Date: มกราคม 30, 2019
ป้ายกำกับ:ความพร้อมใช้งานสูงสำหรับเซิร์ฟเวอร์ sql

มั่นใจในความพร้อมใช้งานสูงสำหรับ SQL Server บน Amazon Web Services
ผู้ดูแลระบบฐานข้อมูลและระบบมีตัวเลือกที่หลากหลายเพื่อให้แน่ใจว่าแอพพลิเคชั่นฐานข้อมูลที่มีความสำคัญต่อภารกิจนั้นยังคงมีอยู่ในระดับสูง โครงสร้างพื้นฐานคลาวด์สาธารณะเช่นเดียวกับที่จัดทำโดย Amazon Web Services มีตัวเลือกความพร้อมใช้งานสูงเพิ่มเติมซึ่งได้รับการสนับสนุนโดยข้อตกลงระดับบริการ แต่การกำหนดค่าที่ทำงานได้ดีในระบบคลาวด์ส่วนตัวอาจเป็นไปไม่ได้ในระบบคลาวด์สาธารณะ ตัวเลือกที่ไม่ดีในบริการ AWS ที่ใช้และ / หรือวิธีการกำหนดค่าเหล่านี้อาจทำให้ข้อกำหนดการเข้าแทนที่ล้มเหลวเมื่อจำเป็นจริง ๆ บทความนี้แสดงตัวเลือกต่าง ๆ ที่พร้อมใช้งานเพื่อให้แน่ใจว่ามีความพร้อมใช้งานสูงสำหรับ SQL Server ในคลาวด์ AWS
ตัวเลือก
สำหรับแอปพลิเคชันฐานข้อมูล AWS ให้ทางเลือกพื้นฐานแก่ผู้ดูแลระบบสองทาง แต่ละข้อมีข้อกำหนดความพร้อมใช้งานสูง (HA) และการกู้คืนความเสียหาย (DR) ที่แตกต่างกัน: บริการฐานข้อมูลเชิงสัมพันธ์ของ Amazon (RDS) และ Amazon Elastic Compute Cloud (EC2)
RDS
RDS เป็นบริการที่มีการจัดการอย่างสมบูรณ์เหมาะสำหรับการใช้งานที่มีความสำคัญต่อภารกิจ มันมีตัวเลือกของเอ็นจิ้นฐานข้อมูลหกแบบที่แตกต่างกัน แต่การรองรับ SQL Server นั้นไม่แข็งแกร่งเท่าที่ควรสำหรับตัวเลือกอื่น ๆ เช่น Amazon Aurora, My SQL และ MariaDB ต่อไปนี้เป็นข้อกังวลทั่วไปที่ผู้ดูแลระบบมีเกี่ยวกับการใช้ RDS สำหรับแอปพลิเคชัน SQL Server ที่มีความสำคัญต่อภารกิจ:
- สนับสนุนอินสแตนซ์สแตนด์บายแบบมิรเรอร์เดียวเท่านั้น
- งานตัวแทนไม่ได้ถูกมิร์เรอร์ดังนั้นจึงต้องสร้างแยกต่างหากในอินสแตนซ์สแตนด์บาย
- ตรวจไม่พบความล้มเหลวที่เกิดจากซอฟต์แวร์แอปพลิเคชันฐานข้อมูล
- ไม่รองรับอินสแตนซ์ฐานข้อมูลในหน่วยความจำที่ได้รับการเพิ่มประสิทธิภาพ
- ขึ้นอยู่กับการมอบหมายโซนความพร้อมใช้งาน (ซึ่งลูกค้าไม่มีการควบคุม) ประสิทธิภาพอาจได้รับผลกระทบ
- Enterprise Edition ที่มีราคาแพงกว่าของ SQL Server นั้นจำเป็นสำหรับคุณสมบัติการมิเรอร์ข้อมูลที่มีเฉพาะในกลุ่มความพร้อมใช้งานตลอดเวลาเท่านั้น
Elastic Compute Cloud
ตัวเลือกพื้นฐานอื่น ๆ คือ Elastic Compute Cloud ที่มีความสามารถที่มากขึ้น สิ่งนี้ทำให้เป็นตัวเลือกที่ต้องการเมื่อ HA และ DR มีความสำคัญยิ่ง ข้อได้เปรียบที่สำคัญของ EC2 คือการควบคุมที่สมบูรณ์ซึ่งจะให้ผู้ดูแลระบบในการกำหนดค่าและนำเสนอผู้ดูแลระบบด้วยตัวเลือกเพิ่มเติมบางอย่าง
การเลือกระบบปฏิบัติการ
บางทีตัวเลือกที่สำคัญที่สุดคือระบบปฏิบัติการที่ใช้: Windows หรือ Linux Windows Server Failover Clustering เป็นความสามารถที่ทรงพลังพิสูจน์แล้วและเป็นที่นิยมซึ่งมาพร้อมกับมาตรฐานของ Windows แต่ WSFC ต้องการพื้นที่เก็บข้อมูลที่ใช้ร่วมกันและไม่มีอยู่ใน EC2 เนื่องจาก Multi-AZ และ Multi-Region จำเป็นต้องมีการกำหนดค่าสำหรับการป้องกัน HA / DR ที่แข็งแกร่งจึงจำเป็นต้องใช้ซอฟต์แวร์เชิงพาณิชย์หรือกำหนดเองแยกต่างหากเพื่อทำซ้ำข้อมูลในคลัสเตอร์ของอินสแตนซ์ของเซิร์ฟเวอร์ Storage Spaces Direct (S2D) ของ Microsoft ไม่ใช่ตัวเลือกที่นี่เนื่องจากไม่รองรับการกำหนดค่าที่ครอบคลุมโซนความพร้อมใช้งาน ความต้องการบทบัญญัติ HA / DR เพิ่มเติมนั้นยิ่งใหญ่กว่าสำหรับ Linux ซึ่งขาดความสามารถในการทำคลัสเตอร์พื้นฐานเช่น WSFC Linux ให้ผู้ดูแลระบบสองตัวเลือกที่ไม่ดีเท่า ๆ กันสำหรับความพร้อมใช้งานสูง: จ่ายเพิ่มเติมสำหรับ Enterprise Edition ของ SQL Server ที่มีราคาแพงกว่า หรือพยายามทำให้การกำหนดค่า HA Linux ที่ต้องทำด้วยตัวเองที่ซับซ้อนโดยใช้ซอฟต์แวร์โอเพ่นซอร์สทำงานได้ดี
เปรียบเทียบ
ตัวเลือกทั้งสองนี้จะทำลายเหตุผลที่ประหยัดต้นทุนในการใช้ซอฟต์แวร์โอเพ่นซอร์สบนฮาร์ดแวร์สินค้าโภคภัณฑ์ในบริการคลาวด์สาธารณะ SQL Server สำหรับ Linux พร้อมใช้งานสำหรับรุ่นที่ใหม่กว่า (และราคาแพงกว่า) เริ่มต้นในปี 2560 และทางเลือก DIY HA อาจมีราคาแพงสำหรับองค์กรส่วนใหญ่ อันที่จริงแล้วการทำให้ Distributed Replicated Block Device, Corosync, Pacemaker และซอฟต์แวร์โอเพนซอร์ซอื่น ๆ ทำงานได้ตามที่ต้องการในระดับแอปพลิเคชันภายใต้สถานการณ์ความล้มเหลวทั้งหมด นี่คือเหตุผลว่าทำไมองค์กรขนาดใหญ่มากเท่านั้นจึงจำเป็นต้องมี (ชุดทักษะและการจัดบุคลากร) ที่จำเป็นในการพิจารณาดำเนินการ เนื่องจากปัญหาที่เกี่ยวข้องกับการบังคับใช้บทบัญญัติ HA / DR ที่สำคัญต่อภารกิจสำหรับ Linux AWS แนะนำให้ใช้การรวมกันของ Elastic Load Balancing และ Auto Scaling เพื่อปรับปรุงความพร้อมใช้งาน แต่บริการเหล่านี้มีข้อ จำกัด ของตนเองที่คล้ายคลึงกับบริการการจัดการฐานข้อมูลเชิงสัมพันธ์ ทั้งหมดนี้อธิบายว่าทำไมผู้ดูแลระบบจึงเลือกใช้โซลูชันการทำคลัสเตอร์แบบล้มเหลวมากขึ้นซึ่งออกแบบมาโดยเฉพาะเพื่อรับรองการปกป้อง HA และ DR ในสภาพแวดล้อมคลาวด์
Failover Clustering สร้างขึ้นสำหรับคลาวด์
ความนิยมที่เพิ่มขึ้นของคลาวด์ส่วนบุคคลสาธารณะและไฮบริดได้นำไปสู่การถือกำเนิดของโซลูชั่นการจัดกลุ่มความล้มเหลวที่สร้างขึ้นสำหรับสภาพแวดล้อมคลาวด์ โซลูชั่น HA / DR เหล่านี้มีการใช้งานอย่างสมบูรณ์ในซอฟต์แวร์ที่สร้างขึ้นตามชื่อกลุ่มของเซิร์ฟเวอร์และหน่วยเก็บข้อมูลที่มีการเฟลโอเวอร์อัตโนมัติเพื่อรับรองความพร้อมใช้งานสูงในระดับแอปพลิเคชัน โซลูชันเหล่านี้ส่วนใหญ่มีโซลูชัน HA / DR ที่สมบูรณ์ซึ่งรวมการรวมกันของการจำลองข้อมูลบล็อกระดับเรียลไทม์การตรวจสอบแอปพลิเคชันอย่างต่อเนื่องและนโยบายการกู้คืนความล้มเหลว / ล้มเหลวที่กำหนดค่าได้ โซลูชันที่ซับซ้อนยิ่งขึ้นบางตัวยังมีความสามารถขั้นสูงเช่นการสนับสนุน Always on Cluster Instance ใน SQL Server Standard Edition ที่ราคาไม่แพงทั้งสำหรับ Windows และ Linux พวกเขายังมีการเพิ่มประสิทธิภาพ WAN เพื่อเพิ่มประสิทธิภาพการทำงานในหลายภูมิภาค นอกจากนี้ยังมีการสลับการกำหนดเซิร์ฟเวอร์หลักและรองด้วยตนเองเพื่ออำนวยความสะดวกในการบำรุงรักษาตามแผน รวมถึงความสามารถในการสำรองข้อมูลปกติโดยไม่ทำให้แอปพลิเคชันหยุดชะงัก ซอฟต์แวร์การทำคลัสเตอร์การเฟลโอเวอร์ส่วนใหญ่นั้นเป็นแอพพลิเคชั่นที่ไม่เชื่อเรื่องพระเจ้าทำให้องค์กรมีโซลูชัน HA / DR เดียวที่เป็นสากล ความสามารถเดียวกันนี้ยังช่วยป้องกันแอปพลิเคชันเซิร์ฟเวอร์ SQL ทั้งหมด และนั่นรวมถึงฐานข้อมูลการเข้าสู่ระบบงานตัวแทนและอื่น ๆ ทั้งหมดในรูปแบบบูรณาการ แม้ว่าโดยทั่วไปโซลูชันเหล่านี้จะเป็นระบบจัดเก็บข้อมูลที่ไม่เชื่อเรื่องพระเจ้า แต่ช่วยให้สามารถทำงานร่วมกับเครือข่ายพื้นที่เก็บข้อมูลที่ใช้ร่วมกันได้ แต่การแบ่งกลุ่ม SANless failover แบบไม่มีอะไรที่ใช้ร่วมกันมักเป็นที่ต้องการสำหรับความสามารถในการกำจัด การสนับสนุนอินสแตนซ์ Failover Cluster Instances (FCIs) ในรุ่น Standard Edition ที่ถูกกว่าของ SQL Server โดยไม่กระทบกับความพร้อมใช้งานหรือประสิทธิภาพเป็นข้อได้เปรียบที่สำคัญ ในสภาพแวดล้อม Windows ซอฟต์แวร์การทำคลัสเตอร์ล้มเหลวส่วนใหญ่รองรับ FCIs โดยใช้ประโยชน์จากคุณสมบัติ WSFC ในตัว มันทำให้การใช้งานค่อนข้างตรงไปตรงมาสำหรับทั้งผู้ดูแลระบบฐานข้อมูลและ Linux กำลังเป็นที่นิยมมากขึ้นสำหรับ SQL Server และแอปพลิเคชันระดับองค์กรอื่น ๆ โซลูชันการทำคลัสเตอร์ล้มเหลวบางตัวในขณะนี้ทำให้การใช้งาน HA / DR เป็นเรื่องง่ายเหมือนที่ใช้กับ Windows โดยเสนอการรวมเฉพาะแอปพลิเคชัน
โดยทั่วไปสามโหนด SANless Failover Cluster
ตัวอย่างการกำหนดค่า EC2 ในแผนภาพแสดงคลัสเตอร์ล้มเหลวสามโหนด SANless ทั่วไปที่กำหนดค่าเป็น Virtual Private Cloud (VPC) พร้อมอินสแตนซ์ของ SQL Server ทั้งสามในโซนความพร้อมใช้งานที่แตกต่างกัน เพื่อกำจัดโอกาสที่จะเกิดไฟดับในภัยพิบัติในท้องถิ่นที่ส่งผลกระทบต่อทั้งภูมิภาคหนึ่งใน AZs ตั้งอยู่ในภูมิภาค AWS ที่แตกต่างกัน
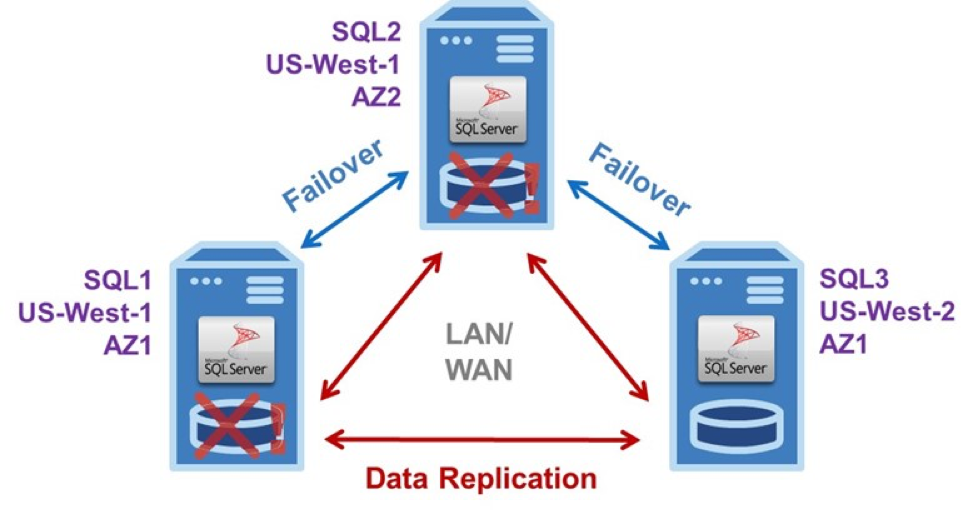
คลัสเตอร์ล้มเหลว SANless สามโหนดนี้ที่มีหนึ่งอินสแตนซ์ของเซิร์ฟเวอร์ที่ใช้งานอยู่และสองอินสแตนซ์สามารถจัดการกับความล้มเหลวที่เกิดขึ้นพร้อมกันสองครั้งด้วยการหยุดทำงานน้อยที่สุดและไม่มีการสูญเสียข้อมูล
คลัสเตอร์ล้มเหลว SANless สามโหนดมีการปกป้อง HA และ DR ระดับผู้ให้บริการ การดำเนินการขั้นพื้นฐานจะเหมือนกันใน LAN และ / หรือ WAN สำหรับ Windows หรือ Linux เซิร์ฟเวอร์ # 1 เป็นอินสแตนซ์หลักหรืออินสแตนซ์ที่ใช้งานอยู่ซึ่งทำซ้ำข้อมูลอย่างต่อเนื่องไปยังเซิร์ฟเวอร์ # 2 และ # 3 มันประสบปัญหา จากนั้นจะทริกเกอร์การ failover อัตโนมัติไปยังเซิร์ฟเวอร์ # 2 ซึ่งตอนนี้กลายเป็นข้อมูลการเรพลิเคทหลักไปยังเซิร์ฟเวอร์ # 3
ตรวจพบความล้มเหลว
หากความล้มเหลวเกิดจากการหยุดทำงานของโครงสร้างพื้นฐานเจ้าหน้าที่ AWS จะเริ่มวินิจฉัยและซ่อมแซมทันทีที่เกิดปัญหา เมื่อแก้ไขแล้วจะสามารถกู้คืนเป็นเซิร์ฟเวอร์หลักหรือเซิร์ฟเวอร์ # 2 สามารถดำเนินการต่อในความสามารถในการจำลองข้อมูลไปยังเซิร์ฟเวอร์ # 1 และ # 3 หากเซิร์ฟเวอร์ # 2 ล้มเหลวก่อนที่เซิร์ฟเวอร์ # 1 จะกลับสู่การดำเนินการดังที่แสดงเซิร์ฟเวอร์ # 3 จะกลายเป็นเซิร์ฟเวอร์หลักหลังจากเกิดความล้มเหลวด้วยตนเอง แน่นอนหากความล้มเหลวเกิดจากแอพพลิเคชั่นซอฟต์แวร์หรือด้านอื่น ๆ ของการกำหนดค่ามันจะขึ้นอยู่กับลูกค้าที่จะค้นหาและแก้ไขปัญหา คลัสเตอร์ล้มเหลว SANless สามารถกำหนดค่าได้ด้วยอินสแตนซ์สแตนด์บายเดียวเท่านั้นแน่นอน แต่การกำหนดค่าขั้นต่ำเช่นนี้ต้องการโหนดที่สามเพื่อใช้เป็นพยาน จำเป็นต้องมีพยานเพื่อให้ครบองค์ประชุมเพื่อพิจารณาการมอบหมายงานหลัก โดยปกติแล้วงานที่สำคัญนี้จะดำเนินการโดยตัวควบคุมโดเมนใน AZ แยกต่างหาก การเก็บทั้งสามโหนด (หลักรองและพยาน) ใน AZ ที่แตกต่างกันช่วยลดความเป็นไปได้ที่จะสูญเสียการโหวตมากกว่าหนึ่งคะแนนหากโซนใดออฟไลน์ นอกจากนี้ยังเป็นไปได้ที่จะมีคลัสเตอร์ล้มเหลว SANless failover สองและสามโหนดในคอนฟิกูเรชันไฮบริดของคลาวด์สำหรับ HA และ / หรือ DR หนึ่งการกำหนดค่าสามโหนดดังกล่าวคือคลัสเตอร์ HA สองโหนดที่อยู่ในศูนย์ข้อมูลขององค์กรพร้อมการจำลองข้อมูลแบบอะซิงโครนัสไปยัง AWS หรือบริการคลาวด์อื่นสำหรับการป้องกัน DR หรือในทางกลับกัน ในกลุ่มภายในภูมิภาคเดียวซึ่งการจำลองข้อมูลเป็นแบบซิงโครนัสความล้มเหลวจะถูกกำหนดค่าให้เกิดขึ้นโดยอัตโนมัติ สำหรับกลุ่มที่มีโหนดที่ขยายหลายภูมิภาคโดยที่การเรพลิเคทข้อมูลแบบอะซิงโครนัสความล้มเหลวมักถูกควบคุมด้วยตนเองเพื่อหลีกเลี่ยงโอกาสในการสูญหายของข้อมูล คลัสเตอร์สามโหนดโดยไม่คำนึงถึงภูมิภาคที่ใช้ยังสามารถอำนวยความสะดวกในการบำรุงรักษาฮาร์ดแวร์และซอฟต์แวร์ตามแผนสำหรับเซิร์ฟเวอร์ทั้งสามในขณะที่ให้การป้องกัน DR อย่างต่อเนื่องสำหรับแอปพลิเคชันและข้อมูล
เพิ่มความพร้อมใช้งานสูงให้สูงสุดสำหรับ SQL Server
ด้วยการนำเสนอความพร้อมใช้งาน 55 โซนที่กระจายอยู่ใน 18 ภูมิภาคทำให้ AWS Global Infrastructure มีโอกาสมหาศาลในการเพิ่มความพร้อมใช้งานสูงให้กับ SQL Server โดยการกำหนดค่าคลัสเตอร์ล้มเหลว SANless ด้วยการสำรองข้อมูลซ้ำซ้อนที่กระจายอยู่ในพื้นที่หลายแห่ง รอยเท้าทั่วโลกนี้ยังช่วยให้แอปพลิเคชันและข้อมูลเซิร์ฟเวอร์ SQL ทั้งหมดอยู่ใกล้กับผู้ใช้ปลายทางเพื่อให้ได้ประสิทธิภาพที่น่าพอใจ ด้วยโซลูชันที่ออกแบบมาเพื่อวัตถุประสงค์ความพร้อมใช้งานระดับสูงของผู้ให้บริการไม่จำเป็นต้องหมายถึงการจ่ายค่าใช้จ่ายสูงเช่นเดียวกับผู้ให้บริการ เนื่องจากซอฟต์แวร์การทำคลัสเตอร์ล้มเหลวที่สร้างขึ้นโดยมีจุดประสงค์ทำให้การใช้ทรัพยากรการคำนวณการจัดเก็บและเครือข่ายของ EC2 มีประสิทธิภาพและประสิทธิผลในขณะที่ติดตั้งและใช้งานง่ายโซลูชันเหล่านี้จะลดต้นทุนและค่าใช้จ่ายในการดำเนินงานทั้งหมด เคย ทำซ้ำจาก TheNewStack