How to Achieve High Availability with Clusters
How to Achieve High Availability with Clusters
How to Achieve High Availability with Clusters
What is High Availability?
High availability (HA) is a component of a technology system that eliminates single points of failure to ensure continuous operations or uptime for an extended period. High availability clusters are groups of servers that support business-critical applications that require minimal downtime and continuous availability.
All organizations use a variety of business-critical databases and applications, such as data warehouses, e-commerce applications, customer relationship management systems (CRM), financial systems, supply chain management, and business intelligence systems. When a system, database, or application fails, these organizations require high availability protection to keep systems up and running and minimize the risk of lost revenue, unproductive employees, and unhappy customers.
Highly available clusters incorporate five design principles:
- They automatically failover to a redundant system to pick up an operation when an active component fails. This eliminates single points of failure.
- They can automatically detect application-level failures as they happen, regardless of the causes.
- They ensure no amount of data loss during a system failure.
- They automatically and quickly failover to redundant components to minimize downtime.
- They provide the ability to manually failover and failback to minimize downtime during planned maintenance.
TechTarget defines HA as “a system or component that is continuously operational for a desirably long length of time. Availability can be measured relative to ‘100% operational’ or ‘never failing.’ A widely-held but difficult-to-achieve standard of availability for a system or product is known as ‘five 9s’ (99.999%) availability.”
But let’s define High Availability in simple terms:
High Availability ensures your systems, databases, and applications operate when and as needed.
The “when” takes into consideration the percentage of time the application must be up and running. The “as needed” takes into consideration the proper operation of the system, database, and/or applications with no data loss.
Depending on the system and/or application, high availability will be different. For example, with mission-critical applications, such as your eCommerce systems, four 9s’ (99.99%) availability is considered an industry standard. With 99.99% availability, you can expect no more than 52.60 minutes of downtime per year or 8.64 seconds of downtime per day. However, for non-critical applications and systems, such as a single desktop failure, high availability may be two 9s (99%), which equates into 8.77 hours of downtime per year or 1.44 minutes of downtime per day. When measuring acceptable downtime, it is important that you consider:
- Unplanned downtime (e.g., hardware or software failures)
- The planned downtime needed for routine hardware and software maintenance
- Uptime at the database and application level
Your choice for high availability is dependent on many factors, including how critical the applications are to the business, whether customers are impacted, how often the applications run, how many users are affected, how quickly a database or application must failover to the redundant system, and how much data loss is tolerable.
High Availability Metrics: RTO and RPO
The two metrics normally used to assess HA (and Disaster Recovery (DR) as well) are the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO).
- RTO is the maximum tolerable duration of any outage. Online transaction processing applications generally have the lowest RTOs, and those that are mission-critical often have an RTO of only a few seconds.
- RPO is the maximum amount of data loss that can be tolerated when a failure happens. For HA, RPO is often zero to specify there should be zero data loss under all failure scenarios.
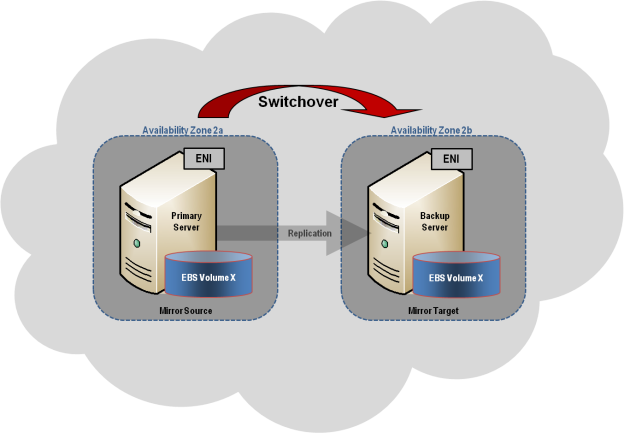
However, there is a difference between what RTOs and RPOs you can achieve to support high availability versus disaster recovery. With HA, data replication can be synchronous because your redundant components are on your LAN environment. Active and standby databases can be concurrently updated, enabling full, automatic, real-time recoveries that can satisfy the most demanding RTOs and RPOs. As a result, your standby instance is “hot” and in sync with your active instance, so it is ready to immediately take over in the event of a failure.
However, to recover systems, software, and data in the event of a disaster requires redundant components to be on a wide-area network (WAN). This is important because you must keep redundant components in a geographic location away from the active instance. But with a WAN, data replication is asynchronous to avoid negatively impacting throughput performance. This means that updates to standby instances will lag updates made to the active instance, resulting in a delay during the recovery process. Since disasters are rare, some delay may be tolerable and is dependent upon (a) how critical it is to your business to achieve the lowest possible RTO and RPO and (b) how much budget you can allocate to achieve the best RTO and RPO.
How SIOS Helps You Achieve High Availability
SIOS offers a single solution to meet both high availability and disaster recovery needs across a wide variety of operating systems, infrastructure environments, and applications, including SAP, SQL Server, Oracle, and other environments running in SAN-based, shared storage configurations or SANless, local data storage configurations.
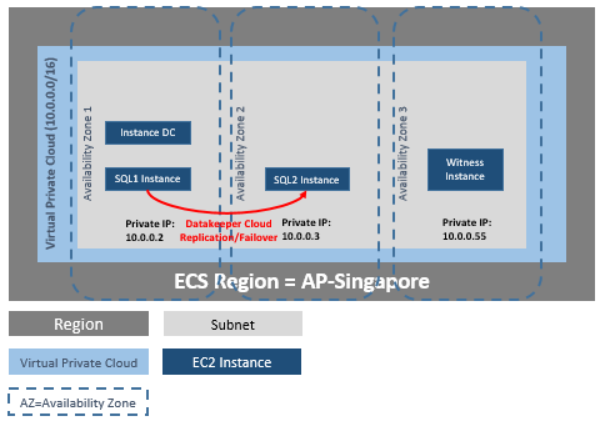
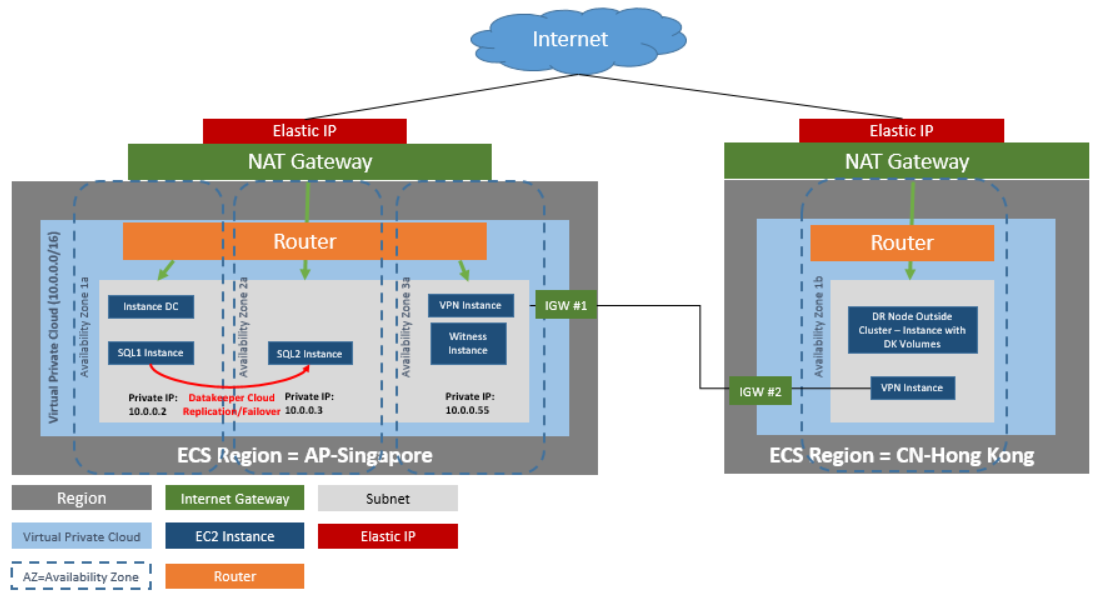
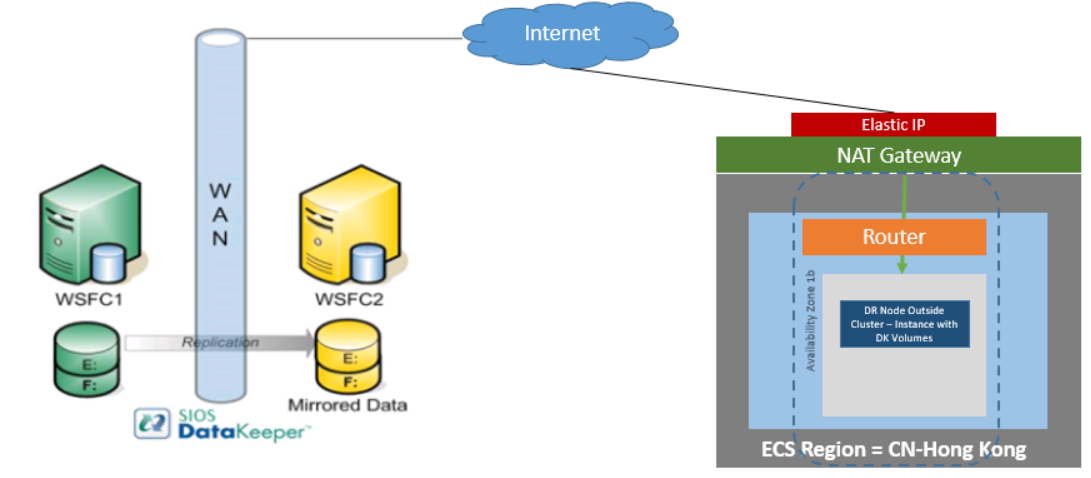
- Windows Environment: When added to a Windows Server Failover Cluster (WSFC) environment, SIOS DataKeeper lets you create a SANless cluster, where shared storage clusters are impossible or impractical, or add replication for disaster protection in your SAN-based Windows clusters. Fast, efficient host-based replication synchronizes local storage on local and remote cluster nodes, creating a SANLess cluster in any combination of physical, virtual, or cloud environments.
- Linux Environments: SIOS Protection Suite for Linux is a packaged clustering software solution that uses SIOS LifeKeeper and SIOS DataKeeper to provide a tightly integrated combination of high availability failover clustering, continuous application monitoring, data replication, and configurable recovery policies to protect your business-critical applications and data from downtime and disasters. SIOS Protection Suite lets you build SAN or SANLess clusters using a wide range of storage devices, including direct-attached storage, iSCSI, and Fibre Channel. SIOS Protection Suite for Linux supports all major Linux distributions, including Red Hat Enterprise Linux, SUSE Linux Enterprise Server, CentOS, and Oracle Linux.
With SIOS solutions, RPO is always zero and RTO is dependent on the application but typically 30 seconds to a few minutes for some applications. Let’s discuss one customer’s “SIOS in action” case study using HA clusters at Switzerland’s largest retail company.
Migros Achieves Critical Business Continuity of its POS system with SIOS High Availability Solutions
Migros is Switzerland’s largest retail company, its largest supermarket chain, and the largest employer with more than 100,000 employees. It is also one of the forty largest retailers in the world. Partnering with Realstuff Informatik AG, a Switzerland-based IT service provider and reseller of SIOS solutions, Migros was looking to replace its Point of Sale (POS) system with a new platform that was more efficient to operate and could minimize the threat of downtime.
The new POS system provides price and product assortment information in Migros’ 650 stores and the retailer needed a high availability solution to support day-to-day sales. Without an HA system, employees could not price products or weigh goods if there was a system failure, bringing operations to a standstill. After evaluating options, Migros decided it wanted an open-source server environment that offered high availability and continuous data protection, was independent of a virtual environment, and could be internally operated by the company’s IT staff. To address these requirements, the team picked SIOS Protection Suite for Linux for replication to safeguard POS data.
For system design, customer training, and native language support, Realstuff partnered with the SIOS Competence and Support Center for Central and Eastern Europe, based in Dresden, Germany and operated by Computer Concept. It was important to Migros to get 24x7x365 support during the regional office time from the Competence and Support Center.
Realstuff implemented the SIOS Protection Suite high-availability solution to constantly monitor the POS servers and replicate data. At each store location, two servers are used to ensure continuous data protection. If one server fails, the second instance takes over the work instantaneously. In addition, both servers mirror data assets on the monitoring system. Read the full Migros case study here.
Final Thoughts
The regional Competence and Support Center consulted with Realstuff to provide insight and direction on the implementation and launch and conducted a three-day training workshop to train the Migros team. Richard Huber, manager and a member of the executive board at Realstuff, commented post-deployment that the benefits of the SIOS high availability solution were its flexibility, reliability, ease of use, and assurance that data is kept in sync at all times.
Today, Migros has met its requirements for HA with SIOS easy-to-use solution, which provides continuous monitoring of servers, storage, applications, databases, and network connections to detect points of failure, reduce downtime, maintain client connectivity, and provide uninterrupted data access.
For more information on SIOS solutions and how SIOS can help you achieve HA in a SQL Server environment, you can read “Why Clustering for SQL Server High Availability” here.