Date: กันยายน 15, 2023

วิธีปกป้องแอปพลิเคชันในแพลตฟอร์มคลาวด์
แพลตฟอร์มคลาวด์ปกป้องแอปพลิเคชันจากการหยุดทำงานที่เกิดจากความล้มเหลวของฮาร์ดแวร์เท่านั้น แอปพลิเคชันที่สำคัญต่อภารกิจจำเป็นต้องมีการป้องกัน HA/DR โดยไม่คำนึงถึงสภาพแวดล้อมคลาวด์ที่แอปพลิเคชันทำงาน
เมื่อจัดให้มีการป้องกันความพร้อมใช้งานสูง ถือเป็นหลักการทั่วไปเพื่อให้แน่ใจว่าส่วนประกอบทั้งหมดมีความซ้ำซ้อนเพื่อหลีกเลี่ยง Single Points of Failure (SPOF) นั่นคือ ตรวจสอบให้แน่ใจว่าไม่มีองค์ประกอบใดที่ทำให้ระบบทั้งหมดหยุดทำงานหากล้มเหลว อย่างไรก็ตาม สิ่งสำคัญคือต้องทราบว่าโครงสร้างพื้นฐานการดำเนินงานนั้นเข้าถึงได้ยากในระบบคลาวด์สาธารณะ
ในคลัสเตอร์ความพร้อมใช้งานสูงบนระบบคลาวด์ มีความเป็นไปได้ที่โหนดสแตนด์บายจะอยู่บนโฮสต์เซิร์ฟเวอร์เดียวกัน ในแร็คเดียวกัน และใช้สวิตช์เครือข่ายเดียวกันกับโหนดปฏิบัติการ ยกเว้นกรณีที่คุณกำหนดค่าองค์ประกอบเหล่านี้ด้วยความซ้ำซ้อน องค์ประกอบใดๆ อาจเป็น SPOF และทำให้แอปพลิเคชันเสี่ยงต่อความล้มเหลวร้ายแรง
จำเป็นต้องตรวจสอบให้แน่ใจว่าโหนดคลัสเตอร์อยู่บน “ภูมิภาค” คลาวด์และ “โซนความพร้อมใช้งาน” ที่แตกต่างกันซึ่งแยกศูนย์ข้อมูลและโครงสร้างพื้นฐานการปฏิบัติงานออกจากกันทางกายภาพในที่ตั้งทางภูมิศาสตร์ที่แตกต่างกัน
หลักการสำคัญในการรับรองความพร้อมใช้งานในระบบคลาวด์คืออะไร
คุณไม่สามารถคาดหวังว่าส่วนประกอบต่างๆ ที่ประกอบเป็นโครงสร้างพื้นฐานด้านไอทีทางกายภาพจะทำงานตามข้อกำหนดตลอดไปได้ เนื่องจากชิ้นส่วนเสื่อมสภาพ ระบบเข้ากันไม่ได้ และการตั้งค่าเปลี่ยนแปลง แม้ว่าการบำรุงรักษาตามปกติจะช่วยลดความเสี่ยงของการหยุดทำงาน แต่ก็มีแนวโน้มว่าบางสิ่งจะล้มเหลวตลอดวงจรชีวิตผลิตภัณฑ์
ในบางกรณีที่เกิดขึ้นไม่บ่อยนัก คุณอาจมีข้อบกพร่องร้ายแรงที่แฝงอยู่ในระบบปฏิบัติการหรือซอฟต์แวร์ฝังตัวที่ทำให้แอปพลิเคชันหยุดทำงาน
ดังที่คุณอาจสังเกตเห็นแล้วว่าการกำหนดค่าคลัสเตอร์ HA สอดคล้องกับหลักการนี้ทุกประการ และจุดความล้มเหลวจุดเดียวจะถูกกำจัดโดยการทำให้เซิร์ฟเวอร์ที่สำคัญและทรัพยากรซ้ำซ้อนกับระบบที่ใช้งานอยู่ (ระบบที่ใช้งานจริง) อย่างไรก็ตาม สิ่งสำคัญคือต้องจำสองสิ่ง: 1. ฮาร์ดแวร์เซิร์ฟเวอร์ไม่ใช่ส่วนประกอบที่สำคัญเพียงอย่างเดียว และ 2. ส่วนประกอบ SPOF ที่สำคัญอื่นๆ อาจไม่ปรากฏให้คุณเห็นในโครงสร้างพื้นฐานระบบคลาวด์สาธารณะ
ระวังข้อผิดพลาดของความล้มเหลวจุดเดียวที่ซ่อนอยู่ในโครงสร้างพื้นฐานที่มองไม่เห็นของระบบคลาวด์
คลาวด์สาธารณะส่วนใหญ่ทำงานในโหมดที่เรียกว่า “ผู้เช่าหลายราย” นั่นคือพวกเขารัน VM ของหลายบริษัทบนเซิร์ฟเวอร์โฮสต์จริงเดียวกัน และด้วยสัญญาปกติ คุณจะไม่สามารถระบุเซิร์ฟเวอร์โฮสต์ที่ระบบของคุณทำงานอยู่ได้ ซึ่งอาจทำให้เกิดปัญหาได้เช่น
โหนดสแตนด์บายในคลัสเตอร์คลาวด์ของคุณอาจวางอยู่บนเซิร์ฟเวอร์โฮสต์เดียวกันกับที่ดำเนินการโหนดที่ใช้งานอยู่ แม้ว่าคุณจะกำหนดค่าการกำหนดค่าคลัสเตอร์ HA หากโฮสต์เซิร์ฟเวอร์ล่ม โหนดปฏิบัติการและโหนดสแตนด์บายก็จะล่มเช่นกัน ในสถานการณ์นี้ ผู้ให้บริการระบบคลาวด์ของคุณจะเป็นผู้ตัดสินใจว่าระบบของคุณจะได้รับการกู้คืนเมื่อใดและอย่างไร
เซิร์ฟเวอร์โฮสต์ที่ดำเนินการโหนดที่ใช้งานอยู่และเซิร์ฟเวอร์โฮสต์ที่ดำเนินการโหนดสแตนด์บายอาจอยู่ในแร็คเดียวกัน ในกรณีนี้ ชั้นวางจะกลายเป็น SPOF ดังนั้นหากเกิดความล้มเหลว โหนดที่ใช้งานอยู่และโหนดสแตนด์บายที่อยู่ด้านล่างก็จะล้มเหลวเช่นกัน
นอกจากนี้ ในชั้นบนของโครงสร้างพื้นฐานของคุณ เช่น สวิตช์เครือข่ายที่รวมแร็ค เกตเวย์และเราเตอร์หลายชุด และหน่วยจ่ายไฟในศูนย์ข้อมูล โหนดระบบปฏิบัติการและโหนดระบบสแตนด์บายอาจอยู่ร่วมกันในระบบเดียวกัน และหากคีย์เหล่านี้ ส่วนประกอบต่างๆ ไม่ซ้ำซ้อน แสดงว่าคุณมีจุดล้มเหลวจุดเดียวที่หลีกเลี่ยงไม่ได้ ขอย้ำอีกครั้งสำหรับบริษัทที่เป็นผู้ใช้คลาวด์สาธารณะ โครงสร้างพื้นฐานของศูนย์ข้อมูลดังกล่าวเปรียบเสมือนกล่องดำ จึงอาจไม่สามารถดูการกำหนดค่าโดยละเอียดเพื่อระบุ SPOF ได้
โซนและภูมิภาคความพร้อมใช้งานของระบบคลาวด์สาธารณะควรได้รับการใช้ประโยชน์จากความพร้อมใช้งาน
เราจะหลีกเลี่ยงความล้มเหลวจุดเดียวที่ซ่อนอยู่ในระบบคลาวด์สาธารณะอย่างชัดเจนได้อย่างไร วิธีการที่มีประสิทธิภาพที่สุดคือการใช้ “Availability Zones” และ “Regions” ที่เตรียมไว้บนฝั่งคลาวด์
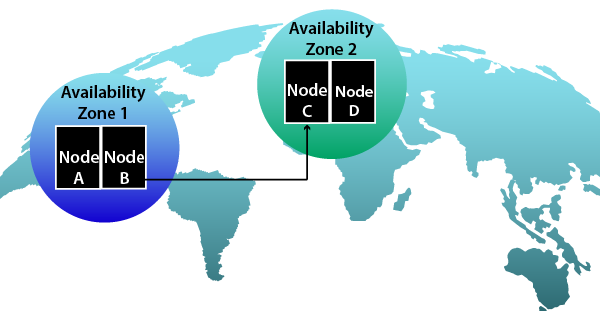
Availability Zone คือการแยกโครงสร้างพื้นฐานทางกายภาพภายในศูนย์ข้อมูลของคุณโดยอิสระ และภูมิภาคเป็นศูนย์ข้อมูลอิสระที่แยกจากกันตามภูมิศาสตร์ คลาวด์สาธารณะช่วยให้คุณสามารถใช้ Availability Zone หรือภูมิภาคเหล่านี้โดยเจตนาเพื่อวัตถุประสงค์ที่แตกต่างกัน
ด้วยการสร้างการกำหนดค่าคลัสเตอร์ HA ซึ่งมีการกระจายโหนดปฏิบัติการและโหนดสแตนด์บายในโซนความพร้อมใช้งานที่แตกต่างกันทั่วทั้งสองภูมิภาคหรือมากกว่านี้ ทำให้สามารถหลีกเลี่ยง SPOF เกือบทั้งหมดได้อย่างแน่นอน หากคุณปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเหล่านี้ คุณสามารถรับประกันความพร้อมใช้งานได้อย่างมั่นใจ DR(การกู้คืนระบบ) และ BCP (การวางแผนความต่อเนื่องทางธุรกิจ)
ทำซ้ำโดยได้รับอนุญาตจากSIOS