Date: มกราคม 17, 2023

ทำความเข้าใจกับความซับซ้อนของความพร้อมใช้งานสูงสำหรับแอปพลิเคชันที่สำคัญต่อธุรกิจ
การลดเวลาหยุดทำงานในระบบ ฐานข้อมูล และแอปพลิเคชันให้เหลือน้อยที่สุดเป็นกุญแจสำคัญในการเพิ่มผลผลิตสูงสุด องค์กรสมัยใหม่พึ่งพาระบบ ฐานข้อมูล และแอปพลิเคชันที่สำคัญต่อธุรกิจ เช่น การวางแผนทรัพยากรขององค์กร (ERP) การจัดการลูกค้าสัมพันธ์ (CRM) อีคอมเมิร์ซ ระบบการเงิน และการจัดการห่วงโซ่อุปทาน เพื่อดำเนินการอย่างมีประสิทธิภาพและมอบประสบการณ์ที่เหนือกว่าแก่ลูกค้า . เมื่อระบบ ฐานข้อมูล หรือแอปพลิเคชันล้มเหลว การป้องกันความพร้อมใช้งานสูงจะกู้คืนการดำเนินการเพื่อให้ธุรกิจดำเนินต่อไปได้
ความพร้อมใช้งานสูงคืออะไร?
ความพร้อมใช้งานสูงเป็นแอตทริบิวต์ของระบบ ฐานข้อมูล หรือแอปพลิเคชันที่ได้รับการออกแบบให้ทำงานอย่างต่อเนื่องและเชื่อถือได้เป็นระยะเวลานาน เป้าหมายของความพร้อมใช้งานสูงคือการลดหรือขจัดเวลาหยุดทำงานทั้งที่วางแผนไว้และไม่ได้วางแผนไว้สำหรับแอปพลิเคชันที่สำคัญ โดยผสมผสานส่วนประกอบที่ซ้ำซ้อนและเทคโนโลยีอื่นๆ เพื่อจัดการกับจุดล้มเหลวจุดเดียวในระบบ ฐานข้อมูล หรือแอปพลิเคชัน
กล่าวง่ายๆว่า ความพร้อมใช้งานสูง ตรวจสอบให้แน่ใจว่าระบบ ฐานข้อมูล หรือแอปพลิเคชันของคุณทำงานเมื่อใดและตามที่คาดไว้: “เมื่อ” หมายถึงเปอร์เซ็นต์ของเวลาที่ระบบ ฐานข้อมูล หรือแอปพลิเคชันต้องเปิดใช้งานและทำงานตามที่คาดหมาย หมายความว่าแอปพลิเคชันทำงานตามที่ผู้ใช้คาดหวังและเป็นไปตาม ความต้องการของตนได้อย่างทันท่วงที
ไอดีซีโมเดล
ข้อตกลงระดับบริการ (SLA) สำหรับความพร้อมใช้งานสูงช่วยให้แน่ใจว่าองค์ประกอบหลักของโครงสร้างพื้นฐานด้านไอทีนั้นใช้งานได้และพร้อมใช้งานในช่วงเวลาทำการ IDC ได้สร้างแบบจำลอง SLA สำหรับความพร้อมใช้งานสูงที่กำหนดห้าระดับด้วยข้อกำหนดด้านเวลาทำงานต่อไปนี้: • AL4 (ความพร้อมใช้งานอย่างต่อเนื่อง—ความทนทานต่อความผิดพลาดของระบบ): ไม่มีการหยุดชะงักของผู้ใช้และเวลาหยุดทำงานทั้งที่วางแผนไว้และไม่ได้วางแผนรวมสูงสุดไม่เกิน 5 นาที 15 วินาทีต่อปี (ความพร้อมใช้งาน 99.999% หรือ "ห้า-เก้า")
• AL3 (ความพร้อมใช้งานสูง—การทำคลัสเตอร์แบบดั้งเดิม): การหยุดชะงักของผู้ใช้น้อยที่สุดและเวลาหยุดทำงานทั้งที่วางแผนไว้และไม่ได้วางแผนรวมสูงสุดไม่เกิน 52 นาที 35 วินาทีต่อปี (ความพร้อมใช้งาน 99.99% หรือ "สี่-เก้า")
• AL2 (การกู้คืน—การจำลองข้อมูลและการสำรองข้อมูล): การขัดจังหวะของผู้ใช้บางรายและเวลาหยุดทำงานทั้งที่วางแผนไว้และไม่ได้วางแผนรวมสูงสุดไม่เกิน 8 ชั่วโมง 45 นาที และ 56 วินาทีต่อปี (ความพร้อมใช้งาน 99.9% หรือ "สามเก้า")
• AL1 (ความน่าเชื่อถือ—ส่วนประกอบที่ถอดเปลี่ยนได้อย่างรวดเร็ว): การหยุดให้บริการทั้งหมดและเวลาหยุดทำงานทั้งที่วางแผนไว้และไม่ได้วางแผนรวม 87 ชั่วโมง 39 นาที 29 วินาทีต่อปี (ความพร้อมใช้งาน 99% หรือ “ทู-ไนน์”)
• AL0 (เซิร์ฟเวอร์ที่ไม่มีการป้องกัน): หยุดให้บริการทั้งหมด และไม่มีการกำหนด SLA สถานะการออนไลน์
ความต้องการความพร้อมใช้งานสูงของคุณขึ้นอยู่กับความสำคัญของระบบโดยรวม แอปพลิเคชัน และปัจจัยอื่นๆ อีกมากมาย ได้แก่: • แอปพลิเคชันมีความสำคัญต่อธุรกิจเพียงใด • ลูกค้าสังเกตเห็นผลกระทบหรือไม่ • แอปพลิเคชันทำงานบ่อยเพียงใด • ผู้ใช้จำนวนเท่าใดที่ได้รับผลกระทบจากการหยุดทำงาน • ฐานข้อมูลหรือแอปพลิเคชันต้องล้มเหลวอย่างรวดเร็วเพียงใดไปยังระบบสำรองเพื่อหลีกเลี่ยงการหยุดชะงัก • ปริมาณข้อมูล การสูญเสียเป็นสิ่งที่ยอมรับได้ โดยทั่วไปความพร้อมใช้งาน Five Nines จะถูกสงวนไว้สำหรับแอปพลิเคชันที่ต้องการการดำเนินการแบบ "Stateful" อย่างต่อเนื่อง สำหรับแอปพลิเคชันที่สำคัญทางธุรกิจ ความพร้อมใช้งานสี่ในเก้าเป็นมาตรฐาน ระบบและแอปพลิเคชันที่ไม่สำคัญ คุณอาจต้องการความพร้อมใช้งานเพียงสองในเก้าเท่านั้น เมื่อพิจารณาเวลาหยุดทำงานที่ยอมรับได้ สิ่งสำคัญคือต้องพิจารณา: • เวลาหยุดทำงานที่ไม่ได้วางแผนไว้ (นั่นคือความล้มเหลวของฮาร์ดแวร์หรือซอฟต์แวร์) • เวลาหยุดทำงานตามแผนสำหรับการบำรุงรักษาฮาร์ดแวร์และซอฟต์แวร์ตามปกติ • เวลาทำงานในระดับแอปพลิเคชันและฐานข้อมูล โซลูชันความพร้อมใช้งานสูงต่างๆ สามารถช่วยให้ธุรกิจบรรลุวัตถุประสงค์ SLA ได้ สำหรับระบบ ฐานข้อมูล และแอปพลิเคชันต่างๆ แม้ว่าความพร้อมใช้งานอย่างต่อเนื่อง (AL4) อาจดูเหมือนเป็นเป้าหมายที่เหมาะสมที่สุดสำหรับการปรับใช้ที่สำคัญต่อธุรกิจ สิ่งสำคัญคือต้องหาสมดุลที่เหมาะสมระหว่างต้นทุนและความพร้อมใช้งาน ความพร้อมใช้งานอย่างต่อเนื่องอาจส่งผลเสียต่อเวลาหยุดทำงานที่จำเป็นสำหรับการบำรุงรักษาตามแผน เนื่องจากโดยทั่วไประบบจะต้องออฟไลน์เมื่อมีการใช้การอัปเดตแอปพลิเคชันหรือระบบปฏิบัติการ เมื่อเทียบกับความพร้อมใช้งานสูง ซึ่งโดยทั่วไปจะอนุญาตให้มีการอัปเดตแบบต่อเนื่อง
เมตริกความพร้อมใช้งานสูง: RTO กับ RPO
นอกจากเวลาทำงานและความพร้อมใช้งานแล้ว Recovery Time Objectives (RTO) และ Recovery Point Objectives (RPO) ยังเป็นเมตริกที่สำคัญที่ใช้ในการประเมินความพร้อมใช้งานสูง (เช่นเดียวกับการกู้คืนความเสียหาย) ในระบบ ฐานข้อมูล หรือแอปพลิเคชัน
ร.ฟ.ท คือระยะเวลาสูงสุดที่ยอมรับได้ของการหยุดทำงานใดๆ แอปพลิเคชันการประมวลผลธุรกรรมออนไลน์โดยทั่วไปมี RTO ต่ำที่สุด และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจมักมี RTO เพียงไม่กี่วินาที
RPO คือจำนวนการสูญเสียข้อมูลสูงสุดที่สามารถยอมรับได้เมื่อเกิดความล้มเหลวขึ้น สำหรับการกู้คืนระบบ RPO ทั่วไปสำหรับแอปพลิเคชันและข้อมูลที่เกี่ยวข้องอาจใช้เวลา 24 ชั่วโมง การสำรองข้อมูลทุกคืนช่วยให้มั่นใจได้ว่าการเปลี่ยนแปลงข้อมูลในช่วง 24 ชั่วโมงที่ผ่านมาสามารถกู้คืนได้ในกรณีที่เกิดภัยพิบัติ อย่างไรก็ตาม สำหรับแอปพลิเคชันและข้อมูลที่มีความพร้อมใช้งานสูง RPO มักจะเป็นศูนย์ นั่นคือ ไม่ควรมีข้อมูลสูญหายภายใต้สถานการณ์ความล้มเหลวใดๆ
การทำคลัสเตอร์แบบดั้งเดิม
คลัสเตอร์ความพร้อมใช้งานสูงคือกลุ่มของโหนดเซิร์ฟเวอร์ (และส่วนประกอบอื่นๆ) ที่รองรับแอปพลิเคชันที่สำคัญต่อธุรกิจซึ่งต้องการเวลาหยุดทำงานน้อยที่สุดซอฟต์แวร์การทำคลัสเตอร์ ให้คุณกำหนดค่าเซิร์ฟเวอร์ของคุณเป็นคลัสเตอร์เพื่อให้เซิร์ฟเวอร์หลายเครื่องสามารถทำงานร่วมกันเพื่อให้มีความพร้อมใช้งานสูงและป้องกันข้อมูลสูญหาย องค์กรด้านไอทีพึ่งพาการทำคลัสเตอร์ที่มีความพร้อมใช้งานสูงเพื่อขจัดความล้มเหลวเพียงจุดเดียวและลดความเสี่ยงของการหยุดทำงานและข้อมูลสูญหาย
คลัสเตอร์ความพร้อมใช้งานสูงในสถานที่แบบดั้งเดิมคือกลุ่มของโหนดเซิร์ฟเวอร์ตั้งแต่สองโหนดขึ้นไปที่เชื่อมต่อกับที่เก็บข้อมูลที่ใช้ร่วมกัน (โดยทั่วไปคือเครือข่ายพื้นที่จัดเก็บหรือ SAN) ที่ได้รับการกำหนดค่าด้วยระบบปฏิบัติการ ฐานข้อมูล และแอปพลิเคชันเดียวกัน (ดูรูปที่ 1 ).
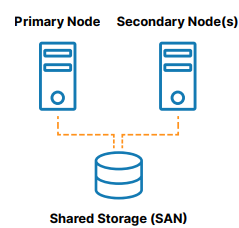
โหนดหนึ่งถูกกำหนดให้เป็นโหนดหลัก (หรือแอ็คทีฟ) และอีกโหนดถูกกำหนดให้เป็นโหนดรอง (หรือสแตนด์บาย) หากโหนดหลักล้มเหลว การทำคลัสเตอร์จะช่วยให้การทำงานของระบบ ฐานข้อมูล หรือแอปพลิเคชันล้มเหลวโดยอัตโนมัติไปยังโหนดรองตั้งแต่หนึ่งโหนดขึ้นไป และดำเนินการต่อตามปกติโดยมีการหยุดชะงักน้อยที่สุด เนื่องจากโหนดรองเชื่อมต่อกับที่เก็บข้อมูลเดียวกัน การดำเนินการจึงดำเนินต่อไปโดยไม่มีข้อมูลสูญหาย ประโยชน์ของสถาปัตยกรรมคลัสเตอร์นี้คือลดเวลาหยุดทำงาน กำจัดข้อมูลสูญหาย และปกป้องความสมบูรณ์ของข้อมูล
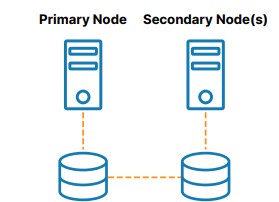
อย่างไรก็ตาม มีหลายกรณีที่ไม่ต้องการใช้พื้นที่เก็บข้อมูลร่วมกัน ความล้มเหลวในที่เก็บข้อมูลที่ใช้ร่วมกันจะทำให้คลัสเตอร์ทั้งหมดออฟไลน์ ทำให้มีความเสี่ยงที่จะเกิดความล้มเหลวเพียงจุดเดียว (SPoF) พื้นที่จัดเก็บ SAN อาจมีต้นทุนสูงและซับซ้อนในการเป็นเจ้าของและจัดการ ประการสุดท้าย การใช้ที่เก็บข้อมูลร่วมกันในระบบคลาวด์สามารถเพิ่มต้นทุนและความซับซ้อนที่สำคัญโดยไม่จำเป็น คลาวด์บางตัวไม่มีตัวเลือกพื้นที่เก็บข้อมูลที่ใช้ร่วมกันเลย
ดังที่ปรากฏใน รูปที่ 2 คลัสเตอร์ SANless หรือ “ไม่มีอะไรแบ่งปัน” เป็นทางเลือกที่ดีที่สุดสำหรับที่เก็บข้อมูลที่ใช้ร่วมกัน ในการกำหนดค่าเหล่านี้ โหนดคลัสเตอร์ทุกโหนดมีที่จัดเก็บในเครื่องของตัวเอง การจำลองแบบระดับบล็อกบนโฮสต์ที่มีประสิทธิภาพใช้เพื่อซิงโครไนซ์ที่เก็บข้อมูลบนโหนดคลัสเตอร์ ทำให้เหมือนกัน ในกรณีที่เกิดข้อผิดพลาด โหนดรองจะเข้าถึงสำเนาที่เหมือนกันของที่เก็บข้อมูลที่ใช้โดยโหนดหลัก ประโยชน์ของสถาปัตยกรรมคลัสเตอร์นี้คือการกำจัด SPoF การกำจัดต้นทุนและความซับซ้อนของ SAN ใช้งานง่ายและประหยัดต้นทุนในระบบคลาวด์ ลดเวลาหยุดทำงาน และลดการสูญเสียข้อมูล
หลักการออกแบบ
คลัสเตอร์ High Availability ที่ล้ำหน้าที่สุดมีหลักการออกแบบดังต่อไปนี้: • พวกเขาล้มเหลวโดยอัตโนมัติและรวดเร็วไปยังระบบที่ซ้ำซ้อนเมื่อส่วนประกอบที่ใช้งานล้มเหลว • พวกเขารักษาแนวทางปฏิบัติที่ดีที่สุดเฉพาะแอปพลิเคชันในระหว่างและหลังความล้มเหลว • พวกเขาให้ความสามารถในการสลับและสลับกลับด้วยตนเองเพื่อให้การทดสอบมีประสิทธิภาพและการบำรุงรักษาแบบ "ต่อเนื่อง" โดยน้อยที่สุด ดาวน์ไทม์ที่วางแผนไว้ • สามารถตรวจจับความล้มเหลวโดยอัตโนมัติในเครือข่าย ที่เก็บข้อมูล OS ฮาร์ดแวร์ หรือแอปพลิเคชัน • ป้องกันข้อมูลสูญหายในกรณีที่ระบบล้มเหลว • ล้มเหลวในโหนดที่แยกจากกันทางภูมิศาสตร์สำหรับการกู้คืนความเสียหาย
การทำคลัสเตอร์ความพร้อมใช้งานสูง
มีโซลูชันซอฟต์แวร์การทำคลัสเตอร์ที่หลากหลายสำหรับ Windows, Linux ดิสทริบิวชัน และไฮเปอร์ไวเซอร์ต่างๆ (โซลูชันเครื่องเสมือน) กลุ่มหนึ่งรองรับระบบปฏิบัติการเดียวเท่านั้น เช่นต่อไปนี้: • Windows Server Failover Clustering (WSFC): ให้ความพร้อมใช้งานสูงและการกู้คืนความเสียหายสำหรับแอปพลิเคชันที่โฮสต์ เช่น Microsoft SQL Server และ Microsoft Exchange • SUSE Linux Enterprise High Availability Extension (HAE): รองรับการทำคลัสเตอร์ของเซิร์ฟเวอร์ Linux จริงและเสมือนด้วยการทำคลัสเตอร์ที่ขับเคลื่อนด้วยนโยบายและการจำลองข้อมูลอย่างต่อเนื่อง • เครื่องกระตุ้นหัวใจแบบหมวกสีแดง (เครื่องกระตุ้นหัวใจ): สร้างคลัสเตอร์ไซต์เดียวเพื่อประสิทธิภาพ ความพร้อมใช้งานสูง โหลดบาลานซ์ และความสามารถในการปรับขนาด ไม่มีโซลูชันใดที่แสดงรายการในที่นี้ที่สามารถปกป้อง SAP ที่ทำงานบนระบบปฏิบัติการ Oracle Linux เป็นต้น ดังนั้น แต่ละโซลูชันจะจำกัดความยืดหยุ่นและตัวเลือกการปรับใช้ของคุณ ก้าวหน้ายิ่งขึ้น โซลูชันความพร้อมใช้งานสูง เช่น SIOS Protection Suite สำหรับ Linux มอบการป้องกันที่รับรู้แอปพลิเคชันใน Linux ดิสทริบิวชันหลักๆ รวมถึง Oracle Linux, Red Hat และ SUSE
นอกจากนี้ ทุกแอปพลิเคชัน ฐานข้อมูล และระบบ ERP มีข้อกำหนดของตนเองสำหรับการกำหนดค่าและการจัดการอย่างต่อเนื่อง เพื่อให้เป็นไปตามข้อกำหนดเหล่านี้ โดยทั่วไป HAE และ Pacemaker ต้องการทักษะทางเทคนิคระดับสูงและการเขียนสคริปต์ด้วยตนเองที่ซับซ้อน ซึ่งทำให้เกิดข้อผิดพลาดของมนุษย์และความล้มเหลวที่ไม่น่าเชื่อถือ
ตัวอย่างของแอปพลิเคชัน ฐานข้อมูล และระบบ ERP ที่มีความสำคัญต่อธุรกิจโดยทั่วไปได้รับการปกป้องด้วยการทำคลัสเตอร์เมื่อเกิดข้อผิดพลาด ได้แก่ SAP S/4HANA, SQL Server และแอปพลิเคชันและฐานข้อมูลอื่นๆ
SAP S/4HANA ผู้จำหน่าย Linux หลายรายเสนอส่วนขยายความพร้อมใช้งานสูงแบบโอเพ่นซอร์สสำหรับ SAP ในการสมัครสมาชิก “Enterprise for SAP” สภาพแวดล้อม SAP S/4HANA ประกอบด้วยบริการหลายอย่าง เช่น ABAP SAP Central Service (ASCS), Evaluated Receipt Settlement (ERS) และส่วนประกอบ SAP อื่นๆ ที่จำเป็นต้องได้รับการบำรุงรักษาในตำแหน่งที่ถูกต้องและเริ่มต้นตามลำดับที่ถูกต้อง ในผลิตภัณฑ์การทำคลัสเตอร์แบบโอเพ่นซอร์ส เช่น SUSE HAE และ Red Hat Pacemaker การกำหนดค่าและจัดการคลัสเตอร์ด้วยตนเองในสภาพแวดล้อมที่ซับซ้อนเหล่านี้อาจใช้เวลานานและมีแนวโน้มที่จะเกิดข้อผิดพลาดจากมนุษย์ ซึ่งจะเพิ่มความเสี่ยงต่อการหยุดทำงานอย่างรุนแรงและข้อมูลสูญหาย
จำเป็นต้องมีความเชี่ยวชาญเชิงลึกเฉพาะในแอปพลิเคชันและฐานข้อมูลเพื่อสร้างโซลูชันความพร้อมใช้งานสูงที่รับรู้แอปพลิเคชัน ในทางตรงกันข้าม, ชุดป้องกัน SIOS สำหรับ Linux รวมถึงชุดการกู้คืนแอปพลิเคชันสำหรับ SAP และ HANA ที่รับรองว่าการเฟลโอเวอร์จะคงไว้ซึ่งแนวทางปฏิบัติที่ดีที่สุดของแอปพลิเคชัน
SAP ยังมี HANA System Replication ซึ่งเป็นคุณสมบัติที่มาพร้อมกับซอฟต์แวร์ HANA มีการซิงโครไนซ์อย่างต่อเนื่องของฐานข้อมูล SAP HANA กับตำแหน่งรองในศูนย์ข้อมูลเดียวกัน ที่ไซต์ระยะไกล หรือในระบบคลาวด์ ข้อมูลจะถูกจำลองไปยังไซต์รองและโหลดไว้ล่วงหน้าในหน่วยความจำ เมื่อเกิดความล้มเหลว ไซต์รองจะเข้าแทนที่โดยไม่ต้องรีสตาร์ทฐานข้อมูล ซึ่งช่วยลด RTO อย่างไรก็ตาม การย้อนกลับไปยังโหนดหลักจะต้องถูกเรียกใช้ด้วยตนเอง HSR จำเป็นต้องจับคู่กับซอฟต์แวร์การทำคลัสเตอร์ที่รู้จักแอปพลิเคชัน เช่น SIOS Protection Suite ที่สามารถตรวจจับความล้มเหลวและจัดการความล้มเหลวได้หากจำเป็น
เซิร์ฟเวอร์ SQL
บริษัทหลายแห่งใช้ SQL Server เป็นฐานข้อมูลส่วนหลังสำหรับแอปพลิเคชันหลักที่สนับสนุนฟังก์ชันทางธุรกิจที่สำคัญ Microsoft WSFC มักใช้เพื่อสนับสนุน Always On Availability Groups (AG) และ SQL Server Failover Cluster Instances (FCI) สำหรับแอปพลิเคชัน SQL Server
อย่างไรก็ตาม WSFC ที่มี AG ต้องการสิทธิ์ใช้งาน SQL Server Enterprise Edition ที่มีค่าใช้จ่ายสูง นอกจากนี้ ด้วย FCI อินสแตนซ์ทั้งหมดจะล้มเหลวผ่านไปยังโหนดสแตนด์บาย ด้วย AG เฉพาะฐานข้อมูลในกลุ่มเท่านั้นที่ได้รับการป้องกัน
โดยใช้ SIOS Data Keeper ด้วย WSFC ช่วยให้คุณสามารถให้การป้องกันความพร้อมใช้งานขั้นสูงขั้นสูงสำหรับ SQL Server โดยใช้สิทธิ์การใช้งาน Standard Edition ที่คุ้มค่า
แอปพลิเคชั่นและฐานข้อมูลอื่น ๆ
ซอฟต์แวร์ SIOS สามารถใช้เพื่อป้องกันแอปพลิเคชันที่สำคัญทางธุรกิจ ฐานข้อมูล และ ERP ที่หลากหลาย รวมถึง Oracle, MaxDB, MySQL, PostgreSQL และ DB2 ซอฟต์แวร์ SIOS เปิดใช้งานการทำคลัสเตอร์และการกู้คืนระบบ
ในบล็อกถัดไป เราจะดูกรณีการใช้งานเฉพาะในอุตสาหกรรมเพื่อช่วยให้คุณเข้าใจว่าธุรกิจต่างๆ บรรลุความพร้อมใช้งานสูงสำหรับแอปพลิเคชันที่มีความสำคัญต่อภารกิจได้อย่างไร
ทำซ้ำโดยได้รับอนุญาตจาก SIOS