| 1월 13, 2023 |
Epicure, Amazon EC2 및 SIOS SANLess 클러스터링 소프트웨어로 비즈니스 크리티컬 SQL 서버 보호 |
| 1월 10, 2023 |
SIOS DataKeeper 클러스터링 소프트웨어를 통해 Gulliver International은 내부 IT 시스템을 Amazon Web Services로 안전하게 이동할 수 있습니다. |
| 1월 5, 2023 |
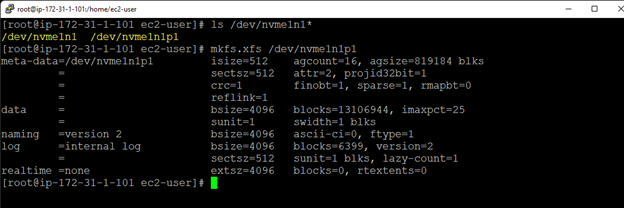
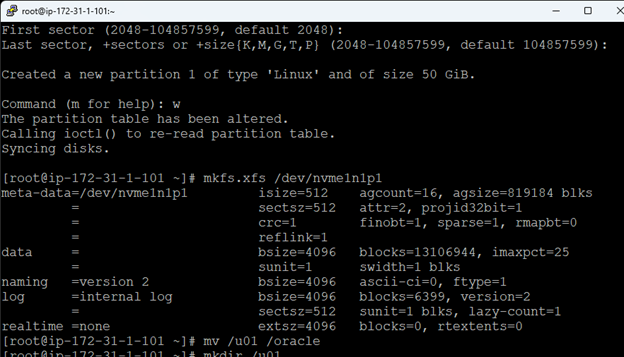
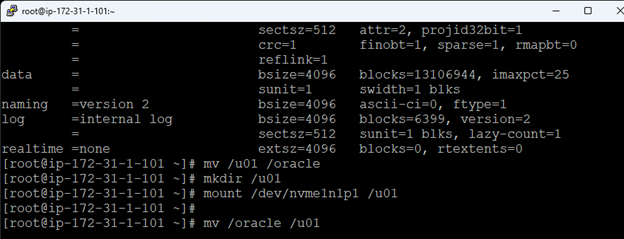
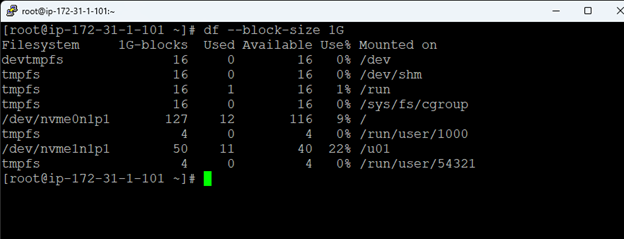
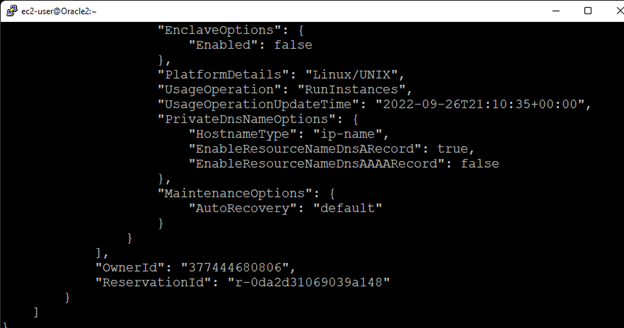
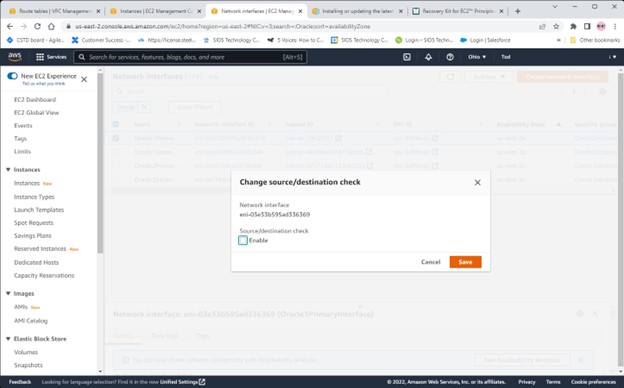
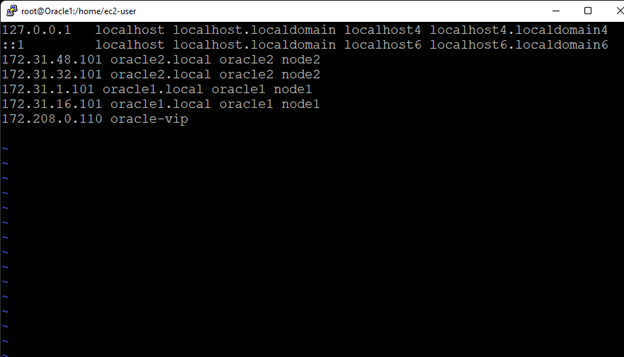
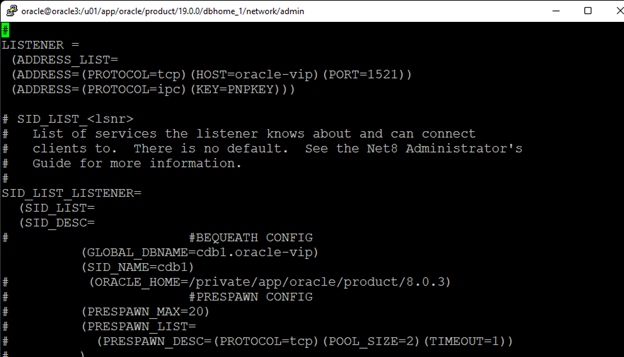
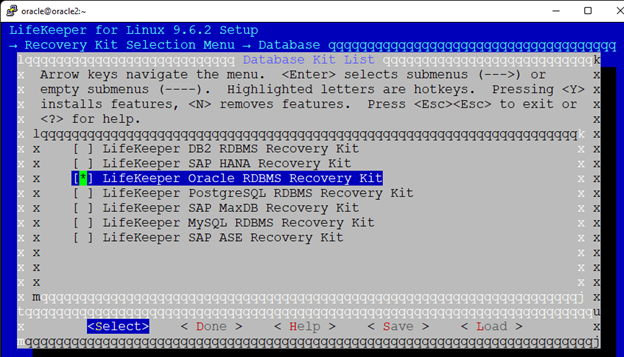
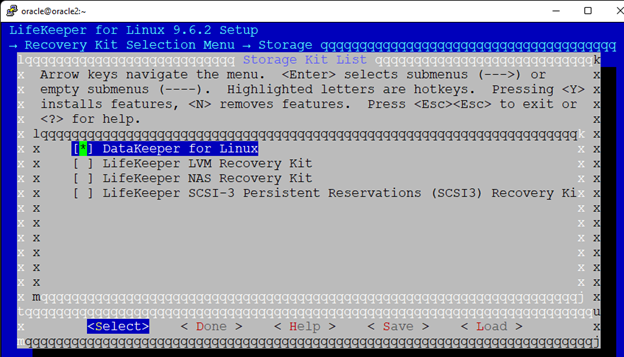
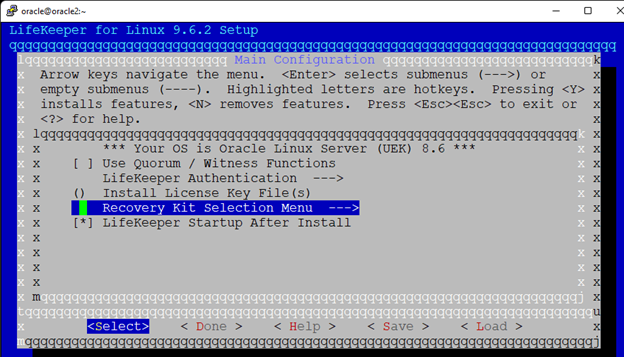
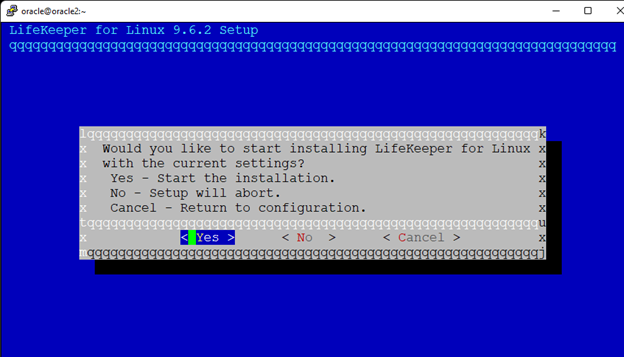
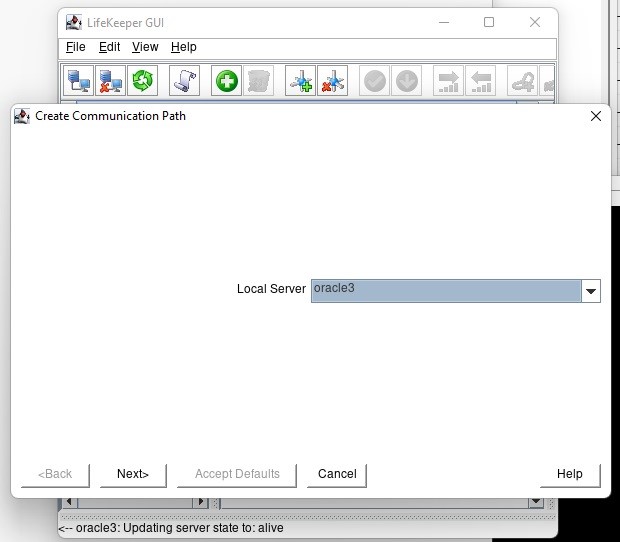
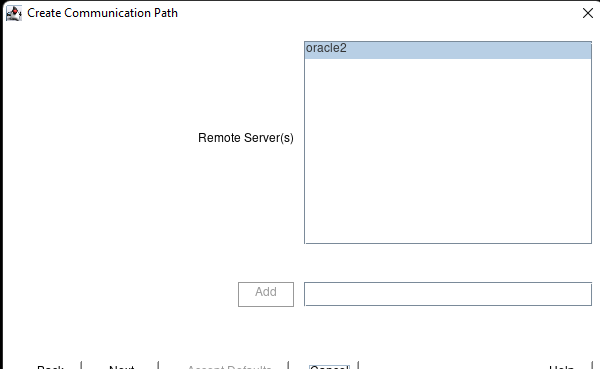
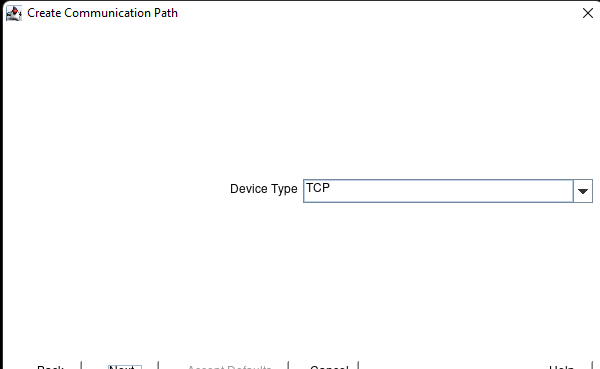
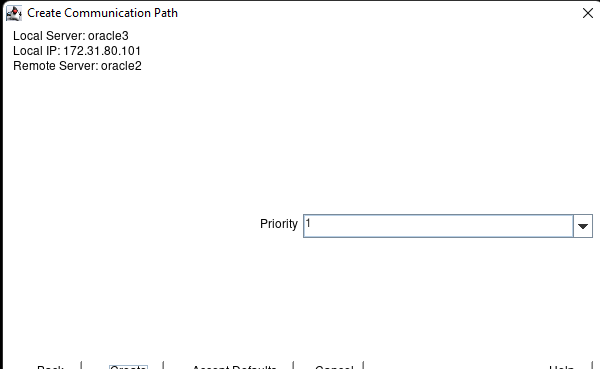
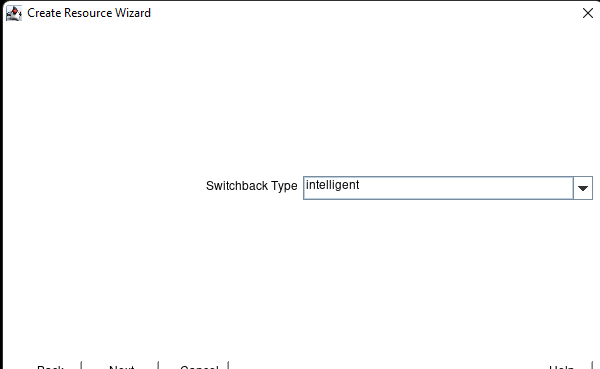
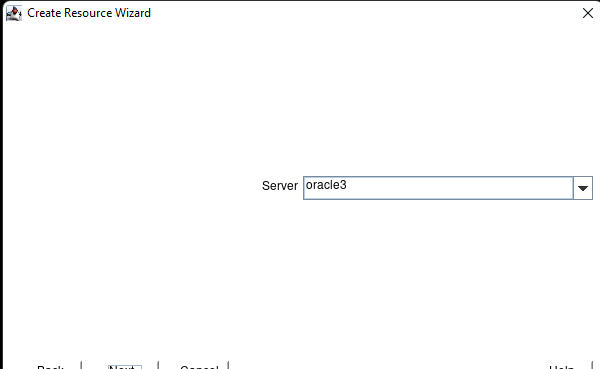
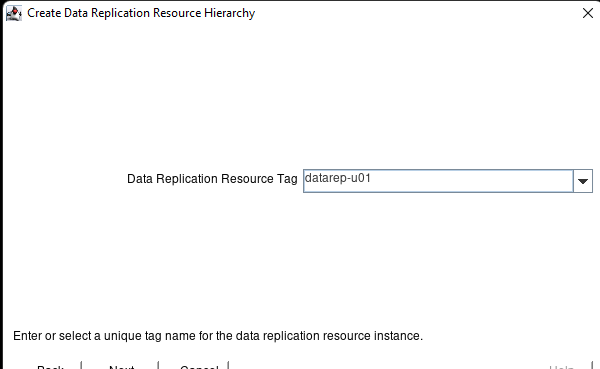
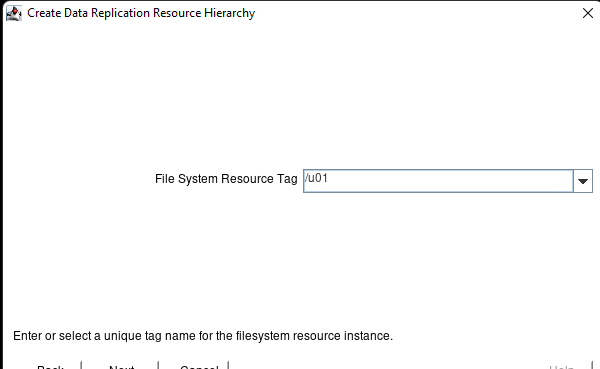
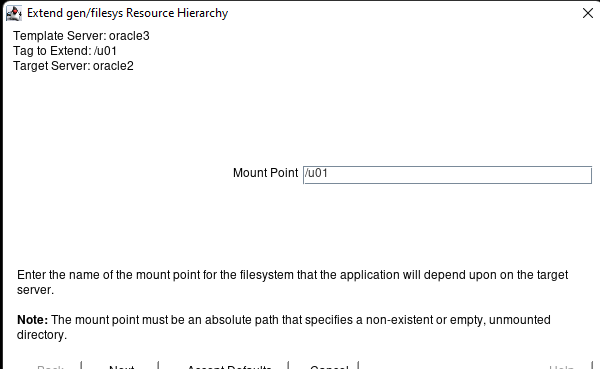
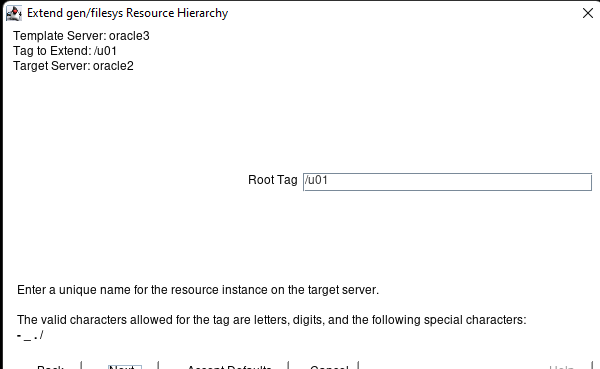
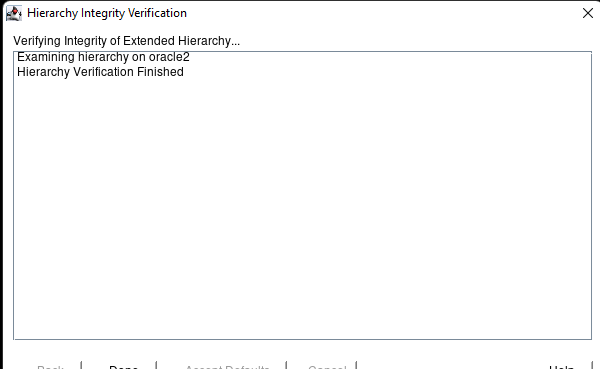
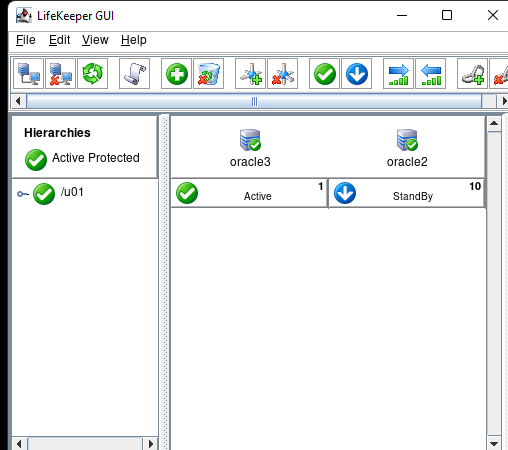
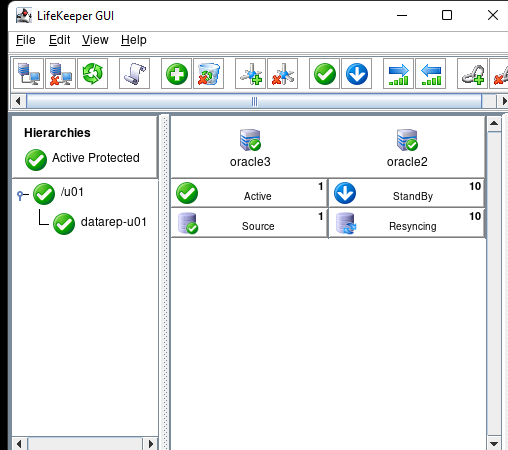
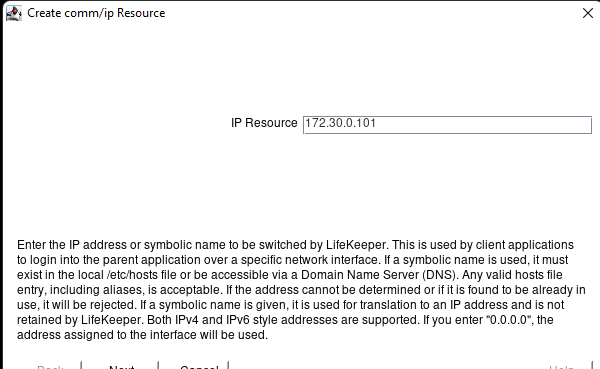
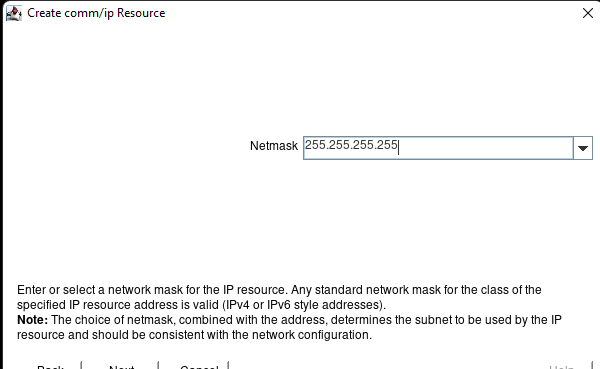
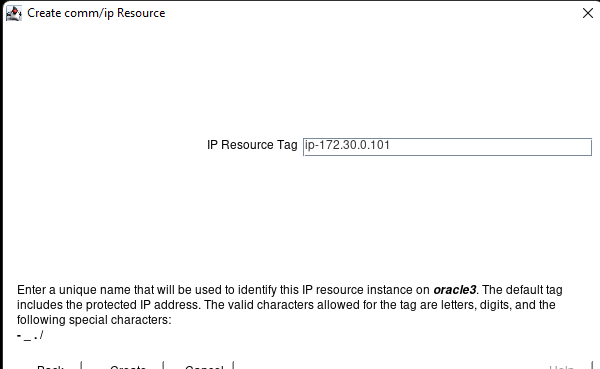
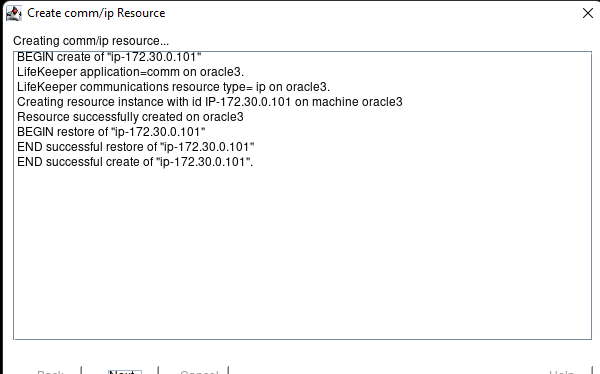
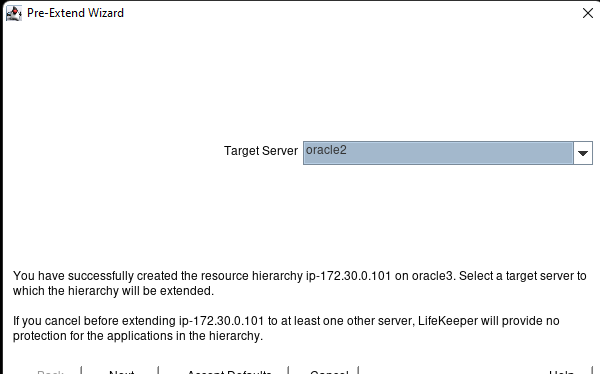
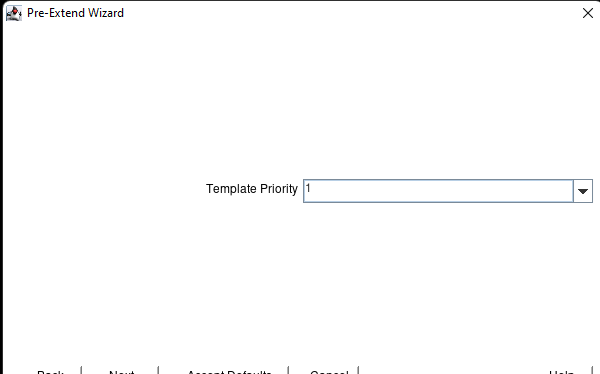
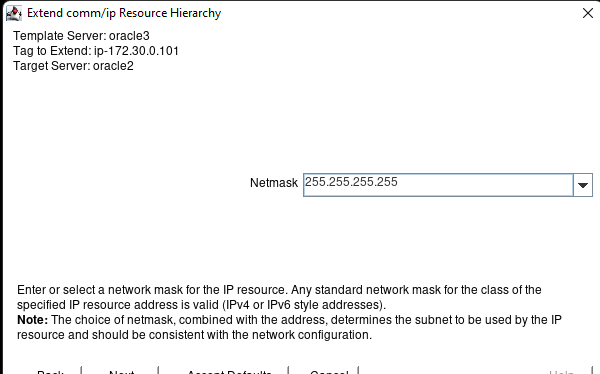
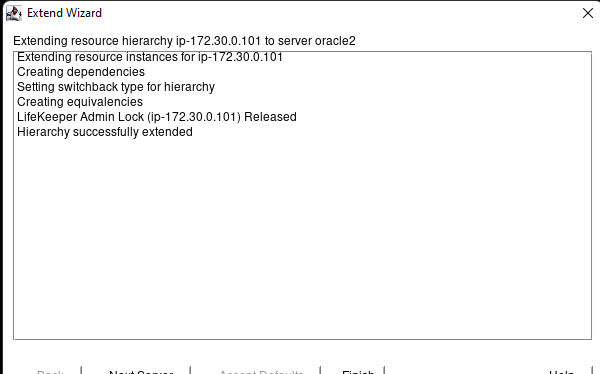
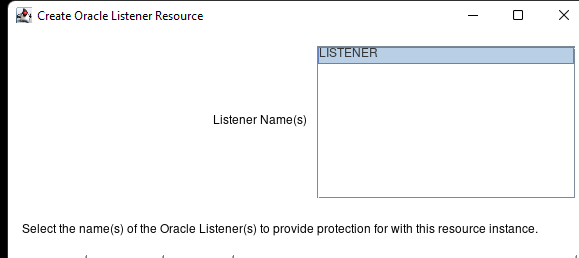
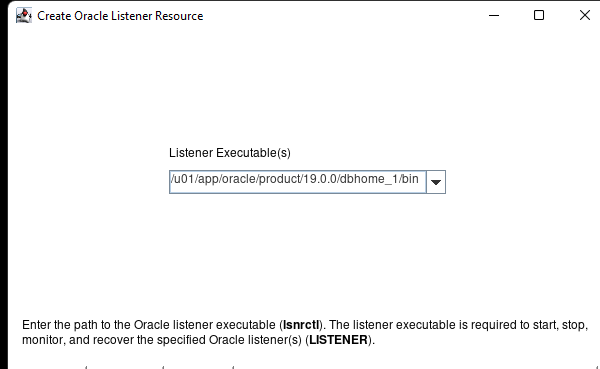
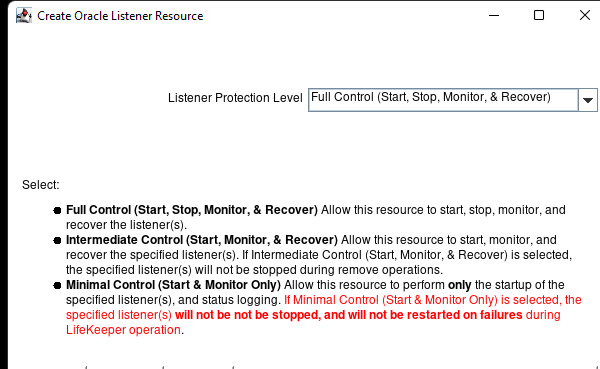
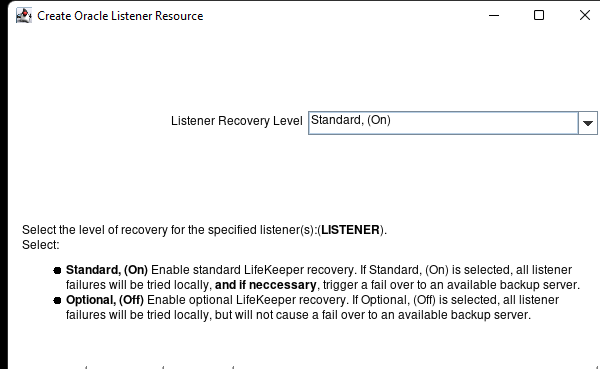
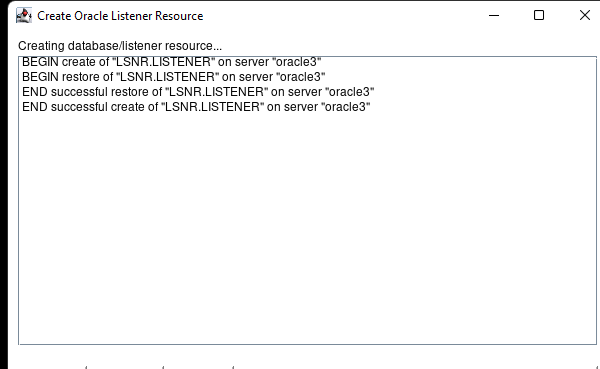
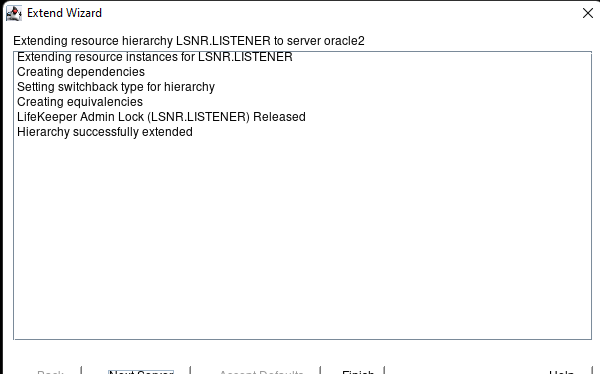
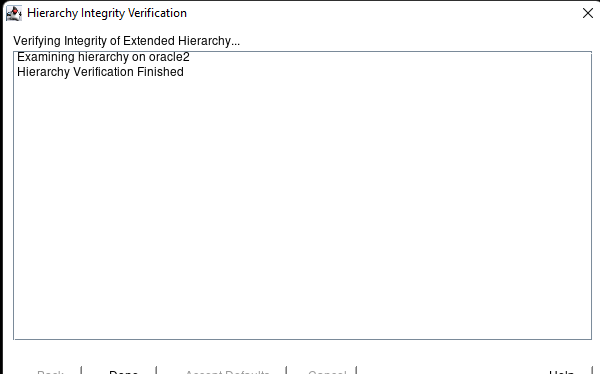
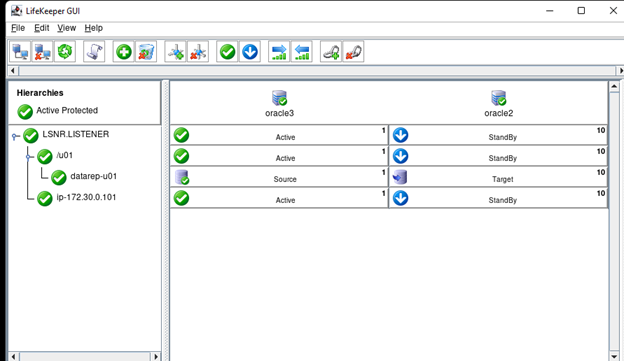
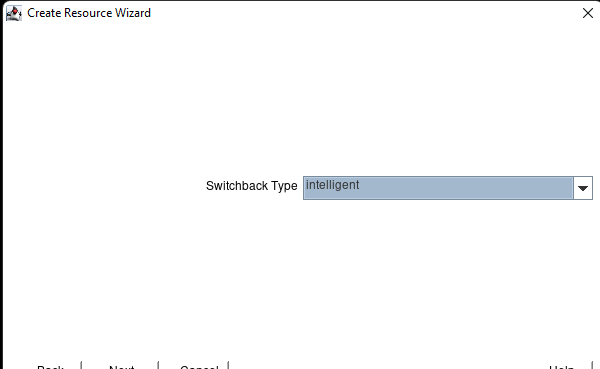
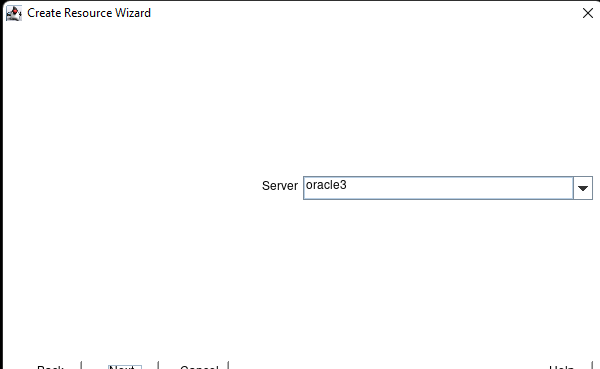
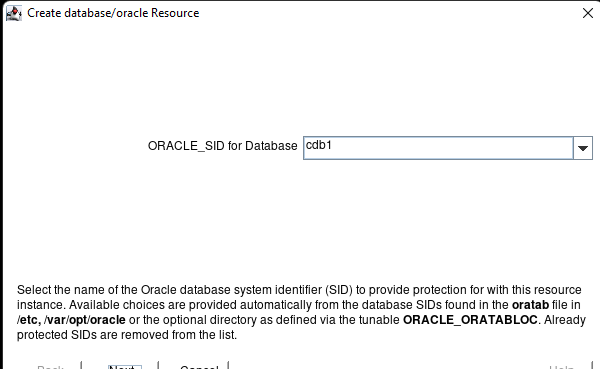
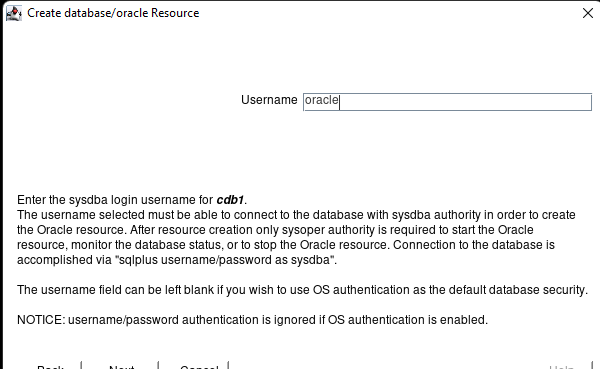
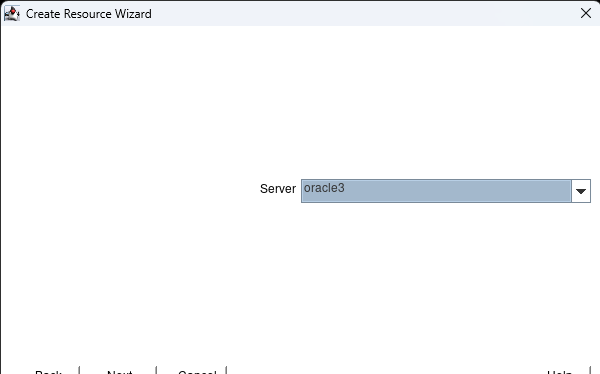
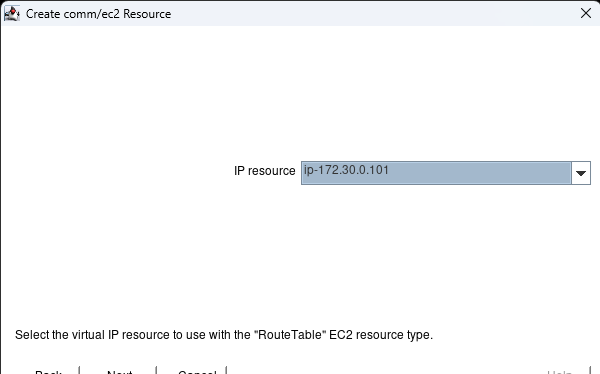
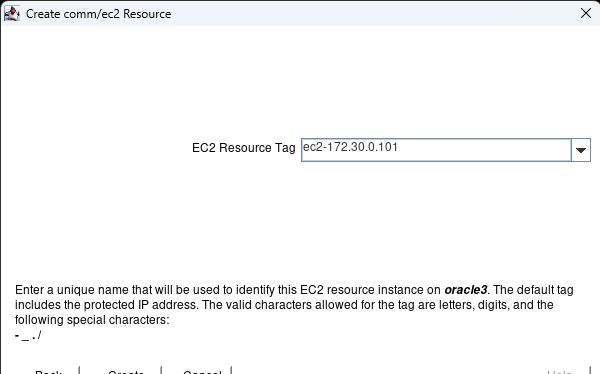
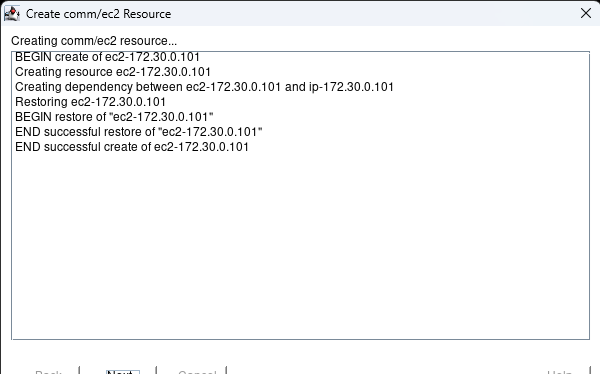
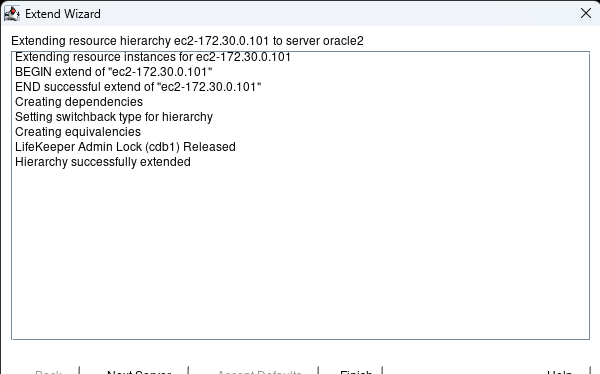
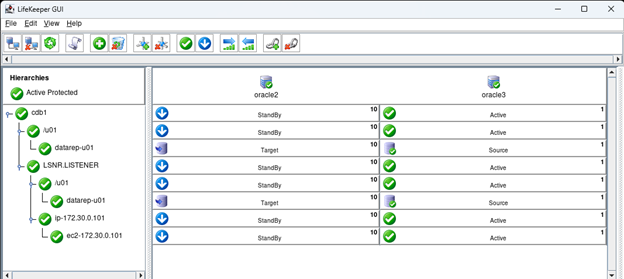
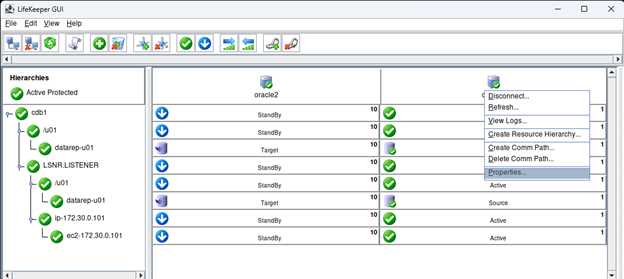
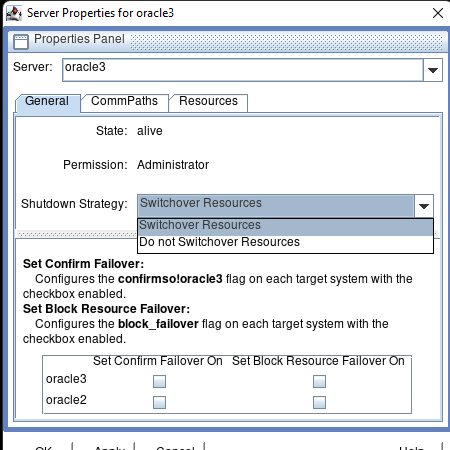
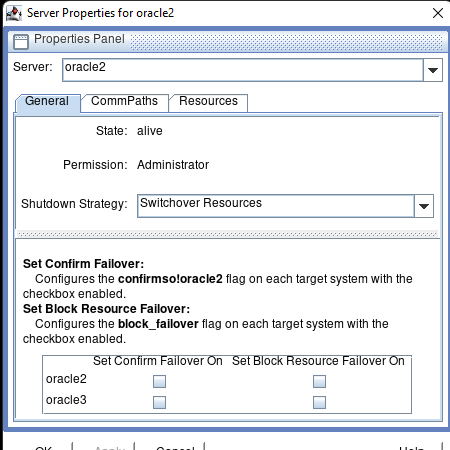
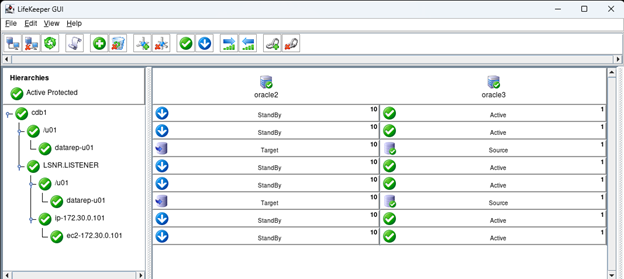
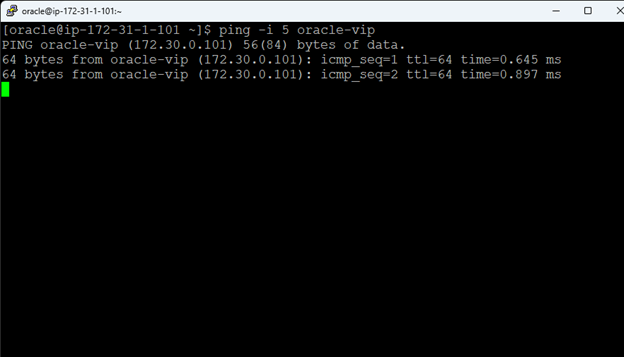
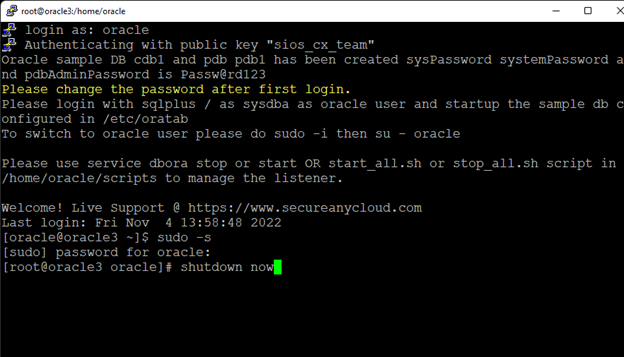
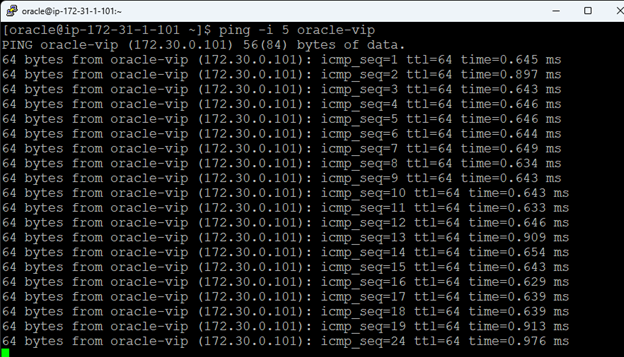
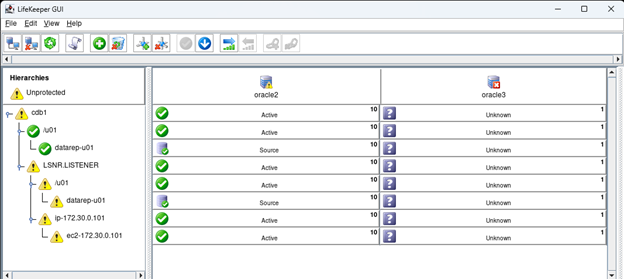
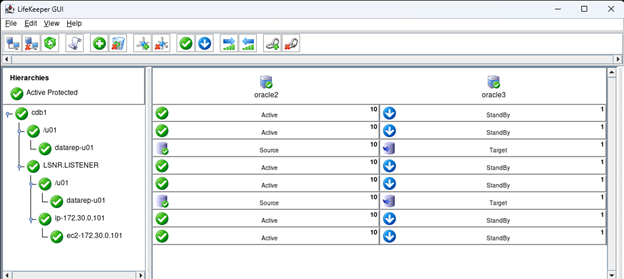
AWS에서 HA Oracle Database 서버 클러스터 생성 |
| 12월 30, 2022 |
선도적인 음료 제조업체가 AWS EC2 클라우드에서 중요한 SAP ERP를 보호합니다. |
| 12월 26, 2022 |
비디오: SIOS가 금융 서비스 산업의 고가용성을 보장하는 방법비디오: SIOS가 금융 서비스 산업의 고가용성을 보장하는 방법 다양한 산업 분야의 고가용성(HA) 및 재해 복구(DR)에 대한 이 지속적인 시리즈에서, 그렉 터커 , 선임 제품(Windows) 지원 엔지니어 SIOS 기술 , 회사가 다운타임 및 장애 조치로부터 금융 산업을 보호하는 방법에 대한 통찰력을 공유하기 위해 우리와 함께합니다. SIOS는 상업 은행, 다양한 중개 회사, 자산 관리, CPA 회사 등 다양한 고객과 함께 금융 업계에서 세계적인 입지를 확보하고 있습니다. 고객이 온라인 뱅킹 시스템, ATM 및 지불 시스템을 위해 중요한 애플리케이션에 의존하는 금융 산업보다 미션 크리티컬하고 다운타임과 실패에 민감한 산업은 없습니다. "우리는 다운타임 및/또는 치명적인 이벤트로부터 중요한 애플리케이션과 데이터를 보호할 장애 또는 클러스터링 소프트웨어를 제공합니다."라고 Tucker는 말합니다. Tucker는 본질적으로 중요한 애플리케이션이 온프레미스이든 클라우드이든 상관없이 보조 서버 또는 여러 서버로 클러스터링되는 기본 서버에 배포된다고 설명합니다. “클러스터링 소프트웨어가 장애를 감지하면 모든 리소스를 보조 노드로 이동하고 서비스를 최종 사용자에게 자동으로 복원합니다. 데이터 손실이나 중단이 없습니다.”라고 그는 덧붙입니다. 자세한 내용은 위의 전체 인터뷰를 확인하십시오. 토론의 하이라이트:
솔루션
그렉 터커와 연결( 링크드인 ) 의 허가를 받아 복제됨 시오스 |