| กันยายน 10, 2020 |
วิธีการส่งมอบความพร้อมใช้งานสูงสำหรับ SQL Server ในสภาพแวดล้อม Linux
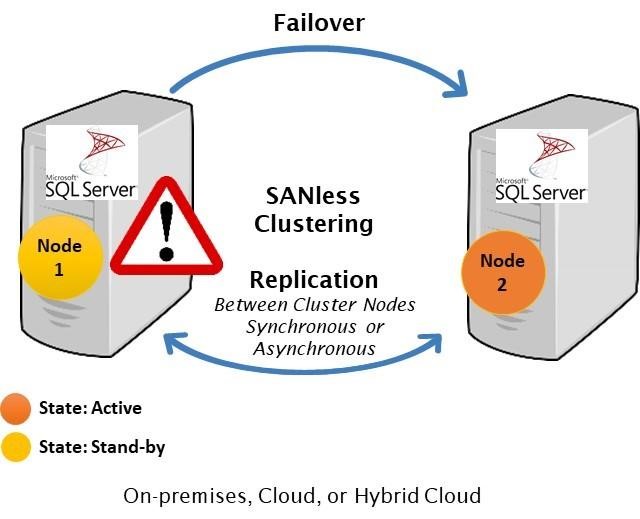
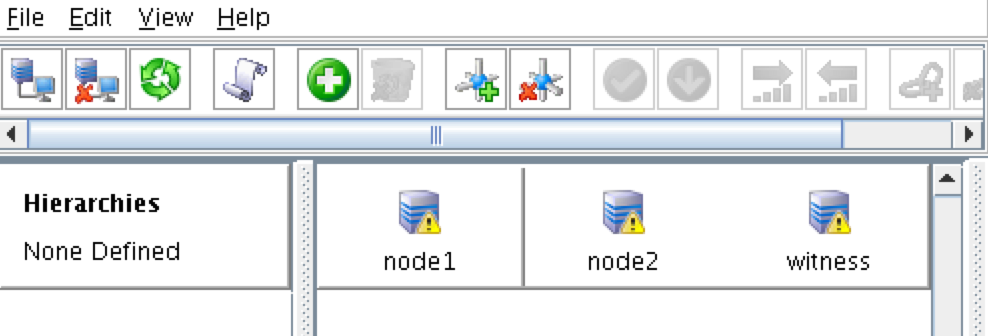
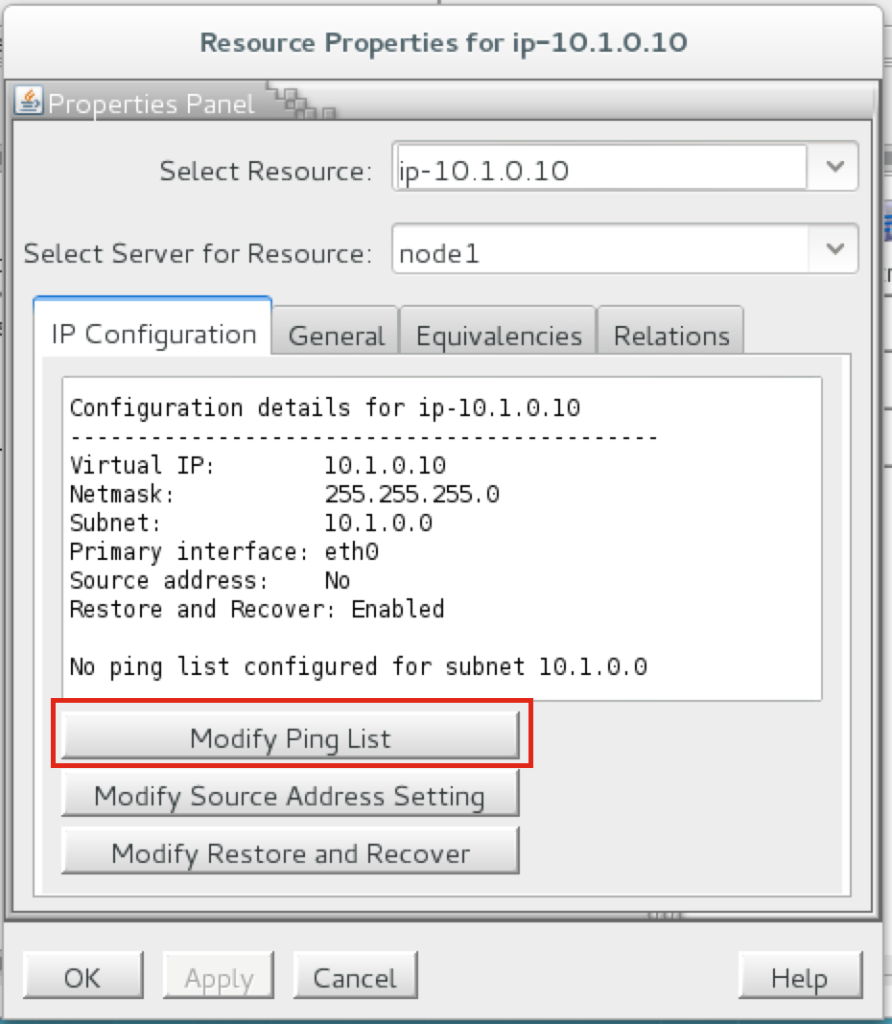
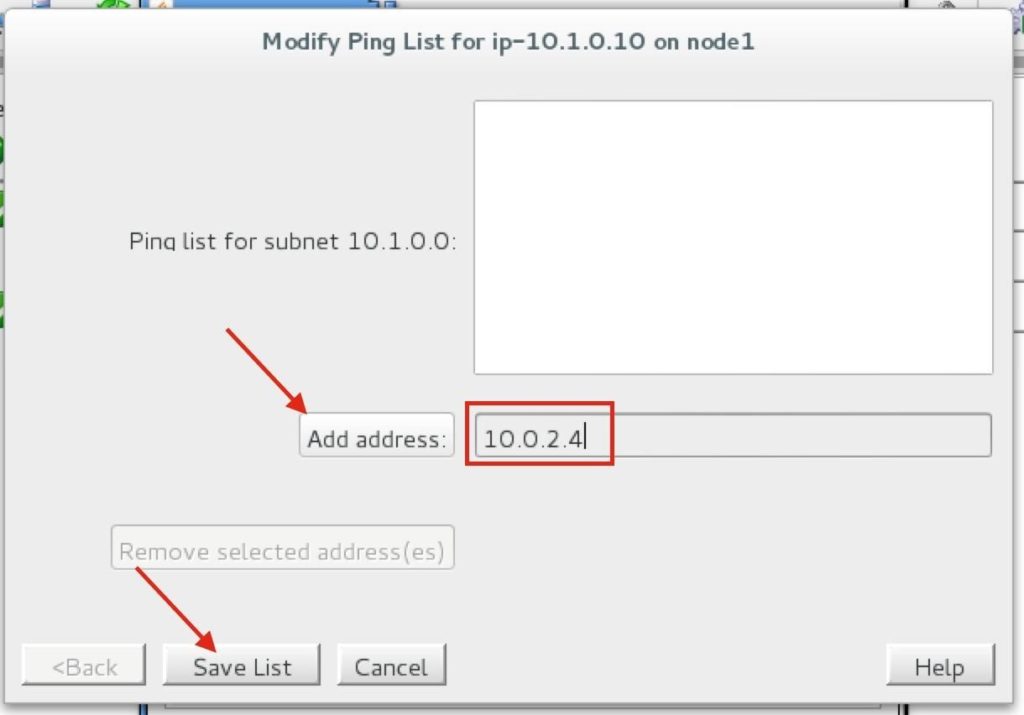
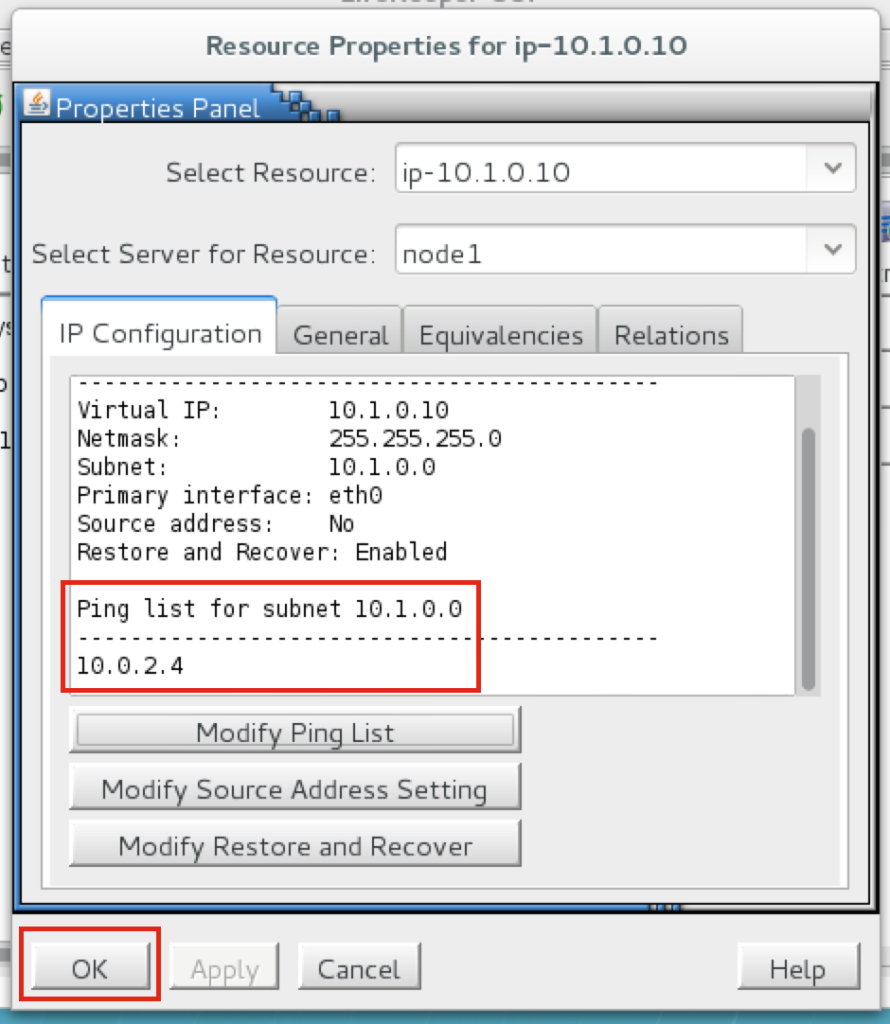
วิธีส่งมอบความพร้อมใช้งานสูงสำหรับ SQL Server ในสภาพแวดล้อม Linuxหากองค์กรของคุณใช้ Microsoft SQL Server ที่มีความสำคัญทางธุรกิจบน Linux ทีมไอทีของคุณจะรู้ดีว่าการรักษาความพร้อมใช้งานประสิทธิภาพและความปลอดภัยอย่างต่อเนื่องนั้นยากเพียงใด สิ่งที่ยากอย่างยิ่งคือการทำให้มั่นใจว่ามีความพร้อมใช้งานสูงด้วยการจำลองแบบที่มีประสิทธิภาพและการเฟลโอเวอร์อัตโนมัติ การใช้ซอฟต์แวร์โอเพนซอร์สและโซลูชันคลัสเตอร์ HA SANless ที่กำหนดค่าได้ง่ายสามารถนำเสนอแนวทางการบำรุงรักษาที่ง่ายขึ้นโดยไม่ต้องเสียสละความปลอดภัยและประสิทธิภาพที่องค์กรของคุณต้องการ ตัวเลือกความพร้อมใช้งานสูงที่ จำกัด สำหรับ Linuxการกระจาย Linux ส่วนใหญ่ทำให้แผนกไอทีมีทางเลือกที่ด้อยกว่าสองทางสำหรับความพร้อมใช้งานที่สูง: จ่ายเพิ่มสำหรับ SQL Server Enterprise Edition เพื่อใช้งาน Always On Availability Groups หรือพยายามทำให้การกำหนดค่า HA Linux ที่ซับซ้อนต้องทำด้วยตัวเองทำงานได้ดีซึ่งเป็นสิ่งที่สามารถพิเศษได้ ยากที่จะทำ ปัญหาในการใช้ Enterprise Edition คือมันทำลายกลยุทธ์การประหยัดต้นทุนสำหรับการใช้ระบบปฏิบัติการโอเพนซอร์สบนฮาร์ดแวร์สินค้าโภคภัณฑ์ สำหรับแอ็พพลิเคชัน SQL Server ขนาดเล็กจำนวน จำกัด อาจเป็นไปได้ที่จะปรับค่าใช้จ่ายเพิ่มเติม แต่ราคาแพงเกินไปสำหรับแอปพลิเคชันฐานข้อมูลจำนวนมากและจะไม่ทำอะไรเลยเพื่อจัดหา HA สำหรับ Linux สำหรับวัตถุประสงค์ทั่วไป การจัดเตรียม HA ในแอปพลิเคชันทั้งหมดที่ทำงานในสภาพแวดล้อม Linux สามารถทำได้โดยใช้ซอฟต์แวร์โอเพนซอร์สเช่น Pacemaker และ Corosync หรือ SUSE Linux Enterprise High Availability Extension แต่การทำให้ซอฟต์แวร์สแต็กเต็มรูปแบบทำงานได้ตามที่ต้องการจำเป็นต้องสร้าง (และทดสอบ) สคริปต์ที่กำหนดเองสำหรับแต่ละแอปพลิเคชันและสคริปต์เหล่านี้มักจะต้องได้รับการทดสอบและอัปเดตใหม่หลังจากที่มีการเปลี่ยนแปลงเล็กน้อยกับซอฟต์แวร์หรือฮาร์ดแวร์ที่ใช้ ความสามารถที่เกี่ยวข้องกับความพร้อมใช้งานที่ไม่ได้รับการสนับสนุนทั้งใน SQL Server Standard Edition และ Linux สามารถทำให้ความพยายามนี้ท้าทายมากขึ้น การค้นหาโซลูชันความพร้อมใช้งานสูงทางเลือกสำหรับ SQL Server ใน Linuxเพื่อให้ HA ทั้งประหยัดต้นทุนและใช้งานง่ายคุณอาจต้องการพิจารณาสองวิธีที่แตกต่างกันสำหรับวัตถุประสงค์ทั่วไป ระบบหนึ่งกำลังใช้ระบบที่ใช้หน่วยเก็บข้อมูลซึ่งปกป้องข้อมูลโดยการจำลองแบบภายในเครือข่ายพื้นที่จัดเก็บข้อมูล (SAN) ที่ซ้ำซ้อนและยืดหยุ่น วิธีนี้ไม่เชื่อเรื่องพระเจ้าเกี่ยวกับระบบปฏิบัติการโฮสต์ แต่ต้องการให้โครงสร้างพื้นฐาน SAN ทั้งหมดต้องได้รับจากผู้จำหน่ายรายเดียวและต้องอาศัยข้อกำหนดเกี่ยวกับความล้มเหลวแยกต่างหากเพื่อให้มีความพร้อมใช้งานสูง อีกวิธีหนึ่งคือการใช้โฮสต์และเกี่ยวข้องกับการสร้างคลัสเตอร์ SANless ที่ไม่เชื่อเรื่องพระเจ้าบนอินสแตนซ์เซิร์ฟเวอร์ Linux ในฐานะโอเวอร์เลย์ HA คลัสเตอร์เหล่านี้สามารถดำเนินการได้ทั้ง LAN และ WAN ในคลาวด์ส่วนตัวสาธารณะและไฮบริด การซ้อนทับยังไม่เชื่อเรื่องพระเจ้าโดยใช้แอปพลิเคชันทำให้องค์กรต่างๆมีโซลูชัน HA แบบสากลเดียวสำหรับทุกแอปพลิเคชัน แม้ว่าวิธีนี้จะใช้ทรัพยากรโฮสต์ แต่ก็มีราคาไม่แพงนักและปรับขนาดได้ง่ายในสภาพแวดล้อม Linux ตัวเลือกคลัสเตอร์ HA SANless ส่วนใหญ่มีการรวมกันของการจำลองข้อมูลระดับบล็อกแบบเรียลไทม์การตรวจสอบแอปพลิเคชันอย่างต่อเนื่องและนโยบายการกู้คืนสำหรับความล้มเหลว / ความล้มเหลวที่กำหนดค่าได้เพื่อปกป้องแอปพลิเคชันที่มีความสำคัญทางธุรกิจทั้งหมดรวมถึงแอปพลิเคชันที่ใช้อินสแตนซ์คลัสเตอร์แบบปิดตลอดเวลาที่มีอยู่ใน Standard Edition ของ SQL Server SIOS Technology Corp. นำเสนอโซลูชันคลัสเตอร์ HA SANless ที่มีประสิทธิภาพมากขึ้นสำหรับ Linux พร้อมความสามารถขั้นสูงที่ออกแบบมาเพื่อปลดปล่อยไอทีจากความซับซ้อนและความท้าทายในชีวิตประจำวันในการสนับสนุนและเพิ่มประสิทธิภาพโครงสร้างพื้นฐานคอมพิวเตอร์ โซลูชัน SIOS Protection Suite พร้อม LifeKeeper ให้:
ตัวอย่างเช่นคลัสเตอร์ SANless สามารถจัดการกับความล้มเหลวพร้อมกันสองครั้ง การทำงานพื้นฐานจะเหมือนกันใน LAN และ WAN รวมถึงคลาวด์ส่วนตัวสาธารณะและไฮบริด
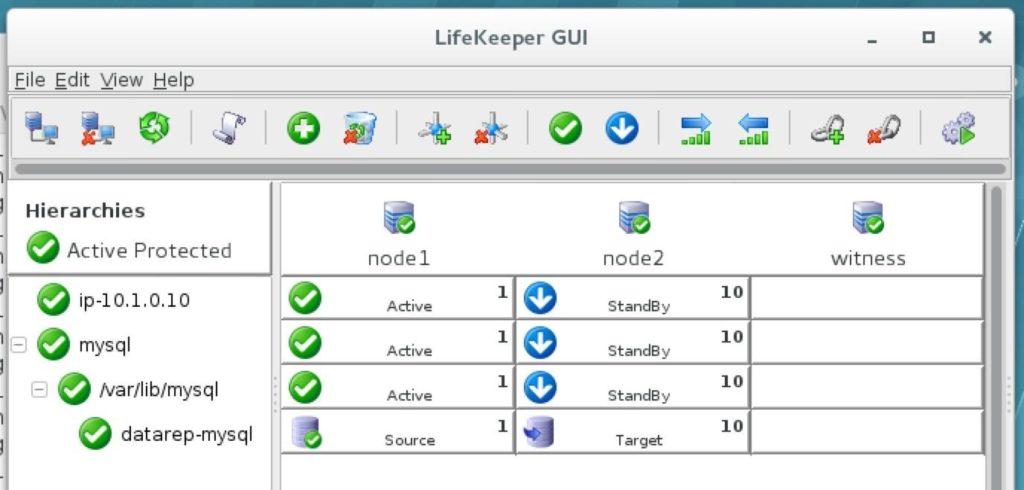
ในเซิร์ฟเวอร์คลัสเตอร์สองโหนดทั่วไป # 1 เริ่มแรกเป็นเซิร์ฟเวอร์หลักที่จำลองข้อมูลไปยังเซิร์ฟเวอร์ # ประสบปัญหาโดยอัตโนมัติทริกเกอร์ล้มเหลวไปยังเซิร์ฟเวอร์ # 2 ซึ่งตอนนี้กลายเป็นหลัก ในสถานการณ์เช่นนี้แผนกไอทีน่าจะเริ่มวินิจฉัยและซ่อมแซมปัญหาใดก็ตามที่ทำให้เซิร์ฟเวอร์ # 1 ล้มเหลว เมื่อแก้ไขแล้วอาจรับช่วงต่อเนื่องจากเซิร์ฟเวอร์หลักหรือเซิร์ฟเวอร์ # 2 สามารถดำเนินการต่อในความสามารถนั้นในการจำลองข้อมูลไปยังเซิร์ฟเวอร์ # 1 ด้วยการกำหนดค่าการทำคลัสเตอร์แบบ HA SANless ส่วนใหญ่การเฟลโอเวอร์จะเป็นไปโดยอัตโนมัติและทั้งเฟลโอเวอร์และเฟลแบ็คสามารถควบคุมได้โดยคอนโซลที่ใช้เบราว์เซอร์ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับโซลูชัน SIOS LifeKeeper และ Protection Suite โปรดไปที่ SIOS SAN และ SANless High Availability Clusters สำหรับสภาพแวดล้อมของเซิร์ฟเวอร์คลัสเตอร์ ทำซ้ำโดยได้รับอนุญาตจาก SIOS |
| กันยายน 6, 2020 |
วิธีเปิดใช้งานใบอนุญาตสำหรับซอฟต์แวร์ SIOS Clustering |
| สิงหาคม 30, 2020 |
จะเกิดอะไรขึ้นถ้าเรากำจัด Apache Downtime?
|
| สิงหาคม 25, 2020 |
เคล็ดลับในการกู้คืน SIOS Protection Suite สำหรับ Linux Configuration Specifics
เคล็ดลับในการกู้คืน SIOS Protection Suite สำหรับ Linux Configuration Specificsเยี่ยมมาก "สุ่มเพื่อนร่วมงาน"! และโดยดีฉันไม่ได้หมายถึงงานดีจริงๆ และโดย "Random Coworker" ฉันหมายถึงผู้ชายที่ทำเครื่องหมายในช่องที่ไม่ควรเลือกหรือยกเลิกการเลือกช่องที่ควรเลือกชายหรือหญิงที่ข้ามข้อความและคำเตือนและมาตรการความปลอดภัย "โปรดยืนยัน" และทำลายการกำหนดค่า SIOS Protection Suite สำหรับ Linux ของคุณ เราทุกคนเคยไปที่นั่น มันเป็นอุบัติเหตุ. อย่างไรก็ตามมันเกิดขึ้นมันเกิดขึ้น ทันใดนั้นคุณกำลังคิดหาสิ่งที่ต้องทำเพื่อกู้คืนการกำหนดค่าข้อมูลและ "อะไรก็ตาม" ก่อนที่เจ้านายจะรู้ ในฐานะรองประธานฝ่ายประสบการณ์ลูกค้าของ SIOS Technology Corp. ทีมงานของเรากำลังทำงานร่วมกับพันธมิตรและลูกค้าในการออกแบบและใช้ความพร้อมขององค์กรเพื่อป้องกันระบบของพวกเขาจากการหยุดทำงาน อุบัติเหตุเกิดขึ้นและประสบการณ์ล่าสุดของลูกค้าเตือนฉันว่าแม้จะมีการตรวจสอบและคำเตือนหลายครั้งของเราแม้แต่ผลิตภัณฑ์ SIOS Protection Suite สำหรับ Linux ก็ไม่ได้รับผลกระทบจากการเปลี่ยนแปลงการกำหนดค่าโดยไม่ได้ตั้งใจ แต่มีเคล็ดลับง่ายๆสำหรับการกู้คืนที่เร็วขึ้นจาก“ Random Coworker "ความผิดพลาดโดยบังเอิญ วิธีการกู้คืน SIOS Protection Suite สำหรับ Linux หลังจากเปลี่ยนแปลงการกำหนดค่าโดยบังเอิญมาพร้อมกับ SIOS Protection Suite สำหรับ Linux (SPS-L) เป็นเครื่องมือที่เรียกว่า lkbackup ซึ่งอยู่ภายใต้ / opt / LifeKeeper / bin / lkbackup เครื่องมือตามชื่ออาจแนะนำสร้างข้อมูลสำรองของรายละเอียดการกำหนดค่า SPS-L หมายเหตุ: เครื่องมือนี้ไม่ได้สำรองข้อมูลแอปพลิเคชันทั้งหมด แต่จะสร้างการสำรองข้อมูลทั้งหมดสำหรับการกำหนดค่า SPS-L เช่น: คำจำกัดความของทรัพยากรการปรับแต่งค่าในไฟล์ / etc / default / LifeKeeper ลูกค้าสร้างขึ้นโดยทั่วไป แอ็พพลิเคชันสคริปต์แฟล็กที่เกี่ยวข้องกับสถานะของคลัสเตอร์พา ธ การสื่อสาร / นิยามคลัสเตอร์และอื่น ๆ [root@baymax ~ ] # / opt / LifeKeeper / bin / lkbackup -c -f /root/mylkbackup-5.15.2020-v9.4.1 –cluster –ssh ตัวอย่าง: lkbackup สร้างไวยากรณ์ สิ่งนี้จะสร้างไฟล์สำรองชื่อ mylkbackup-5.15.2020-v9.4.1 ภายใต้โฟลเดอร์ / root –cluster บอกให้ lkbackup สร้างไฟล์เดียวกันบนแต่ละโหนดคลัสเตอร์ –ssh ใช้โปรโตคอล ssh เพื่อเชื่อมต่อกับโหนดคลัสเตอร์แต่ละโหนด รายละเอียด lkbackup เพิ่มเติมอยู่ที่นี่: ทีมบริการประสบการณ์ลูกค้าของเราขอแนะนำให้ทำการสำรองข้อมูลก่อนทำการเปลี่ยนแปลงการกำหนดค่า SPS-L เช่นการอัปเกรดการนำทรัพยากรออกหรือเพิ่มเติมหรือเปลี่ยนแปลงการกำหนดค่า ดังนั้นเมื่อคุณต้องการกู้คืนคอนฟิกูเรชัน SPS-L การเปลี่ยนแปลงทำได้ง่ายเพียงแค่เรียกใช้ lkbackup อีกครั้ง [root@baymax ~ ] # / opt / LifeKeeper / bin / lkbackup -x -f /root/mylkbackup-5.15.2020-v9.4.1 –cluster –ssh ตัวอย่าง: lkbackup restore syntax คุณสมบัติการสำรองข้อมูลอัตโนมัติจับไฟล์ lkbackup โดยอัตโนมัติแต่คุณจะทำอย่างไรถ้าคุณลืมเรียกใช้ lkbackup เพื่อสร้างไฟล์นี้ก่อนที่“ Random Coworker” ของคุณจะทำให้การตั้งค่าและการกำหนดค่า SPS-L ใช้เวลาไปหลายชั่วโมง คุณจะทำอย่างไรหาก“ Guy” หรือ“ Gal” ที่ตั้งค่า SPS-L อยู่ในช่วงพักร้อนลาเพื่อคลอดบุตรหรือลาคลอด จะเป็นอย่างไรถ้าคุณเป็น“ Random Coworker” และ Steve จากทีม Basis กำลังมุ่งหน้าไปตามโถงทางเดินเพื่อดูว่าสิ่งต่างๆเป็นอย่างไร สำหรับการติดตั้งส่วนใหญ่ SIOS จะเปิดใช้งานคุณลักษณะการสำรองข้อมูลอัตโนมัติระหว่างการติดตั้ง คุณลักษณะการสำรองข้อมูลอัตโนมัตินี้จะจับไฟล์ lkbackup ให้คุณโดยอัตโนมัติในเวลา 03.00 น. ตามเวลาท้องถิ่นภายใต้ /opt/LifeKeeper/config/auto-backup#.tgz [root@baymax ~]# ls -ltr /opt/LifeKeeper/config/auto-backup.*
ตัวอย่าง. เอาต์พุตจากรายการ config / auto-backup หากระบบของคุณได้รับการติดตั้งและกำหนดค่าอย่างถูกต้องการสำรองข้อมูลอัตโนมัติจะทำงานทุกคืนพร้อมที่จะครอบคลุมคุณเมื่อมีการประท้วง“ Random Coworker” ค้นหาการสำรองข้อมูลอัตโนมัติ SPS-L #. tgz ก่อนเกิดข้อผิดพลาดและใช้เครื่องมือ SPS-L lkbackup ดึงและกู้คืน SIOS Protection Suite สำหรับ Linux Configuration กลับสู่สถานะที่กำหนดค่าไว้ก่อนหน้านี้ [root@baymax ~ ] # lkstop; / opt / LifeKeeper / bin / lkbackup -c -f /opt/LifeKeeper/config/auto-backup.0.tgz ตัวอย่าง: lkbackup restore syntax สำหรับ auto-backup ทำซ้ำกับโหนดอื่นในคลัสเตอร์ตามต้องการ บันทึก. หากระบบของคุณไม่ได้รับการกำหนดค่าให้สร้างไฟล์สำรองข้อมูลอัตโนมัติและปกป้องคุณจาก“ Random Coworker” ของคุณเอง SIOS จะเสนอบริการติดตั้งและกำหนดค่าและการตรวจสอบการกำหนดค่าที่ดำเนินการโดย SIOS Professional Services Engineer – Cassius Rhue รองประธานฝ่ายประสบการณ์ลูกค้า ทำซ้ำโดยได้รับอนุญาตจาก SIOS |
| สิงหาคม 18, 2020 |
ทีละขั้นตอน: วิธีกำหนดค่าคลัสเตอร์ล้มเหลว SANless MySQL Linux ใน Amazon EC2
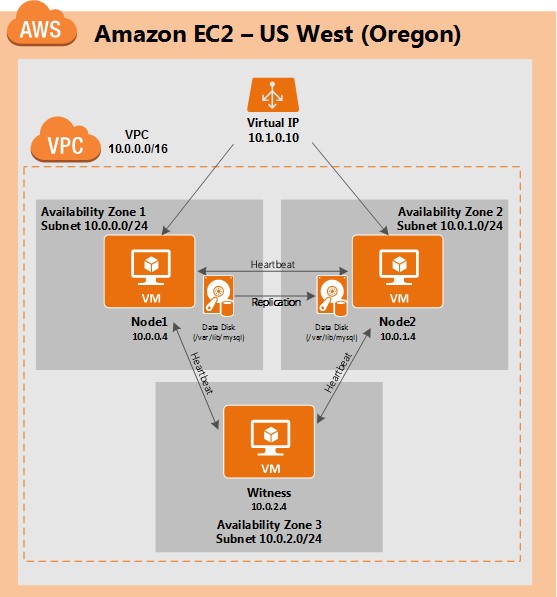
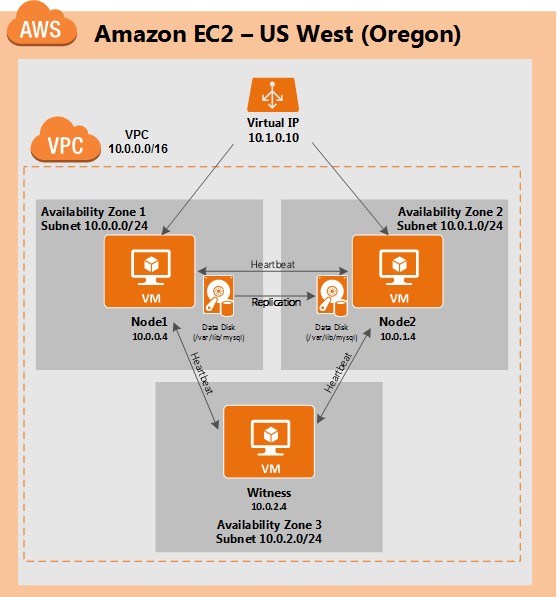
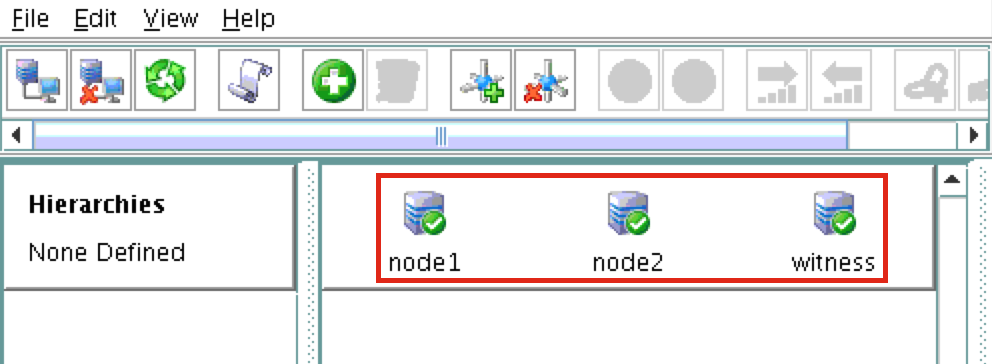
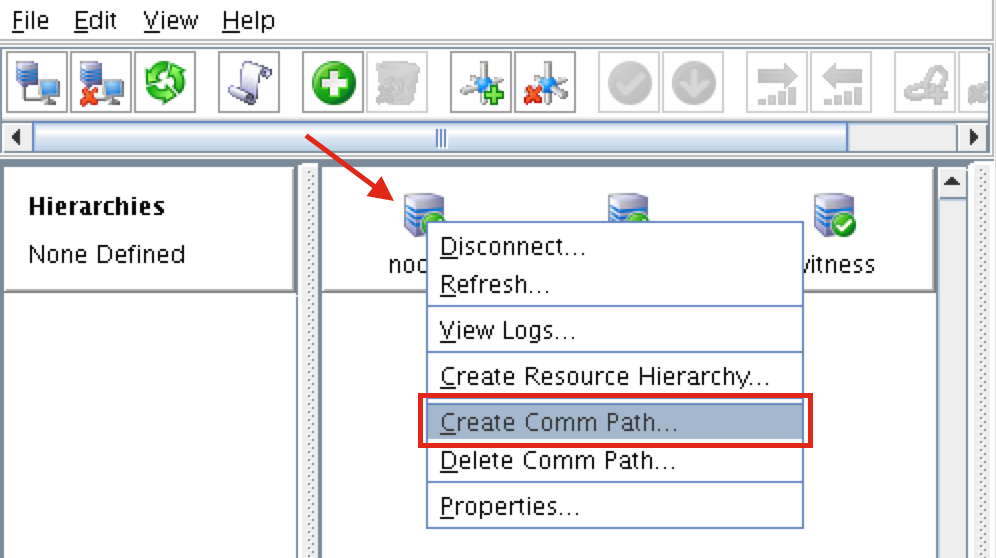
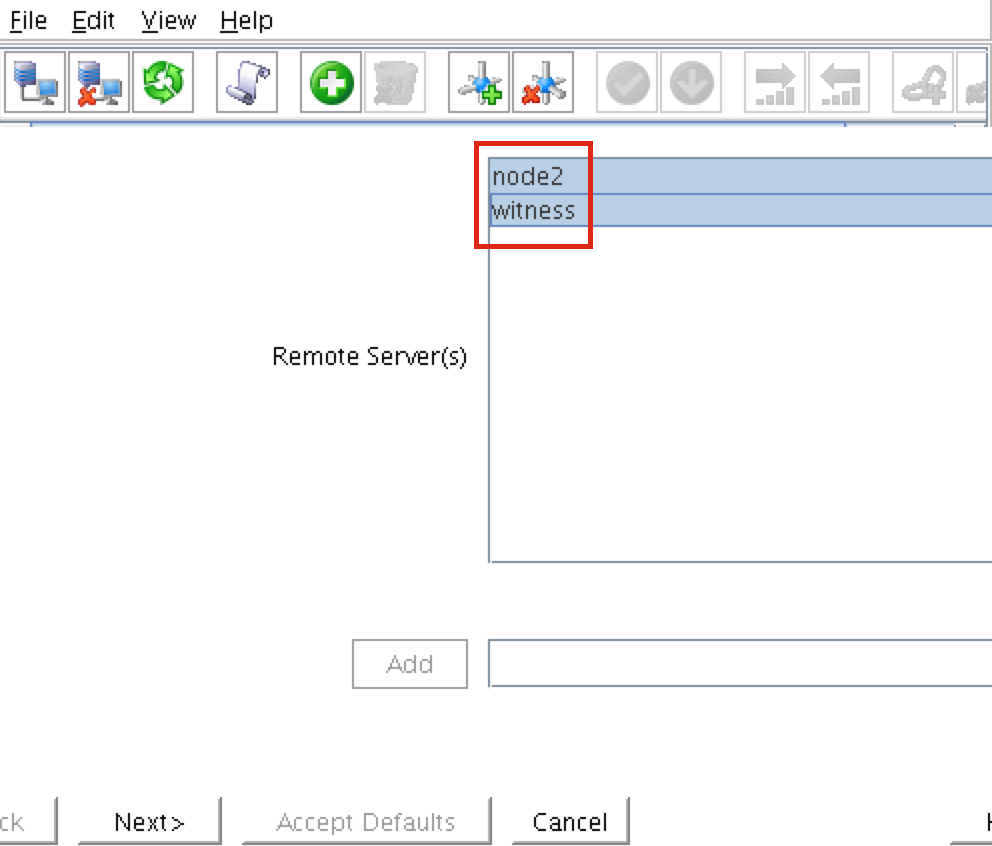
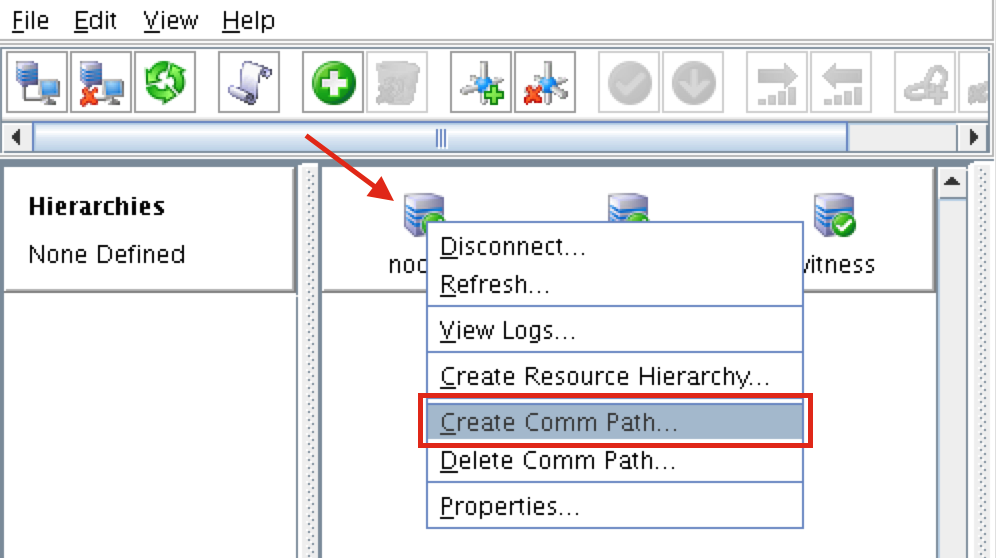
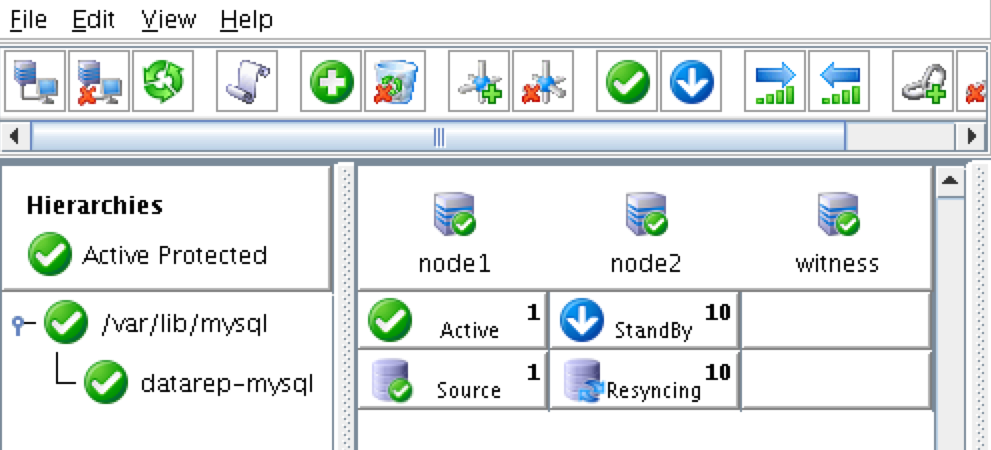
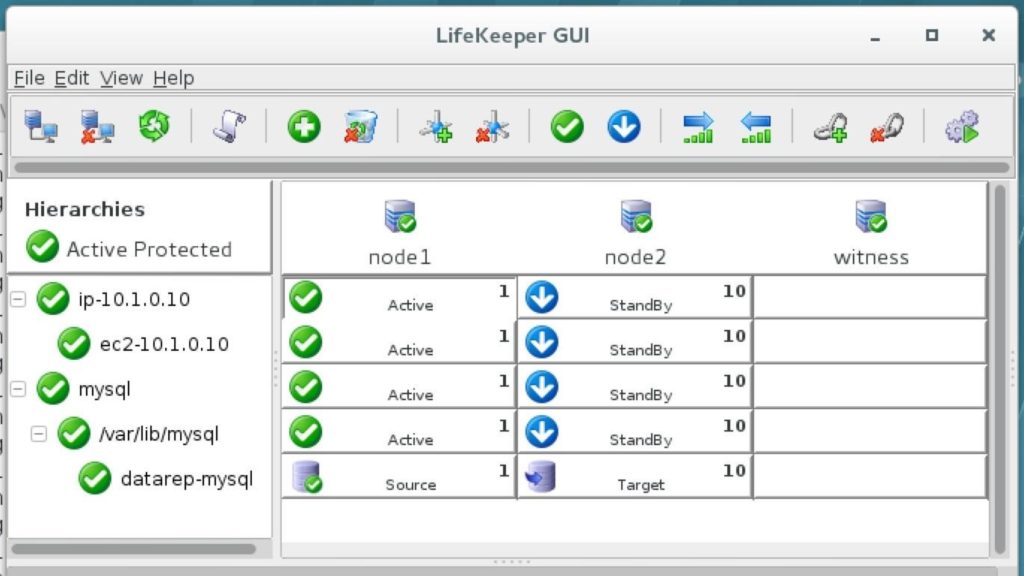
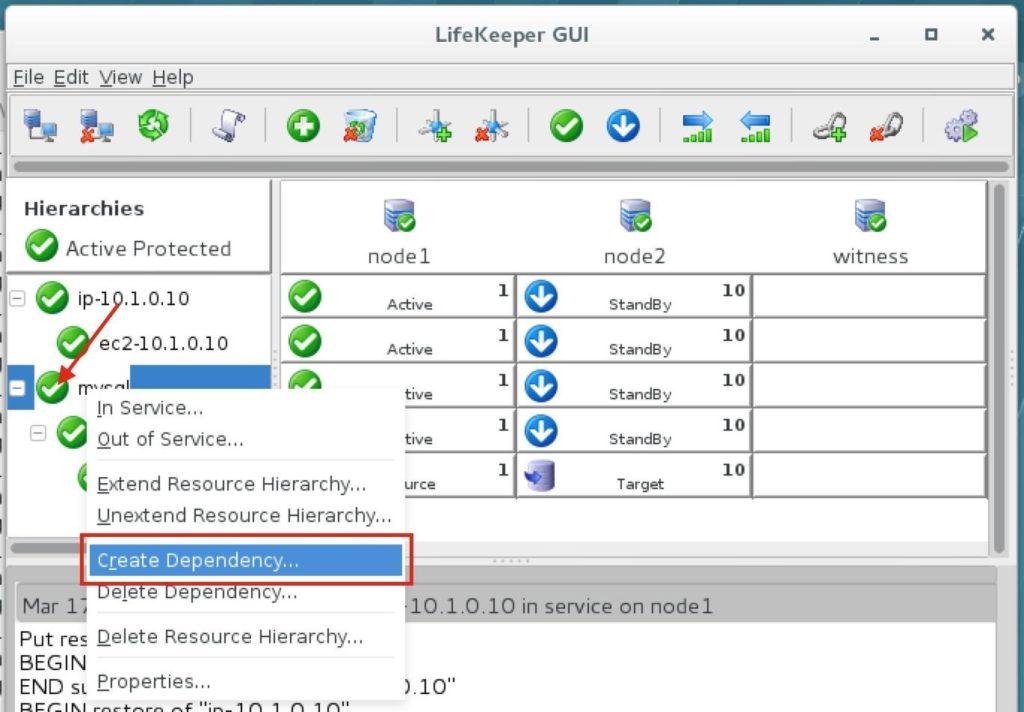
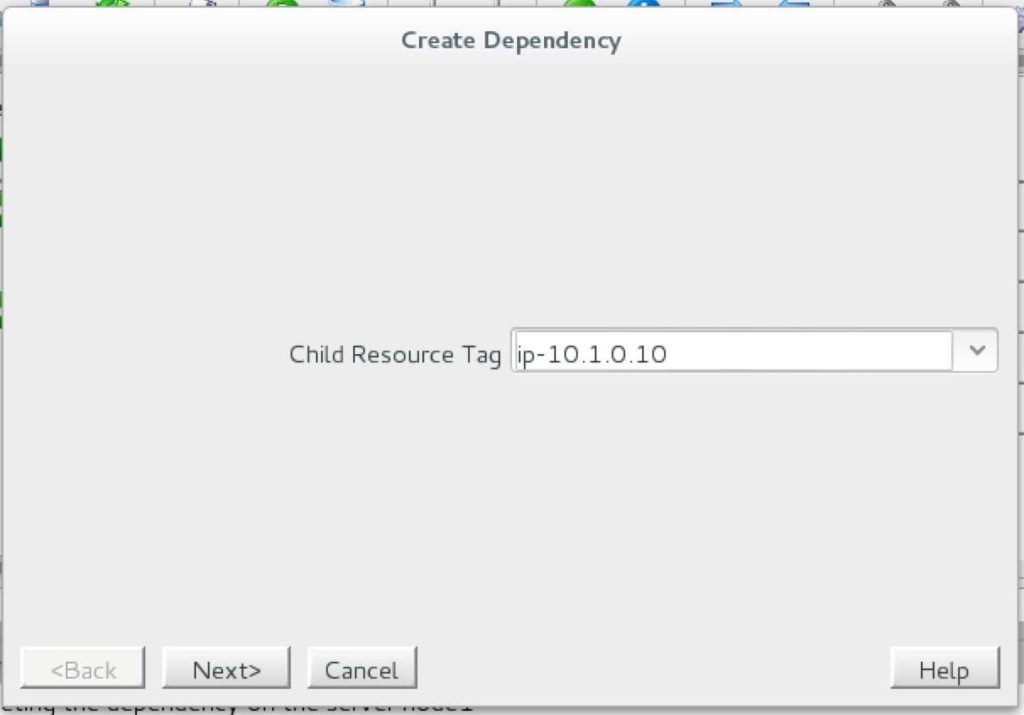
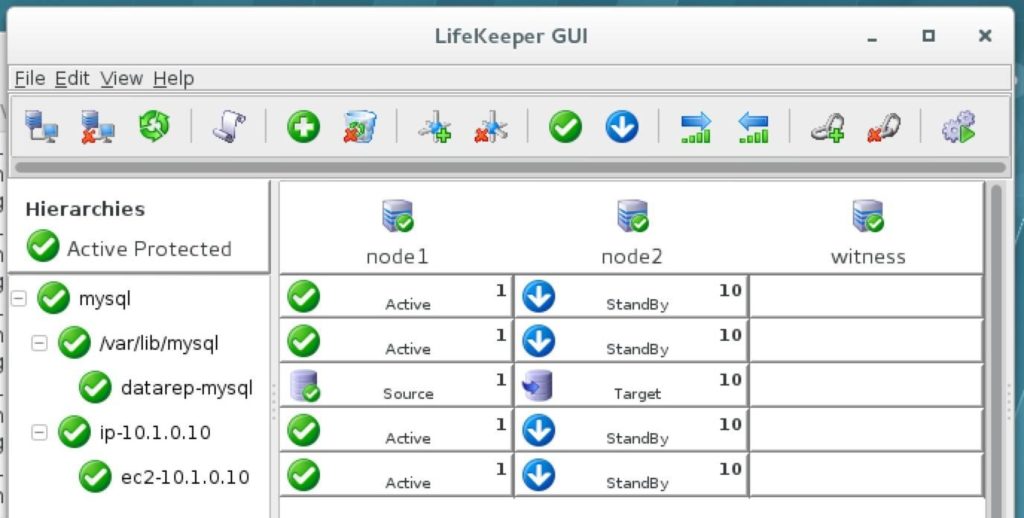
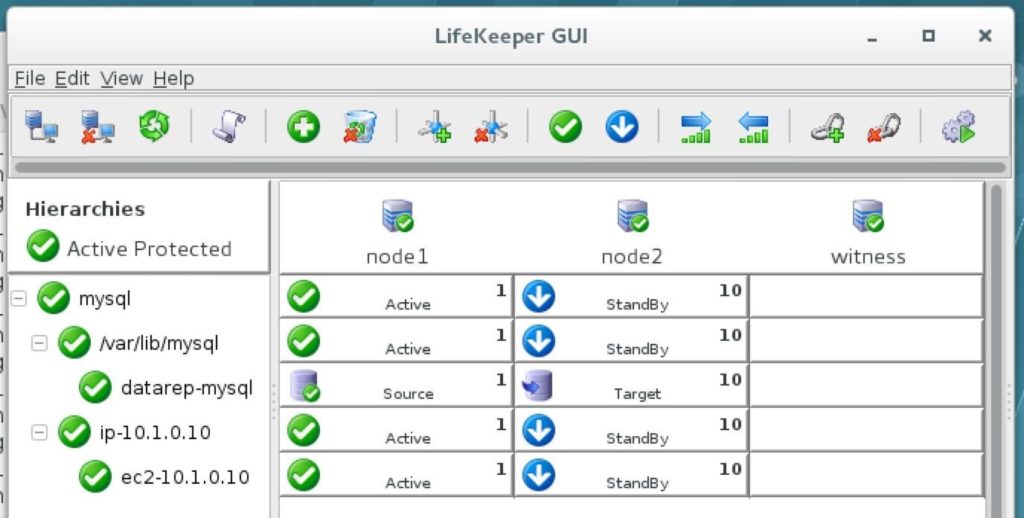
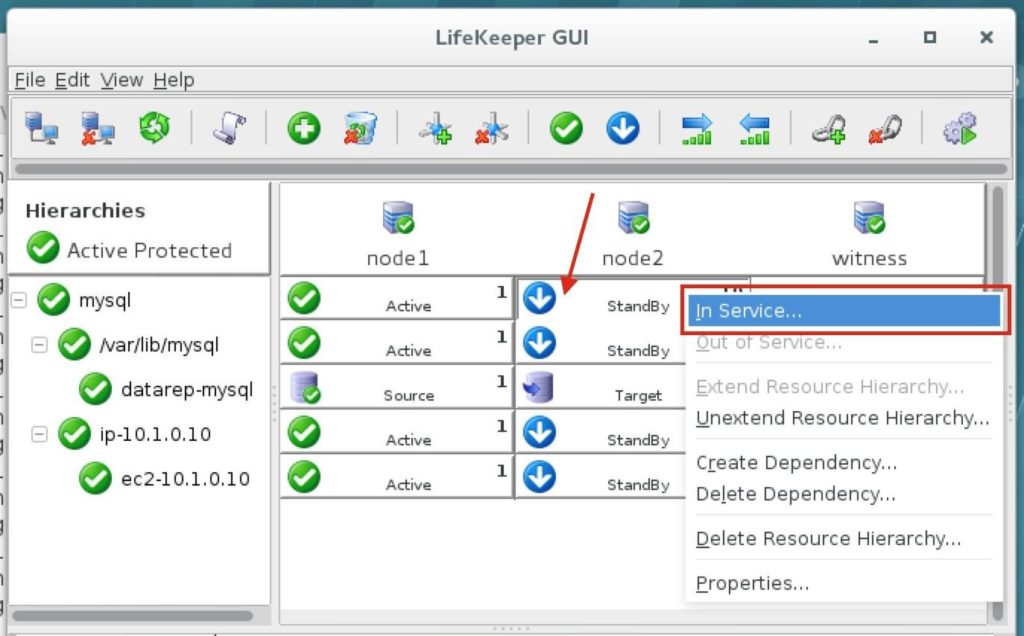
ทีละขั้นตอน: วิธีกำหนดค่าคลัสเตอร์ล้มเหลว SANless MySQL Linux ใน Amazon EC2ในคำแนะนำทีละขั้นตอนนี้ฉันจะนำคุณผ่านขั้นตอนทั้งหมดที่จำเป็นในการกำหนดค่าคลัสเตอร์ MySQL แบบ 2 โหนดที่พร้อมใช้งานสูง (รวมถึงเซิร์ฟเวอร์พยาน) ใน Elastic Compute Cloud ของ Amazon (Amazon EC2) คู่มือนี้มีทั้งภาพหน้าจอคำสั่งเชลล์และข้อมูลโค้ดตามความเหมาะสม ฉันคิดว่าคุณคุ้นเคยกับ Amazon EC2 และมีบัญชีอยู่แล้ว หากไม่เป็นเช่นนั้นคุณสามารถลงทะเบียนได้ตั้งแต่วันนี้ ฉันจะสมมติว่าคุณมีความคุ้นเคยพื้นฐานกับการดูแลระบบ Linux และแนวคิดการทำคลัสเตอร์แบบเฟลโอเวอร์เช่น Virtual IPs เป็นต้น Failover clustering มีมาหลายปีแล้ว ในการกำหนดค่าทั่วไปโหนดสองโหนดขึ้นไปจะถูกกำหนดค่าด้วยพื้นที่เก็บข้อมูลที่ใช้ร่วมกันเพื่อให้แน่ใจว่าในกรณีที่เกิดความล้มเหลวบนโหนดหลักโหนดรองหรือเป้าหมายจะเข้าถึงข้อมูลที่เป็นปัจจุบันที่สุด การใช้พื้นที่เก็บข้อมูลที่ใช้ร่วมกันไม่เพียง แต่เปิดใช้งานจุดกู้คืนที่ใกล้เป็นศูนย์เท่านั้น แต่ยังเป็นข้อกำหนดบังคับสำหรับซอฟต์แวร์การทำคลัสเตอร์ส่วนใหญ่ อย่างไรก็ตามพื้นที่เก็บข้อมูลที่ใช้ร่วมกันมีความท้าทายหลายประการ ประการแรกมันเป็นความเสี่ยงจุดเดียวของความล้มเหลว หากพื้นที่เก็บข้อมูลที่ใช้ร่วมกันซึ่งโดยทั่วไปคือ SAN ล้มเหลวโหนดทั้งหมดในคลัสเตอร์จะล้มเหลว ประการที่สอง SAN อาจมีราคาแพงและซับซ้อนในการซื้อติดตั้งและจัดการ ประการที่สามพื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกันในคลาวด์สาธารณะรวมถึง Amazon EC2 นั้นเป็นไปไม่ได้หรือไม่สามารถใช้งานได้จริงสำหรับ บริษัท ที่ต้องการรักษาความพร้อมใช้งานสูง (เวลาพร้อมใช้งาน 99.99%) เวลาในการกู้คืนที่ใกล้เป็นศูนย์และวัตถุประสงค์ของจุดกู้คืนและการป้องกันการกู้คืนจากภัยพิบัติ ต่อไปนี้แสดงให้เห็นว่าการสร้างคลัสเตอร์ SANless ในคลาวด์นั้นง่ายเพียงใดเพื่อขจัดความท้าทายเหล่านี้ในขณะที่พบกับ HA / DR SLA ที่เข้มงวด ขั้นตอนด้านล่างใช้ฐานข้อมูล MySQL กับ Amazon EC2 แต่สามารถปรับขั้นตอนเดียวกันเพื่อสร้างคลัสเตอร์ 2 โหนดใน AWS เพื่อปกป้อง SQL, SAP, Oracle หรือแอปพลิเคชันอื่น ๆ หมายเหตุ: มุมมองคุณสมบัติหน้าจอและปุ่มของคุณอาจแตกต่างจากภาพหน้าจอที่แสดงด้านล่างเล็กน้อย 1 สร้าง Virtual Private Cloud (VPC) ภาพรวมบทความนี้จะอธิบายวิธีสร้างคลัสเตอร์ภายในภูมิภาค Amazon EC2 เดียว โหนดคลัสเตอร์ (node1, node2 และเซิร์ฟเวอร์พยาน) จะอยู่ใน Availability Zones ที่แตกต่างกันเพื่อความพร้อมใช้งานสูงสุด นอกจากนี้ยังหมายความว่าโหนดจะอยู่ในเครือข่ายย่อยที่แตกต่างกัน
จะใช้ที่อยู่ IP ต่อไปนี้:
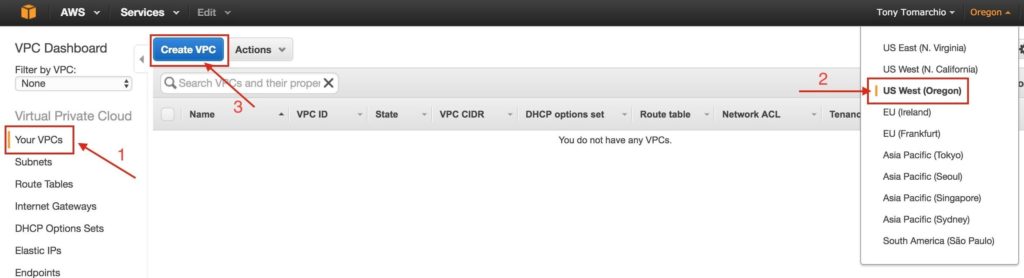
ขั้นตอนที่ 1: สร้าง Virtual Private Cloud (VPC)ขั้นแรกสร้าง Virtual Private Cloud (aka VPC) VPC คือเครือข่ายแยกต่างหากภายในคลาวด์ของ Amazon ที่ทุ่มเทให้กับคุณ คุณสามารถควบคุมสิ่งต่างๆได้อย่างเต็มที่เช่นบล็อกที่อยู่ IP และเครือข่ายย่อยตารางเส้นทางกลุ่มความปลอดภัย (เช่นไฟร์วอลล์) และอื่น ๆ คุณจะเปิดตัวเครื่องเสมือน Azure Iaas (VMs) ของคุณในเครือข่ายเสมือนของคุณ จากแดชบอร์ด AWS หลักเลือก“ VPC”
ภายใต้“ VPC ของคุณ” ตรวจสอบให้แน่ใจว่าคุณได้เลือกภูมิภาคที่เหมาะสมที่ด้านบนขวาของหน้าจอ ในคู่มือนี้จะใช้ภูมิภาค“ US West (Oregon)” เนื่องจากเป็นภูมิภาคที่มี Availability Zone 3 แห่ง สำหรับข้อมูลเพิ่มเติมเกี่ยวกับภูมิภาคและโซนความพร้อมใช้งานคลิกที่นี่
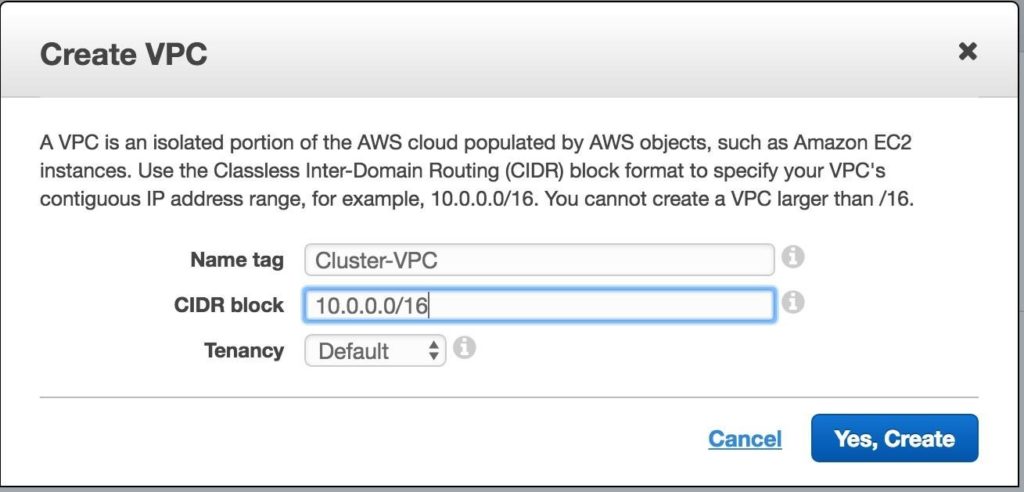
ตั้งชื่อ VPC และระบุบล็อก IP ที่คุณต้องการใช้ 10.0.0.0/16 จะใช้ในคู่มือนี้:
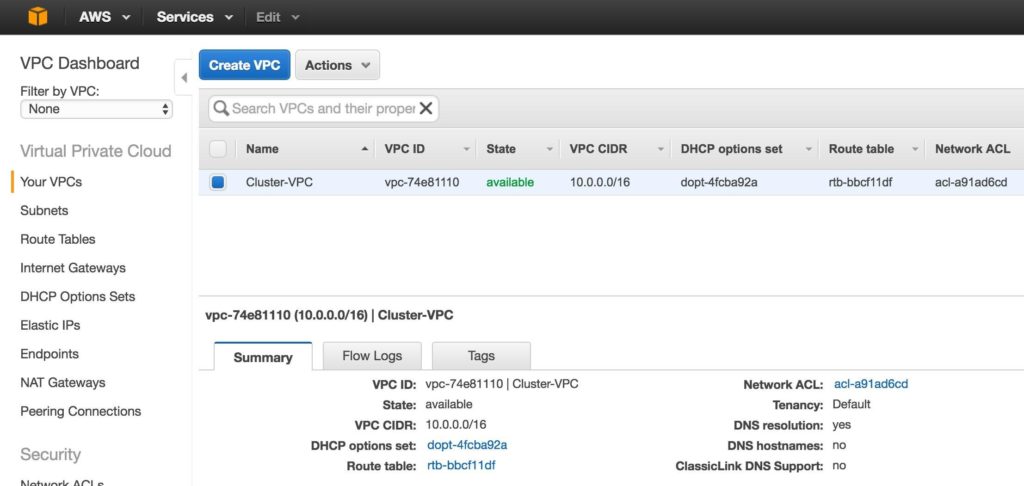
ตอนนี้คุณควรเห็น VPC ที่สร้างขึ้นใหม่บนหน้าจอ“ VPC ของคุณ”:
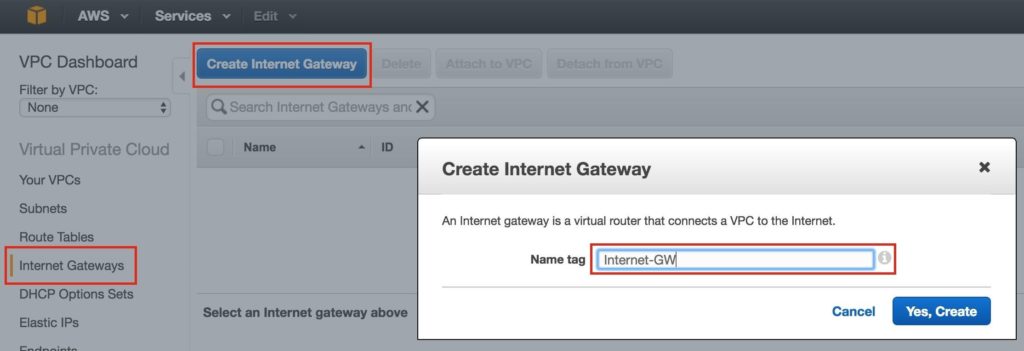
ขั้นตอนที่ 2: สร้างอินเทอร์เน็ตเกตเวย์จากนั้นสร้างอินเทอร์เน็ตเกตเวย์ สิ่งนี้จำเป็นหากคุณต้องการให้อินสแตนซ์ (VM) ของคุณสามารถสื่อสารกับอินเทอร์เน็ตได้ ที่เมนูด้านซ้ายเลือกเกตเวย์อินเทอร์เน็ตแล้วคลิกปุ่มสร้างเกตเวย์อินเทอร์เน็ต ตั้งชื่อและสร้าง:
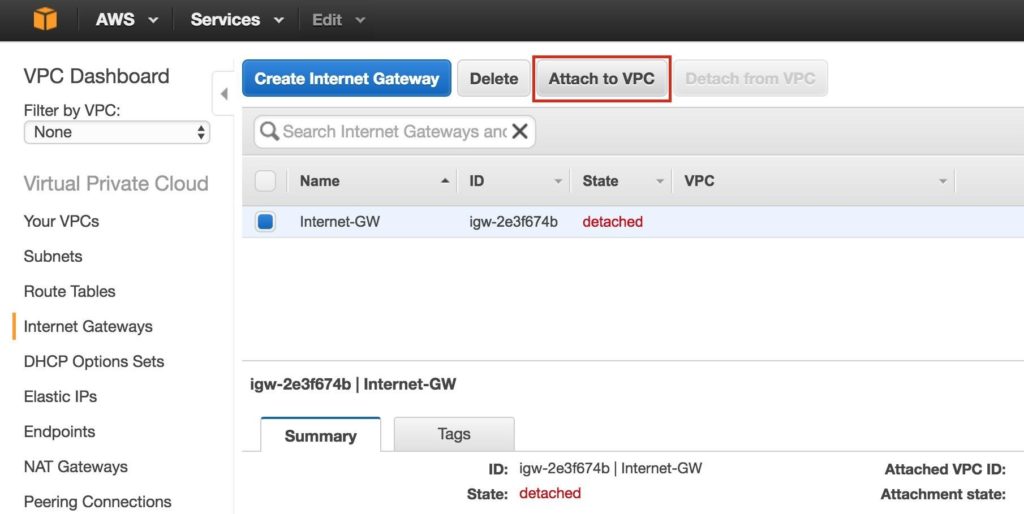
จากนั้นแนบอินเทอร์เน็ตเกตเวย์เข้ากับ VPC ของคุณ:
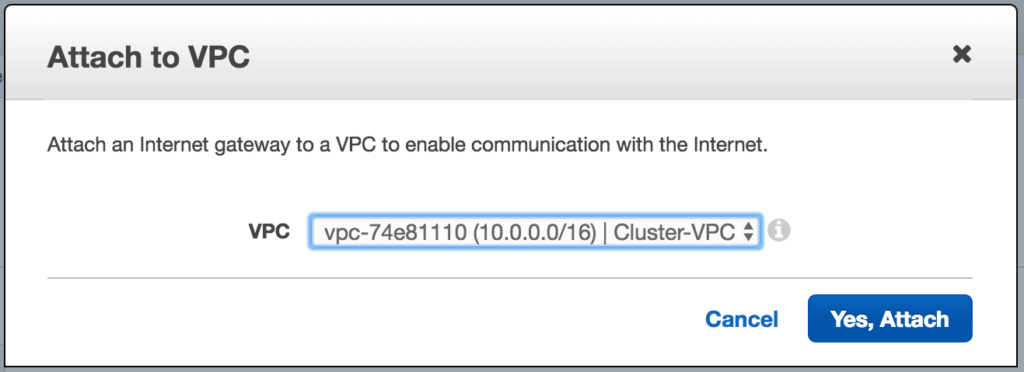
เลือก VPC ของคุณแล้วคลิกแนบ:
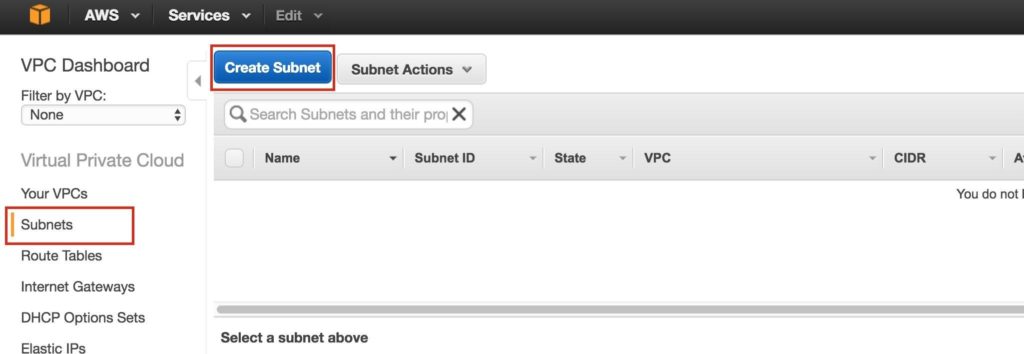
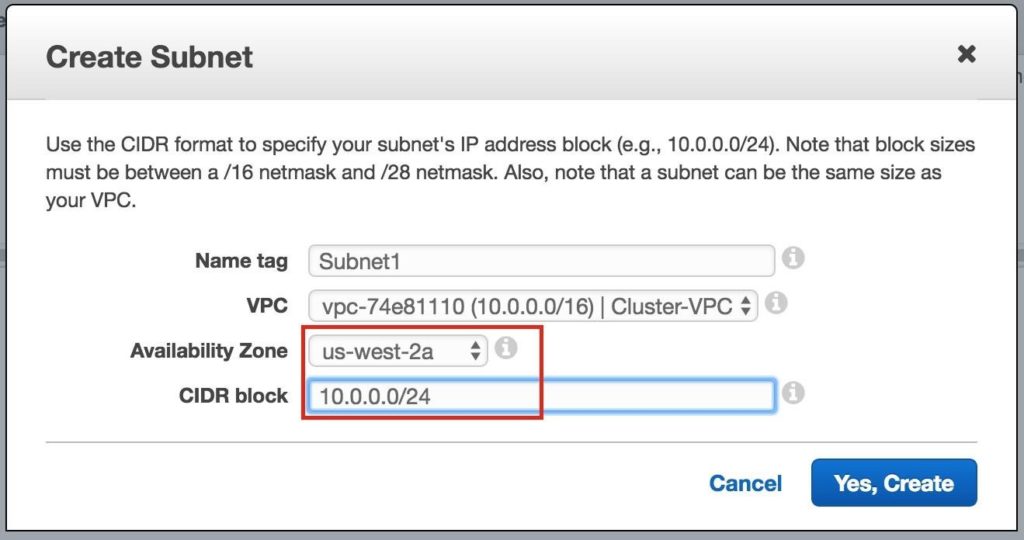
ขั้นตอนที่ 3: สร้างเครือข่ายย่อย (โซนความพร้อมใช้งาน)จากนั้นสร้าง 3 เครือข่ายย่อย เครือข่ายย่อยแต่ละเครือข่ายจะอยู่ใน Availability Zone ของตนเอง อินสแตนซ์ 3 อินสแตนซ์ (VMs: node1, node2, พยาน) จะถูกเรียกใช้ในเครือข่ายย่อยแยกกัน (ดังนั้น Availability Zone) ดังนั้นความล้มเหลวของ Availability Zone จะไม่นำโหนดหลายโหนดออกจากคลัสเตอร์ ภูมิภาคตะวันตกของสหรัฐอเมริกา (ออริกอน) หรือที่เรียกว่า us-west-2 มี 3 โซนให้บริการ (us-west-2a, us-west-2b, us-west-2c) สร้างเครือข่ายย่อย 3 เครือข่ายหนึ่งในแต่ละโซนความพร้อมใช้งาน 3 โซน ภายใต้ VPC Dashboard ไปที่ Subnets จากนั้นสร้าง Subnet:
ตั้งชื่อซับเน็ตแรก (“ Subnet1)” เลือกโซนความพร้อมใช้งาน us-west-2a และกำหนดบล็อกเครือข่าย (10.0.0.0/24):
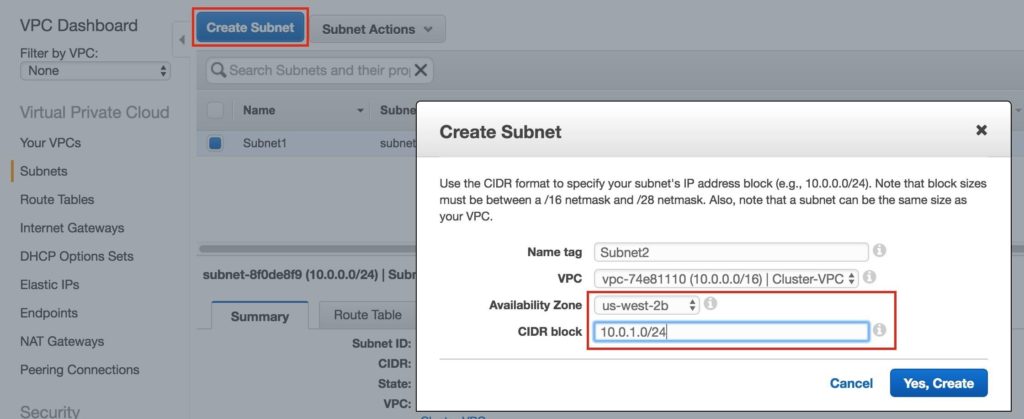
ทำซ้ำเพื่อสร้างโซนความพร้อมใช้งานซับเน็ตที่สอง us-west-2b:
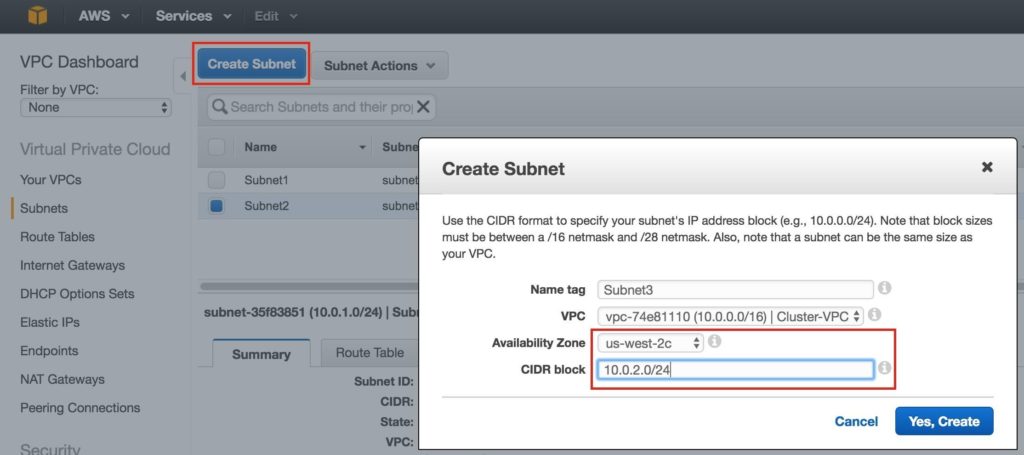
ทำซ้ำเพื่อสร้างซับเน็ตที่สามในโซนความพร้อมใช้งาน us-west-2c:
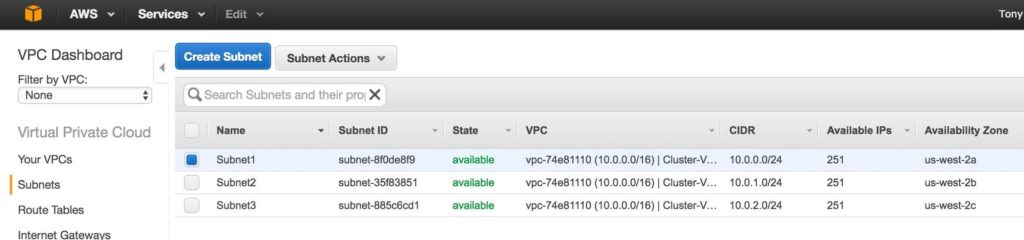
เมื่อดำเนินการเสร็จแล้วให้ตรวจสอบว่าเครือข่ายย่อย 3 เครือข่ายถูกสร้างขึ้นโดยแต่ละเครือข่ายมีบล็อก CIDR ที่แตกต่างกันและใน Availability Zone ที่แยกจากกันดังที่แสดงด้านล่าง:
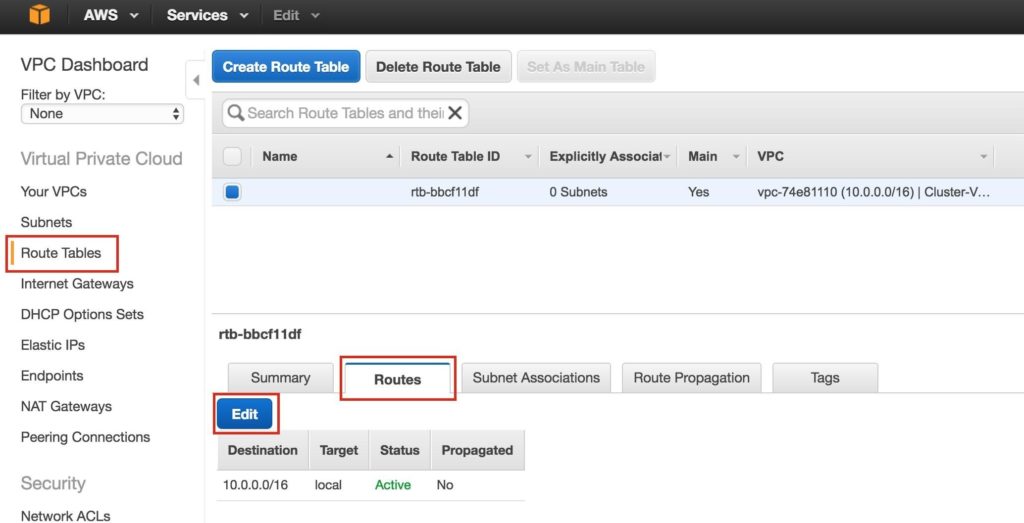
ขั้นตอนที่ 4: กำหนดค่าตารางเส้นทางอัปเดตตารางเส้นทางของ VPC เพื่อให้การรับส่งข้อมูลไปยังโลกภายนอกถูกส่งไปยังอินเทอร์เน็ตเกตเวย์ที่สร้างขึ้นในขั้นตอนก่อนหน้า จากแดชบอร์ด VPC เลือกตารางเส้นทาง ไปที่แท็บเส้นทางและโดยค่าเริ่มต้นจะมีเพียงเส้นทางเดียวที่อนุญาตให้รับส่งข้อมูลภายใน VPC เท่านั้น คลิกแก้ไข:
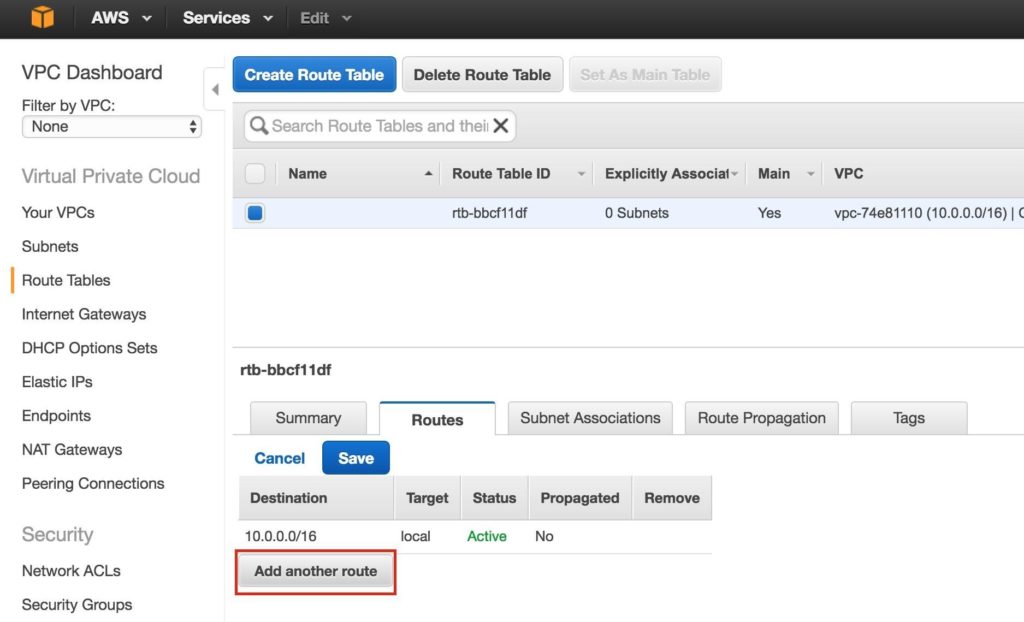
เพิ่มเส้นทางอื่น:
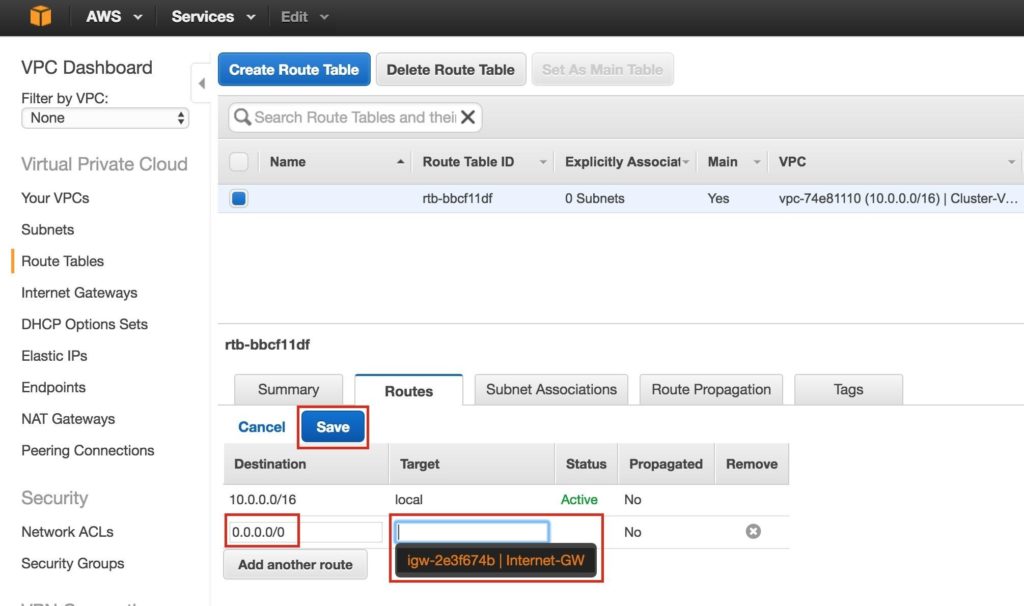
ปลายทางของเส้นทางใหม่จะเป็น“ 0.0.0.0/0” (อินเทอร์เน็ต) และสำหรับ Target ให้เลือก Internet Gateway ของคุณ จากนั้นคลิกบันทึก:
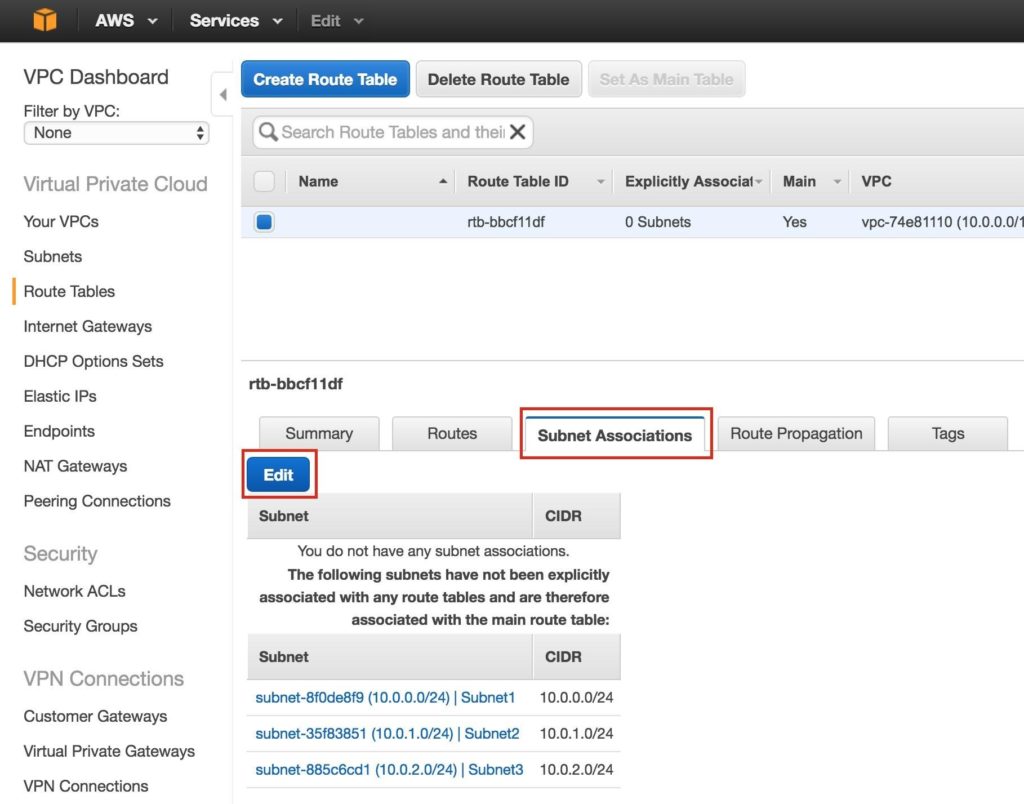
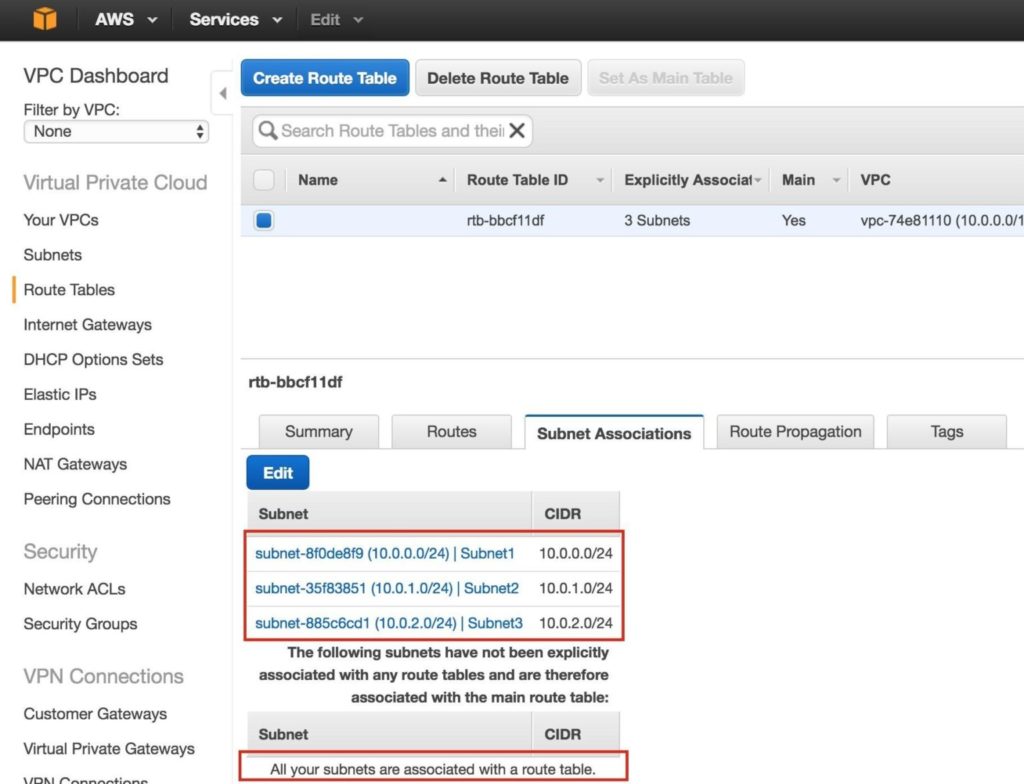
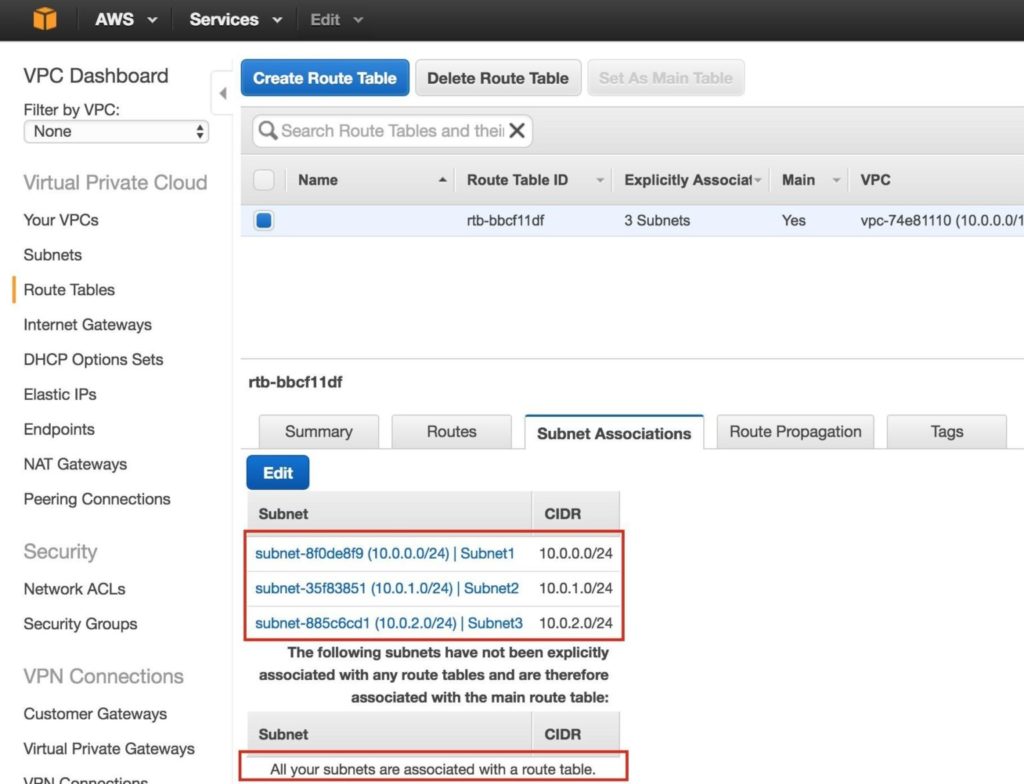
จากนั้นเชื่อมโยงเครือข่ายย่อย 3 เครือข่ายกับตารางเส้นทาง คลิกแท็บ“ Subnet Associates” และแก้ไข:
ทำเครื่องหมายในช่องถัดจากเครือข่ายย่อยทั้ง 3 เครือข่ายแล้วบันทึก:
ตรวจสอบว่าเครือข่ายย่อยทั้ง 3 เชื่อมโยงกับตารางเส้นทางหลัก:
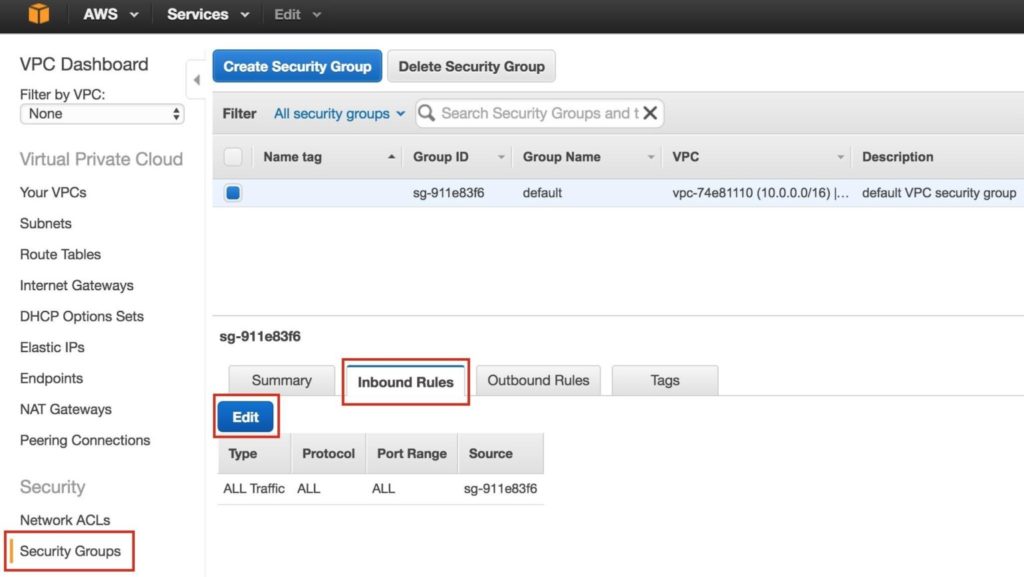
ในภายหลังเราจะกลับมาและอัปเดตตารางเส้นทางอีกครั้งโดยกำหนดเส้นทางที่จะอนุญาตให้ทราฟฟิกสื่อสารกับ Virtual IP ของคลัสเตอร์ได้ แต่จะต้องดำเนินการหลังจากสร้างอินสแตนซ์ linux (VMs) แล้ว ขั้นตอนที่ 5: กำหนดค่ากลุ่มความปลอดภัยแก้ไข Security Group (ไฟร์วอลล์เสมือน) เพื่ออนุญาตการรับส่งข้อมูล SSH และ VNC ที่เข้ามา ทั้งสองจะถูกใช้ในภายหลังเพื่อกำหนดค่าอินสแตนซ์ linux ตลอดจนการติดตั้ง / กำหนดค่าซอฟต์แวร์คลัสเตอร์ ที่เมนูด้านซ้ายเลือก "กลุ่มความปลอดภัย" จากนั้นคลิกแท็บ "กฎขาเข้า" คลิกแก้ไข:
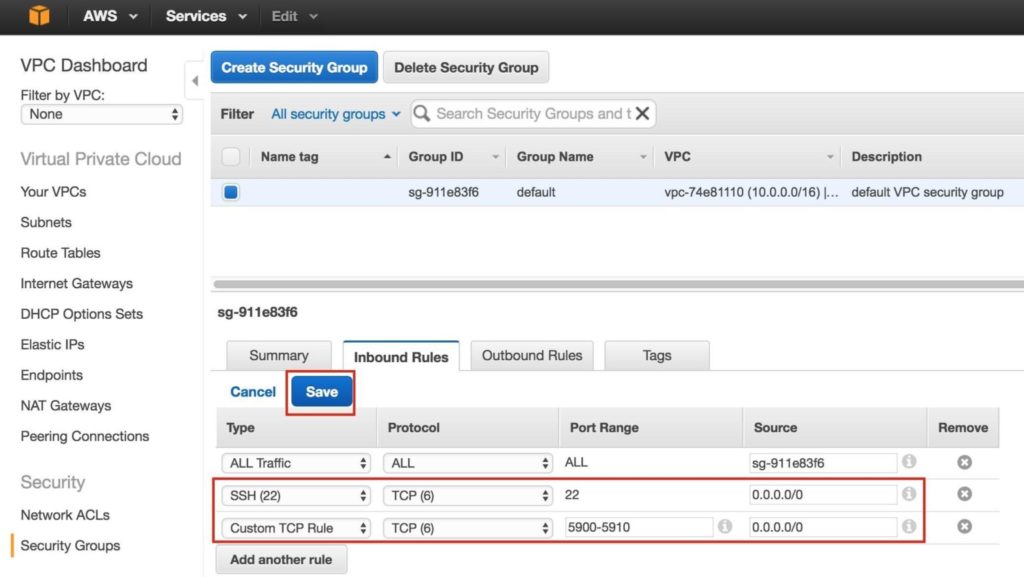
เพิ่มกฎสำหรับทั้ง SSH (พอร์ต 22) และ VNC โดยทั่วไป VNC ใช้พอร์ตใน 5900 ขึ้นอยู่กับว่าคุณกำหนดค่าอย่างไรดังนั้นเพื่อวัตถุประสงค์ของคู่มือนี้เราจะเปิดช่วงพอร์ต 5900-5910 กำหนดค่าตามการตั้งค่า VNC ของคุณ:
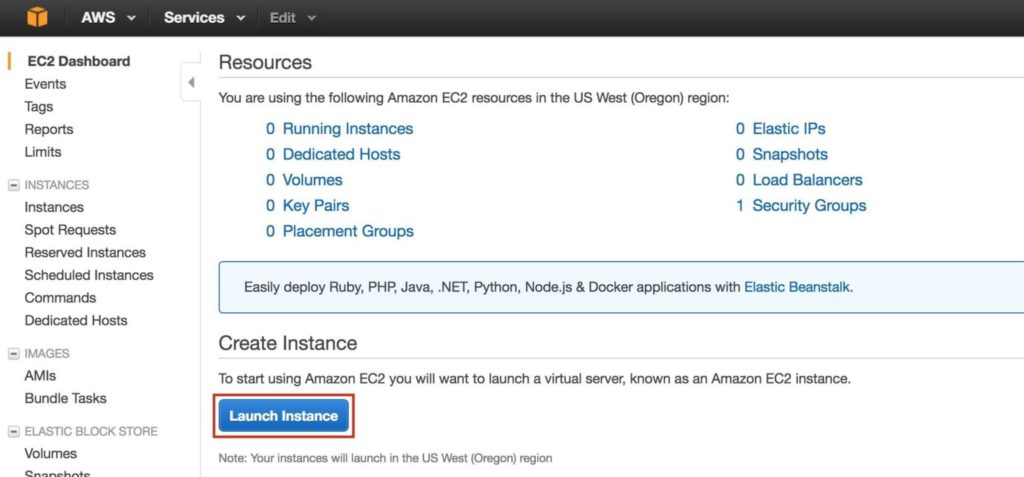
ขั้นตอนที่ 6: เปิดอินสแตนซ์เราจะจัดเตรียมอินสแตนซ์ 3 รายการ (เครื่องเสมือน) ในคู่มือนี้ VM สองตัวแรก (เรียกว่า“ node1” และ“ node2”) จะทำหน้าที่เป็นโหนดคลัสเตอร์ที่มีความสามารถในการนำฐานข้อมูล MySQL และทรัพยากรที่เกี่ยวข้องมาทางออนไลน์ VM ตัวที่ 3 จะทำหน้าที่เป็นเซิร์ฟเวอร์พยานของคลัสเตอร์เพื่อเพิ่มการป้องกันจากสมองแยก เพื่อให้แน่ใจว่ามีความพร้อมใช้งานสูงสุด VM ทั้ง 3 จะถูกปรับใช้ใน Availability Zone ต่างๆภายในภูมิภาคเดียว ซึ่งหมายความว่าแต่ละอินสแตนซ์จะอยู่ในเครือข่ายย่อยที่แตกต่างกัน ไปที่แดชบอร์ด AWS หลักและเลือก EC2:
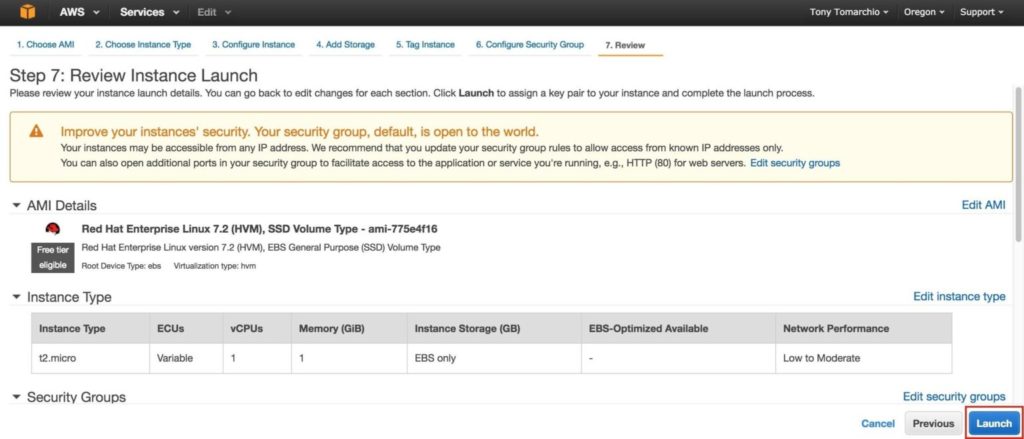
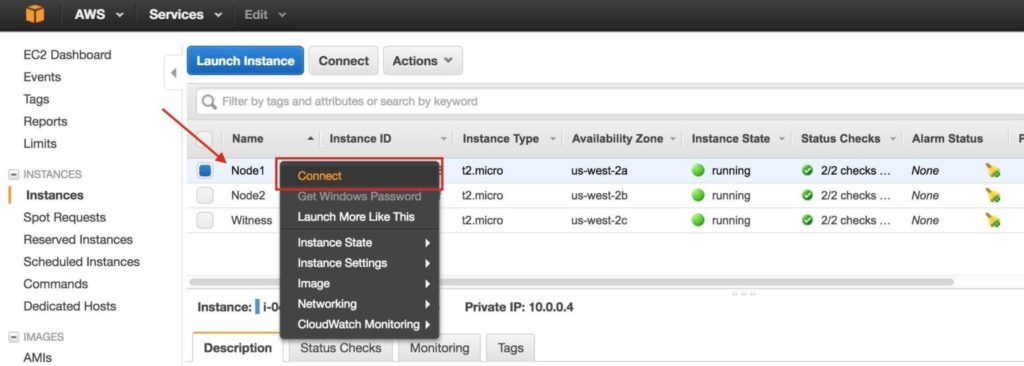
สร้าง“ node1” สร้างอินสแตนซ์แรกของคุณ (“ node1”) คลิก Launch Instance:
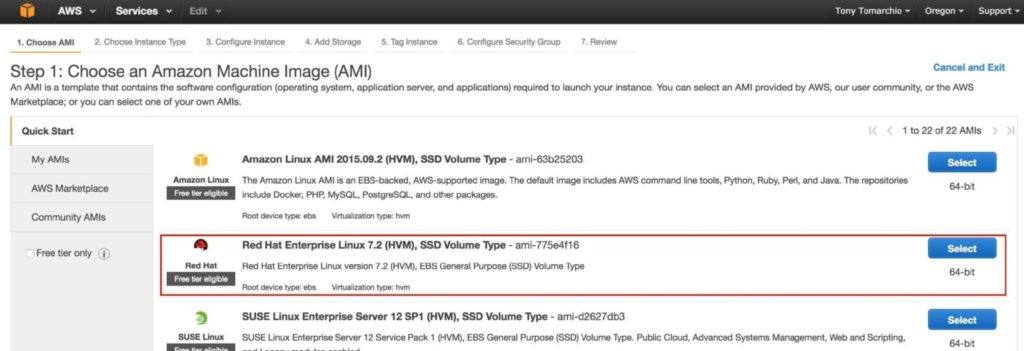
เลือกการกระจาย linux ของคุณ ซอฟต์แวร์คลัสเตอร์ที่ใช้ในภายหลังรองรับ RHEL, SLES, CentOS และ Oracle Linux ในคู่มือนี้เราจะใช้ RHEL 7.X:
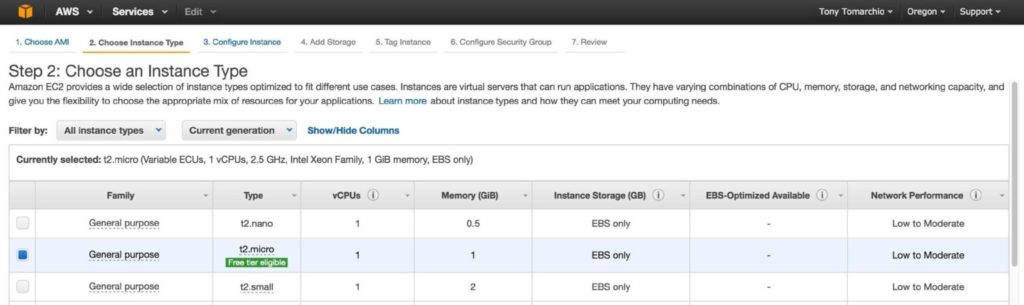
ปรับขนาดอินสแตนซ์ของคุณให้เหมาะสม เพื่อวัตถุประสงค์ของคู่มือนี้และเพื่อลดต้นทุนจึงใช้ขนาด t2.micro เนื่องจากมีสิทธิ์ระดับฟรี ดูข้อมูลเพิ่มเติมเกี่ยวกับขนาดและราคาของอินสแตนซ์ได้ที่นี่
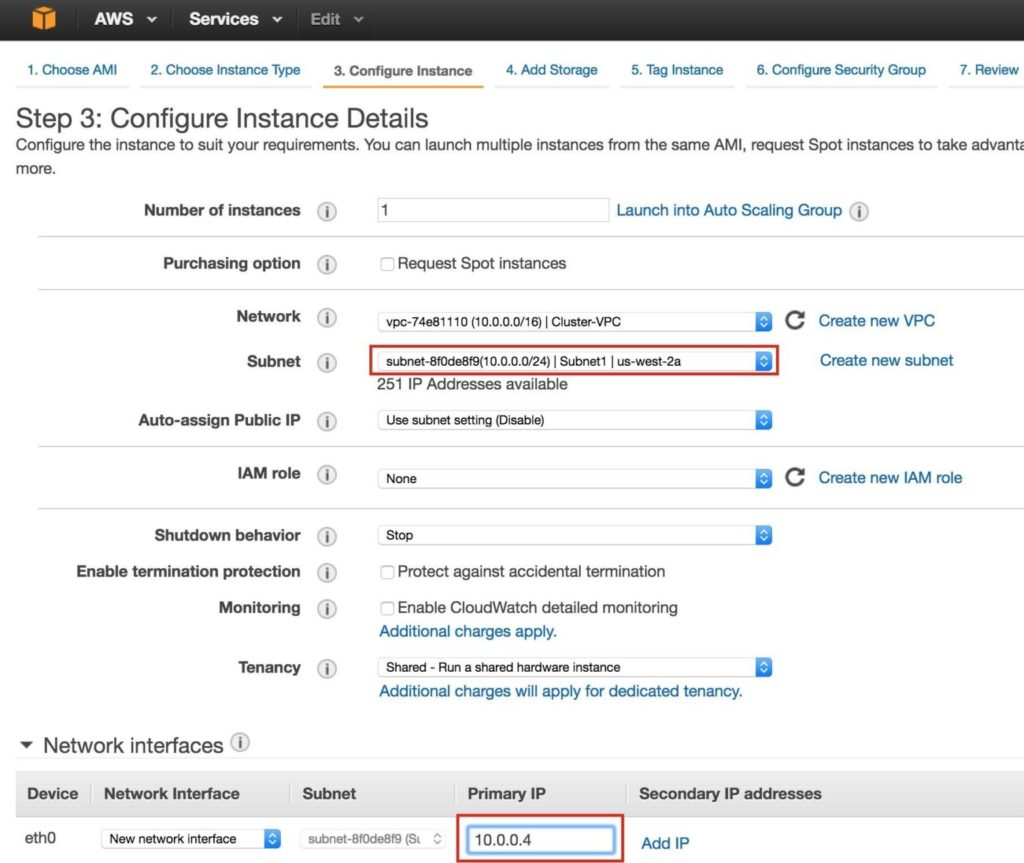
จากนั้นกำหนดค่ารายละเอียดอินสแตนซ์ สำคัญ: อย่าลืมเปิดอินสแตนซ์แรก (VM) นี้ใน“ Subnet1” และกำหนดที่อยู่ IP ที่ถูกต้องสำหรับซับเน็ต (10.0.0.0/24) – เลือกต่ำกว่า 10.0.0.4 เนื่องจากเป็น IP ฟรีตัวแรกในซับเน็ต
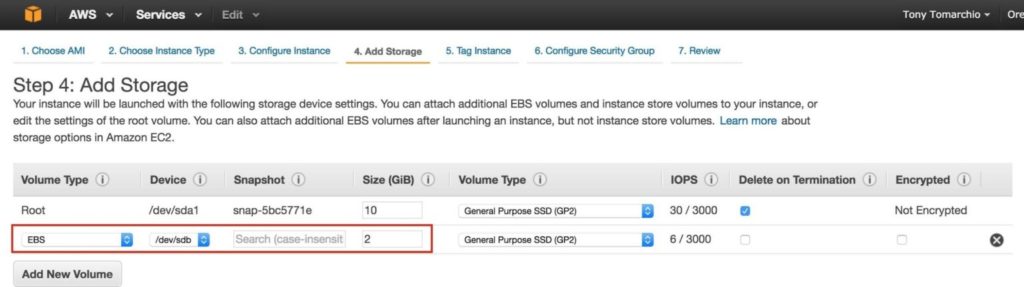
จากนั้นเพิ่มดิสก์พิเศษให้กับโหนดคลัสเตอร์ (ซึ่งจะทำได้ทั้งบน“ node1” และ“ node2”) ดิสก์นี้จะจัดเก็บฐานข้อมูล MySQL ของเราและในภายหลังจะถูกจำลองแบบระหว่างโหนด หมายเหตุ: คุณไม่จำเป็นต้องเพิ่มดิสก์เพิ่มเติมในโหนด "พยาน" เฉพาะ“ node1” และ“ node2” เพิ่มระดับเสียงใหม่และป้อนขนาดที่ต้องการ:
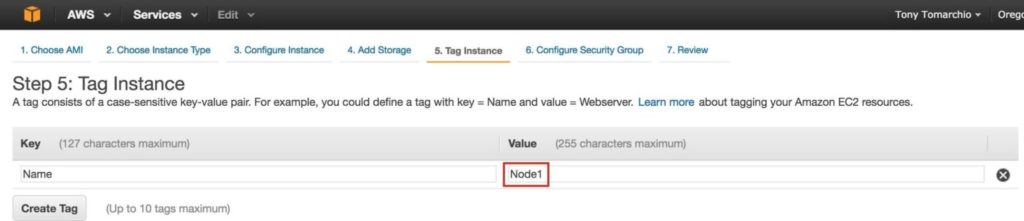
กำหนดแท็กสำหรับอินสแตนซ์ Node1:
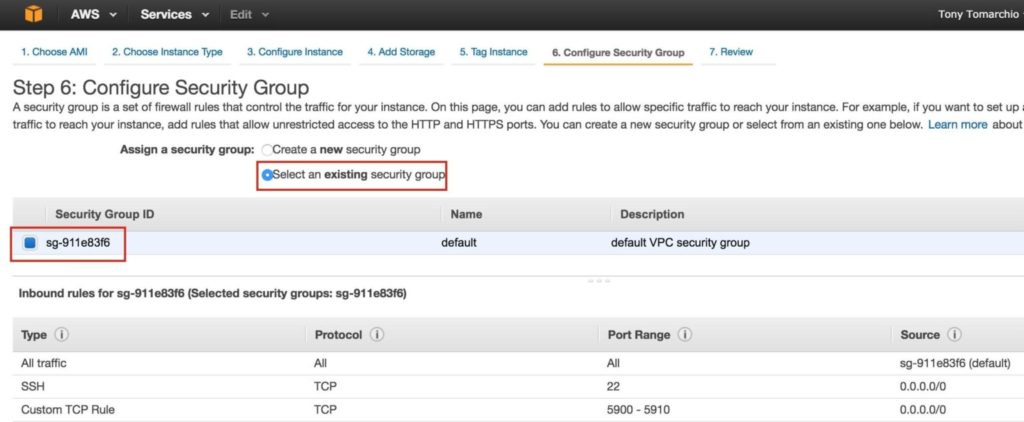
เชื่อมโยงอินสแตนซ์กับกลุ่มความปลอดภัยที่มีอยู่ดังนั้นกฎไฟร์วอลล์ที่สร้างไว้ก่อนหน้านี้จะใช้งานได้:
คลิกเปิด:
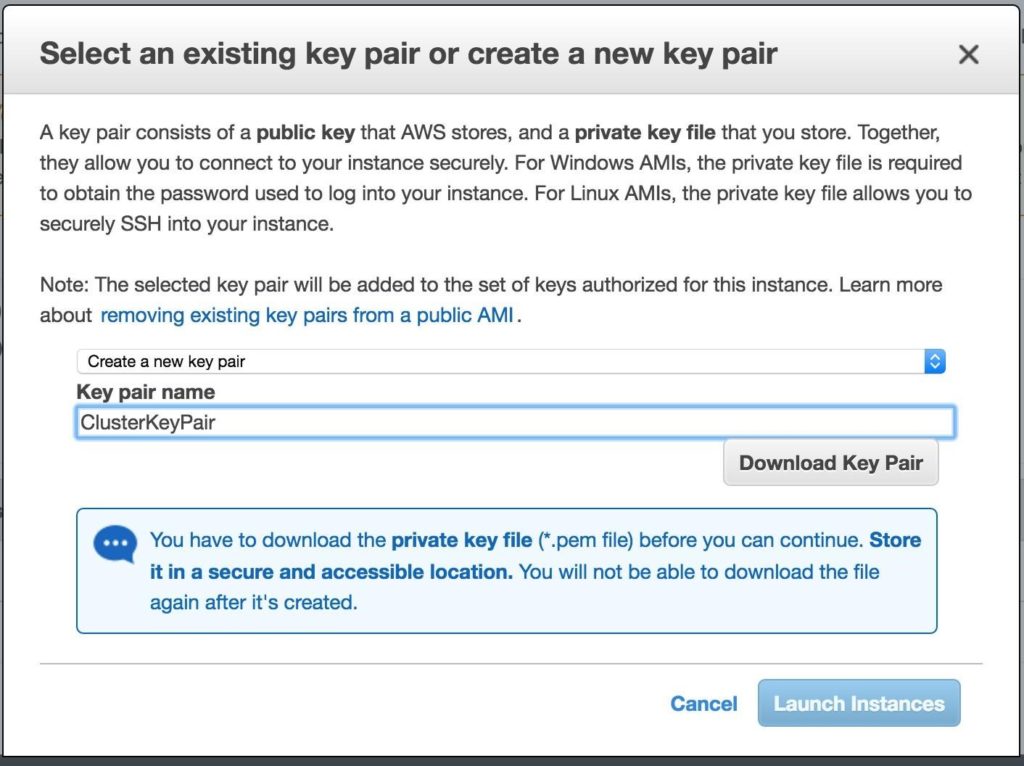
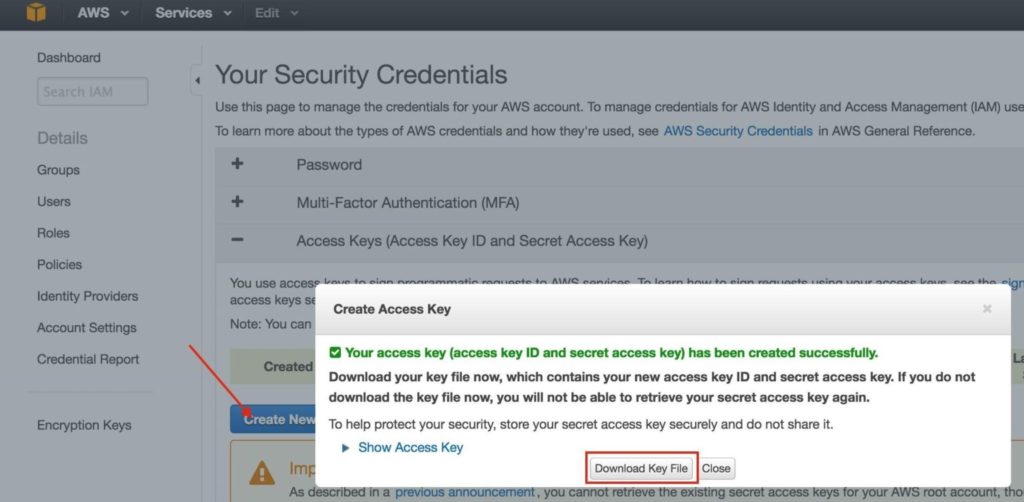
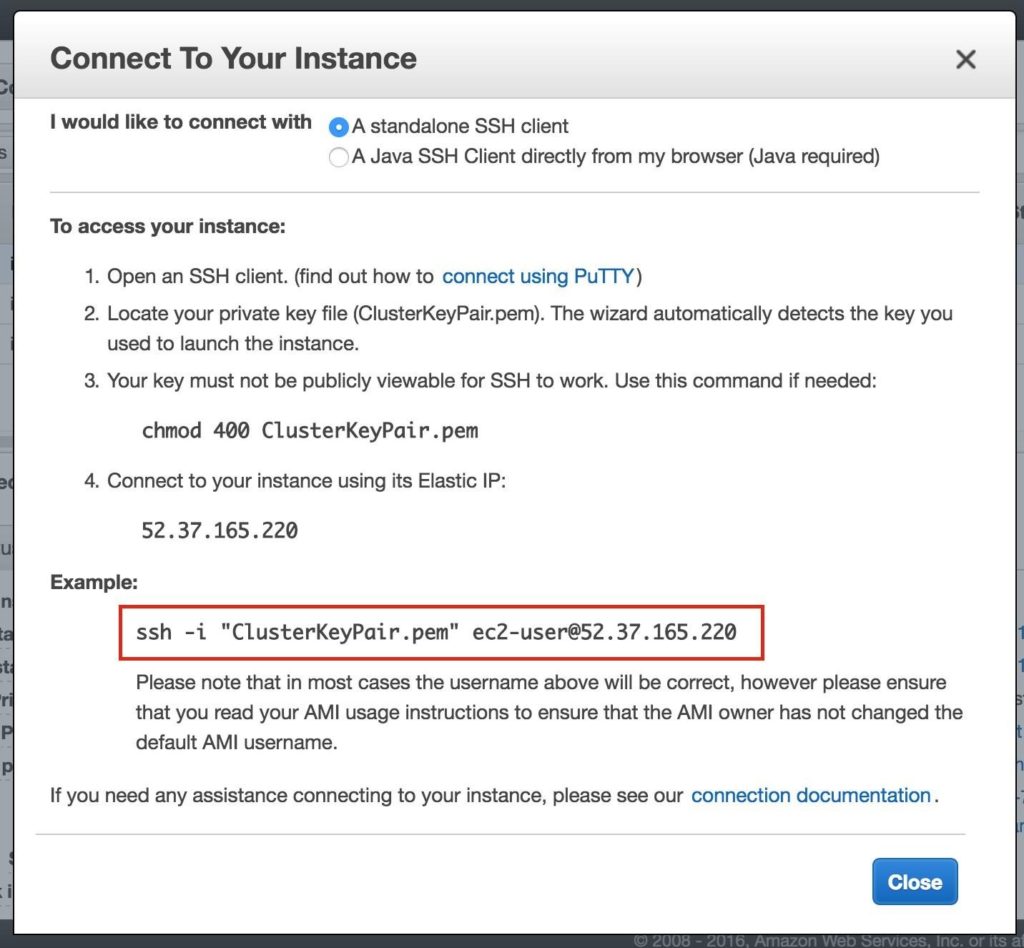
สำคัญ: หากนี่เป็นอินสแตนซ์แรกในสภาพแวดล้อม AWS ของคุณคุณจะต้องสร้างคู่คีย์ใหม่ ไฟล์คีย์ส่วนตัวจะต้องถูกเก็บไว้ในตำแหน่งที่ปลอดภัยเนื่องจากจะต้องใช้เมื่อคุณ SSH เข้าสู่อินสแตนซ์ linux
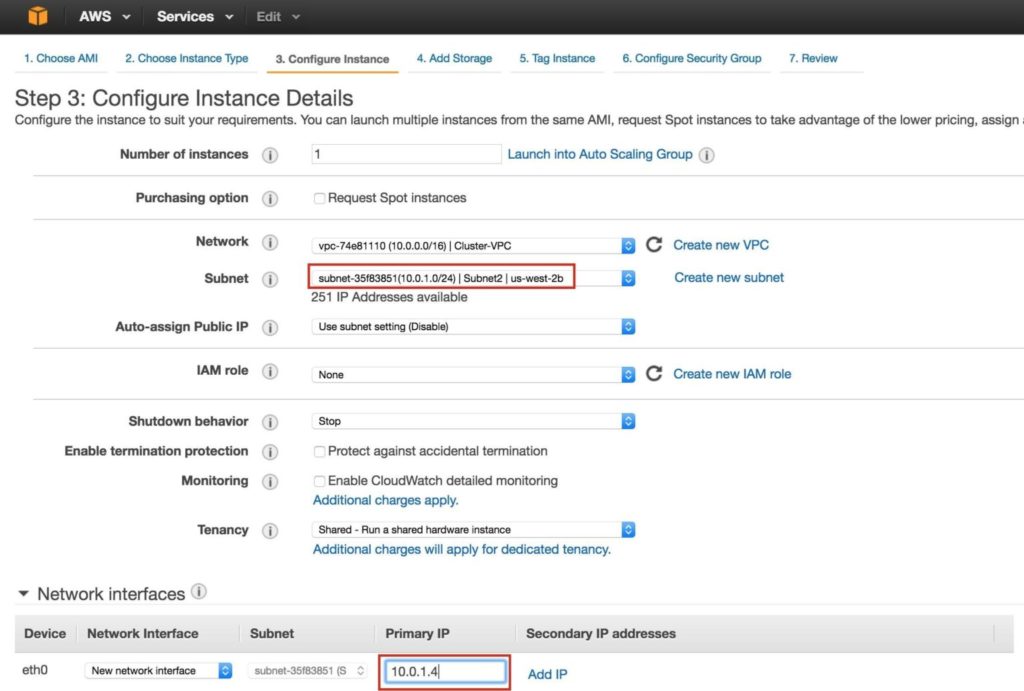
สร้าง“ node2” ทำซ้ำขั้นตอนด้านบนเพื่อสร้างอินสแตนซ์ลินุกซ์ที่สองของคุณ (node2) กำหนดค่าให้เหมือนกับ Node1 อย่างไรก็ตามตรวจสอบให้แน่ใจว่าคุณปรับใช้ใน“ Subnet2” (us-west-2b availability zone) ช่วง IP สำหรับ Subnet2 คือ 10.0.1.0/24 ดังนั้นจึงใช้ IP 10.0.1.4 ที่นี่:
อย่าลืมเพิ่มดิสก์ที่ 2 ใน Node2 ด้วย ควรมีขนาดเท่ากันกับดิสก์ที่คุณเพิ่มใน Node1:
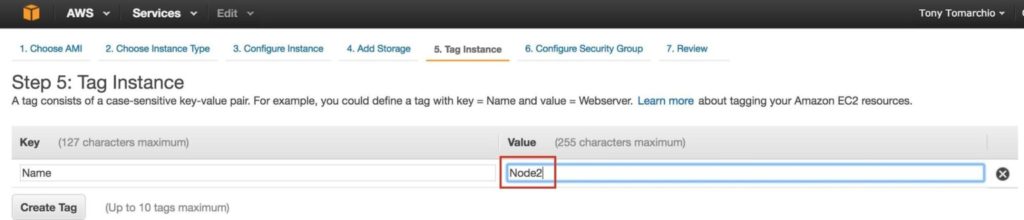
ให้แท็กอินสแตนซ์ที่สอง…. “Node2”:
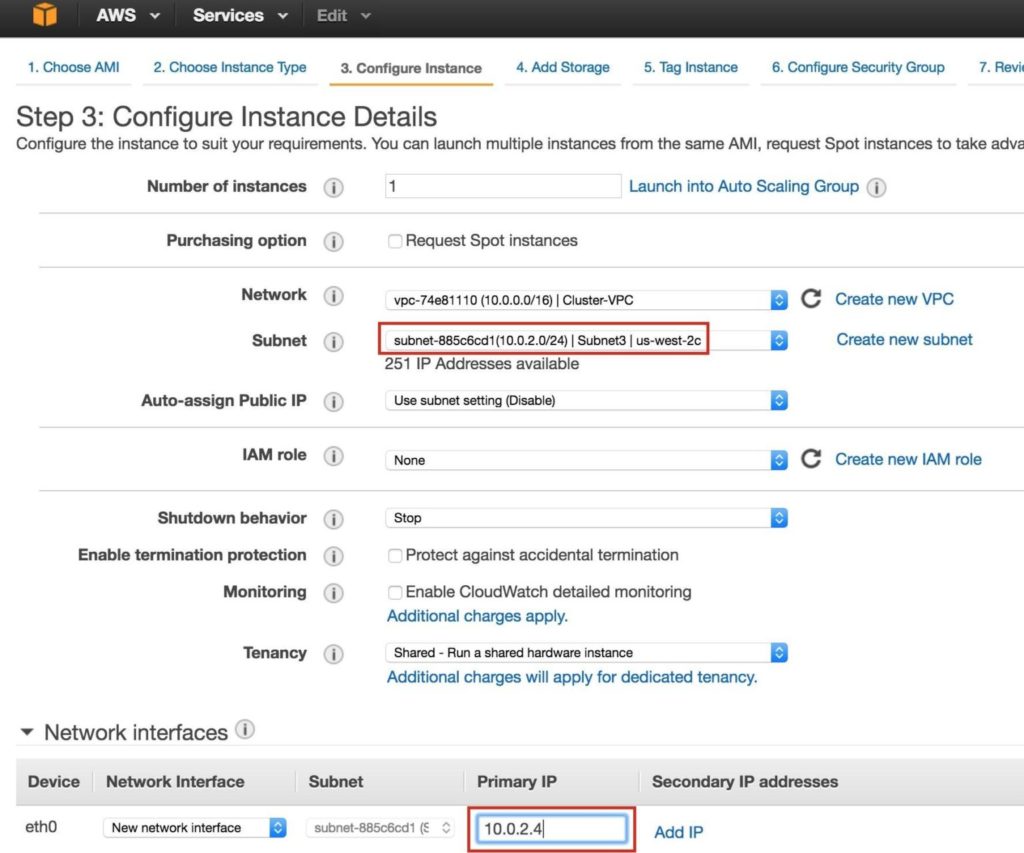
สร้าง "พยาน" ทำซ้ำขั้นตอนด้านบนเพื่อสร้างอินสแตนซ์ linux ที่สามของคุณ (พยาน) กำหนดค่าให้เหมือนกับ Node1 & Node2 ทุกประการยกเว้นคุณไม่จำเป็นต้องเพิ่มดิสก์ที่ 2 เนื่องจากอินสแตนซ์นี้จะทำหน้าที่เป็นพยานให้กับคลัสเตอร์เท่านั้นและจะไม่นำ MySQL ออนไลน์ ตรวจสอบให้แน่ใจว่าคุณปรับใช้ใน“ Subnet3” (us-west-2c availability zone) ช่วง IP สำหรับ Subnet2 คือ 10.0.2.0/24 ดังนั้นจึงใช้ IP 10.0.2.4 ที่นี่:
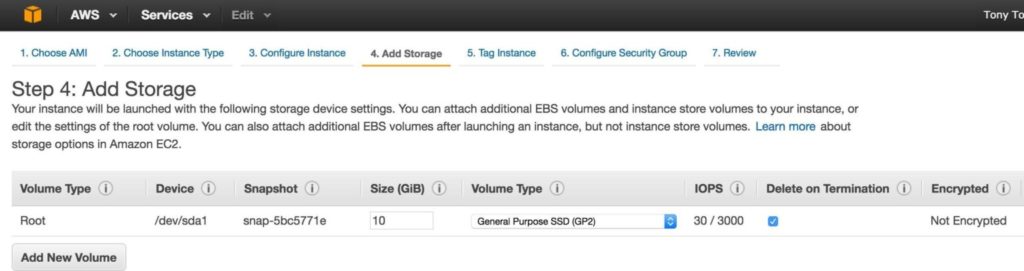
หมายเหตุ: การกำหนดค่าดิสก์เริ่มต้นใช้ได้ดีสำหรับโหนดพยาน ไม่จำเป็นต้องใช้ดิสก์ที่ 2:
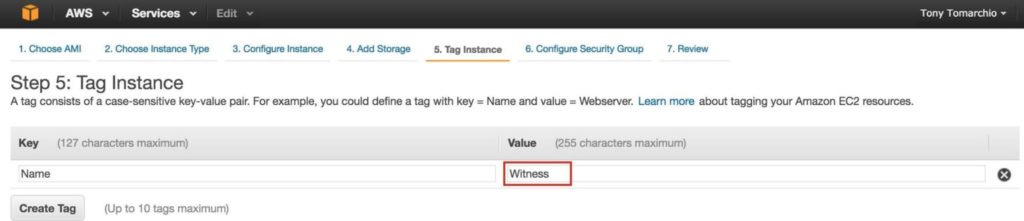
แท็กโหนดพยาน:
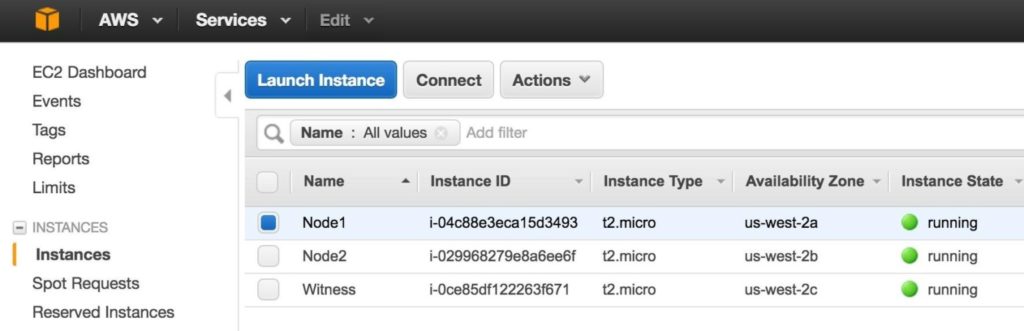
อาจใช้เวลาสักครู่ในการจัดสรรอินสแตนซ์ 3 รายการของคุณ เมื่อดำเนินการเสร็จแล้วคุณจะเห็นรายการว่าทำงานในคอนโซล EC2 ของคุณ:
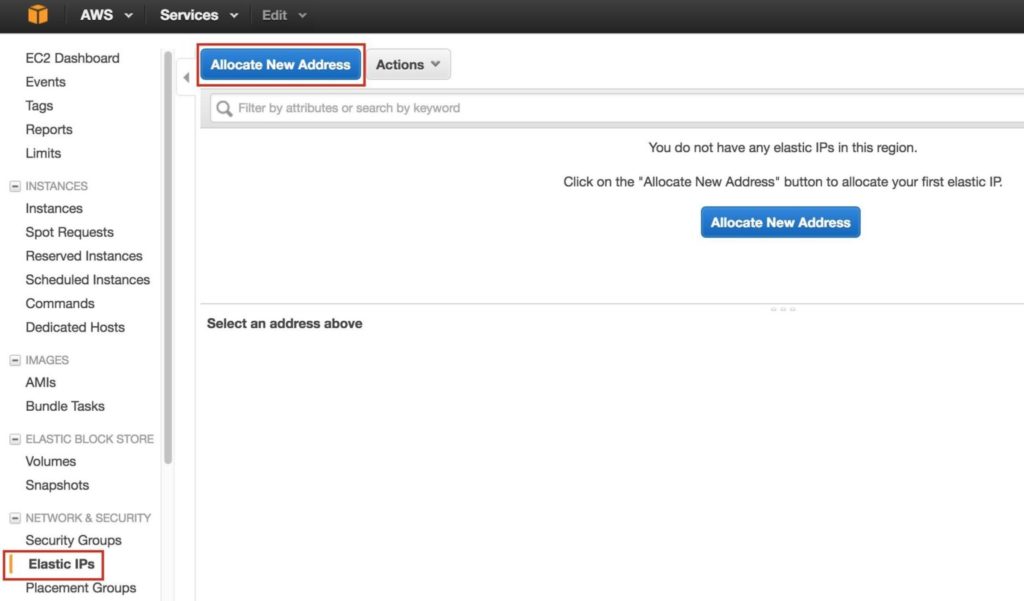
ขั้นตอนที่ 7: สร้าง Elastic IPจากนั้นสร้าง Elastic IP ซึ่งเป็นที่อยู่ IP สาธารณะที่จะใช้เพื่อเชื่อมต่อกับอินสแตนซ์ของคุณจากโลกภายนอก เลือก Elastic IPs ในเมนูด้านซ้ายจากนั้นคลิก“ Allocate New Address”:
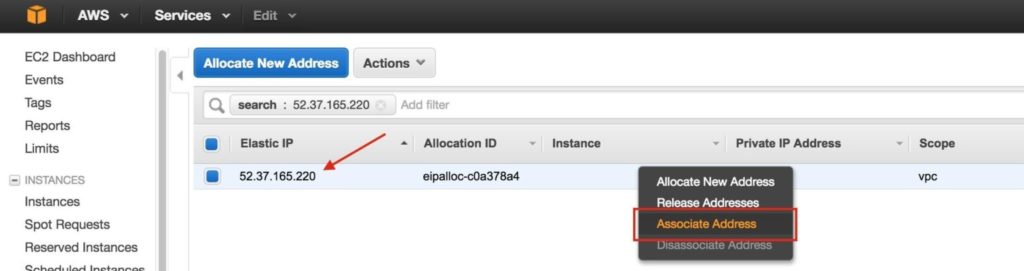
เลือก Elastic IP ที่สร้างขึ้นใหม่คลิกขวาและเลือก“ Associate Address”:
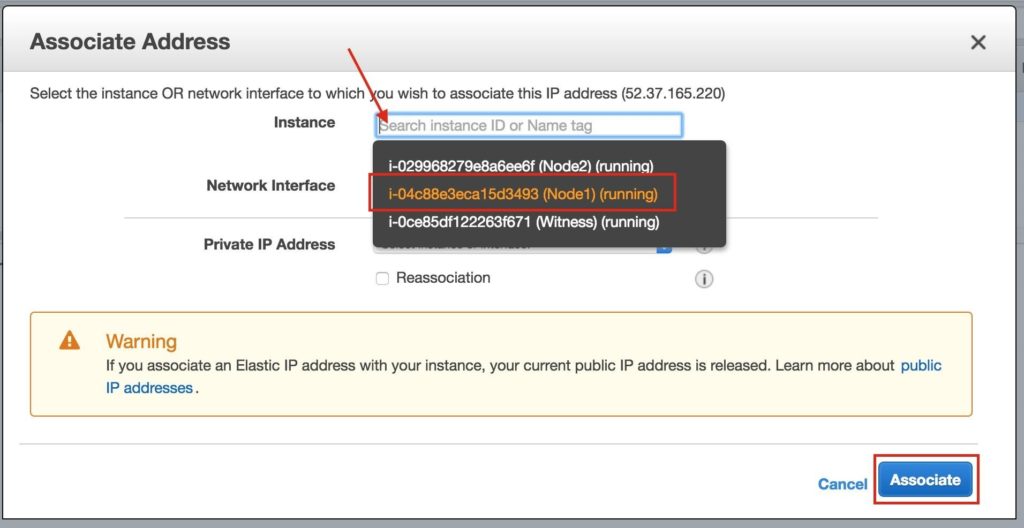
เชื่อมโยง Elastic IP นี้กับ Node1:
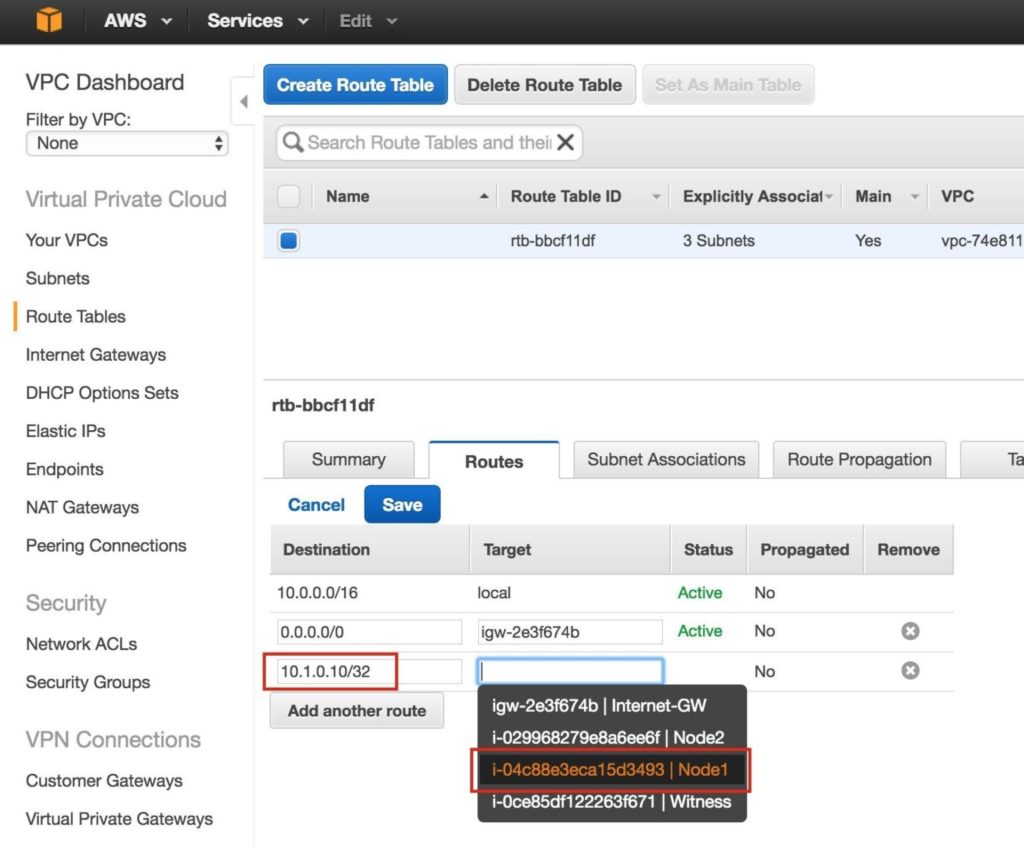
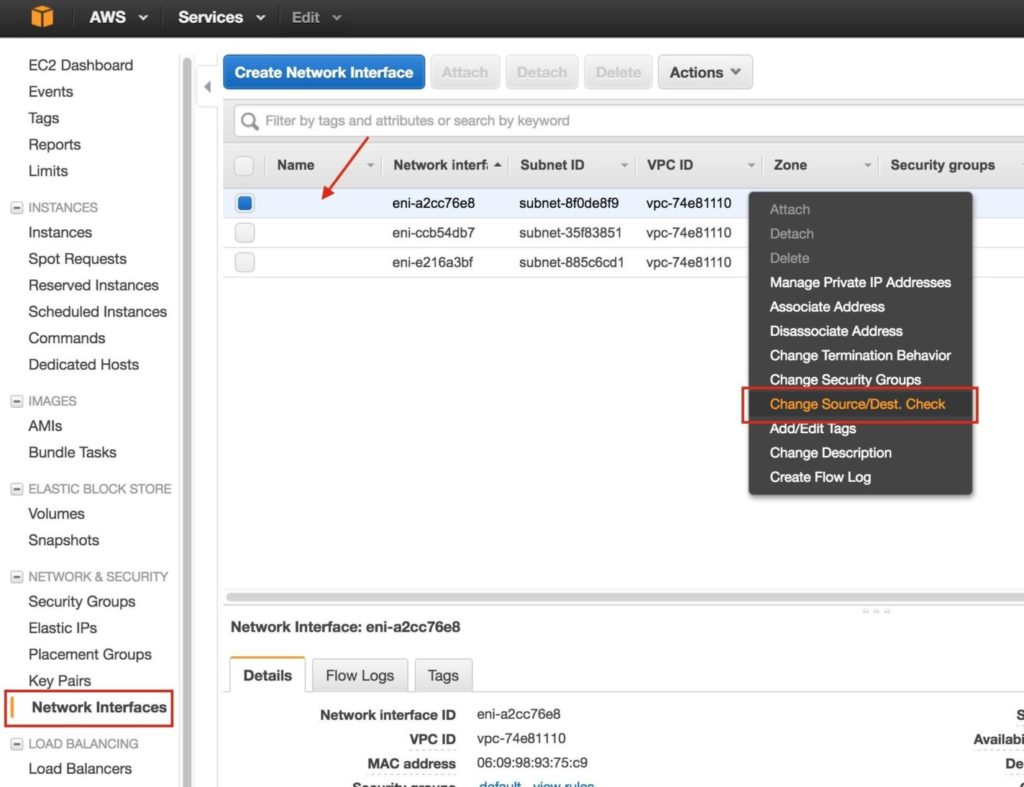
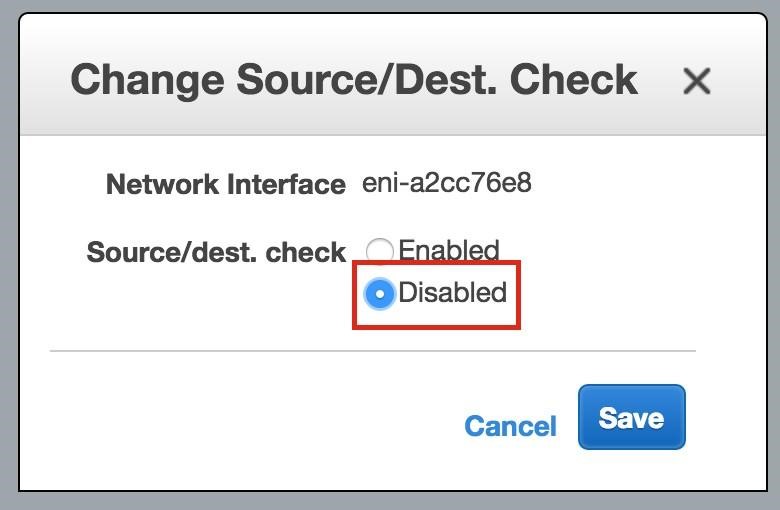
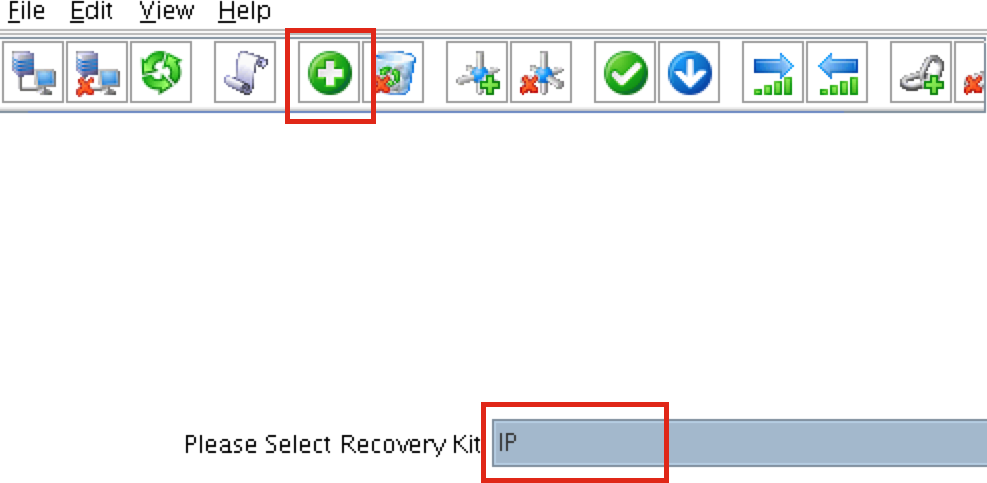
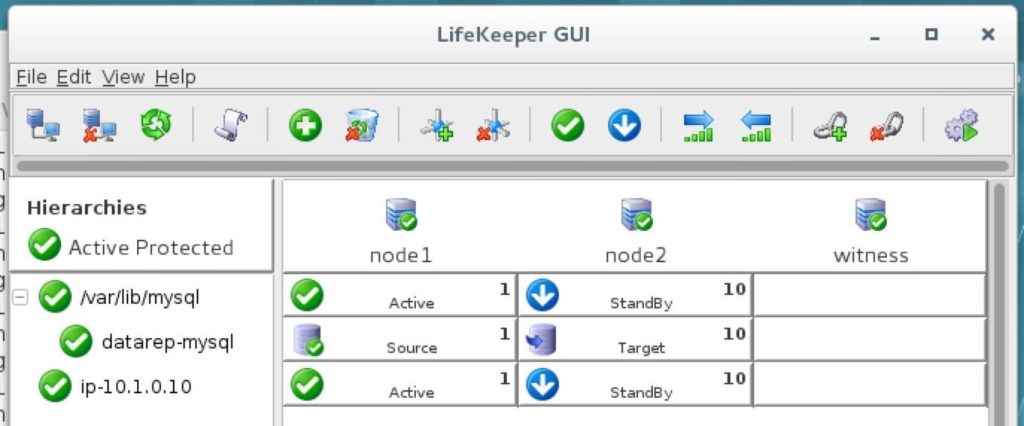
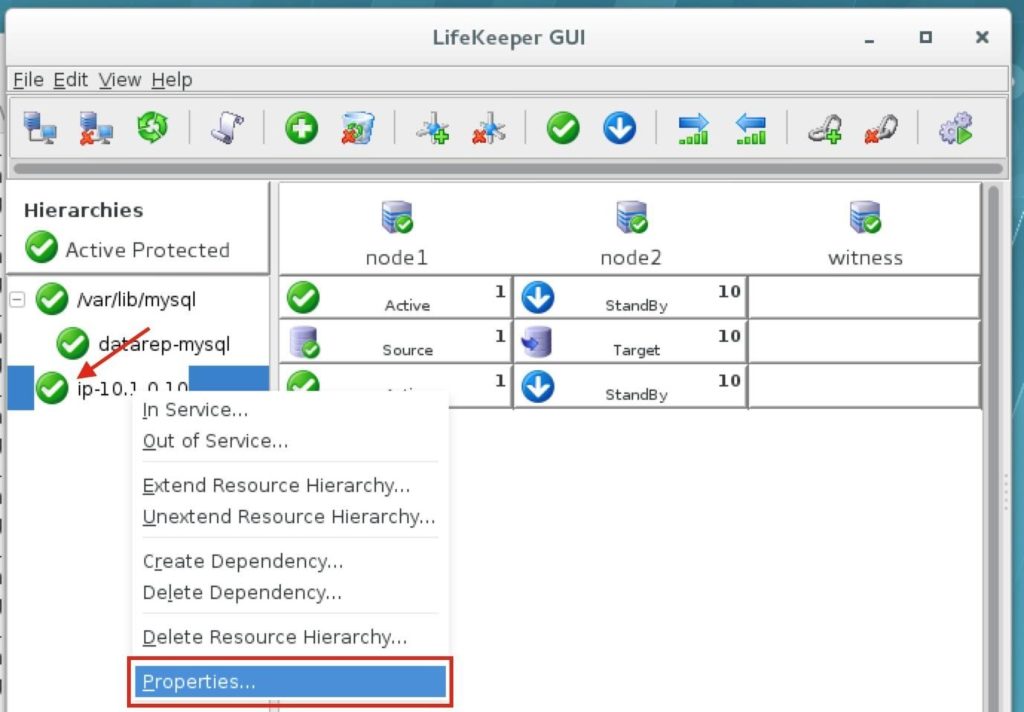
ทำซ้ำกับอีกสองอินสแตนซ์หากคุณต้องการให้พวกเขาเข้าถึงอินเทอร์เน็ตหรือสามารถ SSH / VNC เข้ามาได้โดยตรง ขั้นตอนที่ 8: สร้างรายการเส้นทางสำหรับ IP เสมือนเมื่อถึงจุดนี้ทั้ง 3 อินสแตนซ์ได้ถูกสร้างขึ้นและตารางเส้นทางจะต้องได้รับการอัปเดตอีกครั้งเพื่อให้ Virtual IP ของคลัสเตอร์ทำงานได้ ในการกำหนดค่าคลัสเตอร์แบบหลายซับเน็ตนี้ Virtual IP ต้องอยู่นอกช่วงของ CIDR ที่จัดสรรให้กับ VPC ของคุณ กำหนดเส้นทางใหม่ที่จะกำหนดเส้นทางการรับส่งข้อมูลไปยัง Virtual IP ของคลัสเตอร์ (10.1.0.10) ไปยังโหนดคลัสเตอร์หลัก (Node1) จากแดชบอร์ด VPC เลือกตารางเส้นทางคลิกแก้ไข เพิ่มเส้นทางสำหรับ“ 10.1.0.10/32” โดยมีปลายทางเป็น Node1: |