| มิถุนายน 23, 2022 |
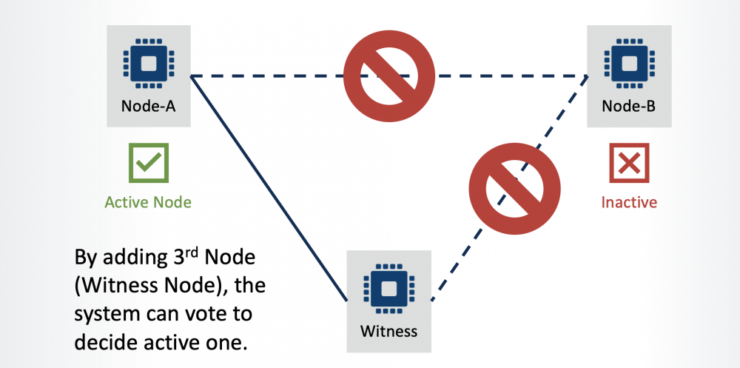
“Split Brain” คืออะไรและจะหลีกเลี่ยงได้อย่างไร |
| มิถุนายน 19, 2022 |
การจำลองข้อมูลระหว่างโหนดทำงานอย่างไร |
| มิถุนายน 15, 2022 |
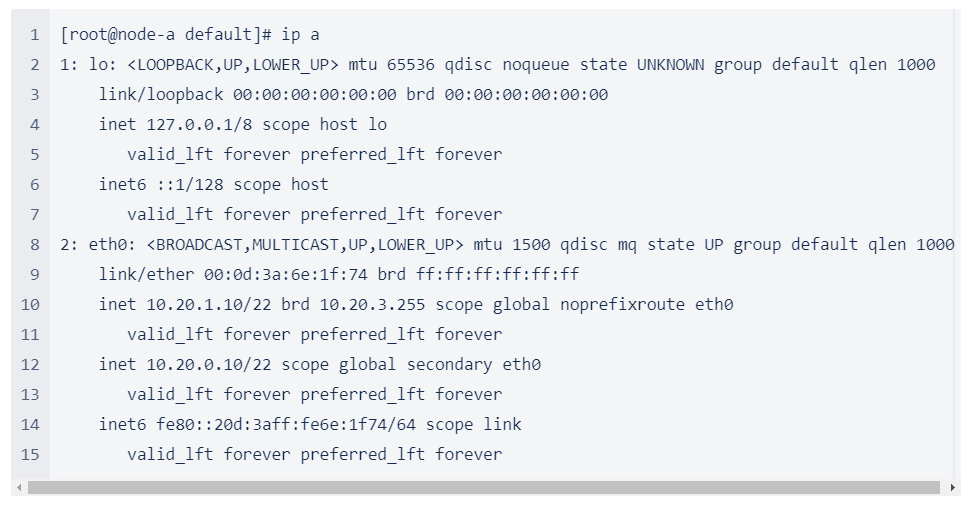
วิธีที่ไคลเอ็นต์เชื่อมต่อกับ Active Node |
| มิถุนายน 11, 2022 |
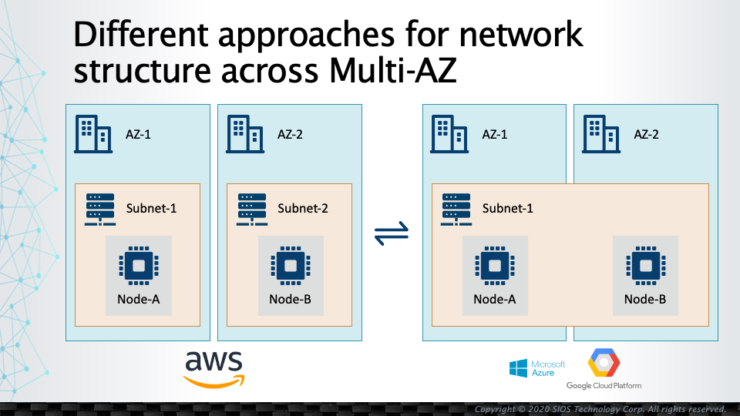
แพลตฟอร์มคลาวด์สาธารณะและความแตกต่างของโครงสร้างเครือข่าย |
| มิถุนายน 7, 2022 |
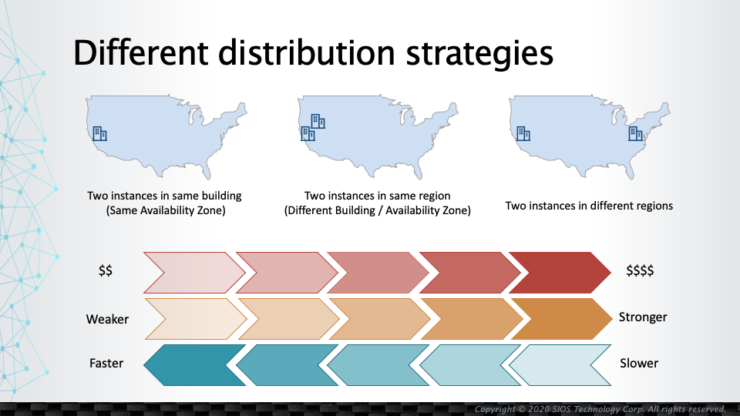
วิธีการกระจายปริมาณงานเมื่อย้ายไปยังสภาพแวดล้อมระบบคลาวด์ |