Date: สิงหาคม 19, 2018
ป้ายกำกับ: , Failover Clusters, ผู้จัดการทรัพยากร Azure

การปรับใช้คลัสเตอร์ล้มเหลวของ Microsoft SQL Server 2014 ในตัวจัดการทรัพยากร Azure
ในโพสต์นี้เราจะอธิบายรายละเอียดขั้นตอนเฉพาะที่จำเป็นสำหรับการปรับใช้ SQL Server Failover Clusters ใน Azure Resource Manager ฉันจะสมมติว่าคุณคุ้นเคยกับแนวคิดพื้นฐานของ Azure และแนวคิดพื้นฐานของ SQL Server Failover Cluster การปรับใช้ SQL Server Failover Cluster 2 โหนดในพื้นที่เดียวของ Azure โดยใช้ Azure Resource Manager ไม่ใช่วิทยาศาสตร์จรวด สิ่งที่ฉันจะเน้นในบทความนี้คือความเป็นเอกลักษณ์เกี่ยวกับการปรับใช้ SQL Server Failover Cluster ใน Azure Resource Manager ถ้าคุณยังคงใช้ Azure Classic และต้องการปรับใช้ SQL Server Failover Cluster ใน Classic โปรดอ่านบทความ "STEP-BY-STEP: HOW TO CONFIGURE SQL SERVER FAILOVER CLUSTER INSTANCE (FCI) ใน MICROSOFT AZURE IAAS #SQLSERVER #AZURE # SANLESS "ก่อนที่เราจะเริ่มต้นให้ทำความคุ้นเคยกับบทความ Windows Azure ความพร้อมใช้งานสูงและการกู้คืนระบบสำหรับ SQL Server ใน Azure Virtual Machines ในบทความนี้จะมีการระบุตัวเลือกทั้งหมดของ HA ไว้ รวมถึง AlwaysOn AG, Mirroring ของฐานข้อมูล, Log Shipping, Backup and Restore และ Failover Cluster Instances ในที่สุด สมมติว่าคุณได้ยกเลิกตัวเลือกอื่น ๆ เนื่องจากค่าใช้จ่ายที่เกี่ยวข้องกับ Enterprise Edition ของ SQL Server หรือไม่มีคุณลักษณะเราจะมุ่งเน้นไปที่ตัวเลือกสุดท้าย – SQLA Server AlwaysOn Failover Cluster Instance (FCI) เมื่อคุณอ่านบทความนั้นจะเห็นได้ชัดว่าการขาดการจัดเก็บข้อมูลที่แชร์ใน Azure เป็นอุปสรรคในการปรับใช้ SQL Server Failover Clusters อย่างไรก็ตามมีบางทางเลือกที่อธิบายไว้ในบทความนั้น เราจะเน้นการใช้ SIOS DataKeeper เพื่อจัดเตรียมพื้นที่เก็บข้อมูลที่จะใช้ในคลัสเตอร์ รูปที่ 1 นโยบายการสนับสนุนของ Microsoft สำหรับ  SQL Server Failover Clusters https://azure.microsoft.com/en-us/documentation/articles/virtual-machines- ด้วย DataKeeper Cluster Edition คุณสามารถจัดเก็บข้อมูลที่แนบมาภายในไม่ว่าจะเป็น Premium หรือ Standard Disks และทำซ้ำดิสก์เหล่านี้ทั้งแบบ synchronously, asynchronous หรือ mixed หรือทั้งสองอย่างระหว่างสอง หรือมากกว่าโหนดคลัสเตอร์ นอกจากนี้รีซอร์ส DataKeeper Volume ถูกลงทะเบียนใน Windows Server Failover Clustering ซึ่งใช้แทน Physical Disk resource แทนที่จะควบคุมการจอง SCSI-3 เช่น Physical Disk Resource ปริมาณไดรฟ์ DataKeeper จะควบคุมทิศทางของกระจกเพื่อให้แน่ใจว่าโหนดที่ใช้งานอยู่เสมอคือแหล่งที่มาของกระจก SQL Server และ Failover Clustering เกี่ยวข้องกับ SQL Server และ Failover Clustering จะมีลักษณะรู้สึกและมีกลิ่นเหมือน Physical Disk และใช้งานได้เช่นเดียวกับ Physical Disk Resource
SQL Server Failover Clusters https://azure.microsoft.com/en-us/documentation/articles/virtual-machines- ด้วย DataKeeper Cluster Edition คุณสามารถจัดเก็บข้อมูลที่แนบมาภายในไม่ว่าจะเป็น Premium หรือ Standard Disks และทำซ้ำดิสก์เหล่านี้ทั้งแบบ synchronously, asynchronous หรือ mixed หรือทั้งสองอย่างระหว่างสอง หรือมากกว่าโหนดคลัสเตอร์ นอกจากนี้รีซอร์ส DataKeeper Volume ถูกลงทะเบียนใน Windows Server Failover Clustering ซึ่งใช้แทน Physical Disk resource แทนที่จะควบคุมการจอง SCSI-3 เช่น Physical Disk Resource ปริมาณไดรฟ์ DataKeeper จะควบคุมทิศทางของกระจกเพื่อให้แน่ใจว่าโหนดที่ใช้งานอยู่เสมอคือแหล่งที่มาของกระจก SQL Server และ Failover Clustering เกี่ยวข้องกับ SQL Server และ Failover Clustering จะมีลักษณะรู้สึกและมีกลิ่นเหมือน Physical Disk และใช้งานได้เช่นเดียวกับ Physical Disk Resource
Pre-Requisites เพื่อใช้งาน SQL Server Failover Clusters ใน Azure Resource Manager
- คุณเคยใช้ Azure Portal มาก่อนและสามารถปรับใช้เครื่องเสมือนได้อย่างสะดวกใน Azure IaaS
- ได้รับใบอนุญาตหรือ eval ของ SIOS DataKeeper แล้ว
- คุ้นเคยกับ SQL Server AlwaysOn Failover Cluster Instance ถ้าไม่โปรดอ่านเอกสารที่ https://msdn.microsoft.com/en-us/library/ms189134.aspx
วิธีง่ายๆในการทำ Proof-Of-Concept
ถ้าคุณคุ้นเคยกับ Azure Resource Manager คุณทราบว่าหนึ่งในคุณสมบัติใหม่ที่ยอดเยี่ยมคือความสามารถในการใช้เทมเพลตการปรับใช้เพื่อปรับใช้แอ็พพลิเคชันที่ประกอบด้วยทรัพยากร Azure ที่เชื่อมโยงกันอย่างรวดเร็ว แม่แบบเหล่านี้จำนวนมากได้รับการพัฒนาโดย Microsoft และพร้อมใช้งานในชุมชนของ Github ในชื่อ "Quickstart Templates" สมาชิกชุมชนสามารถขยายเทมเพลตหรือเผยแพร่แม่แบบของตนเองได้ที่ GitHub หนึ่งแม่แบบดังกล่าวมีชื่อว่า "อินสแตนซ์คลัสเตอร์ชั่วคราวของ SQL Server 2014 AlwaysOn ด้วยเทมเพลตการปรับใช้ SIOS DataKeeper Azure" ที่เผยแพร่โดย SIOS Technology ทำให้กระบวนการปรับใช้ SQL Server 2-Server FCI ในโดเมน Active Directory ใหม่เสร็จสมบูรณ์โดยอัตโนมัติ ในการปรับใช้เทมเพลตนี้จะทำได้ง่ายเพียงคลิกที่ปุ่ม "Deploy to Azure" ในเทมเพลต รูปที่ 2 – ไปที่ https://github.com/SIOSDat![]() aKeeper/SIOSDataKeeper-SQL-Cluster เพื่อจัดเตรียมชุด SQL SQL แบบ 2 โหนดอย่างรวดเร็ว [/ caption]
aKeeper/SIOSDataKeeper-SQL-Cluster เพื่อจัดเตรียมชุด SQL SQL แบบ 2 โหนดอย่างรวดเร็ว [/ caption]
การปรับใช้ SQL Server Failover Cluster Instance โดยใช้ Azure Portal
แม้ว่าเทมเพลตการปรับใช้ Azure โดยอัตโนมัติเป็นวิธีที่ง่ายและรวดเร็วในการรับเซิร์ฟเวอร์ SQL Server 2 โหนดและทำงานได้อย่างรวดเร็วมีข้อ จำกัด บางประการ สำหรับหนึ่งจะใช้รุ่นการประเมินผล 180 วันของ SQL Server ดังนั้นคุณจึงไม่สามารถใช้ในการผลิตจนกว่าคุณจะอัพเกรดใบอนุญาต SQL eval นอกจากนี้ยังสร้างโดเมน AD ใหม่ทั้งหมดดังนั้นหากคุณต้องการผสานรวมกับโดเมนที่มีอยู่ของคุณคุณจะต้องสร้างด้วยตนเอง ในการสร้าง SQL Server Failover Cluster Instance 2 โหนดใน Azure เราจะสมมติว่าคุณมี Virtual Network พื้นฐานจาก Azure Resource Manager (ไม่ใช่ Azure Classic) และคุณมีเครื่องเสมือนอย่างน้อยหนึ่งเครื่องทำงานและกำหนดค่าเป็น a Domain Controller เมื่อคุณมีเครือข่ายเสมือนจริงและโดเมนที่กำหนดค่าคุณจะจัดหาอุปกรณ์เสมือนใหม่สองเครื่องซึ่งจะทำหน้าที่เป็นโหนดสองโหนดในกลุ่มของเรา สภาพแวดล้อมของเราจะมีลักษณะดังนี้: DC1 – Domain Controller และ File Share Witness SQL1 และ SQL2 – โหนดทั้งสองของคลัสเตอร์ SQL Server ของเรา
การจัดเตรียมโหนดคลัสเตอร์ (SQL1 และ SQL2)
การใช้ Azure Portal เราจะจัดเตรียมทั้ง SQL1 และ SQL2 ในลักษณะเดียวกัน มีตัวเลือกมากมายให้เลือก ได้แก่ ขนาดตัวอย่างตัวเลือกการจัดเก็บเป็นต้น คู่มือนี้ไม่ได้หมายถึงการเป็นแนวทางที่ละเอียดถี่ถ้วนในการปรับใช้ SQL Server ใน Azure เนื่องจากมีแหล่งข้อมูลที่ดีจริงๆและมีการเผยแพร่ข้อมูลทุกวัน อย่างไรก็ตามคุณควรคำนึงถึงสิ่งสำคัญบางอย่างเมื่อสร้างอินสแตนซ์โดยเฉพาะอย่างยิ่งในสภาวะแวดล้อมแบบคลัสเตอร์ ชุดความพร้อมใช้งาน – เป็นสิ่งสำคัญที่ทั้ง SQL1, SQL2 และ DC1 อยู่ในชุดการพร้อมใช้งานเดียวกัน โดยวางไว้ในชุดการตั้งค่าความพร้อมกันเราจะตรวจสอบว่าแต่ละโหนดคลัสเตอร์และพยานแชร์ไฟล์อาศัยอยู่ในโดเมนฟอรัมและโดเมนการอัปเดตที่แตกต่างกัน ช่วยให้มั่นใจได้ว่าในระหว่างการบำรุงรักษาตามแผนและการบำรุงรักษาที่ไม่ได้วางแผนคลัสเตอร์จะยังคงสามารถรักษาองค์ประชุมและหลีกเลี่ยงการหยุดทำงาน รูปที่ 3 – ตรวจสอบให้แน่ใจว่าได้เพิ่มโหนดค ลัสเตอร์ทั้งสองและพยานในการแชร์ไฟล์ไปยังชุดข้อมูลการจองที่เหมือนกัน [/ caption]
ลัสเตอร์ทั้งสองและพยานในการแชร์ไฟล์ไปยังชุดข้อมูลการจองที่เหมือนกัน [/ caption]
ที่อยู่ IP แบบคงที่
เมื่อ VM แต่ละตัวถูกจัดเตรียมไว้คุณจะต้องไปที่การตั้งค่าและเปลี่ยนการตั้งค่าเพื่อให้ที่อยู่ IP เป็นแบบคงที่ เราไม่ต้องการให้ที่อยู่ IP ของโหนดคลัสเตอร์ของเรามีการเปลี่ยนแปลง รูปที่ 4 – ตรวจสอบให้แน่ใจว่าแต่ละโ หนดคลัสเตอร์ใช้ IP แบบคงที่ [/ caption]
หนดคลัสเตอร์ใช้ IP แบบคงที่ [/ caption]
การเก็บรักษา
คุณจำเป็นต้องปรึกษาแนวทางปฏิบัติที่ดีที่สุดสำหรับ SQL Server ใน Azure Virtual Machines ไม่ว่าในกรณีใดคุณจะต้องเพิ่มดิสก์อย่างน้อยหนึ่งรายการให้กับแต่ละโหนดคลัสเตอร์ของคุณ DataKeeper สามารถใช้ Basic Disk, Premium Storage หรือแม้แต่ Storage Pools ซึ่งประกอบด้วยดิสก์หลายตัวในพูลเก็บข้อมูล เพียงแค่ต้องแน่ใจว่าได้เพิ่มพื้นที่เก็บข้อมูลเท่ากันไปยังแต่ละโหนดคลัสเตอร์และกำหนดค่าให้เหมือนกัน รูปที ่ 5 – ตรวจสอบให้แน่ใจว่าได้เพิ่มพื้นที่เก็บข้อมูลเพิ่มเติมสำหรับแต่ละโหนดคลัสเตอร์ [/ caption]
่ 5 – ตรวจสอบให้แน่ใจว่าได้เพิ่มพื้นที่เก็บข้อมูลเพิ่มเติมสำหรับแต่ละโหนดคลัสเตอร์ [/ caption]
สร้างคลัสเตอร์
สมมติว่าทั้งโหนดคลัสเตอร์ (SQL1 และ SQL2) ได้รับการจัดเตรียมตามที่อธิบายไว้ข้างต้นและเพิ่มลงในโดเมนที่มีอยู่แล้วของคุณเราพร้อมที่จะสร้างคลัสเตอร์แล้ว ก่อนที่เราจะสร้างคลัสเตอร์มีคุณลักษณะบางอย่างที่จำเป็นต้องเปิดใช้งาน คุณลักษณะเหล่านี้คือ .Net Framework 3.5 และ Failover Clustering คุณลักษณะเหล่านี้จำเป็นต้องเปิดใช้งานทั้งโหนดคลัสเตอร์ รูปที่ 6 – เปิดใช้งานทั้ง. Net Framework 3.5 แ ละ Failover Clustering ในคลัสเตอร์ทั้งสองโหนด [/ caption] เมื่อคุณสมบัติเหล่านี้ได้รับการเปิดใช้งานแล้วคุณก็พร้อมที่จะใช้งาน สร้างกลุ่มของคุณ ขั้นตอนส่วนใหญ่ที่ฉันกำลังจะแสดงให้คุณสามารถทำได้ทั้งผ่านทาง PowerShell และ GUI อย่างไรก็ตามผมจะแนะนำว่าสำหรับขั้นตอนแรกนี้คุณใช้ PowerShell เพื่อสร้างคลัสเตอร์ของคุณ ถ้าคุณเลือกที่จะใช้ Failover Cluster Manager GUI เพื่อสร้างคลัสเตอร์คุณจะพบว่าคุณได้รับการแก้ไขด้วยคลัสเตอร์ที่กำลังออกที่อยู่ IP ซ้ำ โดยไม่ต้องไปรายละเอียดมากสิ่งที่คุณจะพบคือ Azure VMs ต้องใช้ DHCP การระบุ "IP แบบสโตร" เมื่อเราสร้าง VM ในพอร์ทัล Azure ทั้งหมดที่เราทำคือสร้างการจัดเรียงแบบ DHCP ไม่เหมือนกับการจอง DHCP เนื่องจากการจอง DHCP จริงจะนำที่อยู่ IP ออกจากพูล DHCP แทนที่จะระบุ IP แบบคงที่ในพอร์ทัล Azure ก็หมายความว่าถ้าที่อยู่ IP นี้ยังคงพร้อมใช้งานเมื่อ VM ร้องขอให้ Azure จะออก IP ดังกล่าว อย่างไรก็ตามถ้า VM ของคุณออฟไลน์และโฮสต์อื่นมาออนไลน์ในเครือข่ายย่อยเดียวกันนั้นเป็นอย่างดีอาจจะออกที่อยู่ IP เดียวกัน มีผลข้างเคียงแปลก ๆ กับ Azure ที่มีการใช้ DHCP เมื่อสร้างคลัสเตอร์ด้วย Windows Server Failover Cluster GUI เมื่อโฮสต์ใช้ DHCP (ซึ่งจำเป็นต้องมี) ไม่มีตัวเลือกในการระบุที่อยู่ IP ของคลัสเตอร์ แทนที่จะต้องอาศัย DHCP เพื่อขอรับที่อยู่ สิ่งแปลกคือ DHCP จะออกที่อยู่ IP ซ้ำกันโดยปกติจะเป็นที่อยู่ IP เดียวกันกับโฮสต์ที่ขอที่อยู่ IP ใหม่ คลัสเตอร์มักจะสมบูรณ์ แต่คุณอาจมีข้อผิดพลาดที่แปลก ๆ และอาจจำเป็นต้องเรียกใช้ Windows Server Failover Cluster GUI จากโหนดอื่นเพื่อให้ทำงานได้ เมื่อคุณได้รับมันทำงานคุณจะต้องการเปลี่ยนที่อยู่ IP คลัสเตอร์ไปยังที่อยู่ที่ไม่ได้ใช้งานในเครือข่าย คุณสามารถหลีกเลี่ยงปัญหาทั้งหมดได้ด้วยการสร้างคลัสเตอร์ผ่าน Powershell และระบุที่อยู่ IP ของคลัสเตอร์เป็นส่วนหนึ่งของคำสั่ง PowerShell เพื่อสร้างคลัสเตอร์ คุณสามารถสร้างคลัสเตอร์โดยใช้คำสั่ง New-Cluster ดังนี้:
ละ Failover Clustering ในคลัสเตอร์ทั้งสองโหนด [/ caption] เมื่อคุณสมบัติเหล่านี้ได้รับการเปิดใช้งานแล้วคุณก็พร้อมที่จะใช้งาน สร้างกลุ่มของคุณ ขั้นตอนส่วนใหญ่ที่ฉันกำลังจะแสดงให้คุณสามารถทำได้ทั้งผ่านทาง PowerShell และ GUI อย่างไรก็ตามผมจะแนะนำว่าสำหรับขั้นตอนแรกนี้คุณใช้ PowerShell เพื่อสร้างคลัสเตอร์ของคุณ ถ้าคุณเลือกที่จะใช้ Failover Cluster Manager GUI เพื่อสร้างคลัสเตอร์คุณจะพบว่าคุณได้รับการแก้ไขด้วยคลัสเตอร์ที่กำลังออกที่อยู่ IP ซ้ำ โดยไม่ต้องไปรายละเอียดมากสิ่งที่คุณจะพบคือ Azure VMs ต้องใช้ DHCP การระบุ "IP แบบสโตร" เมื่อเราสร้าง VM ในพอร์ทัล Azure ทั้งหมดที่เราทำคือสร้างการจัดเรียงแบบ DHCP ไม่เหมือนกับการจอง DHCP เนื่องจากการจอง DHCP จริงจะนำที่อยู่ IP ออกจากพูล DHCP แทนที่จะระบุ IP แบบคงที่ในพอร์ทัล Azure ก็หมายความว่าถ้าที่อยู่ IP นี้ยังคงพร้อมใช้งานเมื่อ VM ร้องขอให้ Azure จะออก IP ดังกล่าว อย่างไรก็ตามถ้า VM ของคุณออฟไลน์และโฮสต์อื่นมาออนไลน์ในเครือข่ายย่อยเดียวกันนั้นเป็นอย่างดีอาจจะออกที่อยู่ IP เดียวกัน มีผลข้างเคียงแปลก ๆ กับ Azure ที่มีการใช้ DHCP เมื่อสร้างคลัสเตอร์ด้วย Windows Server Failover Cluster GUI เมื่อโฮสต์ใช้ DHCP (ซึ่งจำเป็นต้องมี) ไม่มีตัวเลือกในการระบุที่อยู่ IP ของคลัสเตอร์ แทนที่จะต้องอาศัย DHCP เพื่อขอรับที่อยู่ สิ่งแปลกคือ DHCP จะออกที่อยู่ IP ซ้ำกันโดยปกติจะเป็นที่อยู่ IP เดียวกันกับโฮสต์ที่ขอที่อยู่ IP ใหม่ คลัสเตอร์มักจะสมบูรณ์ แต่คุณอาจมีข้อผิดพลาดที่แปลก ๆ และอาจจำเป็นต้องเรียกใช้ Windows Server Failover Cluster GUI จากโหนดอื่นเพื่อให้ทำงานได้ เมื่อคุณได้รับมันทำงานคุณจะต้องการเปลี่ยนที่อยู่ IP คลัสเตอร์ไปยังที่อยู่ที่ไม่ได้ใช้งานในเครือข่าย คุณสามารถหลีกเลี่ยงปัญหาทั้งหมดได้ด้วยการสร้างคลัสเตอร์ผ่าน Powershell และระบุที่อยู่ IP ของคลัสเตอร์เป็นส่วนหนึ่งของคำสั่ง PowerShell เพื่อสร้างคลัสเตอร์ คุณสามารถสร้างคลัสเตอร์โดยใช้คำสั่ง New-Cluster ดังนี้:
คลัสเตอร์ใหม่ -Name cluster1 -Node sql1, sql2 -StaticAddress 10.0.0.101 -NoStorage
หลังจากการสร้างคลัสเตอร์เสร็จสมบูรณ์แล้วคุณจะต้องเรียกใช้การตรวจสอบคลัสเตอร์ด้วยการเรียกใช้คำสั่งต่อไปนี้:
ทดสอบคลัสเตอร์
[image caption = "attachment_1736" align = "alignnone" wi dth = "660"] รูปที่ 7 – ผลลัพธ์ของการสร้างคลัสเตอร์และคำสั่งตรวจสอบคลัสเตอร์ [/ caption]
dth = "660"] รูปที่ 7 – ผลลัพธ์ของการสร้างคลัสเตอร์และคำสั่งตรวจสอบคลัสเตอร์ [/ caption]
สร้างพยานร่วมแบ่งปันไฟล์
เนื่องจากไม่มีที่จัดเก็บข้อมูลที่ใช้ร่วมกันคุณจะต้องสร้างพยานแชร์ไฟล์บนเซิร์ฟเวอร์อื่นในชุดการตั้งค่าความพร้อมกันเหมือนโหนดคลัสเตอร์สองโหนด เมื่อวางไว้ในชุดการพร้อมใช้งานเดียวกันคุณสามารถมั่นใจได้ว่าคุณจะเสียคะแนนเพียงอย่างเดียวจากโควรัมของคุณในเวลาใดก็ตาม หากคุณไม่แน่ใจว่าจะสร้างพยานแชร์ไฟล์คุณสามารถอ่านบทความนี้ได้ที่ http://www.howtonetworking.com/server/cluster12.htm ในการสาธิตของฉันฉันใส่พยานแชร์ไฟล์บนตัวควบคุมโดเมน ฉันได้เผยแพร่คำอธิบายเกี่ยวกับ quorum แบบคลัสเตอร์ที่ครบถ้วนแล้วที่ https://blogs.msdn.microsoft.com/microsoft_press/2014/04/28/from-the-mvps-understanding-the-windows-server-failover-cluster-quorum- ในหน้าต่างเซิร์ฟเวอร์ 2012 R2 / ใน
ติดตั้ง DataKeeper
หลังจากสร้างคลัสเตอร์แล้วก็ถึงเวลาที่ต้องติดตั้ง DataKeeper สิ่งสำคัญคือต้องติดตั้ง DataKeeper หลังจากคลัสเตอร์เริ่มต้นถูกสร้างขึ้นเพื่อให้สามารถลงทะเบียนรีซอร์สคลัสเตอร์แบบกำหนดเองกับคลัสเตอร์ได้ ถ้าคุณติดตั้ง DataKeeper ก่อนสร้างคลัสเตอร์คุณจะต้องติดตั้งอีกครั้งและทำการติดตั้งซ่อมแซม รูปที่ 8 – ติดตั้ง DataKeeper หลังจา กสร้างคลัสเตอร์ [/ caption] ระหว่างการติดตั้งคุณสามารถใช้ตัวเลือกเริ่มต้นทั้งหมดได้ บัญชีบริการที่คุณใช้ต้องเป็นบัญชีโดเมนและอยู่ในกลุ่มผู้ดูแลระบบภายในของแต่ละโหนดในคลัสเตอร์ รูปที่ 9 – บัญชีบริการต้องเป็นบัญชีโดเมนที
กสร้างคลัสเตอร์ [/ caption] ระหว่างการติดตั้งคุณสามารถใช้ตัวเลือกเริ่มต้นทั้งหมดได้ บัญชีบริการที่คุณใช้ต้องเป็นบัญชีโดเมนและอยู่ในกลุ่มผู้ดูแลระบบภายในของแต่ละโหนดในคลัสเตอร์ รูปที่ 9 – บัญชีบริการต้องเป็นบัญชีโดเมนที ่อยู่ในกลุ่ม Local Admins ในแต่ละโหนด [/ caption] เมื่อ DataKeeper ได้รับการติดตั้งและได้รับสิทธิการใช้งานแล้ว แต่ละโหนดคุณจะต้องรีบูตเซิร์ฟเวอร์
่อยู่ในกลุ่ม Local Admins ในแต่ละโหนด [/ caption] เมื่อ DataKeeper ได้รับการติดตั้งและได้รับสิทธิการใช้งานแล้ว แต่ละโหนดคุณจะต้องรีบูตเซิร์ฟเวอร์
สร้างไดรฟ์ข้อมูล DataKeeper ทรัพยากร
ในการสร้าง DataKeeper Volume Resource คุณจะต้องเริ่มต้น DataKeeper UI และเชื่อมต่อกับทั้งสองเซิร์ฟเวอร์  เชื่อมต่อกับ SQL
เชื่อมต่อกับ SQL 1 เชื่อมต่อกับ SQ
1 เชื่อมต่อกับ SQ L2 เมื่อคุณเชื่อมต่อกับเซิร์ฟเวอร์แต่ละเครื่องคุณพร้อมที่จะสร้าง DataKeeper Volume แล้ว คลิกขวาที่งานและเลือก "สร้างง
L2 เมื่อคุณเชื่อมต่อกับเซิร์ฟเวอร์แต่ละเครื่องคุณพร้อมที่จะสร้าง DataKeeper Volume แล้ว คลิกขวาที่งานและเลือก "สร้างง าน" ให้ชื่องานและคำอธิบาย
าน" ให้ชื่องานและคำอธิบาย  เลือกเซิร์ฟเวอร์ต้นทาง IP และไดรฟ์ข้อมูล ที่อยู่ IP คือการรับส่งข้อมูลการจำลองแบบจะเดินทางหรือไม่
เลือกเซิร์ฟเวอร์ต้นทาง IP และไดรฟ์ข้อมูล ที่อยู่ IP คือการรับส่งข้อมูลการจำลองแบบจะเดินทางหรือไม่  เลือกเซิร์ฟเวอร์เป้าหมายของคุณ
เลือกเซิร์ฟเวอร์เป้าหมายของคุณ  เลือกตัวเลือกของคุณ สำหรับจุดประสงค์ของเราที่ VM ทั้งสองอยู่ในพื้นที่ทางภูมิศาสตร์เดียวกันเราจะเลือกการจำลองแบบซิงโครนัส สำหรับการจำลองแบบระยะไกลคุณจะต้องการใช้แบบอะซิงโครนัสและเปิดใช้งานการบีบอัดบางอย่าง
เลือกตัวเลือกของคุณ สำหรับจุดประสงค์ของเราที่ VM ทั้งสองอยู่ในพื้นที่ทางภูมิศาสตร์เดียวกันเราจะเลือกการจำลองแบบซิงโครนัส สำหรับการจำลองแบบระยะไกลคุณจะต้องการใช้แบบอะซิงโครนัสและเปิดใช้งานการบีบอัดบางอย่าง  เมื่อคลิกใช่ที่ป๊อปอัปล่าสุดคุณจะลงทะเบียนแหล่งข้อมูลไดรฟ์ DataKeeper ใหม่ในที่จัดเก็บที่พร้อมใช้งานใน Failover Clustering
เมื่อคลิกใช่ที่ป๊อปอัปล่าสุดคุณจะลงทะเบียนแหล่งข้อมูลไดรฟ์ DataKeeper ใหม่ในที่จัดเก็บที่พร้อมใช้งานใน Failover Clustering 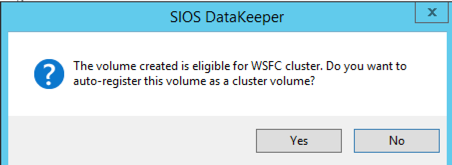 คุณจะเห็นแหล่งข้อมูล Volume DataKeeper ใหม่ใน Storage ที่มีอยู่
คุณจะเห็นแหล่งข้อมูล Volume DataKeeper ใหม่ใน Storage ที่มีอยู่ 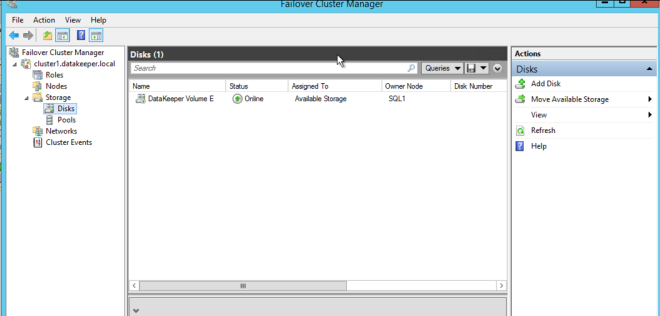
ติดตั้งโหนดคลัสเตอร์แรก
ตอนนี้คุณพร้อมที่จะติดตั้งโหนดแรกแล้ว การติดตั้งคลัสเตอร์จะดำเนินการเหมือนกับกลุ่ม SQL อื่น ๆ ที่คุณสร้างขึ้น ฉันยังไม่ได้คัดลอกภาพหน้าจอทุกภาพเพียงเล็กน้อยเพื่อแนะนำคุณตลอดทาง 

 คุณเห็นว่า DataKeeper Volume Resource ได้รับการยอมรับว่าเป็นรีซอร์สดิสก์ที่ใช้ได้เช่นเดียวกับที่เป็นดิสก์ที่ใช้ร่วมกัน
คุณเห็นว่า DataKeeper Volume Resource ได้รับการยอมรับว่าเป็นรีซอร์สดิสก์ที่ใช้ได้เช่นเดียวกับที่เป็นดิสก์ที่ใช้ร่วมกัน 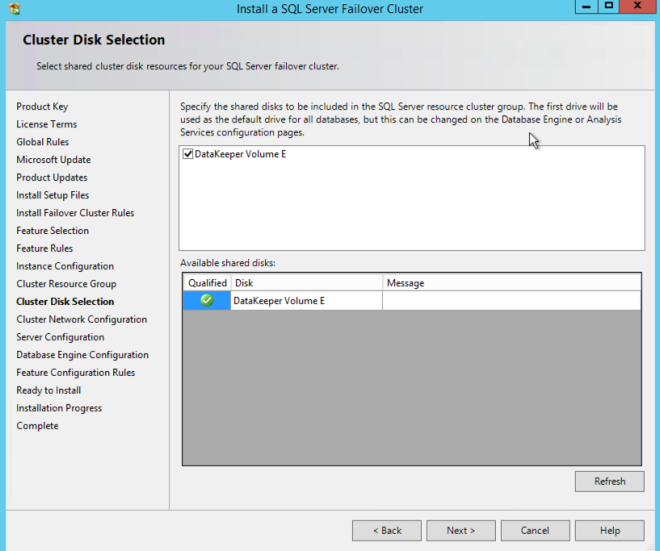 จดบันทึกที่อยู่ IP ที่คุณเลือกไว้ที่นี่ ต้องเป็นที่อยู่ IP เฉพาะในเครือข่ายของคุณ เราจะใช้ที่อยู่ IP เดียวกันนี้ในภายหลังเมื่อเราสร้าง Balancer โหลดภายในของเรา
จดบันทึกที่อยู่ IP ที่คุณเลือกไว้ที่นี่ ต้องเป็นที่อยู่ IP เฉพาะในเครือข่ายของคุณ เราจะใช้ที่อยู่ IP เดียวกันนี้ในภายหลังเมื่อเราสร้าง Balancer โหลดภายในของเรา 
เพิ่มโหนดที่สอง
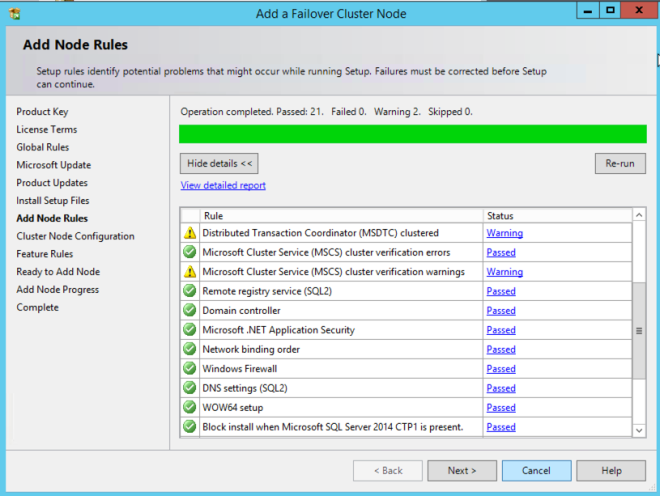
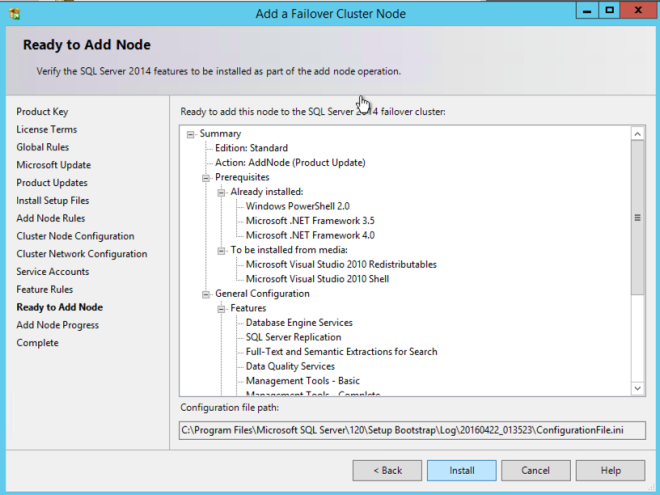
หลังจากที่โหนดแรกติดตั้งเสร็จเรียบร้อยแล้วคุณจะเริ่มการติดตั้งบนโหนดที่สองโดยใช้ตัวเลือก "เพิ่มโหนดไปยังคลัสเตอร์ failover ของ SQL Server" อีกครั้งติดตั้งจะสวยตรงไปข้างหน้าเพียงใช้แนวทางปฏิบัติที่ได้มาตรฐานที่ดีที่สุดเท่าที่คุณจะติดตั้งคลัสเตอร์ SQL อื่น ๆ 

สร้าง Balancer โหลดภายใน
นี่คือจุดที่ failover clustering ใน Azure แตกต่างจากโครงสร้างพื้นฐาน สแต็คเครือข่าย Azure ไม่สนับสนุน ARPS ที่ให้เปล่าดังนั้นไคลเอ็นต์ไม่สามารถเชื่อมต่อโดยตรงกับที่อยู่ IP ของคลัสเตอร์ได้ แต่ลูกค้าจะเชื่อมต่อกับ balancer โหลดภายในและเปลี่ยนเส้นทางไปยังโหนดคลัสเตอร์ที่ใช้งานอยู่ สิ่งที่เราต้องทำคือสร้าง balancer โหลดภายใน ทั้งหมดนี้สามารถทำได้ผ่าน Azure Portal ดังที่แสดงด้านล่าง ขั้นแรกให้สร้าง Balancer โหลดใหม่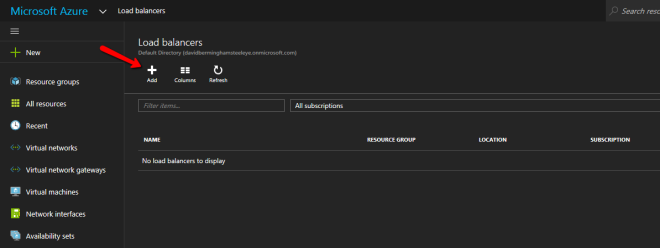 คุณสามารถใช้ Public Balancer โหลดถ้าไคลเอ็นต์ของคุณเชื่อมต่อผ่านทางอินเทอร์เน็ตสาธารณะ แต่สมมติว่าลูกค้าของคุณอาศัยอยู่ใน vNet เดียวกันเราจะสร้าง Internal Balancer โหลด สิ่งสำคัญที่ต้องจดบันทึกไว้ในที่นี้ก็คือ Virtual Network จะเหมือนกับเครือข่ายที่โหนดคลัสเตอร์ของคุณอาศัยอยู่ นอกจากนี้ที่อยู่ IP ส่วนตัวที่คุณระบุจะเหมือนกับที่อยู่ที่คุณใช้ในการสร้างทรัพยากรคลัสเตอร์ SQL
คุณสามารถใช้ Public Balancer โหลดถ้าไคลเอ็นต์ของคุณเชื่อมต่อผ่านทางอินเทอร์เน็ตสาธารณะ แต่สมมติว่าลูกค้าของคุณอาศัยอยู่ใน vNet เดียวกันเราจะสร้าง Internal Balancer โหลด สิ่งสำคัญที่ต้องจดบันทึกไว้ในที่นี้ก็คือ Virtual Network จะเหมือนกับเครือข่ายที่โหนดคลัสเตอร์ของคุณอาศัยอยู่ นอกจากนี้ที่อยู่ IP ส่วนตัวที่คุณระบุจะเหมือนกับที่อยู่ที่คุณใช้ในการสร้างทรัพยากรคลัสเตอร์ SQL 
 หลังจากสร้าง Internal Load Balancer (ILB) แล้วคุณจะต้องแก้ไขไฟล์ สิ่งแรกที่เราจะทำคือการเพิ่มแบ็กเอนด์พูล ในขั้นตอนนี้คุณจะเลือกชุดความพร้อมใช้งานที่เครื่องเซิร์ฟเวอร์คลัสเตอร์ของ SQL อยู่ อย่างไรก็ตามเมื่อคุณเลือก VM ที่แท้จริงเพื่อเพิ่มลงในแบ็กเอนด์พูลให้แน่ใจว่าคุณไม่ได้เลือกพยานร่วมกันในการแชร์ไฟล์ของคุณ เราไม่ต้องการเปลี่ยนเส้นทางการรับส่งข้อมูล SQL ไปยังพยานที่แชร์ไฟล์ของคุณ
หลังจากสร้าง Internal Load Balancer (ILB) แล้วคุณจะต้องแก้ไขไฟล์ สิ่งแรกที่เราจะทำคือการเพิ่มแบ็กเอนด์พูล ในขั้นตอนนี้คุณจะเลือกชุดความพร้อมใช้งานที่เครื่องเซิร์ฟเวอร์คลัสเตอร์ของ SQL อยู่ อย่างไรก็ตามเมื่อคุณเลือก VM ที่แท้จริงเพื่อเพิ่มลงในแบ็กเอนด์พูลให้แน่ใจว่าคุณไม่ได้เลือกพยานร่วมกันในการแชร์ไฟล์ของคุณ เราไม่ต้องการเปลี่ยนเส้นทางการรับส่งข้อมูล SQL ไปยังพยานที่แชร์ไฟล์ของคุณ 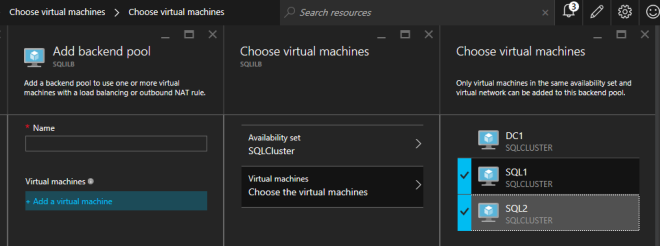
 สิ่งต่อไปที่เราจะทำคือเพิ่ม Probe การสอบสวนที่เราเพิ่มจะโพรบ Port 59999 โพรบนี้จะกำหนดโหนดที่ใช้งานอยู่ในคลัสเตอร์ของเรา
สิ่งต่อไปที่เราจะทำคือเพิ่ม Probe การสอบสวนที่เราเพิ่มจะโพรบ Port 59999 โพรบนี้จะกำหนดโหนดที่ใช้งานอยู่ในคลัสเตอร์ของเรา 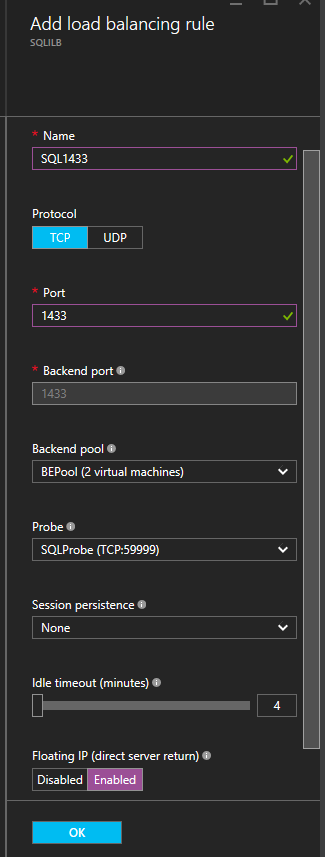 จากนั้นเราจำเป็นต้องมีกฎการกระจายการโหลดเพื่อเปลี่ยนเส้นทางการรับส่งข้อมูล SQL Server ในตัวอย่างของเราเราใช้อินสแตนซ์เริ่มต้นของ SQL ซึ่งใช้พอร์ต 1433 นอกจากนี้คุณยังอาจต้องการเพิ่มกฎสำหรับ 1434 หรืออื่น ๆ ตามความต้องการในการใช้งานของคุณ สิ่งสำคัญที่ต้องสังเกตในภาพหน้าจอด้านล่างคือการส่งคืนเซิร์ฟเวอร์โดยตรงจะได้รับการเปิดใช้งาน ตรวจสอบให้แน่ใจว่าคุณได้ทำการเปลี่ยนแปลงนั้น
จากนั้นเราจำเป็นต้องมีกฎการกระจายการโหลดเพื่อเปลี่ยนเส้นทางการรับส่งข้อมูล SQL Server ในตัวอย่างของเราเราใช้อินสแตนซ์เริ่มต้นของ SQL ซึ่งใช้พอร์ต 1433 นอกจากนี้คุณยังอาจต้องการเพิ่มกฎสำหรับ 1434 หรืออื่น ๆ ตามความต้องการในการใช้งานของคุณ สิ่งสำคัญที่ต้องสังเกตในภาพหน้าจอด้านล่างคือการส่งคืนเซิร์ฟเวอร์โดยตรงจะได้รับการเปิดใช้งาน ตรวจสอบให้แน่ใจว่าคุณได้ทำการเปลี่ยนแปลงนั้น
แก้ไขทรัพยากร IP ของเซิร์ฟเวอร์ SQL
ขั้นตอนสุดท้ายสำหรับการปรับใช้ SQL Server Failover Clusters ใน Azure Resource Manager เรียกใช้สคริปต์ PowerShell ต่อไปนี้ในโหนดคลัสเตอร์ของคุณ ซึ่งจะช่วยให้ Cluster IP Address สามารถตอบสนองต่อโพรโตคอล ILB และตรวจสอบว่าไม่มีข้อขัดแย้งเกี่ยวกับที่อยู่ IP ระหว่าง Cluster IP Address และ ILB โปรดทราบ; คุณจะต้องแก้ไขสคริปต์นี้ให้เหมาะกับสภาพแวดล้อมของคุณ ซับเน็ตมาสก์ถูกตั้งค่าเป็น 255.255.255.255 นี่ไม่ใช่ความผิดพลาดให้ปล่อยทิ้งไว้ ซึ่งจะสร้างเส้นทางเฉพาะโฮสต์เพื่อหลีกเลี่ยงความขัดแย้งกับที่อยู่ IP กับ ILB
# กำหนดตัวแปร
$ ClusterNetworkName = ""
# ชื่อเครือข่ายคลัสเตอร์
(ใช้ Get-ClusterNetwork ใน Windows Server 2012 ที่สูงกว่าเพื่อค้นหาชื่อ)
$ IPResourceName = ""
# ชื่อที่อยู่ IP Address
$ ILBIP = ""
# ที่อยู่ IP ของ Balancer โหลดภายใน (ILB)
การนำเข้าโมดูล FailoverClusters
# หากคุณใช้ Windows Server 2012 หรือสูงกว่า:
Get-ClusterResource $ IPResourceName | ตั้ง ClusterParameter
-Multiple @ {ที่อยู่ = $ ILBIP; ProbePort = 59999; SubnetMask = "255.255.255.255";
เครือข่าย = $ ClusterNetworkName; EnableDHCP = 0}
# ถ้าคุณกำลังใช้ Windows Server 2008 R2 ใช้:
#cluster res $ IPResourceName / priv enabledhcp = 0 ที่อยู่ = $ ILBIP probeport = 59999
SubnetMask = 255.255.255.255
ข้อสรุป
ขณะนี้คุณควรมีอินสแตนซ์คลัสเตอร์ล้มเหลวของ SQL Server ที่ทำงานอยู่ เผชิญหน้ากับปัญหาในการปรับใช้ SQL Server Failover Clusters ใน Azure Resource Manager? ติดต่อฉันทาง Twitter @daveberm และเรายินดีที่จะให้ความช่วยเหลือ หากคุณต้องการคีย์การประเมินผลของ DataKeeper โปรดกรอกแบบฟอร์มที่ http://us.sios.com/clustersyourway/cta/14-day-trial, SIOS จะส่งรหัสประเมินผลที่ส่งถึงคุณ