| กุมภาพันธ์ 19, 2022 |
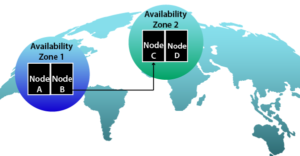
วิธีขจัดจุดเดียวของความล้มเหลวในระบบคลาวด์ด้วยคลัสเตอร์ที่มีความพร้อมใช้งานสูง |
| กุมภาพันธ์ 15, 2022 |
วิธีป้องกันแอปพลิเคชันในแพลตฟอร์มคลาวด์ – คลัสเตอร์สำหรับความพร้อมใช้งานสูงของ Microsoft Azure |
| กุมภาพันธ์ 11, 2022 |
วิธีปกป้องแอปพลิเคชันในแพลตฟอร์มคลาวด์ – คลัสเตอร์ความพร้อมใช้งานสูงของ AWS EC2 |
| กุมภาพันธ์ 7, 2022 |
วิธีป้องกันแอปพลิเคชันในแพลตฟอร์มคลาวด์ – คลัสเตอร์ SANless สำหรับสภาพแวดล้อมคลาวด์วิธีป้องกันแอปพลิเคชันในแพลตฟอร์มคลาวด์ – คลัสเตอร์ SANless สำหรับสภาพแวดล้อมคลาวด์ทำซ้ำโดยได้รับอนุญาตจาก SIOS |
| กุมภาพันธ์ 3, 2022 |
สิ่งสำคัญเจ็ดประการในการเปลี่ยนทีมความพร้อมใช้งานสูง |