Date: มกราคม 19, 2019
ป้ายกำกับ:หลายเมฆ, เซิร์ฟเวอร์ล้มเหลว, โลกไซเบอร์, ไฟดับเมฆ, ไมโครซอฟท์สีฟ้า

การจัดการการกู้คืนตามเวลาจริงใน Cloud Outage ที่สำคัญ
ภัยพิบัติเกิดขึ้นทำให้ความเป็นจริงหยุดทำงานกะทันหัน แต่มีหลายสิ่งที่ลูกค้าทุกคนสามารถทำได้เพื่อความอยู่รอดของระบบคลาวด์ สิ่งที่เกิดขึ้น ความล้มเหลว – ทั้งเล็กและใหญ่ – หลีกเลี่ยงไม่ได้ สิ่งที่หลีกเลี่ยงไม่ได้คือการขยายเวลาหยุดทำงาน พิจารณาวันที่ภาคกลางของสหรัฐอเมริกาทางใต้ของ Azure cloud ของ Microsoft ประสบความล้มเหลวอย่างรุนแรง พายุฝนฟ้าคะนองรุนแรงนำไปสู่การเรียงลำดับของปัญหาที่ในที่สุดก็ทำให้ศูนย์ข้อมูลทั้งหมดล้มเหลว ในสิ่งที่บางคนเรียกว่า "The Day the Azure Cloud Fell from the Sky" ลูกค้าส่วนใหญ่ออฟไลน์ไม่ใช่เพียงแค่ไม่กี่วินาทีหรือนาที แต่สำหรับทั้งวัน บางคนออฟไลน์นานกว่าสองวัน ในขณะที่ไมโครซอฟท์ได้กล่าวถึงปัญหาต่าง ๆ ที่นำไปสู่การหยุดทำงาน แต่ผู้เชี่ยวชาญด้านไอทีจะจดจำเหตุการณ์นี้ได้นาน นั่นเป็นข่าวร้าย ข่าวดีก็คือ: มีทุกสิ่งที่ลูกค้า Azure ทุกคนสามารถทำได้เพื่อให้สามารถอยู่รอดได้ในทุกสถานการณ์ อาจมาจากเซิร์ฟเวอร์เดียวที่ล้มเหลวไปจนถึงศูนย์ข้อมูลทั้งหมดที่ออฟไลน์ ในความเป็นจริงลูกค้า Azure ที่ใช้ข้อกำหนดด้านความพร้อมใช้งานสูงและ / หรือการกู้คืนความเสียหายที่สมบูรณ์พร้อมด้วยการจำลองข้อมูลตามเวลาจริงและการล้มเหลวอัตโนมัติที่รวดเร็วสามารถคาดหวังว่าจะไม่มีการสูญหายของข้อมูล ดูเพิ่มเติมที่: Nutanix มองเห็นคลาวด์ขององค์กรที่ชนะการแข่งขันคลาวด์
การจัดการ The Cloud Outage
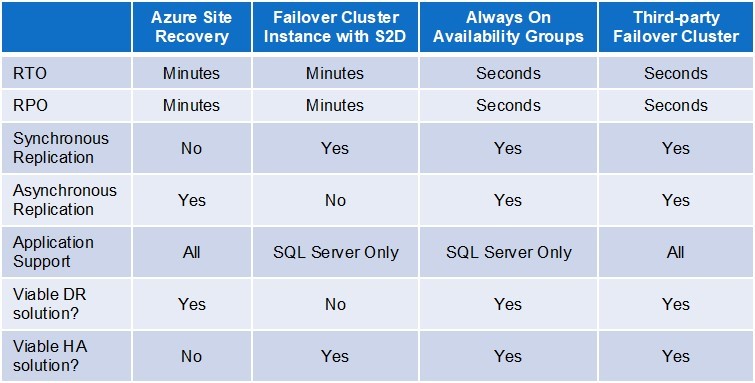
บทความนี้ตรวจสอบสี่ตัวเลือกสำหรับการให้การกู้คืนความเสียหาย (DR) และความพร้อมใช้งานสูง (HA) ในการกำหนดค่าระบบคลาวด์แบบไฮบริดและ Azure ล้วนๆ ตัวเลือกสองตัวเลือกเฉพาะสำหรับฐานข้อมูล Microsoft SQL Server ซึ่งเป็นแอปพลิเคชั่นยอดนิยมในระบบคลาวด์ Azure อีกสองตัวเลือกคือโปรแกรมไม่เชื่อเรื่องพระเจ้า ตัวเลือกสี่ตัวเลือกซึ่งสามารถใช้ในชุดค่าผสมต่าง ๆ เปรียบเทียบในตารางและรวมถึง:
- บริการ Azure Site Recovery (ASR)
- SQL Server Failover Cluster อินสแตนซ์ที่มีพื้นที่เก็บข้อมูลโดยตรง
- SQL Server บนกลุ่มความพร้อมใช้งานเสมอ
- ซอฟต์แวร์การทำคลัสเตอร์ Failover บุคคลที่สาม
RTO และ RPO 101
ก่อนที่จะอธิบายถึงสี่ตัวเลือกจำเป็นต้องมีความเข้าใจพื้นฐานของตัวชี้วัดสองตัวที่ใช้ในการประเมินประสิทธิภาพของบทบัญญัติ DR และ HA: เวลาในการกู้คืนวัตถุประสงค์และวัตถุประสงค์ของจุดกู้คืน ผู้ที่คุ้นเคยกับ RTO และ RPO สามารถข้ามส่วนนี้ได้ RTO เป็นระยะเวลาที่ยอมรับได้สูงสุดของการหยุดทำงาน โดยทั่วไปแอปพลิเคชันการประมวลผลธุรกรรมออนไลน์มี RTO ที่ต่ำที่สุดและแอปพลิเคชันที่สำคัญต่อภารกิจมักมี RTO เพียงไม่กี่วินาที RPO เป็นช่วงเวลาสูงสุดในระหว่างที่สามารถทนต่อการสูญเสียข้อมูล หากไม่มีการสูญเสียข้อมูลที่ยอมรับได้ RPO จะเป็นศูนย์ ปกติแล้ว RTO จะกำหนดประเภทของการป้องกัน HA และ / หรือ DR ที่จำเป็น เวลาในการกู้คืนที่ต่ำมักจะต้องการบทบัญญัติ HA ที่แข็งแกร่งซึ่งป้องกันระบบปกติและความล้มเหลวของซอฟต์แวร์ในขณะที่ RTOs อีกต่อไปสามารถพึงพอใจกับบทบัญญัติ DR พื้นฐานที่ออกแบบมาเพื่อป้องกันการแพร่กระจายที่แพร่หลายมากขึ้น การจำลองข้อมูลที่ใช้กับบทบัญญัติ HA และ DR สามารถสร้างความต้องการการแลกเปลี่ยนที่เป็นไปได้ระหว่าง RTO และ RPO ในสภาพแวดล้อม LAN ที่มีความหน่วงต่ำซึ่งการจำลองข้อมูลสามารถซิงโครไนซ์ชุดข้อมูลหลักและชุดรองสามารถอัปเดตพร้อมกันได้ สิ่งนี้ช่วยให้การกู้คืนเต็มรูปแบบเกิดขึ้นโดยอัตโนมัติและในเวลาจริงทำให้สามารถตอบสนองเวลาการกู้คืนและวัตถุประสงค์ของจุดกู้คืนที่ต้องการได้มากที่สุด (ไม่กี่วินาทีและศูนย์ตามลำดับ) โดยไม่จำเป็นต้องแลกเปลี่ยน ในทางตรงกันข้ามการบังคับให้หลักรอให้รองเพื่อยืนยันความสมบูรณ์ของการอัปเดตสำหรับทุกธุรกรรมจะส่งผลเสียต่อประสิทธิภาพการทำงาน ด้วยเหตุนี้การจำลองข้อมูลใน WAN จึงมักจะไม่ตรงกัน สิ่งนี้สามารถสร้างการแลกเปลี่ยนระหว่างการรองรับ RTO และ RPO ซึ่งโดยปกติแล้วจะส่งผลให้เวลาการกู้คืนเพิ่มขึ้น นี่คือเหตุผล: เพื่อให้เป็นไปตาม RPO ศูนย์ต้องดำเนินการด้วยตนเองเพื่อให้แน่ใจว่าข้อมูลทั้งหมด (เช่นจากบันทึกธุรกรรม) ได้รับการทำซ้ำอย่างสมบูรณ์ในลำดับที่สองก่อนที่จะเกิดความล้มเหลวเกิดขึ้นความพยายามพิเศษนี้ มักใช้สำหรับ DR ไม่ใช่ HA
บริการ Azure Site Recovery (ASR)
ASR เป็นการนำเสนอ DR-as-a-service (DRaaS) ของ Azure ASR จำลองทั้งเครื่องจริงและเสมือนไปยังไซต์ Azure อื่น ๆ ที่อาจเกิดขึ้นในภูมิภาคอื่น ๆ หรือจากอินสแตนซ์ในสถานที่ไปยังคลาวด์ Azure บริการนี้ให้การกู้คืนที่รวดเร็วพอสมควรจากระบบและสถานที่เกิดเหตุขัดข้องและยังอำนวยความสะดวกในการบำรุงรักษาตามแผนโดยไม่ต้องหยุดทำงานในระหว่างการอัพเกรดซอฟต์แวร์ เช่นเดียวกับข้อเสนอ DRaaS ทั้งหมด ASR มีข้อ จำกัด บางประการการที่ร้ายแรงที่สุดคือการไม่สามารถตรวจจับและล้มเหลวจากความล้มเหลวจำนวนมากที่ทำให้แอปพลิเคชันหยุดทำงานโดยอัตโนมัติ แน่นอนนี่คือเหตุผลที่บริการนี้มีลักษณะเป็น DR และไม่ใช่สำหรับ HA ด้วย ASR เวลาในการกู้คืนจะอยู่ที่ประมาณ 3-4 นาทีซึ่งแน่นอนว่าผู้ดูแลระบบสามารถตรวจจับและตอบสนองต่อปัญหาได้อย่างรวดเร็วด้วยตนเองอย่างไร ตามที่อธิบายไว้ข้างต้นความจำเป็นในการจำลองข้อมูลแบบอะซิงโครนัสข้าม WAN สามารถเพิ่มเวลาการกู้คืนสำหรับแอปพลิเคชันที่มี RPO เป็นศูนย์ต่อไป
SQL Server Failover Cluster Instance พร้อมที่เก็บ Spaces โดยตรง
SQL Server มีตัวเลือก HA / DR ของตัวเองสองตัวเลือก: Failover Cluster Instances (ที่กล่าวถึงที่นี่) และ Always On Groups Availability (ที่กล่าวถึงถัดไป) FCIs มีข้อดีสองประการ: คุณสมบัตินี้มีอยู่ใน Standard Edition ที่ราคาถูกกว่าของ SQL Server และไม่ได้ขึ้นอยู่กับการมีพื้นที่เก็บข้อมูลที่ใช้ร่วมกันเหมือนคลัสเตอร์ HA ดั้งเดิม ข้อได้เปรียบหลังนี้มีความสำคัญเนื่องจากพื้นที่เก็บข้อมูลที่ใช้ร่วมกันนั้นไม่มีอยู่ในระบบคลาวด์ – จาก Microsoft หรือผู้ให้บริการคลาวด์อื่น ๆ ทางเลือกที่ได้รับความนิยมสำหรับการจัดเก็บใน Azure cloud คือ Storage Spaces Direct (S2D) ซึ่งรองรับแอพพลิเคชั่นหลากหลายและการสนับสนุนสำหรับ SQL Server จะปกป้องอินสแตนซ์ทั้งหมด ข้อเสียที่สำคัญของ S2D คือเซิร์ฟเวอร์จะต้องอยู่ในดาต้าเซ็นเตอร์เดียวทำให้ตัวเลือกนี้เหมาะสำหรับความต้องการ HA บางอย่าง แต่ไม่ใช่สำหรับ DR สำหรับการปกป้อง HA และ DR แบบหลายไซต์การจำลองข้อมูลที่จำเป็นจะต้องได้รับจากการจัดส่งบันทึกหรือโซลูชันการทำคลัสเตอร์ล้มเหลวของบุคคลที่สาม
SQL Server บนกลุ่มความพร้อมใช้งานเสมอ
ในขณะที่กลุ่มความพร้อมใช้งานตลอดเวลาเป็นข้อเสนอที่มีความสามารถมากที่สุดของ SQL Server สำหรับทั้ง HA และ DR แต่ต้องมีการออกใบอนุญาต Enterprise Edition ที่มีราคาแพงกว่า ตัวเลือกนี้สามารถส่งมอบเวลาการกู้คืน 5-10 วินาทีและจุดการกู้คืนของวินาทีหรือน้อยกว่า นอกจากนี้ยังมีคุณสมบัติที่สองที่สามารถอ่านได้สำหรับการสืบค้นฐานข้อมูล (ด้วยสิทธิ์ใช้งานที่เหมาะสม) และไม่มีข้อ จำกัด เกี่ยวกับขนาดของฐานข้อมูลหรือจำนวนอินสแตนซ์รอง การกำหนดค่ากลุ่มความพร้อมใช้ตลอดเวลาที่ให้การปกป้องทั้ง HA และ DR ประกอบด้วยการจัดเรียงสามโหนดที่มีสองโหนดในชุดความพร้อมใช้งานหรือโซนเดียวและที่สามในภูมิภาค Azure ที่แยกต่างหาก ข้อ จำกัด หนึ่งที่น่าสังเกตคือมีเพียงฐานข้อมูลเท่านั้นที่ถูกจำลองและไม่ใช่อินสแตนซ์ SQL ทั้งหมดซึ่งต้องได้รับการปกป้องด้วยวิธีการอื่น นอกเหนือจากการเป็นฐานข้อมูลที่ต้องห้ามสำหรับแอพพลิเคชั่นฐานข้อมูลบางตัวแล้วแนวทางนี้ก็มีข้อเสียอีกประการหนึ่ง การใช้งานเฉพาะแอพพลิเคชั่นนั้นต้องใช้แผนกไอทีในการบังคับใช้ข้อกำหนด HA และ DR อื่น ๆ สำหรับแอปพลิเคชันอื่นทั้งหมด การใช้โซลูชัน HA / DR หลายตัวสามารถเพิ่มความซับซ้อนและค่าใช้จ่ายได้อย่างมาก (สำหรับการออกใบอนุญาตการฝึกอบรมการติดตั้งและการใช้งานอย่างต่อเนื่อง) จึงเป็นอีกสาเหตุหนึ่งที่ทำให้องค์กรต้องการใช้โซลูชันของบุคคลที่สาม
ซอฟต์แวร์การทำคลัสเตอร์ Failover บุคคลที่สาม
ด้วยการออกแบบแอพพลิเคชั่นที่ไม่เชื่อเรื่องพระเจ้าและแพลตฟอร์มที่ไม่เชื่อเรื่องพระเจ้าซอฟต์แวร์การทำคลัสเตอร์ล้มเหลวสามารถให้บริการโซลูชั่น HA และ DR ที่สมบูรณ์แบบสำหรับการใช้งานแทบทุกประเภทในสภาพแวดล้อมคลาวด์ส่วนตัวสาธารณะและไฮบริด ซึ่งรวมถึงทั้ง Windows และ Linux การเป็นผู้ไม่เชื่อเรื่องการประยุกต์ใช้ทำให้ไม่จำเป็นต้องมีบทบัญญัติ HA / DR ที่แตกต่างกันสำหรับการใช้งานที่แตกต่างกัน การเป็นผู้ไม่เชื่อเรื่องพระเจ้าบนแพลตฟอร์มทำให้สามารถใช้ประโยชน์จากความสามารถและบริการต่าง ๆ ในระบบคลาวด์ Azure รวมถึง Fault Domains, ชุดความพร้อมใช้งานและเขตพื้นที่, คู่ของภูมิภาคและ Azure Site Recovery ในฐานะที่เป็นโซลูชันที่สมบูรณ์ซอฟต์แวร์จะรวมการจำลองข้อมูลอย่างน้อยตามเวลาจริงการตรวจสอบอย่างต่อเนื่องสามารถตรวจจับความล้มเหลวในระดับแอปพลิเคชันและนโยบายที่กำหนดค่าได้สำหรับการเข้าแทนที่และความล้มเหลว โซลูชันส่วนใหญ่ยังมีความสามารถที่เพิ่มมูลค่าหลากหลายที่ช่วยให้คลัสเตอร์ล้มเหลวสามารถส่งมอบการกู้คืนได้ต่ำกว่า 20 วินาทีโดยมีการสูญเสียข้อมูลน้อยที่สุดหรือไม่มีเลยเพื่อตอบสนองความต้องการ HA / DR ทั้งหมด
ทำให้เป็นจริง
ตัวเลือกทั้งสี่ไม่ว่าจะทำงานแยกกันหรืออยู่ในคอนเสิร์ตสามารถมีบทบาทในการปกป้อง DR และ HA อย่างต่อเนื่องมีประสิทธิภาพมากขึ้นและราคาไม่แพงสำหรับแอพพลิเคชั่นขององค์กรอย่างเต็มรูปแบบ ซึ่งรวมถึงผู้ที่สามารถทนต่อการสูญเสียข้อมูลและช่วงเวลาที่หยุดทำงานนานไปจนถึงผู้ที่ต้องการกู้คืนแบบเรียลไทม์เพื่อให้เกิดความพร้อมในการทำงานห้าถึง 9 โดยมีการสูญเสียข้อมูลน้อยที่สุดหรือไม่มีเลย เพื่อความอยู่รอดของระบบคลาวด์ต่อไปในโลกแห่งความเป็นจริงให้ตรวจสอบให้แน่ใจว่าบทบัญญัติ DR และ / หรือ HA ใดที่คุณเลือกได้รับการกำหนดค่าโดยมีโหนดอย่างน้อยสองโหนดกระจายอยู่ทั่วทั้งสองไซต์ นอกจากนี้ต้องแน่ใจว่าเข้าใจว่าบทบัญญัตินั้นสอดคล้องกับเวลาในการกู้คืนและวัตถุประสงค์ของจุดกู้คืนของแต่ละแอปพลิเคชันอย่างไร รวมถึงข้อ จำกัด ใด ๆ ที่อาจมีอยู่รวมถึงความต้องการกระบวนการที่ต้องดำเนินการด้วยตนเองที่จำเป็นในการตรวจสอบความล้มเหลวที่เป็นไปได้ทั้งหมดและทำให้เกิดความล้มเหลวในรูปแบบที่รับประกันความต่อเนื่องของทั้งแอปพลิเคชัน
เกี่ยวกับ Jonathan Meltzer
Jonathan Meltzer เป็นผู้อำนวยการฝ่ายจัดการผลิตภัณฑ์ของ SIOS Technology เขามีประสบการณ์กว่า 20 ปีในการจัดการผลิตภัณฑ์และการตลาดสำหรับซอฟต์แวร์และผลิตภัณฑ์ SaaS ที่ช่วยให้ลูกค้าสามารถจัดการเปลี่ยนแปลงและเพิ่มประสิทธิภาพทุนมนุษย์และทรัพยากรไอทีของพวกเขา ทำซ้ำจาก RTinsights