| March 11, 2023 |
Cloud Repatriation and HA |
| March 7, 2023 |
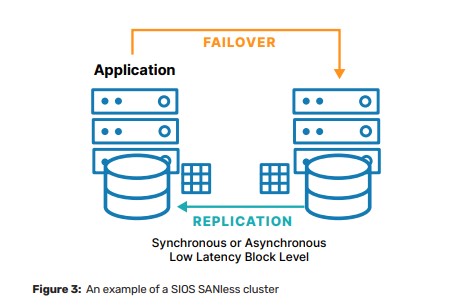
Video: High Availability for State, local government, and education (SLED)Video: High Availability for State, local government, and education (SLED) In this video, Dave Bermingham, SIOS Director of Customer Success, discusses the company’s provision of high availability solutions to state, local government, and education (SLED) organizations. Dave highlights the importance of high availability for SLED organizations, specifically mentioning communication and collaboration tools used by emergency services, financial management systems, student information systems, and learning management systems, which all need to be constantly accessible. He highlights the key features that a high availability solution should have, such as being cost-effective, reliable, providing redundancy, maintaining high-performance levels, detecting failures and performing recovery actions, scalable, and integratable with existing systems and infrastructure. Bermingham gives two examples of SIOS’s SANless clustering solution in action. The first example is how they provided high availability at both the application and data center level to eliminate downtime during university enrollment. The second example is how they worked with an integrator to ensure the call center CAD system was highly available and able to dispatch police, fire, or rescue teams during multiple disasters. It’s important to consider adding a high availability clustering solution like SIOS that can address the application level high availability needs which can then contribute towards maintaining application performance. Reproduce with permission from SIOS |
| March 2, 2023 |
8 Changes That Can Undermine Your High Availability Solution |
| February 28, 2023 |
High Availability Options for SQL Server on Azure VMs |
| February 24, 2023 |
Exploring High Availability Use Cases in Regulated Industries |