| 8월 28, 2022 |
재해: 라이브! 재해에서 운영으로의 SQL Server |
| 8월 24, 2022 |
백서: Oracle에 비용 절감 및 유연성을 제공하는 고가용성 솔루션 |
| 8월 20, 2022 |
백서: 비즈니스 크리티컬 애플리케이션을 위한 고가용성의 복잡성 이해
|
| 8월 18, 2022 |
SIOS LifeKeeper 및 Google Cloud용 일반 로드 밸런서 키트 소개 |
| 8월 12, 2022 |
SAP에서 다운타임을 줄이는 방법
SAP에서 다운타임을 줄이는 방법방법에 대해 생각하고 SAP의 다운타임 감소 초기 솔루션 설계 중에 방문해야 하는 중요한 주제입니다. 기존 SAP 환경을 변경할 수 있으며 가동 중지 시간이 문제가 되는 기존 프로덕션 환경에서는 더 까다로울 수 있습니다. SAP 환경에는 단일 실패 지점으로 간주될 수 있는 몇 가지 일반적인 구성 요소가 있습니다. ASCS(중앙 서비스), HANA DB, NFS 노드 및 SAP 애플리케이션 서버. 이상적으로는 고가용성 구성에서 중복 서버를 사용하여 보호해야 합니다. SAP의 HA/DR 목표SAP용 고가용성/재해 복구의 구성 요소를 설계할 때의 핵심 목표는 다음과 같아야 합니다.● 가동 중지 시간 최소화 ● 데이터 손실 제거 ● 데이터 무결성 유지 ● 유연한 구성 활성화 오늘날의 현대적인 클라우드 환경에서 기본 하드웨어의 인프라는 일반적으로 여러 중복 NIC, 중복 스토리지 및 하드웨어 가용성 영역을 사용하여 장애로부터 잘 보호되지만 여전히 그렇지는 않습니다. SAP 응용 프로그램이 실행되고 요청에 응답한다고 보장하지 않습니다. 사용 고가용성 SIOS Protection Suite와 같은 솔루션은 로컬 디스크 복제와 결합된 지능형 고가용성을 도입하여 SAP 애플리케이션 및 서비스가 지속적으로 모니터링되고 보호되며 장애가 감지되면 자동으로 중복 하드웨어로 전환할 수 있는 기능을 제공합니다. 이제 HA로 보호되지 않는 SAP 구성의 간단한 예를 고려해 보겠습니다. 다음과 같이 보일 수 있습니다(그림 1). 이제 이 영업 처리 환경(위 그림)이 HA가 없는 클라우드에서 구성되었다고 가정해 봅시다. 설계자가 클라우드 환경에서 고도로 이중화된 하드웨어가 장애로부터 보호하기에 충분하다고 생각했기 때문입니다.해당 HANA DB에 문제가 발생하여 종료되는 경우 데이터베이스를 백업하고 실행하는 데 일반적으로 필요한 단계를 살펴보겠습니다. ● HANA가 HANA System Replication으로 구성되어 있어도 보조 HANA DB 시스템으로의 장애 조치는 자동화되지 않습니다. 이를 위해서는 HANA를 알고 있는 사람이 오류를 감지하고 중단을 통보한 후 수정해야 합니다. IBM의 이 보고서 시간당 평균 다운타임 비용은 $10,000입니다. 고객 규모를 확장하면 시스템 다운 상황이 발생하면 수십만 달러의 비용이 발생하고 해결하는 데 상당한 인력 리소스가 소모될 가능성이 매우 높습니다. 또 다른 IBM 보고서 응답자의 44%가 격월로 계획되지 않은 정전을 경험했으며 또 다른 35%는 매월 계획되지 않은 정전을 경험했다고 밝혔습니다. 계획된 중단 자체는 또 다른 잠재적인 문제로 응답자의 46%가 월간 계획된 중단을 보고했으며 추가로 29%는 연간 계획된 중단을 보고했습니다. HA 소프트웨어로 애플리케이션과 서비스를 보호하면 유지 관리 활동 중에 서비스를 실행 중인 시스템으로 이동하여 이러한 계획된 중단을 완화할 수도 있습니다. 에 대해 자세히 알아보기 SAP 및 S/4HANA에 대한 고가용성 . |




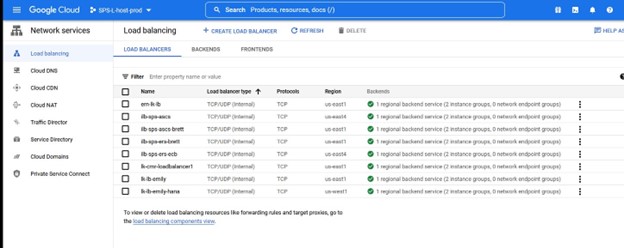
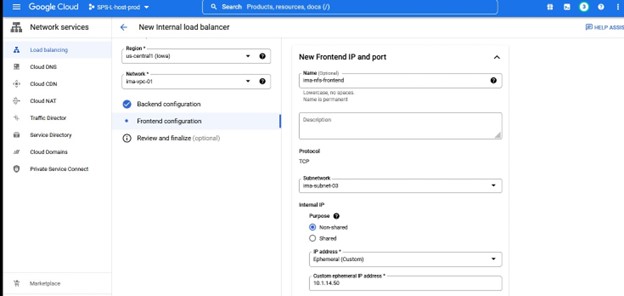
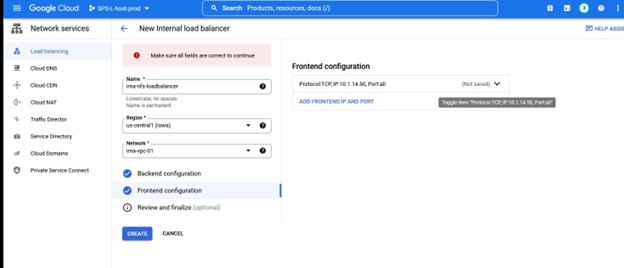
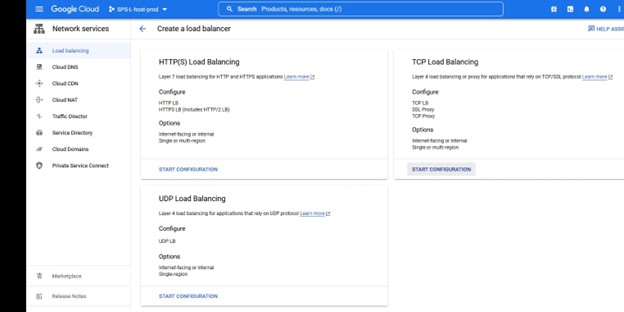 이 인스턴스에서 우리는 TCP 로드 밸런싱을 원합니다. 로드 밸런서를 만들고 이름과 함께 배포할 리소스 그룹을 선택합니다. 저는 클러스터 유형과 일치하는 이름을 사용하고 싶습니다. 예를 들어 IMA-NFS-LB와 함께 로드 밸런서를 사용하면 두 IMA-NFS 노드 앞에 배치됩니다.
이 인스턴스에서 우리는 TCP 로드 밸런싱을 원합니다. 로드 밸런서를 만들고 이름과 함께 배포할 리소스 그룹을 선택합니다. 저는 클러스터 유형과 일치하는 이름을 사용하고 싶습니다. 예를 들어 IMA-NFS-LB와 함께 로드 밸런서를 사용하면 두 IMA-NFS 노드 앞에 배치됩니다.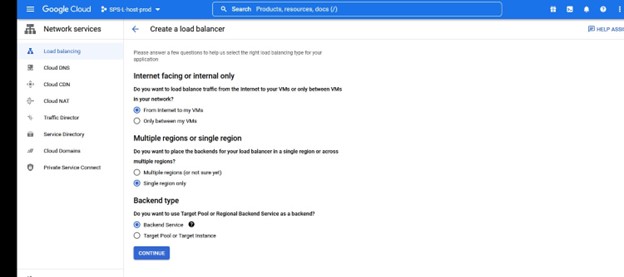
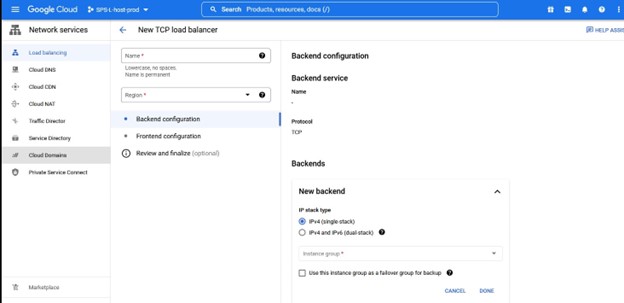
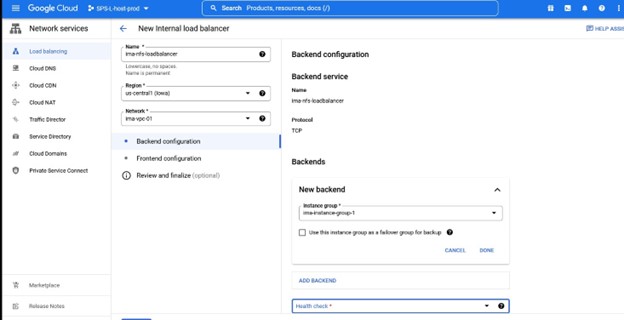
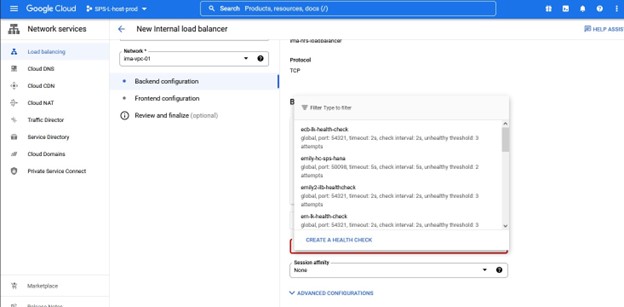
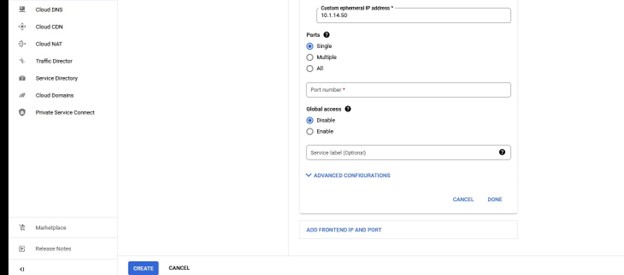
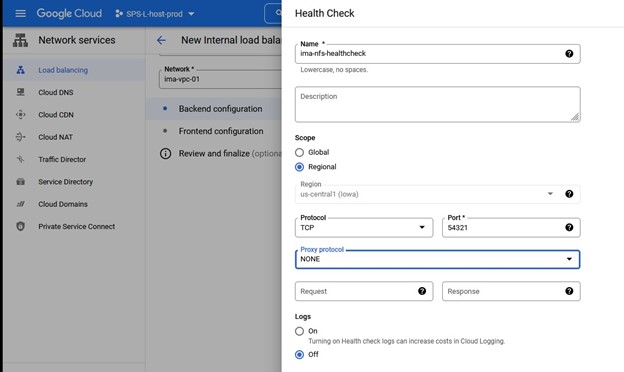 다시 말하지만 포트 번호는 Lifekeeper와 함께 사용되므로 주의하십시오.
다시 말하지만 포트 번호는 Lifekeeper와 함께 사용되므로 주의하십시오.
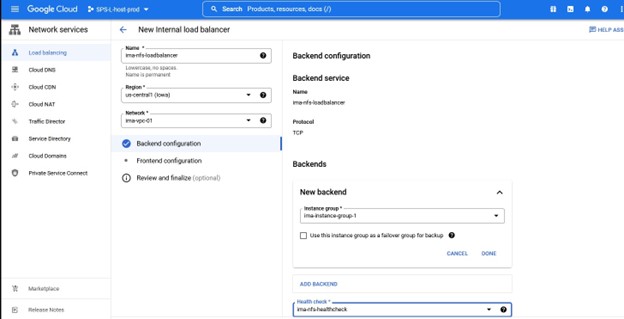
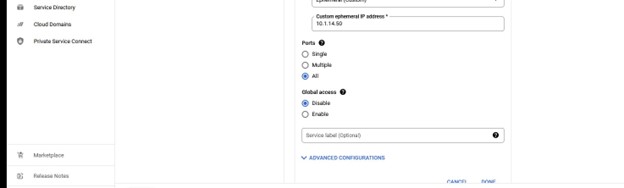
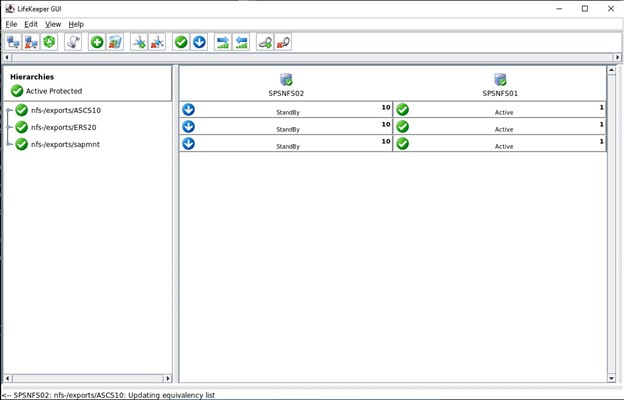 내에서 우리가 해야 할 일
내에서 우리가 해야 할 일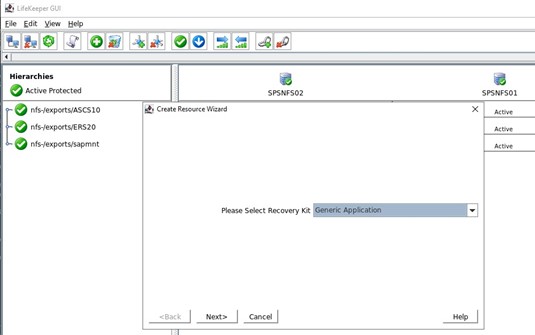
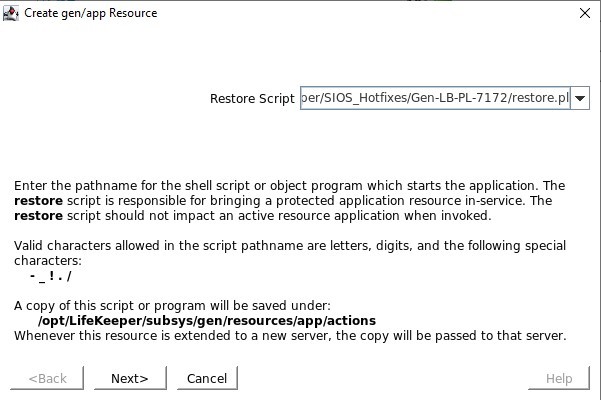 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 restore.pl 스크립트를 정의합니다.
/opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 restore.pl 스크립트를 정의합니다.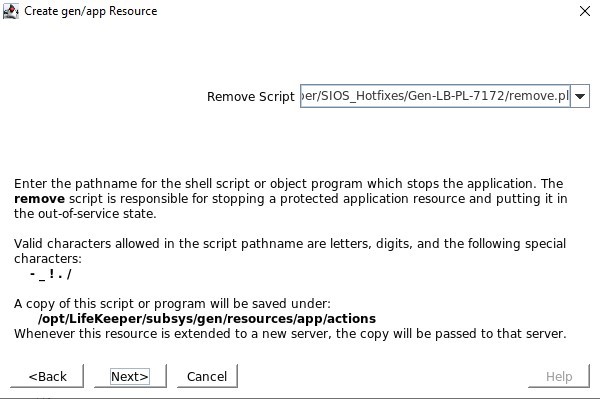 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 remove.pl 스크립트를 정의하십시오.
/opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 remove.pl 스크립트를 정의하십시오.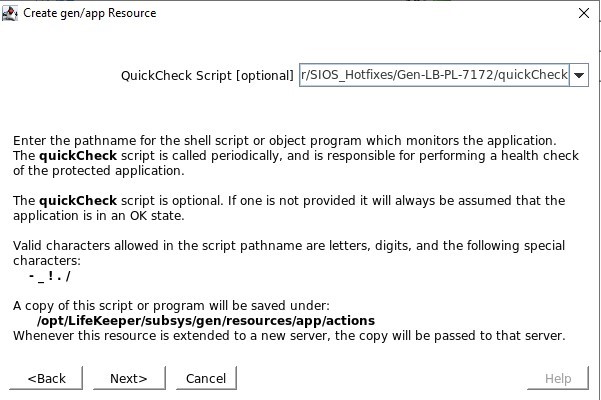 /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 quickCheck 스크립트를 정의하십시오.
/opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/에 있는 quickCheck 스크립트를 정의하십시오.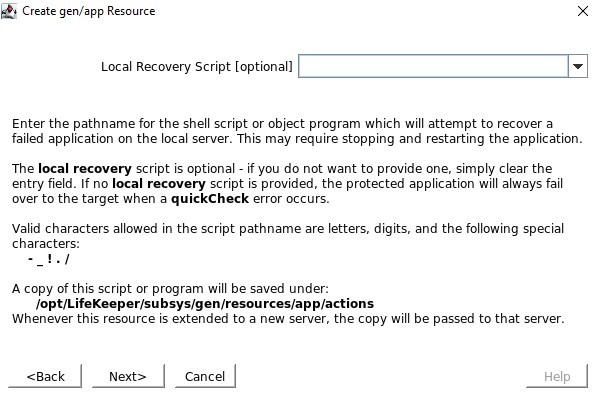 로컬 복구 스크립트가 없으므로 이 입력을 지워야 합니다.
로컬 복구 스크립트가 없으므로 이 입력을 지워야 합니다.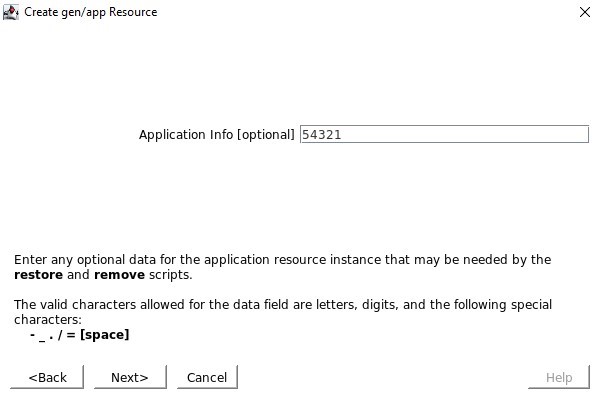 애플리케이션 정보를 묻는 메시지가 표시되면 Healthcheck 포트에서 구성한 것과 동일한 포트 번호(예: 54321)를 입력하려고 합니다.
애플리케이션 정보를 묻는 메시지가 표시되면 Healthcheck 포트에서 구성한 것과 동일한 포트 번호(예: 54321)를 입력하려고 합니다.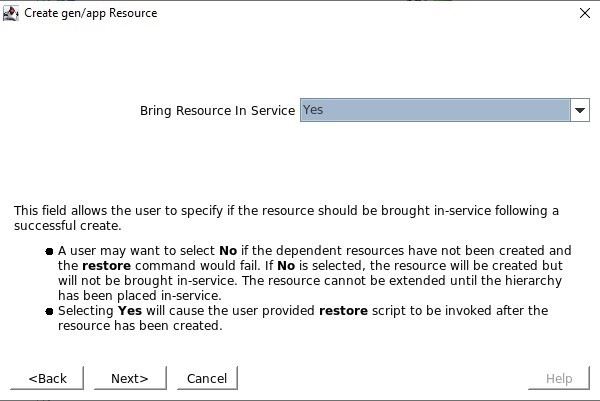 서비스가 생성되면 서비스를 제공하도록 선택할 것입니다.
서비스가 생성되면 서비스를 제공하도록 선택할 것입니다.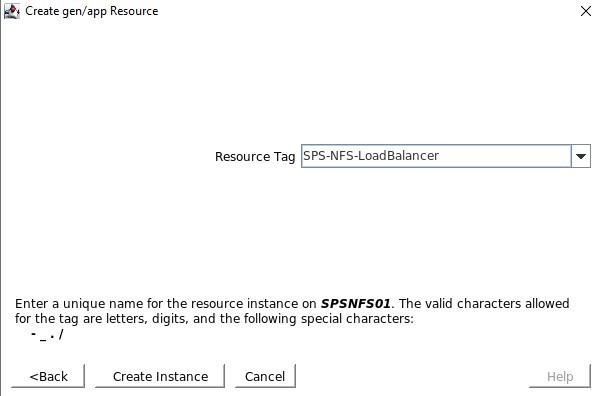 리소스 태그는 SPS-L GUI에 표시되는 이름입니다. 저는 쉽게 식별할 수 있는 이름을 사용하고 싶습니다.
리소스 태그는 SPS-L GUI에 표시되는 이름입니다. 저는 쉽게 식별할 수 있는 이름을 사용하고 싶습니다.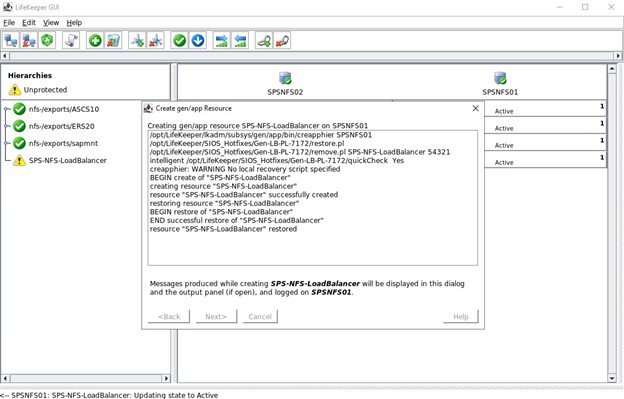 모든 것이 올바르게 구성된 경우 "END 성공적인 복원"이 표시되면 리소스를 두 노드 중 하나에서 호스팅할 수 있도록 이를 다른 노드로 확장할 수 있습니다.
모든 것이 올바르게 구성된 경우 "END 성공적인 복원"이 표시되면 리소스를 두 노드 중 하나에서 호스팅할 수 있도록 이를 다른 노드로 확장할 수 있습니다.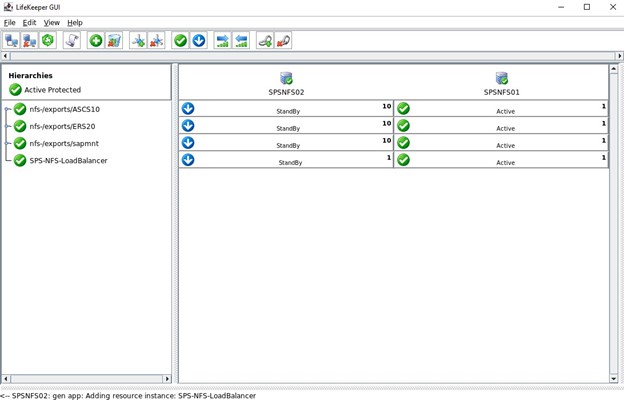
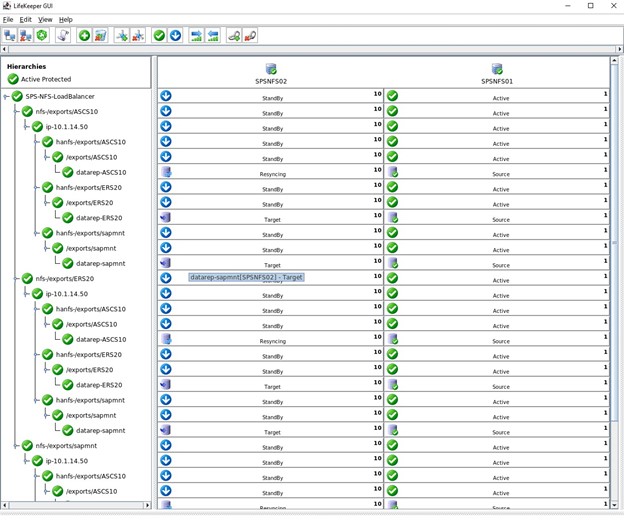
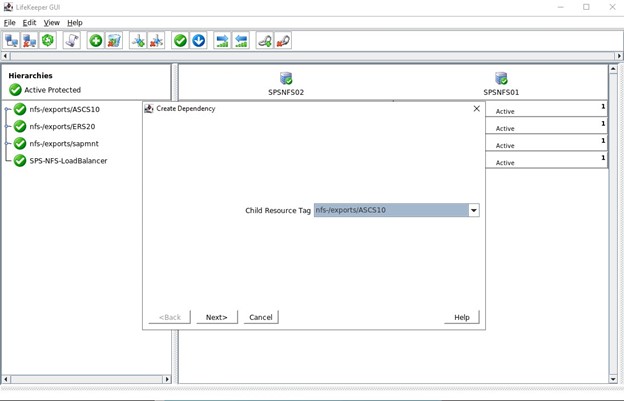 이 클러스터의 마지막 단계는 세 가지 NFS 내보내기에 대한 하위 종속성을 생성하는 것입니다. 즉, Datakeeper 미러 및 IP로 완료된 모든 NFS 내보내기는 로드 밸런서에 의존합니다. 활성 노드에서 심각한 문제가 발생하면 이러한 모든 리소스가 다른 작동 중인 노드로 장애 조치됩니다.
이 클러스터의 마지막 단계는 세 가지 NFS 내보내기에 대한 하위 종속성을 생성하는 것입니다. 즉, Datakeeper 미러 및 IP로 완료된 모든 NFS 내보내기는 로드 밸런서에 의존합니다. 활성 노드에서 심각한 문제가 발생하면 이러한 모든 리소스가 다른 작동 중인 노드로 장애 조치됩니다.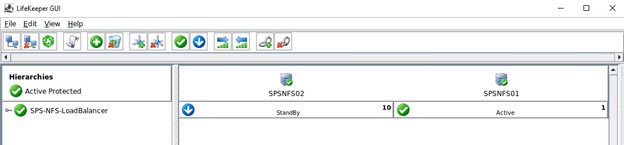

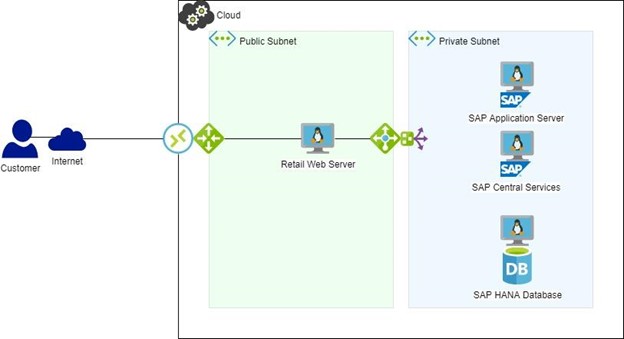 이 환경이 고객에게 의류를 판매하는 데 사용되는 웹 서버의 트랜잭션을 처리하는 데 사용되는 경우 SAP는 이러한 트랜잭션을 기반으로 판매 처리, 주문 추적, 재고 추적 및 다중 자동 주문 제공 등에 사용됩니다.
이 환경이 고객에게 의류를 판매하는 데 사용되는 웹 서버의 트랜잭션을 처리하는 데 사용되는 경우 SAP는 이러한 트랜잭션을 기반으로 판매 처리, 주문 추적, 재고 추적 및 다중 자동 주문 제공 등에 사용됩니다.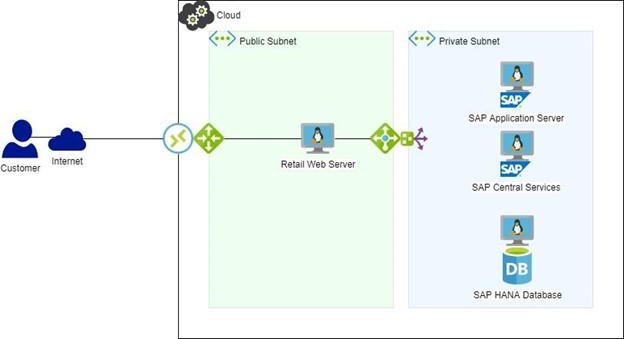
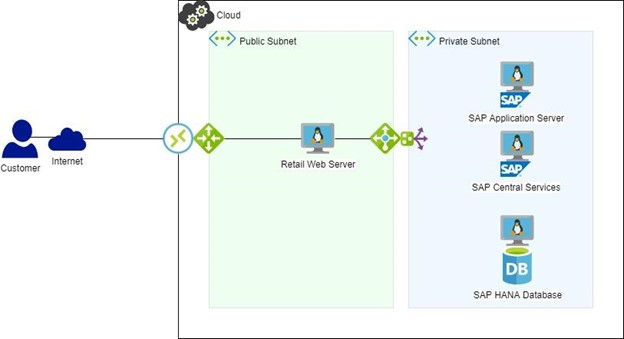
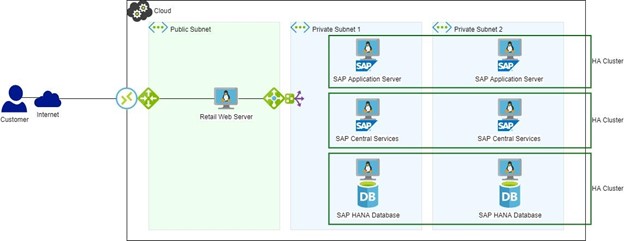 그림 2: HA/DR이 포함된 SAP 환경 HA 소프트웨어가 사용 중이었다면(그림 2), HANA DB 장애 조치가 자동으로 이루어지고 웹 서버에 대한 중단이 구성된 시간 초과 내에 있었을 것이며 판매 손실은 전혀 없었을 것입니다. 경보가 발생하고 시스템 다운 상황보다 여유롭게 원인을 살펴보고 진단할 수 있습니다.
그림 2: HA/DR이 포함된 SAP 환경 HA 소프트웨어가 사용 중이었다면(그림 2), HANA DB 장애 조치가 자동으로 이루어지고 웹 서버에 대한 중단이 구성된 시간 초과 내에 있었을 것이며 판매 손실은 전혀 없었을 것입니다. 경보가 발생하고 시스템 다운 상황보다 여유롭게 원인을 살펴보고 진단할 수 있습니다.