| 11월 20, 2020 |
이제 AWS Marketplace에서 SIOS AppKeeper 사용 가능
이제 AWS Marketplace에서 SIOS AppKeeper 사용 가능DevOps 환경에 자동 수정을 더 쉽게 추가 할 수 있습니다.오늘 우리는 Amazon Web Services에서 실행되는 소프트웨어를 쉽게 찾고, 테스트하고, 구매하고, 배포 할 수있는 독립 소프트웨어 공급 업체의 수천 개의 소프트웨어 목록이 포함 된 디지털 카탈로그 인 AWS Marketplace에서 SIOS AppKeeper 솔루션을 사용할 수 있음을 발표하게되어 기쁩니다. (AWS). 이제 최종 사용자와 AWS 파트너 네트워크 (APN) 구성원이 SIOS AppKeeper를 시도, 획득 및 배포하여 DevOps 환경에 자동화 된 치료를 추가하는 것이 그 어느 때보 다 쉬워졌습니다.AWS Marketplace에서 AppKeeper를 보려면 여기를 클릭하십시오. SIOS AppKeeper는 Amazon EC2에서 실행되는 애플리케이션을 지속적으로 모니터링하고 보호합니다. 2017 년부터 일본에서 AppKeeper를 판매하고 있으며 올해 초 미국 시장에 SaaS 서비스를 도입했습니다.우리는 클라우드로 이전하고 제한된 리소스로 어려움을 겪으면서 잠재적 인 다운 타임을 줄이는 데 관심이있는 고객의 요구에 부응하여 AppKeeper를 만들었습니다. AppKeeper를 설치하고 사용하는 것이 얼마나 쉬운 지에 대한 비디오를 보려면 여기를 클릭하십시오.
AWS EC2 애플리케이션 모니터링 – SIOS AppKeeper | SIOS Amazon EC2 사용자는 얼마나 자주 다운 타임을 경험합니까? 고객 데이터에 따르면 Amazon EC2 인스턴스가 3 개 뿐인 일반 고객은 적어도 한 달에 한 번 다운 타임을 경험합니다.이는 소프트웨어 구성 실수 등으로 인한 것일 수 있습니다. 응용 프로그램 모니터링을 넘어 자동화 된 문제 해결 제공많은 AWS 사용자가 AppDynamics, Datadog, Dynatrace 또는 New Relic과 같은 애플리케이션 성능 모니터링 (APM) 솔루션을 배포하여 AWS 환경을 모니터링하고 있습니다.그러나 이것들은 어떤 일이 일어났다는 사실과 왜 일어 났는지에 대해서만 경고합니다. 다운 타임을 줄이기 위해 아무것도하지 않습니다. 바로 AppKeeper가 등장합니다. AppKeeper가 Amazon EC2에서 실행중인 애플리케이션 서비스에서 가동 중지 시간을 감지하면 영향을받는 서비스를 다시 시작하고 필요한 경우 인스턴스를 재부팅하여 자동으로 응답합니다. AppKeeper는 응용 프로그램 서비스 오류의 85 %를 해결합니다. 자동화 된 복구를 통해 IT 팀에 대한 값 비싼 아웃소싱 모니터링 또는 산만 함의 필요성을 줄입니다.AppKeeper에서 APM 자동화에 대해 자세히 알아보세요. 이미 APM 솔루션을 사용하고 있고 Amazon EC2 가동 중지 시간이 감지되면 자동 교정을 포함하도록 기능을 확장하려는 AWS 고객은 AppKeeper의 웹훅 API를 활용하여 선택한 APM 솔루션과 통합 할 수 있습니다. SIOS AppKeeper를 AWS Marketplace에 등록하기로 결정한 이유여기 SIOS Technology Corporation에서는 2014 년부터 주로 SIOS DataKeeper 및 SIOS LifeKeeper 고 가용성 솔루션을 중심으로 Amazon AWS와 전략적 파트너십을 맺었습니다.SIOS Technology는 현재 APN 어드밴스드 파트너이며 100 명의 공동 고객을 공유합니다. 이제 SIOS AppKeeper의 효과에 대한 고객 증명을 얻었으므로 (여기에 여러분이 좋아할만한 최근 사례 연구가 있습니다) Amazon 고객과 APN 파트너가 AppKeeper를 더 쉽게 사용하고 구매하고 사용할 수 있도록하고 싶었습니다.많은 추산에 따르면 AWS Marketplace의 소프트웨어를 사용하는 활성 AWS 고객은 200,000 명 이상이며, 이들은 모두 AWS Marketplace가 클라우드 여정을 계속하면서 보완 솔루션을 얼마나 쉽게 검색, 획득 및 사용할 수 있는지를 활용하고 있습니다. 그리고 Amazon의 우리 친구들은 더 나은 말을 할 수 없었을 것입니다. "우리 고객이 점점 더 많은 애플리케이션을 클라우드로 마이그레이션함에 따라 가용성 수준과 모든 애플리케이션의 비용을 균형있게 조정할 수있는 유연성을 찾고 있습니다."라고 Chris Grusz는 말했습니다. AWS Marketplace, Amazon Web Services, Inc. 이사“SIOS AppKeeper를 AWS Marketplace로 환영하고 성능 변화가 발생할 때 고객에게 더 많은 선택권을 제공하게되어 기쁩니다.” 불필요한 다운 타임으로부터 EC2 애플리케이션을 보호하는 데 관심이있는 AWS 고객은 이제 신속하게 AppKeeper를 사용해 볼 수 있으며, Amazon Enterprise 할인 플랜이있는 경우 AppKeeper를 구입할 수 있습니다.SIOS AppKeeper의 가격은 인스턴스 당 월 40 달러부터 시작됩니다. 파트너는 이제 AppKeeper를 고객 솔루션에 통합하고 있습니다.이제 다양한 파트너가 AppKeeper를 고객 솔루션에 통합하고 있으며, AWS Marketplace에서 AppKeeper를 사용할 수 있다는 것은 APN 멤버가 솔루션이 비즈니스와 고객에게 적합한 지 평가하기가 더 쉬워 짐을 의미합니다. 관리 형 서비스 제공 업체 (MSP)는 다운 타임과 자체 운영 비용을 줄이기위한 방법으로 고객의 AWS 환경을 모니터링하고 관리하는 방법에 AppKeeper를 포함하기 시작했습니다.다른 ISV는 AppKeeper의 자동화 된 치료 기능을 자체 클라우드 관리 솔루션에 통합하고 있으며 AWS 컨설팅 파트너는 고객을 위해 AWS에서 애플리케이션을 개발하고 배포 할 때 AppKeeper를 패키징하고 있습니다. AppKeeper가 자신의 비즈니스에 적합한 지 평가하려는 APN 회원은 이메일 (d-yoshioka@us.sios.com)로 문의해야합니다. SIOS AppKeeper를 직접 사용해보고 (14 일 무료 평가판과 간편한 설치 프로세스가 제공됨) Amazon EC2 가동 중지 시간을 줄이기 위해 자동화 된 교정이 마련되어 있다는 사실을 알고 안심하고있는 많은 고객과 함께하십시오. 경험할 수 있습니다. |
| 11월 12, 2020 |
APM 자동화 – 애플리케이션 성능 모니터링 솔루션을위한 누락 된 요소
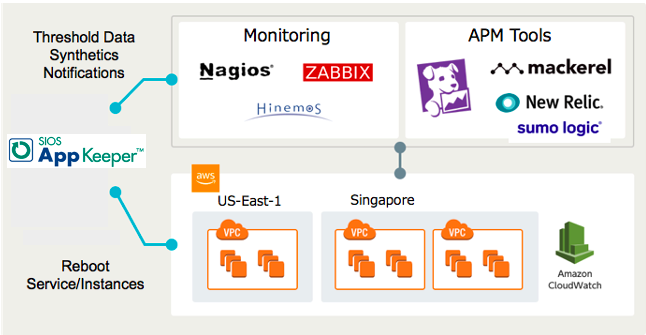
APM 자동화 – 애플리케이션 성능 모니터링 솔루션을위한 누락 된 요소애플리케이션을 호스팅하기 위해 클라우드로 전환하는 회사는 애플리케이션 호스팅을 Amazon Web Services와 같은 타사 클라우드 공급 업체에 아웃소싱했지만 일반적으로 애플리케이션 성능 모니터링을 통해 해당 애플리케이션을 직접 모니터링하고 관리해야한다는 점을 이해합니다. 솔루션 또는 APM. 어제의 클라이언트-서버 컴퓨팅 애플리케이션 인 I.T. 부서는 서버, 네트워크 및 최종 사용자 컴퓨팅 환경을 거의 완벽하게 제어했습니다.하지만 오늘날의 클라우드 환경은 더 복잡 해져서 제어 할 수없는 움직이는 부분이 더 많습니다. 일부 회사는 디지털 전환에 착수하여 고객 상호 작용을 중요한 웹 기반 애플리케이션으로 밀어 넣었습니다.이제 APM 자동화 솔루션을 통해 모든 애플리케이션 성능 및 다운 타임 문제에 신속하게 대응하는 것이 그 어느 때보 다 중요합니다. APM 솔루션을 선택하는 방법많은 회사에서 AppDynamics, Datadog, Dynatrace 또는 New Relic과 같은 애플리케이션 성능 관리 솔루션을 사용합니다.APM 솔루션은 코드에서 성능 병목 현상을 식별하고 사용자가 영향을 받기 전에 이러한 문제를 해결하는 데 도움이됩니다. 좋은 APM 솔루션은 어떤 일이 일어 났는지, 왜 그런지, 그리고 미래에 이런 일이 발생하지 않도록 방지하는 방법을 알려줍니다.APM 솔루션은 모니터링중인 애플리케이션 또는 시스템이 특정 조건 (부하, 응답 시간 등)을 충족 할 때 경고합니다.경고를 받으면 응용 프로그램이 제대로 작동하지 않는 이유를 식별 할 수 있어야합니다.이 정보로 무장하면 개발 팀이 문제를 해결하고 향후 문제가 발생하지 않도록하는 매우 상세한 진단을 제공 할 수 있습니다. 그러나 올바른 애플리케이션 성능 모니터링 솔루션 솔루션을 어떻게 선택합니까?Google에서 "클라우드 APM 솔루션"을 빠르게 검색하면 5,830,000 개의 결과가 반환됩니다!공간에 익숙하지 않은 사람에게는 압도적 일 수 있습니다.고맙게도 또 다른 Google 검색은 귀하에게 적합한 APM 솔루션을 선택하는 방법에 대한 많은 조언과 리소스를 제공합니다.요구 사항을 구성하고 이러한 요구 사항을 충족하는 짧은 선택 목록을 개발하는 데 도움이되는 타사의 비 공급 업체 조언을 찾아야합니다.Gartner는이 카테고리를 한동안 지켜보고 있으며 매년 APM Magic Quadrant를 게시합니다.애플리케이션 성능 모니터링 솔루션 솔루션을 평가하는 방법을 이해하고 최고 공급 업체에 대한 좋은 개요를 제공하는 방법을 이해하는 데 유용한 리소스입니다. 수정 요구 사항 목록에 APM 자동화 추가여기 SIOS Technology Corporation에서는 애플리케이션을 클라우드로 마이그레이션하는 고객과 항상 협력하고 있습니다.그들은 종종 불필요한 다운 타임으로부터 애플리케이션을 보호하는 방법을 알고 싶어하고 저희에게 조언을 요청합니다.애플리케이션을 보호하는 방법의 선택은 해당 애플리케이션의 중요도에 따라 결정됩니다 (더 중요한 애플리케이션에는 종종 장애 조치 솔루션 등이 필요함). 그러나 우리는 또한 그들의 애플리케이션이 취약한 이유를 이해하도록 도와줍니다. 이전에는 백업 및 데이터 보호가 별도의 기능이었습니다 (APM 솔루션이 다운 타임을 식별 한 경우에만 필요했던 기능).그러나 오늘날의 복잡한 클라우드 환경에서는 조직이 중요한 애플리케이션을 모니터링하고 관리 할 때 전체적인 접근 방식을 찾아야한다고 생각합니다.기존 APM 솔루션이 문제가 발생하는시기를 식별하고 그 원인을 진단 할 수있게 해준다면 가능한 경우 불필요한 다운 타임을 방지하지 못하는 이유는 무엇인가요? 자동화는 대부분의 클라우드 APM 솔루션에서 누락 된 요소라고 믿습니다.많은 고객이 APM 솔루션에서 너무 많은 경고를 수신하여 어떻게 압도 당하고 있는지 알려주며, 각각은 중단하고 발생한 일과 이유를 이해해야합니다.그들은 무엇을 무시하고 무엇에주의를 기울여야하는지 빠르게 이해합니다 (그리고 좋은 APM 솔루션은 기계 학습을 통해이를 수행하는 데 도움이됩니다).또한 애플리케이션이 다운되면 APM 솔루션은 다운 타임에 대해 경고하고 다시 발생하지 않도록 도와야하는 이유를 진단합니다.그러나 APM 솔루션은 즉각적인 다운 타임을 줄이지 않습니다. 이것이 바로 SIOS AppKeeper가 등장하는 곳입니다. AppKeeper는 Amazon EC2에서 실행되는 고객의 애플리케이션을 모니터링하고 EC2에서 서비스를 자동으로 다시 시작하거나 가동 중지 시간이 감지되면 EC2 인스턴스를 재부팅합니다.Amazon EC2 인스턴스가 3 개 뿐인 평균 고객은 적어도 한 달에 한 번 다운 타임을 경험합니다.이는 중요하고 종종 고객을 대상으로하는 애플리케이션을 사용할 수없는 경우와 I.T. 팀은 모든 것을 버리고 대응해야합니다. AppKeeper의 APM 자동화 솔루션은 고객이 Amazon EC2 다운 타임 상황의 85 % 이상을 자동으로 복구 할 수 있도록합니다.AppKeeper가 작동하는 모습을보고 싶다면 빠른 동영상 링크가 있습니다. AppKeeper의 API를 통해 고객은 APM 솔루션의 알림이 AppKeeper를 트리거하여 영향을받는 Amazon EC2 서비스를 자동으로 다시 시작하거나 필요한 경우 인스턴스를 재부팅하도록함으로써 APM 솔루션의 가치를 프로그래밍 방식으로 확장하고 있습니다.
애플리케이션 성능 모니터링 및 자동화 된 수정.땅콩 버터와 젤리보다 낫습니까?대부분의 경우 AppKeeper 고객은 Amazon EC2 인스턴스가 8 개 미만인 Amazon EC2 환경을 쉽게 관리 할 수 있습니다.이들에게는 AppKeeper의 기본 모니터링 및 자동화 된 치료 기능으로 인해 다운 타임이 발생하는 경우 사전에 감소하고 있음을 알기 때문에 밤에 푹 잠들 수 있습니다. 그러나 우리는 많은 고객이보다 정교한 클라우드 환경을 보유하고 있으며 New Relic, Datadog, Dynatrace, LogicMonitor 또는 Zabbix와 같은 APM 솔루션에 이미 투자 한 것으로 알고 있습니다.그들은 무슨 일이 일어 났고 왜 일어 났는지 진단하는 데 도움이되는 즉각적인 경고와 풍부한 데이터 세트를 기대하게되었습니다.이 고객들은 APM 툴킷에 AppKeeper의 자동 치료 기능을 추가함으로써 애플리케이션 성능 제어와 다운 타임 감소라는 두 가지 장점을 모두 누릴 수 있다고 생각합니다. 향후 몇 개월 동안 SIOS Technology는 여러 주요 APM 공급 업체와 협력하여 APM 솔루션과 AppKeeper 간의 패키지 및 인증 통합을 제공 할 것입니다.이러한 AppKeeper와의 통합을 사용하면 이러한 사용자는 이제 폐쇄 루프 시스템을 즐길 수 있으며, 여기에서 감지 된 Amazon EC2 다운 타임과 AppKeeper가 취한 교정 조치에 대한 알림을 받게됩니다. 그러니 흥미로운 소식을 기대해주세요.한편, SIOS AppKeeper를 직접 사용해보고 싶다면 AppKeeper 14 일 무료 평가판에 자유롭게 등록하세요. AppKeeper는 인스턴스 당 월 40 달러부터 시작합니다. SIOS의 허가를 받아 복제 |
| 10월 25, 2020 |
SIOS 고 가용성 소프트웨어를 구매하지 않는 6 가지 이유. . . 감히 |
| 10월 19, 2020 |
Amazon EC2에서 호스팅되는 WordPress 사이트의 가동 중지 시간 줄이기 |
| 9월 27, 2020 |
클라우드로 마이그레이션 하시겠습니까? Amazon EC2로 이동할 때 DevOps 우선 순위가 어떻게 변경되어야하는지 다음과 같습니다. |





 많은 WordPress 모니터링 솔루션 (무료 플러그인에서 저렴한 부분 유료 서비스에 이르기까지)은 WordPress 사이트가 다운되면 알려줍니다.모니터링 솔루션의 정교함 (및 비용)에 따라 WordPress 사이트가 다운 된 이유를 알 수 있습니다.하지만 다운 타임을 줄이고 서비스를 자동으로 다시 시작하거나 다운 타임이 발생했을 때 인스턴스를 재부팅하는 데 도움이 될까요?
많은 WordPress 모니터링 솔루션 (무료 플러그인에서 저렴한 부분 유료 서비스에 이르기까지)은 WordPress 사이트가 다운되면 알려줍니다.모니터링 솔루션의 정교함 (및 비용)에 따라 WordPress 사이트가 다운 된 이유를 알 수 있습니다.하지만 다운 타임을 줄이고 서비스를 자동으로 다시 시작하거나 다운 타임이 발생했을 때 인스턴스를 재부팅하는 데 도움이 될까요?