| January 10, 2023 |
SIOS DataKeeper Clustering Software Enables Gulliver International to Move Internal IT Systems to Amazon Web Services Safely |
| January 5, 2023 |
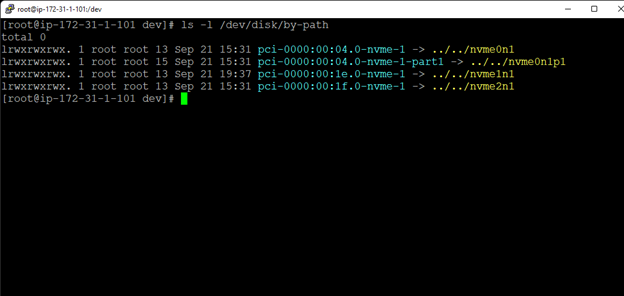
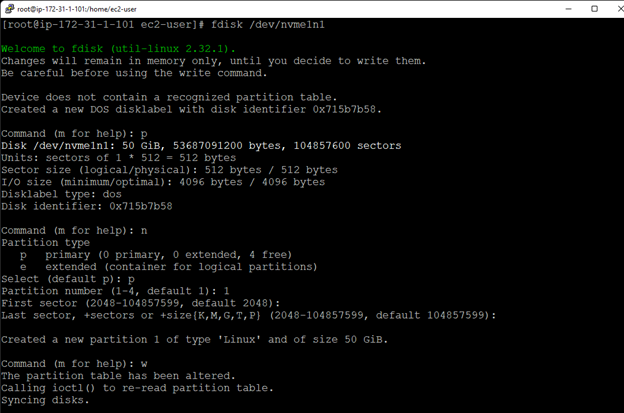
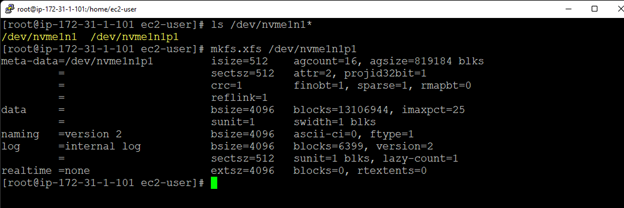
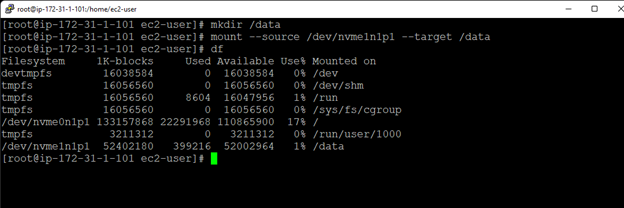
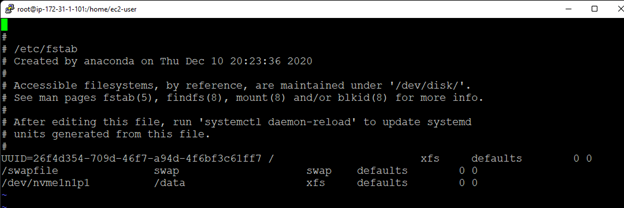
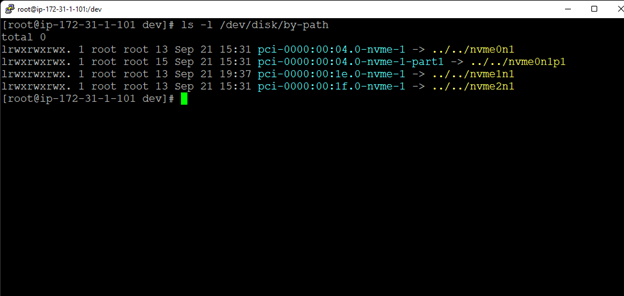
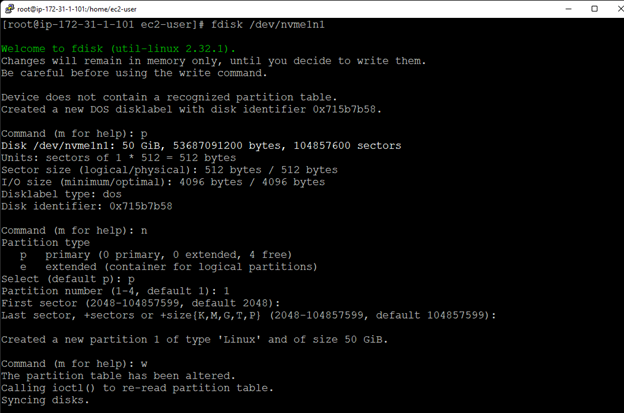
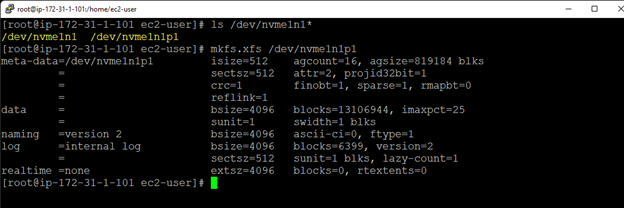
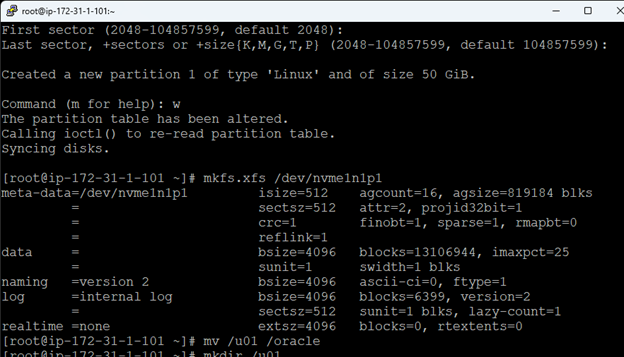
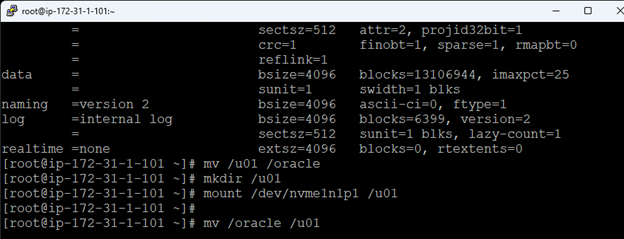
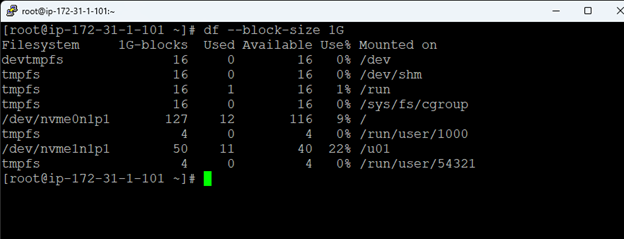
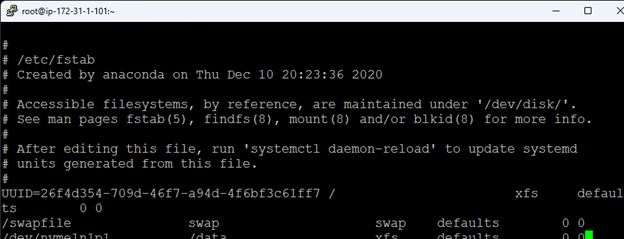
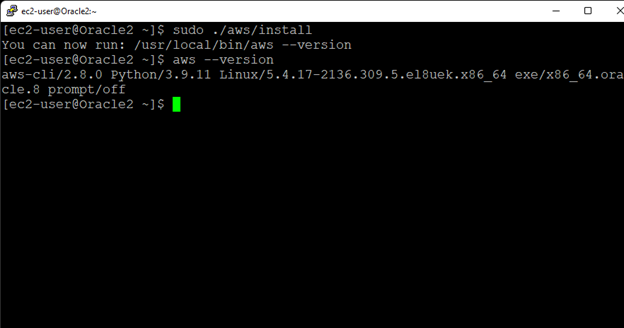
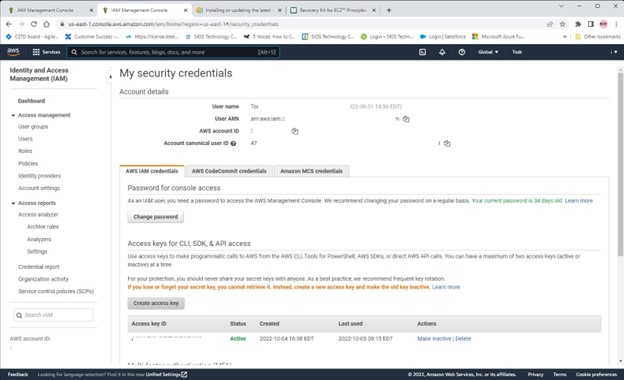
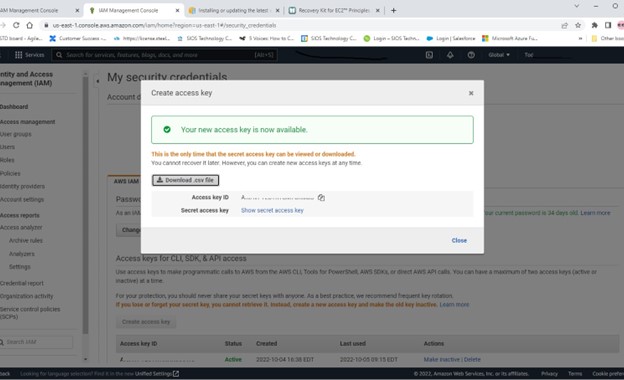
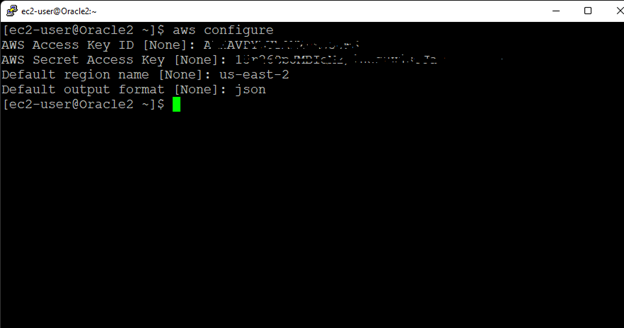
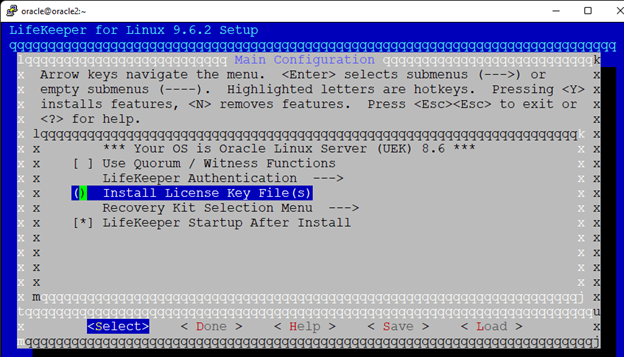
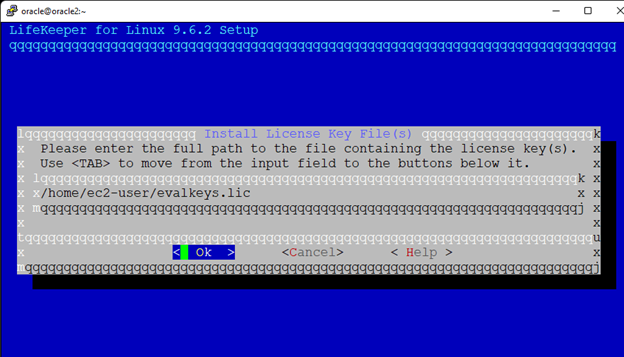
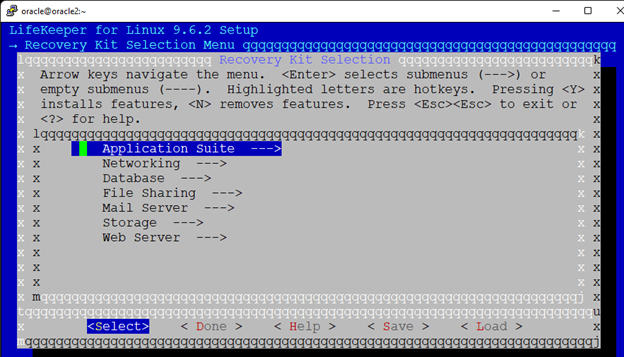
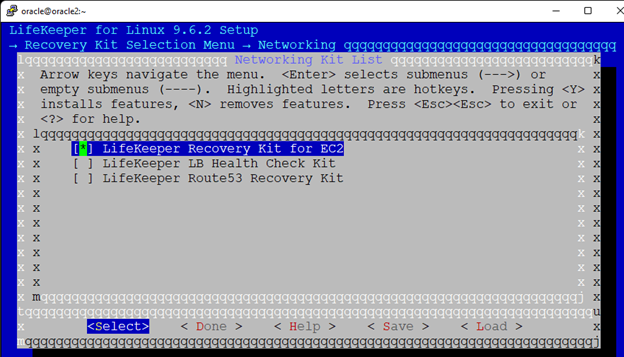
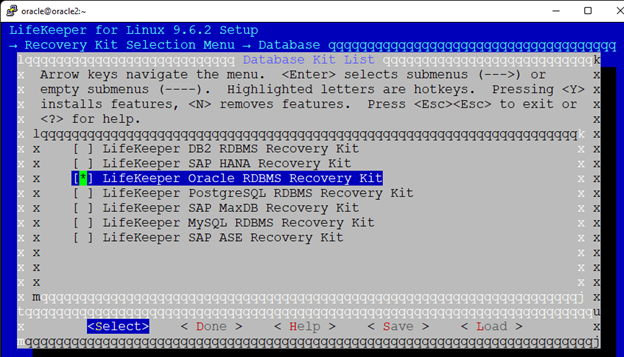
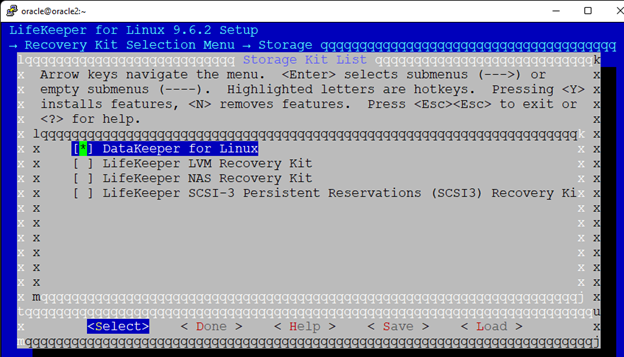
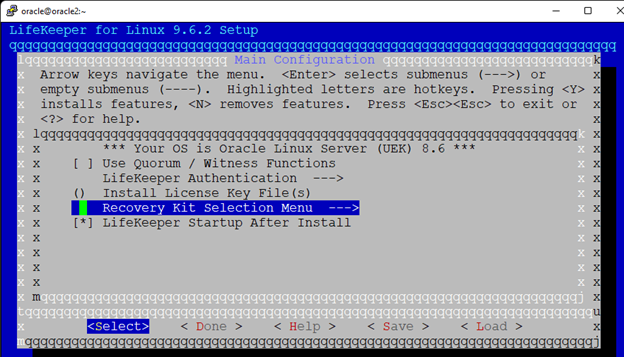
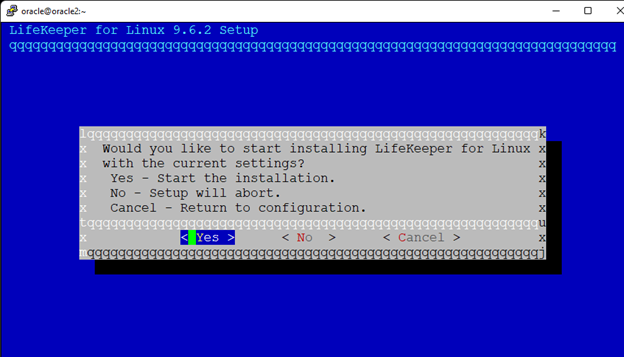
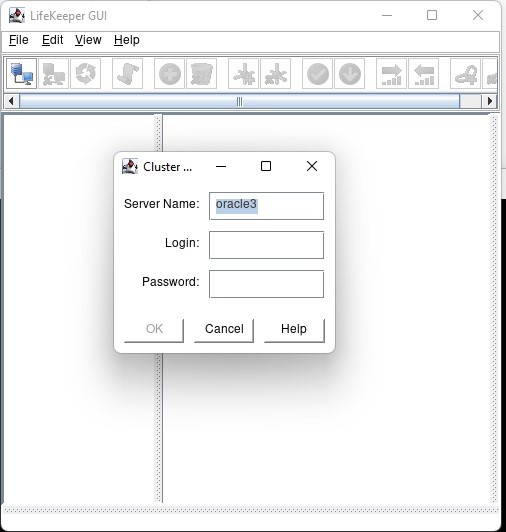
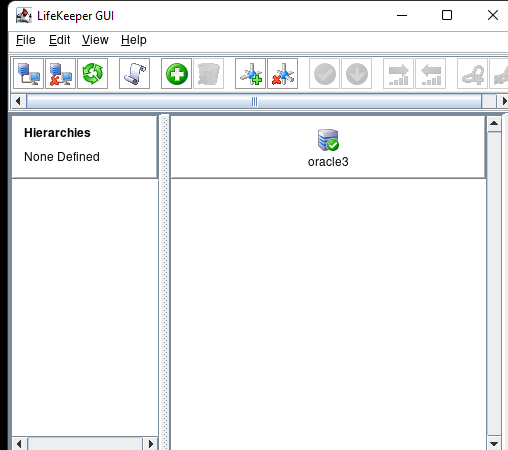
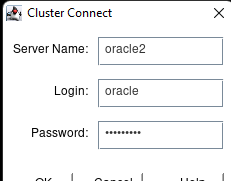
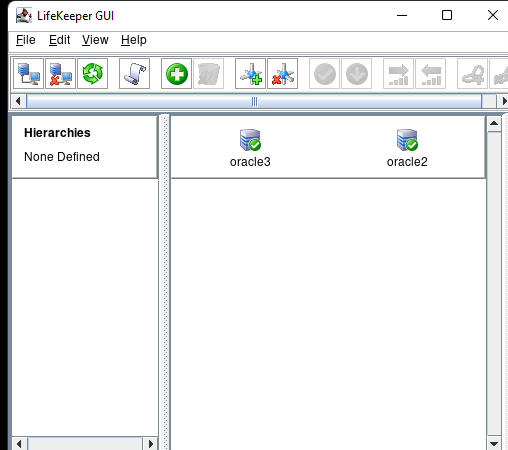
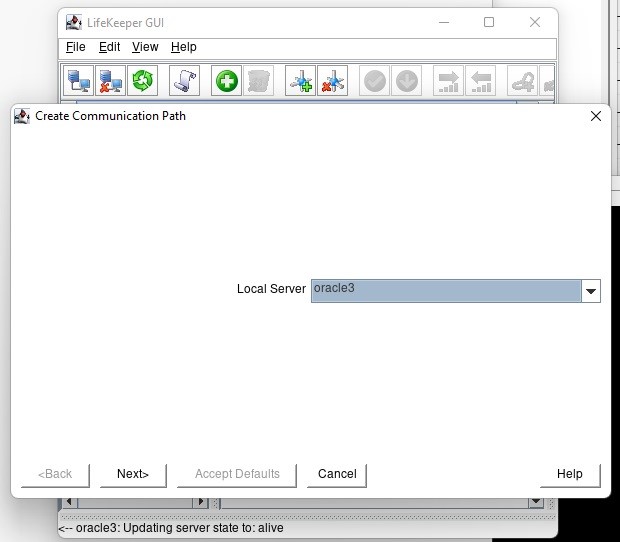
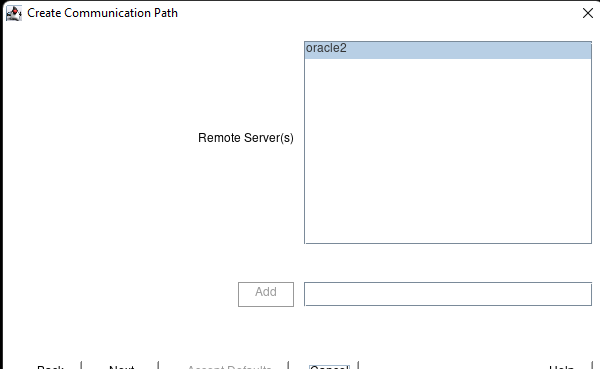
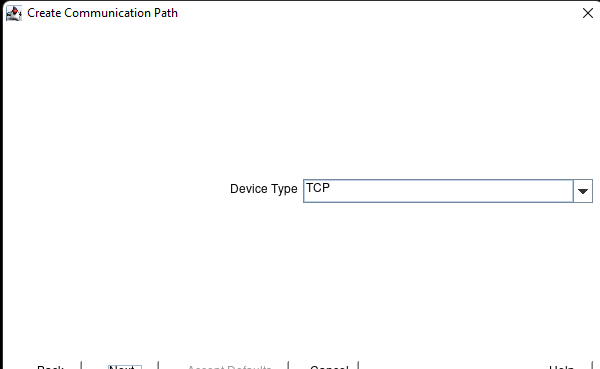
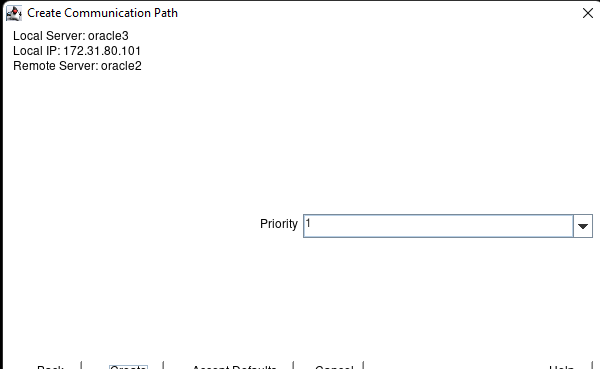
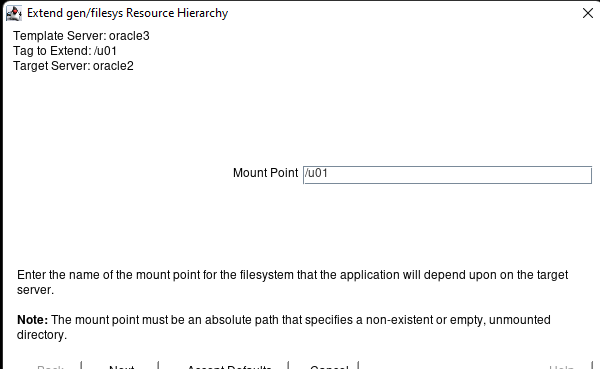
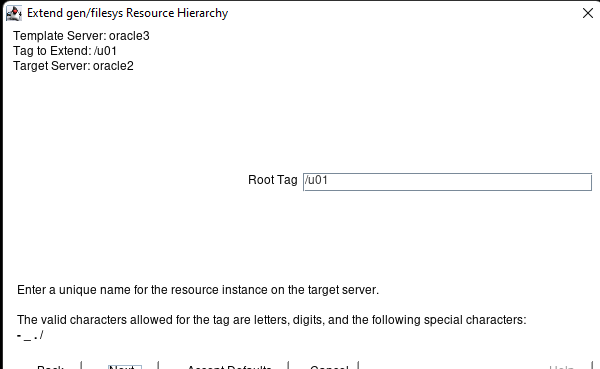
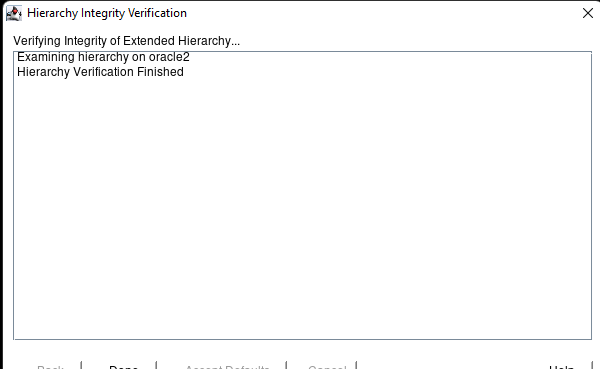
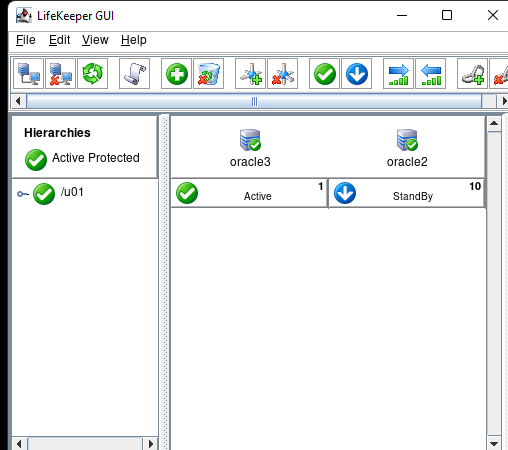
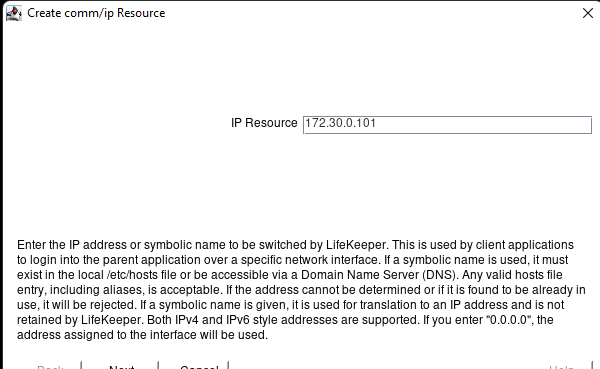
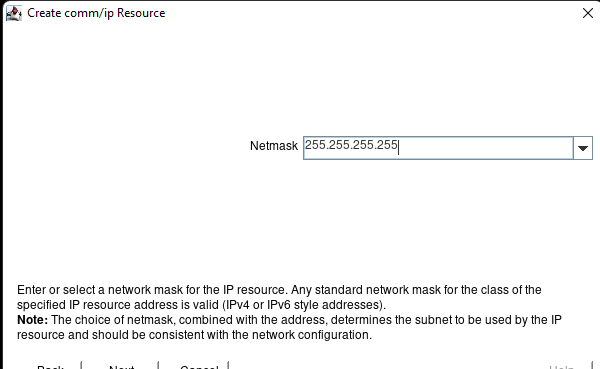
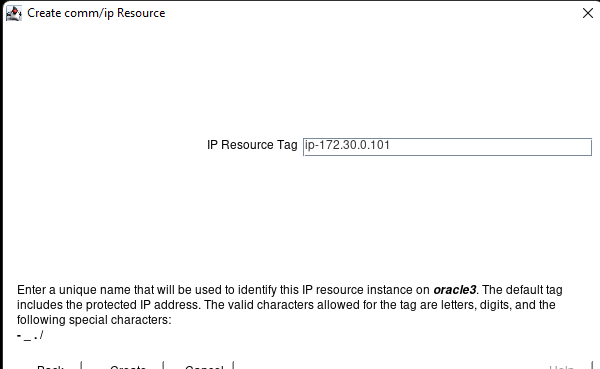
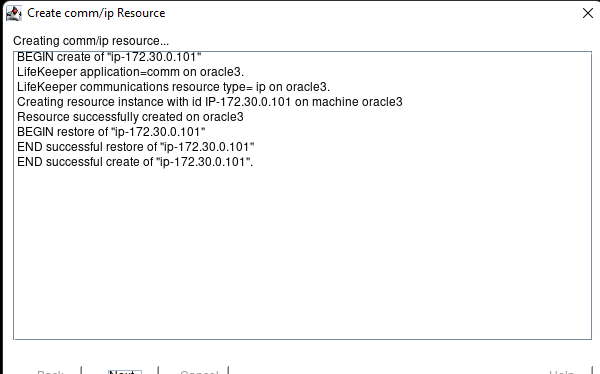
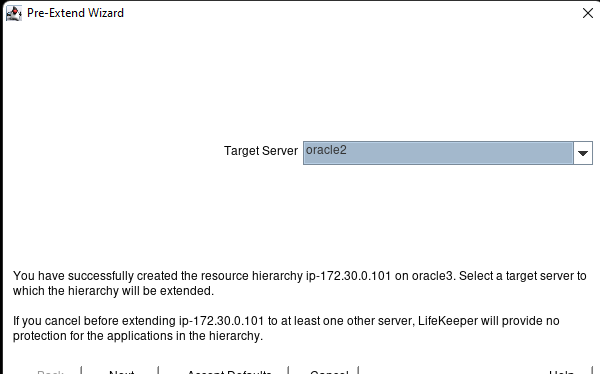
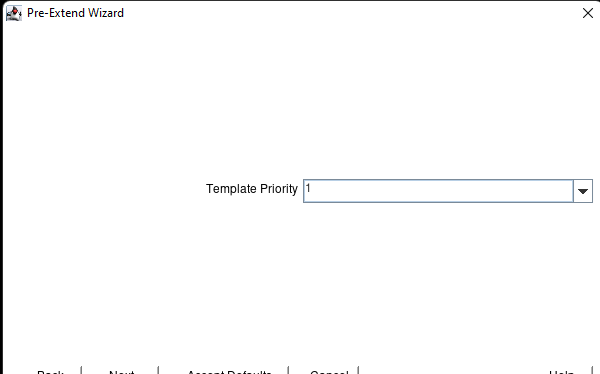
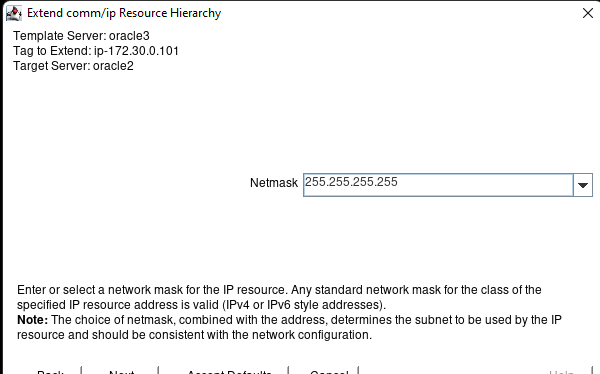
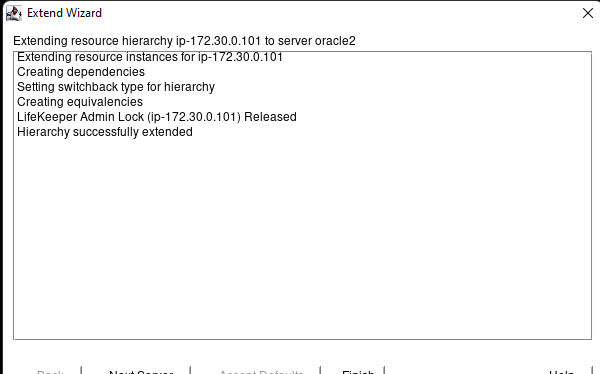
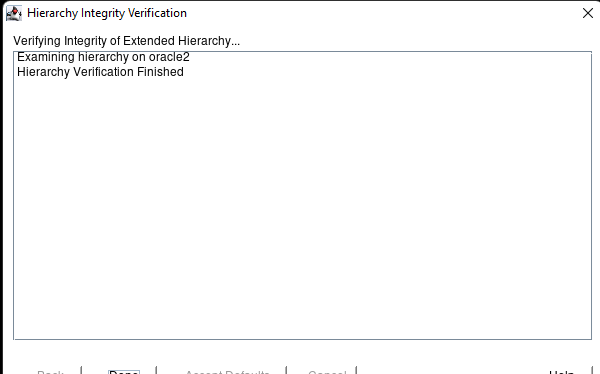
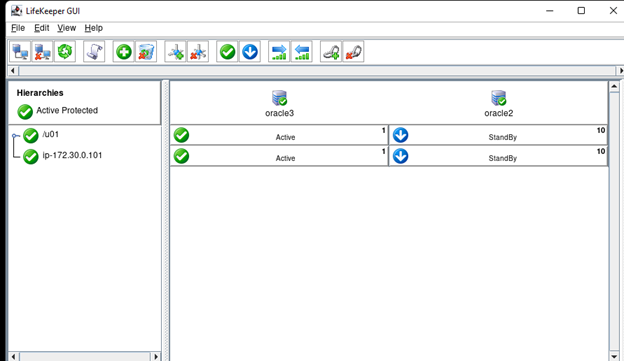
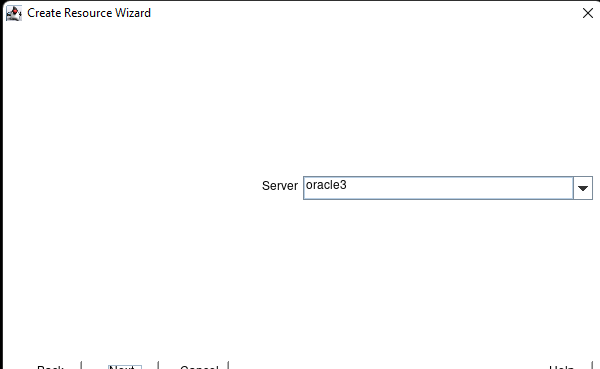
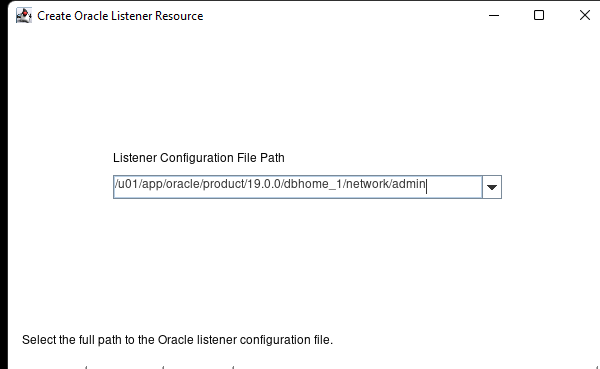
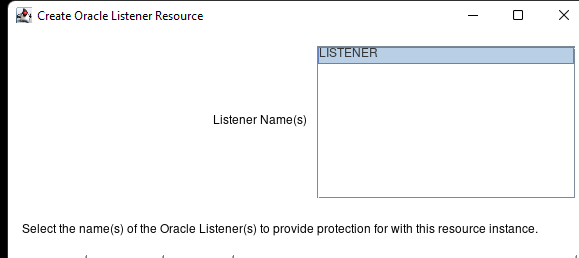
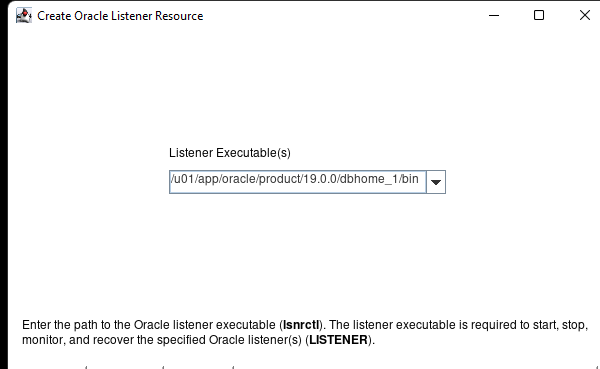
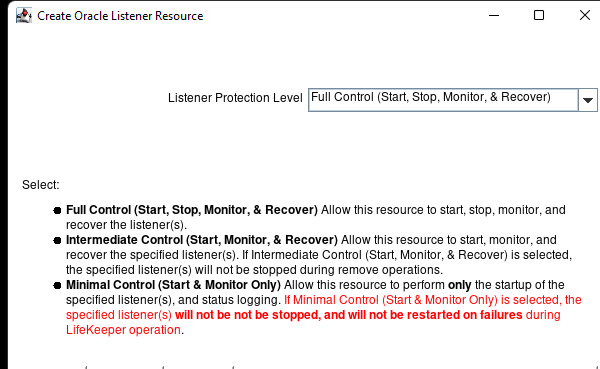
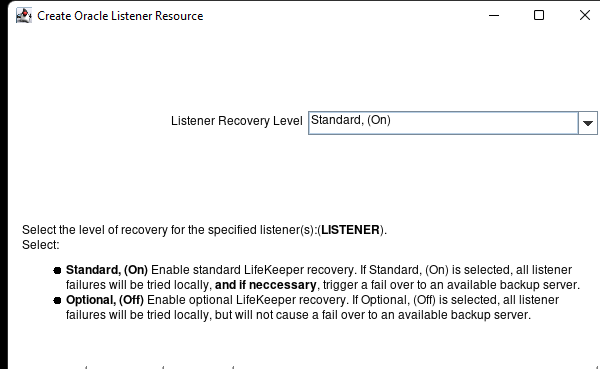
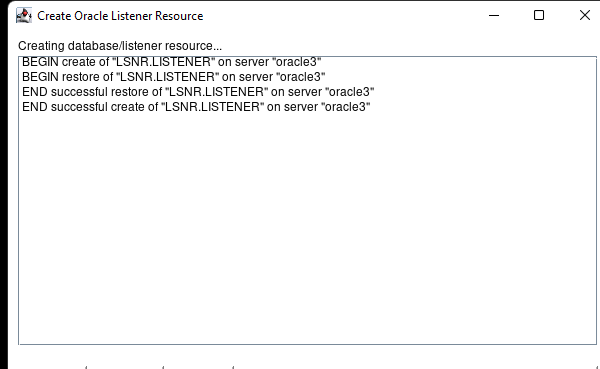
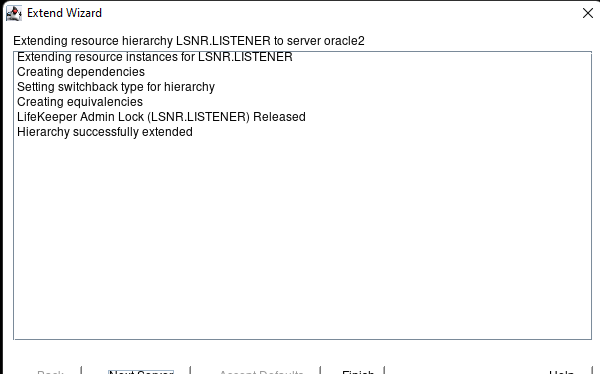
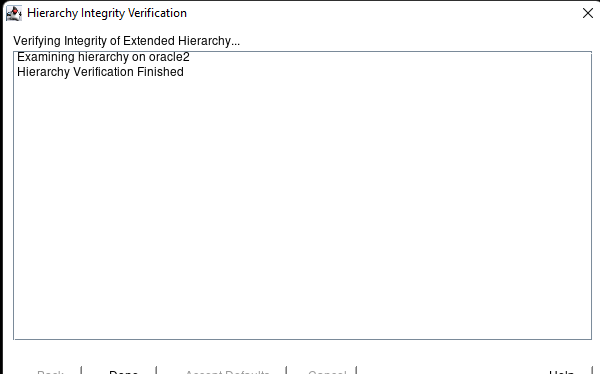
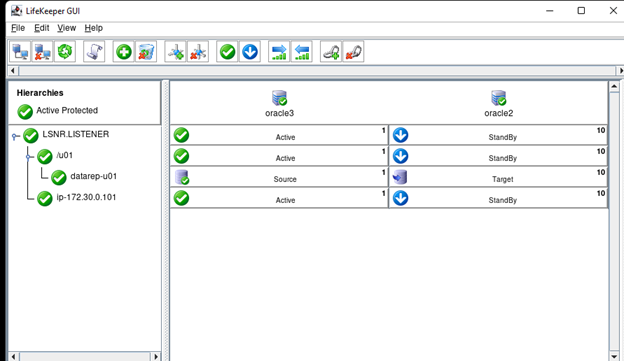
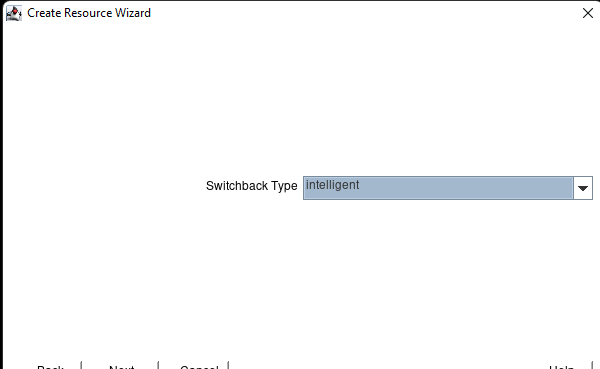
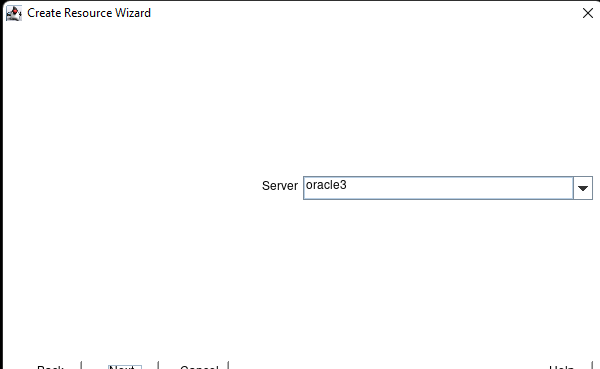
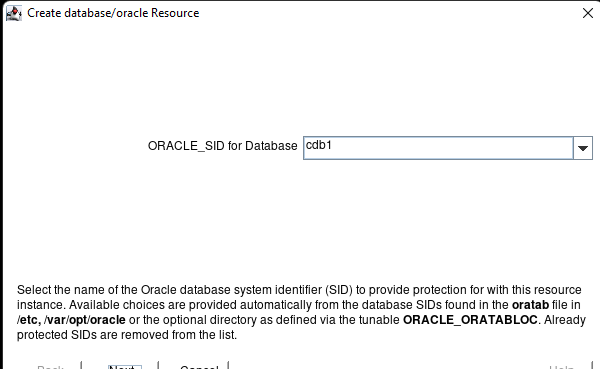
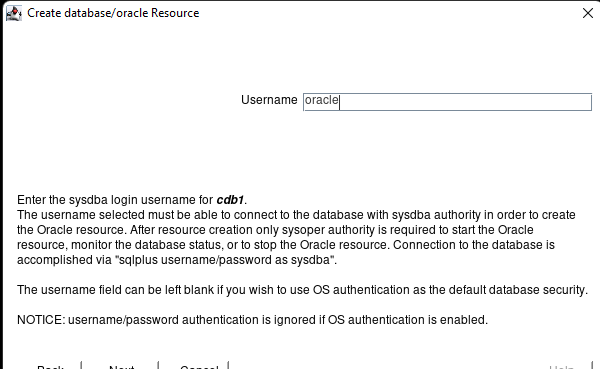
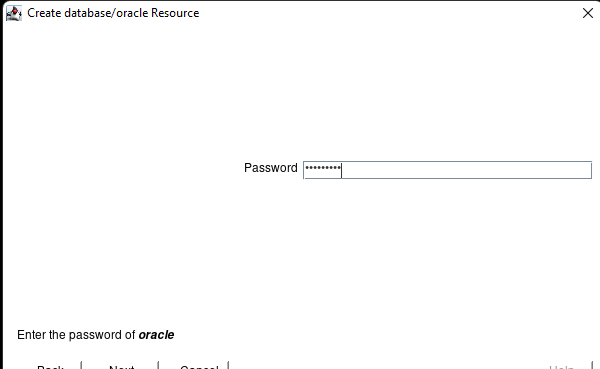
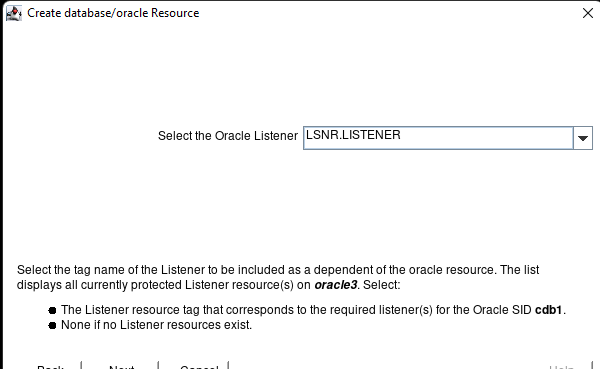
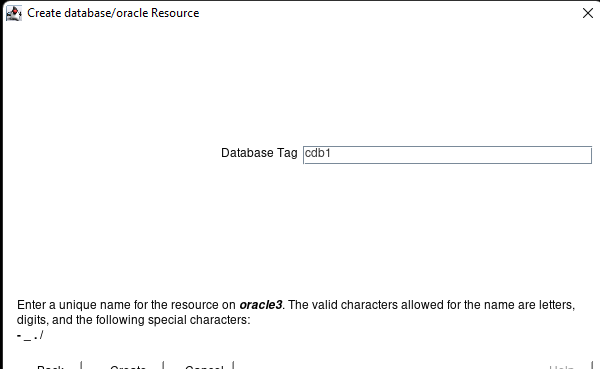
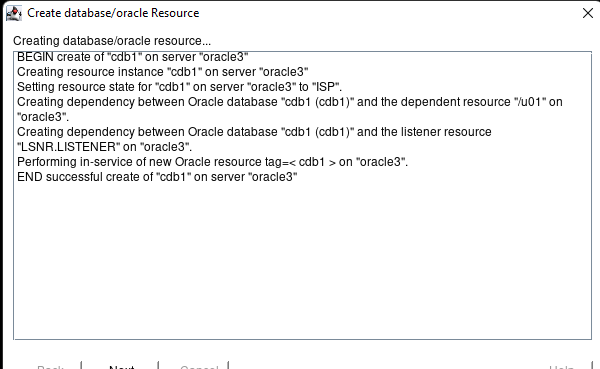
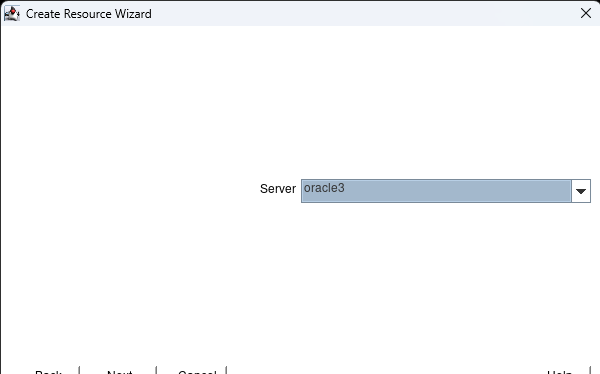
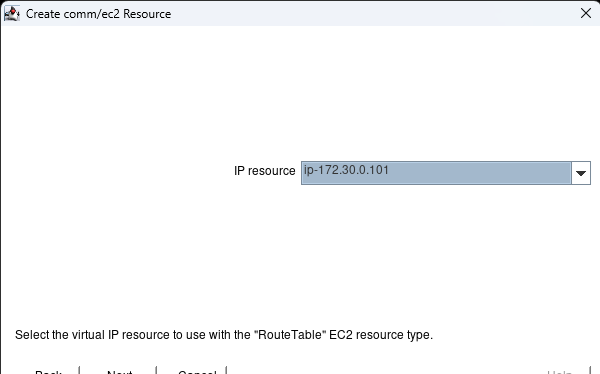
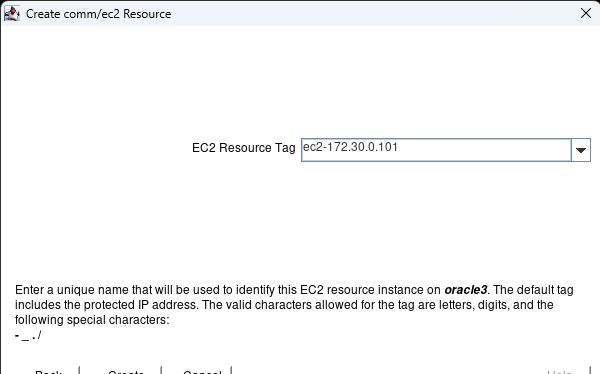
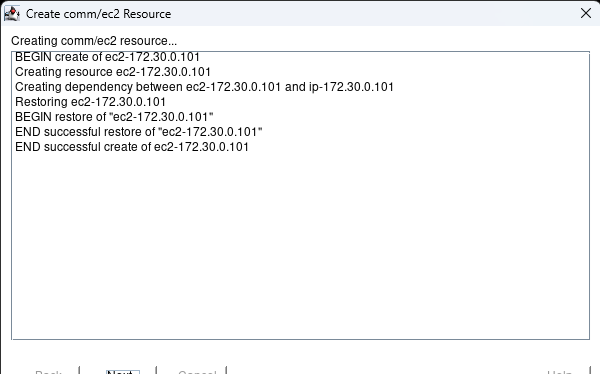
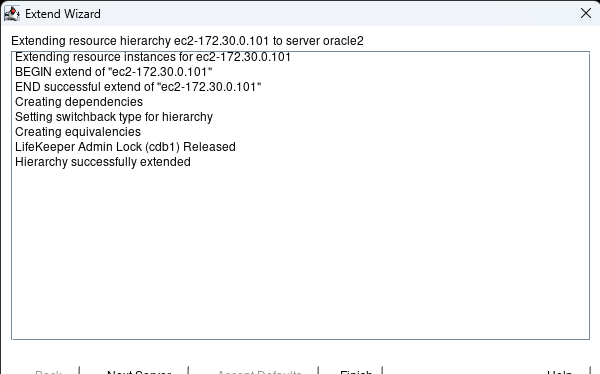
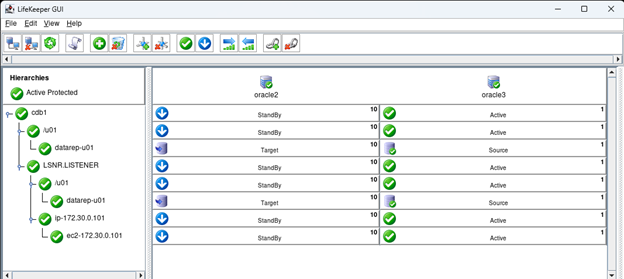
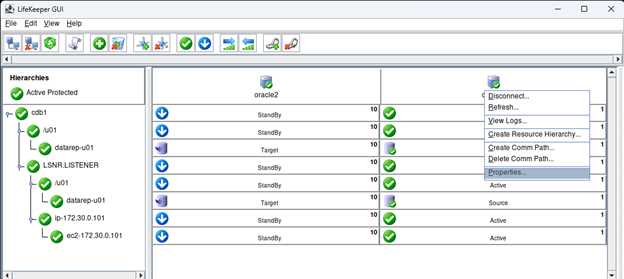
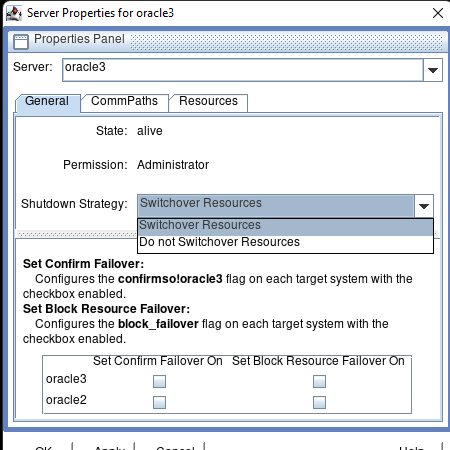
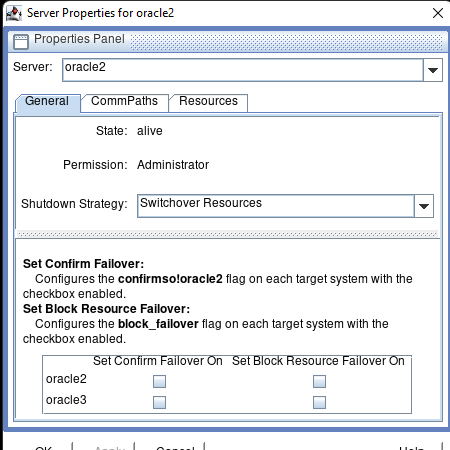
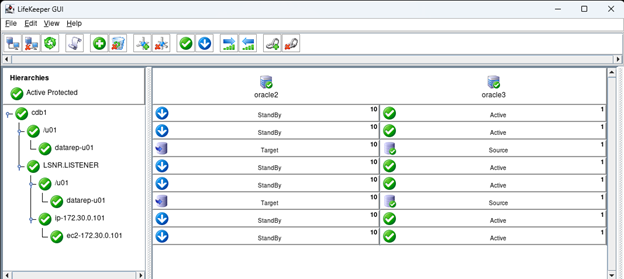
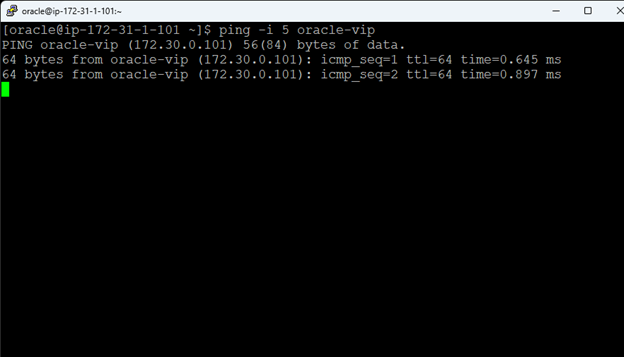
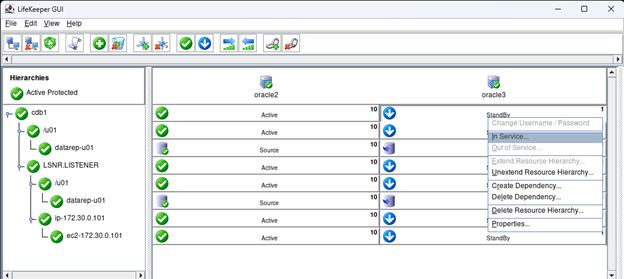
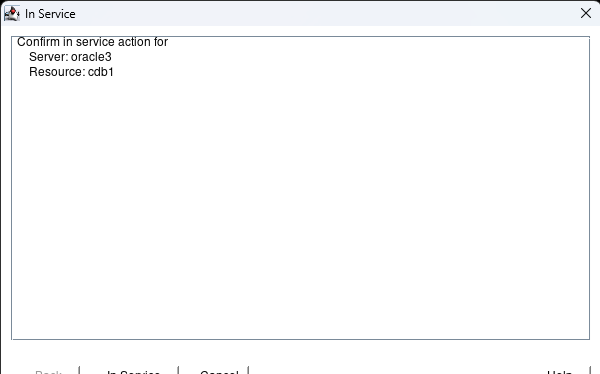
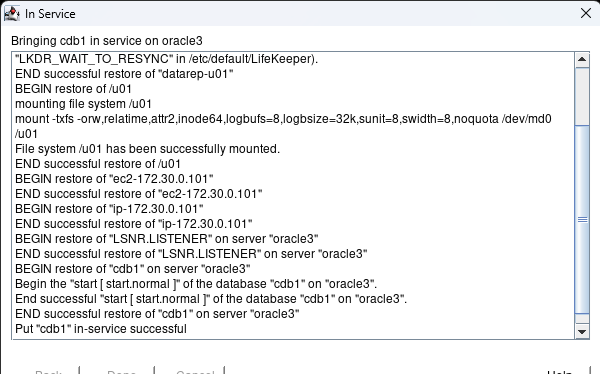
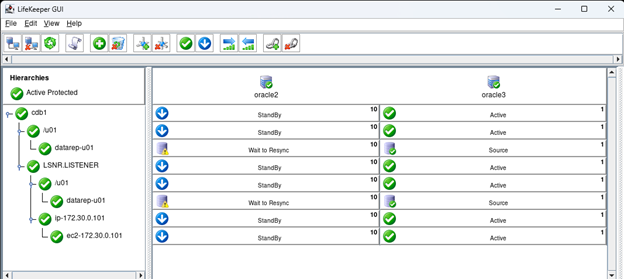
Creating a HA Oracle Database server cluster in AWS |
| December 30, 2022 |
Leading Beverage Manufacturer Protects Critical SAP ERP in AWS EC2 Cloud |
| December 26, 2022 |
Video: How SIOS Ensures High Availability For The Financial Services IndustryVideo: How SIOS Ensures High Availability For The Financial Services Industry In this ongoing series about high availability (HA) and disaster recovery (DR) for various industries, Greg Tucker, Senior Product (Windows) Support Engineer at SIOS Technology, joins us to share his insights about how the company protects the financial industry from downtime and failover. SIOS has a global presence in the financial industry with customers ranging from commercial banking, various brokerage firms, wealth management, CPA firms and so on. No other industry is more mission-critical and sensitive to downtime and failure than the financial industry, with customers relying on critical applications for their online banking systems, ATMs, and payment systems. “We provide failure or clustering software that will protect their critical applications and data from downtime and/or a catastrophic event,” says Tucker. Tucker explains that in essence, the critical applications are deployed on a primary server, whether it be on-prem or in the cloud, as it is clustered with a secondary server or multiple servers. “In the event, the clustering software detects a failure, it will move all the resources over to the secondary node and restore services to the end users automatically; no data loss, no disruption,” he adds. Check out the whole interview above to learn more. Highlights of the discussion:
Solutions
Connect with Greg Tucker (LinkedIn) Reproduced with permission from SIOS |
| December 18, 2022 |
Video: High Availability for Building Management and Security |