Date: กุมภาพันธ์ 19, 2022

วิธีขจัดจุดเดียวของความล้มเหลวในระบบคลาวด์ด้วยคลัสเตอร์ที่มีความพร้อมใช้งานสูง
เมื่อให้การป้องกันความพร้อมใช้งานสูง หลักการทั่วไปคือต้องแน่ใจว่าส่วนประกอบทั้งหมดซ้ำซ้อนเพื่อหลีกเลี่ยงจุดเดียวของความล้มเหลว (SPOF) นั่นคือ ตรวจสอบให้แน่ใจว่าไม่มีองค์ประกอบใดที่ทำให้ทั้งระบบหยุดทำงานหากล้มเหลว อย่างไรก็ตาม สิ่งสำคัญที่ควรทราบคือโครงสร้างพื้นฐานด้านการปฏิบัติงานนั้นยากต่อการเข้าถึงในระบบคลาวด์สาธารณะ
ใน คลัสเตอร์ความพร้อมใช้งานสูงบนคลาวด์ มีความเป็นไปได้ที่โหนดสแตนด์บายจะอยู่บนโฮสต์เซิร์ฟเวอร์เดียวกัน ในแร็คเดียวกัน และใช้สวิตช์เครือข่ายเดียวกันกับโหนดปฏิบัติการ เว้นแต่คุณจะกำหนดค่าองค์ประกอบเหล่านี้ด้วยความซ้ำซ้อน องค์ประกอบใดๆ อาจเป็น SPOF และทำให้แอปพลิเคชันเสี่ยงต่อการล้มเหลวจากภัยพิบัติ
จำเป็นต้องตรวจสอบให้แน่ใจว่าโหนดคลัสเตอร์อยู่ใน "ภูมิภาค" และ "โซนความพร้อมใช้งาน" ของคลาวด์ที่แตกต่างกันซึ่งแยกศูนย์ข้อมูลและโครงสร้างพื้นฐานด้านการปฏิบัติงานออกจากตำแหน่งทางภูมิศาสตร์ที่แตกต่างกัน
หลักการสำคัญในการรับรองความพร้อมใช้งานมีอะไรบ้าง
คุณไม่สามารถคาดหวังให้ส่วนประกอบต่างๆ ที่ประกอบเป็นโครงสร้างพื้นฐานด้านไอทีจริงจะทำงานตามข้อกำหนดตลอดไปไม่ได้ ชิ้นส่วนสึกหรอ ระบบเข้ากันไม่ได้ และการตั้งค่าเปลี่ยนไป แม้ว่าการบำรุงรักษาตามปกติจะช่วยลดความเสี่ยงของการหยุดทำงาน แต่มีแนวโน้มว่าจะมีบางอย่างล้มเหลวตลอดวงจรชีวิตผลิตภัณฑ์
ในบางกรณีซึ่งเกิดขึ้นไม่บ่อยนัก คุณอาจมีจุดบกพร่องร้ายแรงที่แฝงอยู่ในระบบปฏิบัติการหรือซอฟต์แวร์ฝังตัวที่ทำให้แอปพลิเคชันหยุดทำงาน
ดังที่คุณอาจสังเกตเห็นแล้ว การกำหนดค่าคลัสเตอร์ High Availability นั้นสอดคล้องกับหลักการนี้ทุกประการ และจุดความล้มเหลวเพียงจุดเดียวจะถูกกำจัดโดยการทำให้เซิร์ฟเวอร์สำคัญและทรัพยากรซ้ำซ้อนกับระบบที่ใช้งานอยู่ (ระบบการผลิต) อย่างไรก็ตาม สิ่งสำคัญที่ต้องจำไว้สองสิ่งคือ หนึ่ง ฮาร์ดแวร์เซิร์ฟเวอร์ไม่ใช่ส่วนประกอบที่สำคัญเพียงอย่างเดียว จุดที่สอง ส่วนประกอบ SPOF ที่สำคัญอื่นๆ อาจไม่ปรากฏให้คุณเห็นในโครงสร้างพื้นฐานคลาวด์สาธารณะ
ระวังหลุมพรางของความล้มเหลวจุดเดียวที่ซ่อนอยู่ในโครงสร้างพื้นฐานที่มองไม่เห็นของคลาวด์
ระบบคลาวด์สาธารณะส่วนใหญ่ทำงานในโหมดที่เรียกว่า "ผู้เช่าหลายราย" นั่นคือพวกเขาเรียกใช้ VM ของหลายบริษัทบนเซิร์ฟเวอร์โฮสต์จริงเดียวกัน และด้วยสัญญาปกติ คุณไม่สามารถระบุได้ว่าเซิร์ฟเวอร์โฮสต์ใดที่ระบบของคุณทำงาน ซึ่งอาจทำให้เกิดปัญหาเนื่องจากโหนดสแตนด์บายในคลัสเตอร์ระบบคลาวด์ของคุณอาจถูกวางบนเซิร์ฟเวอร์โฮสต์เดียวกันกับที่ทำงานบนโหนดที่ใช้งานอยู่ แม้ว่าคุณจะกำหนดค่าคอนฟิกูเรชันคลัสเตอร์ HA หากเซิร์ฟเวอร์โฮสต์หยุดทำงาน โหนดปฏิบัติการและโหนดสแตนด์บายก็จะลดลงด้วย ในสถานการณ์สมมตินี้ ผู้ให้บริการระบบคลาวด์ของคุณตัดสินใจว่าจะกู้คืนระบบเมื่อใดและอย่างไร
เซิร์ฟเวอร์โฮสต์ที่ดำเนินการโหนดที่ใช้งานอยู่และเซิร์ฟเวอร์โฮสต์ที่ดำเนินการโหนดสแตนด์บายอาจอยู่ในชั้นวางเดียวกัน ในกรณีนี้ ชั้นวางจะกลายเป็น SPOF ดังนั้นหากเกิดความล้มเหลวขึ้นที่นั่น ทั้งโหนดที่ทำงานอยู่และโหนดสแตนด์บายภายใต้โหนดนั้นจะล้มเหลวด้วย
นอกจากนี้ ในชั้นบนของโครงสร้างพื้นฐานของคุณ เช่น สวิตช์เครือข่ายที่รวมชั้นวาง เกตเวย์และเราเตอร์หลายตัว และหน่วยจ่ายไฟในศูนย์ข้อมูล โหนดระบบปฏิบัติการและโหนดระบบสแตนด์บายอาจอยู่ร่วมกันในระบบเดียวกัน และหากองค์ประกอบหลักเหล่านี้ไม่ซ้ำซ้อน แสดงว่าคุณมีจุดบกพร่องจุดเดียวที่หลีกเลี่ยงไม่ได้ อีกครั้งสำหรับบริษัทที่เป็นผู้ใช้คลาวด์สาธารณะ โครงสร้างพื้นฐานของศูนย์ข้อมูลดังกล่าวเป็นกล่องดำ อาจเป็นไปไม่ได้ที่จะเห็นการกำหนดค่าโดยละเอียดเพื่อระบุ SPOF
ควรใช้ประโยชน์จากโซนความพร้อมใช้งานคลาวด์สาธารณะและภูมิภาคเพื่อความพร้อมใช้งาน
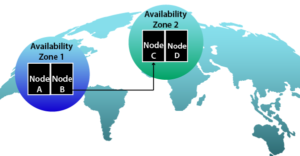
เราจะหลีกเลี่ยงจุดบกพร่องจุดเดียวที่ซ่อนอยู่ในคลาวด์สาธารณะได้อย่างไร วิธีที่มีประสิทธิภาพที่สุดคือการใช้ "Availability Zones" และ "Regions" ที่เตรียมไว้บนฝั่งคลาวด์
Availability Zone คือการแยกโครงสร้างพื้นฐานทางกายภาพที่เป็นอิสระภายในศูนย์ข้อมูลของคุณ และภูมิภาคต่าง ๆ เป็นศูนย์ข้อมูลอิสระที่แยกจากกันทางภูมิศาสตร์ ระบบคลาวด์สาธารณะบางระบบอนุญาตให้คุณใช้ Availability Zone หรือภูมิภาคเหล่านี้โดยเจตนาเพื่อจุดประสงค์ที่แตกต่างกัน
ตัวอย่างเช่น Amazon Web Service (AWS) มี 12 ภูมิภาคทั่วโลก นอกจากนี้ Microsoft Azure ยังมี 22 ภูมิภาคโดยการสร้างคอนฟิกูเรชันคลัสเตอร์ HA ซึ่งโหนดปฏิบัติการและโหนดสแตนด์บายถูกแจกจ่ายในโซนความพร้อมใช้งานที่แตกต่างกันทั่วทั้งสองภูมิภาคขึ้นไป เกือบทั้งหมดสามารถหลีกเลี่ยง SPOF ได้อย่างแน่นอนหากคุณปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเหล่านี้ คุณจะมั่นใจได้ถึงความพร้อมใช้งาน DR (การกู้คืนระบบ ) และ BCP (การวางแผนความต่อเนื่องทางธุรกิจ)