
การวัดและปรับปรุงประสิทธิภาพปริมาณงานเขียนบน GCP โดยใช้ SIOS DataKeeper สำหรับ Windows
พื้นหลัง
โพสต์นี้ใช้เพื่อบันทึกสิ่งที่ค้นพบของฉันใน GCP เกี่ยวกับประสิทธิภาพการเขียนไปยังดิสก์ที่กำลังจำลองแบบไปยัง GCP แต่ก่อนอื่น ข้อมูลพื้นฐานบางอย่าง ลูกค้าแสดงความกังวลว่า DataKeeper เพิ่มโอเวอร์เฮดจำนวนมากให้กับประสิทธิภาพการเขียนเมื่อทำการทดสอบด้วยมิเรอร์ซิงโครนัสระหว่าง Google Zones ในภูมิภาคเดียวกัน การทดสอบดั้งเดิมที่พวกเขาทำคือกับไฟล์บิตแมปบนไดรฟ์ C ซึ่งเป็น SSD แบบถาวร ในการกำหนดค่านี้ พวกเขากดเพียง 70 MBps เท่านั้น พวกเขาพยายามย้ายบิตแมปไปยังดิสก์ GCP สุดขีด แต่ประสิทธิภาพไม่ดีขึ้น
การย้ายบิตแมปไปยัง SSD ในเครื่อง
ฉันแนะนำให้พวกเขาย้ายบิตแมปไปยัง SSD ในเครื่อง แต่พวกเขาลังเลเพราะพวกเขาเชื่อว่าดิสก์สุดขีดที่พวกเขาใช้สำหรับบิตแมปนั้นมีเวลาแฝงและปริมาณงานที่ดีหรือดีกว่า SSD ในเครื่อง ดังนั้นพวกเขาจึงสงสัยว่ามันจะทำให้ ความแตกต่าง. นอกจากนี้ การเพิ่ม SSD ภายในไม่ใช่งานเล็กน้อย เนื่องจากจะเพิ่มได้ก็ต่อเมื่อ VM ได้รับการจัดเตรียมในตอนแรกเท่านั้น
การเลือกประเภทอินสแตนซ์
ขณะที่ฉันออกเดินทางเพื่อทำงานให้เสร็จ สิ่งแรกที่ฉันค้นพบก็คืออินสแตนซ์บางประเภทไม่รองรับ SSD ในเครื่อง ตัวอย่างเช่น E2-Standard-8 ไม่รองรับ SSD ภายใน สำหรับการทดสอบครั้งแรกของฉัน ฉันเลือกใช้อินสแตนซ์ประเภท C2-Standard-8 ซึ่งถือว่าเป็น "การเพิ่มประสิทธิภาพการประมวลผล" ฉันแนบ SSD ถาวรขนาด 500 GB และเริ่มทำการทดสอบประสิทธิภาพการเขียน และค้นพบอย่างรวดเร็วว่าฉันสามารถเขียนดิสก์ได้เพียงประมาณ 140MBps แทนที่จะเป็นความเร็วสูงสุด 240MBps ลูกค้ายืนยันว่าเห็นแบบเดียวกัน เป็นเรื่องที่น่าสับสน แต่เราตัดสินใจดำเนินการต่อและลองใช้อินสแตนซ์ประเภทอื่น
ประเภทอินสแตนซ์ที่สองที่เราเลือกคือ N2-Standard-8 ด้วยอินสแตนซ์ประเภทนี้ เราจึงสามารถพุชดิสก์ให้มีความเร็วปริมาณงานสูงสุด 240 MBps เมื่อไม่ได้จำลองดิสก์ ฉันย้ายบิตแมปไปยัง SSD ในเครื่องที่ฉันได้จัดเตรียมไว้และทำซ้ำการทดสอบเดียวกันบนมิเรอร์ซิงโครนัส (DataKeeper v8.8.2) และได้รับผลลัพธ์ที่แสดงด้านล่าง
ผลลัพธ์
พารามิเตอร์การทดสอบ Diskspd diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b64K -Sh -LD:data.dat diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b8K -Sh -LD:data .dat diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b4K -Sh -LD:data.dat
MBps
ข้อมูล
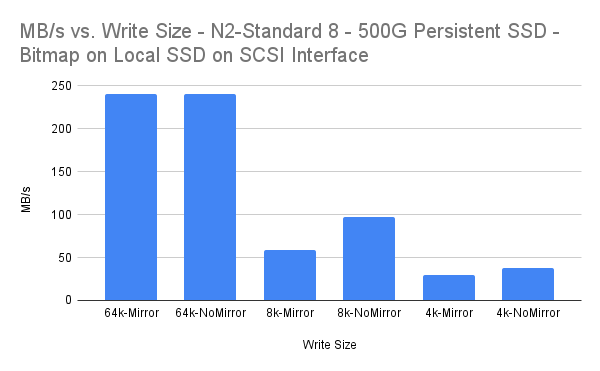
| เขียนขนาด | MB/วินาที | ค่าใช้จ่ายร้อยละ MBps |
| 64k-กระจก | 240.01 | 0.00% |
| 64k-NoMirror | 240.02 | |
| 8k-กระจก | 58.87 | 39.18% |
| 8k-NoMirror | 96.8 | |
| 4k-กระจกเงา | 29.34 | 21.84% |
| 4k-NoMirror | 37.54 |
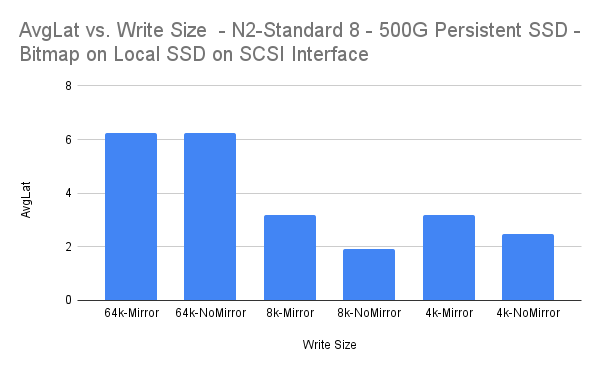
| เขียนขนาด | AvgLat | ค่าใช้จ่ายเฉลี่ย |
| 64k-กระจก | 6.247 | -0.02% |
| 64k-NoMirror | 6.248 | |
| 8k-กระจก | 3.183 | 39.21% |
| 8k-NoMirror | 1.935 | |
| 4k-กระจกเงา | 3.194 | 21.88% |
| 4k-NoMirror | 2.495 |
บทสรุป
ขนาดการเขียน 64k และ 4k ทั้งหมดมีค่าใช้จ่ายซึ่งอาจถือได้ว่า "ยอมรับได้" สำหรับการจำลองแบบซิงโครนัส ขนาดการเขียน 8k ดูเหมือนว่าจะมีค่าใช้จ่ายจำนวนมาก แม้ว่าเวลาแฝงเฉลี่ยที่ 3.183 มิลลิวินาทียังค่อนข้างต่ำ
-Dave Bermingham ผู้อำนวยการ Customer Success ทำซ้ำโดยได้รับอนุญาตจาก SIOS




