Date: 2월 19, 2022

고가용성 클러스터링으로 클라우드에서 단일 실패 지점을 제거하는 방법
고가용성 보호를 제공할 때 SPOF(Single Point of Failure)를 피하기 위해 모든 구성 요소가 중복되도록 하는 것이 일반적인 원칙입니다. 즉, 단일 요소가 실패할 경우 전체 시스템이 중지되지 않도록 합니다. 그러나 운영 인프라는 퍼블릭 클라우드에서 액세스하기 어렵다는 점에 유의해야 합니다.
안에 클라우드 기반 고가용성 클러스터 , 대기 노드가 동일한 호스트 서버, 동일한 랙에 있고 운영 노드와 동일한 네트워크 스위치를 사용할 가능성이 있습니다. 이러한 요소를 중복으로 구성하지 않으면 그 중 하나가 SPOF가 될 수 있으며 응용 프로그램이 치명적인 실패의 위험에 처할 수 있습니다.
클러스터 노드가 서로 다른 지리적 위치에 있는 데이터 센터와 운영 인프라를 물리적으로 분리하는 서로 다른 클라우드 "지역" 및 "가용성 영역"에 있도록 해야 합니다.
가용성을 보장하기 위한 주요 원칙은 무엇입니까?
물리적 IT 인프라를 구성하는 다양한 구성 요소가 사양에 따라 영원히 작동할 것이라고 기대할 수는 없습니다. 부품이 마모되고 시스템이 호환되지 않으며 설정이 변경됩니다. 정기적인 유지 관리를 통해 가동 중지 시간의 위험을 줄일 수 있지만 제품 수명 주기 동안 문제가 발생할 가능성이 있습니다.
드문 경우지만 OS 또는 임베디드 소프트웨어에 잠재적으로 존재하는 심각한 버그로 인해 애플리케이션이 작동하지 않을 수 있습니다.
이미 눈치채셨겠지만 고가용성 클러스터 구성은 이 원칙과 정확히 일치하며 중요한 서버와 해당 리소스를 활성 시스템(프로덕션 시스템)에 이중화하여 단일 장애 지점을 제거합니다. 그러나 두 가지를 기억하는 것이 중요합니다. 첫째, 서버 하드웨어가 유일한 핵심 구성 요소가 아닙니다. 두 번째 요점은 공용 클라우드 인프라에서 다른 중요한 SPOF 구성 요소가 보이지 않을 수 있다는 것입니다.
클라우드의 보이지 않는 인프라에 숨겨진 단일 장애 지점의 함정에 주의하십시오.
대부분의 퍼블릭 클라우드는 소위 "다중 테넌트" 모드에서 작동합니다. 즉, 동일한 물리적 호스트 서버에서 여러 회사의 VM을 실행합니다. 그리고 일반 계약에서는 시스템이 실행되는 호스트 서버를 지정할 수 없습니다. 이는 클라우드 클러스터의 대기 노드가 활성 노드를 작동하는 동일한 호스트 서버에 배치될 수 있으므로 문제를 일으킬 수 있습니다. HA 클러스터 구성을 하여도 호스트 서버가 다운되면 운영 노드와 대기 노드도 함께 다운된다. 이 시나리오에서 클라우드 운영자는 시스템 복원 시기와 방법을 결정합니다.
액티브 노드를 운영하는 호스트 서버와 스탠바이 노드를 운영하는 호스트 서버는 같은 랙에 있을 수 있다. 이 경우 랙이 SPOF가 되므로 장애가 발생하면 그 아래에 있는 활성 및 대기 노드도 모두 실패합니다.
또한 여러 랙, 게이트웨이 및 라우터를 묶는 네트워크 스위치, 데이터 센터의 전원 공급 장치와 같은 인프라의 상위 계층에서 운영 체제 노드와 대기 시스템 노드가 동일한 시스템에 공존할 수 있습니다. 그리고 이러한 주요 구성 요소가 중복되지 않으면 피할 수 없는 단일 실패 지점이 있습니다. 다시 말하지만, 퍼블릭 클라우드 사용자인 회사에게 이러한 데이터 센터 인프라는 블랙박스입니다. SPOF를 식별하기 위해 세부 구성을 확인하는 것이 불가능할 수 있습니다.
가용성을 위해 공용 클라우드 가용성 영역 및 지역을 활용해야 합니다.
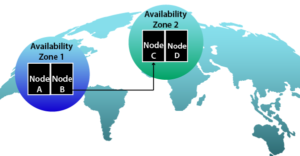
퍼블릭 클라우드에서 숨겨진 단일 실패 지점을 어떻게 명시적으로 피할 수 있습니까? 가장 강력한 방법은 클라우드 측에 준비된 "Availability Zones" 및 "Regions"를 사용하는 것입니다.
가용 영역은 데이터 센터 내 인프라의 독립적인 물리적 분리입니다. 그리고 지역은 지리적으로 분리된 독립적인 데이터 센터입니다. 일부 퍼블릭 클라우드에서는 이러한 가용 영역 또는 지역을 다른 목적으로 의도적으로 사용할 수 있습니다.
예를 들어, Amazon Web Service(AWS)에는 전 세계적으로 12개의 리전이 있습니다. 또한 Microsoft Azure에는 22개의 지역이 있습니다.운영 노드와 대기 노드가 이러한 두 개 이상의 지역에 걸쳐 서로 다른 가용 영역에 분산되어 있는 HA 클러스터 구성을 구성하면 거의 모든 SPOF를 확실하게 피할 수 있습니다.이러한 모범 사례를 준수하면 가용성, DR을 자신 있게 보장할 수 있습니다. (재해 복구 ) 및 BCP(비즈니스 연속성 계획).