| July 15, 2020 |
SIOS Protection Suite for Linux Version 9.5 is Here! |
| July 14, 2020 |
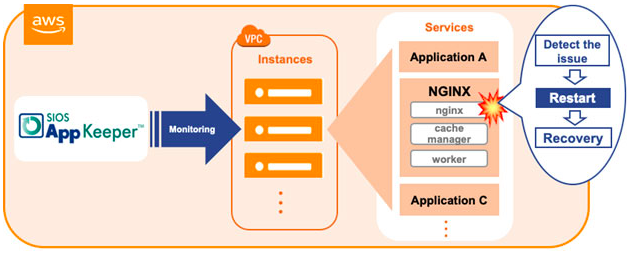
EC2 Monitoring Best Practices: Using SIOS AppKeeper to Protect NGINX Webservers on Amazon EC2
|
| July 12, 2020 |
What is Amazon CloudWatch?
What is Amazon CloudWatch?What you can do with CloudWatch and some hurdles to considerWith AWS boasting a dominant share of the cloud market, many companies are migrating their on-premises systems to the cloud with Amazon AWS. So, how should a system running in the AWS environment be managed? In this blog post, we will introduce the features of Amazon CloudWatch, a monitoring service provided by AWS, as well as the challenges of implementing it and how to solve them. Using Amazon CloudWatch to closely monitor your AWS environmentTo ensure that you have a stable cloud environment, it is important to detect anomalies (“system impairments”) quickly and respond in a timely manner. Monitoring becomes an important and necessary task for any organization moving to the cloud. This is no different than if you were managing on-premises applications and infrastructure. So, how should you monitor in an AWS environment? One choice is to use Amazon CloudWatch, which monitors CPU, memory, and disk usage and notifies you when a predetermined threshold is exceeded. Plus, you can set up your own metrics to monitor various items such as application logs. The best part about Amazon CloudWatch is that it’s a service provided by AWS itself. It has a high affinity with Amazon EC2 and other AWS services, so it can quickly respond to frequent functional extensions and specification changes, and can easily support AWS Auto Scaling, which automatically increases or decreases resources according to the load. Amazon CloudWatch provides precise monitoring tailored to each environment’s unique circumstances. Amazon CloudWatch implementation challengesWhile Amazon CloudWatch is an ideal fit for organizations with experienced cloud engineers and DevOps teams, there are some things the average users should be aware of. Amazon CloudWatch is effective for monitoring an organization’s AWS environment, but it requires a certain level of skill and knowledge to configure and deploy. Especially when you set your own metrics, are setting up alerts, or taking into account Auto Scaling, the complexity increases. For example, If you’re setting up monitoring, it’s easy, but if you’re setting up email, rebooting, AutoScaling, etc., depending on the resource situation, it can be difficult. If you want to automate the recovery process with instructions such as “restart the server when an error occurs”, you must first create a recovery scenario with an AWS Lambda script that provides a detailed description of the conditions and actions to be taken. How familiar is your team with AWS Lambda? The principal advantage of Amazon CloudWatch is that you can monitor your environment closely, but in order to do that, you must properly design in advance for each system what items to monitor and when, threshold values, etc. These design tasks can take a lot of time. Of course, your mission-critical systems need to be closely monitored in this way, but this level of detail and sophistication is not appropriate for all systems. For some, such as internal websites or WordPress servers, you will want to minimize your operating and labor costs. In such cases, we would like to suggest you consider a tool that can be more easily operated and managed. For mission-critical applications, you need high availability protection with SIOS clustering software. Add SIOS DataKeeper software to a Windows Server Failover Clustering environment to create a SANless cluster in Amazon EC2 that fails over across availability zones and regions. Use SIOS Protection Suite for Linux for application-aware clustering designed to simplify complexity and orchestrate failover according to application-specific best practices. Contact the SIOS availability experts today to learn more about achieving maximum uptime for your mission-critical applications. Reproduced from SIOS |
| July 8, 2020 |
Test/QA Systems are a Critical Part of Enterprise Availability
Test/QA Systems are a Critical Part of Enterprise Availability“I could kiss you,” that’s what a friend blurted out to me nearly three decades ago as she ran towards me. She had dropped her reeds for her saxophone on the way to one of the biggest band competitions in our region. I didn’t know whose they were, but when I saw the pack of reeds on the seat on the bus I picked them up and took them with me to the warm-up area. Three minutes into her warm-up, her 1st reed cracked and she panicked as she reached into empty pockets for replacements. When I piped up that I had found them, she blurted out, “I could kiss you right now.” As the VP of Customer Experience at SIOS Technology Corp. I have the unique and distinct pleasure of working with a number of enterprise customers and partners at different phases of the availability spectrum. Sometimes I have the opportunity of working with end customers for issue resolution, mitigation, and improvements. At other times our teams are actively working with partners and customers to architect and implement enterprise availability to protect their systems from downtime. A recent customer experience reminded me of something that happened nearly 30 years ago when my friend blurted out, “I could kiss you.” My team and I were on a customer call. The call began with the usual pleasantries, introductions, and an overview of the customer’s enterprise environment. Thirty minutes into the call, things were going so well. Their architecture was solid, thoughtful, and well documented. Their team was knowledgeable, technically sound, and experienced. But then, the customer intimated that due to cost savings they would not be planning to maintain a dedicated test/quality system. I took a deep breath. Actually it was more of an exhale like the rush of air from a gut punch. I prepared to respond, but before I could a voice broke through. “The number one cause of downtime is lack of process,” exclaimed the Partner Rep Architect on the call with us. After a brief banter, the customer agreed to maintain a test/QA system and I nearly blurted out, “I could kiss you!” On the front lines of many Enterprise deployments (new systems, data center migrations, and system updates) my teams in Support and Services have seen dozens of issues that could have been mediated by utilizing a test system/cluster. A test/quality system is an invaluable part of an HA strategy to avoid downtime. Common tasks associated with maintaining an enterprise deployment such as patches, updates, and configuration changes come with risk. Enormous risk. Commonly identified risks of testing in production include several serious and potentially catastrophic issues:
If a customer attempts to apply risky changes in production, the result can be quite damaging. On top of those listed above, there is an increased risk of downtime, corruption of application installations, and in some cases irreversible damage. Take the case of Customer X (a high profile SAP Enterprise shop in the manufacturing industry).
When patches are applied to a test/QA or sandbox system, patches and critical fixes can be managed and verified to reduce loss of productivity and unplanned downtime. Testing applications in a production-like environment allows you to identify unforeseen problems and correct the issues before they adversely impact your operations. Pre-production design and testing eliminate costly business disruption, improve your customer experience and protect your brand. Using a test QA System to Improve Production Availability and ProcessesHere are the basics that using a test/QA system, can provide for improving your production availability and processes. A controlled environment, that is similar (it must resemble production as close as possible) to the production environment, provides the ability to:
If you have a Test/QA environment for deploying your critical enterprise availability software, I could kiss you right now. Having this environment gives your team the ability “to test, validate and verify(2)” architecture, business requirements, user scenarios, and general integration with a system or set of systems that most closely resembles the production environment- you know the one that makes the money. Of course, you will still have to schedule windows to maintain your production systems and perform testing on them as well, but after a safe buffer step has been completed in between. — Cassius Rhue, VP, Customer Experience ————- References:
|
| June 29, 2020 |
Enterprise Availability: Lessons from the Court
Enterprise Availability: Lessons from the CourtI love basketball. I love to play it, watch it, and think through the cerebral aspects of the game; the thoughts and motivations, strategy and tactics. I like to look for the little things that work or fail, the screen set too soon or the roll that happened too late. I like defense and rotation. I like to know the coaches’ strategy for practice, walkthroughs, travel, and so on. So naturally a few months ago, when I had a day off from the 24/7 world of availability, imagine that, I took my day off to watch basketball, and more specifically my daughter’s middle school basketball practice. About a third of the way through watching, I couldn’t contain myself. I whistled to and “prodded” the young girl lollygagging and trotting up the court and yelled, “Run! Hustle!” And she did, as did the teammates within earshot. The next few minutes, plays, and drills were filled with energy, crisp cuts, smooth motions, and drive. But, it didn’t last. Instead, there were more whistles required, more emphatic pleas to move and run, to play hard, make sharp cuts, dive, pay attention, focus, learn, and correct. When the 2 hours were nearly over I took my last moment of attention to prophesy, “The way you practice will be the way you play!” I can almost feel you channeling the spirit of AI, not Artificial Intelligence (AI), Allen Iverson (AI). “Are we talking about, practice. Practice!” I thought this was about availability. Well, my love for basketball met my passion for availability when I considered my daughter and her teammates. How? Three Ways Basketball Strategies Are Like Availability Strategies:
Enterprise Availability Needs a PlanYour availability, specifically your disaster, planned maintenance, and outage recovery strategies, are only as good as those you create. Simply put, what is your plan for an outage (note clouds fail, servers crash, networks get saturated, and human error— enough said). Do you have a documented plan? Do you have identified owners and backups owners? Do you know your architecture and topology (what server does what, where is it located, what team does it belong to, what function does it serve, what business priorities are tied to it, and what SLO/SLA does it require)? Who are your key vendors, and what are their call down lists? What are your checkpoints, data protection plans, and backup strategies? And what are your test plans and validation plans for verification of this plan? Enterprise Availability Needs PracticeA good plan, check. Now what about practice. Implementing disaster recovery steps and unplanned outage strategies are a necessary component of every, every enterprise configuration. But, a strategy that is not rehearsed is not really a strategy. In that case it is simply a possible and proposed approach. It is more like a suggestion, rather than an actual plan of record. The second step is practice. Walk through the strategies of your plan. Rehearse maintenance timings. Restore backups and data. Validate assumptions and failure modes. Enterprise Availability Requires TestingA plan and a walkthrough, check. Now that you have two of the three let me go back to my daughter’s team. My parting words, as an “unofficial coach “ were as follows: “The way you practice will be the way you play!” Fast forward three days. The game is down to the final minutes. The team they are playing is athletically mismatched, and outsized just as they were last year when that year’s game was over by halftime. But this year, the undermanned and undersized team had clearly come in more prepared. What should have been an easy win now enters the final minute nearly tied. The home team, the opponent, begins a press— something my daughter’s team had prepared for, albeit haphazardly and lethargically, during that fateful practice. What ensued wasn’t pretty. Four unforced turnovers, two critical fouls during three-pointer attempts, a four to nothing run, and a bevy of frustrations culminating in a devastating one-point loss as time expired. My final point, how well are you practicing for your real outage, disaster, or planned maintenance? Do you practice with real data, real clients, and with a real sense of urgency? How often does your upper management check-in? Trust me, the presence of a boss in pressure-packed moments makes people do strange and unwise things! Does your sandbox and test system look like production? In a past life, I once worked with a customer who had different hardware, storage and Linux OS versions between prod and QA. When they went into prod with application updates, disaster struck hard. Do you have users and data, and jobs that run during your testing? What about actual disaster simulation? It’s a hard pill to swallow, testing a hard crash with potentially destructive consequences, recovery from offsite, and even harder to simulate simultaneous multi-point, multiple systems failures, but the unpracticed is often the weak point that turns a 2 hour planned maintenance into an eight-hour multi-team corporate disaster. The under-practiced or poorly practiced is the difference between a stunning victory for your strategy and team, or a crushing defeat and costly failure for team, vendors, enterprise, and customers. In basketball, the plan under fire will hold up only as good as the plan was practiced. When implementing a recovery and disaster plan a good plan and validation are key, but great practice is king. Contact a rep at SIOS to learn how our availability experts and products can help you with the plan, procedures, and practice. Visit back for a post on tests you should never avoid simulating. — Cassius Rhue, VP, Customer Experience Article reproduced from SIOS |

 EC2 Monitoring Best Practices: Using SIOS AppKeeper to Protect NGINX Webservers on Amazon EC2
EC2 Monitoring Best Practices: Using SIOS AppKeeper to Protect NGINX Webservers on Amazon EC2