การจำลองข้อมูล
การจำลองข้อมูลตามเวลาจริงเพื่อความพร้อมใช้งานสูง
การจำลองข้อมูลคืออะไร
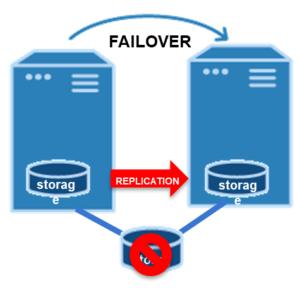
การจำลองข้อมูล เป็นกระบวนการที่ข้อมูลบนเซิร์ฟเวอร์จริง/เสมือนหรืออินสแตนซ์คลาวด์ (อินสแตนซ์หลัก) ถูกจำลองหรือคัดลอกอย่างต่อเนื่องไปยังเซิร์ฟเวอร์รองหรืออินสแตนซ์คลาวด์ (อินสแตนซ์สแตนด์บาย) องค์กรจำลองข้อมูลเพื่อรองรับ ความพร้อมใช้งานสูง , การสำรองข้อมูล และ/หรือการกู้คืนข้อมูลหลังภัยพิบัติ ข้อมูลจะถูกจำลองแบบซิงโครนัสหรืออะซิงโครนัสทั้งนี้ขึ้นอยู่กับตำแหน่งของอินสแตนซ์รอง วิธีที่ข้อมูลถูกจำลองแบบส่งผลกระทบต่อ Recovery Time Objectives (RTO) และ Recovery Point Objectives (RPO)
ตัวอย่างเช่น หากคุณต้องการกู้คืนจากความล้มเหลวของระบบ อินสแตนซ์สแตนด์บายของคุณควรอยู่บนเครือข่ายท้องถิ่น (LAN) สำหรับแอปพลิเคชันฐานข้อมูลที่สำคัญ คุณสามารถจำลองข้อมูลแบบซิงโครนัสจากอินสแตนซ์หลักผ่าน LAN ไปยังอินสแตนซ์รองได้ ซึ่งจะทำให้อินสแตนซ์สแตนด์บายของคุณ "ร้อน" และซิงค์กับอินสแตนซ์ที่ใช้งานอยู่ ดังนั้นจึงพร้อมรับช่วงต่อทันทีในกรณีที่เกิดความล้มเหลว สิ่งนี้เรียกว่าความพร้อมใช้งานสูง (HA)
ในกรณีที่เกิดภัยพิบัติ คุณต้องแน่ใจว่าอินสแตนซ์รองของคุณไม่ได้อยู่ร่วมกับอินสแตนซ์หลักของคุณ ซึ่งหมายความว่าคุณต้องการให้อินสแตนซ์รองในไซต์ทางภูมิศาสตร์อยู่ห่างจากอินสแตนซ์หลักหรือในอินสแตนซ์ระบบคลาวด์ที่เชื่อมต่อผ่าน WAN เพื่อหลีกเลี่ยงผลกระทบด้านลบต่อประสิทธิภาพของปริมาณงาน การจำลองข้อมูลบน WAN จะไม่พร้อมกัน ซึ่งหมายความว่าการอัปเดตอินสแตนซ์สแตนด์บายจะทำให้การอัปเดตที่ทำกับอินสแตนซ์ที่ใช้งานอยู่ล่าช้า ส่งผลให้เกิดความล่าช้าในระหว่างกระบวนการกู้คืน
ทำไมต้องทำซ้ำข้อมูลไปยังคลาวด์?
มีเหตุผลห้าประการที่คุณต้องการจำลองข้อมูลของคุณไปยังคลาวด์
- ดังที่เราได้กล่าวไว้ข้างต้น การจำลองแบบบนคลาวด์จะเก็บข้อมูลของคุณไว้นอกสถานที่และอยู่ห่างจากไซต์ของบริษัท แม้ว่าภัยพิบัติครั้งใหญ่ เช่น ไฟไหม้ น้ำท่วม พายุ ฯลฯ สามารถทำลายล้างอินสแตนซ์หลักของคุณ อินสแตนซ์รองของคุณนั้นปลอดภัยในระบบคลาวด์ และสามารถนำมาใช้เพื่อกู้คืนข้อมูลและแอปพลิเคชันที่ได้รับผลกระทบจากภัยพิบัติ
- การจำลองแบบคลาวด์มีราคาถูกกว่าการจำลองข้อมูลไปยังศูนย์ข้อมูลของคุณเอง คุณสามารถขจัดค่าใช้จ่ายที่เกี่ยวข้องกับการบำรุงรักษาศูนย์ข้อมูลสำรอง ซึ่งรวมถึงค่าใช้จ่ายด้านฮาร์ดแวร์ การบำรุงรักษา และการสนับสนุน
- สำหรับธุรกิจขนาดเล็ก การจำลองข้อมูลไปยังระบบคลาวด์จะมีความปลอดภัยมากขึ้น โดยเฉพาะหากคุณไม่มีความชำนาญด้านความปลอดภัยเกี่ยวกับพนักงาน ทั้งความปลอดภัยทางกายภาพและเครือข่ายที่ผู้ให้บริการระบบคลาวด์มอบให้นั้นไม่มีใครเทียบได้
- การจำลองข้อมูลไปยังระบบคลาวด์ทำให้สามารถปรับขนาดได้ตามต้องการ เมื่อธุรกิจของคุณเติบโตหรือหดตัว คุณไม่จำเป็นต้องลงทุนในฮาร์ดแวร์เพิ่มเติมเพื่อรองรับอินสแตนซ์รองของคุณ หรือให้ฮาร์ดแวร์นั้นไม่ได้ใช้งานหากธุรกิจชะลอตัว คุณยังไม่มีสัญญาระยะยาว
- เมื่อจำลองข้อมูลไปยังระบบคลาวด์ คุณมีตัวเลือกทางภูมิศาสตร์มากมาย รวมถึงการมีอินสแตนซ์ระบบคลาวด์ในเมืองถัดไป ทั่วประเทศ หรือในประเทศอื่นตามที่ธุรกิจของคุณกำหนด
เหตุใดจึงต้องทำซ้ำข้อมูลระหว่างอินสแตนซ์ระบบคลาวด์
แม้ว่าผู้ให้บริการระบบคลาวด์จะระมัดระวังทุกวิถีทางเพื่อให้แน่ใจว่าพร้อมใช้งานได้ 100 เปอร์เซ็นต์ แต่ก็เป็นไปได้ที่เซิร์ฟเวอร์คลาวด์แต่ละตัวจะล้มเหลวอันเนื่องมาจากความเสียหายทางกายภาพต่อความผิดพลาดของฮาร์ดแวร์และซอฟต์แวร์ ซึ่งเป็นสาเหตุเดียวกันทั้งหมดที่ทำให้ฮาร์ดแวร์ภายในองค์กรล้มเหลว ด้วยเหตุผลนี้ องค์กรที่รันแอปพลิเคชันที่มีความสำคัญต่อภารกิจในคลาวด์ควรทำซ้ำข้อมูลบนคลาวด์เพื่อรองรับ ความพร้อมใช้งานสูง และ การกู้คืนระบบ . คุณสามารถจำลองข้อมูลระหว่างโซนความพร้อมใช้งานในภูมิภาคเดียว ระหว่างภูมิภาคในคลาวด์ ระหว่างแพลตฟอร์มคลาวด์ต่างๆ กับระบบภายในองค์กร หรือการผสมผสานแบบไฮบริดใดๆ
การจำลองข้อมูลแบบเรียลไทม์ของ SIOS เพื่อความพร้อมใช้งานสูงและการกู้คืนจากภัยพิบัติ
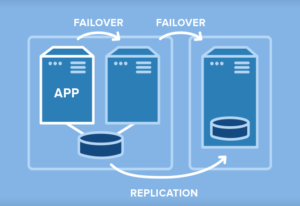
SIOS Datakeeper™ ใช้การจำลองข้อมูลระดับบล็อกที่มีประสิทธิภาพเพื่อให้อินสแตนซ์หลักและรองของคุณซิงโครไนซ์ หากเกิดเฟลโอเวอร์ อินสแตนซ์รองยังคงทำงานต่อไป ทำให้ผู้ใช้สามารถเข้าถึงข้อมูลล่าสุดได้ ด้วยโซลูชัน SIOS RPO จะเป็นศูนย์เสมอ และ RTO จะขึ้นอยู่กับแอปพลิเคชัน แต่โดยทั่วไปแล้ว 30 วินาทีถึงสองสามนาที
ผลิตภัณฑ์ SIOS ปกป้องแอปพลิเคชันที่ใช้ Windows หรือ Linux ที่ทำงานในสภาพแวดล้อมจริง เสมือน คลาวด์หรือไฮบริด และในสถานการณ์การกู้คืนไซต์หรือภัยพิบัติร่วมกัน ทำให้มีความพร้อมใช้งานสูงและการกู้คืนจากความเสียหายสำหรับแอปพลิเคชัน เช่น SAP และฐานข้อมูล รวมทั้ง Oracle , ฮานา, MaxDB, SQL Server , DB2 และอื่นๆ อีกมากมาย ความเรียบง่าย "นอกกรอบ" ความยืดหยุ่นในการกำหนดค่า ความน่าเชื่อถือ ประสิทธิภาพ และความคุ้มค่าของผลิตภัณฑ์ SIOS ทำให้พวกเขาแตกต่างจากผลิตภัณฑ์อื่นๆ ซอฟต์แวร์จัดกลุ่ม .
ในสภาพแวดล้อม Windows SIOS DataKeeper Cluster Edition จะผสานรวมกับและขยาย Windows Server Failover Clustering (WSFC) ได้อย่างราบรื่นด้วยกลไกการจำลองข้อมูลตามโฮสต์ที่เพิ่มประสิทธิภาพการทำงาน ในขณะที่ WSFC จัดการคลัสเตอร์ซอฟต์แวร์ SIOS จะทำการจำลองข้อมูลเพื่อเปิดใช้งานการป้องกันจากภัยพิบัติ และทำให้แน่ใจว่าข้อมูลสูญหายเป็นศูนย์ ในกรณีที่คลัสเตอร์การจัดเก็บข้อมูลที่ใช้ร่วมกันเป็นไปไม่ได้หรือทำไม่ได้ เช่น ในสภาพแวดล้อมการจัดเก็บข้อมูลบนคลาวด์ ระบบเสมือน และประสิทธิภาพสูง
ในสภาพแวดล้อม Linux SIOS LifeKeeper และ SIOS DataKeeper ให้การรวมกันอย่างแน่นหนาของคลัสเตอร์เฟลโอเวอร์ที่มีความพร้อมใช้งานสูง การตรวจสอบแอปพลิเคชันอย่างต่อเนื่อง การจำลองข้อมูล และนโยบายการกู้คืนที่กำหนดค่าได้ ปกป้องแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของคุณจากการหยุดทำงานและภัยพิบัติ
——————————————————————————————————————————— นี่คือตัวอย่างในโลกแห่งความเป็นจริง ว่าบริษัทผู้ผลิตชั้นนำรายใดรายหนึ่งใช้ SIOS เพื่อสร้างโซลูชันที่มีความพร้อมใช้งานสูงในระบบคลาวด์โดยใช้การจำลองข้อมูลแบบเรียลไทม์
วิธีบรรลุ HA ในสภาพแวดล้อมคลาวด์ด้วยการจำลองข้อมูลตามเวลาจริง
Bonfiglioli เป็นบริษัทชั้นนำด้านการออกแบบ ผลิต และจัดจำหน่ายของอิตาลี เชี่ยวชาญด้านระบบอัตโนมัติทางอุตสาหกรรม เครื่องจักรเคลื่อนที่ และผลิตภัณฑ์พลังงานลม และมีพนักงานมากกว่า 3,600 คนในสถานที่ต่างๆ ทั่วโลก ในการดำเนินธุรกิจ บริษัทต้องอาศัยแอปพลิเคชันที่สำคัญต่อภารกิจต่างๆ รวมถึงระบบ SAP ERP โครงสร้างพื้นฐานด้านไอทีของบริษัทประกอบด้วยศูนย์ข้อมูล VMware ภายในองค์กรและศูนย์ข้อมูลระยะไกลเพื่อความต่อเนื่องทางธุรกิจและการป้องกันภัยพิบัติ เนื่องจากแอปพลิเคชันส่วนใหญ่ทำงานในสภาพแวดล้อม Windows Bonfiglioli จึงใช้คลัสเตอร์ Windows Server failover ระดับแขกในสภาพแวดล้อม VMware เพื่อให้มีความพร้อมใช้งานสูงและการป้องกันภัยพิบัติ
ทีมไอทีของบริษัทใช้โปรแกรมเพื่อย้ายส่วนหนึ่งของการดำเนินงานด้านไอทีไปยังคลาวด์ของ Microsoft Azure และใช้ประโยชน์จาก Azure เป็นไซต์กู้คืนจากความเสียหาย ข้อกำหนดที่สำคัญของแผนการโยกย้ายของบริษัทคือการทำให้แน่ใจว่าสถาปัตยกรรมคลาวด์สามารถให้การป้องกันความพร้อมใช้งานสูงได้ดีกว่าเมื่อก่อน และทำให้แน่ใจว่า Bonfiglioli สามารถปฏิบัติตามข้อตกลงระดับบริการ (SLA) ที่เข้มงวดได้ต่อไป
ในสภาพแวดล้อมภายในองค์กร บริษัทใช้คลัสเตอร์ VMware ซึ่งช่วยให้ Windows Server Failover Clustering (WSFC) สามารถจัดการการเฟลโอเวอร์ไปยังเซิร์ฟเวอร์รองในกรณีที่โครงสร้างพื้นฐานล้มเหลว อย่างไรก็ตาม การให้การป้องกันประเภทนี้ในระบบคลาวด์ถือเป็นความท้าทาย เนื่องจากการใช้คลัสเตอร์เกสต์กับดิสก์บัสที่ใช้ร่วมกันไม่ใช่โซลูชันระบบคลาวด์ที่ทำงานได้ การสร้างคลัสเตอร์ใน VMware โดยใช้ Raw Device Mapping และแชร์บัสดิสก์ (RDM) นั้นท้าทายและสร้างข้อจำกัดสำหรับการสำรองข้อมูลเครื่องเสมือน
การแก้ไขปัญหา
หลังจากประเมินโซลูชันหลายรายการแล้ว Bonfiglioli เลือก SIOS DataKeeper ให้เป็นระบบคลาวด์ที่มีความพร้อมใช้งานสูงและโซลูชันการกู้คืนจากความเสียหายเมื่อเรียนรู้ว่า SIOS DataKeeper เป็นโซลูชันคลัสเตอร์ที่มีความพร้อมใช้งานสูงที่ผ่านการรับรองเพียงโซลูชันเดียวสำหรับ SAP ในระบบคลาวด์สาธารณะ นอกจากนี้ BGP ซึ่งเป็นหุ้นส่วนที่ปรึกษาด้านการจัดการของ Bonfiglioli มีประสบการณ์กับ SIOS DataKeeper และรู้ว่าติดตั้งง่าย โปร่งใสต่อระบบปฏิบัติการ และโซลูชันที่ได้รับการพิสูจน์แล้วและมีประสิทธิภาพสูง
ด้วย SIOS ทีมไอทีได้สร้างสภาพแวดล้อมแบบคลัสเตอร์โดยไม่มี RDM พวกเขาสร้างคลัสเตอร์สองโหนดใน VMware และเพิ่ม SIOS DataKeeper Cluster Edition เพื่อซิงโครไนซ์ที่เก็บข้อมูลผ่านการจำลองข้อมูลแบบเรียลไทม์ในแต่ละอินสแตนซ์ของคลัสเตอร์ ในสภาพแวดล้อมภายในองค์กร พื้นที่จัดเก็บข้อมูลแบบซิงโครไนซ์จะปรากฏต่อ WSFC เป็นดิสก์จัดเก็บข้อมูลที่ใช้ร่วมกันเพียงแผ่นเดียว
SIOS DataKeeper ยังให้การป้องกันความพร้อมใช้งานสูงสำหรับอินสแตนซ์ SAP ของบริษัท และกำจัดจุดล้มเหลวเพียงจุดเดียว ทีมไอทีใช้ SIOS DataKeeper จำลองดิสก์พาร์ติชันระดับ SSD ในศูนย์ข้อมูลภายในองค์กรของบริษัทโดยใช้การจำลองข้อมูลแบบเรียลไทม์ ซึ่งช่วยให้ Bonfiglioli สามารถกู้คืนเครื่องเสมือนไปยัง Microsoft Azure ได้ในกรณีที่เกิดภัยพิบัติ
ผลลัพธ์
Daniele Bovina สถาปนิกระบบที่ Bonfiglioli แสดงความคิดเห็นเกี่ยวกับผลลัพธ์ "SIOS DataKeeper ทำให้เรามีวิธีง่ายๆ ในการย้ายระบบ SAP ที่มีความสำคัญต่อธุรกิจของเราไปยัง Microsoft Azure cloud พร้อมปฏิบัติตาม SLA ที่เข้มงวดของเราในด้านความพร้อมใช้งาน การกู้คืนจากความเสียหาย และประสิทธิภาพ” ——————————————————————————————————————————– สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ SIOS Clustering Solutions ติดต่อเรา หรือ ขอทดลองใช้ฟรี .
อ้างอิง
- https://storageservers.wordpress.com/2018/02/12/difference-between-backup-and-replication-2/
- http://www.bbc.co.uk/newsbeat/article/16838342/could-the-digital-cloud-used-for-storage-ever-crash
สืบพันธุ์จาก SIOS

 วิธีบรรลุความพร้อมใช้งานสูงด้วยคลัสเตอร์
วิธีบรรลุความพร้อมใช้งานสูงด้วยคลัสเตอร์