| September 28, 2021 |
Deployment of a SQL Server Failover Cluster Instance on Huawei Cloud |

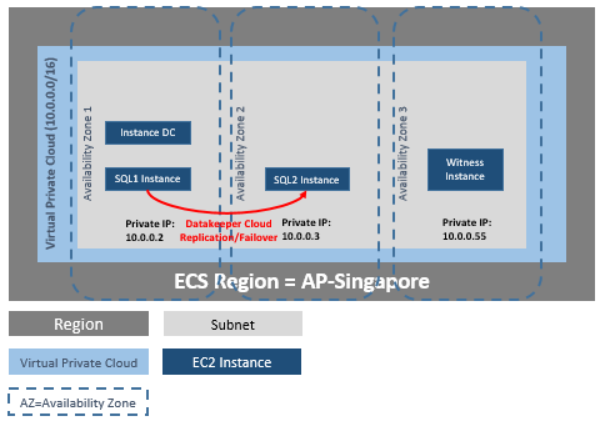
| Description | Requirement |
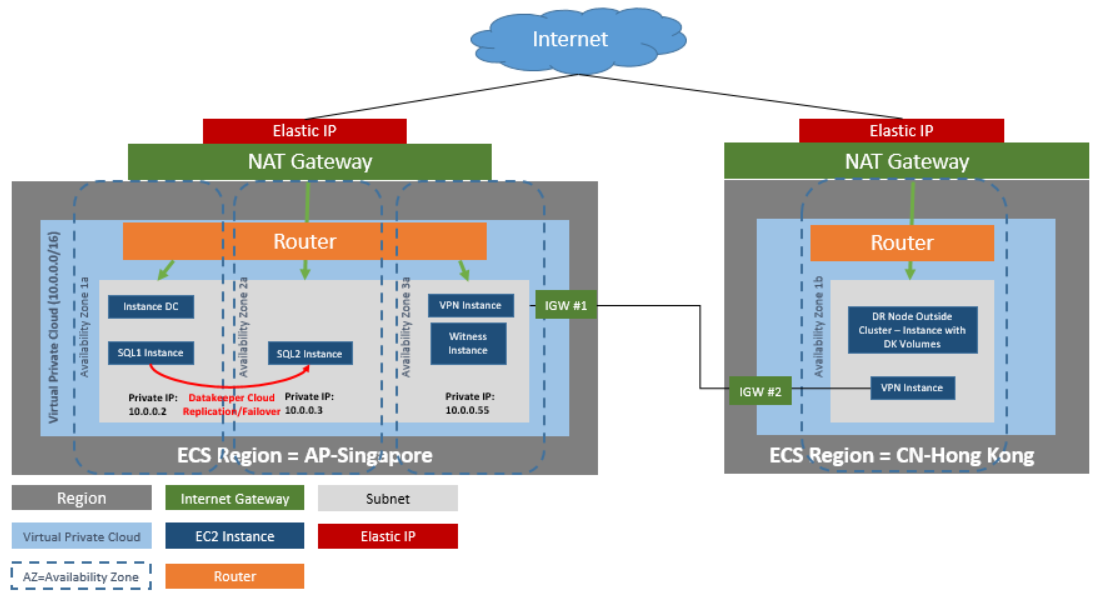
| Virtual Private Cloud | In a single region with three availability zones |
| Instance Type | Minimum recommended instance type: s3.large.2 |
| Operating System | See the DKCE Support Matrix |
| Elastic IP | One elastic IP address connected to the domain controller |
| Four instances | One domain controller instance, two SQL Server instances and one quorum/witness instance |
| Each SQL Server | ENI (Elastic Network Interface) with 4 IPs
· Primary ENI IP statically defined in Windows and used by DataKeeper Cluster Edition · Three IPs maintained by ECS while used by Windows Failover Clustering , DTC and SQLFC |
| Volumes | Three volumes (EBS and NTFS only)
· One primary volume (C drive) · Two additional volumes o One for Failover Clustering o One for MSDTC |
Release Notes
Before beginning, make sure you read the DataKeeper Cluster Edition Release Notes for the latest information. It is highly recommended that you read and understand the DataKeeper Cluster Edition Installation Guide.
Create a Virtual Private Cloud (VPC)
A virtual private cloud is the first object you create when using DataKeeper Cluster Edition.
*A virtual Private Cloud (VPC) is an isolated private cloud consisting of a configurable pool of shared computing resources in a public cloud.
- Using the email address and password specified when signing up for Huawei Cloud, sign in to the Huawei Cloud Management Console.
- From the Services dropdown, select Virtual Private Cloud.
- On the right side of the screen, click on Create VPC and select the region that you want to use.
- Input the name that you want to use for the VPC
- Define your virtual private cloud subnet by entering your CIDR (Classless Inter-Domain Routing) as described below
- Input the subnet name, then click Create Now.
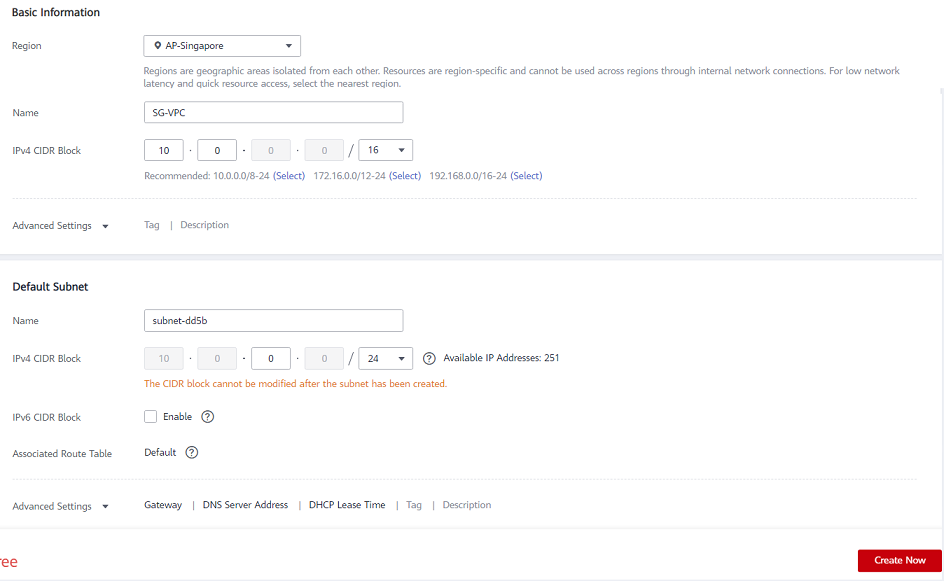
*A Route Table will automatically be created with a “main” association to the new VPC. You can use it later or create another Route Table.
*HELPFUL LINK:
Huawei’s Creating a Virtual Private Cloud (VPC)
Launch an Instance
The following walks you through launching an instance into your subnet. You will want to launch two instances into one availability zone, one for your domain controller instance and one for your SQL instance. Then you will launch another SQL instance into another availability zone and a quorum witness instance into yet another availability zone.
*HELPFUL LINKS:
Huawei Cloud ECS Instances
- Using the email address and password specified when signing up for Huawei Cloud, sign in to the Huawei Cloud Management Console.
- From the Service List dropdown, select Elastic Cloud Server.

- Select Buy ECS button and choose the Billing Mode, Region and AZ (Availability Zone) to deploy the Instance
- Select your Instance Type. (Note:Select s3.large.2 or larger.).
- Choose an Image. Under Public Image, select the Windows Server 2019 Datacenter 64bit English image
- For Configure Network, select your VPC.
- For Subnet, select an Subnet that you want to use, select Manually-specified IP address and input the IP address that you want to use
- Select the Security Group to use or Edit and select an existing one.
- Assign an EIPif you need the ECS instance to access the internet
- Click Configure Advanced Settings and provide a name for the ECS, use Password for Login Mode and provide the secure password for Administrator login
- Click Configure Now on Advanced Options Add a Tag to name your instance and Click on Confirm
- Perform final review of the Instance and click on Submit.
*IMPORTANT: Make a note of this initial administrator password. It will be needed to log on to your instance.
Repeat the above steps for all instances.
Connect to Instances
You can connect to your domain controller instance via Remote Login from the ECS pane.
Login as administrator and enter your administrator password.
*BEST PRACTICE: Once logged on, it is best practice to change your password.
Configure the Domain Controller Instance
Now that the instances have been created, we started with setting up the Domain Service instance.
This guide is not a tutorial on how to set up an Active Domain server instance. We recommend reading articles on how to set up and configure an Active Directory server. It is very important to understand that even though the instance is running in a Huawei cloud, this is a regular installation of Active Directory.
Static IP Addresses
Configure Static IP Addresses for your Instances
- Connect to your domain controller instance.
- Click Start/ Control Panel.
- Click Network and Sharing Center.
- Select your network interface.
- Click Properties.
- Click Internet Protocol Version 4 (TCP/IPv4), then Properties.
- Obtain your current IPv4 address, default gateway and DNS server for the network interface from Amazon.
- In the Internet Protocol Version 4 (TCP/IPv4) Properties dialog box, under Use the following IP address, enter your IPv4 address.
- In the Subnet mask box, type the subnet mask associated with your virtual private cloud subnet.
- In the Default Gateway box, type the IP address of the default gateway and then click OK.
- For the Preferred DNS Server, enter the Primary IP Address of Your Domain Controller(ex. 15.0.1.72).
- Click Okay, then select Close. Exit Network and Sharing Center.
- Repeat the above steps on your other instances.
Join the Two SQL Instances and the Witness Instance to Domain
*Before attempting to join a domain make these network adjustments. On your network adapter, Add/Change the Preferred DNS server to the new Domain Controller address and its DNS server. Use ipconfig /flushdns to refresh the DNS search list after this change. Do this before attempting to join the Domain.
*Ensure that Core Networking and File and Printer Sharing options are permitted in Windows Firewall.
- On each instance, click Start, then right-click Computer and select Properties.
- On the far right, select Change Settings.
- Click on Change.
- Enter a new Computer Name.
- Select Domain.
- Enter Domain Name– (ex. docs.huawei.com).
- Click Apply.
*Use Control Panel to make sure all instances are using the correct time zone for your location.
*BEST PRACTICE: It is recommend that the System Page File is set to system managed (not automatic) and to always use the C: drive.
Control Panel > Advanced system settings > Performance > Settings > Advanced > Virtual Memory. Select System managed size, Volume C: only, then select Set to save.
Assign Secondary Private IPs to the Two SQL Instances
In addition to the Primary IP, you will need to add three additional IPs (Secondary IPs) to the elastic network interface for each SQL instance.
- From the Service List dropdown, select Elastic Cloud Server.
- Click the instance for which you want to add secondary private IP addresses.
- Select NICs > Manage Virtual IP Address.
- Click on Assign Virtual IP address and select Manual enter an IP address that is within the subnet range for the instance (ex. For 15.0.1.25, enter 15.0.1.26). Click Ok.
- Click on the More dropdown on the IP address row, and select Bind to Server, select the server to bind the IP address to, and the NIC card.
- Click OK to save your work.
- Perform the above on both SQL Instances.
*HELPFUL LINKS:
Managing Virtual IP Addresses
Binding a Virtual IP Address to an EIP or ECS
Create and Attach Volumes
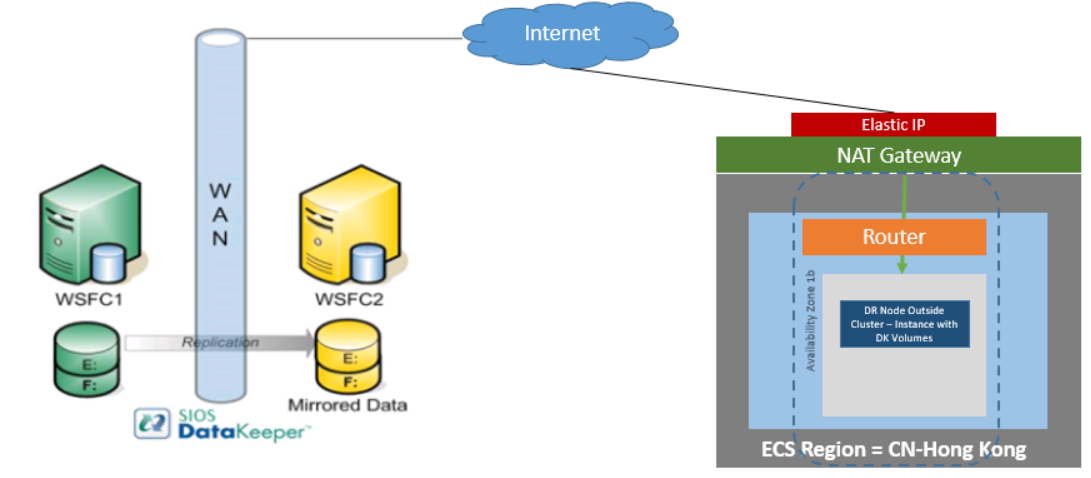
DataKeeper is a block-level volume replication solution and requires that each node in the cluster have additional volume(s) (other than the system drive) that are the same size and same drive letters. Please review Volume Considerations for additional information regarding storage requirements.
Create Volumes
Create two volumes in each availability zone for each SQL server instance, a total of four volumes.
- From the Service List dropdown, select Elastic Cloud Server.
- Click the instance for which you want to manage
- Go to the Disks tab
- Click Add Disk to add a new volume of your choice and size, make sure you select the volume in the same AZ as the SQL server that you intend to attach it to
- Select the check box to agree to the SLA and Submit
- Click Back to Server Console
- Attach the disk if necessary to the SQL instance
- Do this for all four volumes.
*HELPFUL LINKS:
Elastic Volume Service
Configure the Cluster
Prior to installing DataKeeper Cluster Edition, it is important to have Windows Server configured as a cluster using either a node majority quorum (if there is an odd number of nodes) or a node and file share majority quorum (if there is an even number of nodes). Consult the Microsoft documentation on clustering in addition to this topic for step-by-step instructions. Note: Microsoft released a hotfix for Windows 2008R2 that allows disabling of a node’s vote which may help achieve a higher level of availability in certain multi-site cluster configurations.
Add Failover Clustering
Add the Failover Clustering feature to both SQL instances.
- Launch Server Manager.
- Select Features in the left pane and click Add Features in the Features This starts the Add Features Wizard.
- Select Failover Clustering.
- Select Install.
Validate a Configuration
- Open Failover Cluster Manager.
- Select Failover Cluster Manager, select Validate a Configuration.
- Click Next, then add your two SQL instances.
Note: To search, select Browse, then click on Advanced and Find Now. This will list available instances.
- Click Next.
- Select Run Only Tests I Select and click Next.
- In the Test Selection screen, deselect Storage and click Next.
- At the resulting confirmation screen, click Next.
- Review Validation Summary Report then click Finish.
Create Cluster
- In Failover Cluster Manager, click on Create a Cluster then click Next.
- Enter your two SQL instances.
- On the Validation Warning page, select No then click Next.
- On the Access Point for Administering the Cluster page, enter a unique name for your WSFC Cluster. Then enter the Failover Clustering IP address for each node involved in the cluster. This is the first of the three secondary IP addresses added previously to each instance.
- IMPORTANT!Uncheck the “Add all available storage to the cluster” checkbox. DataKeeper mirrored drives must not be managed natively by the cluster. They will be managed as DataKeeper Volumes.
- Click Next on the Confirmation
- On Summary page, review any warnings then select Finish.
Configure Quorum/Witness
- Create a folder on your quorum/witness instance (witness).
- Share the folder.
- Right-click folder and select Share With / Specific People….
- From the dropdown, select Everyone and click Add.
- Under Permission Level, select Read/Write.
- Click Share, then Done. (Make note of the path of this file share to be used below.)
- In Failover Cluster Manager, right-click cluster and choose More Actions and Configure Cluster Quorum Settings. Click Next.
- On the Select Quorum Configuration, choose Node and File Share Majority and click Next.
- On the Configure File Share Witness screen, enter the path to the file share previously created and click Next.
- On the Confirmation page, click Next.
- On the Summary page, click Finish.
Install and Configure DataKeeper
After the basic cluster is configured but prior to any cluster resources being created, install and license DataKeeper Cluster Edition on all cluster nodes. See the DataKeeper Cluster Edition Installation Guide for detailed instructions.
- Run DataKeeper setup to install DataKeeper Cluster Edition on both SQL instances.
- Enter your license key and reboot when prompted.
- Launch the DataKeeper GUI and connect to server.
*Note: The domain or server account used must be added to the Local System Administrators Group. The account must have administrator privileges on each server that DataKeeper is installed on. Refer to DataKeeper Service Log On ID and Password Selection for additional information.
- Right click on Jobs and connect to both SQL servers.
- Create a Job for each mirror you will create. One for your DTC resource, and one for your SQL resource..
- When asked if you would like to auto-register the volume as a cluster volume, select Yes.
*Note: If installing DataKeeper Cluster Edition on Windows “Core” (GUI-less Windows), make sure to read Installing and Using DataKeeper on Windows 2008R2/2012 Server Core Platforms for detailed instructions.
Configure MSDTC
- For Windows Server 2012 and 2016, in the Failover Cluster Manager GUI, select Roles, then select Configure Role.
- Select Distributed Transaction Coordinator (DTC), and click Next.
*For Windows Server 2008, in the Failover Cluster Manager GUI, select Services and Applications, then select Configure a Service or Application and click Next.
- On the Client Access Point screen, enter a name, then enter the MSDTC IP address for each node involved in the cluster. This is the second of the three secondary IP addresses added previously to each instance. Click Next.
- Select the MSDTC volume and click Next.
- On the Confirmation page, click Next.
- Once the Summary page displays, click Finish.
Install SQL on the First SQL Instance
- On the domain controller server create a folder and share it..
- For example “TEMPSHARE” with Everyone permission.
- Create a sub folder “SQL” and copy the SQL .iso installer into that sub folder.
- On the SQL server, create a network drive and attach it to the shared folder on the domain controller.
- . For example “net use S: \\\TEMPSHARE
- On the SQL server the S: drive will appear. CD to the SQL folder and find the SQL .iso installer. Right click on the .iso file and select Mount. The setup.exe installer will appear with the SQL .iso installer.
F:\>Setup /SkipRules=Cluster_VerifyForErrors /Action=InstallFailoverCluster
- On Setup Support Rules, click OK.
- On the Product Key dialog, enter your product key and click Next.
- On the License Terms dialog, accept the license agreement and click Next.
- On the Product Updates dialog, click Next.
- On the Setup Support Files dialog, click Install.
- On the Setup Support Rules dialog, you will receive a warning. Click Next, ignoring this message, since it is expected in a multi-site or non-shared storage cluster.
- Verify Cluster Node Configuration and click Next.
- Configure your Cluster Network by adding the “third” secondary IP address for your SQL instance and click Next. Click Yes to proceed with multi-subnet configuration.
- Enter passwords for service accounts and click Next.
- On the Error Reporting dialog, click Next.
- On the Add Node Rules dialog, skipped operation warnings can be ignored. Click Next.
- Verify features and click Install.
- Click Close to complete the installation process.
Install SQL on the Second SQL Instance
Installing the second SQL instance is similar to the first one.
- On the SQL server, create a network drive and attach it to the shared folder on the domain controller as explained above for the first SQL server.
- Once the .iso installer is mounted, run SQL setup once again from the command line in order to skip the Validate Open a Command window, browse to your SQL install directory and type the following command:
Setup /SkipRules=Cluster_VerifyForErrors /Action=AddNode /INSTANCENAME=”MSSQLSERVER”
(Note: This assumes you installed the default instance on the first node)
- On Setup Support Rules, click OK.
- On the Product Key dialog, enter your product key and click Next.
- On the License Terms dialog, accept the license agreement and click Next.
- On the Product Updates dialog, click Next.
- On the Setup Support Files dialog, click Install.
- On the Setup Support Rules dialog, you will receive a warning. Click Next, ignoring this message, since it is expected in a multi-site or non-shared storage cluster.
- Verify Cluster Node Configuration and click Next.
- Configure your Cluster Network by adding the “third” secondary IP address for your SQL Instance and click Next. Click Yes to proceed with multi-subnet configuration.
- Enter passwords for service accounts and click Next.
- On the Error Reporting dialog, click Next.
- On the Add Node Rules dialog, skipped operation warnings can be ignored. Click Next.
- Verify features and click Install.
- Click Close to complete the installation process.
Common Cluster Configuration
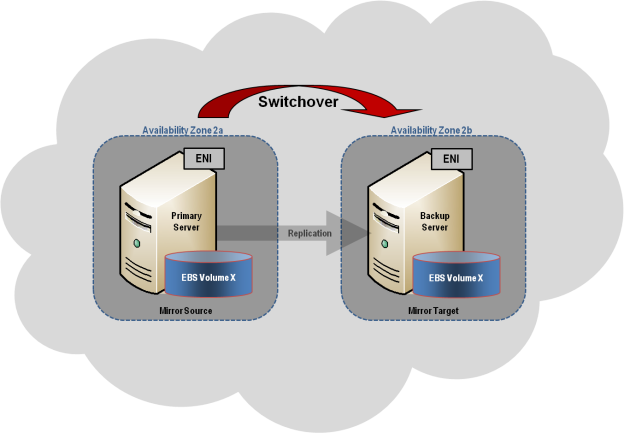
This section describes a common 2-node replicated cluster configuration.
- The initial configuration must be done from the DataKeeper UI running on one of the cluster nodes. If it is not possible to run the DataKeeper UI on a cluster node, such as when running DataKeeper on a Windows Core only server, install the DataKeeper UI on any computer running Windows XP or higher and follow the instruction in the Core Only section for creating a mirror and registering the cluster resources via the command line.
- Once the DataKeeper UI is running, connect to each of the nodes in the cluster.
- Create a Job using the DataKeeper UI. This process creates a mirror and adds the DataKeeper Volume resource to the Available Storage.
!IMPORTANT: Make sure that Virtual Network Names for NIC connections are identical on all cluster nodes.
- If additional mirrors are required, you can Add a Mirror to a Job.
- With the DataKeeper Volume(s)now in Available Storage, you are able to create cluster resources (SQL, File Server, etc.) in the same way as if there were a shared disk resource in the cluster. Refer to Microsoft documentation for additional information in addition to the above for step-by-step cluster configuration instructions.
Connectivity to the cluster (virtual) IPs
In addition to the Primary IP and secondary IP, you will also need to configure the virtual IP addresses in the Huawei Cloud so that they can be routed to the active node.
- From the Service List dropdown, select Elastic Cloud Server.
- Click on one of the SQL instance for which you want to add cluster virtual IP address (one for MSDTC, one for SQL Failover Cluster)
- Select NICs > Manage Virtual IP Address.
- Click on Assign Virtual IP address and select Manual enter an IP address that is within the subnet range for the instance (ex. For 15.0.1.25, enter 15.0.1.26). Click Ok.
- Click on the More dropdown on the IP address row, and select Bind to Server, select both the server to bind the IP address to, and the NIC card.
- Use the same steps 4. and 5 for the MSDTC and SQLFC virtual IPs
- Click OKto save your work.
Management
Once a DataKeeper volume is registered with Windows Server Failover Clustering, all of the management of that volume will be done through the Windows Server Failover Clustering interface. All of the management functions normally available in DataKeeper will be disabled on any volume that is under cluster control. Instead, the DataKeeper Volume cluster resource will control the mirror direction, so when a DataKeeper Volume comes online on a node, that node becomes the source of the mirror. The properties of the DataKeeper Volume cluster resource also display basic mirroring information such as the source, target, type and state of the mirror.
Troubleshooting
Use the following resources to help troubleshoot issues:
- Troubleshooting issues section
- For customers with a support contract – http://us.sios.com/support/overview/
- For evaluation customers only – Pre-sales support
Additional Resources:
Step-by-Step: Configuring a 2-Node Multi-Site Cluster on Windows Server 2008 R2 – Part 1 — http://clusteringformeremortals.com/2009/09/15/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93-part-1/
Step-by-Step: Configuring a 2-Node Multi-Site Cluster on Windows Server 2008 R2 – Part 3 — http://clusteringformeremortals.com/2009/10/07/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93-part-3/
Beginning Well is Great, But Maintaining Uptime Takes Vigilance

Understanding and Avoiding Split Brain Scenarios

High Availability Architecture and Best Practices

12 Questions to Uncomplicate Your Cloud Migration

12 Questions to Uncomplicate Your Cloud Migration
Cloud migration best practices
The “cloud is becoming more complicated,” it was the first statement in an hour-long webinar detailing the changes and opportunities with the boom in cloud computing and cloud migration. The presenter continued with an outline of cloud related things that traditional IT is now facing in their journey to AWS, Azure, GCP or other providers.
There were nine areas that surfaced as complications in the traditional transition to cloud:
- Definitions
- Pricing
- Networking
- Security
- Users, Roles, and Profiles
- Applications and Licensing
- Services and Support
- Availability
- Backups
As VP of Customer Experience for SIOS Technology Corp I’ve seen how the following areas can impact a transition to cloud. To mitigate these complications, consumers are turning to managed service providers, cloud solution architects, contractors and consultants, and a bevy of related services, guides, blog posts and related articles. Often in the process of turning to outside or outsourced resources the complications to cloud are not entirely removed. Instead, companies and the teams they have employed to assist or to transition them to cloud still encounter roadblocks, speed bumps, hiccups and setbacks.
Most often these complications and slowdowns in migrating to the cloud come from twelve unanswered questions:
- What are our goals for moving to the cloud?
- What is your current on-premise architecture? Do you have a document, list, flow chart, or cookbook?
- Are all of your application, database, availability and related vendors supported on your target cloud provider platform?
- What are your current on-premises risks and limitations? What applications are unprotected, what are the most common issues faced on-premises?
- Who is responsible for the cloud architecture and design? How will this architecture and design account for your current definitions and the definitions of the cloud provider?
- Who are the key stakeholders, and what are their milestones, business drivers, and deadlines for the business project?
- Have you shared your project plan and milestones with your vendors?
- What are the current processes, governance, and business requirements?
- What is the migration budget and does it include staff augmentation, training, and services? What are your estimates for ongoing maintenance, licensing, and operating expenses?
- What are your team’s existing skills and responsibilities?
- Who will be responsible for updating governance, processes, new cloud models, and the various traditional roles and responsibilities?
- What are the applications, services, or functions that will move from IaaS to SaaS models?
Know Your Goals for the Cloud
So, how will answering these twelve questions will improve your cloud migration. As you can see from the questions, understanding your goals for the cloud is the first, and most important step. It is nearly universally accepted that “a cloud service provider such as AWS, Azure, or Google can provide the servers, storage, and communications resources that a particular application will require,” but for many customers, this only eliminates “he need for computer hardware and personnel to manage that hardware.” Because of this fact, often customers are focused on equipment or data center consolidation or reduction, without considering that there are additional cloud opportunities and gaps that they still need to consider. For example, cloud does eliminate management of hardware, but it “does not eliminate all the needs that an application and its dependencies will have for monitoring and recovery,” so if your goal was to get all your availability from the cloud, you may not reach that goal, or it may require more than just moving on premises to an IaaS model. Knowing your goals will go a long way in helping you map out your cloud journey.
Know Your Current On-Premises Architecture
A second critical category of questions needed for a proper migration to the cloud, (or any new platform) is understanding the current on-premises architecture. This step not only helps with the identification of your critical applications that need availability, but also their underlying dependencies, and any changes required for those applications, databases, and backup solutions based on the storage, networking, and compute changes of the cloud. Answering this question is also a key step in assessing the readiness of your applications and solutions for the cloud and quantifying your current risks.
A third area that will greatly benefit from working through these questions occurs when you discuss and quantify current limitations. Frequently, we see this phase of discovery opening the door to limitations of current solutions that do not exist in the cloud. For example, recently our services team worked with a customer impacted by performance issues in their SQL database cluster. A SIOS expert assisting with their migration inquired about the solution and architecture, and VM sizing decisions. After a few moments, a larger more application sized instance was deployed correcting limitations that the customer had accepted due to their on-premise restrictions on compute, memory, and storage. Similarly we have worked with customers who were storage sensitive. They would run applications with smaller disks and a frequent resizing policy, due to disk capacity constraints. While storage costs should be considered, running with minimal margins can become a limitation of the past.
Understand Business and Governance Changes
The final group of questions help your team understand schedules, business impacts, deadlines, and governance changes that need to be updated or replaced because they may no longer apply in the cloud. Migrating to the cloud can be a smooth transition and journey. However, failing to assess where you are on the journey and when you need to complete the journey can make it into a nightmare. Understanding timing is important and can be keenly aided by considering stakeholders, application vendors, business milestones, and business seasons. Selfishly, SIOS Technology Corp. wants customers to understand their milestones because as a Service provider it minimizes the surprises. But, we also encourage customers to answer these questions as they often uncover misalignment between departments and stakeholders. The DBAs believes that the cutover will happen on the last weekend of the month, but Finance is intent on closing the books over the final weekend of the same month; or the IT team believes that cutover can happen on Monday, but the applications team is unavailable until Wednesday, and perhaps most importantly the legal team hasn’t combed through the list of new NDAs, agreements, licensing, and governance changes necessary to pull it all together.
As customers work through the questions, with safety and empathy, what often emerges is a puzzle of pieces, ownership, processes, and decision makers that needs to be put back together using the cloud provider box top and honest conversations on budget, staffing, training, and services. The end result may not be a flawless migration, but it will definitely be a successful migration.
For help with your cloud migration strategy and high availability implementation, contact SIOS Technology Corp.
– Cassius Rhue, VP, Customer Experience
Learn more about common cloud migration challenges.
Read about some misconceptions about availability in the cloud.
Reproduced from SIOS