RTO vs. RPO: Learning the Difference to Achieve Your Operational Goals
In addition to 99.99% availability time, high availability environments also need to meet stringent recovery time and recovery point objectives, RTO and RPO, respectively. RTO and RPO are two key parameters that businesses should define before creating their business continuity and disaster recovery plans. Both metrics help to design the recovery process, and to define the recovery time limits, the frequency of backups, and the recovery procedures. Although RTO and RPO may seem alike, there are core differences you should consider. Read on to understand the difference between RTO vs. RPO.
To be clear, RTO is a measure of the time elapsed from application failure to restoration of application operation. It is a measure that dictates how much time you have to recover after disaster strikes. On the other hand, RPO is a measure of how up-to-date the data is when application availability has been restored after a downtime issue. It is often described as the maximum amount of data loss that can be tolerated when a failure happens.
Things to consider for evaluating your disaster recovery plan
First, it’s important to define the criticality of the application and its associated data to core business operations. How much does a minute of downtime or data loss for this application cost the company? Next, consider the potential set of disasters against which you would like to protect your organization. Some disasters that require data recovery and backup include:
- Data loss: This may be as simple as someone deleting a folder, or as complex as a case of ransomware or an infected database.
- Application loss: This refers to when changes to security, an update, or system configurations negatively impact services.
- System loss: This includes when hardware fails, or, virtual server crashes.
- Datacenter loss: This includes data centers that are on-premises and in public clouds
- Business location loss: In this instance, a disaster might include an electrical outage, fire, flooding, or even a chemical spill outside the building. The business facilities require recovery to an alternate location.
Reducing an organization’s RPO and RTO
It’s important to consider the RTO and RPO as they apply to different types of data. Organizations that do a file-level backup of a database, rather than investing in an offsite virtual environment, will see longer recovery times and limits to how recently updated that data will be once recovered.
Consider the possible disasters, match them with the data sets that need to be protected, and then identify the recovery objectives. These steps will then provide you the information necessary to build tactical backup solutions that meet your recovery time objective and recovery point objective.
What is RTO and RPO in SQL Server?
SQL Server allows users to set up automated log backups to be restored from a standby server. With this log shipping, users can recover a fairly recent database copy—depending on the RTO and RPO of that process. Those RTO and RPO requirements are set by users, depending on their needs, budget, and any technological network limitations.
However, SQL Server RTO and RPO are not necessarily straightforward. In many cases, the process isn’t as fast as a client may imagine. They may have an ideal RPO in mind, but slow network speeds or an incorrectly configured backup can throttle this process. In addition, restoring a log backup in this way can involve transferring large amounts of data, and this process can easily exceed the determined acceptable RTO.
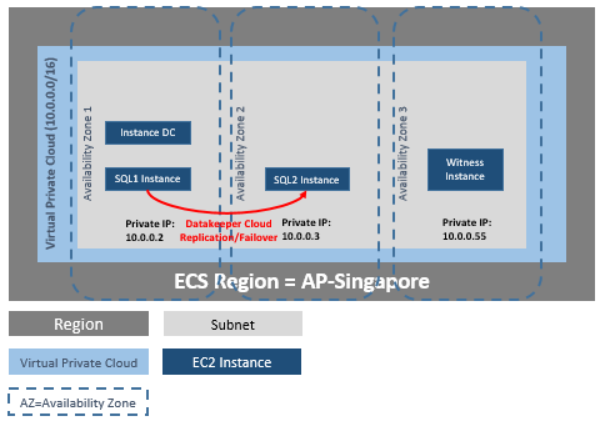
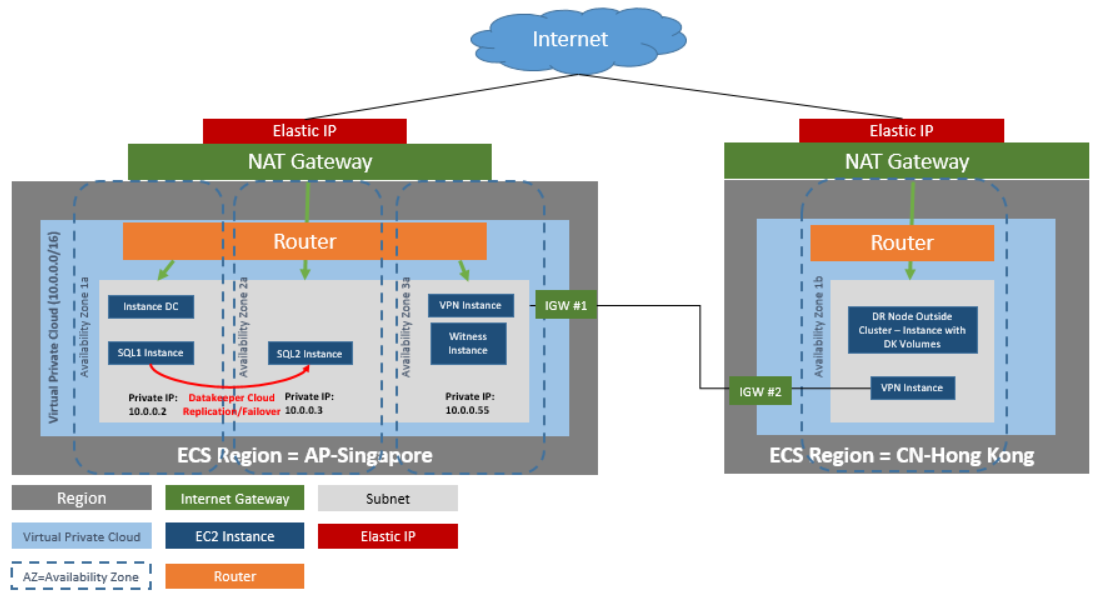
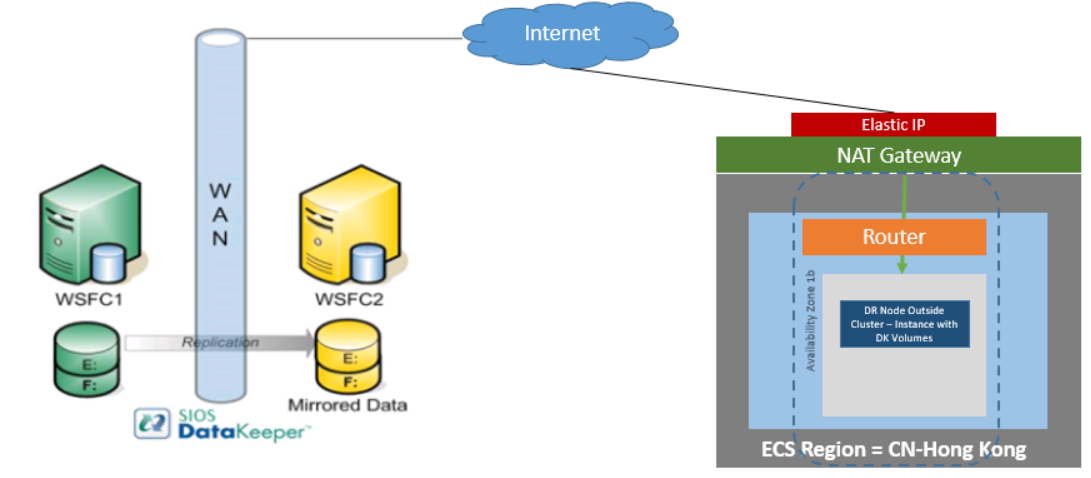
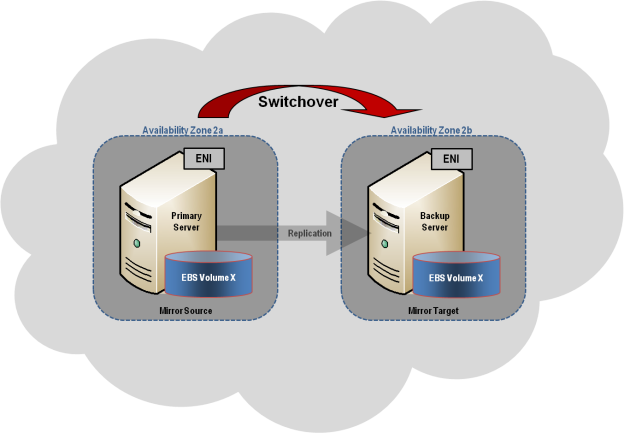
Since SQL Server is typically a business-critical application, customers can easily justify HA/DR protection for it – usually in the form of a failover cluster that can failover across cloud availability zones and regions for disaster recovery. This can be accomplished easily by adding SIOS DataKeeper to a Windows Server Failover Clustering environment or by using SIOS Protection Suite in a Linux environment. Both of these solutions will deliver not only 99.99% availability but also RPO of zero and RTO of mere seconds.
Now that you know…
Ultimately, data loss prevention for business continuity is a crucial requirement for any business. Take the time to consider how you will meet your RTO and RPO goals, no matter how large or small your business is, or what internal IT operations you support. SIOS high availability clusters deliver an RPO of zero and an RTO of mere minutes.
Learn more about SIOS DataKeeper for Windows or SIOS Protection Suite for Linux
To request a free trial, let us know here.
Reproduced from SIOS