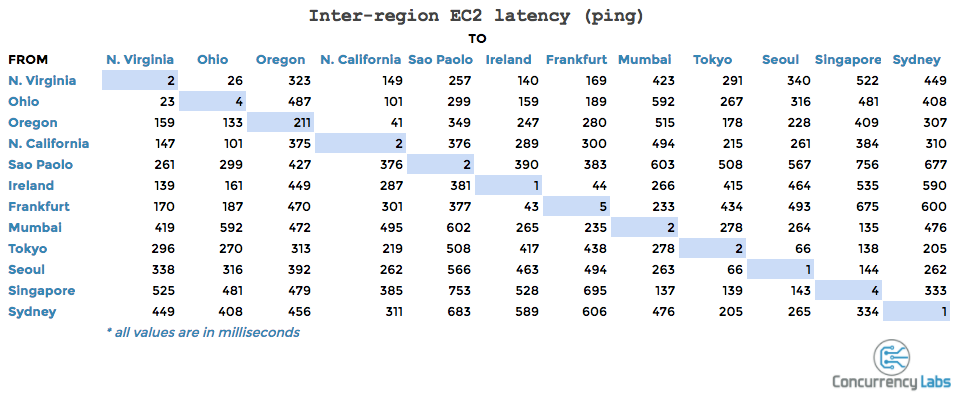
| August 2, 2020 |
Why is AWS EC2 Application Monitoring So Hard? |
| July 30, 2020 |
Planning is Key to Enterprise Availability (and to a Happy Marriage)
Planning is Key to Enterprise Availability (and to a Happy Marriage)Planning dates and getaways, fabulously romantic dinners are a great part of loving your spouse well. Seminars and workshops overflowing with tips for improving your relationship abound in nearly every area of the world. But, listen in on the training session provided by SIOS Technology Corp. Project Manager for Professional Services, Edmond Melkomian, and you’ll quickly learn that planning dinners and anniversary retreats aren’t the only way to love your spouse well. In a recent class on SIOS Protection Suite for Linux, Edmond shared three tips that help you love your spouse well in an enterprise world: plan, plan, plan. 1. “Plan to plan” your enterprise availability solution
In his course, Edmond Melkomian asked students to name the first thing you should do when deploying an enterprise solution. His answer, “Plan, plan, plan.” It seems obvious, but the first step is to start making the plan. A fairly decent start for a plan includes developing the details for each of the project phases, such as milestones, checkpoints, risks, risk mitigation and strategies, stakeholders, timelines, stakeholder communication plans. A decent plan will also include details about kickoff, sign-off and closure, and resources (staffing, management, legal/contracts). Plan to create, review, modify, and update your plan throughout the solution lifecycle. 2. Plan what to deploy for enterprise availabilityPlan what to deploy. It is likely that a large portion of your enterprise infrastructure exists beyond the realm of the current team’s lifespan with your company. As you migrate to the cloud, or update your availability strategy, it is worth the time and effort to make a plan regarding what to deploy. Focus your plan on ensuring that you deploy redundancy at all critical components, network, compute, storage, power, cooling, and applications. All data centers and cloud providers typically ensure cooling, power, and network redundancy to start. A number of firms offer architectural teams, cloud solution providers, availability experts, application architects, and migration specialists who help teams discover critical and sometimes hidden dependencies as well as high risk areas vulnerable to Single Points of Failure (SPOF’s). This investigative work will feed into your plan of what to deploy and/or update in your availability strategy. Plan on reviewing what you need to deploy. 3. Plan to keep a QA/pre-production cluster for reliable availabilityWhen I was in the SIOS Technology Corp. development team, I’ll never forget a Friday night call with a long time, but frantic customer. Earlier in the month a frequent customer unsuccessfully deployed a new software solution into a production environment. The result was a massive failure. He called our 800 number at 4:30pm (EST) on Friday. Why do I recall that exact time? Friday was date night. My wife and I had dinner plans, a babysitter for the six girls on standby (by the hour), and hopes for a romantic and relaxing evening. I was just about to head out for the day when the phone rang. After a tense first hour, we were back up and running. This unfortunate episode could have been avoided or mitigated by keeping a UAT or QA system on hand. As Harrison Howell, the Software Engineer for Customer Experience at SIOS Technology Corp. noted in his blog 6-common-cloud-migration-challenges the limits of on-prem are no longer the same limits. Customers coming from an on-prem system need to remember that resources are no longer a limiting factor. In the cloud, systems can be effortlessly copied and run in isolation of production, something not trivial on-premises. On-demand access to IT resources allows UAT of HA and DR to expand beyond “shut down the primary node”. Networks can be sabotaged, kernels can be panicked, even databases can be corrupted and none of this will impact production! Identifying and testing these scenarios improves HA and DR posture. Plan on deploying and keeping a UAT system for HA and DR testing. As Harrison mentions, “identifying and testing [issues]” “improves [your overall] HA and DR posture,” and that improves your chances of a successful date night. 4. Plan regular maintenance and updates (including documentation)Lastly, plan times for regular maintenance and updates to maintain Enterprise Availability. Your enterprise needs to remain highly available to remain highly profitable and successful. Environments don’t remain stagnant, and patches, security updates, expansion, and general maintenance are a regular occurrence from inception to retirement. Creating a plan for how and when you will incorporate updates and maintenance into your enterprise will ensure that you are not only kept up to date, but that you minimize risks and downtime while doing it. Be sure to include in your plan the use of a test system. Develop a planned routine and process for validating patches, kernel and OS updates, and security software, and don’t forget to update the project documentation and future plans as you go and grow. If you can remember to plan for a highly redundant, highly reliable and highly available system upfront, plan to keep a QA/Pre-production cluster after Go-Live, and plan for regular maintenance and updates you will also be able to keep your plans with your spouse for date night. And not just date night, but you’ll also be able to keep your night’s free from 3am wake up calls due to down production systems. This is my tip for loving your spouse well. I love my wife and so I help customers deploy SIOS Technology Corp.’s DataKeeper Cluster Edition and SIOS Protection Suite for Windows and Linux products as a part of a highly available enterprise protection solution. Contact SIOS. — Cassius Rhue, VP, Customer Experience Article reproduced with permission from SIOS
|
| July 22, 2020 |
How to Combine Backup, Replication and High Availability Clustering
Backup, replication, and high availability (HA) clustering are fundamental parts of IT risk management, and they are as indispensable as the wheels on a car. Replication is also essential to IT data protection. Backup and HA Cluster Environments Are Not Mutually ExclusiveWhile backup, replication, and failover are all important, there are key distinctions among them that need to be understood to ensure they are applied properly. For example, while you can use replication to maintain a continuously up-to-date copy of data, without considering it in the larger data protection environment, you will also copy problem data (such as virus-infected data). In such cases, a backup is essential to bring the data back to the last known good point. By performing replication, you can access the image replicated immediately before the system failure (= RTO / RTO is superior) in a way that simply storing data by generation and supporting it in an eDiscovery type model cannot. Therefore, SIOS Protection Suite includes both SIOS LifeKeeper clustering software and DataKeeper replication software. SIOS LifeKeeper is an HA failover cluster product that monitors application health and orchestrates application failover and DataKeeper is block-based storage replication software. However, just because it is an HA cluster does not mean that backup is unnecessary. Consider the precautions and points to note when backing up in an HA cluster environment using SIOS Protection Suite. Five Points of Backup in a High Availability Clustering EnvironmentConsider the following five points as the target of backup acquisition:
Backup the OSTo back up the OS it is common to use a standard OS utility or third-party backup software. However, since there is no special consideration for the high availability environment, we will not cover it here. Backup the SIOS Protection Suite Clustering SoftwareSIOS Protection Suite includes SIOS LifeKeeper / DataKeeper program can also be obtained with the OS standard utility or third-party backup software, but if the program disappears due to a disk failure etc. without intentionally backing it up, you need to reinstall it. There will probably be some people who think about the dichotomy of doing so. Backup the SIOS Protection Suite Configuration InformationSIOS LifeKeeper comes with a simple command called lkbackup that enables you to backup the configuration information. lkbackup can be run on SIOS LifeKeeper and related resources and will not impact running services. This command can be executed in the following three main cases.
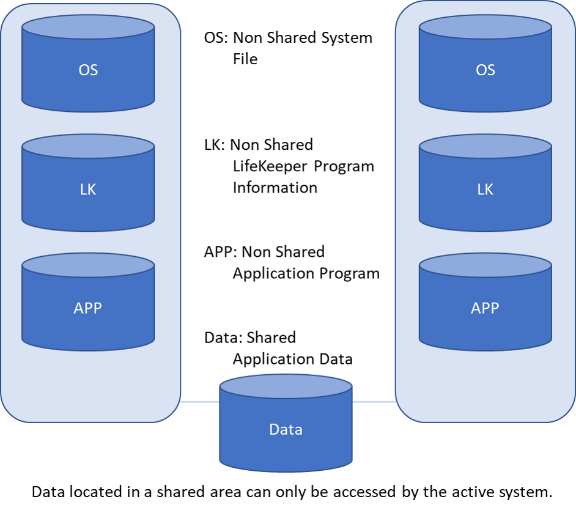
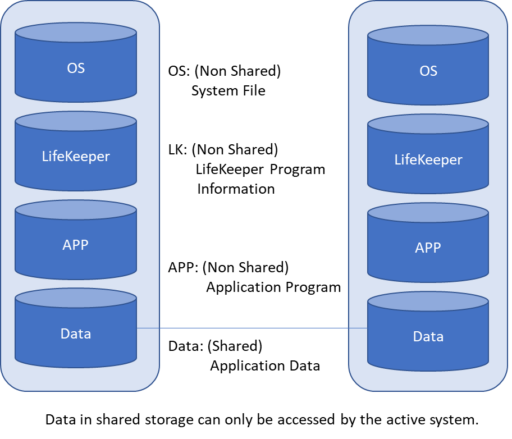
If you back up the configuration information with lkbackup, even if the configuration information disappears due to a disk failure or if the configuration information is corrupted due to an operation mistake, etc.) you can quickly return to the original operational state. Backup Operational ProgramsAlthough backing up operation programs refers to backing up the business applications being protected in your HA cluster, it is possible to create and restore a backup image using the OS standard utility or third-party backup software as in 1. and 2 above. Backup Business Application DataIn an HA cluster environment, shared storage that can be accessed by both active and standby servers is provided. During normal operation, the shared storage is used by the active cluster node. Application data (for example, database data) is usually storage in this shared storage, but the following points should be kept in mind when backing up this storage. For shared storage configurationWhen acquiring a backup of the data located in a SANless cluster configuration with storage shared by both the active cluster node and the standby system, the data can only be accessed from the active system (the standby system cannot access the data). As a result, the backup is also active. In this case, ensure that there is sufficient processing power to handle a failover and backup restore scenario.
For data replication configurationIn the case of the data replication configuration, the backup from the operating system is the basic, but by temporarily stopping the mirroring and releasing the lock, the backup can also be executed on the standby system side. However, in this case, the data is temporarily out of sync.
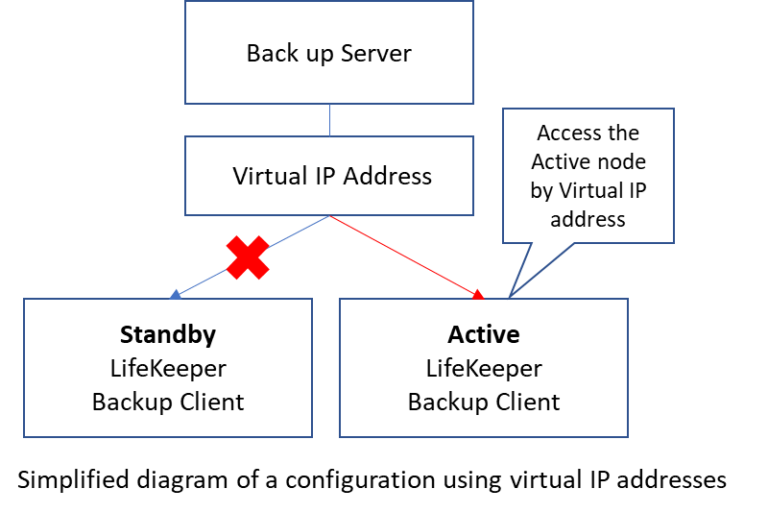
Backing up a cluster node from an external backup serverTo perform a cluster node backup from an external backup server, use either the virtual or real IP address of the cluster node. The points to note in each case are as follows. Backing up using the virtual IP address of a cluster nodeFrom the backup server’s perspective, backup is executed to the node indicated by the virtual IP address of LifeKeeper. In this case, the backup server does not need to be aware of which node is the active node.
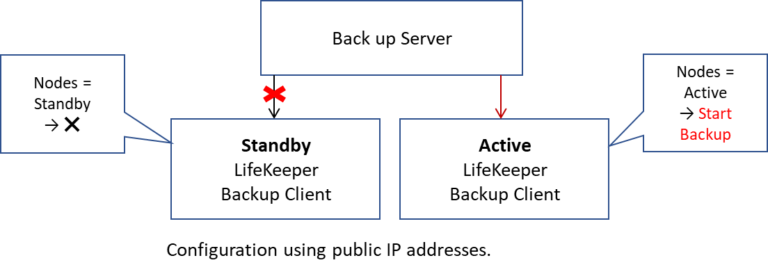
Backing up using the real IP address of the cluster nodeFrom the backup server’s perspective, the backup is performed to the real IP address without using the virtual IP address of LifeKeeper. Since the shared storage cannot be accessed from the standby cluster node, the backup server and client must check which node is the active node.
Combining backup, replication, and failover clustering in a well-tested and verified configuration backup is indispensable. Using perform sufficient operation verification in advance on the user side. Reproduced with permission from SIOS |
| July 18, 2020 |
High Availability Software is Insurance Against SAP Downtime
|
| July 17, 2020 |
6 Common Cloud Migration Challenges |

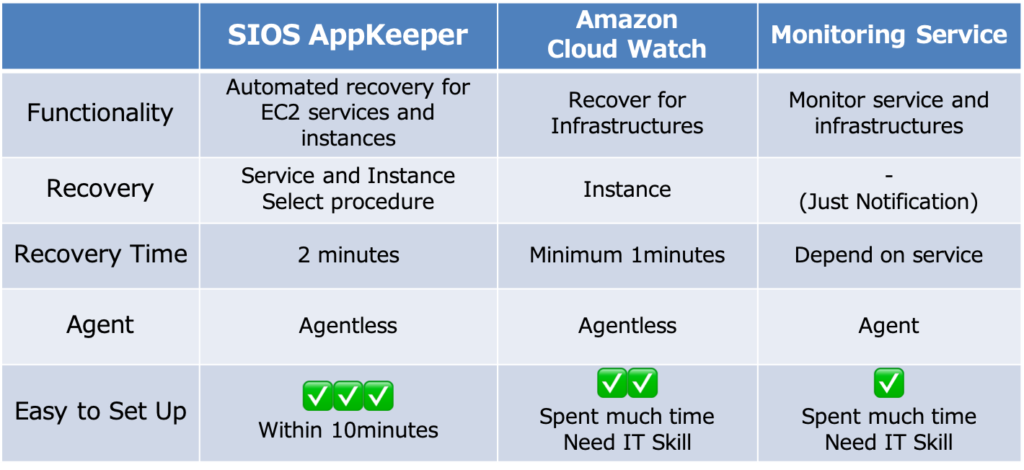
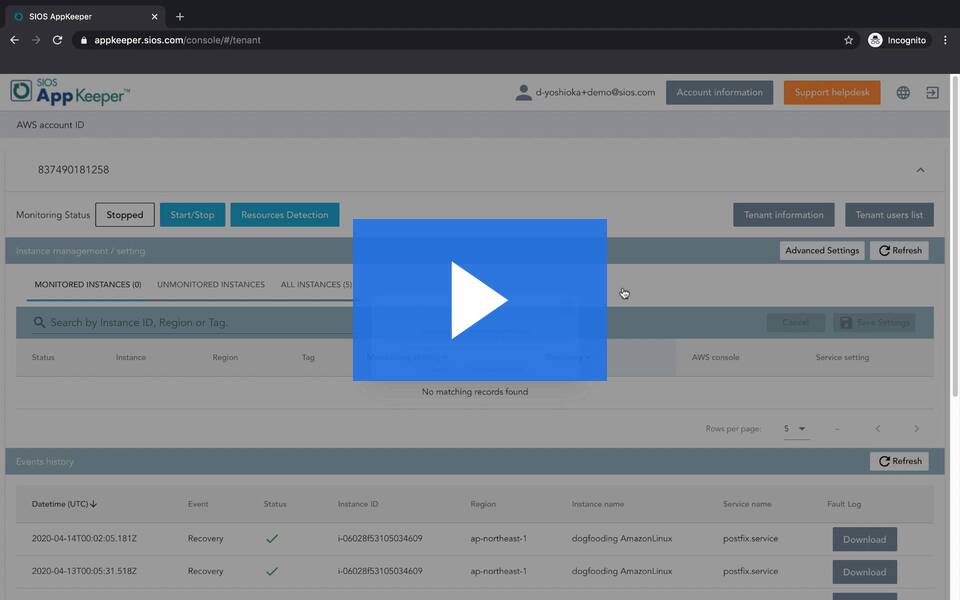



 High Availability Software is Insurance Against SAP Downtime
High Availability Software is Insurance Against SAP Downtime