
Amazon Web Services에서 SQL Server의 고 가용성 보장
데이터베이스 및 시스템 관리자는 오랫동안 미션 크리티컬 한 데이터베이스 애플리케이션의 가용성을 높이기위한 다양한 옵션을 보유 해왔다. Amazon Web Services에서 제공하는 것과 같은 공용 클라우드 인프라 스트럭처는 서비스 레벨 계약에 따라 자체 고 가용성 옵션을 제공합니다. 그러나 사설 클라우드에서 잘 작동하는 구성은 공용 클라우드에서 가능하지 않을 수 있습니다. 사용 된 AWS 서비스의 선택이 불량하거나 실제로 어떻게 구성되는지에 따라 실제로 필요한 경우 장애 조치 규정이 실패 할 수 있습니다. 이 기사에서는 AWS 클라우드에서 SQL Server의 고 가용성을 보장하기 위해 사용할 수있는 다양한 옵션에 대해 설명합니다.
옵션
데이터베이스 애플리케이션의 경우 AWS는 관리자에게 두 가지 기본 선택을 제공합니다. 각기 다른 Amazon (RDS) 및 Amazon Elastic Compute Cloud (EC2)와 같은 고 가용성 (HA) 및 재해 복구 (DR) 조항이 있습니다.
RDS
RDS는 업무 핵심 응용 프로그램에 적합한 완벽하게 관리되는 서비스입니다. 6 가지 데이터베이스 엔진 중 하나를 선택할 수 있지만 SQL Server에 대한 지원은 Amazon Aurora, My SQL 및 MariaDB와 같은 다른 선택의 경우만큼 강력하지 않습니다. 다음은 업무상 중요한 SQL Server 응용 프로그램에 RDS를 사용하는 관리자의 일반적인 우려 사항입니다.
- 미러링 된 단일 대기 인스턴스 만 지원되며,
- 에이전트 작업은 미러링되지 않으므로 대기 인스턴스에서 별도로 만들어야합니다.
- 데이터베이스 응용 프로그램 소프트웨어로 인해 _ 생한 실패는 _ 견되지 않으며,
- 성능 최적화 된 메모리 내 데이터베이스 인스턴스는 지원되지 않지만,
- 고객이 제어 할 수없는 가용성 할당에 따라 성능에 좋지 않은 영향을 줄 수 있습니다.
- SQL Server의 비싼 Enterprise Edition은 Always On Availability Groups에서만 사용할 수있는 데이터 미러링 기능에 필요합니다.
탄성 계산 클라우드
다른 기본적인 선택은 실질적으로 더 큰 기능을 갖춘 Elastic Compute Cloud입니다. 이는 HA 및 DR이 가장 중요 할 때 선호하는 선택이됩니다. EC2의 가장 큰 장점은 구성에 대해 관리자에게 제공되는 완벽한 제어 기능이며 관리자에게 몇 가지 추가 옵션을 제공한다는 것입니다.
운영 체제 따기
아마도 가장 중요한 선택은 Windows 또는 Linux를 사용할 운영 체제입니다. Windows Server 장애 조치 (Failover) 클러스터링은 Windows에서 표준으로 제공되는 강력하고 입증 된 인기 기능입니다. 그러나 WSFC는 공유 저장 장치가 필요하며 EC2에서는 사용할 수 없습니다. 강력한 HA / DR 보호를 위해서는 Multi-AZ 및 Multi-Region 구성이 필요하기 때문에 서버 인스턴스 클러스터에서 데이터를 복제하려면 별도의 상용 또는 사용자 지정 소프트웨어가 필요합니다. Microsoft의 Storage Spaces Direct (S2D)는 가용성 영역에 걸쳐있는 구성을 지원하지 않으므로 여기서는 선택할 수 없습니다. WSFC와 같은 기본적인 클러스터링 기능이 부족한 Linux의 경우 추가 HA / DR 조항이 더 필요합니다. Linux는 관리자에게 고 가용성에 대해 똑같이 나쁜 선택을합니다. SQL Server의 비싼 Enterprise Edition에 대해 더 많은 비용을 지불하여 Always On Availability Groups를 구현하거나, 또는 오픈 소스 소프트웨어를 사용하는 복잡한 자작 (Do-It-Yourself) HA Linux 구성이 제대로 작동하지 않도록 노력해야합니다.
비교
이러한 선택 모두 공공 클라우드 서비스에서 범용 하드웨어에 대한 오픈 소스 소프트웨어 사용에 대한 비용 절감 근거를 손상시킵니다. Linux 용 SQL Server는 2017 년부터 최신 (및보다 비싼) 버전에서만 사용할 수 있습니다. 그리고 DIY HA 대안은 대부분의 조직에서 엄청나게 비쌀 수 있습니다. 실제로 가능한 모든 장애 시나리오에서 분산 복제 블록 장치, Corosync, Pacemaker 및 선택적으로 다른 오픈 소스 소프트웨어 작업을 응용 프로그램 수준에서 원하는대로 작동시키는 것은 매우 어려울 수 있습니다. 그렇기 때문에 매우 큰 조직 만이 업무 수행을 고려하는 데 필요한 기술 (인력 및 인력)을 갖추고 있습니다. Linux에서 업무상 중요한 HA / DR 규정을 구현하는 것이 어려우므로 AWS는 Elastic Load Balancing과 Auto Scaling을 함께 사용하여 가용성을 향상시킬 것을 권장합니다. 그러나 이러한 서비스에는 관리되는 관계형 데이터베이스 서비스의 제한 사항과 유사한 자체 제한 사항이 있습니다. 이 모든 것이 관리자가 클라우드 환경에서 HA 및 DR 보호를 보장하기 위해 특별히 설계된 장애 조치 (failover) 클러스터링 솔루션을 선택하는 이유를 설명합니다.
장애 조치 클러스터링 목적 – 클라우드를 위해 구축되었습니다.
민간, 공공 및 하이브리드 클라우드의 인기가 높아짐에 따라 클라우드 환경을 위해 구축 된 장애 조치 (failover) 클러스터링 솔루션이 등장했습니다. 이러한 HA / DR 솔루션은 이름에서 알 수 있듯이 응용 프로그램 수준에서 고 가용성을 보장하는 자동 장애 조치 (failover) 기능을 갖춘 서버 및 스토리지 클러스터를 생성하는 소프트웨어로 구현됩니다. 이러한 솔루션의 대부분은 실시간 블록 레벨 데이터 복제, 지속적인 애플리케이션 모니터링 및 구성 가능한 장애 조치 / 장애 복구 (failover / failback) 복구 정책의 조합을 포함하는 완벽한 HA / DR 솔루션을 제공합니다. 좀 더 정교한 솔루션 중 일부는 Windows 및 Linux 용으로 저렴한 SQL Server Standard Edition에서 Always on Failover Cluster 인스턴스를 지원하는 것과 같은 고급 기능도 제공합니다. 또한 WAN 최적화를 통해 다중 지역 성능을 극대화합니다. 계획된 유지 관리를 용이하게하기 위해 기본 및 보조 서버 할당을 수동으로 전환 할 수도 있습니다. 응용 프로그램을 중단하지 않고 정기적 인 백업을 수행하는 기능을 포함합니다. 대부분의 장애 조치 (failover) 클러스터링 소프트웨어는 응용 프로그램에 무관심하므로 조직에서 단일의 범용 HA / DR 솔루션을 보유 할 수 있습니다. 이와 동일한 기능으로 전체 SQL Server 응용 프로그램을 보호 할 수 있습니다. 여기에는 데이터베이스, 로그온, 에이전트 작업 등이 모두 통합 된 방식으로 포함됩니다. 이러한 솔루션은 일반적으로 스토리지 독립적 인 기능을 갖추고있어 공유 스토리지 영역 네트워크에서 작동 할 수는 있지만 잠재적으로 SPOF (Single Point of Failure)를 제거 할 수있는 기능으로 SANless 장애 조치 클러스터링이 일반적으로 선호됩니다. 가용성 또는 성능에 대한 타협없이 SQL Server의 저렴한 Standard Edition에서 FCo (Always On Failover Cluster Instance)를 지원하는 것이 큰 이점입니다. Windows 환경에서 대부분의 장애 조치 클러스터링 소프트웨어는 기본 제공되는 WSFC 기능을 활용하여 FCI를 지원합니다. 따라서 데이터베이스 및 시스템 관리자 모두에게 매우 간단하게 구현할 수 있습니다. Linux는 SQL Server 및 기타 여러 엔터프라이즈 응용 프로그램에서 점점 더 많이 사용되고 있습니다. 일부 장애 조치 (failover) 클러스터링 솔루션은 이제 응용 프로그램 별 통합을 제공하여 Windows와 마찬가지로 쉽게 HA / DR 조항을 구현합니다.
일반적인 3- 노드 SANless 장애 조치 클러스터
다이어그램의 예제 EC2 구성은 세 가지 SQL Server 인스턴스가 서로 다른 가용 영역에있는 VPC (Virtual Private Cloud)로 구성된 일반적인 3- 노드 SANless 장애 조치 클러스터를 보여줍니다. 전체 지역에 영향을 미치는 지역 재난의 중단 가능성을 제거하기 위해 AZ 중 하나는 다른 AWS 지역에 있습니다.
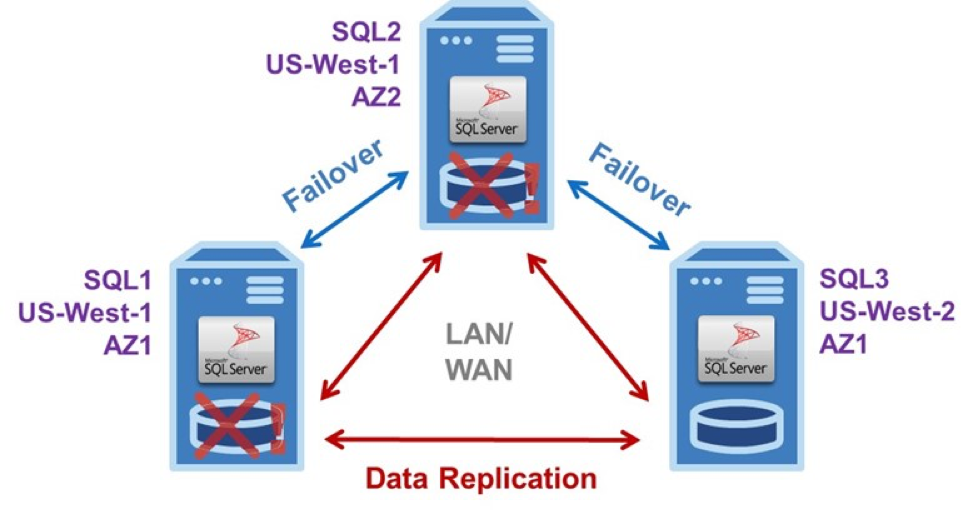
하나의 활성 서버 인스턴스와 두 개의 대기 서버 인스턴스가있는이 3 노드 SANless 장애 조치 클러스터는 최소의 중단 시간과 데이터 손실없이 2 개의 동시 장애를 처리 할 수 있습니다.
3 노드 SANless 장애 조치 클러스터는 캐리어 급 HA 및 DR 보호 기능을 제공합니다. 기본 작동은 Windows 또는 Linux 용 LAN 및 / 또는 WAN에서 동일합니다. 서버 # 1은 초기에 서버 # 2와 # 3 모두에 데이터를 연속적으로 복제하는 기본 또는 활성 인스턴스입니다. 문제가 발생합니다. 그런 다음 서버 # 2에 대한 자동 장애 조치를 트리거합니다. 이제는 서버 # 3에 대한 기본 복제 데이터가됩니다.
오류 감지
인프라 스트럭처 장애로 인해 장애가 발생한 경우 AWS 직원은 문제를 일으킨 원인을 즉시 진단하고 복구 할 것입니다. 일단 고정되면 기본 서버로 복원되거나 서버 # 1 및 # 3에 데이터를 복제하는 용량으로 서버 2를 계속할 수 있습니다. 그림과 같이 서버 # 1이 작동으로 복귀하기 전에 서버 # 2가 실패하면 수동 장애 조치 후에 서버 # 3이 1 차가됩니다. 물론, 애플리케이션 소프트웨어 또는 구성의 특정 측면으로 인해 실패가 발생하면 문제를 찾아 수정하는 것은 고객의 몫입니다. 물론 SANless 장애 조치 클러스터는 단 하나의 대기 인스턴스로 구성 될 수 있습니다. 그러나 최소한의 구성으로는 세 번째 노드가 감시 서버로 작동해야합니다. 증인은 예비 선임 과제를 결정하기위한 정족수를 달성하는 데 필요합니다. 이 중요한 작업은 일반적으로 별도의 AZ에있는 도메인 컨트롤러에서 수행합니다. 서로 다른 AZ에 세 개의 노드 (기본, 보조 및 감시)를 유지하면 영역이 오프라인이 될 때 하나 이상의 투표를 잃을 가능성이 제거됩니다. 또한 HA 및 / 또는 DR 목적으로 하이브리드 클라우드 구성에 2 노드 및 3 노드 SANless 장애 조치 클러스터를 사용할 수도 있습니다. 이러한 3 노드 구성 중 하나는 AWS 로의 비동기 데이터 복제 또는 DR 보호를위한 다른 클라우드 서비스로 엔터프라이즈 데이터 센터에 위치한 2 노드 HA 클러스터로, 그 반대의 경우도 마찬가지입니다. 데이터 복제가 동기 인 단일 영역 내의 클러스터에서는 일반적으로 장애 조치가 자동으로 수행되도록 구성됩니다. 데이터 복제가 비동기적인 여러 영역에 걸쳐있는 노드가있는 클러스터의 경우 일반적으로 데이터 손실 가능성을 피하기 위해 수동으로 장애 조치가 제어됩니다. 사용되는 영역에 관계없이 3- 노드 클러스터는 세 대의 모든 서버에 대해 계획된 하드웨어 및 소프트웨어 유지 관리를 용이하게하는 동시에 응용 프로그램 및 해당 데이터에 대한 지속적인 DR 보호를 제공 할 수 있습니다.
SQL Server의 고 가용성 극대화
AWS Global Infrastructure는 18 개의 지리적 영역에 55 개의 가용 영역을 제공함으로써 지리적으로 분산 된 다중 중복을 통해 SANless 장애 조치 클러스터를 구성함으로써 SQL Server의 고 가용성을 극대화 할 수있는 엄청난 기회를 제공합니다. 또한이 글로벌 발자국은 모든 SQL Server 응용 프로그램과 데이터를 최종 사용자 근처에 배치하여 만족스러운 성능을 제공 할 수있게합니다. 전용 솔루션을 통해 통신 사업자 수준의 고 가용성은 통신 사업자와 같은 높은 비용을 지불 할 필요가 없습니다. 특수 목적의 장애 조치 클러스터링 소프트웨어는 EC2의 컴퓨팅, 스토리지 및 네트워크 리소스를 효과적이고 효율적으로 사용하고 구현 및 운영하기 쉽기 때문에 자본 및 운영 비용을 최소화하므로 고 가용성이보다 강력하고 경제적입니다. 그 어느 때보 다. The NewStack에서 재현 한