| March 8, 2022 |
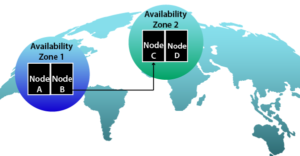
Highly Available or Highly Vulnerable? A Checklist for High Availability |
| March 3, 2022 |
Disney’s Encanto – Lessons on High Availability, IT Teams & downtime |
| February 27, 2022 |
How To Activate a License for SIOS Protection Suite for Linux |
| February 23, 2022 |
How To Install A SIOS Protection Suite for Linux License Key |
| February 19, 2022 |
How to Eliminate Single Points of Failure in the Cloud with High Availability Clustering |