Protect Systems from Downtime
In today’s business environment, organizations rely on applications, databases, and ERP Systems such as SAP, SQL Server, Oracle and more. These applications unify and streamline your most critical business operations. When they fail, they cost you more than just money. It is critical to protect these complicated systems from downtime.
Proven High Availability & Disaster Recovery
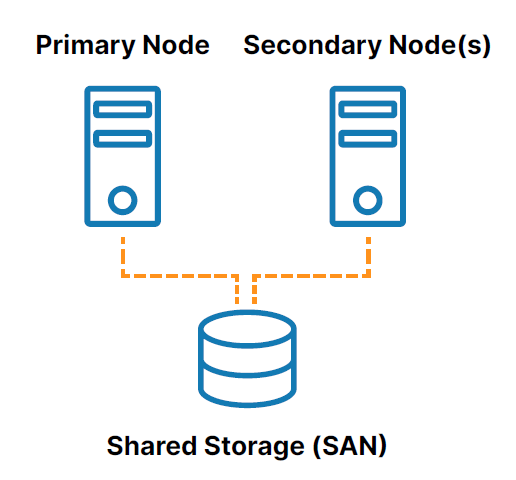
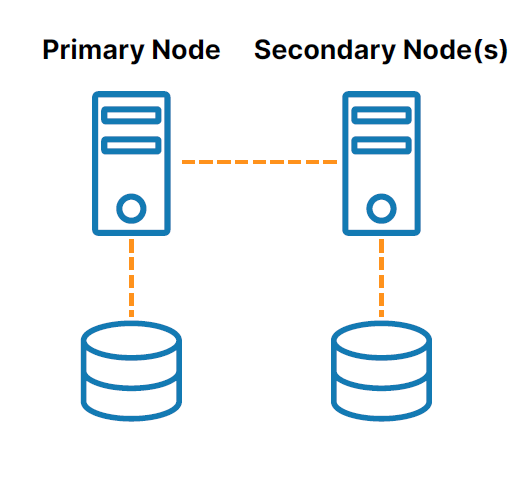
SIOS has 20+ years of experience in high availability and disaster recovery. SIOS knows there isn’t a one size fits all solution. Today’s data systems are a combination of on-premise, public cloud, hybrid cloud and multi cloud environments. The applications themselves can create even more complexity. But configuring open-source cluster software can be painstaking, time consuming, and prone to human error.
SIOS has solutions that provide high availability and disaster recovery for critical applications. These solutions have been developed based on our real-world experience, across different industries and use-cases. Our products include SIOS DataKeeper Cluster Edition for Windows and SIOS LifeKeeper for Linux or Windows. These powerful applications provide failover protection. The Application Recovery Kits included with LifeKeeper speeds up application configuration time by automating configuration and validates inputs.
System Protection On-Premises, in the Cloud or in Hybrid Environments
SIOS provides the protection you need for business-critical applications and reduces complexity of managing them, whether on-premises, in the cloud, or in hybrid cloud environments. Learn more about us in the video below or contact us to learn more about high availability and disaster recovery for your business critical applications.

Reproduced with permission from SIOS