| December 11, 2020 |
Using Datadog for Amazon EC2 Monitoring? Pair with SIOS AppKeeper for Automated Remediation |


| {
“instanceId”: “{{ EC2 Instance ID}}”, “name”: “nginx” } |
Custom Headers: Check the box and enter the following
| { “Content-type”: “application/json”, “accept”: “application/json”, “appkeeper-integration-token”: “{{ Get AppKeeper external integration tokens The tokens obtained in }}” } |
When you are done, press “Save.”
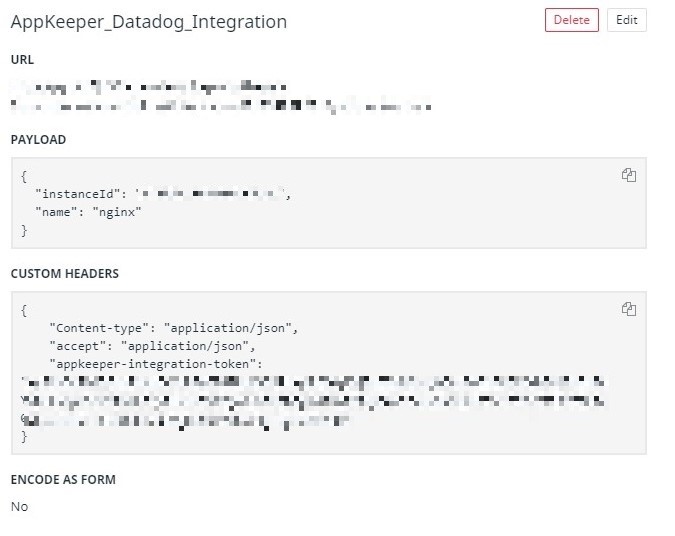
Step Eight: Connecting AppKeeper to the Synthetics test
Next, I had to configure AppKeeper (the registered Webhooks integration) to be called when an alert of the Synthetics monitoring occurs.
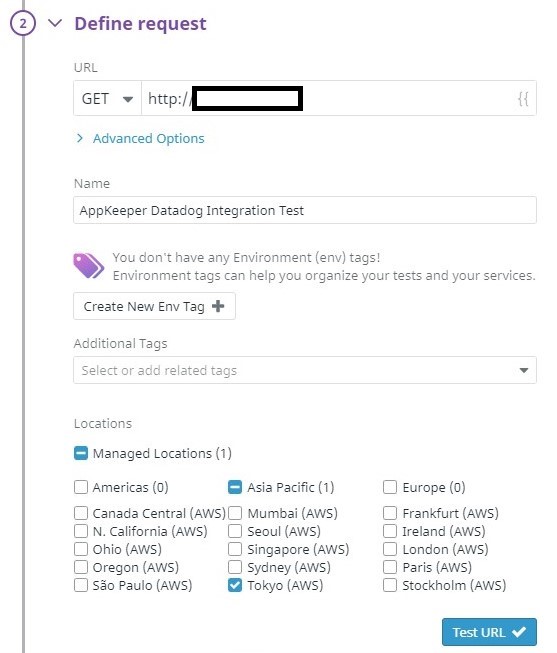
Open the test case that you set up in “Configuring the Synthetic Monitoring with Datadog” from UX Monitoring > Synthetic Tests in the menu.
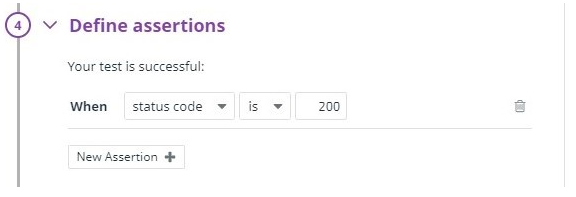
Select “Edit test details” from the top-right gearbox and enter the following values in the “5. Notify Your Team” box to save the changes.
| @webhook-{{ Name of Webhook integration in Datadog }} |
※ You can set “renotify if the monitor has not been resolved”. You can retry if AppKeeper fails to recover for the first time. It is not required for testing purposes, but we recommend you to set it to [10 minutes] (minimum interval).
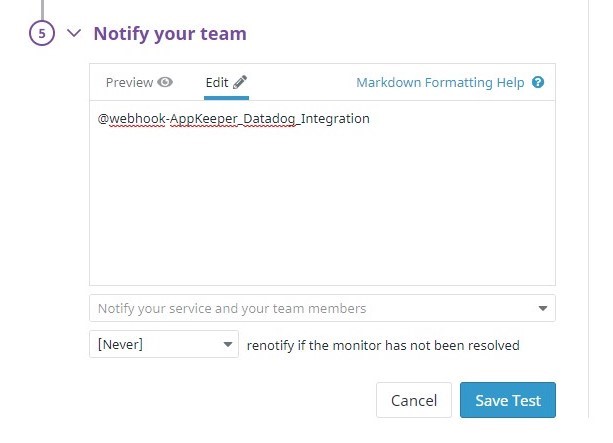
Setup is now complete.
Step Nine: Confirm the integration by running the test again
I then confirmed that AppKeeper would restore the webserver if Datadog detected it to be down.
Open the Synthetics monitoring test case you just set up from UX Monitoring > Synthetic Tests in Datadog.
Click “Resume Test” in the upper right corner and turn on the Synthetics monitoring.

Now Datadog will perform Synthetics monitoring at regular intervals.
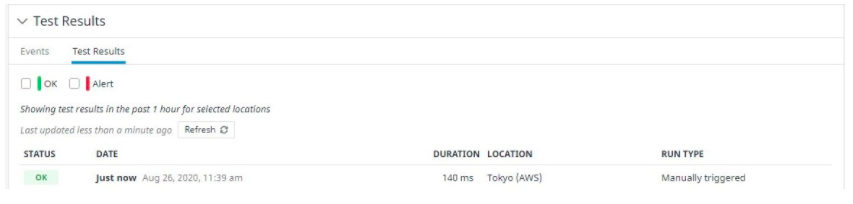
The Test Results show that the server is successfully accessed.
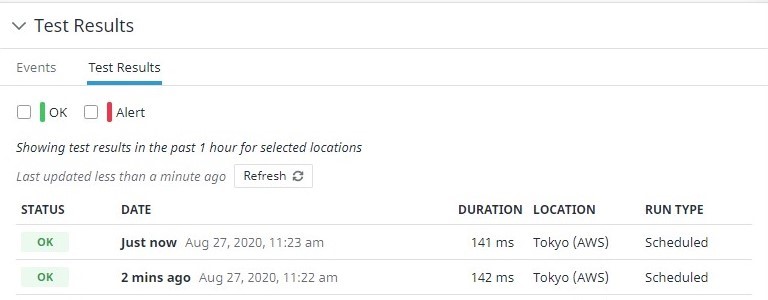
Next, I created a pseudo-failure of the web server to test AppKeeper’s automated remediation.
Since it is difficult to cause a real failure, I stopped the service and created a situation in which you cannot view the web page. To do this I connected to the EC2 instance where the Nginx server is installed using SSH and stopped Nginx.
| sudo systemctl stop nginx |
After a short wait, Datadog detected that the web server is no longer accessible.
The Synthetic Tests page in Datadog also shows that the test case has failed.
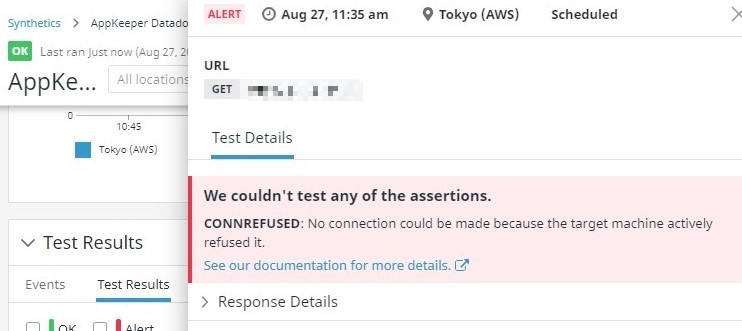
If the test case fails, Datadog will notify AppKeeper that the Synthetics monitoring has failed.
When AppKeeper receives the notification, it will automatically attempt to restart Nginx.
So, if you wait a little while, you see that Datadog’s Synthetics monitoring check will pass again.
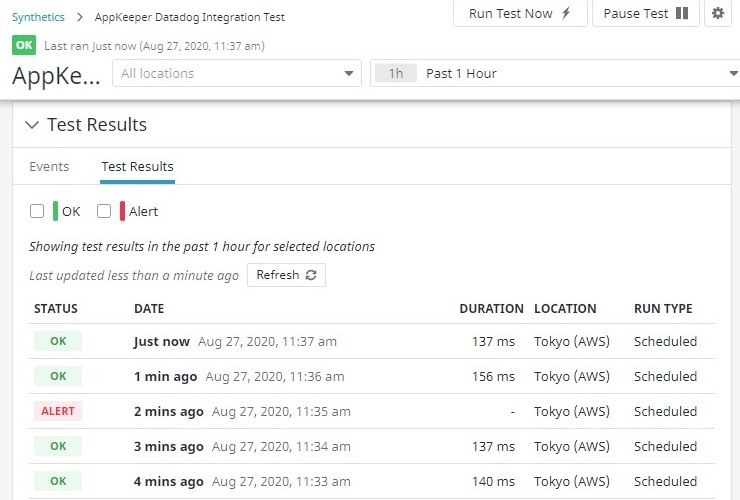
Also, if you log in to your AppKeeper dashboard, you’ll see that the recovery has been performed.

—
In this exercise I used a web server (Nginx) as an example to automate the process of detecting a failure with Datadog and restoring the service with AppKeeper.
Similar automation could be achieved by integrating Datadog with EventBridge and Lambda or by creating custom scripts.
However, if you frequently add target instances or restart a wide variety of services, the cost and complexity of maintaining EventBridge and Lambda or scripts will increase.
AppKeeper’s proven integration with Datadog and the ease with which you can add target instances to your application makes it easy to add automation to your DevOps environment to reduce your downtime.
If you are currently using Datadog and would like to try out AppKeeper’s Restart API, please first sign up for our 14-day free trial here (you can purchase a subscription once you have installed the free trial). Then click here to request a free trial. We’ll walk you through the process and provide you with a free evaluation token to help you get started.
Thank you. I hope you will take this opportunity to learn more about SIOS AppKeeper, which provides automatic monitoring and recovery of applications running on EC2.
— Tatsuya Hirao on the SIOS Technology technical team.
Reproduced with permission from SIOS
5 Signs That It Will Take More Than A Blog Post To Fix Your High Availability

5 Signs That It Will Take More Than A Blog Post To Fix Your High Availability
The signs are there. The warning lights are flashing. In your gut, you can sense it. Maybe you can’t sleep. Your problems with high availability are deep. But, maybe you are not quite sure.
1. If you think your cloud SLA is all you need for high availability
Cloud solutions have provided great advancements in increased hardware availability and resilience. However, application high availability requires more than just selecting the right hypervisor or cloud provider. Your strategy for high availability cannot stop with the SLA provided by the cloud or a virtualization provider. As quoted by Wired, “The almost four-day Amazon outage of April 2011 did not breach Amazon’s EC2 SLA, which as a FAQ explains, “guarantees 99.95% availability of the service within a Region over a trailing 365 period.” In this DZone article, our own David Bermingham breaks down the differences between cloud SLAs and application availability in detail. If you want a highly available infrastructure, it must include monitoring, recovery, and resilience at the data and application layers as well.
2. If you are just using the high availability clustering that came with your open source operating system
If so, then chances are you didn’t select your database based on what was bundled with the OS, so why would you select your HA solution based on that criteria alone. Bundled tools go a long way in providing extra assurance, possibilities, and capabilities. However, despite the ease of access, bundled tools and OS clustering software are not always capable of meeting your SLA, RPO, RTO, and availability requirements. If your enterprise has a combination of Operating Systems, your team will likely need help navigating different tools and understanding how they integrate together. It’s kind of like choosing the hedge clippers and push reel mower left on the curb to shape “Azalea” on the 13th hole par 5 (at Augusta). Both lawn mowers are designed to cut grass but how much time do you have? How are you going to handle the complexity? Which would you trust? Your strategy for high availability requires more than just considering the conveniences of what is bundled with the OS, otherwise, you’d be running MySQL instead of SAP HANA.
3. If you think that enterprise application licensing, such as SQL Enterprise or Oracle Enterprise, is the same thing as enterprise high availability
In addition to increased cost, many enterprise application licenses also increase the ability of the application to recover in some high availability scenarios. However, it is highly unlikely that your entire enterprise is based on a single application. Your high availability is going to require more than just a highly available database solution. You’ll need an enterprise grade application monitoring and recovery solution with a breadth of support for all of your applications and databases. In addition, you’ll need the ability to manage and replicate not just database data, but critical application and configuration data as well. Availability for a single database or a simple application is one thing – but HA for a complex, multipart application and supporting database is very different. More services, more parts that need to be coordinated, more complex architecture to orchestrate, more specific best practices to adhere to before, during and after failover/switchover. More than what your enterprise license paid for.
4. If your downtime is growing and your uptime is shrinking
The pace of life is ever increasing in many fields. When was the last time your team recovered from backup, manually restarted the applications that were deemed critical, or restarted a set of failed virtual machines or nodes? The pace of your outage events cannot continue to outpace sustainability, or your team’s ability to move beyond firefighting to fire prevention and fire proofing. “You can only run so hard so long (Carey Nieuwhof).” For some of you, you’ve been firefighting for too long, and your outages are becoming more common than your up-time.
5. If your first failover test was on the production server
A recent client remarked that it is simply impossible to test for every possible disaster scenario. As new software is created, deployed, updated, and patched the challenges in higher availability are increasing. But, your live, production data is not the place to find out what does not play well together. And while Go-Live and Post-Go-Live will always have their share of surprises, the inability to actually failover and run on the backup node should not be one of them.
Scouring blogs can provide you with helpful tips and insights to define, redefine, and improve your higher availability. But, if the warning signs are going off that you’ve traded true availability for some semblance of ‘just enough’, then it will take more than a blog post, or scouring every blog post in the availability world for that matter, to fix your HA.
– Cassius Rhue, Vice President, Customer Experience
Reproduced with permission from SIOS
9 Signs You Have an Application Availability Problem

APM Automation – The Missing Ingredient For Application Performance Monitoring Solutions

