Date: มีนาคม 8, 2018
ป้ายกำกับ:การกู้คืนข้อมูล, เก็บข้อมูล Azure
Azure Storage Service Interrupt …เวลาสำหรับแผนการกู้คืนความเสียหาย
บริการจัดเก็บข้อมูล Azure ในช่วงเย็นเมื่อวานนี้มีประสบการณ์เกี่ยวกับการหยุดชะงักบริการในสหรัฐอเมริกายุโรปและบางส่วนของเอเชียซึ่งส่งผลกระทบต่อบริการคลาวด์หลายแห่งในภูมิภาคเหล่านี้
เป็นส่วนหนึ่งของการปรับปรุงประสิทธิภาพการทำงานของ Azure Storage พบว่ามีการค้นพบปัญหานี้ซึ่งส่งผลให้ความสามารถลดลงในบริการที่ใช้ Azure Storage รวมถึง Virtual Machines, Visual Studio Online, เว็บไซต์ค้นหาและบริการอื่น ๆ ของ Microsoft
อ่านรายงานทั้งหมดในบล็อก Azure http://azure.microsoft.com/blog/2014/11/19/update-on-azure-storage-service-interruption/
ดังนั้นการหยุดทำงานนี้หมายความว่าอย่างไรกับความคิดเกี่ยวกับการปรับใช้ระบบคลาวด์ การหยุดชะงัก "ระดับโลก" ของขนาดนี้ไม่สามารถเกิดขึ้นได้อย่างสม่ำเสมอสำหรับผู้ให้บริการระบบคลาวด์ใด ๆ โดยเฉพาะอย่างยิ่งหากตั้งใจจะยังคงอยู่ในธุรกิจคลาวด์ไม่ว่าจะเป็น Microsoft, Amazon, Google หรืออื่น ๆ อย่างไรก็ตามในฐานะสถาปนิกระบบคลาวด์หรือผู้รับผิดชอบการใช้งานระบบคลาวด์คุณต้องรับผิดชอบต่อลูกค้าของคุณในการมี "แผนข" ในกระเป๋าหลังของคุณ ใช้เวลาในการวางแผนสำหรับการกู้คืนระบบในกรณีที่เกิดกรณีที่เลวร้ายที่สุด
แผนกู้คืนความเสียหายที่ดีคืออะไร?
แผน B เกี่ยวข้องกับการมีขั้นตอนการดำเนินการที่เป็นลายลักษณ์อักษรเพื่อกู้คืนข้อมูลและบริการในตำแหน่งอื่นในกรณีที่เกิดการแพร่กระจายอย่างกว้างขวางซึ่งส่งผลต่อความสามารถในการให้บริการของผู้ให้บริการระบบคลาวด์ แผนนี้มีความสำคัญแม้ว่าคุณจะมีการใช้งานระบบคลาวด์ที่มีความยืดหยุ่นสูงที่ออกแบบมาเพื่อให้ทำงานต่อไปได้แม้ในกรณีที่เกิดการขัดจังหวะภายในพื้นที่โซนความพร้อมใช้งานหรือโดเมนข้อบกพร่อง
การกู้คืนข้อมูลการกู้คืนแอ็พพลิเคชันและการเข้าถึงไคลเอ็นต์
ในระดับสูงคุณควรกังวลเกี่ยวกับสามประการ ได้แก่ การกู้คืนข้อมูลการกู้คืนแอปพลิเคชันและการเข้าถึงไคลเอ็นต์ มีหลายวิธีในการจัดการกับข้อกังวลเหล่านี้โดยอัตโนมัติมากกว่าคนอื่น ๆ บางส่วนมีวัตถุประสงค์ Recovery Time Objective (RTO) และ Recovery Point Objective (RPO) ที่ดีกว่าประเทศอื่น ๆ
สิ่งที่กำหนดค่าเพื่อ Beat Outage?
เมื่อสัปดาห์ที่แล้วผมได้เขียนบล็อกเกี่ยวกับวิธีสร้างกลุ่มย่อยหลายกลุ่มที่ขยายระหว่าง AWS cloud และ Azure cloud การกำหนดค่าประเภทนี้เป็นเพียงสิ่งที่จำเป็นในกรณีที่มีการหยุดทำงานของขนาดที่เราเพิ่งได้รับเมื่อวานนี้ในเมฆ Azure

แบบจำลองการจำลองแบบ "Cloud-To-Cloud"
อีกทางเลือกหนึ่งสำหรับรูปแบบจำลองแบบ "cloud-to-cloud" คือการใช้ดาต้าเซ็นเตอร์ของคุณเป็นไซต์สำหรับกู้คืนระบบสำหรับการปรับใช้ระบบคลาวด์ เป็นประโยชน์ที่จะมีกรรมสิทธิ์ทางกายภาพของข้อมูลของคุณ แต่นั่นหมายความว่าคุณกลับมาใช้ธุรกิจจัดการดาต้าเซ็นเตอร์อีกครั้ง นี้สามารถลบล้างบางส่วนของประโยชน์ของการใช้งานเมฆบริสุทธิ์
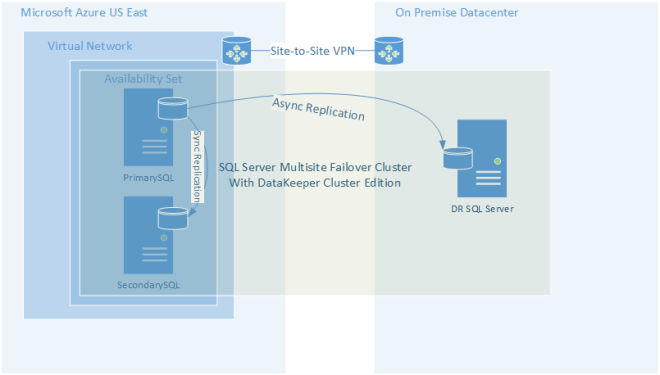
หากคุณยังไม่พร้อมที่จะใช้งานระบบคลาวด์เต็มรูปแบบให้ใช้ประโยชน์จากคลาวด์ในฐานะไซต์กู้คืนระบบ นี่อาจเป็นวิธีที่ง่ายที่สุดและคุ้มค่าที่สุดในการติดตั้งศูนย์ข้อมูลนอกสถานที่สำหรับการกู้คืนความเสียหาย เริ่มใช้ประโยชน์จากสิ่งที่เมฆมีให้โดยไม่ต้องกระทำอย่างเต็มที่เพื่อย้ายปริมาณงานทั้งหมดเข้าสู่ระบบคลาวด์
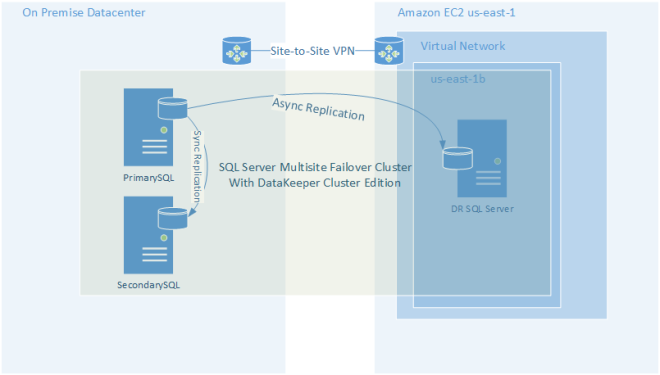
DataKeeper Cluster Edition
ภาพประกอบที่แสดงข้างต้นใช้โซลูชันการจำลองแบบโฮสต์ที่เรียกว่า DataKeeper Cluster Edition เพื่อสร้างกลุ่มเซิร์ฟเวอร์ SQL หลายเครื่อง อย่างไรก็ตาม DataKeeper สามารถใช้เพื่อเก็บข้อมูลใด ๆ ไว้ในซิงค์ ทั้งระหว่างผู้ให้บริการระบบคลาวด์ที่ต่างกันหรือในรูปแบบไฮบริดคลาวด์
การแจ้งเตือน! มีแผน B
ไมโครซอฟท์ไม่ได้เป็นคนเดียวในการจัดการกับปัญหาการขาดแคลนระบบคลาวด์เพราะปัญหาขาดหายไปได้ส่งผลกระทบต่อ Google, Microsoft, Amazon, DropBox และอื่น ๆ อีกมากมายในปีนี้เพียงอย่างเดียว การมี "แผน B" ในสถานที่คือต้องมีตลอดเวลาที่คุณอาศัยอยู่กับบริการใด ๆ ของระบบคลาวด์
ทำซ้ำโดยได้รับอนุญาตจาก https://clusteringformeremortals.com/2014/11/20/azure-storage-service-interruptiontime-for-plan-b/