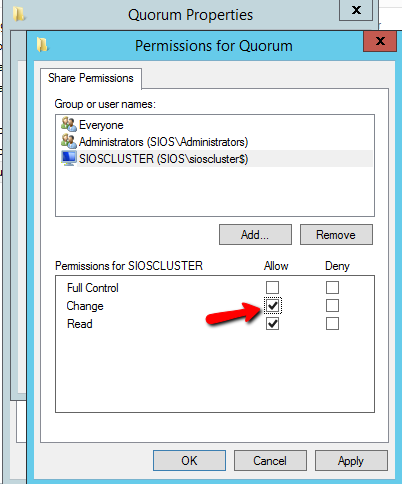
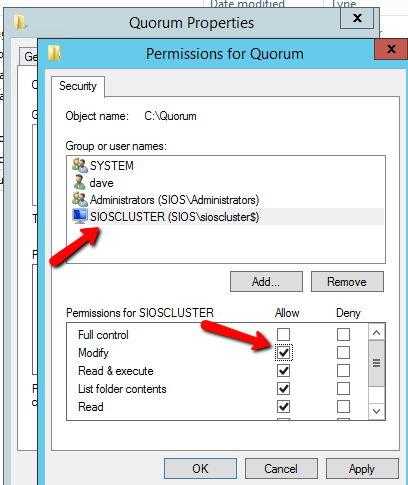
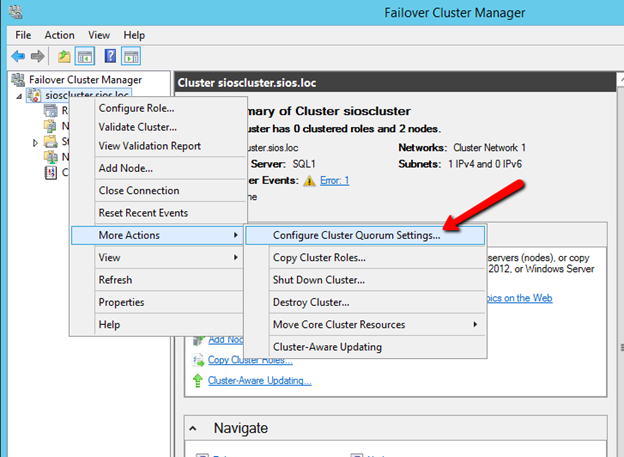
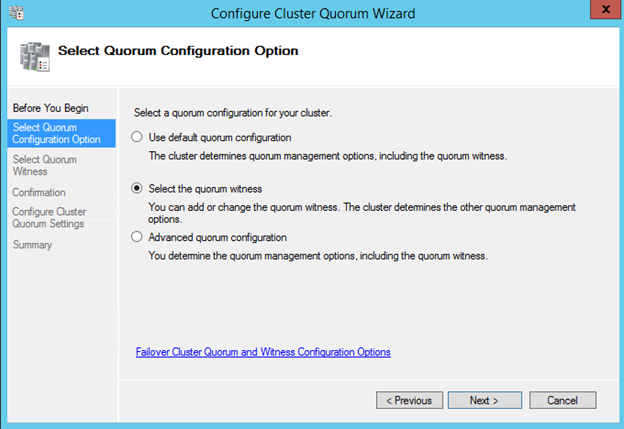
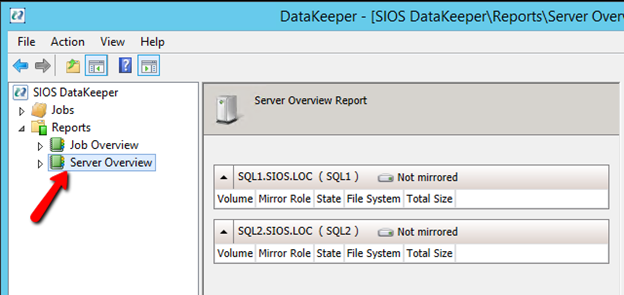
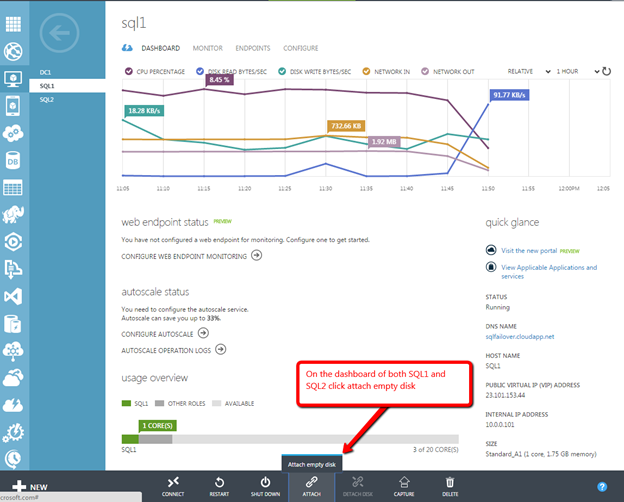
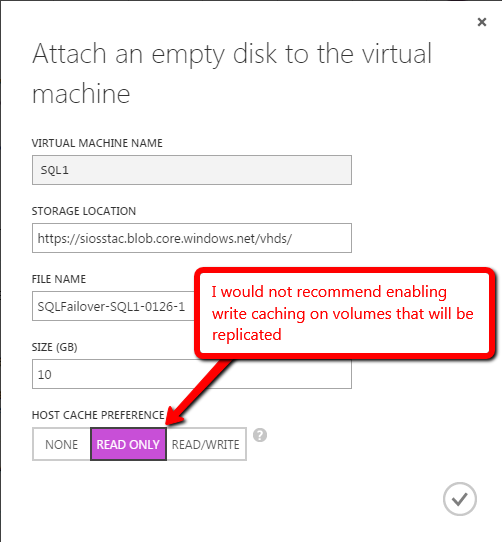
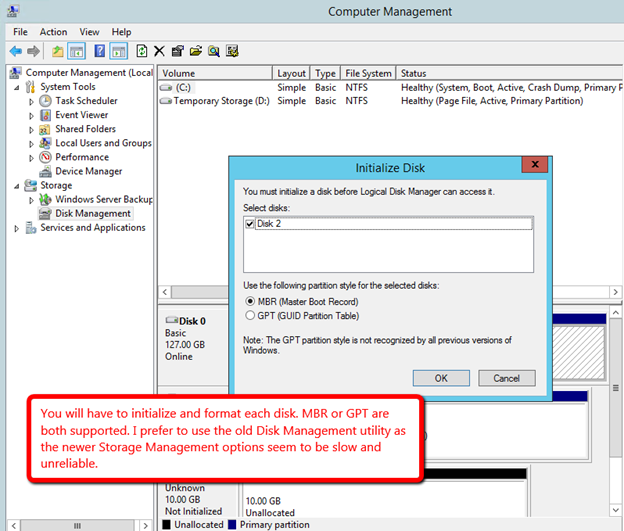
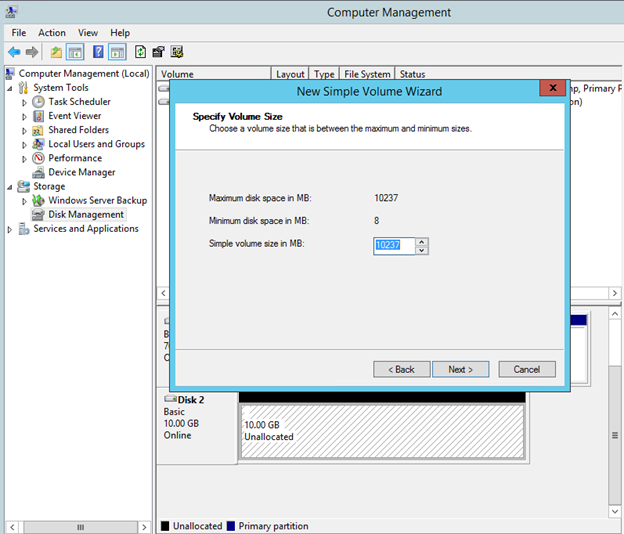
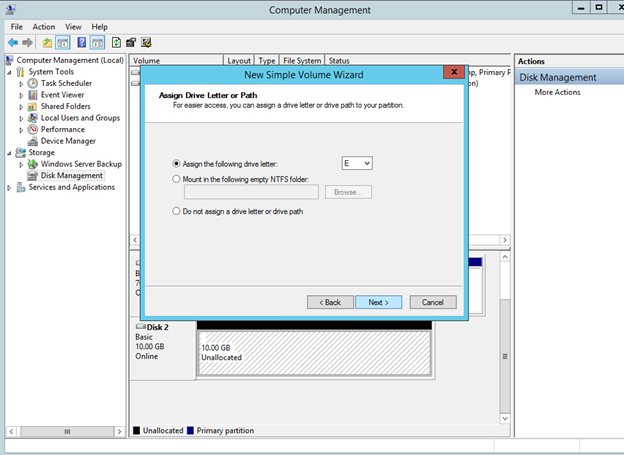
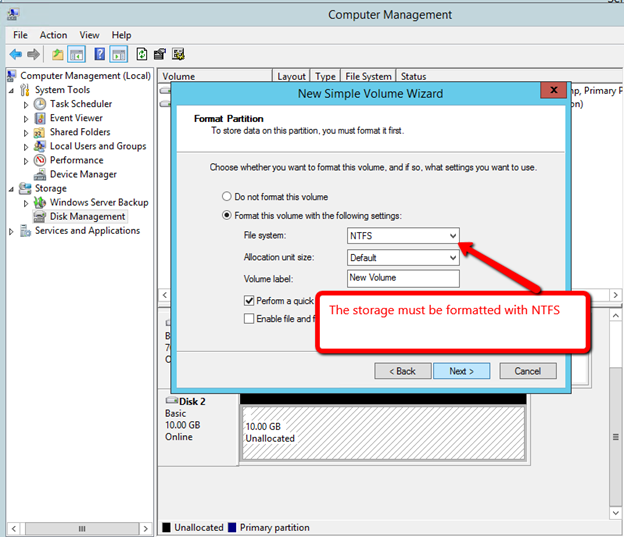
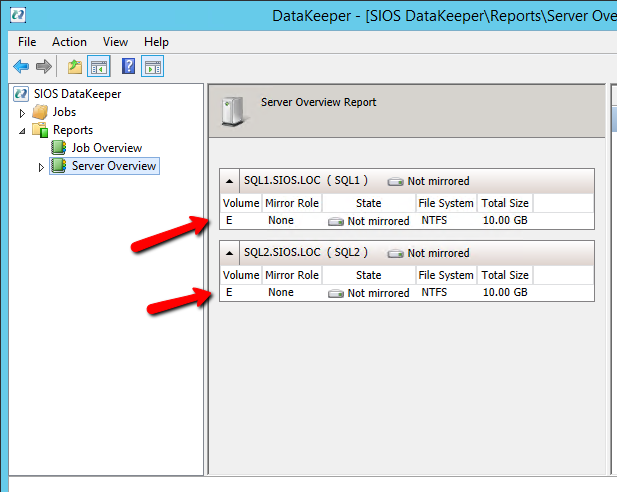
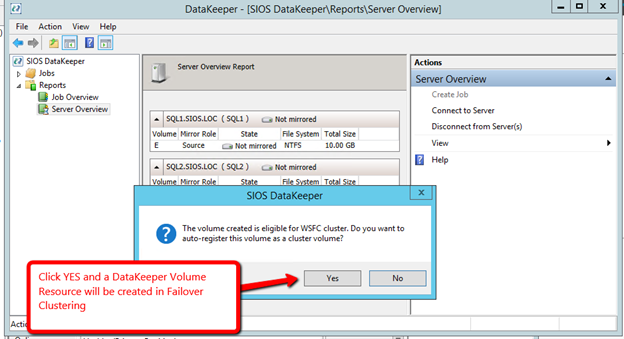
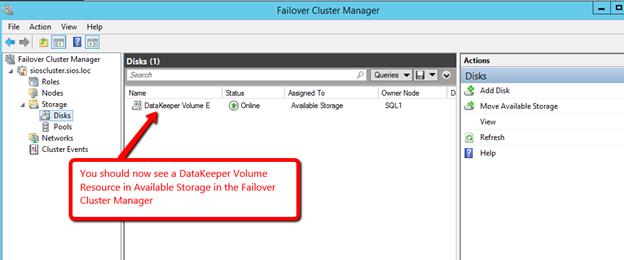
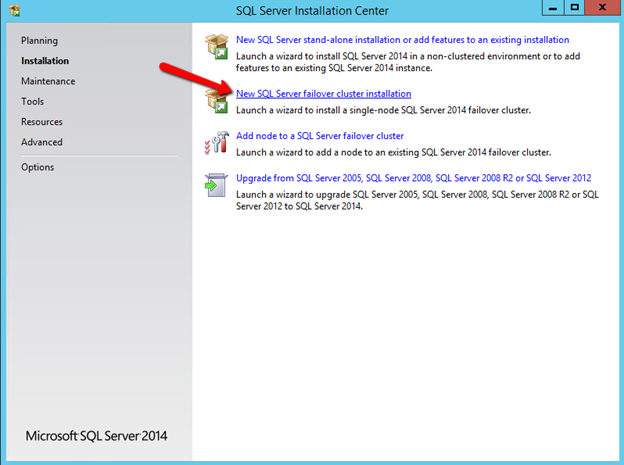
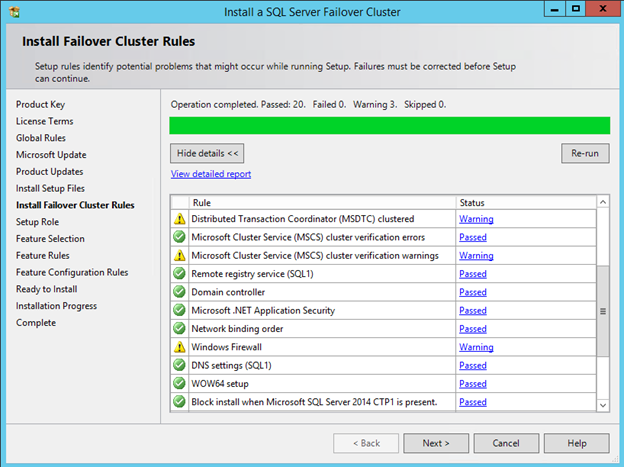
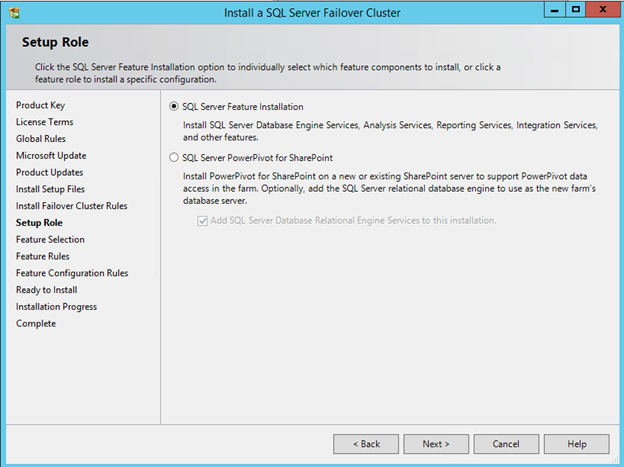
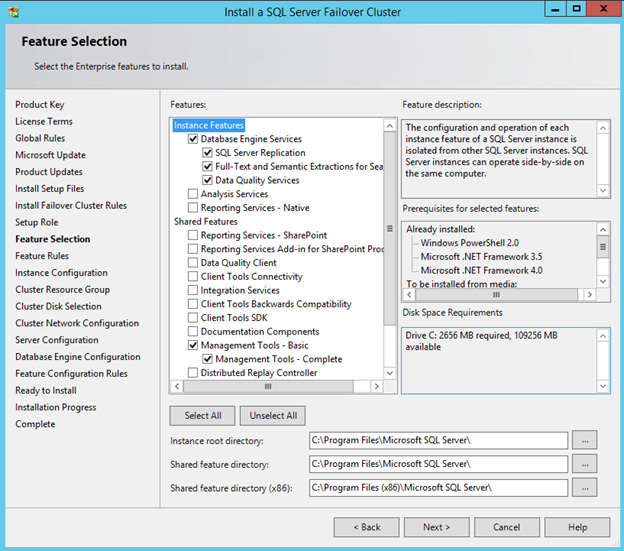
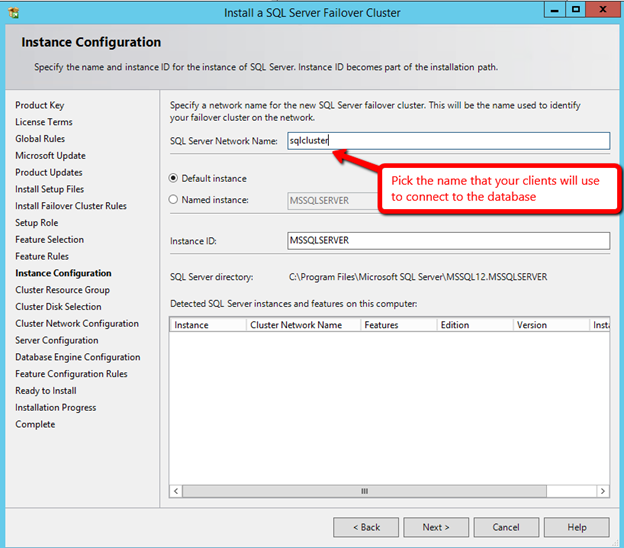
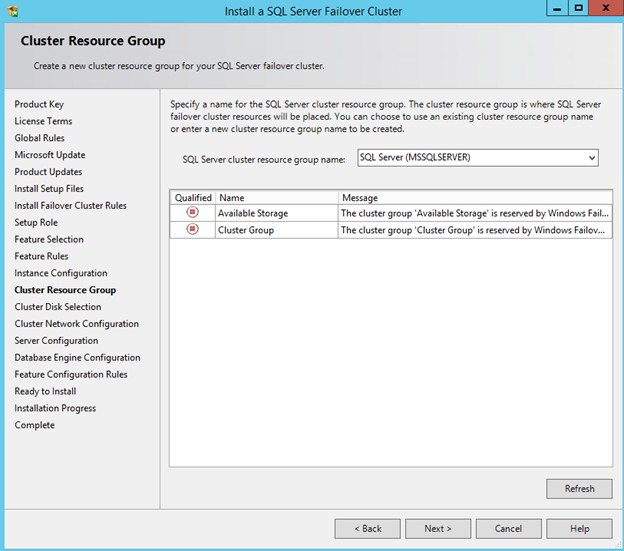
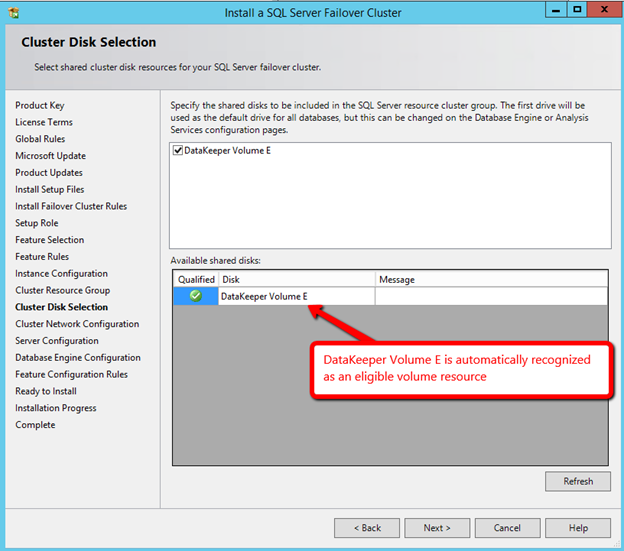
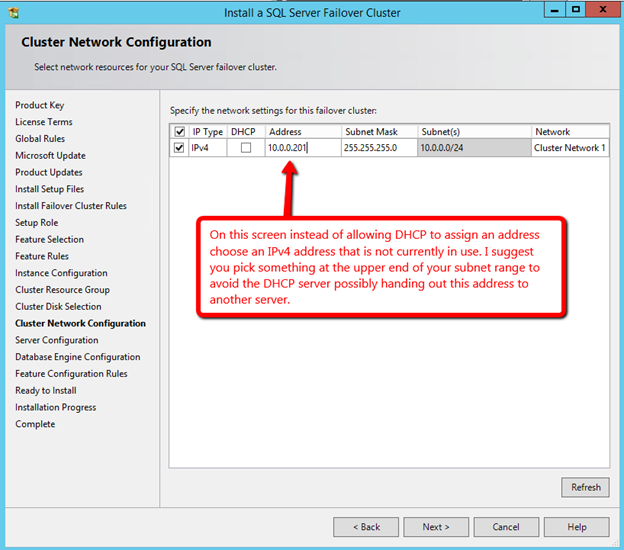
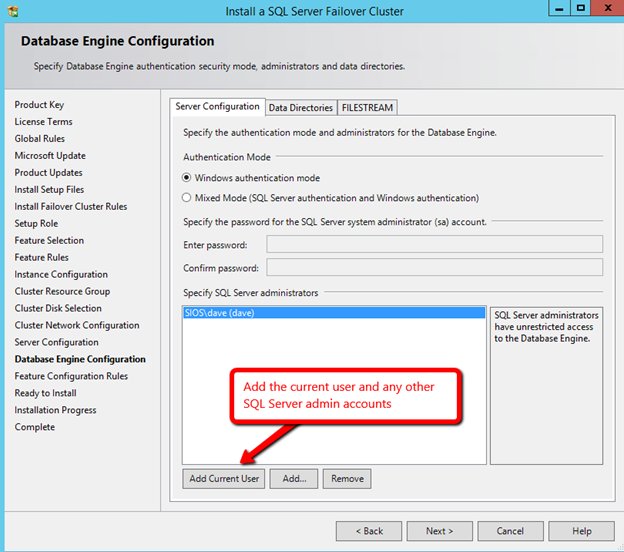
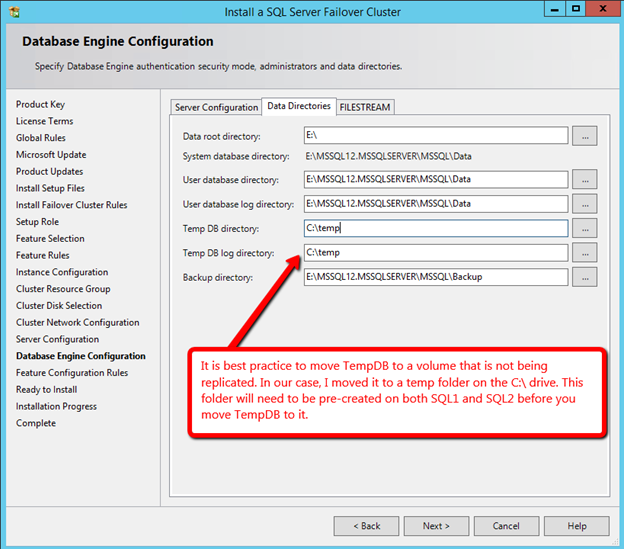
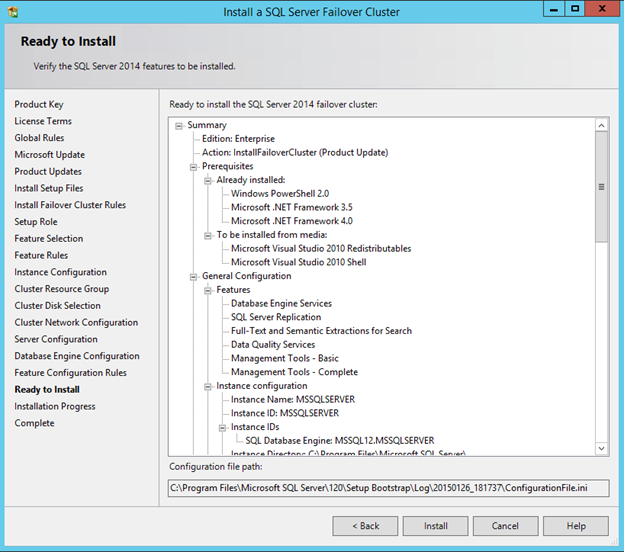
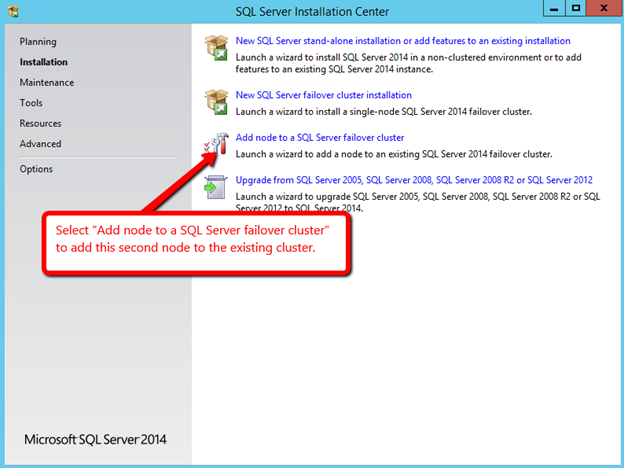
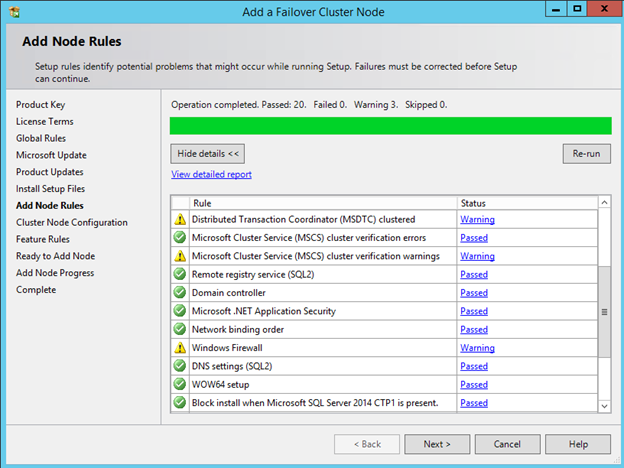
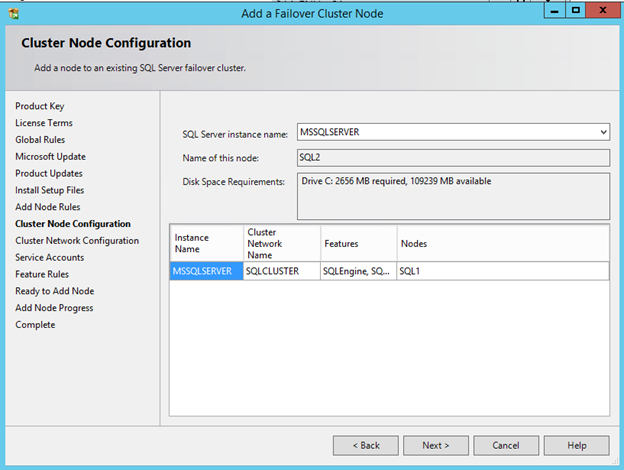
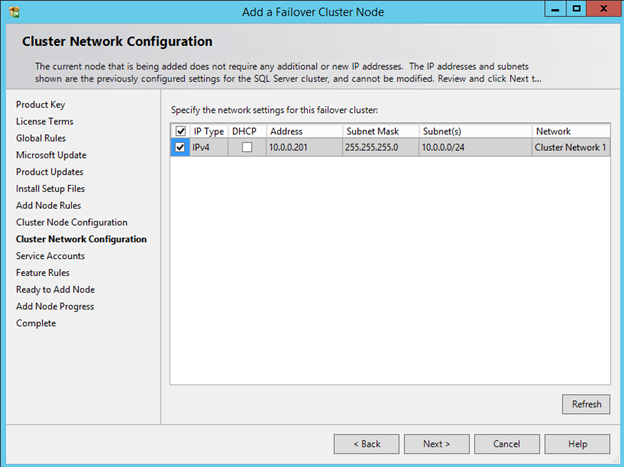
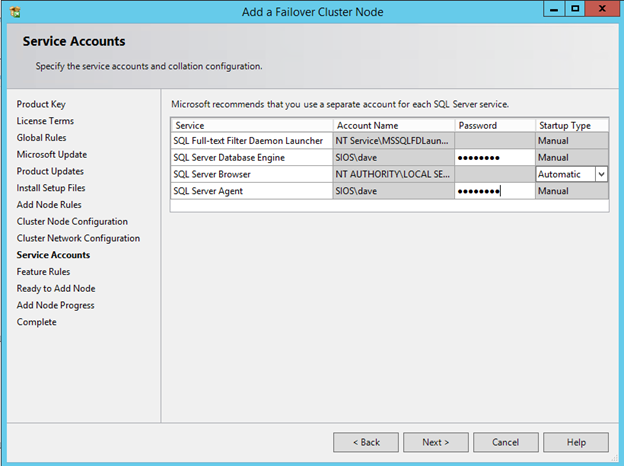
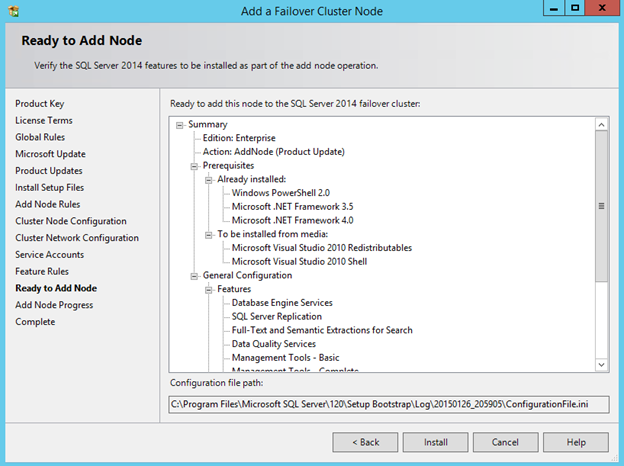
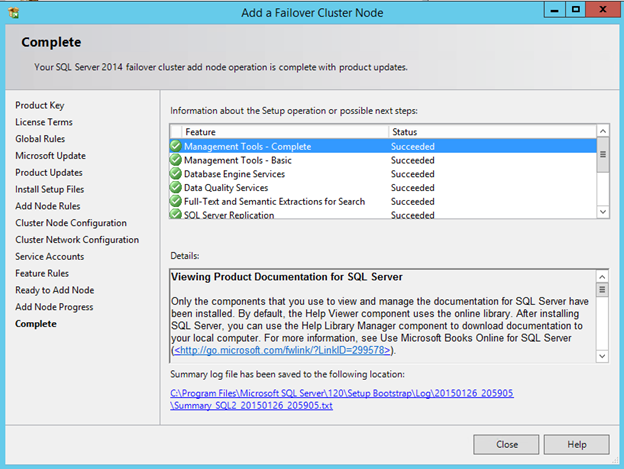
Windows Server 2012 R2 장애 조치 클러스터링 – Microsoft Virtual Academy 배우기
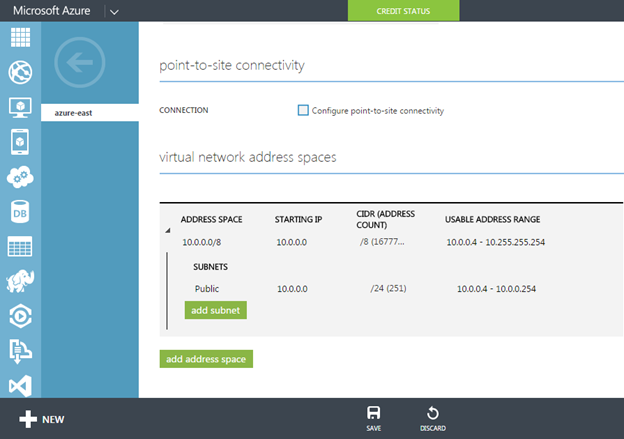
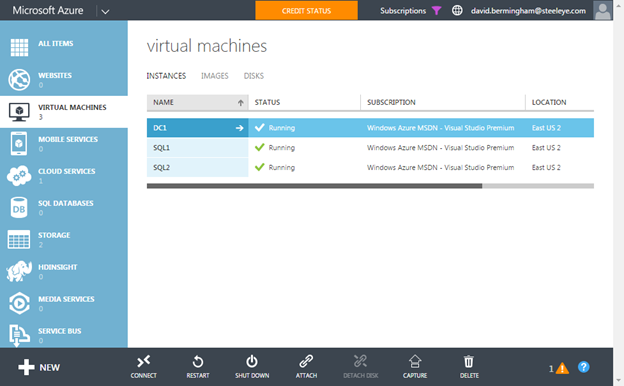
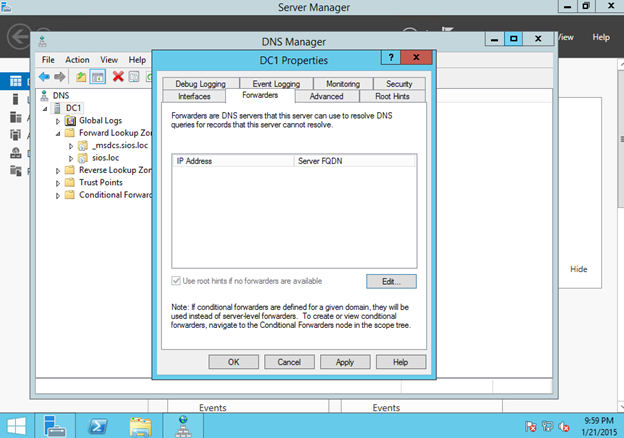
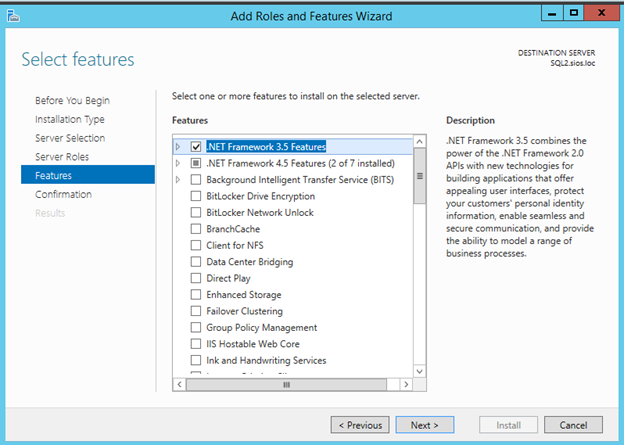
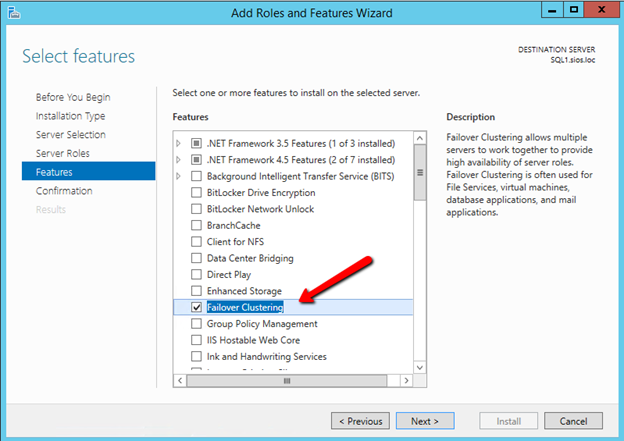
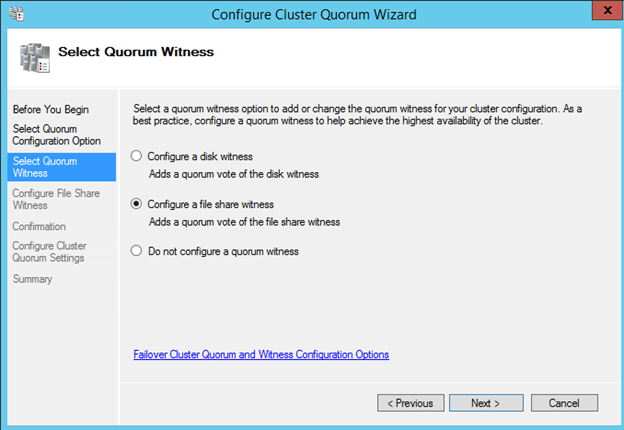
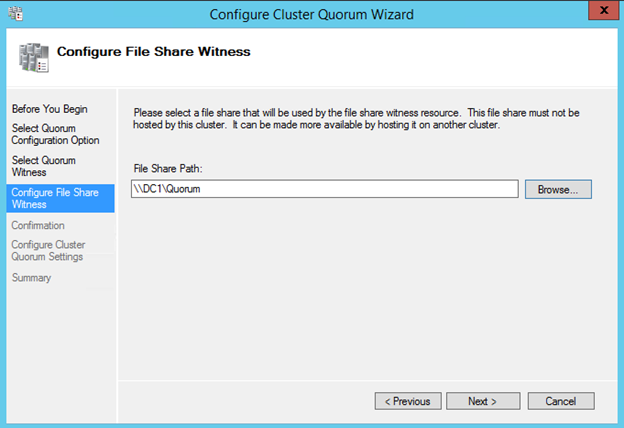
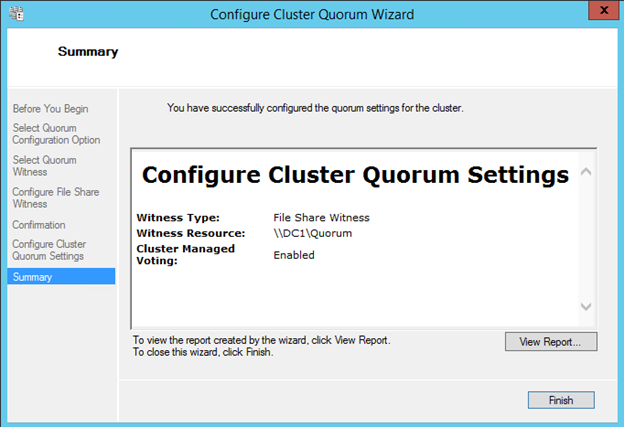
클러스터링에 전혀 노출되지 않았거나 Windows Server 2012 R2에서 클러스터링을 처음 사용 해본 적이없는 사람들을위한 클래스입니다. Symon Perriman (@SymonPerriman), 5nine 소프트웨어 개발 담당 부사장 및 Microsoft Principal Program Manager Lead 인 Elden Christensen은 장애 조치 클러스터링을 실행 및 호흡합니다. 이렇게 훌륭한 지식을 갖춘 강사가 있으면이 두 사람은 다음 프로젝트에 대한 훌륭한 아이디어를 줄 수있을뿐 아니라 대안보기를 제공 할 수 있습니다. 더 좋은 강사는 구할 수 없습니다. 지금하고있는 일을 그만하고 지금 당장 시청하십시오!
https://clusteringformeremortals.com/2015/02/12/learn-windows-server-2012-r2-failover-clustering-microsoft-virtual-academy/에서 허락을 받아 복제했습니다.