| 12월 22, 2020 |
클라우드 마이그레이션이 중단 된 6 가지 이유 |
||||
| 12월 18, 2020 |
클라우드에서 애플리케이션 가용성 계산
클라우드에서 애플리케이션 가용성 계산클라우드에 비즈니스 크리티컬 애플리케이션을 배포 할 때 가용성이 높은지 확인하려고합니다. 좋은 소식은 제대로 계획하면 99.99 % (4-9) 이상의 가용성을 달성 할 수 있다는 것입니다. 그러나 실제 가용성을 계산하는 것은 생각만큼 간단하지 않을 수 있습니다. 가용성을 고려할 때 애플리케이션에 대한 액세스를 가능하게하는 주요 구성 요소를 고려해야합니다.이를 가용성 체인이라고합니다. 가용성 체인의 구성 요소는 다음과 같습니다.
애플리케이션은 가장 약한 링크만큼만 사용할 수 있으며, 체인에 링크를 추가 할 때마다 다운 타임이 기하 급수적으로 증가합니다.각 링크를 살펴 보겠습니다. 컴퓨팅 가용성세 가지 주요 클라우드 서비스 공급자는 각각 몇 가지 유사점이 있습니다. 세 가지 플랫폼에서 공통적으로 사용되는 한 가지는 컴퓨팅에 대해 약속 할 SLA (서비스 수준 계약)입니다. 서로 다른 가용성 영역에 구성된 두 개 이상의 VM이있는 경우 VM에 대한 세 가지 공용 클라우드 공급자 모두에 대한 SLA는 99.99 %입니다.이 SLA는 주어진 시간에 VM 중 하나의 원격 액세스 가능성 만 보장하며 VM 내에서 실행되는 서비스 또는 애플리케이션의 가용성에 대해서는 약속하지 않습니다.단일 데이터 센터 내에 단일 VM을 배포하는 경우이 SLA는 "시간당 90 %"(AWS)에서 99.5 % (Azure 및 GCP) 또는 99.9 % (프리미엄 SSD 사용시 Azure 단일 VM)까지 다양합니다. 진정한 고 가용성은 99.99 %에서 시작하므로 애플리케이션을 사용할 수 있는지 확인하는 첫 번째 단계는 애플리케이션이 가용성 영역에 걸쳐있는 두 개 이상의 VM에 분산되어 있는지 확인하는 것입니다. 두 개의 VM이 두 개의 가용 영역에 분산되어 있으므로 해당 VM 중 하나 이상에 대해 99.99 %의 가용성을 제공하는 경우 세 개의 가용 영역에 분산 된 세 개의 VM이있는 경우 가용성이 99.99 %보다 훨씬 더 크다는 이론을 세울 수 있습니다. 클라우드 제공 업체의 SLA는 사용중인 가용성 영역의 수에 관계없이 99.99 % 이상의 가용성을 보장하지 않지만 순수 통계를 사용하면 가용성이 99.999999 % 또는 8-99 %까지 증가 할 수 있다는 결론에 도달 할 수 있습니다. 가용성, 월 26.30 밀리 초의 다운 타임. 1-(. 0001 * .0001) = .99999999 3 개의 가용 영역으로 99.999999 % 가용성? 그 숫자를 인용하지 마세요. 하지만 두 개의 가용 영역이 99.99 %의 가용성을 제공 할 수 있다는 점을 명심하십시오. 3 개의 가용성 영역이 99.99 % 이상의 가용성을 제공 할 것이라는 것은 당연합니다. 컴퓨팅은 가용성 체인에서 하나의 링크 일뿐입니다. 우리는 여전히 네트워크, 스토리지 및 기타 종속 서비스를 처리해야하며, 이는 모두 가능한 장애 지점을 나타냅니다. 네트워크 가용성애플리케이션을 사용할 수 있으려면 클라이언트와 애플리케이션 간의 모든 네트워크 홉과 애플리케이션이 의존하는 모든 리소스가 사용 가능하고 허용 가능한 대기 시간 범위 내에서 작동해야합니다. 네트워크가 실패 할 수있는 위치를 정확하게 파악하려면 데이터베이스 서버, 애플리케이션 서버, 웹 서버 및 클라이언트 간의 네트워크 링크를 이해해야합니다. 가용성 체인에 링크가 많을수록 전체 가용성이 낮아집니다. 동일한 vNet에있는 VM 간의 네트워크 가용성은 표준 컴퓨팅 SLA에 포함되지만 다른 네트워크 서비스를 활용할 수도 있습니다. 다음은 전체 애플리케이션 가용성에 영향을 미칠 수있는 네트워크 서비스의 몇 가지 예입니다. 급행 노선 – 99.95 % 지금까지 배운 내용을 바탕으로 두 가용 영역에 배포 된 애플리케이션의 가용성을 살펴 보겠습니다. 99.99 % 컴퓨팅 가용성 99.99 %로드 밸런서 가용성 .9999 * .9999 = .9998 99.98 % 가용성 = 월별 다운 타임 최대 9 분 컴퓨팅 및 네트워크 가용성에 대해 다루었으므로 이제 스토리지로 이동하겠습니다. 스토리지 가용성이제 여기에서 이야기가 조금 더 복잡해집니다. 다음 스토리지 SLA를 살펴보십시오. https://azure.microsoft.com/en-us/support/legal/sla/storage/v1_5/ https://cloud.google.com/storage/sla https://aws.amazon.com/compute/sla/ Azure와 Google이 블록 스토리지 솔루션에 대해 99.9 %의 SLA를 제공하고 있음이 분명해 보입니다. AWS는 여기서 EBS를 구체적으로 언급하지 않습니다. VM에 대해 이야기하고 다른 클라우드 제공 업체와 마찬가지로 월 단위가 아닌 시간 단위로 단일 인스턴스 VM 가용성을 측정합니다. 논의를 위해 Azure와 GCP가 모두 게시 한 99.9 % 가용성 보장을 사용하겠습니다. 이전 예제를 바탕으로 방정식에 저장 공간을 추가해 보겠습니다. 99.99 % 컴퓨팅 가용성 99.99 %로드 밸런서 가용성 99.9 % 관리 디스크 .9999 * .9999 * .999 = .9988 99.88 % 가용성 = 매월 약 53 분의 다운 타임. 53 분의 다운 타임은 이전 예제에서 계산 한 9 분의 다운 타임보다 훨씬 큽니다. 99.9 % 스토리지 가용성의 영향을 최소화하려면 어떻게해야합니까? 우리는 스토리지에 더 많은 중복성을 구축해야합니다! 다행히 애플리케이션 가용성을 계획 할 때 일반적으로 스토리지 중복성을 포함합니다. 예를 들어 웹 서버를 세우면 각 웹 서버는 일반적으로 로컬로 연결된 디스크에 데이터를 저장합니다. 도메인 컨트롤러를 배포 할 때 Microsoft Active Directory는 모든 도메인 컨트롤러에서 AD 정보를 복제합니다. SQL Server와 같은 경우에는 Always On 가용성 그룹 또는 SIOS DataKeeper를 활용하여 로컬에 연결된 디스크에서 데이터를 동기화 상태로 유지합니다. 여러 가용 영역에 배포 한 데이터 사본이 많을수록 장애에서 살아남을 가능성이 높아집니다. 예를 들어 서로 다른 가용성 영역에있는 두 개의 서로 다른 디스크에 데이터를 저장하는 애플리케이션은 중복성의 이점을 얻을 수 있으며 99.9 % 가용성 대신 99.9999 %의 스토리지 가용성을 달성 할 가능성이 높습니다. 1 – (.001 * .001) = .999999 이것을 앞의 방정식에 넣으면 그림이 조금 더 밝아지기 시작합니다. .9999 * .9999 * .999999 = .9998 99.98 % 가용성 = 최대 9 분의 다운 타임 여러 AZ, 즉 여러 디스크에 걸쳐 데이터를 복제함으로써 클라우드 스토리지와 관련된 가동 중지 시간을 효과적으로 완화했습니다. 애플리케이션 및 종속 서비스 가용성컴퓨팅, 네트워크 및 스토리지 가용성을 보장하기 위해 할 수있는 모든 작업을 수행했습니다. 하지만 애플리케이션 자체는 어떻습니까? 일부 애플리케이션은 동일한 애플리케이션의 여러 인스턴스간에 부하를 분산하여 확장하고 중복성을 제공 할 수 있습니다. 일반적으로 5 개의 서버간에 웹 요청 부하를 분산 할 수있는 일반적인 웹 서버 팜을 생각해보십시오. 서버 하나가 손실되면로드 밸런서가 다시 응답 할 때까지 순환에서 서버를 제거합니다. 다른 응용 프로그램은 좀 더 많은 관리와 모니터링이 필요합니다. 예를 들어 SQL Server를 사용하십시오. 일반적으로 Always On 가용성 그룹 또는 장애 조치 클러스터 인스턴스는 데이터베이스 가용성을 모니터링하고 응용 프로그램 또는 시스템 수준 오류로 인해 데이터베이스가 응답하지 않는 경우 복구 작업을 수행하는 데 사용됩니다. SQL Server 가용성 솔루션에 대해 게시 된 SLA는 없지만 고 가용성을 위해 적절하게 구성하면 SQL Server가 99.99 %의 가용성을 제공 할 수 있다는 것이 일반적으로 받아 들여집니다. 호스팅 된 Active Directory, 호스팅 된 DNS, 마이크로 서비스와 같은 다른 클라우드 기반 서비스에 의존 할 수 있으며, 클라우드 포털 자체의 가용성까지도 전체 가용성 방정식에 반영해야합니다. 요약애플리케이션 가용성은 모든 움직이는 부품의 합계입니다. 한 영역 만 스킴은 애플리케이션의 전체 가용성에 기하 급수적으로 영향을 미칠 수 있습니다. 시간을내어 컴퓨팅, 네트워크, 스토리지, 애플리케이션 및 종속 서비스를 포함한 약점에 대한 가용성 체인의 모든 링크를 조사하십시오. 일반적으로 여기에 제시된 수치는 최악의 시나리오이며 실제 가용성은 게시 된 SLA를 초과해야합니다. 숙제를하고 고 가용성으로 간주되는 일반적인 임계 값 인 99.99 % 가용성을 보장 할 수없는 서비스에주의하십시오. 인적 오류 및 보안은이 기사에서 다루지 않았습니다. 애플리케이션을 가능한 한 고 가용성으로 만들 수 있습니다. 그러나 외부 위협과 어리석은 인간의 실수로부터 애플리케이션을 보호하기위한 조치를 취하지 않은 경우 가용성과 관련하여 모든 베팅이 해제됩니다. |
||||
| 12월 11, 2020 |
Amazon EC2 모니터링에 Datadog을 사용하십니까? 자동화 된 수정을 위해 SIOS AppKeeper와 페어링 |



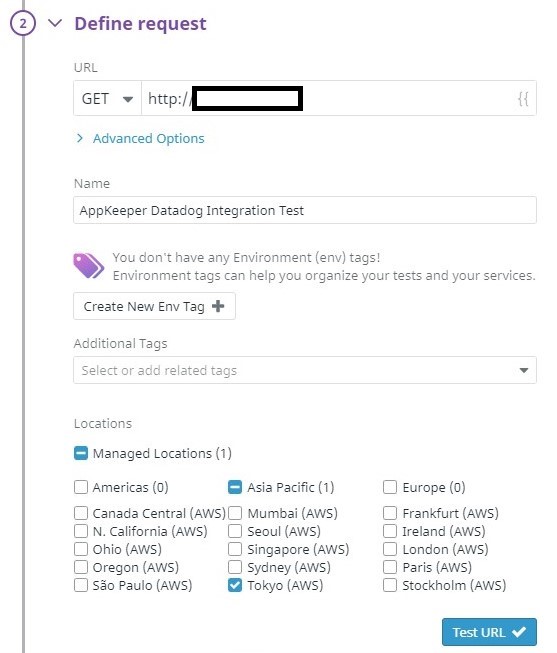
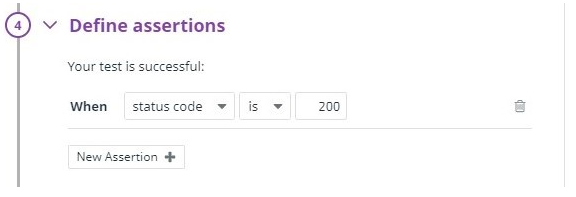
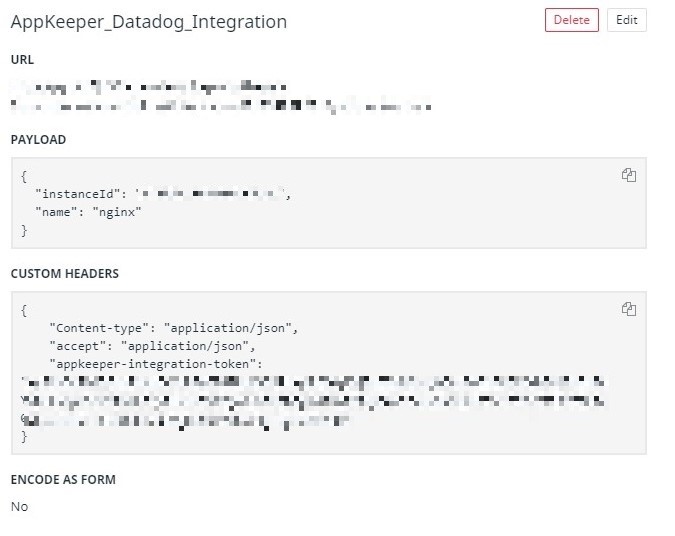
 "구성"을 클릭하여 Webhook 통합 구성 페이지를 엽니 다.
"구성"을 클릭하여 Webhook 통합 구성 페이지를 엽니 다.| {
“instanceId”:“{{EC2 Instance ID}}”, "이름": "nginx" } |
맞춤 헤더 : 체크 박스를 선택하고 다음을 입력합니다.
| { “Content-type”:“application / json”, “accept”:“application / json”, "appkeeper-integration-token": "{{AppKeeper 외부 통합 토큰 가져 오기}}에서 얻은 토큰" } |
완료되면 "저장"을 누르십시오.
8 단계 : AppKeeper를 합성 테스트에 연결
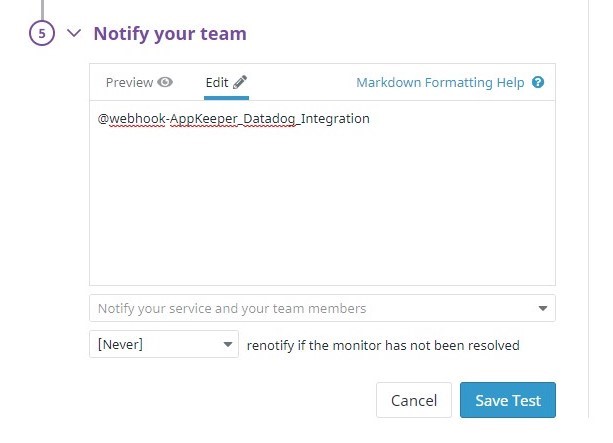
다음으로 Synthetics 모니터링 경고가 발생할 때 호출되도록 AppKeeper (등록 된 Webhooks 통합)를 구성해야했습니다.
메뉴의 UX Monitoring> Synthetic Tests에서 "Configuring the Synthetic Monitoring with Datadog"에서 설정 한 테스트 케이스를 엽니 다.
오른쪽 상단 기어 박스에서 "테스트 세부 정보 편집"을 선택하고 "5. Notify Your Team”상자를 눌러 변경 사항을 저장하십시오.
| @webhook-{{Datadog의 Webhook 통합 이름}} |
※“모니터가 해결되지 않은 경우 다시 알림”을 설정할 수 있습니다.AppKeeper가 처음으로 복구에 실패하면 다시 시도 할 수 있습니다.테스트 목적으로는 필요하지 않지만 (최소 간격)으로 설정하는[10 minutes] 것이 좋습니다.
이제 설치가 완료되었습니다.
9 단계 : 테스트를 다시 실행하여 통합 확인
그런 다음 Datadog이 다운 된 것으로 감지되면 AppKeeper가 웹 서버를 복원 할 것임을 확인했습니다.
UX Monitoring> Synthetic Tests in Datadog에서 방금 설정 한 Synthetics 모니터링 테스트 케이스를 엽니 다.
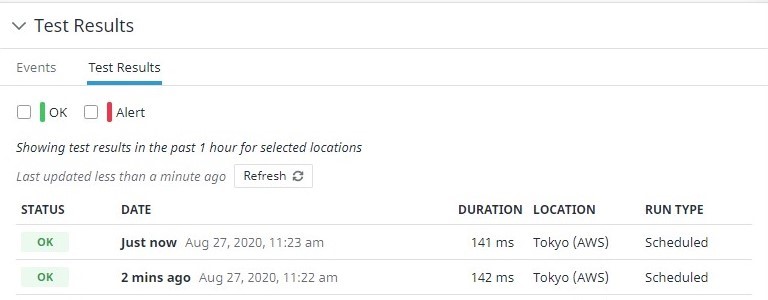
오른쪽 상단의 "Resume Test"를 클릭하고 Synthetics 모니터링을 켭니다.

이제 Datadog은 정기적으로 Synthetics 모니터링을 수행합니다.
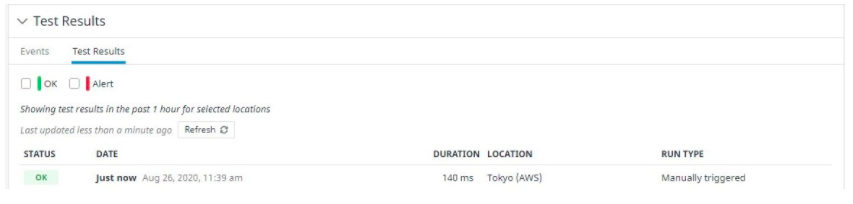
테스트 결과는 서버가 성공적으로 액세스되었음을 보여줍니다.
다음으로 AppKeeper의 자동 수정을 테스트하기 위해 웹 서버의 의사 오류를 생성했습니다.
실제 장애를 일으키기 어렵 기 때문에 서비스를 중단하고 웹 페이지를 볼 수없는 상황을 만들었습니다.이를 위해 SSH를 사용하여 Nginx 서버가 설치된 EC2 인스턴스에 연결하고 Nginx를 중지했습니다.
| sudo systemctl stop nginx |
잠시 후 Datadog은 웹 서버에 더 이상 액세스 할 수 없음을 감지했습니다.
Datadog의 합성 테스트 페이지에도 테스트 케이스가 실패했음을 표시합니다.
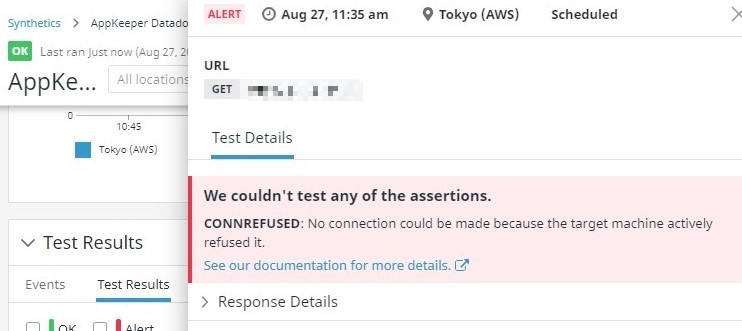
테스트 케이스가 실패하면 Datadog은 Synthetics 모니터링이 실패했음을 AppKeeper에 알립니다.
AppKeeper가 알림을 받으면 자동으로 Nginx를 다시 시작합니다.
따라서 잠시 기다리면 Datadog의 Synthetics 모니터링 검사가 다시 통과되는 것을 볼 수 있습니다.
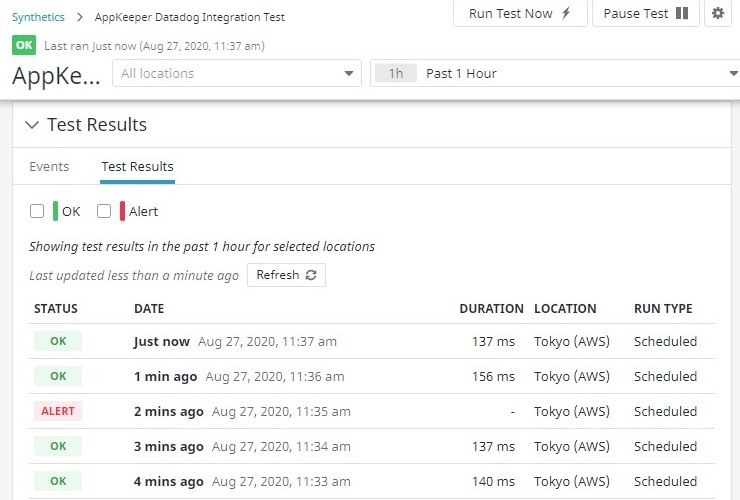
또한 AppKeeper 대시 보드에 로그인하면 복구가 수행되었음을 알 수 있습니다.

—
이 연습에서는 웹 서버 (Nginx)를 예로 사용하여 Datadog에서 오류를 감지하고 AppKeeper로 서비스를 복원하는 프로세스를 자동화했습니다.
Datadog을 EventBridge 및 Lambda와 통합하거나 사용자 지정 스크립트를 생성하여 유사한 자동화를 달성 할 수 있습니다.
그러나 대상 인스턴스를 자주 추가하거나 다양한 서비스를 다시 시작하면 EventBridge 및 Lambda 또는 스크립트를 유지 관리하는 데 드는 비용과 복잡성이 증가합니다.
AppKeeper는 Datadog과의 입증 된 통합 및 애플리케이션에 대상 인스턴스를 쉽게 추가 할 수 있으므로 DevOps 환경에 자동화를 쉽게 추가하여 다운 타임을 줄일 수 있습니다.
현재 Datadog을 사용 중이고 AppKeeper의 Restart API를 사용해 보려면 먼저 여기에서 14 일 무료 평가판에 가입하세요 (무료 평가판을 설치 한 후 구독을 구매할 수 있음).그런 다음 여기를 클릭하여 무료 평가판을 요청하세요. 프로세스를 안내하고 시작하는 데 도움이되는 무료 평가 토큰을 제공합니다.
감사합니다.이번 기회에 EC2에서 실행되는 애플리케이션의 자동 모니터링 및 복구를 제공하는 SIOS AppKeeper에 대해 자세히 알아 보시기 바랍니다.
— SIOS 기술 기술팀의 Tatsuya Hirao.
SIOS의 허가를 받아 복제
고 가용성을 수정하려면 블로그 게시물보다 더 많은 시간이 필요하다는 5 가지 신호

고 가용성을 수정하려면 블로그 게시물보다 더 많은 시간이 필요하다는 5 가지 신호
표지판이 있습니다. 경고등이 깜박입니다.직감에서 느낄 수 있습니다. 잠을 잘 수 없을 수도 있습니다.고 가용성 문제는 심각합니다. 하지만 확실하지 않을 수도 있습니다.
1. 클라우드 SLA가 고 가용성에 필요한 전부라고 생각하는 경우
클라우드 솔루션은 향상된 하드웨어 가용성과 복원력에서 큰 발전을 가져 왔습니다. 그러나 애플리케이션 고 가용성에는 올바른 하이퍼 바이저 또는 클라우드 공급자를 선택하는 것 이상이 필요합니다. 고 가용성을위한 전략은 클라우드 또는 가상화 공급자가 제공하는 SLA로 멈출 수 없습니다. Wired에서 인용 한 바와 같이 "2011 년 4 월에 거의 4 일 동안 발생한 Amazon 중단은 Amazon의 EC2 SLA를 위반하지 않았습니다. FAQ에서 설명하는 것처럼"후행 365 기간 동안 리전 내에서 99.95 %의 서비스 가용성을 보장합니다. " 이 DZone 문서에서 David Bermingham은 클라우드 SLA와 애플리케이션 가용성 간의 차이점을 자세히 설명합니다. 고 가용성 인프라를 원한다면 데이터 및 애플리케이션 계층에서도 모니터링, 복구 및 복원력을 포함해야합니다.
2. 오픈 소스 운영 체제와 함께 제공되는 고 가용성 클러스터링을 사용하는 경우
그렇다면 OS와 함께 제공되는 항목을 기준으로 데이터베이스를 선택하지 않았을 가능성이 있으므로 해당 기준만으로 HA 솔루션을 선택하는 이유는 무엇입니까? 번들 도구는 추가 보증, 가능성 및 기능을 제공하는 데 큰 도움이됩니다. 그러나 액세스 용이성에도 불구하고 번들 도구와 OS 클러스터링 소프트웨어가 항상 SLA, RPO, RTO 및 가용성 요구 사항을 충족 할 수있는 것은 아닙니다. 기업에 운영 체제 조합이있는 경우 팀은 서로 다른 도구를 탐색하고 이들이 어떻게 통합되는지 이해하는 데 도움이 필요할 것입니다. 그것은 마치 울타리 가위를 선택하고 연석에 왼쪽으로 릴 모어를 밀어 13 번 홀 파 5 (Augusta)에있는 "Azalea"모양을 만드는 것과 같습니다. 두 잔디 깎는 기계는 모두 잔디를 깎도록 설계되었지만 시간이 얼마나 있습니까? 복잡성을 어떻게 처리 하시겠습니까? 어느 쪽을 믿으시겠습니까? 고 가용성을위한 전략에는 OS와 함께 제공되는 편의성을 고려하는 것 이상의 것이 필요합니다. 그렇지 않으면 SAP HANA 대신 MySQL을 실행하게됩니다.
3. SQL Enterprise 또는 Oracle Enterprise와 같은 엔터프라이즈 애플리케이션 라이선싱이 엔터프라이즈 고가용 성과 동일하다고 생각하는 경우
비용 증가 외에도 많은 엔터프라이즈 애플리케이션 라이센스는 일부 고 가용성 시나리오에서 애플리케이션의 복구 기능을 증가시킵니다. 그러나 전체 엔터프라이즈가 단일 애플리케이션을 기반으로 할 가능성은 거의 없습니다. 고 가용성에는 고 가용성 데이터베이스 솔루션 이상의 것이 필요합니다. 모든 애플리케이션과 데이터베이스를 광범위하게 지원하는 엔터프라이즈 급 애플리케이션 모니터링 및 복구 솔루션이 필요합니다. 또한 데이터베이스 데이터뿐 아니라 중요한 애플리케이션 및 구성 데이터도 관리하고 복제 할 수있는 기능이 필요합니다. 단일 데이터베이스 또는 간단한 응용 프로그램에 대한 가용성은 한 가지입니다. 그러나 복잡한 다중 부분 응용 프로그램 및 지원 데이터베이스에 대한 HA는 매우 다릅니다. 더 많은 서비스, 조정해야하는 더 많은 부분, 조정해야 할 더 복잡한 아키텍처, 장애 조치 / 전환 전후에 준수해야 할 더 구체적인 모범 사례. 엔터프라이즈 라이선스가 지불 한 것 이상입니다.
4. 다운 타임이 증가하고 가동 시간이 감소하는 경우
삶의 속도는 많은 분야에서 계속 증가하고 있습니다. 팀이 마지막으로 백업에서 복구하거나 중요하다고 간주되는 애플리케이션을 수동으로 다시 시작했거나 실패한 가상 머신 또는 노드 세트를 다시 시작한 것이 언제입니까? 정전 이벤트의 속도가 지속 가능성을 앞지르거나 소방을 넘어서 화재 예방 및 방화로 이동하는 팀의 능력을 능가 할 수는 없습니다. "너는 그렇게 오래 뛸 수있다 (Carey Nieuwhof)." 여러분 중 일부에게는 너무 오랫동안 소방을 해왔고 가동 중단 시간보다 중단이 더 흔해지고 있습니다.
5. 첫 번째 장애 조치 테스트가 프로덕션 서버에있는 경우
최근 고객은 가능한 모든 재난 시나리오를 테스트하는 것은 단순히 불가능하다고 말했습니다. 새로운 소프트웨어가 생성, 배포, 업데이트 및 패치됨에 따라 고 가용성 문제가 증가하고 있습니다. 그러나 라이브 프로덕션 데이터는 함께 잘 작동하지 않는 것을 찾을 수있는 곳이 아닙니다. 그리고 Go-Live와 Post-Go-Live는 항상 놀라움의 몫을 가지고 있지만 실제로 장애 조치를 수행하고 백업 노드에서 실행할 수 없다는 점이 그중 하나가되어서는 안됩니다.
Scouring 블로그는 고 가용성을 정의, 재정의 및 개선하는 데 유용한 팁과 통찰력을 제공 할 수 있습니다. 그러나 '충분히'와 같은 형태로 진정한 가용성을 거래했다는 경고 신호가 나타나면 문제를 해결하기 위해 블로그 게시물 또는 가용성 세계의 모든 블로그 게시물을 수색하는 것 이상이 필요합니다. 귀하의 HA.
– Cassius Rhue, 고객 경험 담당 부사장
SIOS의 허가를 받아 복제
