Date: กุมภาพันธ์ 11, 2015
ผู้ดูแลของ SQL Server มีตัวเลือกสำหรับการใช้งานสูง (HA) ในสภาพแวดล้อม VMware VMware vSphere ฮาด้วย Microsoft มี Windows Server Failover Clustering (WSFC) และ SQL Server ใน WSFC มีตัวเลือกของตัวเองฮา ด้วยกลุ่มความพร้อมใช้งานตลอดเวลาและคลัสเตอร์ล้ม AlwaysOn กลุ่มบุคคลที่สามให้โซลูชั่นเก๋ ๆ สำหรับ HA และภัยพิบัติการกู้คืน และเหล่านี้มักจะรวมเข้ากับโซลูชั่นอื่น ๆ เพื่อสร้างเสริมเพิ่มเติม เช่น แก้ไขปัญหาบางอย่างใช้ประโยชน์จากคุณลักษณะการคลัสเตอร์ล้ม AlwaysOn ที่รวมอยู่ใน SQL เซิร์ฟเวอร์แข็ง HA และปกป้องข้อมูลน้อยกว่าต้นทุนของกลุ่มความพร้อมใช้งานตลอดเวลาที่ต้องแพงกว่ารุ่นองค์กร บทความนี้เน้นสิ่งที่ควรรู้ทุกผู้ดูแลระบบ SQL Server ก่อนการกำหนดกลยุทธ์พร้อมใช้งานสูงสำหรับโปรแกรมประยุกต์ที่สำคัญในสภาพแวดล้อม vSphere กลยุทธ์ดังกล่าวจะคล้ายกับการกำหนดค่าแบบมัลติไซต์ที่แสดงในรูปที่ 1 ซึ่งเป็นไปไม่ได้ มีตัวเลือกบางอย่างฮา 1 กลุ่มความพร้อมสูงสำหรับ vSphere ต้องดิบดิสก์แมปชั้นของนามธรรมใช้ในเซิร์ฟเวอร์เสมือนสามารถมีความยืดหยุ่นมาก แต่ abstractions ดังกล่าวทำให้เกิดปัญหาเมื่อเครื่องเสมือน (VM) ที่ต้องการอินเตอร์เฟซกับอุปกรณ์ทางกายภาพ นี่คือกรณี vSphere กับเครือข่ายพื้นที่เก็บข้อมูล (SANs) การใช้งานร่วมกันกับสารบางอย่างและคุณลักษณะอื่น ๆ ร่วมกันเก็บ เช่นรั้ว I/O และสำรอง SCSI, vSphere ใช้เทคโนโลยีที่เรียกว่า Raw อุปกรณ์การแมป (RDM) เพื่อสร้างการเชื่อมโยงโดยตรงผ่าน hypervisor ระหว่าง VM และระบบเก็บข้อมูลภายนอก ความต้องการสำหรับการใช้ RDM เก็บใช้ร่วมกันที่มีอยู่สำหรับคลัสเตอร์ใด ๆ รวมทั้งคลัสเตอร์ล้มเหลวเซิร์ฟเวอร์ SQL ในคลัสเตอร์แบบดั้งเดิมที่สร้างขึ้น ด้วย WSFC ใน vSphere, RDM ต้อง beused เพื่อให้เครื่องเสมือน (VMs) ถึงการจัดเก็บข้อมูลพื้นฐาน (SAN) สามารถรักษาความเข้ากันได้ 100 เปอร์เซ็นต์กับซานคำสั่งทั้งหมด ทำให้เสมือนจริงเก็บเข้าไร้รอยต่อในระบบปฏิบัติการและโปรแกรมประยุกต์ซึ่งเป็นความต้องการจำเป็นของ WSFC RDM ได้ RDM สามารถทำงานได้อย่างมีประสิทธิภาพ แต่การบรรลุผลลัพธ์ต้องการนั้นไม่ได้ง่าย และไม่อาจเป็นไปได้ ตัวอย่างเช่น RDM ไม่สนับสนุนดิสก์พาร์ติชัน ดังนั้นจึงจำเป็นต้องใช้ "ดิบ" หรือทั้ง Lun (หมายเลขหน่วยทางลอจิคัล), และไม่มีการแม็ปสำหรับเก็บบล็อกแนบโดยตรงและบางอุปกรณ์ RAID 2 ใช้การแมปดิสก์ดิบหมายถึง เสียสละนิยม VMware คุณสมบัติอื่นสำคัญเกี่ยวข้องกับของถูกเต็มทราบเกี่ยวกับ RDM เข้าใจอุปสรรคที่สามารถสร้างสำหรับการใช้คุณสมบัติอื่น ๆ VMware ว่าเป็นที่นิยมกับผู้ดูแลเซิร์ฟเวอร์ SQL เมื่ออุปสรรคเหล่านี้ถือว่าเป็นการยอมรับ พวกเขามักจะ พวกเขาตัดออกการแมปอุปกรณ์วัตถุดิบตัวเลือกสำหรับการใช้งานสูง ปัญหาพื้นฐานคือ วิธี RDM รบกวนลักษณะการทำงานที่ใช้แฟ้มดิสก์ (VMDK) เครื่องเสมือน VMware เช่น RDM ป้องกันการใช้ snapshot ของ VMware และนี้จะป้องกันการใช้คุณลักษณะใด ๆ ที่ต้องใช้ช็อต เช่นงบการเงินรวมเสมือนสำรอง (VCBs) นอกจากนี้การแมปดิสก์ดิบ complicates ข้อมูลการเคลื่อนไหว ซึ่งสร้างอุปสรรคโดยใช้คุณสมบัติที่ทำให้เซิร์ฟเวอร์เสมือนดังนั้นประโยชน์ แปลง VMs เป็นแม่แบบเพื่อให้ง่ายต่อการใช้งาน และโยกย้าย VMs ในโฮสต์แบบไดนามิกที่ใช้ได้ ปัญหาอื่นอาจเกิดขึ้นสำหรับการใช้งานธุรกรรมสูงเช่น SQL Server จะไม่สามารถใช้แฟลชแคอ่านเมื่อมีการกำหนดค่าการ RDM 3 เก็บข้อมูลที่ใช้ร่วมกันสามารถสร้างเดียวจุดของความล้มเหลวเซิร์ฟเวอร์คลัสเตอร์โดยตรงเข้าถึงใช้ร่วมกันเก็บต้องแบบดั้งเดิมสามารถสร้างข้อจำกัดสำหรับการใช้งานสูงและภัยพิบัติบทบัญญัติการกู้คืน และข้อจำกัดเหล่านี้สามารถ ในการเปิด สร้างอุปสรรคต่อการย้ายแอพพลิเคกับ vSphere ในคลัสเตอร์ failover แบบดั้งเดิม น้อยสองเซิร์ฟเวอร์ทางกายภาพ (โหนดคลัสเตอร์) เชื่อมต่อกับระบบของเก็บที่ใช้ร่วมกัน โปรแกรมประยุกต์ที่รัน บนเซิร์ฟเวอร์หนึ่ง และใน กรณี คลัสเตอร์ ซอฟต์แวร์เช่น Windows Server Failover Clustering ย้ายโปรแกรมประยุกต์ไปยังโหนสแตนด์บาย คล้ายคลัสเตอร์เป็นไปได้กับเซิร์ฟเวอร์เสมือนในสภาพแวดล้อม vSphere แต่นี้ต้องใช้เทคโนโลยีเช่นการแมปดิสก์ดิบให้ VMs สามารถเข้าถึงการจัดเก็บข้อมูลที่ใช้ร่วมกันโดยตรง ไม่ว่าเซิร์ฟเวอร์จะจริง หรือเสมือน การใช้พื้นที่เก็บข้อมูลที่ใช้ร่วมกันสามารถสร้างจุดเดียวของความล้มเหลว SAN สามารถมีการกำหนดค่าที่พร้อมใช้งานสูง แน่นอน แต่ที่เพิ่มขึ้นของความซับซ้อนและต้นทุน และสามารถมีผลต่อประสิทธิภาพการทำงาน โดยเฉพาะอย่างยิ่งสำหรับการใช้งานธุรกรรมสูงเช่น SQL Server 4 ฮา vSphere Clusters สามารถสร้างไม่ มีเสียสละ VMware ฟังก์ชันบางโซลูชันมีเก๋ ๆ เพื่อเอาชนะข้อจำกัดที่เกี่ยวข้องกับการเก็บข้อมูลที่ใช้ร่วมกันและข้อกำหนดในการใช้ RDM กับ SQL Server คลัสเตอร์ล้ม AlwaysOn และคลัสเตอร์ล้มเหลวเซิร์ฟเวอร์ Windows [id คำอธิบายเฉพาะ = "" จัดชิด =ความกว้างข อง "alignleft" = "319"] รูปที่ 1 – การกำหนดค่าความพร้อมสูงแบบมัลติไซต์ป้องกันโปรแกรมประยุกต์ขัดข้องที่มีผลต่อการเป็นศูนย์ข้อมูลทั้งหมด [/caption] ที่ดีสุดของการแก้ปัญหาเหล่านี้ให้การกำหนดค่าความยืดหยุ่น เรื่องการสร้างคลัสเตอร์ SANLess เพื่อตอบสนองความหลากหลายของความต้อง การ – จากคลัสเตอร์สองโหนในไซต์เดียว คลัสเตอร์ multinode คลัสเตอร์มีโหนดในสถานทางภูมิศาสตร์ที่แตกต่างกันสำหรับการป้องกันภัยพิบัติดังที่แสดงในรูปที่ 1 บางส่วนของวิธีการเหล่านี้ยังช่วยให้ใช้การจำลองที่ระดับบล็อกแบบเรียลไทม์ LAN/WAN-ปรับในลักษณะใดแบบอะซิงโครนัส หรือแบบซิงโครนัส ผล แก้ปัญหาเหล่านี้จะสามารถสร้าง RAID 1 มิเรอร์ผ่านเครือข่าย การเปลี่ยนทิศทางของการจำลองแบบข้อมูล (แหล่งที่มาและเป้าหมาย) โดยอัตโนมัติตามความจำเป็นหลังจากที่ล้มเหลวและ failback เพียงเป็นสำคัญ คลัสเตอร์ SANLess เป็นมักจะง่ายต่อการใช้ และทำงานกับเซิร์ฟเวอร์ทั้งทางกายภาพ และเสมือน เช่น สำหรับโซลูชั่นที่รวมกับ WSFC ผู้ดูแลจะสามารถกำหนดค่าโดยใช้คุณลักษณะคุ้นเคยในลักษณะที่หลีกเลี่ยงการใช้เก็บข้อมูลที่ใช้ร่วมกันเป็นจุดเดียวเกิดความล้มเหลวของ กลุ่มความพร้อมสูง เมื่อกำหนดค่า โซลูชั่นส่วนใหญ่แล้วโดยอัตโนมัติปรับเก็บภายในในเซิร์ฟเวอร์ที่สอง หรือมากกว่า (ใน หนึ่งศูนย์ข้อมูล), ทำให้พวกเขาปรากฏ WSFC เป็นถ้ามันเป็นอุปกรณ์เก็บข้อมูลที่ใช้ร่วมกัน 5 ฮา SANLess Clusters ส่งซูความสามารถ และประสิทธิภาพการทำงานนอกเหนือจากการสร้างจุดเดียวของความล้มเหลว การจำลองแบบข้อมูลบน SAN สามารถลดอัตราความเร็วประสิทธิภาพในสภาพแวดล้อม VMware ใช้งานสูงเช่น SQL Server เป็นอย่างยิ่งเสี่ยงกับปัจจัยที่เกี่ยวข้องกับประสิทธิภาพการทำงานเหล่านี้ [id คำอธิบายเฉพาะ = "" จัดชิด =ความกว้างของ
อง "alignleft" = "319"] รูปที่ 1 – การกำหนดค่าความพร้อมสูงแบบมัลติไซต์ป้องกันโปรแกรมประยุกต์ขัดข้องที่มีผลต่อการเป็นศูนย์ข้อมูลทั้งหมด [/caption] ที่ดีสุดของการแก้ปัญหาเหล่านี้ให้การกำหนดค่าความยืดหยุ่น เรื่องการสร้างคลัสเตอร์ SANLess เพื่อตอบสนองความหลากหลายของความต้อง การ – จากคลัสเตอร์สองโหนในไซต์เดียว คลัสเตอร์ multinode คลัสเตอร์มีโหนดในสถานทางภูมิศาสตร์ที่แตกต่างกันสำหรับการป้องกันภัยพิบัติดังที่แสดงในรูปที่ 1 บางส่วนของวิธีการเหล่านี้ยังช่วยให้ใช้การจำลองที่ระดับบล็อกแบบเรียลไทม์ LAN/WAN-ปรับในลักษณะใดแบบอะซิงโครนัส หรือแบบซิงโครนัส ผล แก้ปัญหาเหล่านี้จะสามารถสร้าง RAID 1 มิเรอร์ผ่านเครือข่าย การเปลี่ยนทิศทางของการจำลองแบบข้อมูล (แหล่งที่มาและเป้าหมาย) โดยอัตโนมัติตามความจำเป็นหลังจากที่ล้มเหลวและ failback เพียงเป็นสำคัญ คลัสเตอร์ SANLess เป็นมักจะง่ายต่อการใช้ และทำงานกับเซิร์ฟเวอร์ทั้งทางกายภาพ และเสมือน เช่น สำหรับโซลูชั่นที่รวมกับ WSFC ผู้ดูแลจะสามารถกำหนดค่าโดยใช้คุณลักษณะคุ้นเคยในลักษณะที่หลีกเลี่ยงการใช้เก็บข้อมูลที่ใช้ร่วมกันเป็นจุดเดียวเกิดความล้มเหลวของ กลุ่มความพร้อมสูง เมื่อกำหนดค่า โซลูชั่นส่วนใหญ่แล้วโดยอัตโนมัติปรับเก็บภายในในเซิร์ฟเวอร์ที่สอง หรือมากกว่า (ใน หนึ่งศูนย์ข้อมูล), ทำให้พวกเขาปรากฏ WSFC เป็นถ้ามันเป็นอุปกรณ์เก็บข้อมูลที่ใช้ร่วมกัน 5 ฮา SANLess Clusters ส่งซูความสามารถ และประสิทธิภาพการทำงานนอกเหนือจากการสร้างจุดเดียวของความล้มเหลว การจำลองแบบข้อมูลบน SAN สามารถลดอัตราความเร็วประสิทธิภาพในสภาพแวดล้อม VMware ใช้งานสูงเช่น SQL Server เป็นอย่างยิ่งเสี่ยงกับปัจจัยที่เกี่ยวข้องกับประสิทธิภาพการทำงานเหล่านี้ [id คำอธิบายเฉพาะ = "" จัดชิด =ความกว้างของ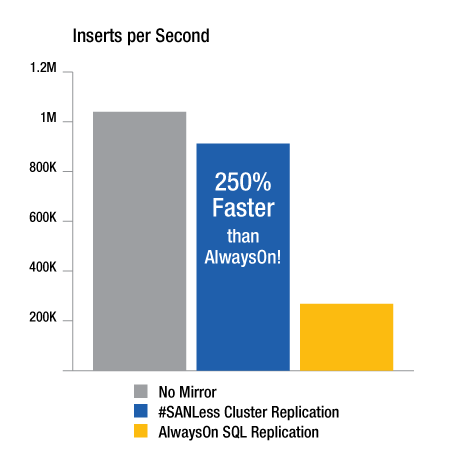 "alignleft" = "362"] รูปที่ 2 – การทดสอบของกลุ่มความพร้อมใช้งานตลอดเวลาและ SIOS SQL Server คลัสเตอร์ #SANLess แสดงประโยชน์ปริมาณได้ ด้วยวัตถุประสงค์เทคนิคการจำลองที่สร้างขึ้นสำหรับการใช้งานสูงและมีประสิทธิภาพสูงขึ้น [/caption] รูปที่ 2 สรุปผลการทดสอบที่แสดง 60-70 เปอร์เซ็นต์ประสิทธิภาพกำหนดโทษเกี่ยวข้องกับการใช้กลุ่มความพร้อมใช้งานตลอดเวลาของเซิร์ฟเวอร์ SQL ในการจำลองข้อมูล ทดสอบเหล่านี้ส่งผลนอกจากนี้ยังแสดงวิธีสร้างความพร้อมสูง SANLess คลัสเตอร์ ซึ่งใช้เก็บข้อมูลท้องถิ่น มีเกือบเป็นโครงแบบไม่ป้องกัน ด้วยการจำลองแบบข้อมูลใด ๆ หรือการสะท้อน #SANLess คลัสเตอร์ทดสอบสามารถบรรลุประสิทธิภาพที่น่าประทับใจนี้ได้เนื่องจากโปรแกรมควบคุมความลึกด้านล่าง NTFS ได้ เขียนเกิดขึ้นบนเซิร์ฟเวอร์หลัก โปรแกรมควบคุมเขียนสำเนาของบล็อก VMDK ในท้องถิ่นและสำเนาพร้อมกันผ่านเครือข่ายไปยังเซิร์ฟเวอร์รองซึ่งมี VMDK อิสระของตนเอง กลุ่ม sANLess มีจำนวนมากข้อดีอื่น ๆ เช่นกัน เช่น ผู้ที่นำเทคโนโลยีจำลองที่ระดับบล็อกที่สมบูรณ์รวมกับ WSFC จะสามารถปกป้องอินสแตนซ์ SQL Server ทั้งหมด รวมทั้งฐานข้อมูล เข้าสู่ระบบ และแทนงานทั้งหมดในแฟชั่นแบบบูรณาการ วิธีการนี้กับกลุ่มความพร้อมใช้งานตลอดเวลา ซึ่งล้มเหลวเพียงผู้ใช้กำหนดฐานข้อมูล ความคมชัด และต้องการพนักงานเพื่อจัดการวัตถุข้อมูลอื่น ๆ สำหรับทุกโหนดคลัสเตอร์แยกต่างหาก และด้วยตนเอง ## เกี่ยวกับผู้สร้างเจอร์รี่ Melnick บิลล์ SIOS เทคโนโลยี corp เจอร์รี่ Melnick (jmelnick@us.sios.com) รับผิดชอบสำหรับการกำหนดกลยุทธ์ขององค์กรและการดำเนินงานที่ SIOS corp.เทคโนโลยี (www.us.sios.com), ผู้ผลิตซอฟต์แวร์คลัสเตอร์ซาน SIOS และ #SANLess (www.clustersyourway.com) เขามากกว่า 25 ปีของประสบการณ์ในอุตสาหกรรมซอฟต์แวร์ระดับสูงและองค์กร ท่านได้รับปริญญาวิทยาศาสตร์บัณฑิตจากวิทยาลัยเบลัวกับงานผลิตบัณฑิตวิศวกรรมคอมพิวเตอร์และวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยบอสตัน
"alignleft" = "362"] รูปที่ 2 – การทดสอบของกลุ่มความพร้อมใช้งานตลอดเวลาและ SIOS SQL Server คลัสเตอร์ #SANLess แสดงประโยชน์ปริมาณได้ ด้วยวัตถุประสงค์เทคนิคการจำลองที่สร้างขึ้นสำหรับการใช้งานสูงและมีประสิทธิภาพสูงขึ้น [/caption] รูปที่ 2 สรุปผลการทดสอบที่แสดง 60-70 เปอร์เซ็นต์ประสิทธิภาพกำหนดโทษเกี่ยวข้องกับการใช้กลุ่มความพร้อมใช้งานตลอดเวลาของเซิร์ฟเวอร์ SQL ในการจำลองข้อมูล ทดสอบเหล่านี้ส่งผลนอกจากนี้ยังแสดงวิธีสร้างความพร้อมสูง SANLess คลัสเตอร์ ซึ่งใช้เก็บข้อมูลท้องถิ่น มีเกือบเป็นโครงแบบไม่ป้องกัน ด้วยการจำลองแบบข้อมูลใด ๆ หรือการสะท้อน #SANLess คลัสเตอร์ทดสอบสามารถบรรลุประสิทธิภาพที่น่าประทับใจนี้ได้เนื่องจากโปรแกรมควบคุมความลึกด้านล่าง NTFS ได้ เขียนเกิดขึ้นบนเซิร์ฟเวอร์หลัก โปรแกรมควบคุมเขียนสำเนาของบล็อก VMDK ในท้องถิ่นและสำเนาพร้อมกันผ่านเครือข่ายไปยังเซิร์ฟเวอร์รองซึ่งมี VMDK อิสระของตนเอง กลุ่ม sANLess มีจำนวนมากข้อดีอื่น ๆ เช่นกัน เช่น ผู้ที่นำเทคโนโลยีจำลองที่ระดับบล็อกที่สมบูรณ์รวมกับ WSFC จะสามารถปกป้องอินสแตนซ์ SQL Server ทั้งหมด รวมทั้งฐานข้อมูล เข้าสู่ระบบ และแทนงานทั้งหมดในแฟชั่นแบบบูรณาการ วิธีการนี้กับกลุ่มความพร้อมใช้งานตลอดเวลา ซึ่งล้มเหลวเพียงผู้ใช้กำหนดฐานข้อมูล ความคมชัด และต้องการพนักงานเพื่อจัดการวัตถุข้อมูลอื่น ๆ สำหรับทุกโหนดคลัสเตอร์แยกต่างหาก และด้วยตนเอง ## เกี่ยวกับผู้สร้างเจอร์รี่ Melnick บิลล์ SIOS เทคโนโลยี corp เจอร์รี่ Melnick (jmelnick@us.sios.com) รับผิดชอบสำหรับการกำหนดกลยุทธ์ขององค์กรและการดำเนินงานที่ SIOS corp.เทคโนโลยี (www.us.sios.com), ผู้ผลิตซอฟต์แวร์คลัสเตอร์ซาน SIOS และ #SANLess (www.clustersyourway.com) เขามากกว่า 25 ปีของประสบการณ์ในอุตสาหกรรมซอฟต์แวร์ระดับสูงและองค์กร ท่านได้รับปริญญาวิทยาศาสตร์บัณฑิตจากวิทยาลัยเบลัวกับงานผลิตบัณฑิตวิศวกรรมคอมพิวเตอร์และวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยบอสตัน