Date: พฤศจิกายน 2, 2021
ป้ายกำกับ:SIOS

การกู้คืนระบบ
วิธีเปิดใช้งานการกู้คืนข้อมูลหลังภัยพิบัติด้วยโซลูชันซอฟต์แวร์คลัสเตอร์เดียว
ปกป้องแอปพลิเคชัน Windows หรือ Linux ที่ทำงานด้วยการผสมผสานระหว่างโครงสร้างพื้นฐานทางกายภาพ เสมือน คลาวด์ หรือไฮบริดพร้อมการกู้คืนจากภัยพิบัติ
การกู้คืนจากภัยพิบัติคืออะไร?
การกู้คืนจากภัยพิบัติมีความสำคัญต่อการดำเนินธุรกิจอย่างต่อเนื่อง
Disaster Recovery (DR) เป็นกลยุทธ์และชุดนโยบาย ขั้นตอน และเครื่องมือที่ช่วยให้มั่นใจได้ว่าระบบ IT ฐานข้อมูล และแอปพลิเคชันที่สำคัญจะยังคงทำงานและพร้อมใช้งานสำหรับผู้ใช้เมื่อเกิดภัยพิบัติที่มนุษย์สร้างขึ้นหรือภัยธรรมชาติ แม้ว่าทีมไอทีจะเป็นเจ้าของกลยุทธ์การกู้คืนจากความเสียหาย DR ก็เป็นองค์ประกอบที่สำคัญของแผนความต่อเนื่องทางธุรกิจของทุกองค์กร ซึ่งเป็นกลยุทธ์และชุดนโยบาย ขั้นตอน และเครื่องมือที่ช่วยให้ธุรกิจทั้งหมดกลับมาทำงานได้หลังจากเกิดภัยพิบัติ
แต่เมื่อเราพูดถึงภัยพิบัติ ไม่จำเป็นต้องเป็นพายุเฮอริเคน ทอร์นาโด น้ำท่วม หรือแผ่นดินไหวเต็มรูปแบบที่ส่งผลกระทบต่อธุรกิจของคุณ ภัยพิบัติมีหลายรูปแบบ เช่น การโจมตีทางไซเบอร์ ข้อผิดพลาดของผู้ใช้ ไฟไหม้ การโจรกรรม การก่อกวน แม้แต่การโจมตีของผู้ก่อการร้าย กล่าวโดยสรุป ภัยพิบัติคือวิกฤตใดๆ ที่ส่งผลให้ระบบหยุดทำงานเป็นเวลานานและ/หรือสูญเสียข้อมูลครั้งใหญ่ในวงกว้างซึ่งส่งผลกระทบต่อโครงสร้างพื้นฐานด้านไอที ศูนย์ข้อมูล และธุรกิจของคุณ
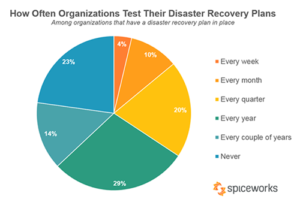
ใน Spiceworks ล่าสุด สำรวจ ร้อยละ 59 ขององค์กรระบุว่าพวกเขาประสบปัญหาการหยุดทำงาน 1 ถึง 3 ครั้ง (นั่นคือ การหยุดชะงักของบริการที่เกี่ยวข้องกับไอทีในระดับปกติ) ตลอดระยะเวลาหนึ่งปี 11 เปอร์เซ็นต์มีประสบการณ์ 4-6 ครั้ง และ 7 เปอร์เซ็นต์ประสบปัญหา 7 หรือ มากกว่า. นอกจากนี้ การสำรวจยังระบุด้วยว่าบริษัทขนาดใหญ่ซึ่งต้องใช้บริการจำนวนมากขึ้น มีแนวโน้มที่จะประสบปัญหาการหยุดชะงักมากกว่าองค์กรขนาดเล็ก ตัวอย่างเช่น 71 เปอร์เซ็นต์ของธุรกิจขนาดเล็กประสบปัญหาการหยุดชะงักอย่างน้อยหนึ่งครั้งในช่วง 12 เดือนที่ผ่านมา เทียบกับ 79 เปอร์เซ็นต์ของธุรกิจขนาดกลาง และ 87 เปอร์เซ็นต์ของธุรกิจขนาดใหญ่ เมื่อคุณดูสถิติเหล่านั้น คุณจะรู้ว่าคุณกำลังใช้ชีวิตอยู่กับเวลาที่ยืมมา ถ้าคุณไม่มีแผนการกู้คืนจากความเสียหาย
แต่มีข่าวดี เมื่อเทียบกับสถิติในปีที่แล้ว ดูเหมือนว่าองค์กรทุกขนาดและจากทุกอุตสาหกรรมจะทำงานได้ดีขึ้นเมื่อต้องมีแผนการกู้คืนความเสียหาย จากการสำรวจเดียวกันของ Spiceworks 95 เปอร์เซ็นต์ ขององค์กรมีแผน DR แต่น่าเสียดายที่ 23 เปอร์เซ็นต์ไม่เคยทดสอบหรือใช้แผนของพวกเขา การใช้แผน DR ของคุณมีความสำคัญพอๆ กับการฝึกดับเพลิงของนักเรียนหรือการฝึกชุมนุม การวางแผนเป็นเพียงขั้นตอนแรก หากผู้ที่เกี่ยวข้องในการดำเนินการตามแผนไม่ทราบว่าต้องทำอย่างไร คุณจะไม่สามารถกู้คืนจากภัยพิบัติได้
ความพร้อมใช้งานสูงเทียบกับ การกู้คืนระบบ
แต่ก่อนที่เราจะดำเนินการต่อ เรามาทำความเข้าใจความแตกต่างระหว่างแนวทางปฏิบัติที่ดีที่สุดสำหรับการจัดการความล้มเหลวของระบบกับภัยพิบัติกันก่อน ในการกู้คืนจากความล้มเหลวของระบบ ระบบสำรอง ซอฟต์แวร์ และข้อมูลควรอยู่ในเครือข่ายท้องถิ่น (LAN) ของคุณ สำหรับแอปพลิเคชันฐานข้อมูลที่สำคัญ คุณสามารถจำลองข้อมูลแบบซิงโครนัสผ่าน LAN ได้ ซึ่งจะทำให้อินสแตนซ์สแตนด์บายของคุณ “ร้อน” และซิงค์กับอินสแตนซ์ที่ใช้งานอยู่ ดังนั้นจึงพร้อมรับช่วงต่อทันทีในกรณีที่เกิดความล้มเหลว นี้เรียกว่า ความพร้อมใช้งานสูง (HA) .
อย่างไรก็ตาม ในการกู้คืนระบบ ซอฟต์แวร์ และข้อมูลในกรณีที่เกิดภัยพิบัติ หมายถึงส่วนประกอบที่ซ้ำซ้อนต้องอยู่บนเครือข่ายบริเวณกว้าง (WAN) ด้วย WAN การจำลองข้อมูลจะไม่พร้อมกันเพื่อหลีกเลี่ยงผลกระทบด้านลบต่อประสิทธิภาพของปริมาณงาน ซึ่งหมายความว่าการอัปเดตอินสแตนซ์สแตนด์บายจะทำให้การอัปเดตที่ทำกับอินสแตนซ์ที่ใช้งานอยู่ล่าช้า ส่งผลให้เกิดความล่าช้าในระหว่างกระบวนการกู้คืน เนื่องจากภัยพิบัติมีน้อยมาก ความล่าช้าบางอย่างอาจพอทนได้และขึ้นอยู่กับ (ก) ความสำคัญของธุรกิจของคุณในการบรรลุ Recovery Time Objective (RTO) และ Recovery Point Objective (RPO) ที่ต่ำที่สุดเท่าที่จะเป็นไปได้ และ (b) งบประมาณที่คุณมี สามารถจัดสรรเพื่อให้ได้ RTO และ RPO ที่ดีที่สุด
RTO คือระยะเวลาสูงสุดที่ยอมรับได้ของการหยุดทำงาน และ RPO คือจำนวนสูงสุดของการสูญเสียข้อมูลที่สามารถยอมรับได้เมื่อเกิดภัยพิบัติ สำหรับการกู้คืนจากความเสียหาย RTO ที่มีความยาวหลายนาทีหรือหลายชั่วโมงนั้นเป็นเรื่องปกติสำหรับโซลูชันบางอย่าง เนื่องจากมีค่าใช้จ่ายสูงเกินกว่าที่จะพยายามกู้คืนผ่าน WAN ในเวลาเพียงไม่กี่นาที สำหรับแอปพลิเคชันที่มีความสำคัญต่อภารกิจ องค์กรของคุณจะต้องการได้รับ RPO ที่ต่ำ แต่ยิ่ง RPO ของคุณต่ำ คุณก็ยิ่งต้องการกระบวนการมากขึ้นเท่านั้น เพื่อให้แน่ใจว่าข้อมูลทั้งหมดได้รับการจำลองแบบบนเซิร์ฟเวอร์สแตนด์บายก่อนที่จะเกิดข้อผิดพลาด ความพยายามนี้มีแนวโน้มที่จะเพิ่มเวลาในการฟื้นตัว
แต่ด้วยโซลูชันการกู้คืนความเสียหาย SIOS คุณสามารถบรรลุ RPO ที่น้อยที่สุดถึงไม่มีข้อมูลสูญหาย และ RTO ที่ใช้เวลาหนึ่งถึงสองนาที
SIOS มอบโซลูชันเดียวเพื่อตอบสนองความต้องการ HA และ DR ของคุณ
| ไม่ว่าคุณจะต้องการ HA ในพื้นที่ภายในไซต์เดียวหรือ DR ที่รวดเร็วและมีประสิทธิภาพในหลายไซต์ โซลูชัน SIOS จะตอบสนองทุกความต้องการด้านความต่อเนื่องทางธุรกิจของคุณ |
NS โซลูชันการกู้คืนความเสียหาย SIOS เป็นคลัสเตอร์แบบหลายไซต์ที่กระจายตัวตามภูมิศาสตร์ที่ให้ RPO วินาทีและ RTO เป็นนาที สิ่งที่ทำให้ SIOS แตกต่างจากผู้ให้บริการ DR รายอื่นๆ คือมีโซลูชันเดียวที่ตอบสนองความต้องการด้านความพร้อมใช้งานสูงและการกู้คืนจากความเสียหาย
เพื่อรองรับ DR คุณต้องกำหนดค่าคลัสเตอร์ของคุณในลักษณะเดียวกับที่คุณทำสำหรับความพร้อมใช้งานสูง แต่มีความแตกต่างที่ชัดเจนสองประการที่กล่าวถึงก่อนหน้านี้:
- โหนดคลัสเตอร์ DR อยู่ในไซต์ทางภูมิศาสตร์ ทั้งในสถานที่ เสมือน หรือในคลาวด์ ซึ่งอยู่ไกลจากอินสแตนซ์ HA
- ไซต์ DR อยู่บนเครือข่ายบริเวณกว้าง (WAN) ซึ่งหมายความว่า การจำลองข้อมูล จะเป็นแบบอะซิงโครนัสเพื่อหลีกเลี่ยงผลกระทบด้านลบต่อประสิทธิภาพของปริมาณงาน
โปรดจำไว้ว่า การจำลองข้อมูลแบบอะซิงโครนัสหมายความว่าการอัปเดตอินสแตนซ์ DR จะทำให้การอัปเดตที่ทำกับอินสแตนซ์ที่ใช้งานอยู่ล่าช้า แต่โดยทั่วไปแล้วจะไม่เกินไม่กี่วินาทีเท่านั้น แต่ด้วยการจำลองข้อมูลที่รวดเร็วอย่างเหลือเชื่อของ SIOS ใน WAN คุณสามารถเก็บสำเนาข้อมูลแบบเรียลไทม์ที่ซิงโครไนซ์ข้ามเซิร์ฟเวอร์และศูนย์ข้อมูลหลายแห่งเพื่อให้ได้ทั้ง HA และ DR
นอกจากโซลูชันเดียวสำหรับ HA/DR และการจำลองข้อมูลแบบเรียลไทม์แล้ว โซลูชัน SIOS HA/DR ยังให้:
- การบีบอัดข้อมูลระดับบล็อกเพื่อลดการโหลดเครือข่าย
- การควบคุมปริมาณแบนด์วิดท์เพื่อควบคุมและลดความแออัดของเครือข่าย
- การเพิ่มประสิทธิภาพ WAN เพื่อปรับปรุงประสิทธิภาพของเครือข่าย
- การผสานรวมกับการแทนที่ด้วยปุ่มกดเพื่อรองรับ DR และการเฟลโอเวอร์อัตโนมัติเพื่อรองรับ HA
- แนวทางแพลตฟอร์มที่ไม่เชื่อเรื่องพระเจ้า ช่วยให้คุณเลือกโซลูชัน DR ในสถานที่ เสมือน คลาวด์ หรือไฮบริด
กรณีศึกษาต่อไปนี้แสดงการใช้ SIOS DataKeeper เพื่อส่ง HA และ DR ในโซลูชันเดียว
—————————————————————————————————————————
การเปิดใช้งานการป้องกัน HA และ DR ที่ศูนย์สุขภาพระดับพรีเมียร์
โรงพยาบาล ALYN ตั้งอยู่ในอิสราเอล เป็นศูนย์สุขภาพเพื่อการฟื้นฟูเด็กชั้นนำ เชี่ยวชาญในการวินิจฉัยและฟื้นฟูทารก เด็ก และวัยรุ่นที่มีความพิการทางร่างกาย ผู้ปกครองพาบุตรหลานจากอิสราเอลและต่างประเทศเพื่อรับบริการทางการแพทย์ การรักษาพยาบาล และบริการฟื้นฟูที่ล้ำสมัยเพิ่มเติม
การค้นหาโซลูชันที่เหมาะสม
โรงพยาบาล ALYN ดำเนินการแอพพลิเคชั่นที่หลากหลาย – รวมถึงเวชระเบียนอิเล็กทรอนิกส์ (EMR), การจัดการลูกค้าสัมพันธ์ (CRM), ฐานข้อมูล SQL Server, Microsoft Exchange และ Microsoft Office เพื่อสนับสนุนการดำเนินงานทางคลินิกและการบริหาร ในฐานะผู้ให้บริการด้านการรักษาพยาบาล โรงพยาบาลต้องปฏิบัติตามกฎระเบียบของรัฐบาลที่เข้มงวด และจำเป็นต้องดำเนินการตามข้อกำหนด DR ที่เข้มงวด เพื่อให้แน่ใจว่ามีการป้องกันและความพร้อมใช้งานของแอปพลิเคชันที่มีความสำคัญต่อภารกิจ โรงพยาบาลได้เลือก Hyper-V Replica เพื่อสนับสนุนกลยุทธ์ DR โดยปฏิบัติการสองห้องเซิร์ฟเวอร์ที่แยกจากกันภายในองค์กร ทำให้ Virtual Machines (VN) ที่สำคัญทั้งหมดทำงานบนเซิร์ฟเวอร์โฮสต์ Hyper-V ใดๆ สามารถจำลองไปยังอีกห้องหนึ่งในอีกห้องหนึ่งได้ ขออภัย การกำหนดค่านี้ไม่เป็นไปตามข้อกำหนด RPO และ RTO ดังนั้นทีมไอทีจึงเริ่มตรวจสอบตัวเลือกอื่นๆ
ในการค้นหาโซลูชัน DR ที่เหมาะสม ทีมไอทีได้พิจารณา Windows Server Failover Clustering (WSFC) ซึ่งใช้พื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกัน น่าเสียดายที่ ALYN ไม่มี SAN และเนื่องจากข้อจำกัดด้านงบประมาณ การนำ SAN ที่เหมือนกันไปใช้ในห้องเซิร์ฟเวอร์ทั้งสองจึงเป็นเรื่องต้องห้ามด้านต้นทุน ด้วยเหตุผลนี้ ALYN จึงตรวจสอบโซลูชันของบุคคลที่สาม
ในการค้นหาเฟลโอเวอร์ของบุคคลที่สาม ซอฟต์แวร์จัดกลุ่ม , ALYN กำหนดสามเกณฑ์:
- โซลูชันต้องทำงานร่วมกับฮาร์ดแวร์ที่มีอยู่
- โซลูชันต้องให้การปกป้องทั้งความพร้อมใช้งานสูง (HA) และการกู้คืนความเสียหาย (DR) ในทุกแอปพลิเคชันที่สำคัญของโรงพยาบาล
- ต้นทุนรวมในการเป็นเจ้าของ (TCO) จะต้องพอดีกับงบประมาณที่จำกัดของแผนก
SIOS DataKeeper – ทางเลือกที่ชัดเจน
หลังจากประเมินโซลูชันต่างๆ มากมาย เจ้าหน้าที่ไอทีได้เลือก SIOS DataKeeper ซึ่งทีมงานอธิบายว่าเป็นโซลูชัน “ที่มอบความสามารถระดับผู้ให้บริการด้วยต้นทุนรวมในการเป็นเจ้าของที่ต่ำอย่างน่าทึ่ง” และนำเสนอ HA และ DR ในโซลูชันเดียวที่คุ้มค่า
SIOS DataKeeper รวมการจำลองข้อมูลแบบเรียลไทม์ระดับบล็อกเข้ากับการตรวจสอบระดับแอปพลิเคชันอย่างต่อเนื่องและนโยบายเฟลโอเวอร์/เฟลแบ็คที่ยืดหยุ่นในโซลูชันทั้งหมดที่ปรับใช้และจัดการได้ง่าย DataKeeper ใช้ประโยชน์จาก WSFC และรักษาความเข้ากันได้กับสภาพแวดล้อมการทำงาน ทำให้ทีมไอทีเรียนรู้วิธีใช้โซลูชันได้อย่างรวดเร็วและกำหนดค่า HA ให้เสร็จสิ้นอย่างรวดเร็วสำหรับแอปพลิเคชันทั้งหมดอย่างรวดเร็ว
ด้วย DataKeeper ทีมไอทีสามารถสร้างสามโหนด SANless คลัสเตอร์ล้มเหลว ด้วยอินสแตนซ์ที่ทำงานอยู่ตัวเดียวและอินสแตนซ์สแตนด์บายสองอินสแตนซ์ ด้วยการกำหนดค่านี้ ALYN สามารถอัปเดตระบบและซอฟต์แวร์ได้อย่างต่อเนื่องโดยไม่กระทบต่อการดำเนินการ เนื่องจากอินสแตนซ์ที่ใช้งานอยู่สามารถย้ายไปยังเซิร์ฟเวอร์ใดๆ ในคลัสเตอร์สามโหนดและยังคงได้รับการปกป้องอย่างเต็มที่ในช่วงระยะเวลาของการบำรุงรักษาฮาร์ดแวร์และซอฟต์แวร์ที่วางแผนไว้
นอกจากนี้ SIOS ยังสามารถทำงานกับพื้นที่จัดเก็บข้อมูลประเภทใดก็ได้และการจำลองข้อมูลที่ปรับให้เหมาะสม WAN ซึ่งทำให้การใช้งานไซต์ DR ระยะไกลของ ALYN ง่ายขึ้น เพื่อรักษาประสิทธิภาพการรับส่งข้อมูลในระดับสูง การจำลองข้อมูลทั่วทั้ง WAN จะเกิดขึ้นแบบอะซิงโครนัส แต่ SIOS DataKeeper ใช้เทคนิคพิเศษเพื่อเพิ่มประสิทธิภาพการรับส่งข้อมูล ทำให้ ALYN บรรลุ RPO และ RTO ที่มีความต้องการสูง
บรรทัดล่าง
วันนี้ SIOS DataKeeper ให้การป้องกันที่มีความพร้อมใช้งานสูงสำหรับแอปพลิเคชันที่มีความสำคัญต่อภารกิจทั้งหมดของ ALYN Hospital Uri Inbar ผู้อำนวยการฝ่ายไอทีของ ALYN Hospital กล่าวว่า “ด้วย SIOS เราพบโซลูชันที่มอบความสามารถระดับผู้ให้บริการด้วยต้นทุนรวมในการเป็นเจ้าของที่ต่ำอย่างน่าทึ่ง สำหรับเรา มันเป็นทางเลือกที่ชัดเจน
โรงพยาบาล ALYN จะทดสอบการกำหนดค่าเป็นประจำ และเปลี่ยนการกำหนดสถานะที่ใช้งานอยู่และสแตนด์บายเป็นประจำ ในขณะที่เปลี่ยนเส้นทางการจำลองข้อมูลตามความจำเป็นระหว่างการอัปเดตซอฟต์แวร์ที่วางแผนไว้ แอปพลิเคชันทำงานอย่างต่อเนื่องไม่ขาดตอน
—————————————————————————————————————————
ความคิดสุดท้ายเกี่ยวกับการกู้คืนภัยพิบัติ SIOS
ในสภาพแวดล้อม Windows SIOS DataKeeper สำหรับ Windows Server มีให้เลือกทั้งแบบ Standard Edition และ Cluster Edition ที่ทนทานกว่าSIOS DataKeeper Standard Edition ให้การจำลองข้อมูลแบบเรียลไทม์สำหรับการป้องกันการกู้คืนจากความเสียหายในสภาพแวดล้อมของ Windows ServerSIOS DataKeeper Cluster Edition ผสานรวมกับ Windows Server Failover Clustering (WSFC) ได้อย่างราบรื่น ทำให้สามารถกำหนดค่าความพร้อมใช้งานสูงและการกู้คืนจากความเสียหายได้
SIOS LifeKeeper และ DataKeeper รองรับการกระจาย Linux ที่สำคัญทั้งหมด รวมถึง Red Hat Enterprise Linux, SUSE Linux Enterprise Server, CentOS และ Oracle Linux และรองรับสถาปัตยกรรมการจัดเก็บข้อมูลที่หลากหลาย
เยี่ยมชมข้อมูลอ้างอิงด้านล่างสำหรับข้อมูลเพิ่มเติมเกี่ยวกับ SIOS DataKeeper หรือ SIOS LifeKeeper: อ้างอิง
- https://betanews.com/2019/05/28/disaster-recovery-sql-server/
- https://community.spiceworks.com/blog/3138-data-snapshot-how-well-equipped-are-businesses-to-bounce-back-from-disaster
- https://www.spiceworks.com/press/releases/spiceworks-study-reveals-one-in-four-companies-never-test-their-disaster-recovery-plan/
ดูเอกสารไวท์เปเปอร์ของเรา: ทำความเข้าใจกับ Disaster Recovery สำหรับตัวเลือกสำหรับ SQL Server