว่าคุณมีตัวเลือกและสิ่งที่ดิสก์แต่ละชนิดนำมาไว้ในตาราง แน่นอนเช่นเดียวกับสิ่งอื่นใดในคลาวด์คุณจะได้รับเงินมากขึ้นพลังยิ่งขึ้นความเร็วปริมาณงานและอื่น ๆ ที่มากขึ้น เคล็ดลับคือการค้นหาการกำหนดค่าที่เหมาะสมที่สุดที่เหมาะสมกับข้อควรพิจารณาในการจัดเก็บของคุณเพื่อให้คุณใช้จ่ายเพียงพอที่จะบรรลุผลลัพธ์ที่ต้องการ ขนาดมีความสำคัญเช่นเดียวกับหลายสิ่งในคลาวด์สเป็คบางอย่างเชื่อมติดกัน สำหรับเซิร์ฟเวอร์หากคุณต้องการ RAM เพิ่มคุณมักจะได้รับ CPU มากขึ้นแม้ว่าคุณจะไม่ต้องการ CPU มากขึ้น สำหรับการจัดเก็บข้อมูล IOPS ปริมาณงานและขนาดจะเชื่อมโยงกัน หากคุณต้องการ IOPS เพิ่มขึ้นคุณต้องมีดิสก์ที่ใหญ่กว่า หากคุณต้องการพื้นที่เพิ่มขึ้นคุณจะได้รับ IOPS เพิ่มขึ้นด้วย แน่นอนว่าคุณสามารถข้ามไปมาระหว่างคลาสหน่วยเก็บข้อมูลเพื่อหลีกเลี่ยงสิ่งนั้นได้ในระดับหนึ่ง แต่มันก็ยังคงเป็นความจริงที่ว่าถ้าคุณต้องการ IOPS มากขึ้นคุณจะมีพื้นที่มากขึ้นสำหรับประเภทหน่วยความจำประเภทต่าง ๆ ขนาดของอินสแตนซ์ของเครื่องเสมือนก็มีความสำคัญเช่นกัน ไม่ว่าคุณจะใช้การตั้งค่าการจัดเก็บแบบใดในที่สุดปริมาณงานโดยรวมจะถูก จำกัด ที่ขนาดใดก็ตามที่อนุญาต ดังนั้นอีกครั้งคุณอาจต้องจ่าย RAM และ CPU มากกว่าที่คุณต้องการเพียงเพื่อให้ได้ประสิทธิภาพการจัดเก็บที่คุณต้องการ ตรวจสอบให้แน่ใจว่าคุณเข้าใจขนาดอินสแตนซ์ของคุณที่สามารถรองรับได้ในแง่ของปริมาณ IOPS สูงสุดและเมกะบิตต่อวินาที หลายครั้งที่อินสแตนซ์ขนาดกลายเป็นคอขวดในปัญหาประสิทธิภาพการจัดเก็บข้อมูลที่รับรู้ใน Azure ใช้ Raid 0RAID 0 นั้นเป็นทางเลือกที่ 3 ของการจัดเก็บข้อมูล แม้ว่าจะให้การผสมผสานที่ดีที่สุดของประสิทธิภาพและการใช้ประโยชน์พื้นที่เก็บข้อมูลของตัวเลือก RAID ใด ๆ แต่ก็มีความเสี่ยงที่จะเกิดความล้มเหลวอย่างรุนแรง ชุดสตริปทั้งหมดล้มเหลวเมื่อเพียงดิสก์เดียวในชุด RAID 0 สตริปล้มเหลว ด้วยเหตุนี้ RAID 0 แบบดั้งเดิมจึงถูกใช้ในสถานการณ์ที่การสูญเสียข้อมูลเป็นที่ยอมรับและต้องการประสิทธิภาพสูง อย่างไรก็ตามในซอฟต์แวร์ Azure RAID 0 เป็นที่ต้องการและแนะนำให้ใช้ในหลาย ๆ สถานการณ์ เราจะไปด้วย RAID 0 ใน Azure ได้อย่างไร คำตอบนั้นง่าย แต่ละดิสก์ที่คุณนำเสนอให้กับอินสแตนซ์ของเครื่องเสมือน Azure มีความซ้ำซ้อนอยู่สามส่วนในแบ็กเอนด์ หมายความว่าคุณจะต้องมีความล้มเหลวหลายครั้งก่อนที่คุณจะสูญเสียชุดแถบ ด้วยการใช้ RAID 0 คุณสามารถรวมหลายดิสก์ได้ ประสิทธิภาพโดยรวมของชุดสตริปรวมจะเพิ่มขึ้น 100% สำหรับแต่ละดิสก์เพิ่มเติมที่คุณเพิ่มไปยังชุดสตริป ตัวอย่างเช่นคุณมีความต้องการ 10,000 IOPS คุณอาจคิดว่าคุณต้องการ UltraSSD เนื่องจาก Premium Storage สูงสุดถึง 7,500 IOPS ด้วย P50 อย่างไรก็ตามด้วยการใส่ P50 สองตัวใน RAID 0 ตอนนี้คุณมีศักยภาพที่จะบรรลุถึง 15,000 IOPS นั่นคือสมมติว่าคุณกำลังเรียกใช้ Standard_F16s_v2 หรือขนาดอินสแตนซ์ขนาดใหญ่ที่คล้ายกันซึ่งสนับสนุน IOPS จำนวนมาก ใน Windows 2012 และหลังจากนั้น RAID 0 สามารถทำได้โดยการสร้าง Simple Storage Space ใน Windows Server 2008 R2 คุณสามารถใช้ Dynamic Disks เพื่อสร้าง RAID 0 Striped Volume เพียงแค่คำเตือน หากคุณกำลังจะใช้พื้นที่เก็บข้อมูลภายในเครื่องและกำหนดค่ากลุ่มความพร้อมใช้งานหรือ SANless Failover Cluster Instance กับ DataKeeper วิธีที่ดีที่สุดคือกำหนดค่าที่เก็บข้อมูลของคุณก่อนสร้างคลัสเตอร์ เพียงเตือนความจำ คุณมีเวลาอีกประมาณสองเดือนในการย้ายอินสแตนซ์ SQL Server 2008 R2 ของคุณไปยัง Azure ลองดูโพสต์ของฉันเกี่ยวกับวิธีปรับใช้ SQL Server 2008 R2 FCI บน Azure เพื่อให้แน่ใจว่ามีความพร้อมใช้งานสูง ไม่ต้องแยกไฟล์บันทึกและข้อมูลตามปกติไฟล์บันทึกและข้อมูลจะอยู่ในดิสก์ที่มีอยู่จริง ไฟล์บันทึกมักจะมีกิจกรรมการเขียนจำนวนมากและไฟล์ข้อมูลมักจะมีกิจกรรมการอ่านมากกว่า ดังนั้นบางครั้งการจัดเก็บจะได้รับการปรับให้เหมาะสมตามลักษณะเหล่านั้น มันเป็นที่พึงปรารถนาที่จะเก็บไฟล์บันทึกและข้อมูลในดิสก์ที่แตกต่างกันเพื่อการกู้คืน หากคุณควรทำอย่างใดอย่างหนึ่งโดยใช้กลยุทธ์การสำรองข้อมูลที่เหมาะสมคุณสามารถกู้คืนฐานข้อมูลของคุณโดยไม่สูญเสียข้อมูล ด้วยที่จัดเก็บข้อมูลบนคลาวด์โอกาสที่จะสูญเสียเพียงโวลุ่มเดียวนั้นต่ำมาก ตอนนี้คุณกำลังคิดถึงข้อควรพิจารณาในการจัดเก็บ หากคุณสูญเสียที่เก็บข้อมูลเป็นไปได้ว่ามันอาจเป็นไปได้ที่คลัสเตอร์จัดเก็บข้อมูลทั้งหมดของคุณ ดังนั้นในขณะที่อาจรู้สึกถูกต้องที่จะใส่บันทึกลงใน E: บันทึกและข้อมูลใน F: data คุณกำลังก่อความเสียหายให้ตัวเองจริงๆ ตัวอย่างเช่นคุณจัดเตรียม P20 สำหรับบันทึกและ P20 สำหรับข้อมูล แต่ละเล่มจะมีขนาด 512 GiB และต่อยอดที่ 2,300 IOPS แค่คิดว่าคุณอาจไม่ต้องการขนาดไฟล์บันทึกทั้งหมด แต่มันอาจไม่ทำให้คุณมีพื้นที่มากพอที่จะเติบโตสำหรับไฟล์ข้อมูลของคุณ ในที่สุดจะต้องย้ายไปที่ P30 แพงกว่าเพียงเพื่อเพิ่มพื้นที่ มันจะดีกว่าหรือเปล่าที่จะรวมเอาสองวอลลุ่มเหล่านี้เข้าด้วยกันในปริมาณ 1 TB ขนาดใหญ่ที่รองรับ 4,600 IOPS ด้วยการทำเช่นนั้นทั้งไฟล์บันทึกและข้อมูลสามารถใช้ประโยชน์จาก IOPS ที่เพิ่มขึ้น และคุณเพียงเพิ่มประสิทธิภาพการใช้พื้นที่เก็บข้อมูลของคุณและลดต้นทุนการจัดเก็บข้อมูลบนคลาวด์ด้วยการย้ายการย้ายไปยังดิสก์ P30 สำหรับไฟล์ข้อมูลของคุณ เช่นเดียวกับที่เก็บไฟล์จริงและกลุ่มไฟล์ คิดถึงสิ่งที่คุณกำลังทำจริงๆ ไม่ว่าจะยังคงสมเหตุสมผลเมื่อคุณย้ายไปที่คลาวด์ สิ่งที่สมเหตุสมผลอาจเป็นเรื่องที่เข้าใจได้ง่ายในสิ่งที่คุณเคยทำในอดีต เมื่อมีข้อสงสัยให้ปฏิบัติตามกฎ KISS, Keep It Simple Stupid! ความสวยงามของคลาวด์คือคุณสามารถเพิ่มพื้นที่เก็บข้อมูลได้มากขึ้นเพิ่มขนาดอินสแตนซ์หรือทำทุกอย่างเพื่อเพิ่มประสิทธิภาพเทียบกับราคา จะทำอย่างไรกับ TempDBใช้ SSD ท้องถิ่นหรือที่รู้จักในชื่อไดรฟ์ D: ไดรฟ์ D จะเป็นตำแหน่งที่ดีที่สุดสำหรับ tempdb ของคุณ เนื่องจากเป็นไดรฟ์ในระบบข้อมูลจึงถูกพิจารณาว่าเป็น "ชั่วคราว" ความหมายอาจหายไปหากย้ายเซิร์ฟเวอร์รีบูตเครื่อง ฯลฯ ไม่เป็นไร. Tempdb จะถูกสร้างขึ้นใหม่ทุกครั้งที่ SQL เริ่มทำงาน SSD ท้องถิ่นจะเร็วและมีเวลาหน่วงต่ำ แต่เนื่องจากเป็นโลคัลการอ่านและเขียนจึงไม่ส่งผลต่อขีด จำกัด IOPS หน่วยเก็บโดยรวมของขนาดอินสแตนซ์ อย่างมีประสิทธิภาพมันฟรี IOPS! ทำไมไม่ใช้ประโยชน์จาก? หากคุณกำลังสร้าง FCless ของ SANless SQL Server ด้วย SIOS DataKeeper อย่าลืมสร้างไดรฟ์ข้อมูลทรัพยากรที่ไม่ใช่มิร์เรอร์ของไดรฟ์ D วิธีนี้คุณไม่จำเป็นต้องทำซ้ำ TempDB คะแนนติดกลายเป็นล้าสมัยโดยทั่วไป Mount Points จะใช้ในการกำหนดค่า FCI ของเซิร์ฟเวอร์ SQL เมื่อมีการติดตั้ง SQL Server หลายอินสแตนซ์บน Windows Cluster เดียวกัน สิ่งนี้ช่วยลดต้นทุนโดยรวมของสิทธิ์การใช้งาน SQL Server สามารถช่วยประหยัดค่าใช้จ่ายด้วยการผลักดันการใช้เซิร์ฟเวอร์ให้สูงขึ้น ดังที่เรากล่าวถึงในอดีตโดยทั่วไปอาจมีไดรฟ์ห้าตัวหรือมากกว่าที่เกี่ยวข้องกับ SQL Server แต่ละอินสแตนซ์ หากไดรฟ์แต่ละตัวเหล่านั้นต้องใช้ตัวอักษรไดรฟ์คุณจะใช้ตัวอักษรหมดในอินสแตนซ์ประมาณสามถึงสี่ตัว ดังนั้นแทนที่จะให้ตัวอักษรแต่ละไดรฟ์จุดเมาท์ถูกใช้เพื่อให้แต่ละอินสแตนซ์สามารถรับบริการด้วยตัวอักษรไดรฟ์เดียวไดรฟ์ราก ไดรฟ์รากมีจุดเมานท์ที่แมปไปยังดิสก์ทางกายภาพที่ไม่มีตัวอักษรของไดรฟ์ อย่างไรก็ตามตามที่เราได้กล่าวถึงข้างต้นแนวคิดของการใช้ดิสก์จำนวนมากแต่ละอันไม่ได้ทำให้เกิดความรู้สึกในคลาวด์ ดังนั้นจุดที่เมาท์จะล้าสมัยในก้อนเมฆ ให้สร้างแถบ RAID 0 แทนเราดังที่อธิบายไว้ แต่ละอินสแตนซ์ของคลัสเตอร์ SQL Server จะมีปริมาณของตัวเองที่ปรับให้เหมาะสมสำหรับพื้นที่ประสิทธิภาพและต้นทุน วิธีนี้จะช่วยแก้ปัญหาการไม่มีตัวอักษรไดรฟ์ นอกจากนี้ยังช่วยให้คุณใช้พื้นที่จัดเก็บและประสิทธิภาพได้ดีขึ้นในขณะที่ลดค่าใช้จ่ายในการจัดเก็บบนคลาวด์ของคุณ สรุปผลการวิจัยโพสต์นี้มีความหมายว่าเป็นจุดกระโดดไม่ใช่แนวทางที่ชัดเจน ประเด็นหลักของการโพสต์คือให้คุณคิดต่างกันเกี่ยวกับข้อควรพิจารณาเกี่ยวกับคลาวด์และสตอเรจเนื่องจากเกี่ยวข้องกับการใช้ SQL Server ใน Azure อย่าใช้สิ่งที่คุณทำในสถานที่และสร้างใหม่ในคลาวด์ ซึ่งจะส่งผลให้ประสิทธิภาพการทำงานที่ดีที่สุดและค่าจัดเก็บข้อมูลขนาดใหญ่กว่าที่จำเป็น ทำซ้ำโดยได้รับอนุญาตจาก Clusteringformeremortals.com |
|
| เมษายน 24, 2019 |
กำหนดค่าอินสแตนซ์ของคลัสเตอร์ล้มเหลว SQL Server 2008 R2 บน Windows Server 2008 R2 ใน Azureทีละขั้นตอน: วิธีการกำหนดค่าอินสแตนซ์ของคลัสเตอร์ล้มเหลว SQL Server 2008 R2 บน Windows Server 2008 R2 ใน AzureIntroในวันที่ 9 กรกฎาคม 2019 การสนับสนุนสำหรับ SQL Server 2008 และ 2008 R2 จะสิ้นสุดลง นั่นหมายถึงการสิ้นสุดการอัพเดตความปลอดภัยปกติ อย่างไรก็ตามหากคุณย้ายอินสแตนซ์ SQL Server เหล่านั้นไปยัง Azure Microsoft จะให้การปรับปรุงความปลอดภัยเสริมสามปีโดยไม่มีค่าใช้จ่ายเพิ่มเติม หากคุณกำลังเรียกใช้ SQL Server 2008/2008 R2 อยู่และคุณไม่สามารถอัปเดตเป็น SQL Server รุ่นใหม่กว่าก่อนวันที่ 9 กรกฎาคมคุณจะต้องใช้ประโยชน์จากข้อเสนอนี้แทนที่จะเสี่ยงกับความเสี่ยงที่จะเกิดช่องโหว่ด้านความปลอดภัยในอนาคต . อินสแตนซ์ที่ไม่ตรงกันของ SQL Server อาจนำไปสู่การสูญเสียข้อมูลการหยุดทำงานหรือการทำลายข้อมูลที่ร้ายแรง หนึ่งในความท้าทายที่คุณจะเผชิญเมื่อใช้งาน SQL Server 2008/2008 R2 ใน Azure คือสร้างความมั่นใจว่ามีความพร้อมใช้งานสูง ในสถานที่คุณอาจใช้งานอินสแตนซ์ SQL Server Failover Cluster (FCI) เพื่อความพร้อมใช้งานสูงหรืออาจเป็นไปได้ว่าคุณกำลังเรียกใช้ SQL Server ในเครื่องเสมือนและอาศัย VMware HA หรือคลัสเตอร์ Hyper-V เพื่อความพร้อมใช้งาน เมื่อย้ายไปยัง Azure จะไม่มีตัวเลือกใด ๆ การหยุดทำงานใน Azure เป็นไปได้จริงมากที่คุณต้องทำตามขั้นตอนเพื่อลด เพื่อลดความเป็นไปได้ของการหยุดทำงานและมีสิทธิ์ได้รับ SLA ของ Azure 99.95% หรือ 99.99% คุณต้องใช้ SIOS DataKeeper DataKeeper เอาชนะการขาดพื้นที่เก็บข้อมูลที่ใช้ร่วมกันของ Azure และช่วยให้คุณสามารถสร้าง SQL Server FCI ใน Azure ที่ใช้ประโยชน์พื้นที่เก็บข้อมูลที่เชื่อมต่อแบบโลคัลในแต่ละอินสแตนซ์ SIOS DataKeeper ไม่เพียง แต่รองรับ SQL Server 2008 R2 และ Windows Server 2008 R2 ตามที่ระบุไว้ในคู่มือนี้เท่านั้น แต่รองรับ Windows Server ทุกรุ่นตั้งแต่ 2008 R2 ถึง Windows Server 2019 และ SQL Server ทุกรุ่นตั้งแต่ SQL Server 2008 ถึง SQL Server 2019 . คู่มือนี้จะอธิบายถึงกระบวนการสร้าง SQL Server 2008 R2 Failover Cluster Instance (FCI) แบบสองโหนดใน Azure ที่ทำงานบน Windows Server 2008 R2 แม้ว่า SIOS DataKeeper ยังสนับสนุนกลุ่มที่ขยายโซนความพร้อมใช้งานหรือภูมิภาคคู่มือนี้จะถือว่าแต่ละโหนดอยู่ในภูมิภาค Azure เดียวกัน แต่เป็นโดเมนความผิดพลาดที่แตกต่างกัน SIOS DataKeeper จะถูกใช้แทนที่ที่เก็บข้อมูลที่ใช้ร่วมกันซึ่งปกติแล้วจะต้องใช้เพื่อสร้าง SQL Server 2008 R2 FCI สร้างอินสแตนซ์ของเซิร์ฟเวอร์ SQL แรกใน Azureคู่มือนี้จะใช้ประโยชน์จาก SQL Server 2008R2SP3 ในอิมเมจ Windows Server 2008R2 ที่เผยแพร่ใน Azure Marketplace 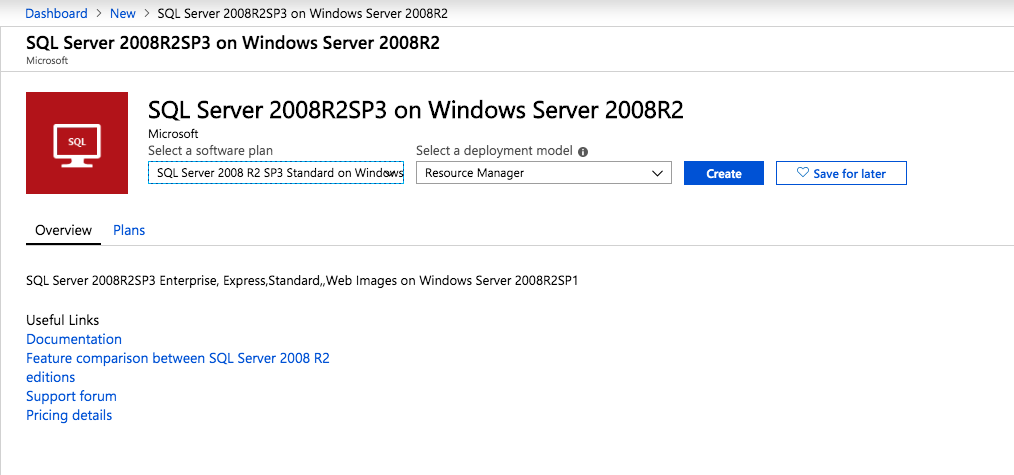 เมื่อคุณจัดเตรียมอินสแตนซ์แรกคุณจะต้องสร้างชุดความพร้อมใช้งานใหม่ ในระหว่างกระบวนการนี้โปรดเพิ่มจำนวนโดเมนความผิดเป็น 3 สิ่งนี้อนุญาตให้โหนดคลัสเตอร์สองโหนดและไฟล์ใช้ร่วมกันเป็นพยานให้แต่ละคนอยู่ใน Fault Domain ของตนเอง 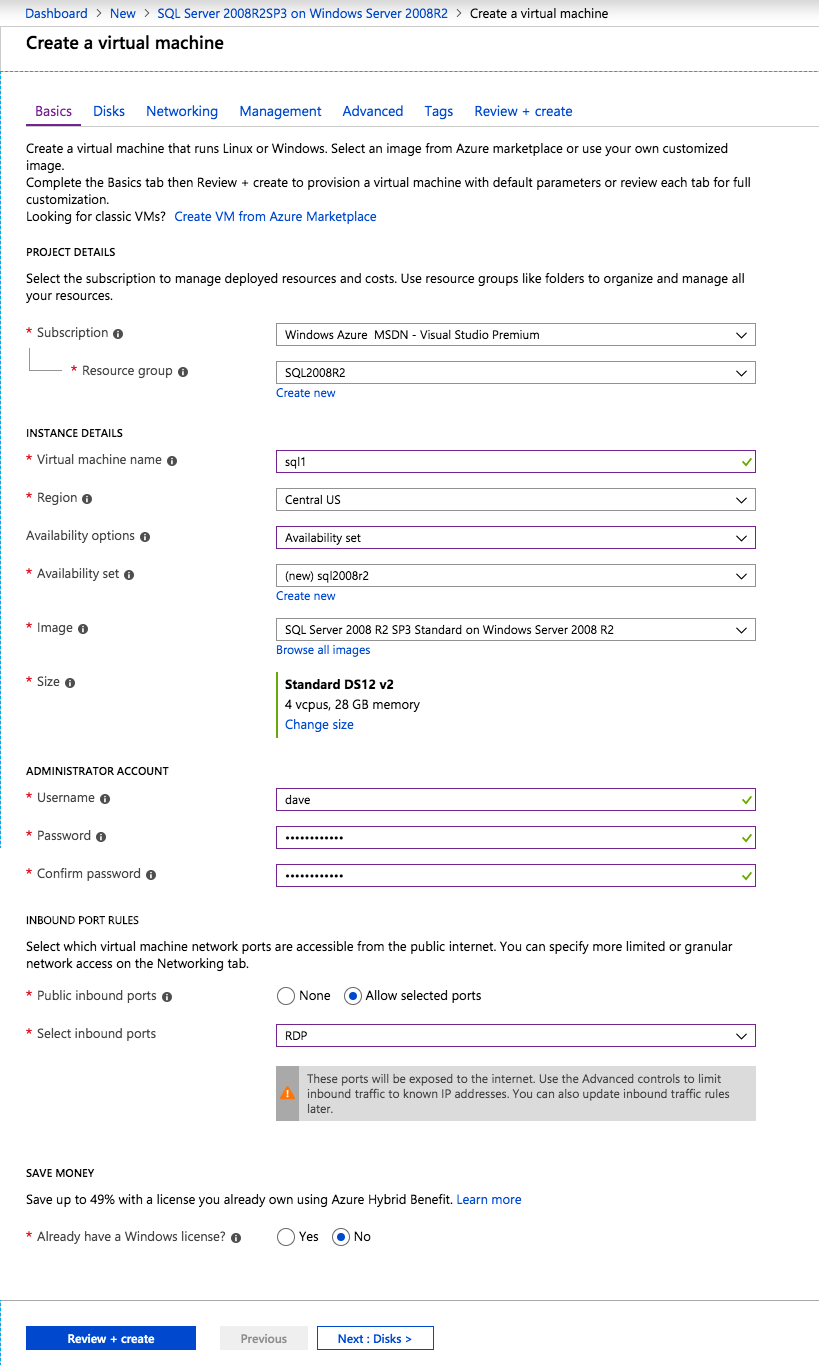 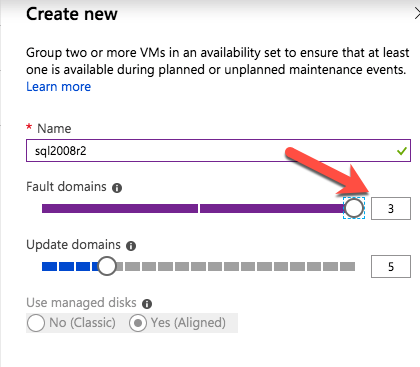  เพิ่มดิสก์เพิ่มเติมให้กับแต่ละอินสแตนซ์ แนะนำให้ใช้ Premium หรือ Ultra SSD ปิดใช้งานการแคชบนดิสก์ที่ใช้สำหรับไฟล์บันทึก SQL เปิดใช้งานการแคชแบบอ่านอย่างเดียวบนดิสก์ที่ใช้สำหรับไฟล์ข้อมูล SQL อ้างอิงถึงแนวทางการปฏิบัติงานสำหรับ SQL Server ใน Azure Virtual Machines สำหรับข้อมูลเพิ่มเติมเกี่ยวกับแนวทางปฏิบัติที่ดีที่สุดในการจัดเก็บ 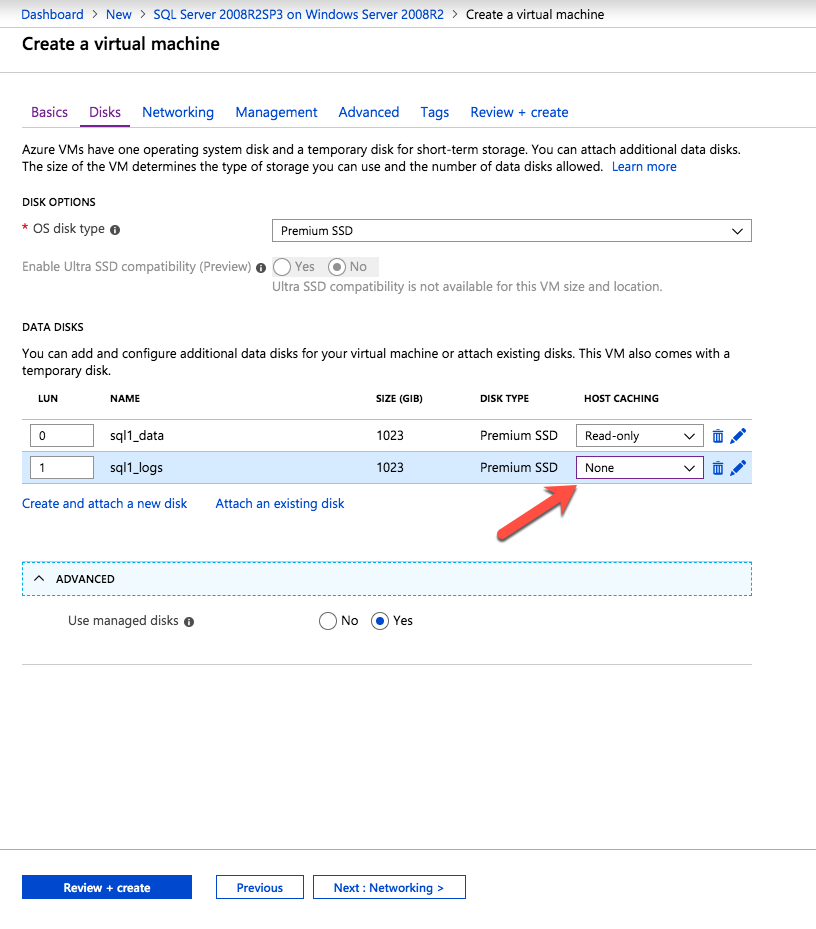 หากคุณยังไม่ได้กำหนดค่าเครือข่ายเสมือนให้อนุญาตวิซาร์ดการสร้างเพื่อสร้างใหม่สำหรับคุณ 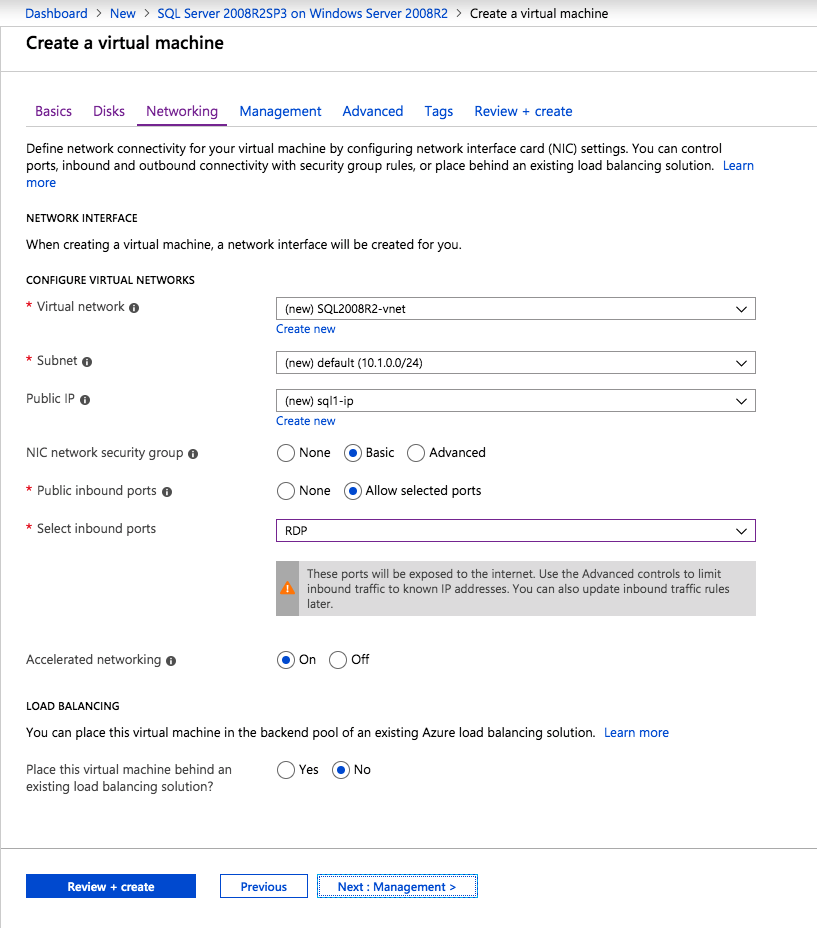 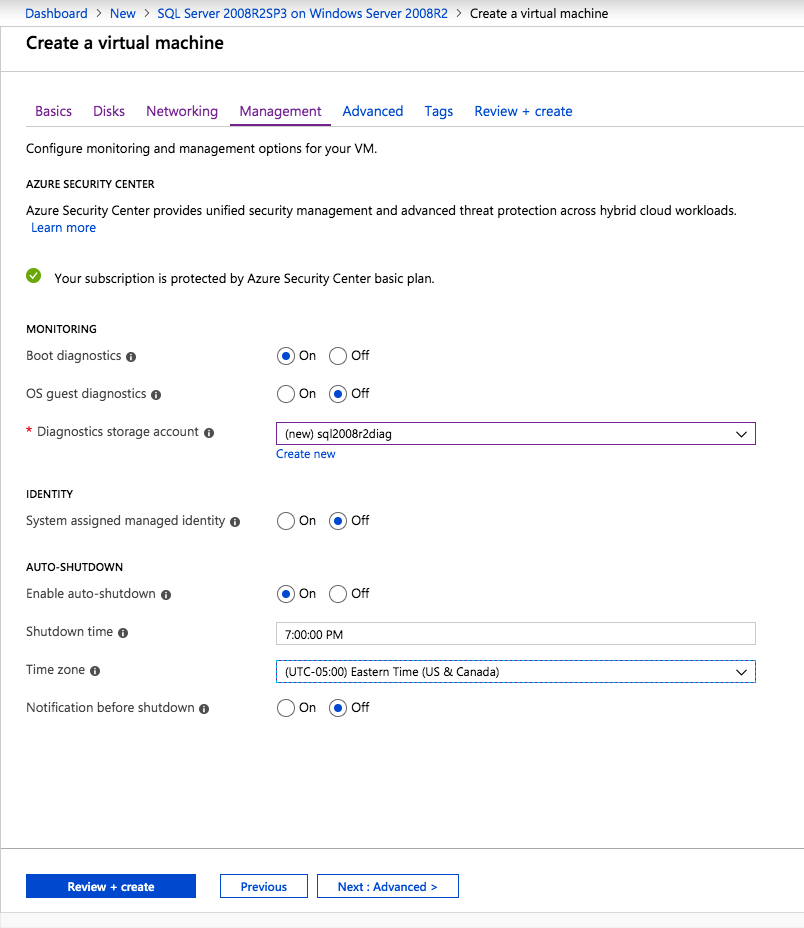 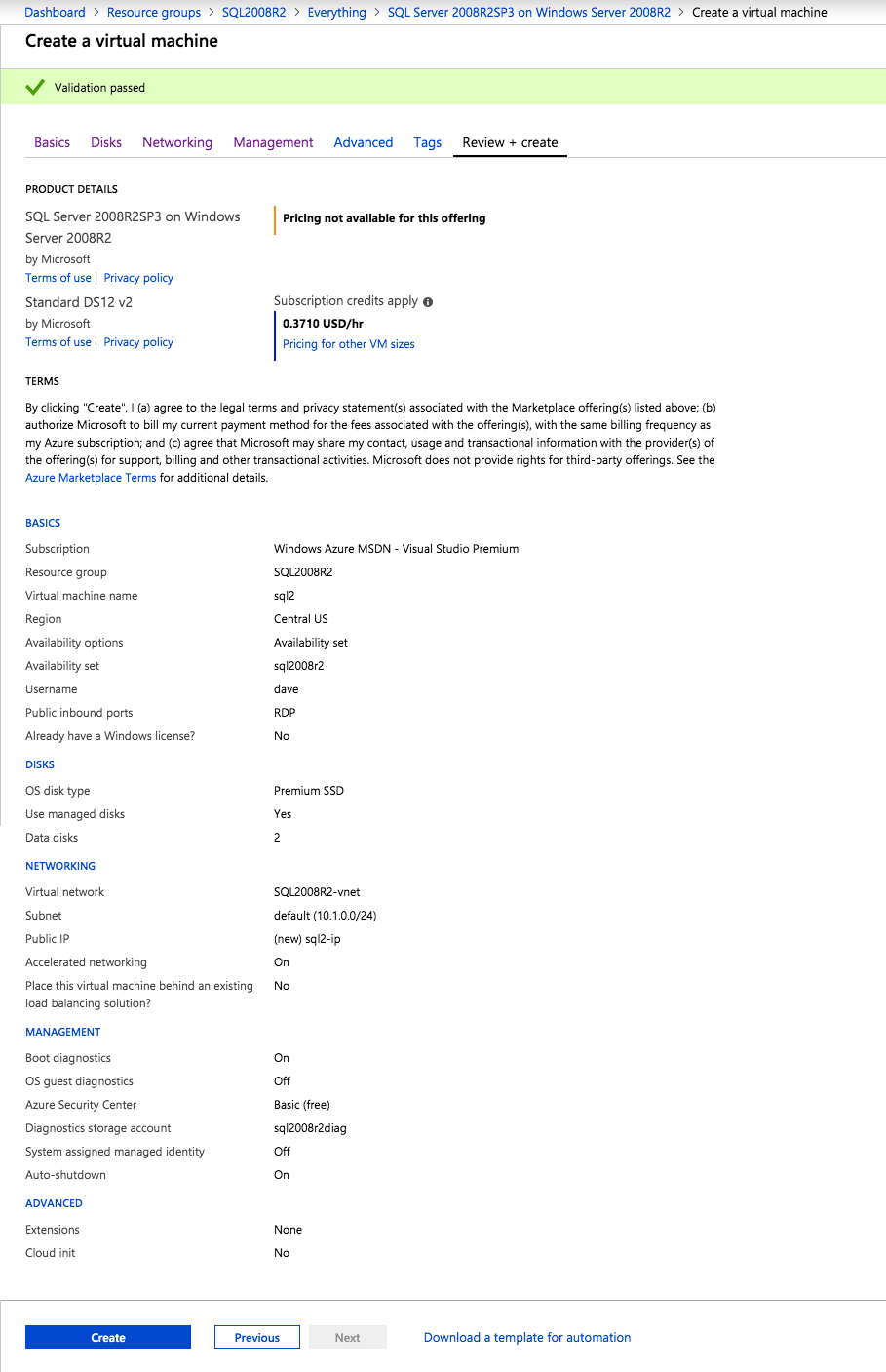 เมื่อสร้างอินสแตนซ์ไปที่การกำหนดค่า IP และทำให้ที่อยู่ IP ส่วนตัวคงที่ สิ่งนี้จำเป็นสำหรับ SIOS DataKeeper และเป็นแนวปฏิบัติที่ดีที่สุดสำหรับอินสแตนซ์ของคลัสเตอร์ 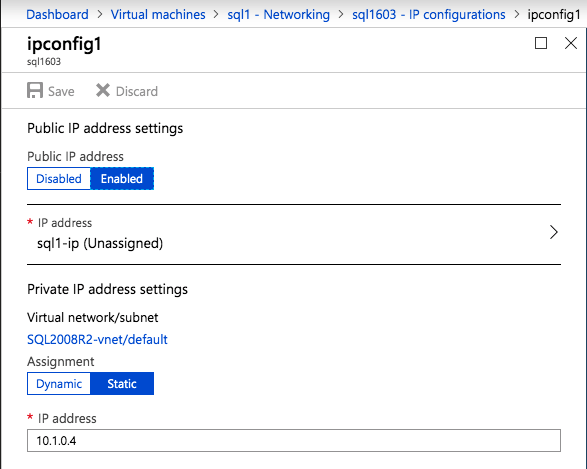 ตรวจสอบให้แน่ใจว่ามีการกำหนดค่าเครือข่ายเสมือนของคุณเพื่อตั้งค่าเซิร์ฟเวอร์ DNS ให้เป็นตัวควบคุมโฆษณาของ Windows ในเครื่อง นี่คือเพื่อให้แน่ใจว่าคุณจะสามารถเข้าร่วมโดเมนได้ในขั้นตอนต่อไป 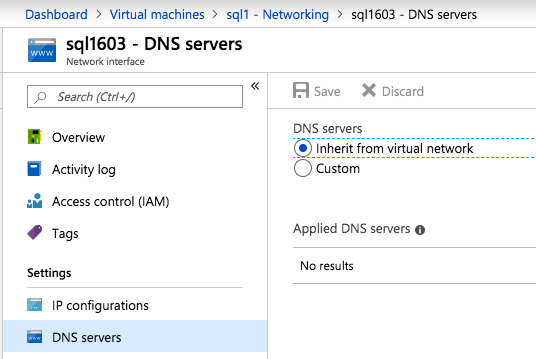 สร้างอินสแตนซ์ของเซิร์ฟเวอร์ SQL ปลายทางใน Azureทำตามขั้นตอนเดียวกับข้างต้น ยกเว้นให้แน่ใจว่าได้วางอินสแตนซ์นี้ในเครือข่ายเสมือนจริงและชุดความพร้อมใช้งานที่คุณสร้างขึ้นด้วยอินสแตนซ์ที่ 1 สร้างอินสแตนซ์แชร์ไฟล์พยาน (FSW)เพื่อให้ Windows Server Failover Cluster (WSFC) ทำงานได้อย่างมีประสิทธิภาพคุณจำเป็นต้องสร้างอินสแตนซ์ของ Windows Server อื่นและวางไว้ในชุดความพร้อมใช้งานเดียวกันกับอินสแตนซ์ของ SQL Server ด้วยการวางไว้ในชุดความพร้อมใช้งานเดียวกันคุณมั่นใจได้ว่าแต่ละโหนดคลัสเตอร์และ FSW อยู่ในโดเมนความผิดพลาดที่แตกต่างกัน ด้วยเหตุนี้จึงมั่นใจได้ว่าคลัสเตอร์ของคุณยังคงออนไลน์หากโดเมนความผิดทั้งหมดหายไป อินสแตนซ์นี้ไม่ต้องการ SQL Server มันสามารถเป็น Windows Server แบบง่าย ๆ เพียงแค่มีการแชร์ไฟล์อย่างง่าย อินสแตนซ์นี้จะโฮสต์พยานไฟล์ที่ WSFC ต้องการ อินสแตนซ์นี้ไม่จำเป็นต้องมีขนาดเท่ากันและไม่จำเป็นต้องแนบดิสก์เพิ่มเติมใด ๆ มีวัตถุประสงค์เพียงเพื่อโฮสต์การแชร์ไฟล์อย่างง่าย ในความเป็นจริงมันสามารถใช้เพื่อวัตถุประสงค์อื่น ในสภาพแวดล้อมห้องปฏิบัติการของฉัน FSW ของฉันยังเป็นตัวควบคุมโดเมนของฉัน ถอนการติดตั้ง SQL Server 2008 R2อินสแตนซ์ของ SQL Server สองตัวที่ถูกเตรียมไว้นั้นมี SQL Server 2008 R2 ติดตั้งอยู่แล้ว อย่างไรก็ตามมีการติดตั้งเป็นอินสแตนซ์ของ SQL Server แบบสแตนด์อโลนไม่ใช่อินสแตนซ์ของคลัสเตอร์ ต้องถอนการติดตั้ง SQL Server จากแต่ละอินสแตนซ์เหล่านี้ก่อนที่เราจะสามารถติดตั้งอินสแตนซ์ของคลัสเตอร์ได้ วิธีที่ง่ายที่สุดในการทำเช่นนั้นคือเรียกใช้การตั้งค่า SQL ดังที่แสดงด้านล่าง เมื่อคุณเรียกใช้ setup.exe / Action-RunDiscovery คุณจะเห็นทุกอย่างที่ติดตั้งไว้ล่วงหน้า 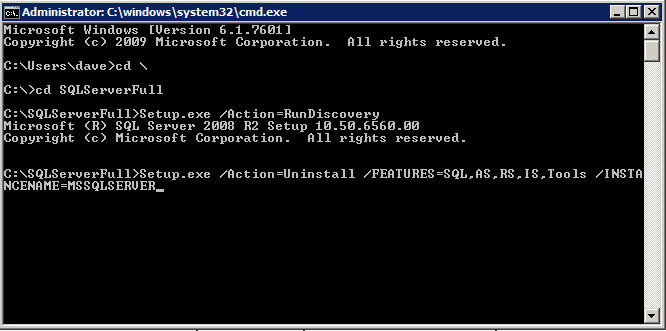  การใช้งาน setup.exe / Action = ถอนการติดตั้ง / คุณสมบัติ = SQL, AS, RS, IS, เครื่องมือ / INSTANCENAME = MSSQLSERVER เริ่มต้นกระบวนการถอนการติดตั้ง 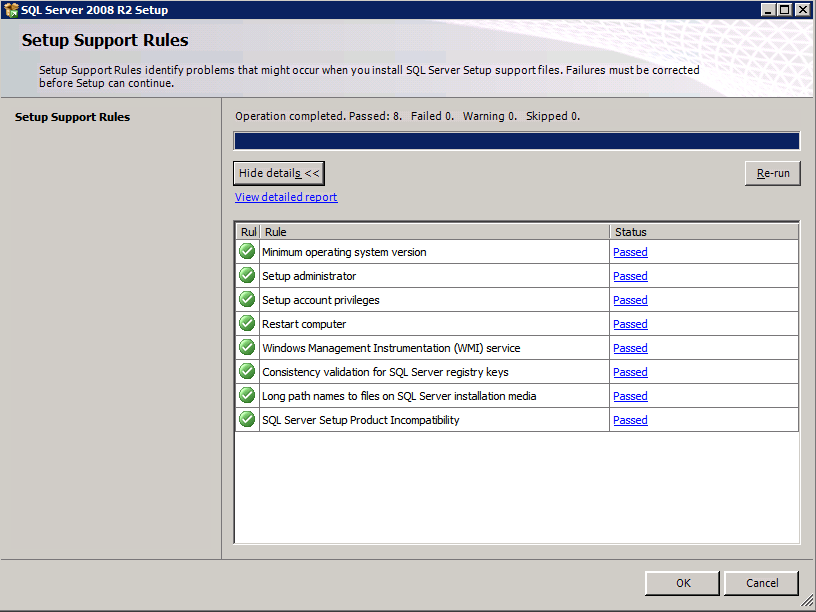  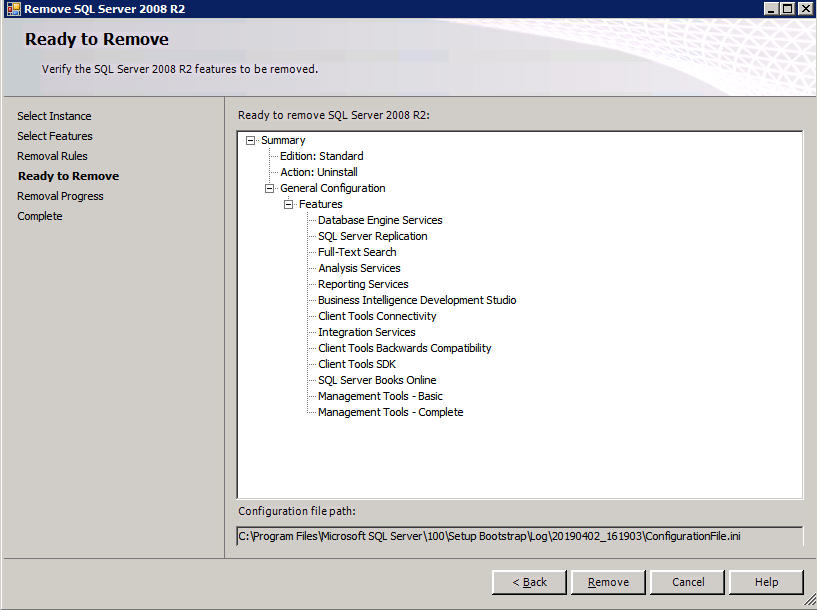  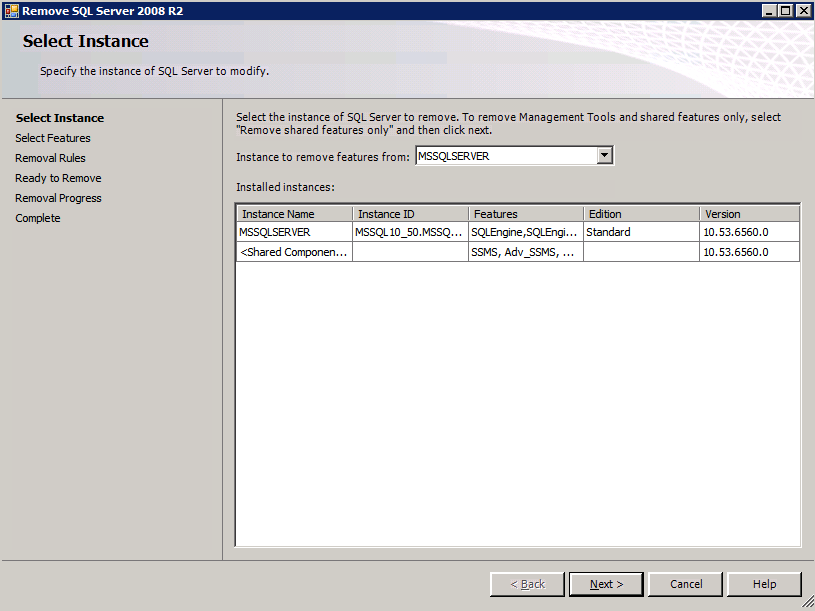 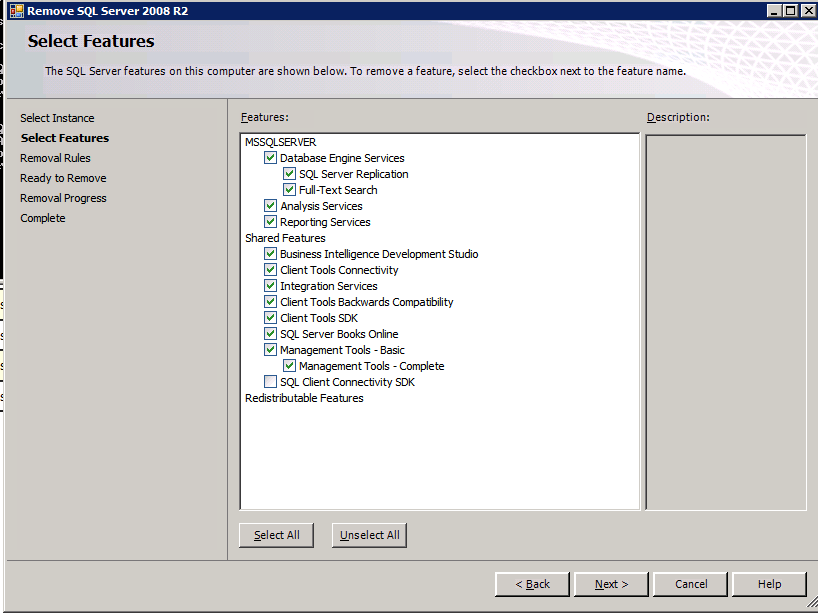 การรัน setup.exe / Action-RunDiscovery ยืนยันว่าการถอนการติดตั้งเสร็จสิ้น 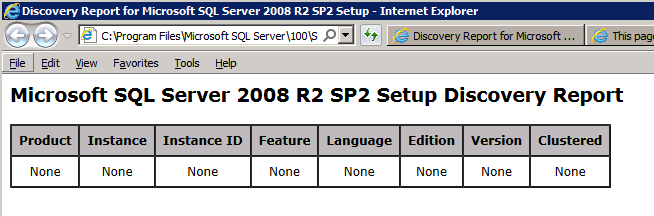 เรียกใช้กระบวนการถอนการติดตั้งนี้อีกครั้งในอินสแตนซ์ที่ 2 เพิ่มอินสแตนซ์ให้กับโดเมนอินสแตนซ์ทั้งสามเหล่านี้จะต้องถูกเพิ่มลงในโดเมน Windows 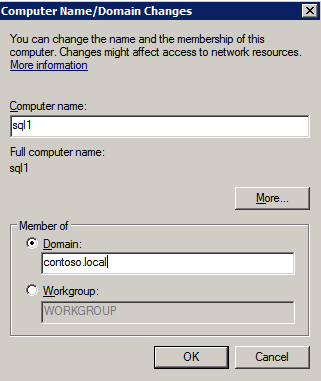 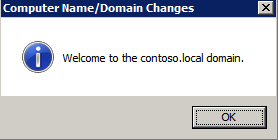 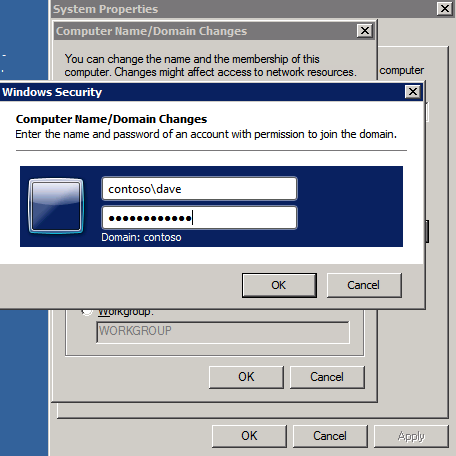 เพิ่มคุณสมบัติการทำคลัสเตอร์ Windows Failoverต้องเพิ่มคุณสมบัติการทำคลัสเตอร์เข้าแทนที่ในอินสแตนซ์ของ SQL Server สองอิน 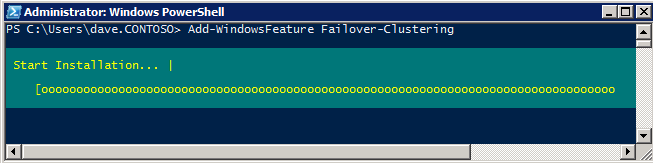 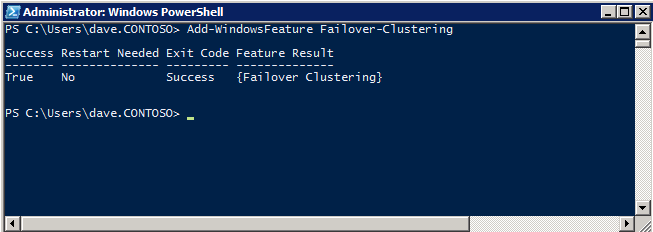 ปิดไฟร์วอลล์ Windowsเพื่อความง่ายให้ปิดไฟร์วอลล์ Windows ในระหว่างการติดตั้งและกำหนดค่าของ SQL Server FCI ศึกษาแนวทางปฏิบัติที่ดีที่สุดด้านความปลอดภัยของเครือข่าย Azure สำหรับคำแนะนำเกี่ยวกับการรักษาความปลอดภัยทรัพยากร Azure ของคุณ รายละเอียดเกี่ยวกับพอร์ต Windows ที่ต้องการสามารถพบได้ที่นี่พอร์ต SQL Server ที่นี่และพอร์ต SIOS DataKeeper ที่นี่ The Internal Load Balancer ที่เราจะกำหนดค่าในภายหลังและต้องมีการเข้าถึงพอร์ต 59999 ดังนั้นโปรดตรวจสอบให้แน่ใจว่าบัญชีของคุณมีการกำหนดค่าความปลอดภัย 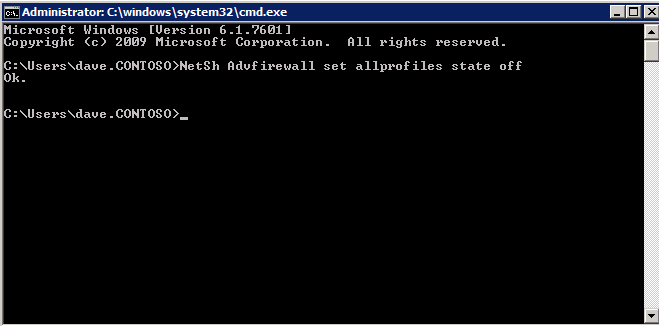 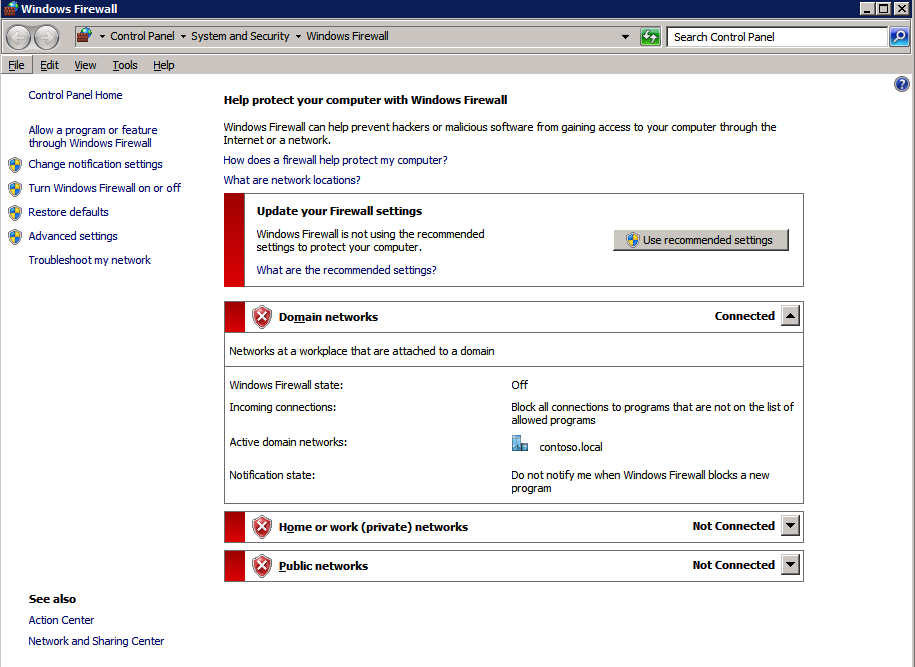 ติดตั้งการปรับปรุงการยกเลิกการอำนวยความสะดวกสำหรับ Windows Server 2008 R2 SP1มีการปรับปรุงที่สำคัญ (kb2854082) ที่จำเป็นเพื่อกำหนดค่าอินสแตนซ์ของ Windows Server 2008 R2 ใน Azure การอัปเดตและอื่น ๆ อีกมากมายนั้นรวมอยู่ในการปรับปรุงการยกเลิกการอำนวยความสะดวกสำหรับ Windows Server 2008 R2 SP1 ติดตั้งโปรแกรมปรับปรุงนี้บนแต่ละอินสแตนซ์ของ SQL Server สองอิน    จัดรูปแบบการจัดเก็บดิสก์เพิ่มเติมที่แนบมาเมื่อ SQL Server สองอินสแตนซ์ถูกจัดเตรียมไว้จะต้องจัดรูปแบบ ทำสิ่งต่อไปนี้สำหรับแต่ละโวลุ่มในแต่ละอินสแตนซ์ 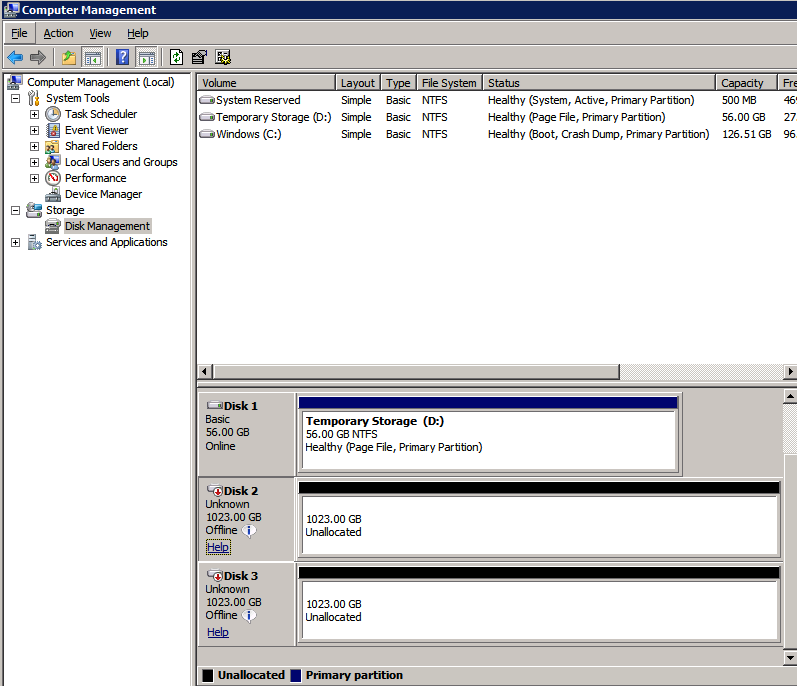 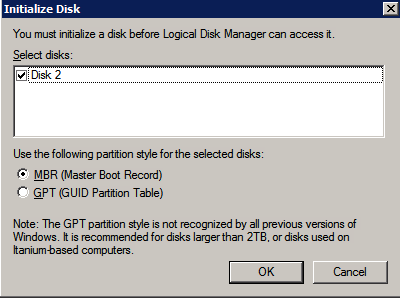  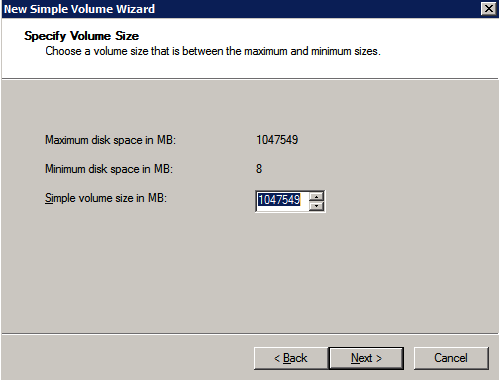 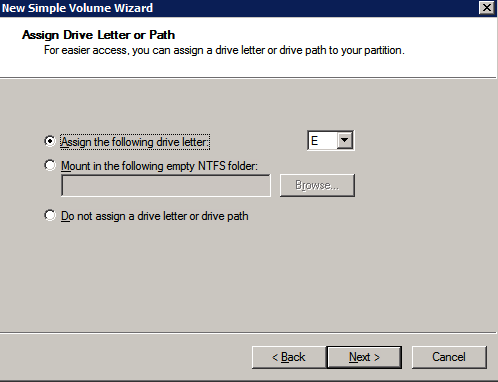 แนวทางปฏิบัติที่ดีที่สุดของ Microsoft กล่าวต่อไปนี้ … “ ขนาดหน่วยการจัดสรร NTFS: เมื่อทำการฟอร์แมตดิสก์ข้อมูลขอแนะนำให้คุณใช้ขนาดหน่วยการจัดสรร 64-KB สำหรับข้อมูลและไฟล์บันทึกเช่นเดียวกับ TempDB” 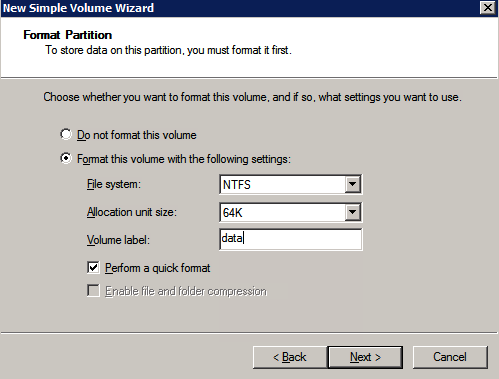 เรียกใช้การตรวจสอบคลัสเตอร์รันการตรวจสอบความถูกต้องของคลัสเตอร์เพื่อให้แน่ใจว่าทุกอย่างพร้อมที่จะทำคลัสเตอร์ 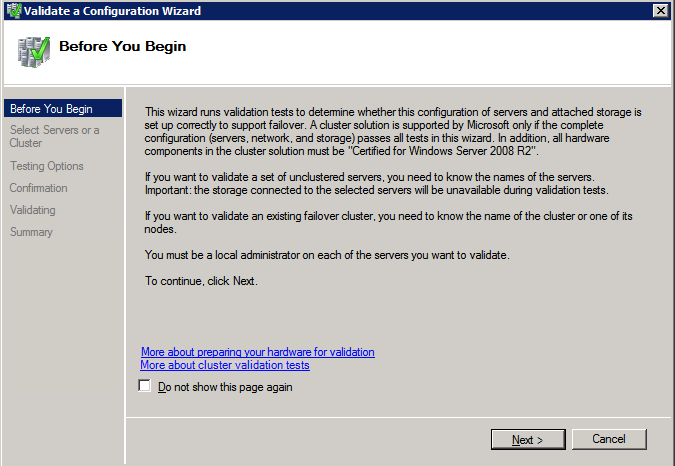 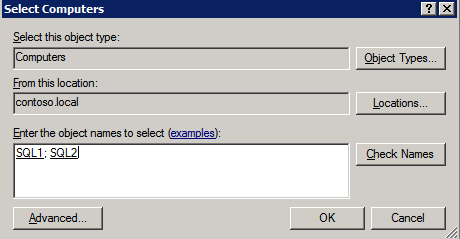 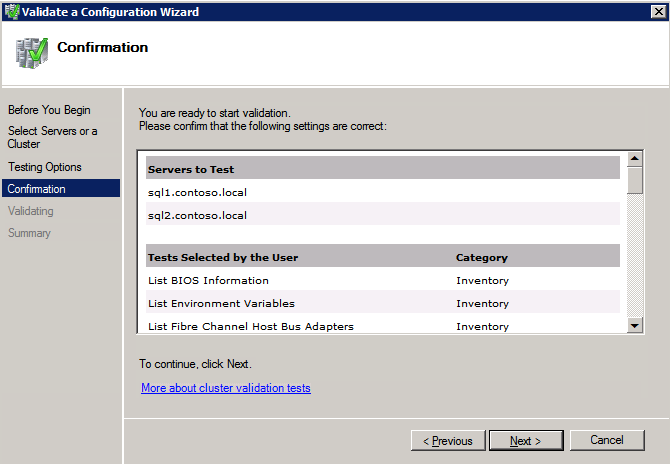 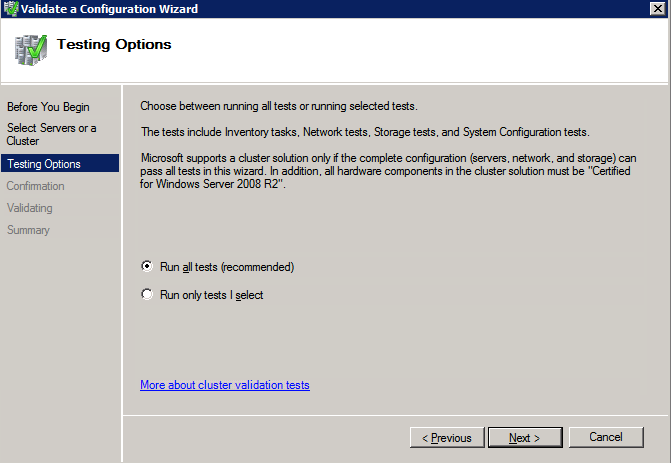 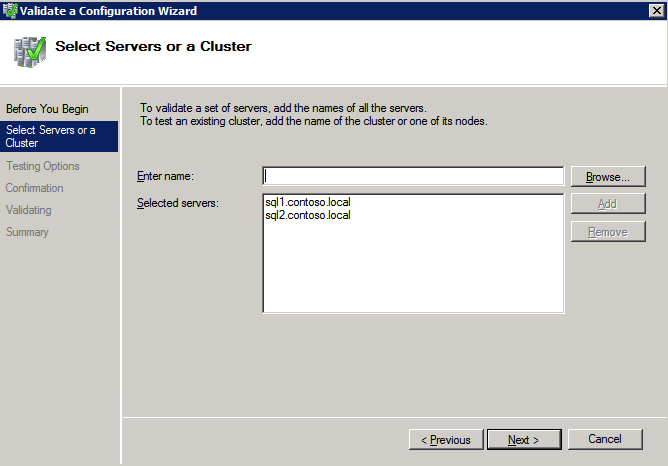 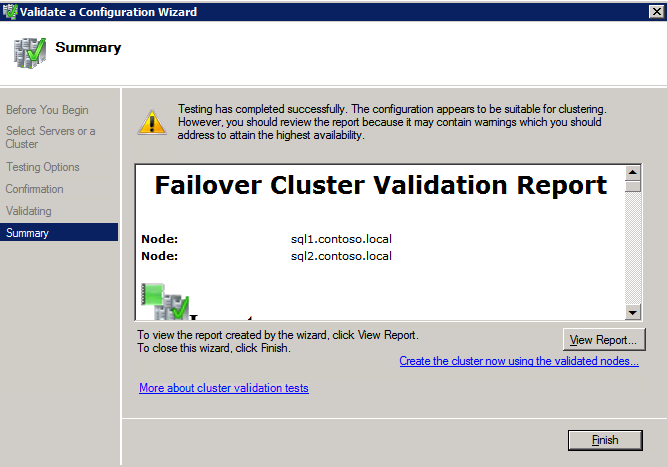 รายงานของคุณจะมีคำเตือนเกี่ยวกับการจัดเก็บและระบบเครือข่าย คุณสามารถละเว้นคำเตือนเหล่านั้นได้เนื่องจากเรารู้ว่าไม่มีดิสก์ที่ใช้ร่วมกันและมีการเชื่อมต่อเครือข่ายเดียวระหว่างเซิร์ฟเวอร์ คุณอาจได้รับคำเตือนเกี่ยวกับลำดับการเชื่อมโยงเครือข่ายซึ่งสามารถละเว้นได้ หากคุณพบข้อผิดพลาดใด ๆ คุณต้องดำเนินการก่อนที่จะดำเนินการต่อ 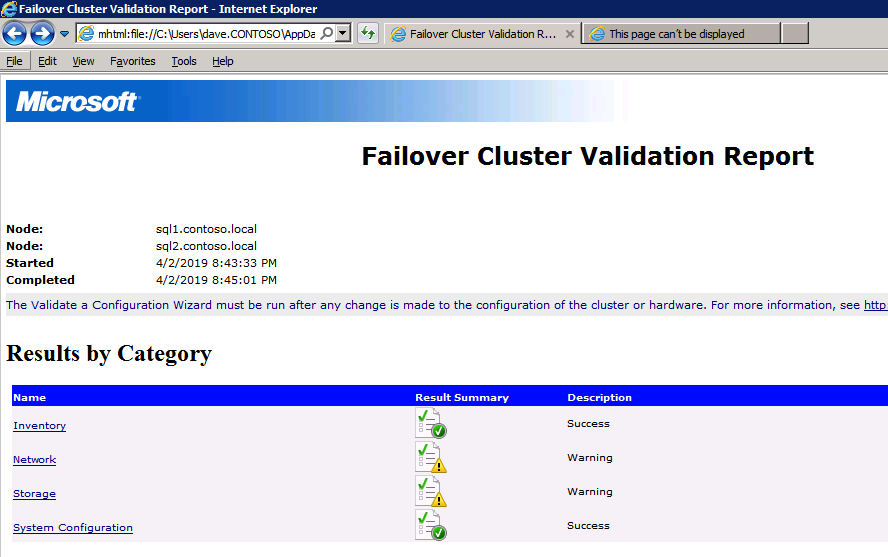 สร้างคลัสเตอร์แนวทางปฏิบัติที่ดีที่สุดสำหรับการสร้างคลัสเตอร์ใน Azure คือการใช้ Powershell ดังที่แสดงด้านล่าง Powershell ช่วยให้เราสามารถระบุที่อยู่ IP แบบคงที่ในขณะที่วิธีการ GUI ไม่ได้ น่าเสียดายที่การใช้ DHCP ของ Azure ทำงานได้ไม่ดีกับ Windows Server Failover Clustering หากคุณใช้วิธี GUI คุณจะปิดท้ายด้วยที่อยู่ IP ที่ซ้ำกันเป็นที่อยู่ IP ของคลัสเตอร์ มันไม่ใช่จุดจบของโลก แต่คุณจะต้องแก้ไขปัญหาดังที่ฉันแสดง ดังที่ฉันได้กล่าวไว้แล้ววิธี Powershell นั้นใช้งานได้ดีที่สุด อย่างไรก็ตามด้วยเหตุผลบางอย่างดูเหมือนว่าจะล้มเหลวใน Windows Server 2008 R2 ดังที่แสดงด้านล่าง 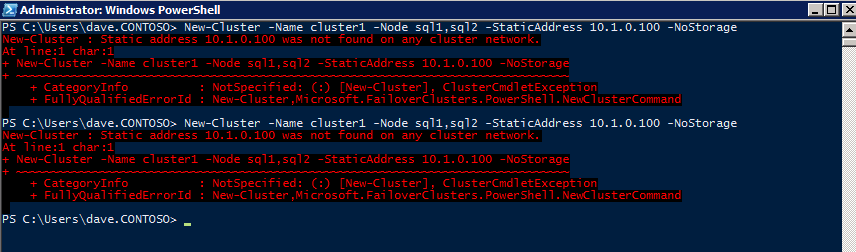 คุณสามารถลองใช้วิธีการนี้และถ้ามันเหมาะกับคุณ – เยี่ยมมาก! ฉันต้องย้อนกลับไปและตรวจสอบเรื่องนี้อีกเล็กน้อยเพื่อดูว่ามันเป็นความบังเอิญหรือไม่ ตัวเลือกอื่นที่ฉันต้องสำรวจหาก Powershell ไม่ทำงานคือ Cluster.exe กำลังรันคลัสเตอร์ / สร้าง /? ให้ไวยากรณ์ที่เหมาะสมที่จะใช้สำหรับการสร้างกลุ่มด้วยคำสั่งเลิกใช้ cluster.exe อย่างไรก็ตามหาก Powershell หรือ Cluster.exe ล้มเหลวคุณขั้นตอนด้านล่างแสดงวิธีการสร้างคลัสเตอร์ผ่านทาง Windows Server Failover Clustering UI รวมถึงการแก้ไขที่อยู่ IP ที่ซ้ำกันซึ่งจะถูกกำหนดให้กับคลัสเตอร์ 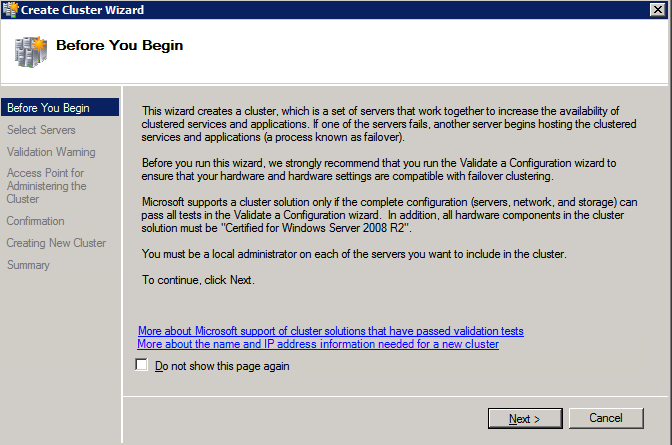 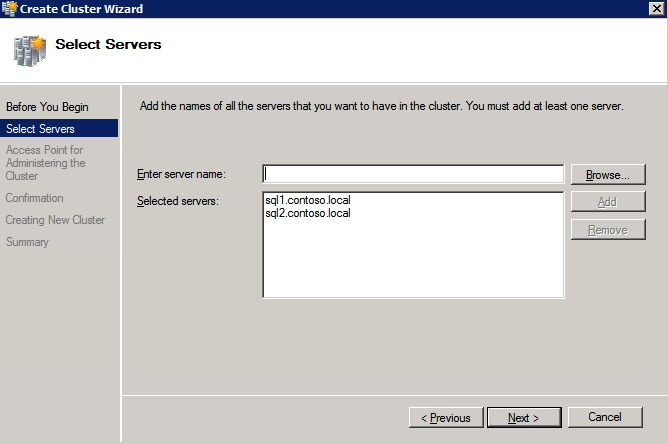 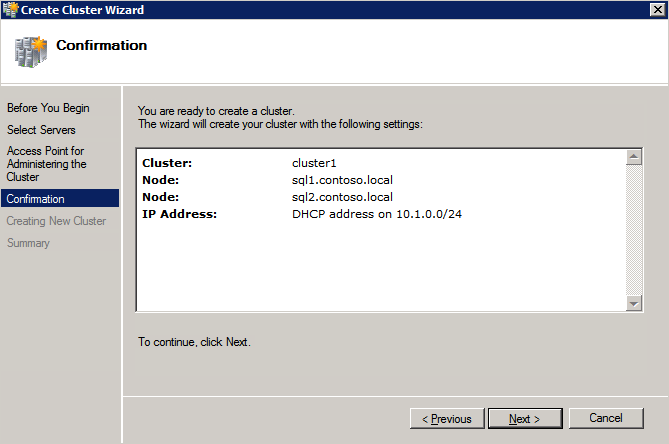 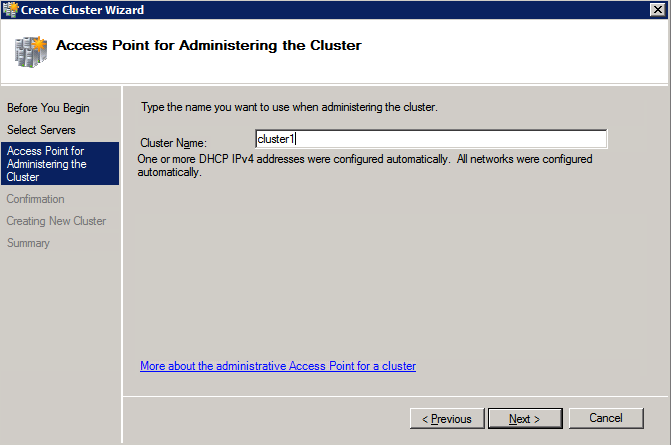 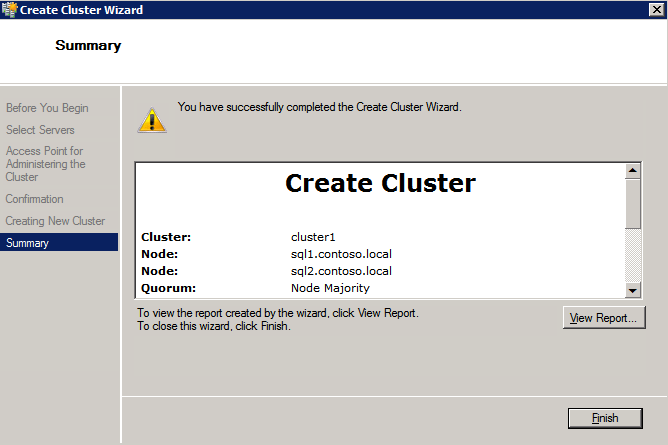 จำไว้ว่าชื่อที่คุณระบุในที่นี้เป็นเพียงชื่อวัตถุคลัสเตอร์ (CNO) นี่ไม่ใช่ชื่อที่ไคลเอ็นต์ SQL ของคุณจะใช้เพื่อเชื่อมต่อกับคลัสเตอร์ เราจะกำหนดว่าในระหว่างการตั้งค่าคลัสเตอร์ SQL Server ในขั้นตอนภายหลัง ณ จุดนี้คลัสเตอร์ถูกสร้างขึ้น แต่คุณอาจไม่สามารถเชื่อมต่อกับคลัสเตอร์ได้ด้วย Windows Server Failover Clustering UI เนื่องจากปัญหาที่อยู่ IP ที่ซ้ำกัน แก้ไขที่อยู่ IP ที่ซ้ำกันอย่างที่ฉันได้กล่าวไปแล้วถ้าคุณสร้างคลัสเตอร์โดยใช้ GUI คุณจะไม่ได้รับโอกาสในการเลือกที่อยู่ IP สำหรับคลัสเตอร์ เนื่องจากอินสแตนซ์ของคุณได้รับการกำหนดค่าให้ใช้ DHCP (จำเป็นใน Azure) GUI ต้องการกำหนดที่อยู่ IP ให้คุณโดยอัตโนมัติโดยใช้ DHCP น่าเสียดายที่การใช้ DHCP ของ Azure ไม่ทำงานตามที่คาดไว้และคลัสเตอร์จะได้รับการกำหนดที่อยู่เดียวกับที่โหนดใดโหนดหนึ่งใช้อยู่ แม้ว่าคลัสเตอร์จะสร้างขึ้นอย่างถูกต้องคุณจะมีเวลาในการเชื่อมต่อกับคลัสเตอร์จนกว่าคุณจะแก้ไขปัญหานี้ เมื่อต้องการแก้ไขปัญหานี้จากโหนดใดโหนดหนึ่งให้เรียกใช้คำสั่งต่อไปนี้เพื่อให้แน่ใจว่าบริการคลัสเตอร์เริ่มต้นขึ้นบนโหนดนั้น 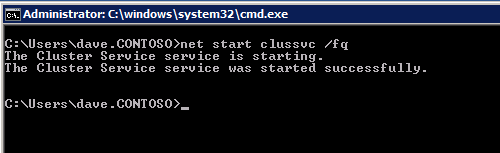 ในโหนดเดียวกันนั้นตอนนี้คุณควรจะสามารถเชื่อมต่อกับ Windows Server Failover Clustering UI ที่ซึ่งคุณจะเห็นที่อยู่ IP ล้มเหลวในการออนไลน์ 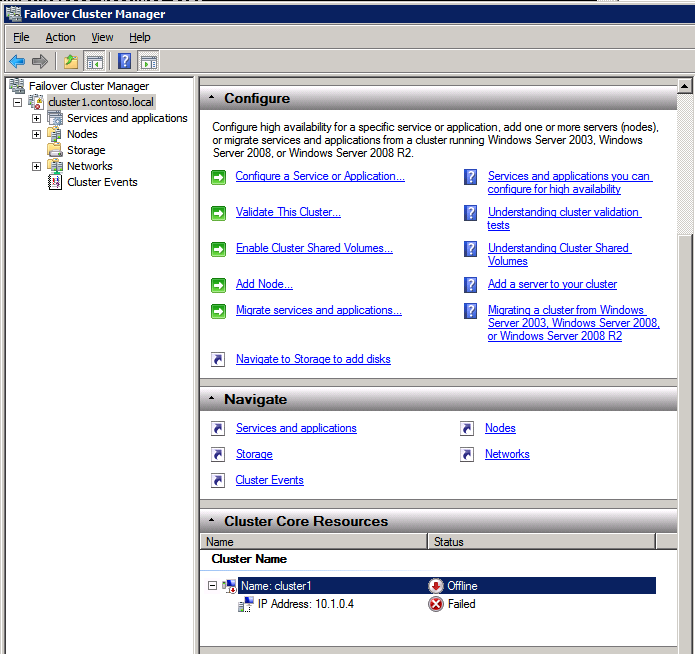 เปิดคุณสมบัติของที่อยู่ IP ของคลัสเตอร์และเปลี่ยนจาก DHCP เป็นแบบคงที่และกำหนดที่อยู่ IP ที่ไม่ได้ใช้ 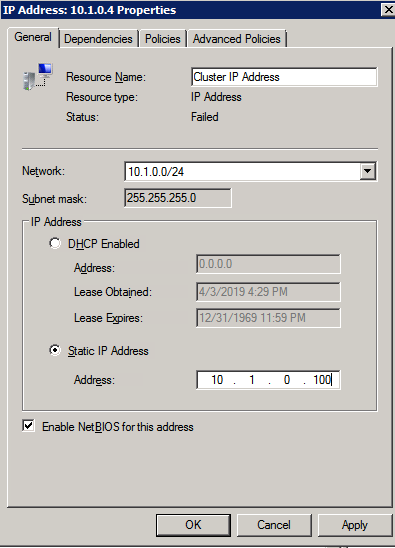 นำทรัพยากรชื่อออนไลน์ 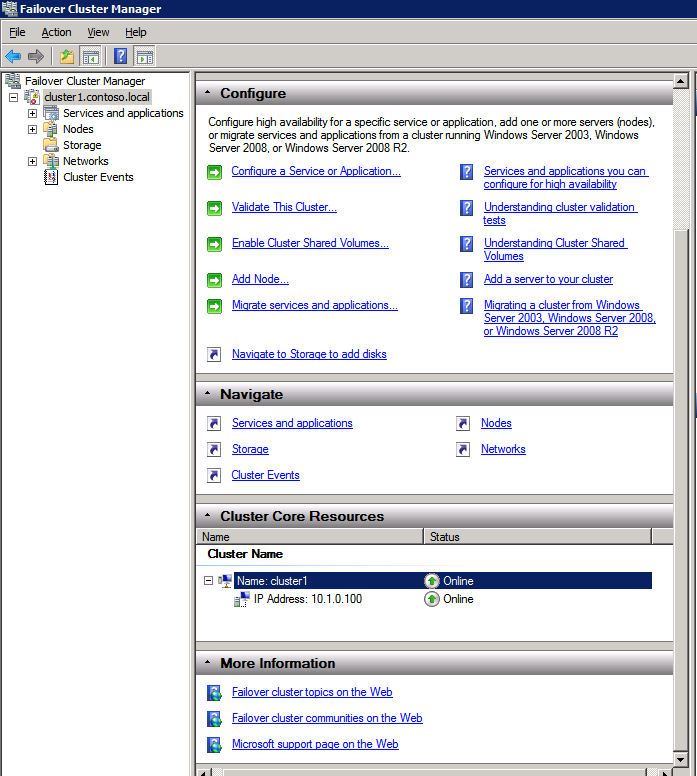 เพิ่มการแชร์ไฟล์พยานต่อไปเราต้องเพิ่ม File Share Witness บนเซิร์ฟเวอร์ตัวที่ 3 ที่เราจัดเตรียมไว้เป็น FSW ให้สร้างโฟลเดอร์และแชร์มันดังที่แสดงด้านล่าง คุณจะต้องให้สิทธิ์การอ่าน / เขียน Cluster Name Object (CNO) ทั้งระดับการแบ่งปันและความปลอดภัยดังที่แสดงด้านล่าง 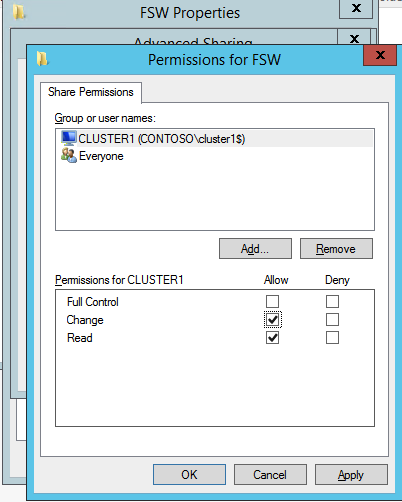 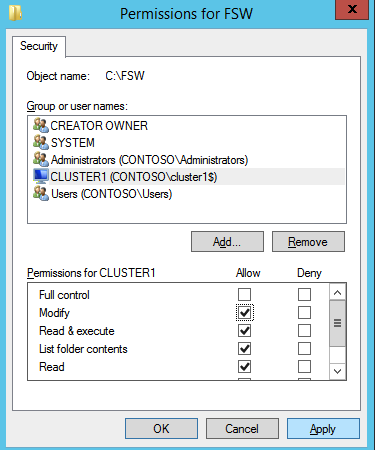 เมื่อสร้างการแชร์แล้วให้รันวิซาร์ด Configure Cluster Quorum บนหนึ่งในโหนดคลัสเตอร์และทำตามขั้นตอนที่แสดงด้านล่าง 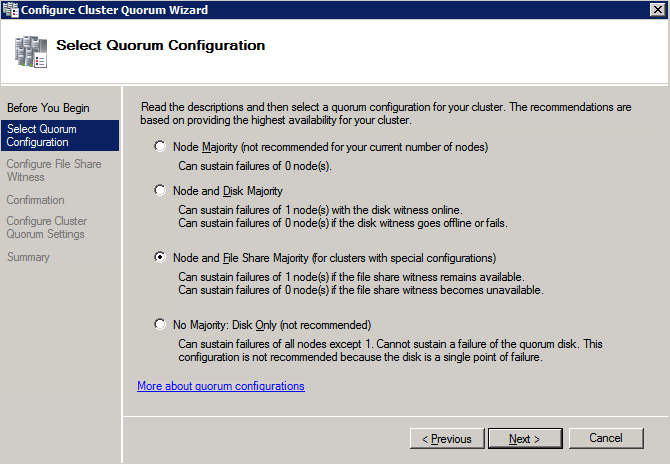 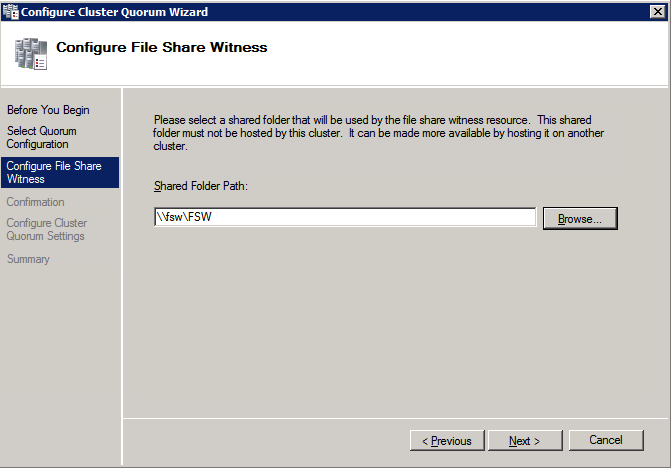 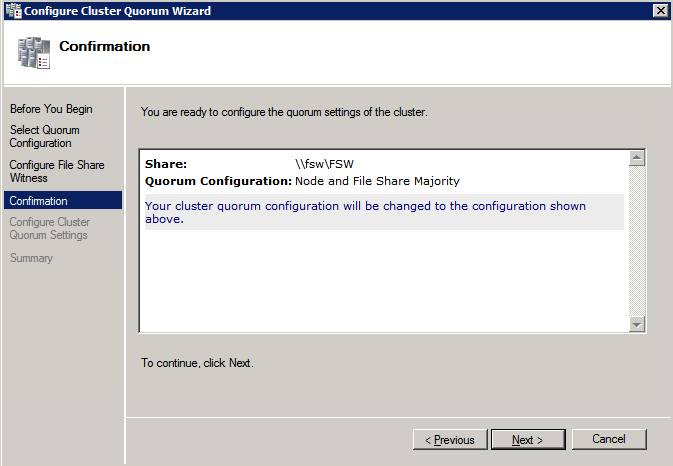 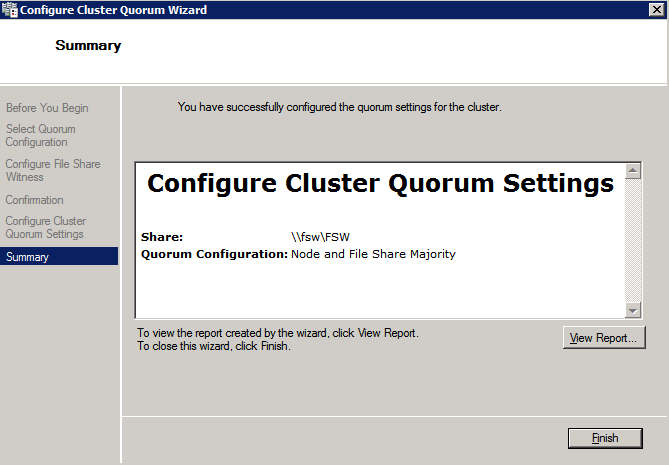 สร้างบัญชีบริการสำหรับ DataKeeperเราเกือบจะพร้อมที่จะติดตั้ง DataKeeper แล้ว อย่างไรก็ตามก่อนที่เราจะทำเช่นนั้นคุณจะต้องสร้างบัญชีโดเมนและเพิ่มลงในกลุ่ม Local Administrators ในแต่ละอินสแตนซ์ของคลัสเตอร์ SQL Server เราจะระบุบัญชีนี้เมื่อเราติดตั้ง DataKeeper 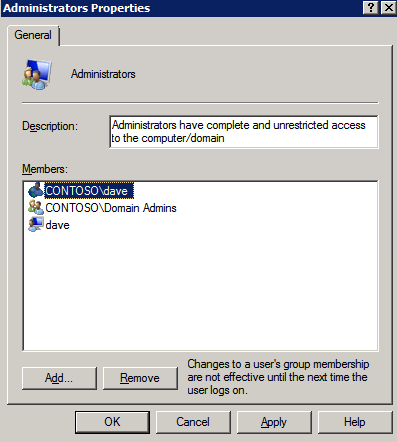 ติดตั้ง DataKeeperติดตั้ง DataKeeper บนโหนดคลัสเตอร์ SQL Server สองโหนดดังที่แสดงด้านล่าง  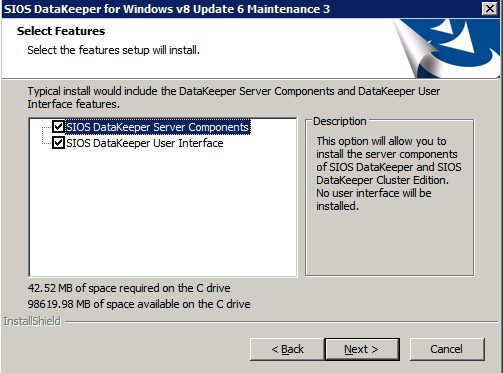 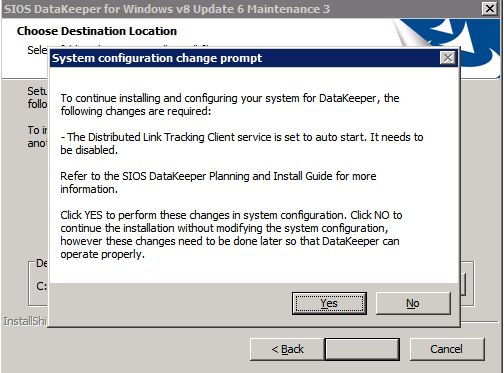 นี่คือที่เราจะระบุบัญชีโดเมนที่เราเพิ่มลงในกลุ่มผู้ดูแลโดเมนท้องถิ่นแต่ละกลุ่ม 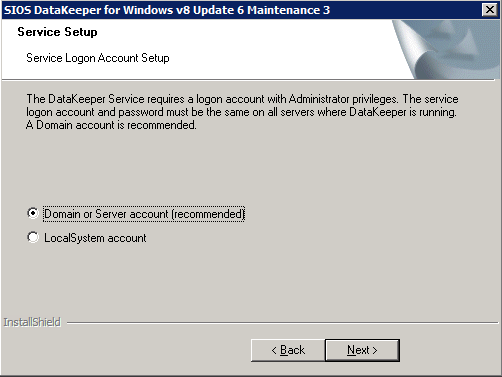 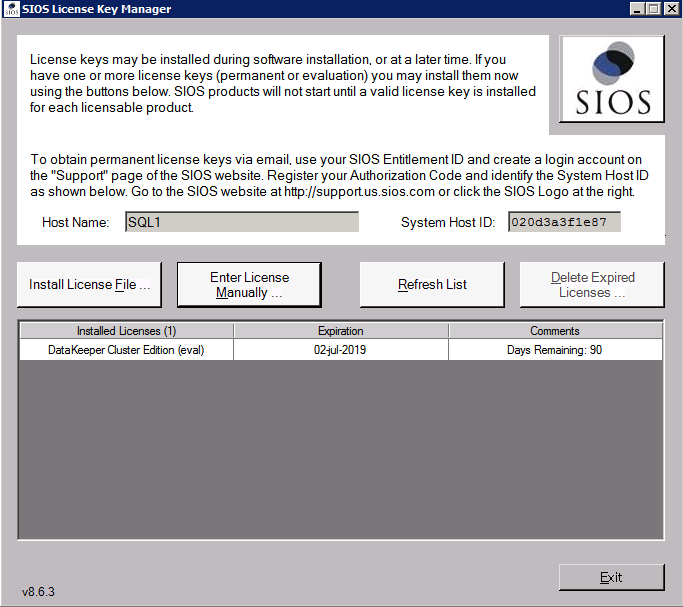  กำหนดค่า DataKeeperเมื่อติดตั้ง DataKeeper บนโหนดคลัสเตอร์ทั้งสองโหนดแล้วคุณก็พร้อมที่จะกำหนดค่า DataKeeper หมายเหตุ – ข้อผิดพลาดที่พบบ่อยที่สุดในขั้นตอนต่อไปนี้เกี่ยวข้องกับความปลอดภัยส่วนใหญ่โดยกลุ่ม Azure Security ที่มีอยู่ก่อนการบล็อกพอร์ตที่จำเป็น โปรดอ้างอิงเอกสาร SIOS เพื่อให้แน่ใจว่าเซิร์ฟเวอร์สามารถสื่อสารผ่านพอร์ตที่ต้องการ ก่อนอื่นคุณต้องเชื่อมต่อกับแต่ละโหนดทั้งสอง 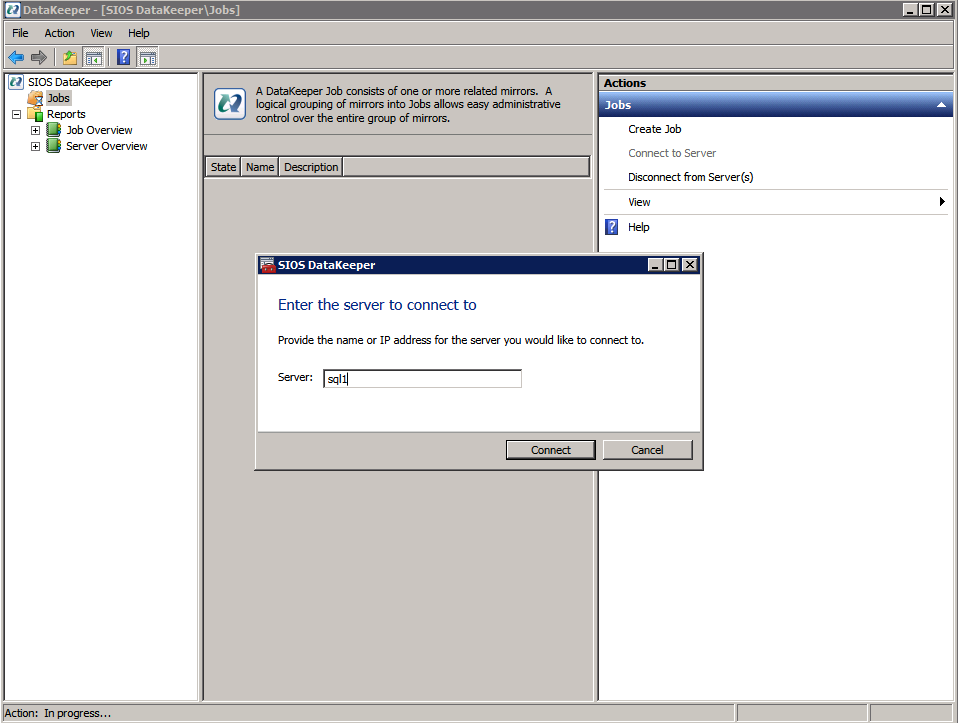 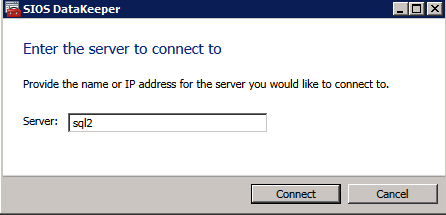 หากการกำหนดค่าทุกอย่างถูกต้องคุณควรดูสิ่งต่อไปนี้ในรายงานภาพรวมเซิร์ฟเวอร์ 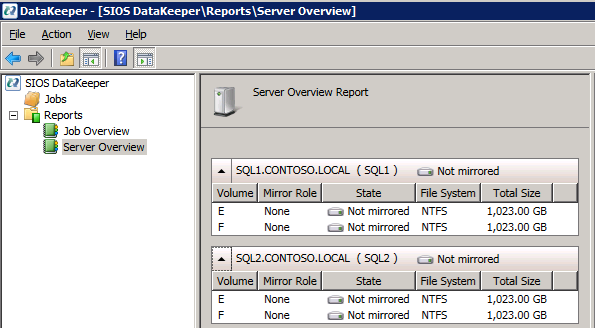 จากนั้นสร้างงานใหม่และทำตามขั้นตอนด้านล่าง 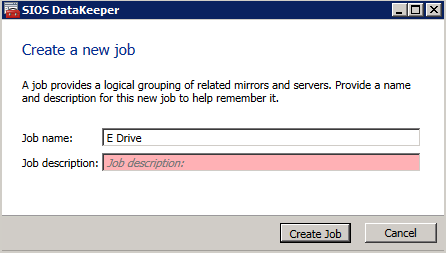 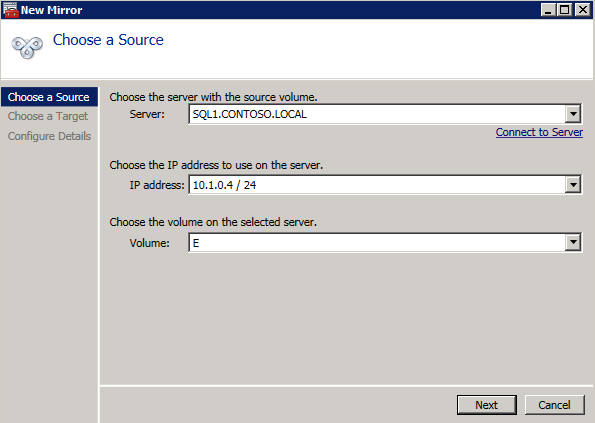 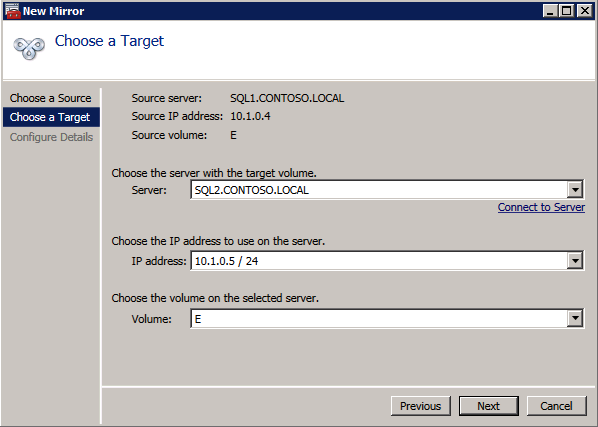 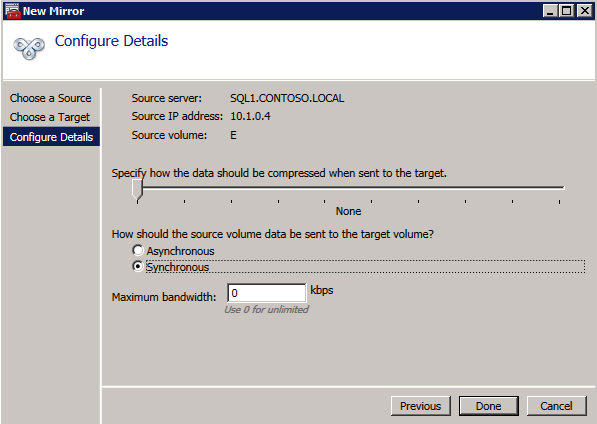 เลือกใช่ที่นี่เพื่อลงทะเบียนทรัพยากร DataKeeper Volume ใน Available Storage 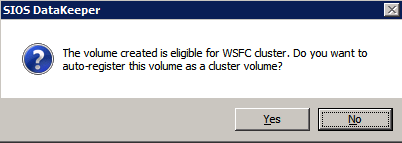 ทำตามขั้นตอนด้านบนสำหรับแต่ละไดรฟ์ เมื่อเสร็จแล้วคุณควรเห็นสิ่งต่อไปนี้ใน Windows Server Failover Clustering UI 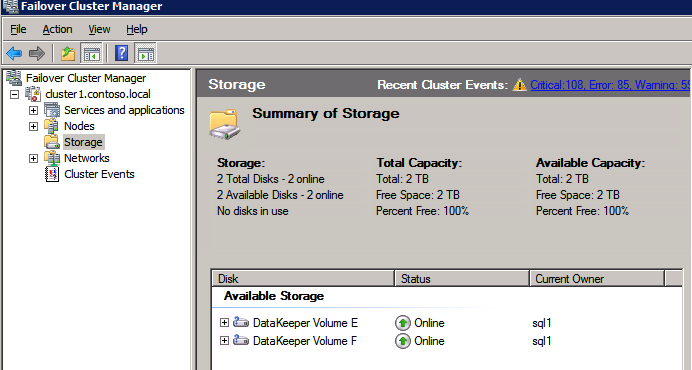 ตอนนี้คุณพร้อมที่จะติดตั้ง SQL Server ในคลัสเตอร์ หมายเหตุ – ณ จุดนี้ไดรฟ์ข้อมูลที่จำลองแบบจะสามารถเข้าถึงได้บนโหนดที่กำลังโฮสต์ที่เก็บข้อมูลที่พร้อมใช้งานในปัจจุบันเท่านั้น เป็นไปตามคาดดังนั้นไม่ต้องกังวล! ติดตั้ง SQL Server บนโหนดแรกบนโหนดแรกเรียกใช้การตั้งค่าเซิร์ฟเวอร์ SQL  เลือกการติดตั้งคลัสเตอร์เซิร์ฟเวอร์ล้มเหลว SQL ใหม่และทำตามขั้นตอนตามที่แสดงในรูป 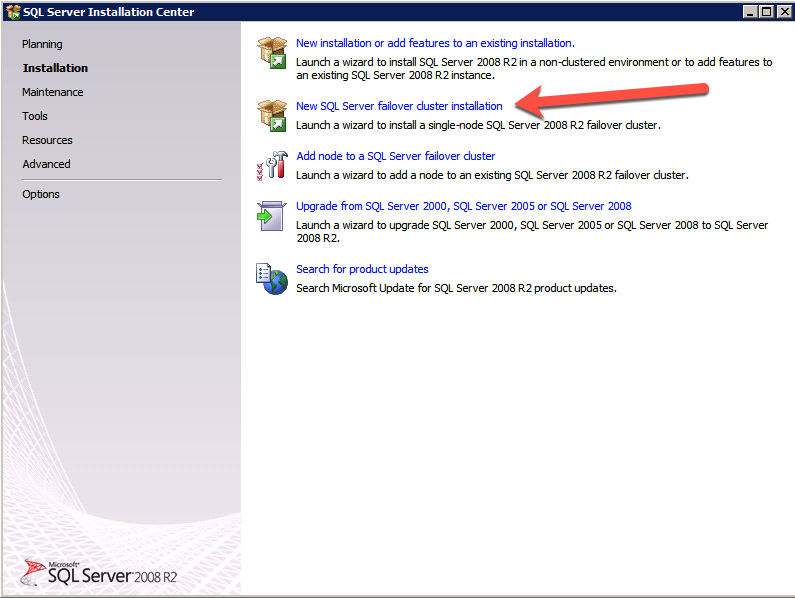 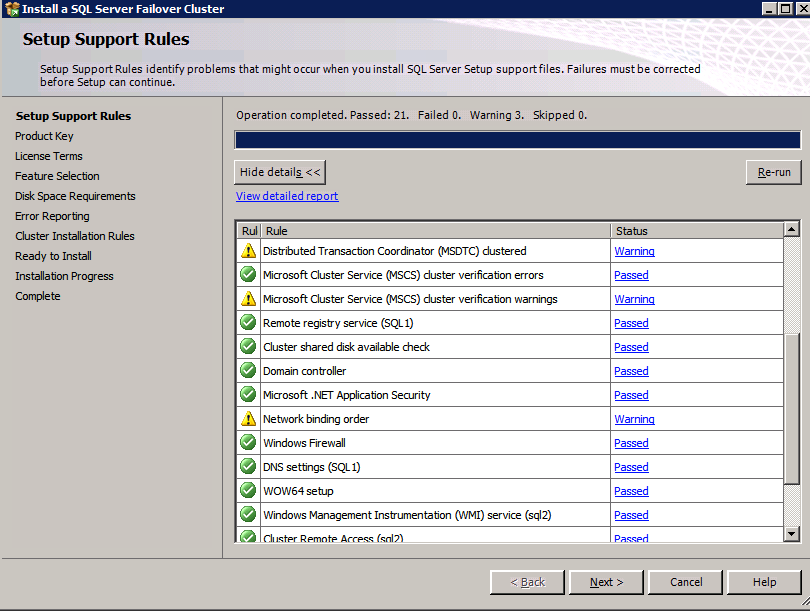 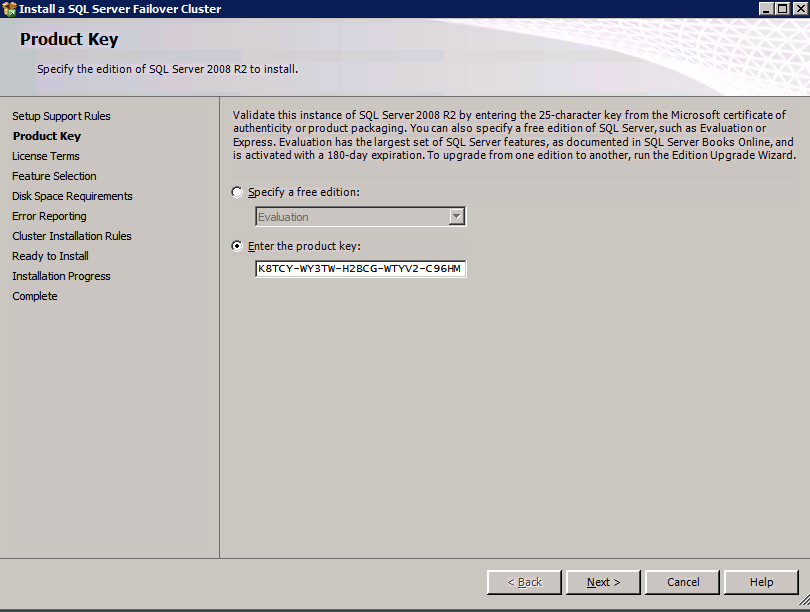  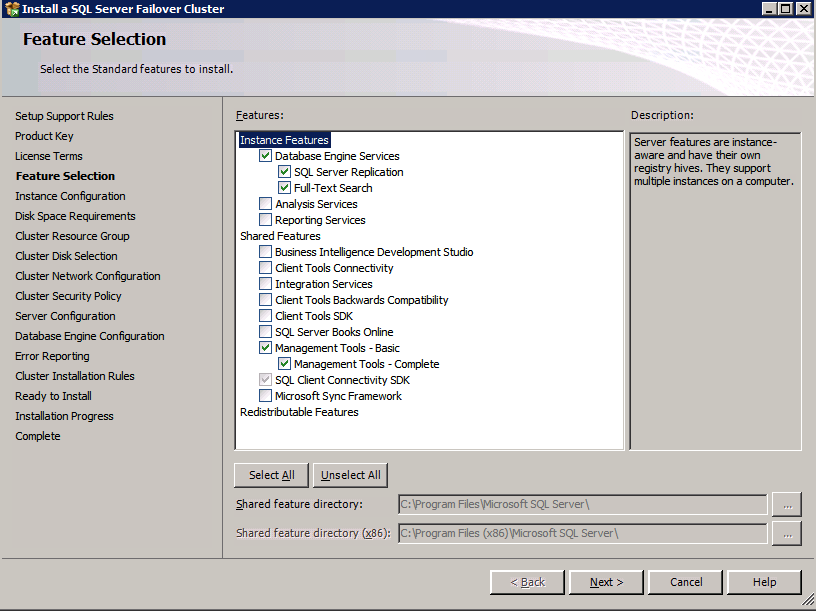 เลือกตัวเลือกที่คุณต้องการเท่านั้น โปรดทราบว่าเอกสารนี้ถือว่าคุณใช้อินสแตนซ์เริ่มต้นของ SQL Server ถ้าคุณใช้อินสแตนซ์ที่มีชื่อคุณต้องตรวจสอบให้แน่ใจว่าคุณล็อกพอร์ตที่ฟังอยู่และใช้พอร์ตนั้นในภายหลังเมื่อคุณกำหนดค่าตัวโหลดบาลานซ์ คุณจะต้องสร้างกฎตัวโหลดบาลานซ์สำหรับ SQL Server Browser Service (UDP 1434) เพื่อเชื่อมต่อกับ Named Instance ข้อกำหนดทั้งสองนี้ไม่ได้กล่าวถึงในคู่มือนี้ แต่ถ้าคุณต้องการ Named Instance มันจะทำงานถ้าคุณทำตามสองขั้นตอนเพิ่มเติมนั้น 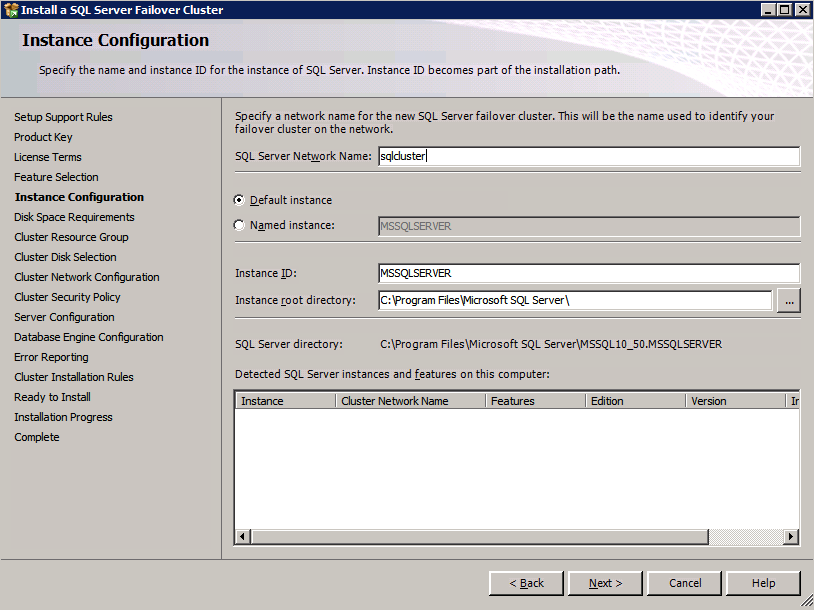 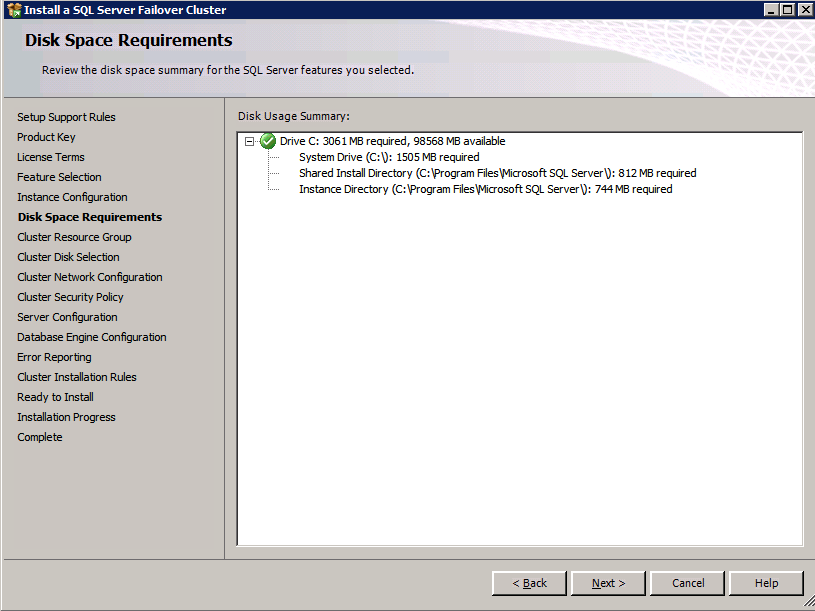 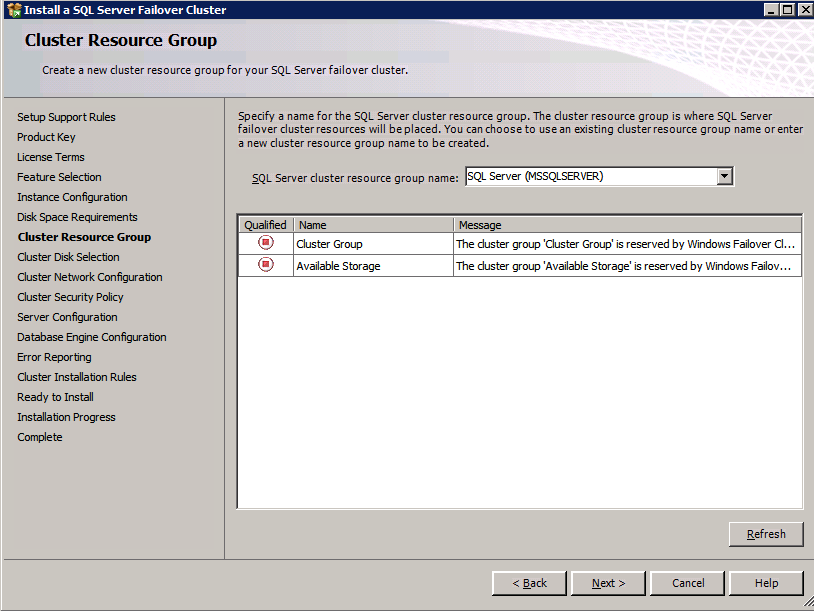 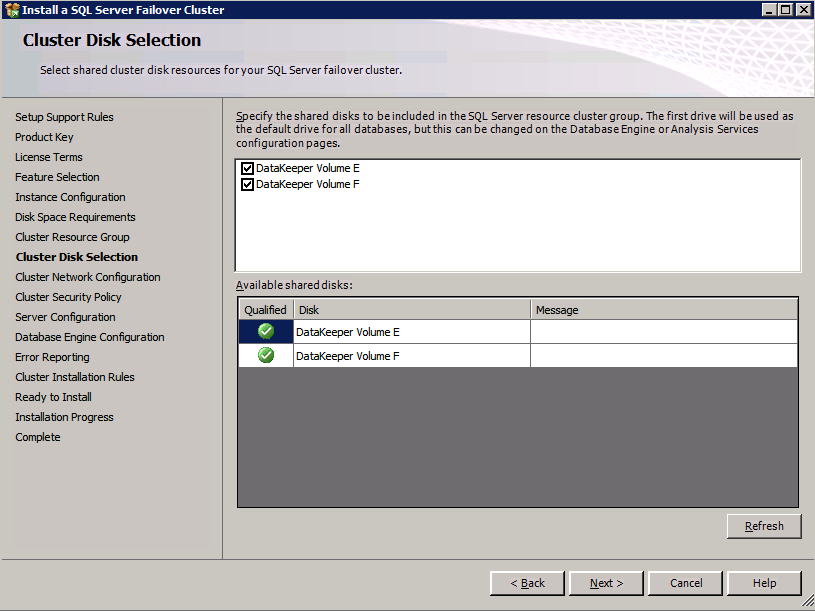 ที่นี่คุณจะต้องระบุที่อยู่ IP ที่ไม่ได้ใช้ 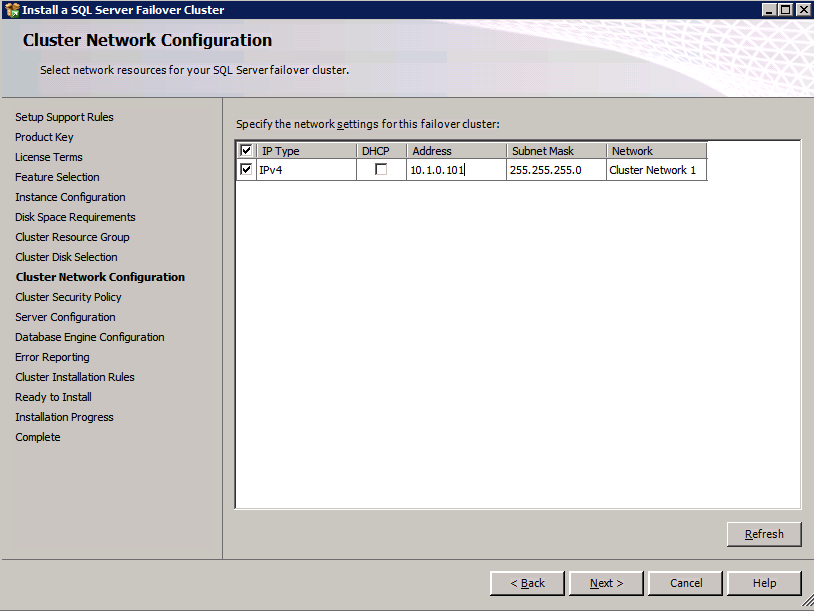 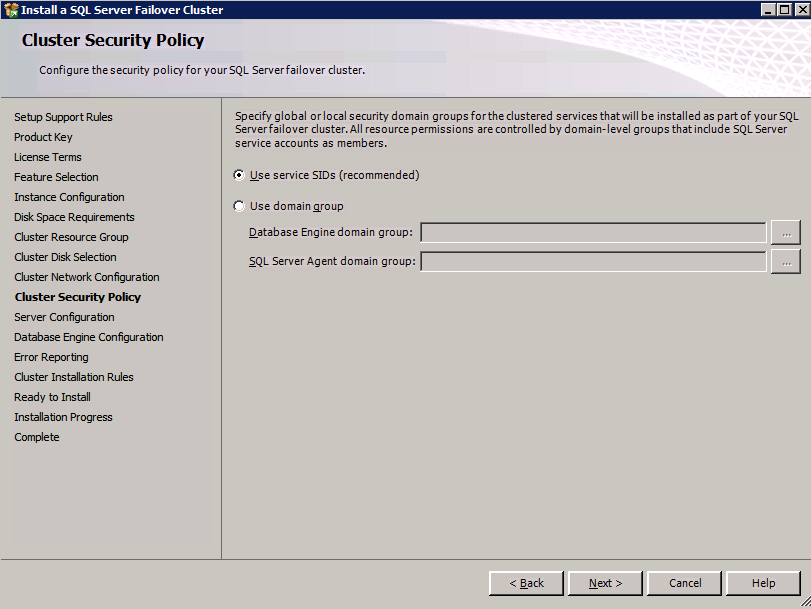 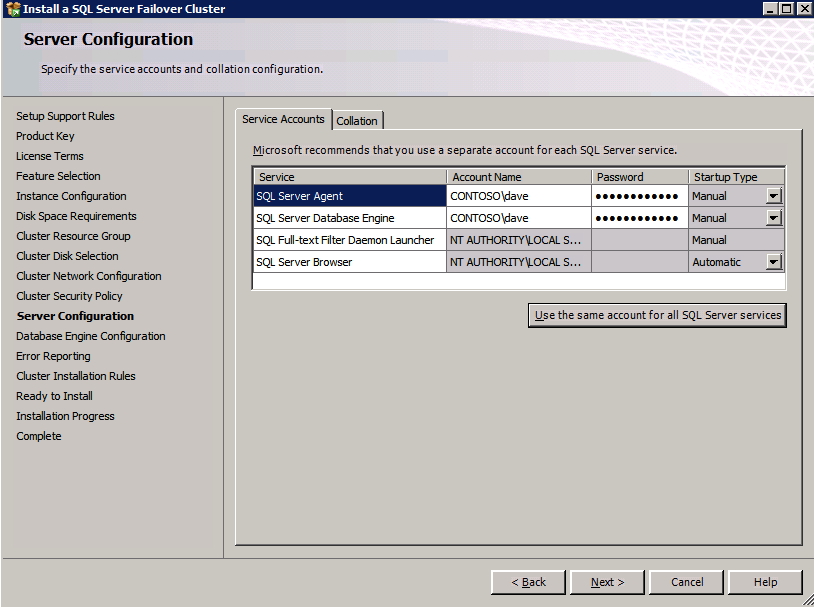 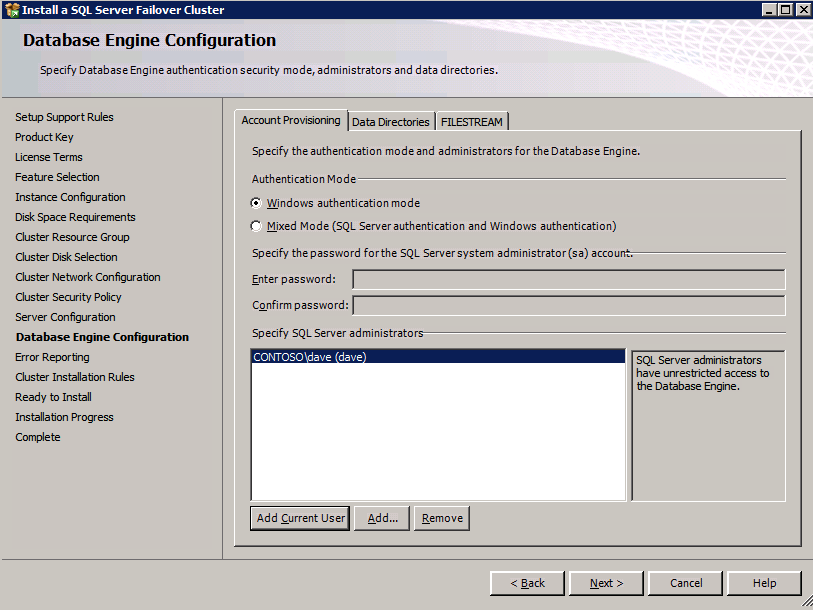 ไปที่แท็บ Data Directories และย้ายข้อมูลและไฟล์บันทึก ในตอนท้ายของคู่มือนี้เราพูดคุยเกี่ยวกับการย้าย tempdb ไปยังไดรฟ์ข้อมูล DataKeeper ที่ไม่ใช่มิร์เรอร์เพื่อประสิทธิภาพที่ดีที่สุด สำหรับตอนนี้ให้เก็บไว้ในดิสก์ที่ทำคลัสเตอร์อย่างใดอย่างหนึ่ง 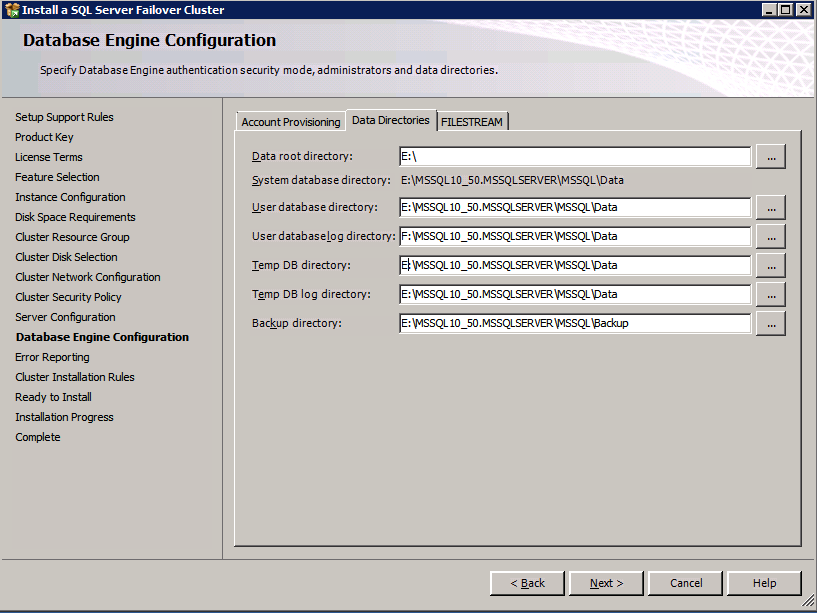     ติดตั้ง SQL บนโหนดที่สองเรียกใช้การตั้งค่าเซิร์ฟเวอร์ SQL อีกครั้งบนโหนดที่สอง จากนั้นเลือกเพิ่มโหนดใน SQL Server Failover Cluster 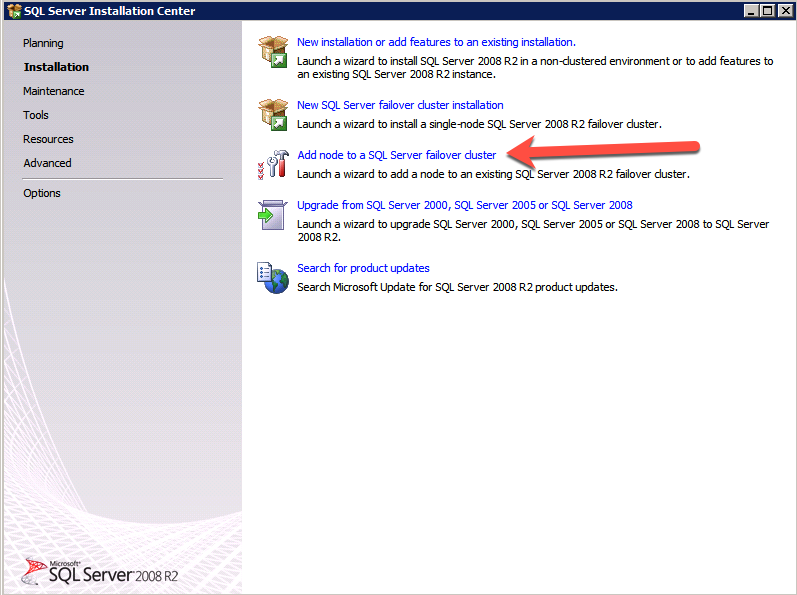 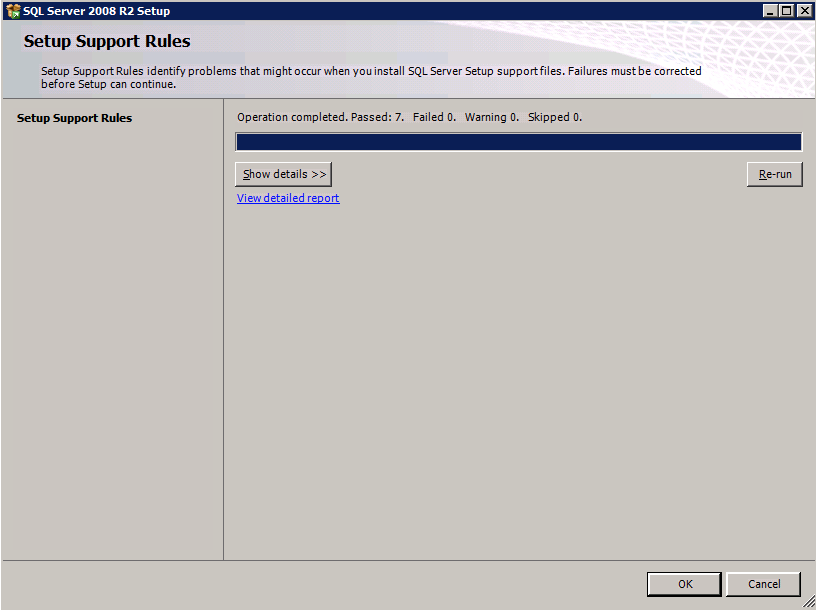 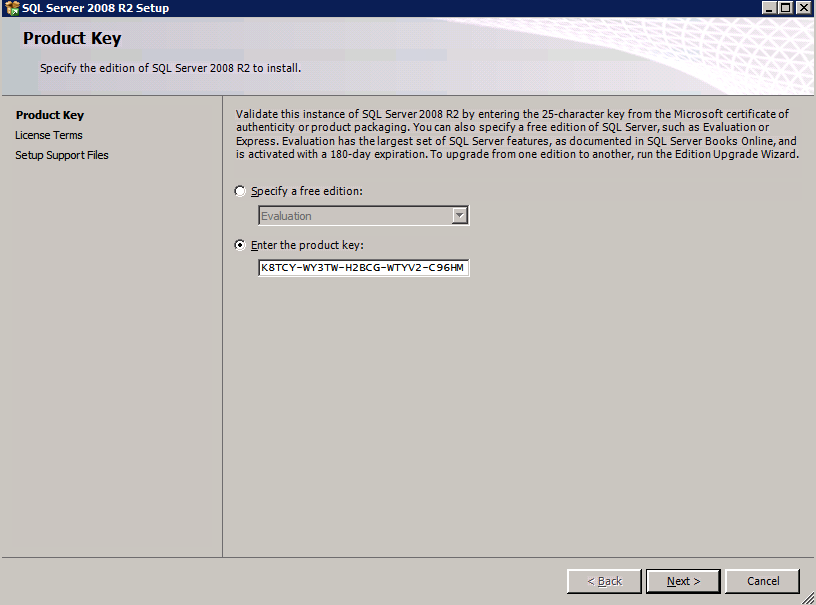          ยินดีด้วยคุณเกือบจะเสร็จแล้ว! อย่างไรก็ตามเนื่องจาก Azure ขาดการสนับสนุน ARP ที่ไม่มีค่าใช้จ่ายเราจะต้องกำหนดค่า Internal Load Balancer (ILB) เพื่อช่วยในการเปลี่ยนเส้นทางลูกค้าดังที่แสดงในขั้นตอนต่อไป อัปเดตที่อยู่ IP ของคลัสเตอร์ SQLเพื่อให้ ILB ทำงานได้อย่างถูกต้องคุณต้องรันคำสั่งต่อไปนี้จากหนึ่งในโหนดคลัสเตอร์ มัน SQL Cluster IP เปิดใช้งานที่อยู่ IP ของ SQL Cluster เพื่อตอบสนองต่อ ILB health probe ในขณะที่ตั้ง subnet mask เป็น 255.255.255.255 เพื่อหลีกเลี่ยง IP address ที่ขัดแย้งกับโพรบ health 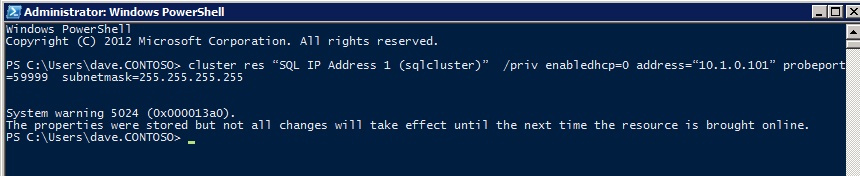 หมายเหตุ – ฉันไม่รู้ว่าเป็นความบังเอิญหรือไม่ ในบางครั้งฉันเรียกใช้คำสั่งนี้และดูเหมือนว่าจะใช้งานได้ แต่มันไม่ทำงานจนเสร็จและฉันต้องเริ่มใหม่อีกครั้ง วิธีที่ฉันสามารถบอกได้ว่าทำงานได้หรือไม่โดยดูที่ Subnet Mask ของทรัพยากร IP ของเซิร์ฟเวอร์ SQL หากไม่ใช่ 255.255.255.255 แสดงว่าคุณไม่สามารถทำงานได้สำเร็จ อาจเป็นปัญหาการรีเฟรช GUI ลองรีสตาร์ทคลัสเตอร์ GUI เพื่อตรวจสอบว่ามีการอัปเดตซับเน็ตมาสก์แล้ว หลังจากทำงานสำเร็จให้ใช้ทรัพยากรออฟไลน์และนำกลับมาออนไลน์เพื่อให้การเปลี่ยนแปลงมีผล 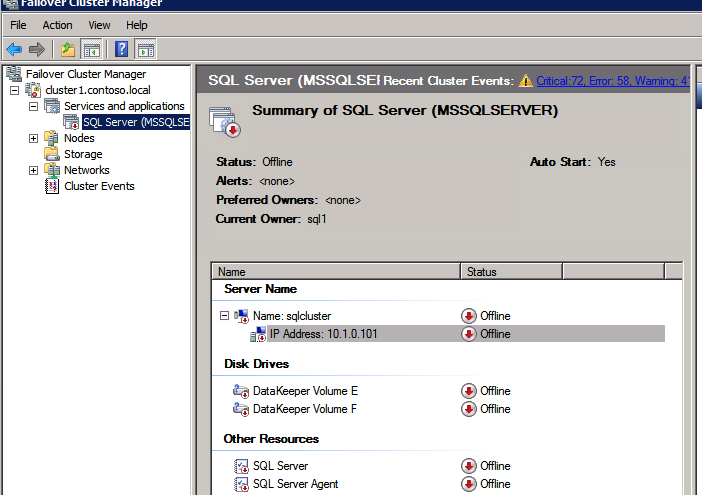 สร้างโหลดบาลานเซอร์ขั้นตอนสุดท้ายคือการสร้าง load balancer ในกรณีนี้เรากำลังสมมติว่าคุณกำลังใช้งานอินสแตนซ์เริ่มต้นของ SQL Server โดยฟังที่พอร์ต 1433 ที่อยู่ IP ส่วนตัวที่คุณกำหนดเมื่อคุณสร้างตัวโหลดบาลานซ์จะเป็นที่อยู่เดียวกับที่แน่นอนที่ SQL Server FCI ของคุณใช้ 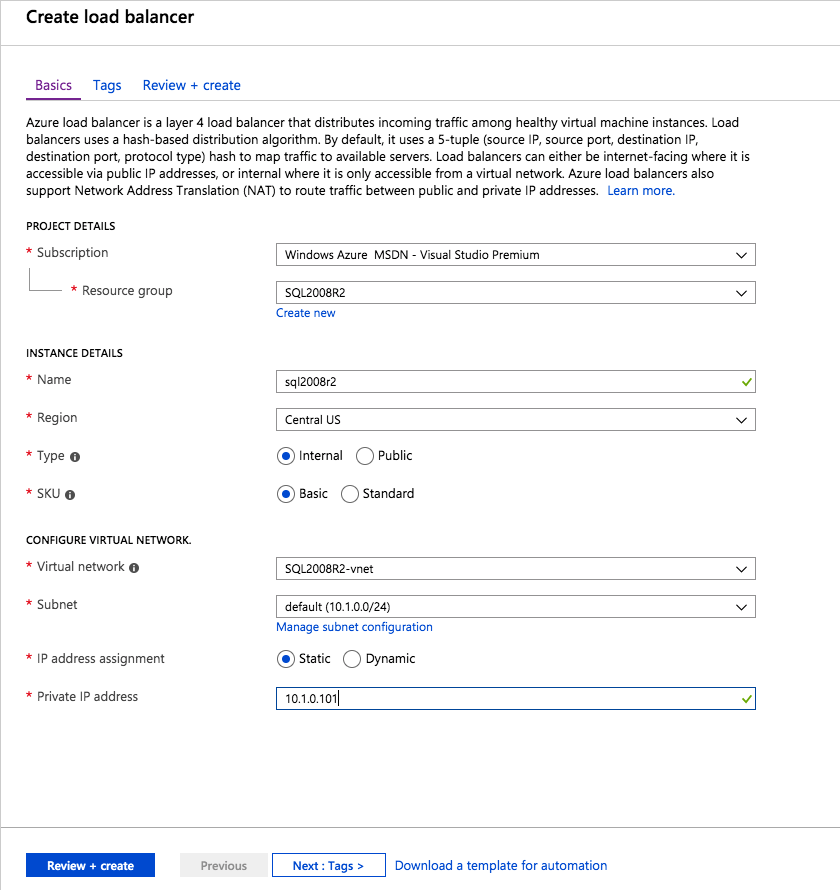 เพิ่มอินสแตนซ์ของ SQL Server เพียงสองอินสแตนซ์ให้กับพูลแบ็คเอนด์ ห้ามเพิ่ม FSW ลงในพูลแบ็คเอนด์ 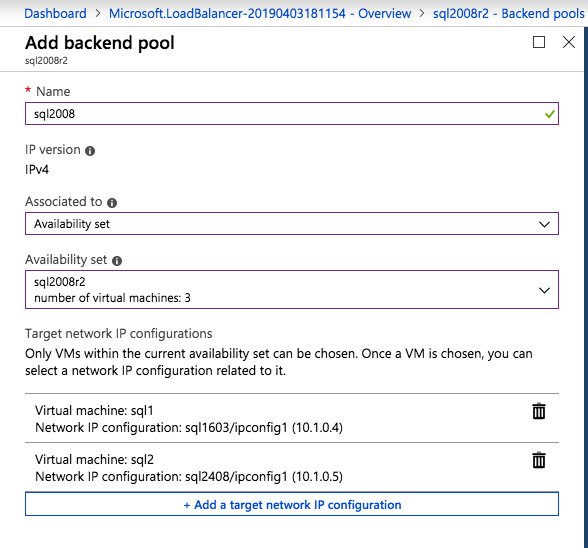 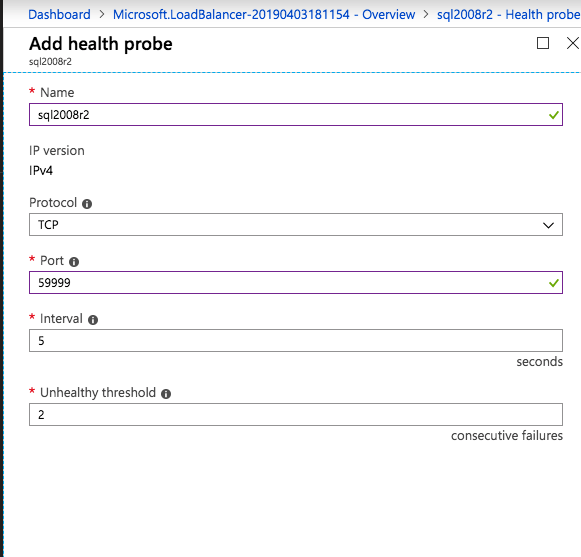 ในกฎดุลการโหลดนี้คุณต้องเปิดใช้ IP แบบลอย 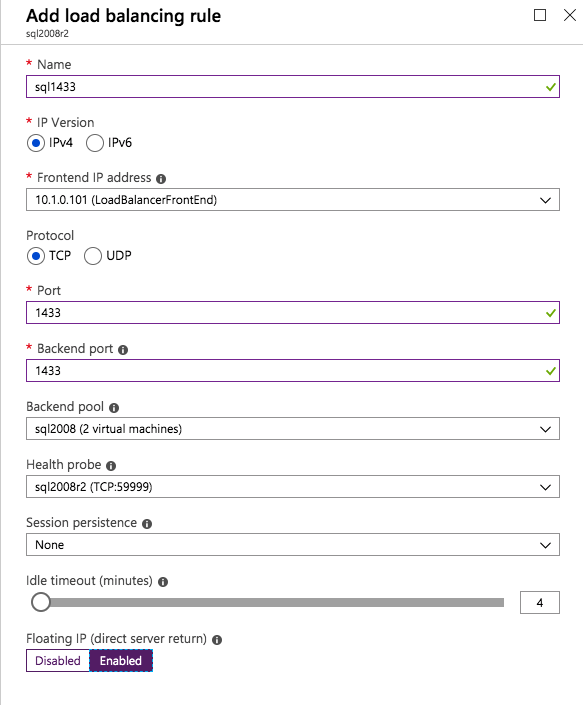 ทดสอบคลัสเตอร์การทดสอบที่ง่ายที่สุดคือการเปิด Studio จัดการเซิร์ฟเวอร์ SQL บนโหนดแฝงและเชื่อมต่อกับคลัสเตอร์ ขอแสดงความยินดี! คุณทำทุกอย่างถูกต้องในขณะที่มันเชื่อมต่อ! หากคุณไม่สามารถเชื่อมต่อได้โปรดอย่ากลัว ฉันเขียนบทความบล็อกเพื่อช่วยแก้ไขปัญหา การจัดการคลัสเตอร์นั้นเหมือนกับการจัดการคลัสเตอร์การจัดเก็บข้อมูลแบบเดิม ทุกอย่างถูกควบคุมผ่าน Failover Cluster Manager ไม่บังคับ – ย้าย TempDBเพื่อประสิทธิภาพที่ดีที่สุดขอแนะนำให้คุณย้าย tempdb ไปยัง SSD ที่ไม่ใช่แบบจำลองภายในเครื่อง แต่ SQL Server 2008 R2 ต้องการ tempdb ให้อยู่ในดิสก์ที่ทำคลัสเตอร์ SIOS มีวิธีการแก้ปัญหาที่เรียกว่าทรัพยากรปริมาณที่ไม่ใช่มิเรอร์ซึ่งแก้ไขปัญหานี้ ขอแนะนำให้สร้างทรัพยากรปริมาณที่ไม่ใช่มิร์เรอร์ของไดรฟ์ SSD ในเครื่องแล้วย้าย tempdb ไปที่นั่น โปรดทราบว่าไดรฟ์ SSD ในตัวเครื่องนั้นไม่ใช่แบบถาวร คุณต้องระมัดระวังเพื่อให้แน่ใจว่าโฟลเดอร์ที่เก็บ tempdb และสิทธิ์ในโฟลเดอร์นั้นถูกสร้างขึ้นใหม่ทุกครั้งที่รีบูทเซิร์ฟเวอร์ หลังจากที่คุณสร้าง Non-Mirrored Volume Resource ของโลคัล SSD ทำตามขั้นตอนในบทความนี้เพื่อย้าย tempdb สคริปต์เริ่มต้นที่อธิบายไว้ในบทความนั้นจะต้องเพิ่มในแต่ละโหนดคลัสเตอร์ ทำซ้ำโดยได้รับอนุญาตจาก Clusteringformeremortals.com |





