| May 9, 2022 |
How to Avoid IO Bottlenecks: DataKeeper Intent Log Placement Guidance for Windows Cloud Deployments |
| May 5, 2022 |
Leading Media Platform Protects Critical SAP S/4 HANA in AWS EC2 Cloud |
| May 1, 2022 |
Protect Systems from Downtime |
| April 29, 2022 |
How to Achieve High Availability in the Cloud Using WSFC |
| April 26, 2022 |
The single best way to deploy quorum/witness |





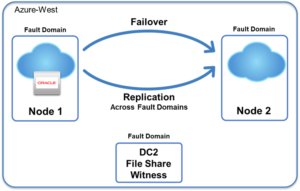
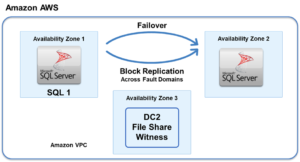

 In a normal cluster environment, the protected application is running on the primary node in the cluster. In the event of an application failure of that primary node, the clustering software moves the application operation to a secondary or remote node, which assumes the role of primary. At any given time, there is only one primary node.
In a normal cluster environment, the protected application is running on the primary node in the cluster. In the event of an application failure of that primary node, the clustering software moves the application operation to a secondary or remote node, which assumes the role of primary. At any given time, there is only one primary node.