Msdtc #Sql #Azure #Msdtc를 사용하여 Azure 가상 컴퓨터에서 SQL Server 장애 조치 (failover) 클러스터 인스턴스 구성
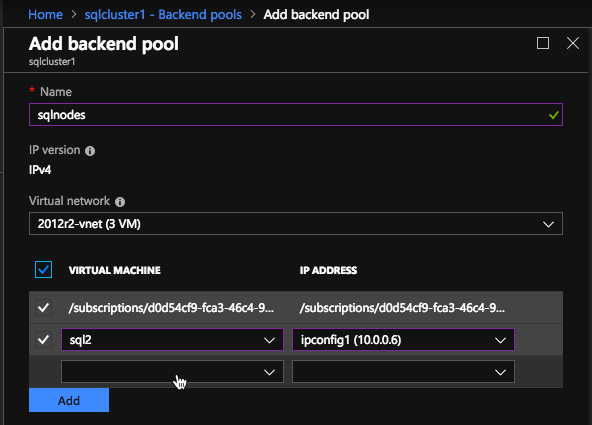
MSDTC 용로드 밸런서 만들기
MSDTC 리소스에는 자체 부하 분산 장치가 필요합니다. 새로운로드 밸런서를 만드는 대신 SQL Server FCI 용으로 이미 구성된로드 밸런서에 새로운 프론트 엔드를 추가합니다. 물론이 프론트 엔드 IP 주소는 클러스터 된 MSDTC 리소스와 연결된 클러스터 IP 주소와 일치해야합니다. 백엔드 풀의 경우 SQL 클러스터 노드가 포함 된 기존 풀을 다시 사용하기 만하면됩니다. MSDTC 리소스 전용의 새 상태 프로브를 만들어야합니다. 사용하는 포트는 SQL 자원에 사용했던 포트와 달라야합니다. 59999를 사용하지 마십시오. 아마도 49999와 같은 것을 사용할 것입니다. 마지막 단계는 MSDTC에 대한로드 균형 조정 규칙을 만드는 것입니다. 새 규칙을 만들고 방금 만든 MSDTC 프론트 엔드와 기존 백엔드를 참조하십시오. 다음으로 새로운로드 밸런싱 규칙을 만들어야합니다. MSDTC는 큰 범위의 포트 인 임시 포트를 사용합니다. 규칙을 만들 때 "HA 포트"라는 상자를 선택해야합니다. 마지막으로 Direct Server Return이 활성화되어 있는지 확인하십시오.
MSDTC 클러스터 IP 리소스 업데이트
SQL Server 클러스터 IP 주소와 같은 기능을합니다. MSDTC 클러스터 IP 리소스가 방금 생성 한 상태 프로브에 응답하는 Powershell 명령을 실행하여 포트 49999를 프로브해야합니다. 또한 MSDTC 클러스터 IP 주소의 서브넷 마스크를 255.255.255.255로 설정하여 동일한 주소를 공유하는로드 밸런서 프런트 엔드와의 IP 주소 충돌을 방지합니다.
# 변수 정의 $ ClusterNetworkName = ""
# 클러스터 네트워크 이름 (Get-ClusterNetwork on 사용
MSDTC 리소스의 이름을 찾는 상위 Windows Server 2012)
$ IPResourceName = ""
# MSDTC 리소스의 IP 주소 리소스 이름 $ ILBIP = ""
# 내부로드 밸런서 (ILB) 및 MSDTC 리소스의 IP 주소
가져 오기 모듈 장애 조치 (failover) 클러스터
# Windows Server 2012 이상을 사용하는 경우 :
Get-ClusterResource $ IPResourceName | Set-ClusterParameter
-Multiple @ {Address = $ ILBIP; ProbePort = 49999; SubnetMask = "255.255.255.255";
네트워크 = $ ClusterNetworkName; EnableDhcp = 0}
# Windows Server 2008 R2를 사용하는 경우 다음을 사용하십시오.
#cluster res $ IPResourceName / priv enabledhcp = 0 address = $ ILBIP probeport = 59999
서브넷 마스크 = 255.255.255.255그것이 작동하는지 확인하십시오!
DTCPing을 사용하거나 구성 요소 서비스로 이동하여 Computers> My Computers> Distributed Transaction Coordinator에서 로컬 DTC 및 클러스터 된 DTC를 볼 수 있습니다. 모든 분산 트랜잭션은 로컬 DTC가 아니라 클러스터 된 DTC에 나타나야합니다. 테스트를 위해 분산 트랜잭션을 작성하는 방법에 대한 예제는이 비디오를 확인하십시오.
다음 단계
이것은 빠르고 더러운 가이드입니다. 숙련 된 사용자는 MSDTC 리소스를 Azure에서 실행해야합니다. 가까운 장래에 세부적인 단계별 가이드를 게시 할 예정입니다. 그동안 방해가되면 Twitter @daveberm에서 나에게 연락을 주저하지 마세요.











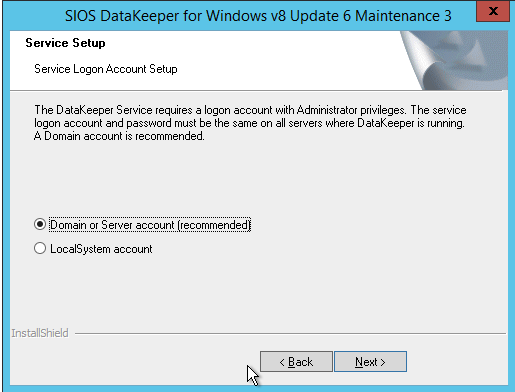
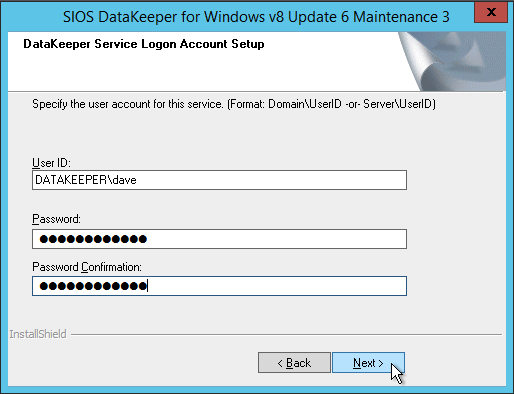



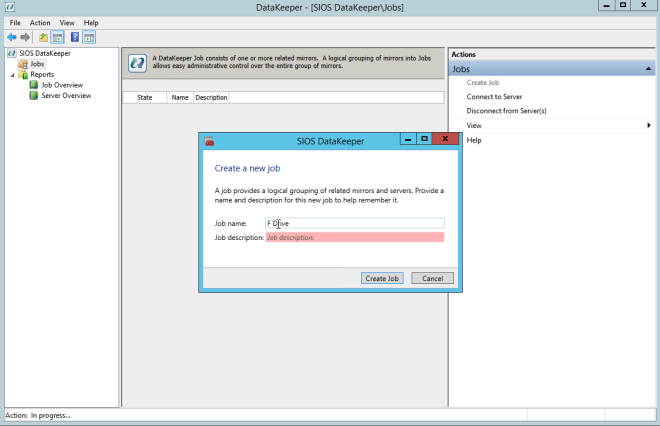












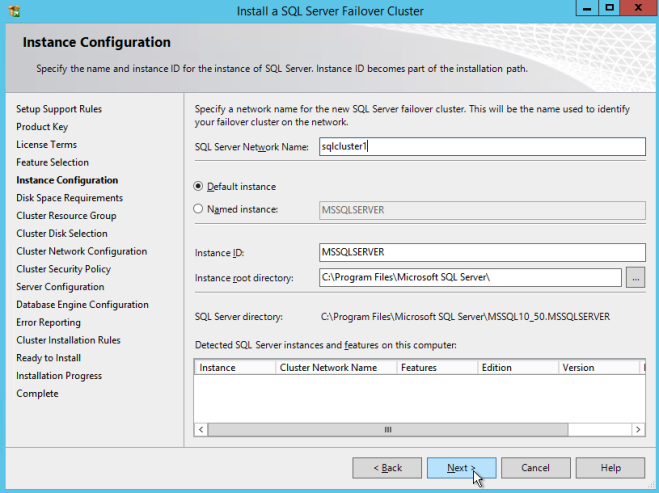


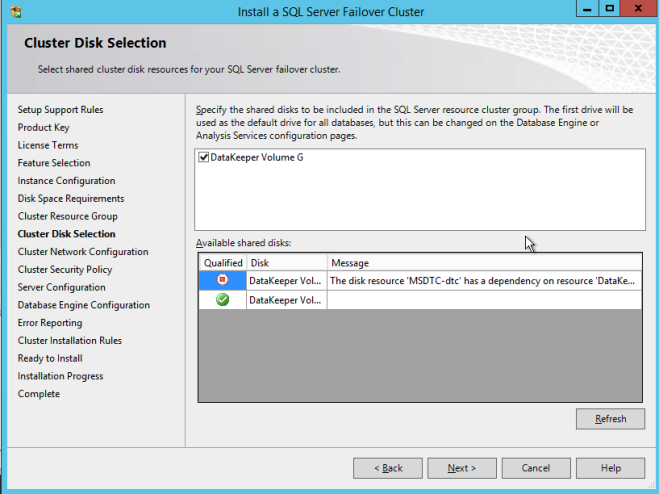


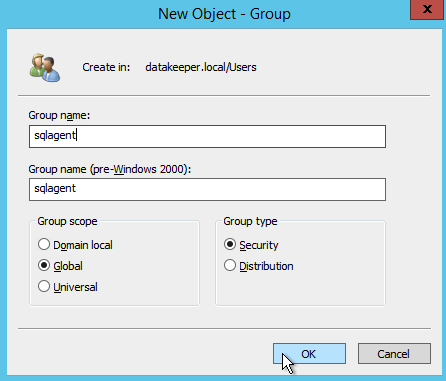
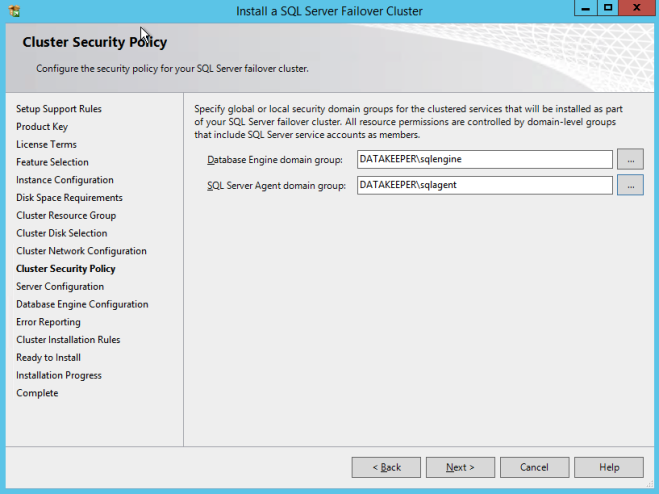

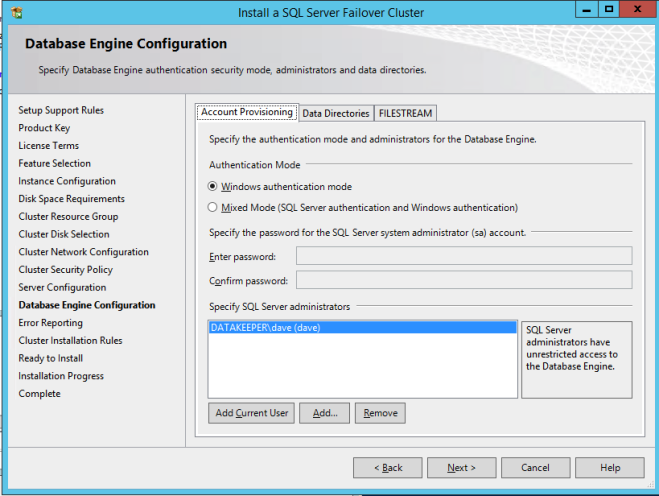













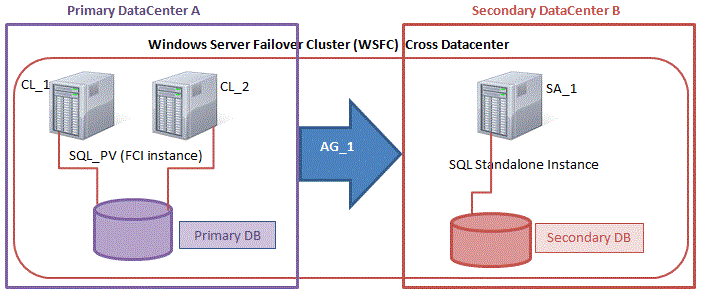
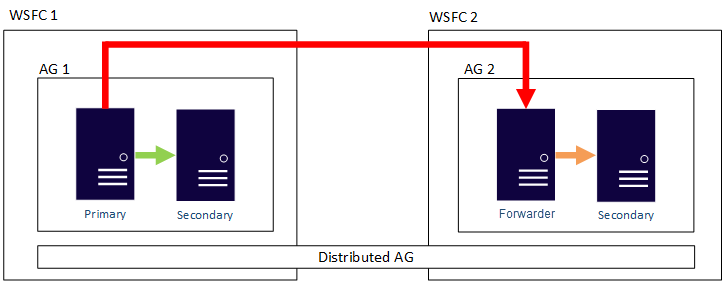


 구성 [/ caption]
구성 [/ caption]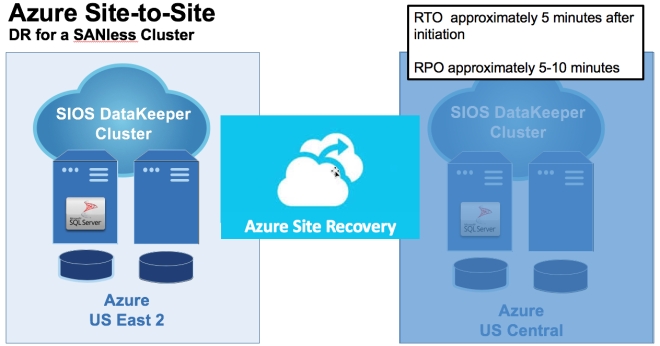 th = "660"] HA 용 SIOS DataKeeper 및 DR 용 Azure 사이트 복구를 활용하는 일반적인 구성 [/ caption]
th = "660"] HA 용 SIOS DataKeeper 및 DR 용 Azure 사이트 복구를 활용하는 일반적인 구성 [/ caption]