| ธันวาคม 18, 2021 |
คลัสเตอร์ล้มเหลว |
| ธันวาคม 13, 2021 |
การจำลองข้อมูล |
| ธันวาคม 8, 2021 |
บรรลุความยืดหยุ่นด้านไอทีด้วยความพร้อมใช้งานสูง
บรรลุความยืดหยุ่นด้านไอทีด้วยความพร้อมใช้งานสูงความยืดหยุ่นด้านไอทีคืออะไร?ความยืดหยุ่นของไอทีคือความสามารถขององค์กรในการรักษาระดับการบริการที่ยอมรับได้ เมื่อเกิดการหยุดชะงักของการดำเนินธุรกิจ กระบวนการที่สำคัญ หรือระบบนิเวศไอทีของคุณ ในยุคดิจิทัลนี้ ความพร้อมใช้งานสูงมีความสำคัญต่อความสำเร็จขององค์กรของคุณ ลูกค้าของคุณจะไม่ยอมให้เว็บไซต์ล่ม และคุณไม่สามารถซื้อ ERP, CRM หรือระบบที่มีความสำคัญต่อธุรกิจอื่นๆ ได้ นี่คือที่ ความพร้อมใช้งานสูง เข้ามา. องค์กรของคุณต้อง "ทำเครื่องหมายในช่อง" ของเทคโนโลยีและโซลูชันต่างๆ มากมายเพื่อให้แน่ใจว่าไอทีมีความยืดหยุ่น อย่างน้อยก็อย่างน้อยในนั้นก็รับประกันว่าคุณมีข้อมูลสำรอง การกู้คืนจากภัยพิบัติ ความยืดหยุ่นทางไซเบอร์ และความพร้อมใช้งานสูง สำหรับวัตถุประสงค์ของบทความนี้ เราจะพูดถึงความพร้อมใช้งานสูง (HA) เป็นหนึ่งในองค์ประกอบหลักที่จำเป็นเพื่อให้แน่ใจว่าไอทีมีความยืดหยุ่น ความพร้อมใช้งานสูงคืออะไร?ระบบที่มีความพร้อมใช้งานสูงช่วยให้มั่นใจได้ว่าการดำเนินธุรกิจจะดำเนินต่อไป – ด้วยความโปร่งใสทั้งหมดต่อลูกค้าและผู้ใช้ – เมื่อระบบ แอปพลิเคชัน และเครือข่ายของคุณล่ม HA เป็นส่วนประกอบของระบบเทคโนโลยีที่ขจัดจุดบกพร่องเพียงจุดเดียวเพื่อให้แน่ใจว่ามีการทำงานอย่างต่อเนื่องหรือเวลาทำงานต่อเนื่องเป็นระยะเวลานาน ระบบที่มีความพร้อมใช้งานสูงรวมเอาหลักการออกแบบห้าประการ: การเฟลโอเวอร์อัตโนมัติ การตรวจจับความล้มเหลวระดับแอปพลิเคชันโดยอัตโนมัติ ไม่มีข้อมูลสูญหาย ความล้มเหลวโดยอัตโนมัติและรวดเร็วไปยังส่วนประกอบที่ซ้ำซ้อน และความล้มเหลวของปุ่มกดและการย้อนกลับสำหรับการบำรุงรักษาตามแผน —————————————————————————————————————————— ความยืดหยุ่นด้านไอทีและความพร้อมใช้งานสูง – ไม่ใช่ตัวอย่าง!เมื่อเดือนสิงหาคมที่ผ่านมา ศูนย์ข้อมูลของ Nissan Group ในเดนเวอร์ ขัดข้องเนื่องจากไฟฟ้าดับ ระบบที่ได้รับผลกระทบเป็นที่รู้จักภายในว่า NNANet เป็นโซลูชันของ Nissan ที่พนักงานใช้ในการสั่งซื้อรถยนต์/ชิ้นส่วน จัดการการขายส่วนลดผลิตภัณฑ์ รับข้อมูลเกี่ยวกับการเรียกคืนรถยนต์ ยื่นคำร้องการรับประกันที่จำเป็นในการตั้งราคาและเริ่มงานบริการ และรับข้อมูลทางการเงินNNANet ถูกอธิบายว่าเป็นเส้นเลือดสำคัญของ Nissan เพราะทุกสิ่งที่ Nissan ทำจะต้องผ่าน NNANet ระบบยังคงหยุดทำงานเป็นเวลาสี่วัน ส่งผลกระทบต่อการดำเนินงานของผู้ค้าปลีกหลายราย และระบบการผลิตในโรงงานสองแห่ง บริษัท ผู้ค้าปลีก และลูกค้าได้รับผลกระทบทั้งหมด ผลกระทบเห็นได้ชัดว่านี่คือตัวอย่างที่ระบบที่มีความพร้อมใช้งานสูงที่กำหนดค่าอย่างถูกต้องและตั้งอยู่ในตำแหน่งที่เหมาะสมจะช่วยประหยัดเวลาได้หรืออย่างน้อยก็ลดผลกระทบของการขัดข้องให้เหลือน้อยที่สุด สถานการณ์ความพร้อมใช้งานสูงกลับกลายเป็นหายนะอย่างแท้จริงสำหรับนิสสันในฐานะ "การค้าระหว่างผู้บริโภค ผู้ค้าปลีก เครือข่ายการจัดจำหน่าย โรงงานผลิต และบริษัทการเงิน" ได้รับผลกระทบทั้งหมดเป็นเวลาสี่วัน[1]Nissan รีเซ็ตเป้าหมายยอดขายของตัวแทนจำหน่าย 10 เปอร์เซ็นต์สำหรับเดือนนั้นอันเป็นผลมาจากเหตุขัดข้อง ผลกระทบทางการเงินโดยรวมสำหรับนิสสันและตัวแทนจำหน่าย/ผู้ค้าปลีก/พันธมิตรยังคงต้องติดตามกันต่อไป ความยืดหยุ่นด้านไอที– ตัวอย่างในโลกแห่งความจริง!Cayan™ เป็นผู้ให้บริการเทคโนโลยีการชำระเงินชั้นนำและ Genius Customer Engagement Platform® ได้รวบรวมและผสานรวมเทคโนโลยีการทำธุรกรรมที่เป็นไปได้ ประเภทการชำระเงิน และโปรแกรมลูกค้าทั้งหมด ทั้งในปัจจุบันและอนาคตไว้ในแพลตฟอร์มเดียว แพลตฟอร์ม Genius รวมถึงแอปพลิเคชันที่สำคัญต่อภารกิจอื่นๆ ที่ Cayan ทำงานบน SQL Server ลูกค้าของ Cayan รวมถึงผู้ค้าปลีกออนไลน์รายใหญ่ที่สุดของโลกบางราย บริษัทต่างๆ ที่ไม่ยอมรับการหยุดทำงาน “ความสำคัญสูงสุดของเราคือสร้างความมั่นใจว่าลูกค้าของเราสามารถทำธุรกรรมได้อย่างต่อเนื่องตลอด 24 ชั่วโมง เจ็ดวันต่อสัปดาห์” Paul Vienneau ประธานเจ้าหน้าที่ฝ่ายเทคโนโลยีของ Cayan กล่าว Cayan ต้องการความพร้อมใช้งานสูงและ การกู้คืนระบบ ระบบสำหรับฐานข้อมูล SQL Server บริษัทพิจารณาคลัสเตอร์การจัดเก็บข้อมูลที่ใช้ร่วมกันแบบดั้งเดิม แต่โซลูชัน SAN มีราคาแพง ซับซ้อนในการจัดการ และนำเสนอความเสี่ยงที่เกี่ยวข้องกับจุดล้มเหลวเพียงจุดเดียว ด้วยเหตุผลเหล่านี้ พนักงาน Cayan IT จึงตัดสินใจใช้คลัสเตอร์ SIOS #SANLess คลัสเตอร์ SANLess ใช้ที่จัดเก็บในตัวเครื่องจึงมีค่าใช้จ่ายด้านประสิทธิภาพน้อยที่สุดและเวลาตอบสนองของแอปพลิเคชันที่รวดเร็ว ซอฟต์แวร์ SIOS SIOS DataKeeper ถูกรวมเข้ากับ Windows Server Failover Clustering (WSFC) SIOS ใช้ประสิทธิภาพแบบเรียลไทม์ การจำลองข้อมูล เพื่อซิงโครไนซ์ที่เก็บข้อมูลในเครื่องในโหนดคลัสเตอร์หลักและระยะไกล ทำให้ปรากฏต่อ WSFC เป็น SAN เสมือน ผลกระทบตั้งแต่ปรับใช้คลัสเตอร์ SIOS SANless Cayan ไม่เคยประสบปัญหาการหยุดทำงานหรือข้อมูลสูญหาย ความคิดเห็นของ Paul Vienneau, CTO, “เรายินดีเป็นอย่างยิ่งกับซอฟต์แวร์ SIOS DataKeeper เป็นไปตามหรือเกินความคาดหมายของเรา การใช้งานและการดูแลระบบอย่างต่อเนื่องเป็นเรื่องง่าย และเราไม่มีเวลาหยุดทำงานตั้งแต่เริ่มใช้งานคลัสเตอร์ SIOS SANLess” ไม่มีปัญหาความพึงพอใจของลูกค้าที่ต้องรายงาน ไม่มีการสูญเสียรายได้ ไม่มีพนักงานที่ไม่มีประสิทธิภาพ ไม่มีการหยุดชะงักของธุรกิจ ——————————————————————————— SIOS: บรรลุความยืดหยุ่นด้านไอทีด้วยความพร้อมใช้งานสูงSIOS DataKeeper™ ใช้การจำลองระดับบล็อกอย่างมีประสิทธิภาพเพื่อให้การจัดเก็บข้อมูลในเครื่องซิงโครไนซ์ ทำให้โหนดรองในคลัสเตอร์ของคุณทำงานต่อไปได้หลังจากเกิดข้อผิดพลาดด้วยการเข้าถึงข้อมูลล่าสุด ผลิตภัณฑ์ SIOS ปกป้องแอปพลิเคชันที่ใช้ Windows หรือ Linux ที่ทำงานในสภาพแวดล้อมทางกายภาพ เสมือน คลาวด์หรือไฮบริด และในสถานการณ์การกู้คืนไซต์หรือเมื่อเกิดภัยพิบัติร่วมกัน ทำให้มีความพร้อมใช้งานสูงและการกู้คืนจากความเสียหายสำหรับแอปพลิเคชัน เช่น SAP S/4HANA และฐานข้อมูล รวมถึง Oracle, SQL Server, DB2 และอื่นๆ อีกมากมาย ความเรียบง่าย "ที่พร้อมใช้งานทันที" ความยืดหยุ่นในการกำหนดค่า ความน่าเชื่อถือ ประสิทธิภาพ และความคุ้มค่าของผลิตภัณฑ์ SIOS ทำให้พวกเขาแตกต่างจากซอฟต์แวร์การทำคลัสเตอร์อื่นๆ ในสภาพแวดล้อม Windows SIOS DataKeeper Cluster Edition จะผสานรวมกับและขยาย Windows Server Failover Clustering (WSFC) ได้อย่างราบรื่นด้วยกลไกการจำลองข้อมูลตามโฮสต์ที่เพิ่มประสิทธิภาพการทำงาน ในขณะที่ WSFC จัดการคลัสเตอร์ซอฟต์แวร์ SIOS จะดำเนินการจำลองแบบเพื่อเปิดใช้งานการป้องกันจากภัยพิบัติและรับรองว่าข้อมูลจะสูญหายเป็นศูนย์ในกรณีที่คลัสเตอร์การจัดเก็บข้อมูลที่ใช้ร่วมกันเป็นไปไม่ได้หรือทำไม่ได้ เช่น ในสภาพแวดล้อมการจัดเก็บข้อมูลบนคลาวด์ เสมือน และประสิทธิภาพสูง ในสภาพแวดล้อม Linux SIOS LifeKeeper™ และ SIOS DataKeeper สำหรับ Linux ให้การผสมผสานที่มีความพร้อมใช้งานสูง การจัดคลัสเตอร์ล้มเหลว การตรวจสอบแอปพลิเคชันอย่างต่อเนื่อง การจำลองข้อมูล และนโยบายการกู้คืนที่กำหนดค่าได้ ปกป้องแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของคุณจากการหยุดทำงานและภัยพิบัติ ไม่ว่าคุณจะอยู่ในสภาพแวดล้อม Windows หรือ Linux ผลิตภัณฑ์ SIOS จะปลดปล่อยทีมไอทีของคุณจากความซับซ้อนและความท้าทายในการสร้างและจัดการโครงสร้างพื้นฐานด้านการประมวลผลที่มีความพร้อมใช้งานสูง พวกเขาให้ข่าวกรอง ระบบอัตโนมัติ ความยืดหยุ่น ความพร้อมใช้งานสูง และความสะดวกในการใช้งานผู้จัดการฝ่ายไอทีที่จำเป็นในการปกป้องแอปพลิเคชันที่มีความสำคัญต่อธุรกิจจากการหยุดทำงานหรือการสูญเสียข้อมูล SIOS = ความยืดหยุ่นด้านไอทีด้วย HA + DRการสำรองข้อมูล ความพร้อมใช้งานสูง การกู้คืนจากภัยพิบัติ และความยืดหยุ่นทางไซเบอร์ล้วนเป็นองค์ประกอบสำคัญในการบรรลุความยืดหยุ่นด้านไอที ด้วยโซลูชัน SIOS คุณสามารถ "ทำเครื่องหมายในช่อง" สำหรับทั้งความพร้อมใช้งานสูงและการกู้คืนจากความเสียหาย – สองโซลูชันในหนึ่งเดียว ด้วยความสามารถในการจำลองแบบไปยังหลายเป้าหมาย คุณสามารถกำหนดค่าคลัสเตอร์เฟลโอเวอร์แบบหลายโหนดที่มีโหนดอยู่ในหลายตำแหน่งเพื่อปกป้องระบบของคุณจากความล้มเหลวและภัยพิบัติ สำหรับข้อมูลเพิ่มเติมและเพื่อให้แน่ใจว่า ความยืดหยุ่นด้านไอที สำหรับองค์กรของคุณ รับการสาธิตฟรี ของ SIOS วันนี้ ข้อมูลอ้างอิง:
ทำซ้ำโดยได้รับอนุญาตจาก SIOS
|
| ธันวาคม 3, 2021 |
วิธีบรรลุความพร้อมใช้งานสูงด้วยคลัสเตอร์
|
| พฤศจิกายน 28, 2021 |
สี่เหตุผลในการใช้กลยุทธ์การหลีกเลี่ยงในความพร้อมใช้งานสูง |

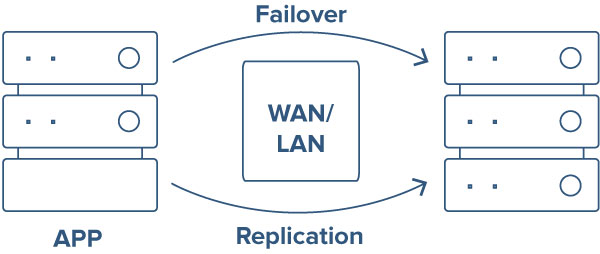


 วิธีบรรลุความพร้อมใช้งานสูงด้วยคลัสเตอร์
วิธีบรรลุความพร้อมใช้งานสูงด้วยคลัสเตอร์