| October 14, 2022 |
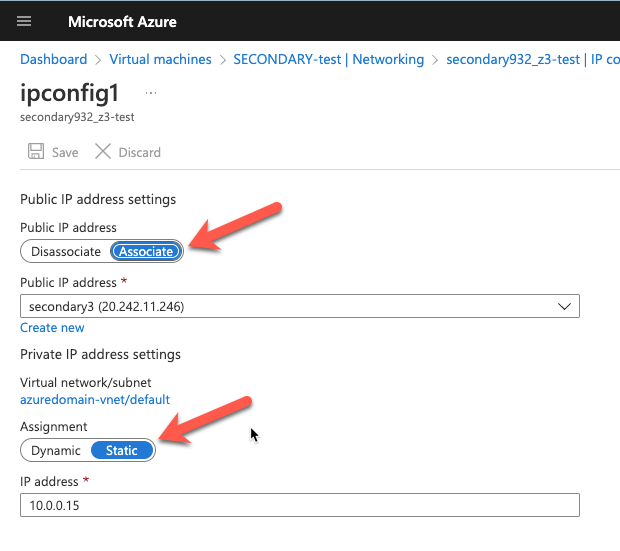
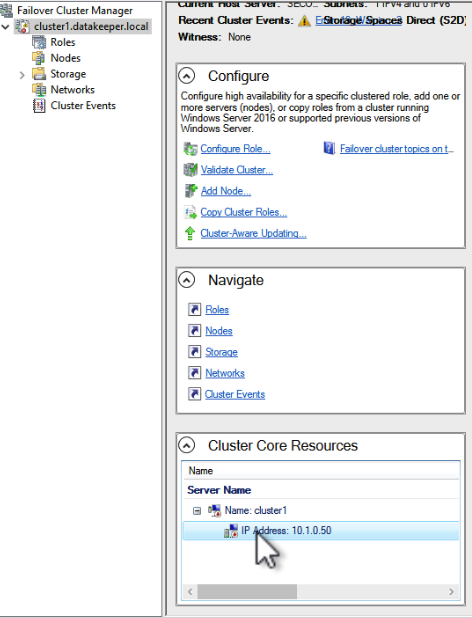
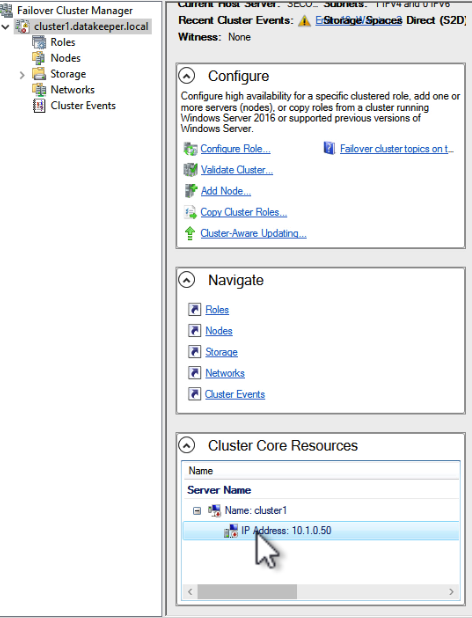
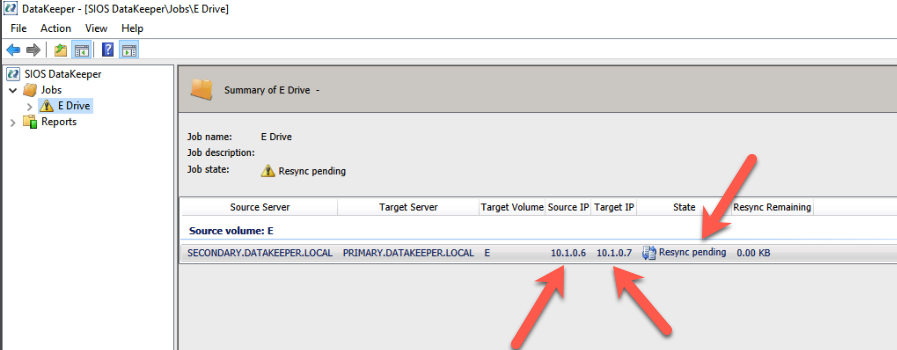
How to use Azure Site Recovery (ASR) to replicate a Windows Server Failover Cluster (WSFC) that uses SIOS DataKeeper for cluster storage |
| October 6, 2022 |
The Generic Application Recovery Kit
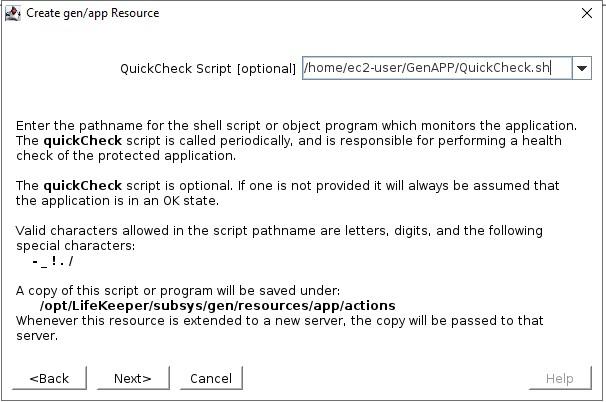
The Generic Application Recovery KitThe SIOS Protection Suite for Linux comes with an array of handy Application Recovery Kits covering major databases such as SAP HANA and Oracle, IP, File Systems and NAS or NFS shares and exports. Every SIOS supplied ARK has restore(start), remove(stop), quickcheck and recover scripts – these are not readily configurable beyond any options asked for during configuration and addition into a protected hierarchy. These ARKs are developed, maintained, quality checked and in some cases “support certified” by the application vendors themselves. What do you do if you have an application or service that’s not covered by an existing SIOS ARK? Enter the generic ARK. The generic ARK can be added into a hierarchy and configured in a similar manner to other SIOS ARKs; the special thing about the generic ARK is that it requires you to provide a restore, remove and quickCheck script and optionally a recover script. You can use any configured scripting language to create your scripts (BASH or Perl are common), lets investigate these scripts a little further:restore: This is the script that is used to start your service or application remove: This is the script used to stop your service or application quickCheck: This script is used to determine whether your application or service is functioning as you would expect it to recover: This script would be used to attempt a recovery following a failure, certain applications and services lend themselves to being restarted or certain commands being run to try to recover from a failure scenario By default, the quickCheck script runs every 180 seconds. If the quickCheck script detects a failure of the application it calls the recover script. The recover script tries to restart the application on the current node. Should the recover script fail to restart the application, or a recover script is not provided, the remove script is then executed. This initiates a failover to the standby node. Templates for the Generic Application KitSIOS provides example templates for the Generic Application Kit. These examples are installed with the lifekeeper software and can be found here: quickCheck, remove and restore /opt/Lifekeeper/lkadm/subsys/gen/app/templates/actions/ recovery /opt/Lifekeeper/lkadm/subsys/gen/app/templates/recovery There are examples for quickCheck, remove and restore in both BASH (.sh) and Perl (.pl) languages. The example scripts are self documented with comments throughout the script. Assuming that you’re familiar with either BASH or Perl then you will be able to understand what the scripts are doing.. A return code of 0 indicates a successful run, other values indicate a failure. The results of a script will trigger the next action that LifeKeeper takes. Setup within LifekeeperAfter you have created your scripts you can create a Generic Application by clicking the green plus sign to create a new resource. Choose “Generic Application” to launch the configuration wizard. 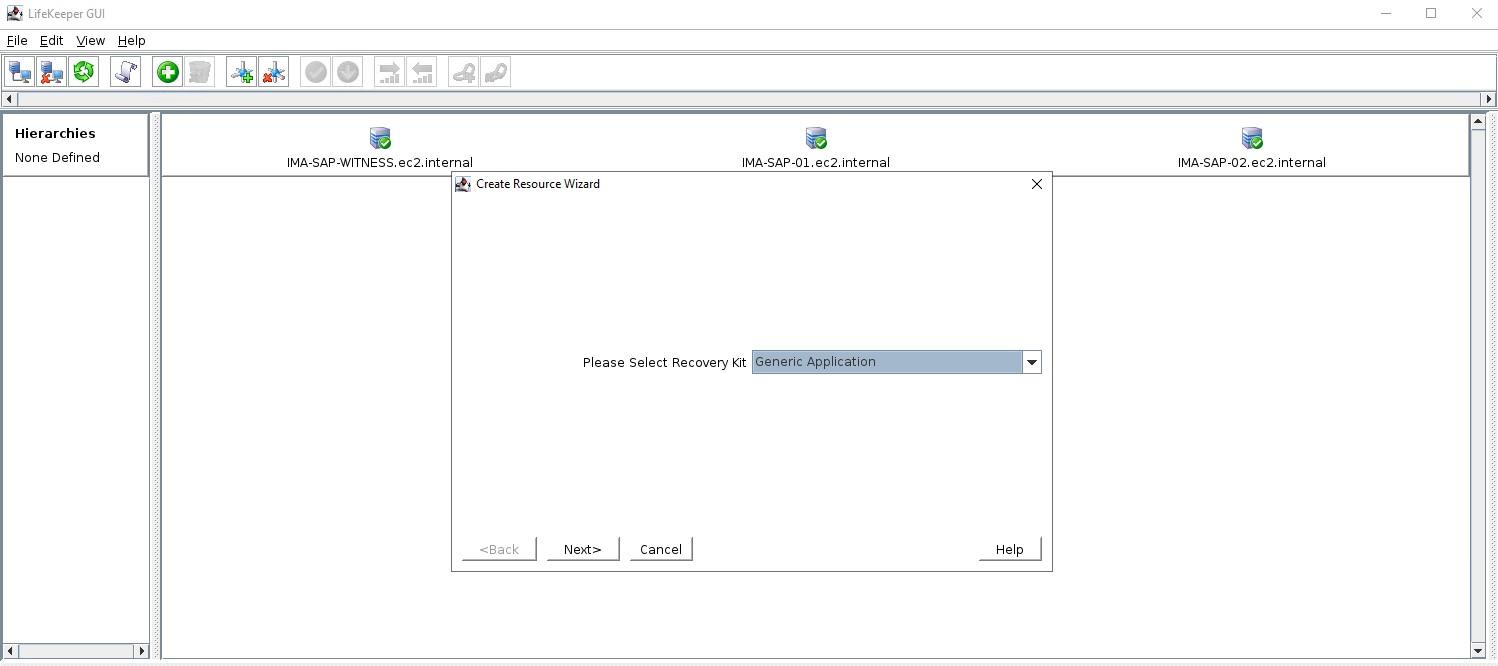 Add a resource and select Generic Application 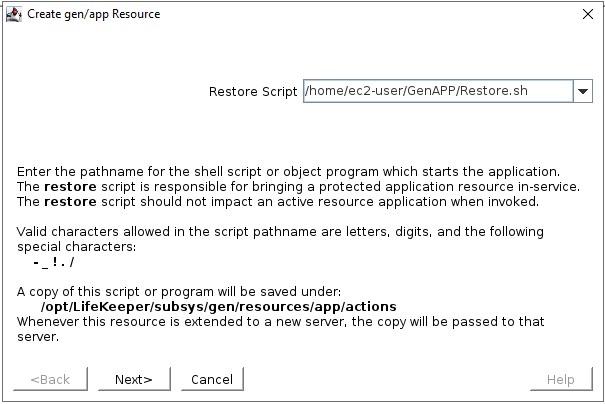 Select the Restore script 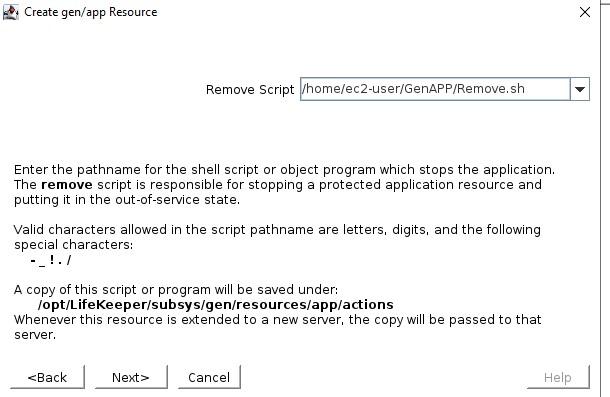 Select the Remove script start from here
Select the QuickCheck script 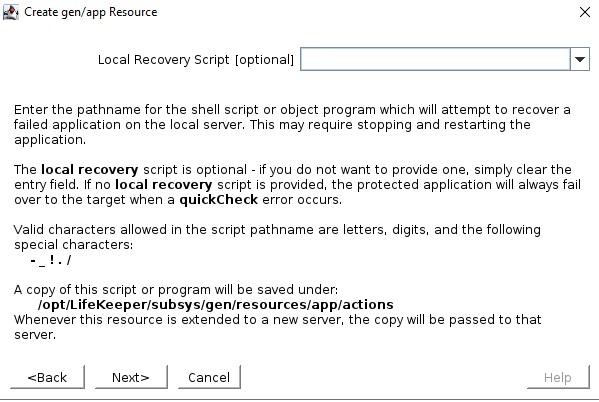 Select the Recovery script (none in this example)  The Application Info is a way to pass in information to the GenAPP scripts. For example, in our GenAPP for the generic load balancer we use this field to pass the port that the load-balancer is listening on. 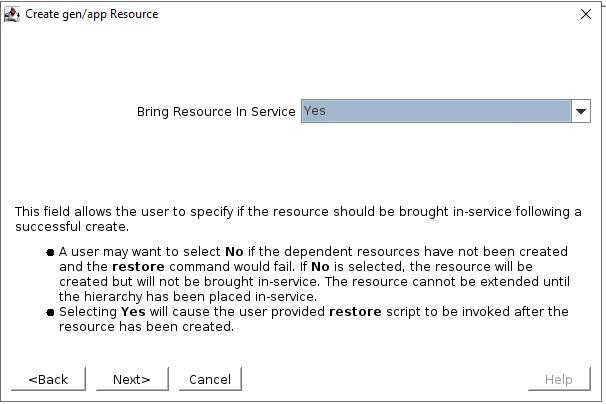 Select whether or not you want to bring the GenAPP online once it’s created, sometimes you want to leave the GenAPP offline so that you can create any dependencies that might be required.  Give the resource that will be created a name  Once you have entered all the information, the resource will be created So you can see that creating a GenAPP to protect almost any application is straightforward and easy. A GenAPP allows you to protect ANY application, even custom applications that are built inhouse. If you would like to learn more about how SIOS can help you keep your business critical applications available please contact us! Reproduced with permission by SIOS |
| October 4, 2022 |
AWS Summit Singapore – SILVER SPONSOR |
| October 2, 2022 |
How to convert from SIOS NFS resources to EFS |
| September 28, 2022 |
What’s new in SIOS LifeKeeper for Linux v 9.6.2? |