| December 13, 2021 |
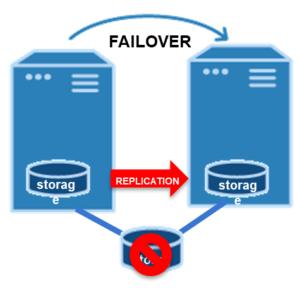
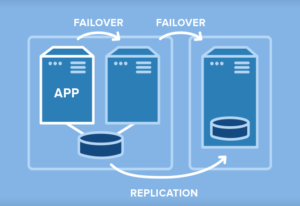
Data Replication |
| December 8, 2021 |
Achieving IT Resilience with High Availability
Achieving IT Resilience with High AvailabilityWhat is IT Resilience?IT resilience is the ability of an organization to maintain acceptable service levels when there is a disruption of business operations, critical processes, or your IT ecosystem. In this digital age, high availability is critical to your organization’s success. Your customers won’t tolerate a downed website. And you cannot afford a downed ERP, CRM, or other business-critical system either. This is where high availability comes in. Your organization must “check the boxes” on many different technologies and solutions to ensure IT resiliency – not the least among them is ensuring, at a minimum, that you have backup, disaster recovery, cyber resilience, and high availability solutions in place. For purposes of this article, we will be talking about high availability (HA) as one of the key elements required to ensure IT resiliency. What is High Availability?High availability systems ensure that business operations continue – with total transparency to customers and users – when your system, applications, and network goes down. HA is a component of a technology system that eliminates single points of failure to ensure continuous operations or uptime for an extended period. Highly available systems incorporate five design principles: automatic failover, automatic detection of application-level failures, no data loss, automatic and quick fail over to redundant components, and push-button failover and failback for planned maintenance. ————————————————————————————————————————– IT Resilience and High Availability – A Non-Example!This past August, Nissan Group’s data center in Denver crashed because of a power outage. The system impacted was known internally as NNANet. It is a Nissan solution used by employees to order cars/parts, manage product rebate sales, get info on vehicle recalls, file warranty claims needed to price and start service work, and getting financing information. NNANet is described as Nissan’s lifeblood because everything Nissan does goes through NNANet. The system remained down for four days, impacting operations at many retailers and production systems at two factories. The company, its retailers, and customers were all impacted. The ImpactClearly, this is an example where correctly configured, properly located high availability systems would have saved the day or at least minimized the impact of the crash. What was a high availability situation literally turned in to a disaster for Nissan as “commerce among consumers, retailers, distribution networks, manufacturing plants and finance companies.” were all affected for four days.[1] Nissan reset dealer sales goals by 10 percent for the month as a result of the crash. The total financial impact for Nissan and its dealers/retailers/partners remains to be seen. IT Resilience– A Real-World Example!Cayan™ is the leading provider of payment technologies and its Genius Customer Engagement Platform® aggregates and integrates every conceivable transaction technology, payment type, and customer program – both present and future – into a single platform. The Genius platform, as well as other mission-critical applications at Cayan, run on SQL Server. Cayan customers include some of the world’s largest online retailers, companies with no tolerance for downtime. “Our top priority is ensuring that our customers can complete transactions continuously 24 hours a day, seven days a week,” said Paul Vienneau, Chief Technology Officer, Cayan. Cayan needed a high availability and disaster recovery system for their SQL Server database. The company considered a traditional shared storage cluster, but a SAN solution was expensive, complicated to manage, and introduced risk associated with a single point of failure. For these reasons, Cayan IT staff decided to use SIOS #SANLess clusters. SANLess clusters use local storage so there is minimal performance overhead and fast application response times. The SIOS software, SIOS DataKeeper, is integrated with Windows Server Failover Clustering (WSFC). SIOS uses efficient, real-time, data replication to synchronize local storage in the primary and remote cluster nodes, making them appear to WSFC as a virtual SAN. The ImpactSince deploying SIOS SANless clusters, Cayan has not experienced any downtime or data loss. Comments Paul Vienneau, CTO, “We are very pleased with the SIOS DataKeeper software. It met or exceeded our expectations. Implementation and ongoing administration were easy, and we have had zero downtime since we implemented our SIOS SANLess clusters.” There are no customer satisfaction issues to report, no lost revenues, no unproductive employees, no disruption to the business. —————————————————————————————————– SIOS: Achieve IT Resilience with High AvailabilitySIOS DataKeeper™ uses efficient block-level replication to keep local storage synchronized, enabling the secondary nodes in your cluster to continue to operate after a failover with access to the most recent data. SIOS products uniquely protect any Windows- or Linux-based application operating in physical, virtual, cloud or hybrid cloud environments and in any combination of site or disaster recovery scenarios, enabling high availability and disaster recovery for applications such as SAP S/4HANA and databases, including Oracle, SQL Server, DB2, and many others. The “out-of-the-box” simplicity, configuration flexibility, reliability, performance, and cost effectiveness of SIOS products set them apart from other clustering software. In a Windows environment, SIOS DataKeeper Cluster Edition seamlessly integrates with and extends Windows Server Failover Clustering (WSFC) by providing a performance-optimized, host-based data replication mechanism. While WSFC manages the software cluster, SIOS performs the replication to enable disaster protection and ensure zero data loss in cases where shared storage clusters are impossible or impractical, such as in cloud, virtual, and high-performance storage environments. In a Linux environment, SIOS LifeKeeper™ and SIOS DataKeeper for Linux provides a tightly integrated combination of high availability failover clustering, continuous application monitoring, data replication, and configurable recovery policies, protecting your business-critical applications from downtime and disasters. Whether you are in a Windows or Linux environment, SIOS products free your IT team from the complexity and challenges of creating and managing high availability computing infrastructures. They provide the intelligence, automation, flexibility, high availability, and ease-of-use IT managers need to protect business-critical applications from downtime or data loss. SIOS = IT Resilience with HA + DRBackup, high availability, disaster recovery, and cyber resilience are all important elements in achieving IT resilience. With SIOS solutions, you can “check the box” for both high availability and disaster recovery – two solutions in one. With the ability to replicate to multiple targets, you can configure a multi-node failover cluster with nodes located in multiple locations to protect your systems from failures and disasters. For more information, and to ensure IT resilience for your organization, get a free demo of SIOS today. References:
Reproduced with permission from SIOS
|
| December 3, 2021 |
How to Achieve High Availability with Clusters
|
| November 28, 2021 |
Four Reasons To Use An Avoidance Strategy In High Availability |
| November 23, 2021 |
Introduction To Clusters – Part 2 |


 How to Achieve High Availability with Clusters
How to Achieve High Availability with Clusters