| April 21, 2022 |
Measuring and Improving Write Throughput Performance on GCP Using SIOS DataKeeper for Windows |

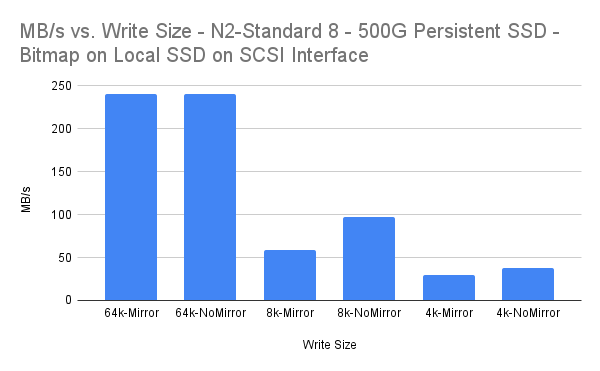
| Write Size | MB/s | MBps Percent Overhead |
| 64k-Mirror | 240.01 | 0.00% |
| 64k-NoMirror | 240.02 | |
| 8k-Mirror | 58.87 | 39.18% |
| 8k-NoMirror | 96.8 | |
| 4k-Mirror | 29.34 | 21.84% |
| 4k-NoMirror | 37.54 |
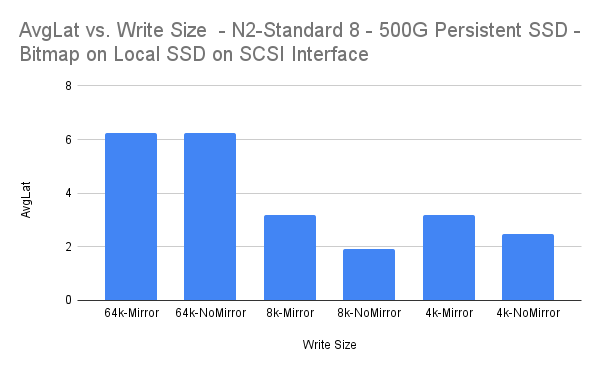
| Write Size | AvgLat | AvgLat Overhead |
| 64k-Mirror | 6.247 | -0.02% |
| 64k-NoMirror | 6.248 | |
| 8k-Mirror | 3.183 | 39.21% |
| 8k-NoMirror | 1.935 | |
| 4k-Mirror | 3.194 | 21.88% |
| 4k-NoMirror | 2.495 |
Conclusions
The 64k and 4k write sizes all incur overhead which could be considered as “acceptable” for synchronous replication. The 8k write size seems to incur a more significant amount of overhead, although the average latency of 3.183ms is still pretty low.
-Dave Bermingham, Director, Customer Success
Reproduced with permission from SIOS
How COVID-19 Impacts High Availability

How COVID-19 Impacts High Availability
Compared to friends, family, and those who have required treatment, hospitalization, or intensive care, my COVID symptoms have been mild. This is likely the result of reasonably good health, both doses of the vaccine, a booster shot, and early detection and treatment. And, my heart goes out to every family who has lost a loved one to any aspect of this pandemic, and to all those who have lost opportunities and special moments. As I and several members of our SIOS team recover from COVId-19, we wanted to share five things that your IT Team may be dealing with as they fight COVID and enterprise downtime, and five things you can do to help them.
Five COVID Concerns Facing IT Teams
-
Personal and Family Concerns and Fears
Initially, my symptoms were barely noticeable, a slight irritation in my throat, and a little sinus drainage, which I self-diagnosed as seasonal allergies. But when the issues worsened, accompanied by a bad cough I became worried. Of course, we’d all like to think that our work performance and responsibilities remain unchanged, but the reality may be a little harder to assess. Despite initial negative tests, I continued to develop symptoms that eventually impacted my ability to work, increased my personal health concerns, and raised a number of fears. If your team has been directly affected by COVID-19, understand that they are likely dealing with personal concerns, fears, and worries in addition to the real health challenges that may impact their schedules, tasks, and activities.In the midst of their personal concerns each team member is likely also dealing with larger concerns, namely concerns about family. During my illness, thankfully, my children all remained well. However, my wife was not so lucky. She became ill three days after my symptoms and remained ill longer and with more severe symptoms and setbacks. While we have the benefits of a large family unit, a licensed teenage driver, and an extra car not driven by COVID-positive parents, your team may not have these luxuries. And even if they do, it does not give them freedom from concern or reduce the amount of time and mental energy they need to apply to sanitize the home, keep their children in school and healthy, and deal with regulations, mandates, and close contact issues. Not to mention concerns over income and expenses. Team members facing personal and family concerns may experience difficulty concentrating, short-tempers, and difficulty meeting deadlines and schedules.
-
FODO – Fear of Disappointing Others
Even without COVID-19 illness, businesses worldwide are feeling the impact of a smaller workforce. The events aptly described as the “Great Shift”, “Great Resignation”, or “Great Shuffle” have already dramatically reshaped workforces, including those dealing with HA, leaving teams with fewer people to carry on critical tasks. This deficit in team members can lead those with COVID to battle a Fear of Disappointing Others (FODO). Sick team members may continue to try to work out of loyalty to the team or a fear of disappointing bosses, peers, or stakeholders. This FODO often leads to workers who are already functioning in a stressed environment (see #1 and 2 above) to attempt to maintain pre-COVID levels of activity. While heroic, it is also counterproductive to personal and professional recovery.
-
Fatigue
As I continue to deal with COVID-19 symptoms, one of the biggest issues I continue to face is fatigue. Initially, that fatigue, which was driven by FODO, prevented me from getting adequate rest and recovery. Because I had seen how shorthanded our team was and witnessed others try to brave their illness to keep up with demand, I tried to do the same. But, without warning I found myself drained, not at the end of the day, but for periods of time throughout the day. For me, starting the day before 5am and continuing to focus on work, tasks, strategy, and personnel matters for 8 to 12 hours was normal. (We can debate later if that was ever healthy). Now some felt like climbing Everest before 8 AM. The best advice I received was from a friend and co-worker who said, “Don’t fight it. When your body says rest, rest!”
-
Brain Fog
Around the same time that I started feeling sick, a colleague shared that they felt like they were in a fog following their bout with COVID symptoms. Like me, they were fully vaccinated and their symptoms and duration were mild. In fact, they actually never tested positive. Nevertheless, they spent days with what we both termed “brain fog.” An experience that we describe as slowness to recall details, a sense of knowing the answer, but lacking some mental sharpness that is somehow different from the physical fatigue and mental fatigue. In some instances, it appears as a slower response to a question, a pause in the keystrokes, or a delay before the light comes on in the room.
-
Failed Recovery
Five days into COVID, I woke up from an early night’s rest feeling better than ever. I jumped into my regular routine and by noon discovered that I had not fully recovered. Instead I was exhausting a small store of energy gained by sleeping well the night before. Trying to fight through this exhaustion created a new setback in my recovery. The following day I felt worse than before. The agony of a failed recovery and a concern about how to avoid more setbacks was added to my fatigue and fog.
So, what should IT team leads, stakeholders and managers do when their teams experience an issue with COVID-19.
Five Ways to Help IT Teams Battling COVID
-
Practice Empathy
Be mindful that COVID affects each person and family differently. Some of your coworkers and administrators will have minor issues, no symptoms, and no complications. While others, single parents, multi-generational families, or families with children or vulnerable persons will have many more issues and concerns. Know that the virus also impacts each person uniquely. Even within my own family my symptoms and those of my wife were different. While I experienced greater fatigue, she experienced more headaches. Have patience for coworkers who may be dealing with brain fog, juggling work schedules, caring for sick loved ones, or dealing with myriad issues related to COVID.
-
Assess needs
Unlike the flu or common cold, COVID recovery is irregular. A team member may show up at work one day feeling much improved and stay home sick the next. Your business still has technical needs and requirements for high availability and disaster recovery. However, with persons in and out of availability due to illness, be sure to understand the current roles and responsibilities required within the team. When an individual is out sick, be sure to assess their role, their impact to the team, their level of responsibility to the infrastructure,etc. You may also need to assess who within the team or organization can provide coverage in the event of a critical downtime event.
-
Prioritize issues
Help your team by prioritizing key issues. Under normal circumstances, your IT team is balancing dozens of requests ranging from the trivial (USB keyboard) to the critical (issues related to downtime, security threats, or storage issues). While it may be obvious to you and the team, other stakeholders may need to understand the status of the IT team and how operations will be handled until a return to more “normal” staffing occurs.
-
Be sure your Processes are up-to-date
As team members swap in and out, it is critical that IT maintenance and management processes are kept up to date. These processes will help each member of the team service your enterprise effectively and efficiently when performing a task that is not their normal responsibility. It will also reduce the amount of time each team member needs to spend researching the status of the systems they are covering while a coworker recuperates.
-
Give People Time
I’ve rushed back into the routine more than I should have, only to suffer the consequences of setbacks and greater fatigue on the following day. As a leader or individual contributor on a team, be sure to give yourself and your team time to “get back to normal.”
As the pandemic continues, we all hope for a future that greatly resembles normalcy, including less illness, fear and worry. In the meantime, being more aware of the concerns your team members are facing during COVID illness and recovery will greatly help you proactively prepare and weather the current storm. In addition, key lessons learned from this pandemic can be applied across a number of other organizational, employee life, and global concerns.
Reproduced with permission from SIOS
How to Get the Most from Your Tech Support Call

How to Get the Most from Your Tech Support Call
Technical support experts share their tips on how to fast-track issue resolution
SIOS provides high availability protection for our customers’ most critical applications, databases, and ERPs. When our customers call tech support, there is no time to waste. We’ve earned a reputation (and several awards) for our HA/DR expertise and support excellence.
We’ve asked our tech support team to share the following five questions that can fast-track your issue resolution.
Fast, Accurate Diagnosis
Thorough and accurate tech support is similar to diagnosing an illness. Imagine asking your doctor to treat a headache. The human body is a complex interaction of multiple systems. The source of your problem may not be obvious or even in your head. To diagnose the issue and recommend a treatment, your doctor typically begins with questions aimed at identifying the circumstances that caused your symptoms.
Failover clustering also involves multiple systems at every layer of the IT infrastructure – network, storage, OS, application, database, and server. And like your real headache, your HA issue is often caused by something unrelated to your HA clustering software. Like your doctor, a good support professional will ask a variety of questions to characterize your issue. The more information you can provide about your support issue, the faster and more effectively it can be diagnosed and resolved.
Fast-Tracking Issue Resolution
As an IT best practice, consider logging key information and system changes as an ongoing business exercise. By putting answers to the following key questions at your fingertips, this process will speed the diagnosis and fast-track issue resolution. (It may also help you prevent issues from occurring in the first place).
- Can you describe the error you are receiving? What is the exact symptom you are witnessing that is causing concern?
- When did it happen (time, time zone you are in?)
A typical diagnostic method is to examine log files from the machine with issues. Log files can be hundreds of lines of message strings or command output. By tracking the precise time you noticed the problematic symptoms, we can significantly narrow the log file examination. - Have you or are you able to upload the logs?
Providing an explanation and description of the error along with the timeframe for which it happened goes a long way in diagnosis provided the logs can be uploaded to the support ticket. In some IT environments uploading the logs requires using corporate-approved file sharing, while dark sites require no electronic distribution of system logs. If logs cannot be provided externally, be sure that the full logs are captured and archived for reference and review with the support agent as the case progresses. Applications and systems, especially those under duress can produce exhaustive and extensive logs that can overwrite critical information. - Which system was the primary cluster node at the time?
Given the interconnected nature of clustering, it is important to inform your tech support representative of whether the cluster node you are calling about was functioning as the primary or secondary node at the time of the issue. - What have you tried to do to remedy the issue?
Great physicians know that their patients have likely tried a home remedy or over-the-counter medication prior to the visit. Knowing this information is helpful in diagnosis and treatment. The same applies with great support technicians. Sharing not only what you were trying to do at the time of the issue, but how you tried to resolve your errors can help them craft a better treatment and recovery plan, and make sure that their recommendations for recovery protect your critical data and applications.
For more than 20 years, SIOS Customer Experience team has been helping enterprise customers implement HA/DR solution for a wide range of use cases. We value our customers and encourage them to contact us whenever they have questions about their HA/DR.
Reproduced with permission from SIOS
Two Truths and a Lie: Understanding the Real Truth About Availability

Two Truths and a Lie: Understanding the Real Truth About Availability
We played two truths and a lie at a company event years ago. The game involved putting forth two true statements and one untrue statement to see if you could fool the most people. The winner put forth ideas that all seemed believable or unbelievable, depending on your own personal history. Here is what was said:
- While growing up, my hometown had no stoplights.
- My grandparents met in the second grade and married in their teens.
- After graduation, I attended a prestigious out-of-state university in Georgia before transferring back home to attend an in-state university.
I grew up in a small community with no stoplights, so that one seemed possible, but I was skeptical. I’ve heard stories of people who met at an early age, and got married in their teens, so that was possible but also the one that I might want to flag. The third one also seemed true, but I wondered who would transfer from a prestigious out-of-state university back to the no stoplight hometown to attend an in-state college. For what seemed like an eternity the entire group reasoned and pondered which of the three statements was a lie. And, it seemed as if no one could spot it. Several of us reasoned that if the hometown had no stoplights, would it really have a university as well? A few took the line that it was unlikely he attended the prestigious out-of-state university, given his age, years with the company, and multiple degrees. After final deliberation the verdict was in, the two truths were number one and number two. The lie was number three.
With all the information swirling around about High Availability, you might feel like you are playing a game of “Two Truths and a Lie.” Depending on where you look, you may find statements about availability that seem believable, but are not completely true when you dig in beneath the surface. For example, the following widely accepted statements are not actually true:
-
Storage availability is all that is needed for high availability
Applications require access to data to be effective and efficient. Your database will need to have access to storage if you are going to successfully run your enterprise. Your other enterprise application likewise must have access to configuration files, data stores, and transaction and error log directories to be usable. But, while reliable, readily accessible, and performant storage is essential for all enterprise systems, websites, databases, applications, and interconnects, storage available alone is not all that is needed for high availability. There are more components that make up a sound, reliable, resilient high availability architecture than just storage.
-
Platform availability is all that is needed for high availability
With the continued development and growth of cloud computing, many enterprises searching for high availability are confused by the concept of platform availability. Platform availability, sometimes referred to as system availability or infrastructure availability relates to the time that the platform (hardware, network, OS, and related components) are accessible and deliver their intended IT service. Applications and databases absolutely need compute, memory, storage, and network resources to operate properly and efficiently. Every service or function in your data center needs a reliable place to execute its logic, and without the underlying platform, these operations are not possible. Because of this, many consider that platform availability is all that is needed for high availability. As VP of Customer Experience, I have helped customers and partners understand the gaps between an available platform and available applications, databases, and client connectivity. In those conversations, we have discussed real examples of platforms showing no downtime or service issues, while simultaneously the enterprise applications running within that data center or cloud infrastructure are unavailable, unstable, or inaccessible to clients due to non-platform issues.
So What’s the Real Truth?
When our co-worker shared his three statements, we all got it wrong. His hometown was a small community, its borders were buffered by larger towns with a stoplight, but his own town did not have one of its own. And, as it turned out, he graduated early and went to that well-known, prestigious out-of-state institute of technology in Georgia, before getting homesick and transferring to an in-state university back home. So the lie was about his grandparents. While they may or may not have met at an early age, they definitely did not meet in the second grade.
The truth about high availability is that storage availability and platform or infrastructure availability are not enough on their own. In order to create the most robust, available, resilient, and reliable high availability infrastructure you must also include a commercial-grade solution to provide application-aware monitoring, alerting and recovery. You’ll also want that solution to be knowledgeable of your storage’s high availability capabilities, have a strong awareness of the infrastructure’s nuances and gaps, and have the ability to leverage best practices across the entire architecture to help your applications, databases, and services achieve your business objectives.
How to Use the SIOS Self-Service Portal

How to Use the SIOS Self-Service Portal
In this 5 minute video, a SIOS Support Representative will walk you through how best to navigate and use our new SIOS Self-Serve Portal.
You will be shown:
- How to view product documentation
- Licensing portal where you can: Activate, view, and manage your product licenses.
- Support portal where you can:
- View and submit cases
- Go into our knowledge-based solutions to assist you with possible issues prior to escalation of need for support
- Find the latest software versions as well as the documentation for supported Windows and Linux software
- It will also take you through the Cases tab where you can see all of your open and closed cases as well as create new ones.
Keep in mind that the licensing portal and the support portal are separate websites with different login credentials.

How to Use the SIOS Self-Service Portal | SIOS
Reproduced with permission from SIOS