Date: 1월 19, 2019
태그: 다중 구름, 마이크로 소프트 푸른, 사이버 보안, 서버 페일 오버, 클라우드 정전

주요 클라우드 작동 중단시 실시간 복구 관리
재해가 일어나 갑작스러운 다운 타임이 발생합니다. 그러나 사실상 모든 클라우드 중단에서 생존하기 위해 모든 고객이 할 수있는 일이 있습니다. 물건이 생겼어. 크고 작은 실패는 필연적입니다. 필연적 인 것은 오랜 기간의 가동 중지 시간입니다. Microsoft의 Azure 클라우드의 South Central United States 지역에서 치명적인 오류가 발생한 날을 생각해보십시오. 심한 뇌우로 인해 계단식 문제가 생겨 결국 전체 데이터 센터가 파괴되었습니다. 일부 사람들은 "하늘 구름이 하늘에서 떨어지는 날"이라고 불렀던 대부분의 고객은 몇 초 또는 몇 분만이 아니라 하루 동안 오프라인 상태였습니다. 일부는 2 일 이상 오프라인 상태였습니다. Microsoft는 그 후 정전으로 이어지는 많은 문제를 해결했지만 IT 전문가는이 문제를 오랫동안 기억할 것입니다. 그것은 나쁜 소식입니다. 좋은 소식은 : Azure 고객이 사실상 중단 된 상황에서 생존하기 위해 할 수있는 일이 있습니다. 단일 서버가 실패하여 전체 데이터 센터가 오프라인 상태가 될 수 있습니다. 실제로 실시간 데이터 복제 및 신속한 자동 장애 조치를 갖춘 강력한 고 가용성 및 재해 복구 조항을 구현 한 Azure 고객은 재해가 발생할 때마다 데이터 손실이 발생하지 않으며 가동 중단 시간이 거의 없거나 전혀 없을 것으로 예상 할 수 있습니다. 또한보십시오 : Nutanix는 기업 구름이 구름 인종을이기는 것을 봅니다
클라우드 정전 관리
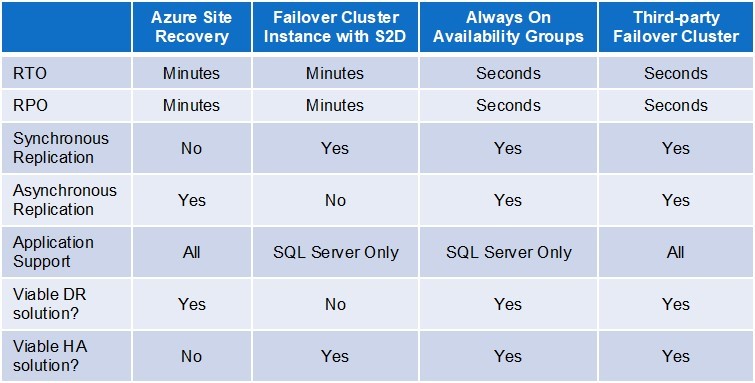
이 기사에서는 하이브리드 및 순수 Azure 클라우드 구성에서 재해 복구 (DR) 및 고 가용성 (HA) 보호를 제공하는 네 가지 옵션을 검토합니다. 두 가지 옵션은 Azure 클라우드에서 널리 사용되는 Microsoft SQL Server 데이터베이스에만 적용됩니다. 다른 두 옵션은 응용 프로그램에 독립적입니다. 다양한 조합으로 사용할 수있는 네 가지 옵션이 테이블에서 비교되어 다음과 같습니다.
- Azure 사이트 복구 (ASR) 서비스
- 저장소 공간이있는 SQL Server 장애 조치 (failover) 클러스터 인스턴스
- SQL Server 상시 가용성 그룹
- 타사 장애 조치 (Failover) 클러스터링 소프트웨어
RTO 및 RPO 101
네 가지 옵션을 설명하기 전에 DR 및 HA 조항의 효율성을 평가하는 데 사용되는 두 가지 메트릭, 즉 복구 시간 목표 및 복구 시점 목표에 대한 기본적인 이해가 필요합니다. RTO 및 RPO에 익숙한 사용자는이 섹션을 건너 뛸 수 있습니다. RTO는 정전의 최대 허용 기간입니다. 온라인 트랜잭션 처리 응용 프로그램은 일반적으로 가장 낮은 RTO를 가지며 미션 크리티컬 한 응용 프로그램은 종종 단 몇 초의 RTO를가집니다. RPO는 데이터 손실을 허용 할 수있는 최대 기간입니다. 데이터 손실이 허용 가능하지 않으면 RPO는 0입니다. RTO는 일반적으로 필요한 HA 및 / 또는 DR 보호의 유형을 결정합니다. 낮은 복구 시간은 일반적으로 일상적인 시스템 및 소프트웨어 장애로부터 보호하는 강력한 HA 규정을 필요로하지만 더 긴 RTO는보다 광범위하지만 덜 빈번한 재해로부터 시스템을 보호하기 위해 설계된 기본 DR 규정에 충족 될 수 있습니다. HA 및 DR 조항에 사용되는 데이터 복제는 RTO와 RPO 간의 잠재적 인 상충 관계에 대한 필요성을 창출 할 수 있습니다. 복제가 동기식이 될 수있는 대기 시간이 짧은 LAN 환경에서 기본 및 보조 데이터 세트를 동시에 업데이트 할 수 있습니다. 이를 통해 전체 복구가 자동 및 실시간으로 수행 될 수 있으므로 절충없이 가장 까다로운 복구 시간 및 복구 지점 목표 (각각 몇 초 및 0)를 만족시킬 수 있습니다. 대조적으로, WAN을 통해 주 서버가 모든 트랜잭션에 대한 업데이트 완료를 확인하기 위해 보조 서버가 성능을 저하시키는 것을 기다리도록 강요합니다. 이러한 이유로 WAN에서의 데이터 복제는 일반적으로 비동기입니다. 이로 인해 RTO와 RPO를 수용하는 것과 일반적으로 복구 시간이 길어지는 것 사이에 절충점이 생길 수 있습니다. 이유는 다음과 같습니다. RPO를 0으로 맞추기 위해서는 페일 오버가 발생할 수 있기 전에 모든 데이터 (예 : 트랜잭션 로그)가 2 차 서버에서 완전히 복제되었는지 확인하기 위해 수동 프로세스가 필요합니다.이 여분의 노력으로 복구 시간이 길어 지므로 이러한 구성 DR이 아닌 HA에 주로 사용됩니다.
Azure 사이트 복구 (ASR) 서비스
ASR은 Azure의 DR as a a service (DRaaS) 오퍼링입니다. ASR은 실제 및 가상 시스템을 다른 Azure 사이트, 잠재적으로 다른 지역 또는 사내 구축 형 인스턴스에서 Azure 클라우드로 복제합니다. 이 서비스는 시스템 및 사이트 중단으로부터의 신속한 복구를 제공하고 롤링 소프트웨어 업그레이드 중 다운 타임을 제거함으로써 계획된 유지 보수를 용이하게합니다. 모든 DRaaS 오퍼링과 마찬가지로 ASR에는 몇 가지 제한 사항이 있습니다. 가장 심각한 것은 응용 프로그램 수준의 작동 중지 시간을 유발하는 여러 가지 장애로부터 자동으로 감지하고 장애 조치 할 수 없다는 것입니다. 물론 이것이 서비스가 HA가 아닌 DR을위한 것으로 특징 지워지는 이유입니다. ASR을 사용할 경우 복구 시간은 일반적으로 관리자가 수동으로 문제를 감지하고 대응할 수있는 속도에 따라 3-4 분이 소요됩니다. 위에서 설명한 것처럼 WAN을 통한 비동기 데이터 복제의 필요성은 RPO가 0 인 응용 프로그램의 복구 시간을 더욱 증가시킬 수 있습니다.
저장소 공간이있는 SQL Server 장애 조치 (Failover) 클러스터 인스턴스
SQL Server는 장애 조치 클러스터 인스턴스 (여기에서 설명 함) 및 Always On Availability Groups (다음에 설명 함)의 두 가지 HA / DR 옵션을 제공합니다. FCI는 다음과 같은 두 가지 이점이 있습니다.이 기능은 저렴한 SQL Server Standard Edition에서 사용할 수 있으며 기존 HA 클러스터와 같은 공유 저장소를 사용하지 않아도됩니다. 후자의 이점은 Microsoft 나 다른 클라우드 서비스 제공 업체의 공유 스토리지를 단순히 클라우드에서 사용할 수 없기 때문에 중요합니다. Azure 클라우드의 저장소로 널리 사용되는 것은 광범위한 응용 프로그램을 지원하는 S2D (Storage Spaces Direct)이며 SQL Server에 대한 지원은 데이터베이스뿐 아니라 전체 인스턴스를 보호합니다. S2D의 가장 큰 단점은 서버가 단일 데이터 센터 내에 있어야한다는 것입니다.이 옵션은 일부 HA 요구에는 적합하지만 DR에는 적합하지 않습니다. 다중 사이트 HA 및 DR 보호의 경우 로그 전달 또는 타사 장애 조치 (Failover) 클러스터링 솔루션을 통해 필요한 데이터 복제를 제공해야합니다.
SQL Server 상시 가용성 그룹
가용성 그룹 항상 가용성 그룹은 HA 및 DR 모두에 대해 SQL Server에서 가장 뛰어난 기능을 제공하지만보다 비싼 Enterprise Edition에 대한 라이센스가 필요합니다. 이 옵션은 5-10 초의 복구 시간과 초 이하의 복구 지점을 제공 할 수 있습니다. 또한 데이터베이스를 쿼리 할 수있는 보조 라이센스를 적절한 라이센스와 함께 제공하며 데이터베이스 크기 나 보조 인스턴스 수에 제한을 두지 않습니다. HA 및 DR 보호를 모두 제공하는 상시 가용성 그룹 구성은 단일 가용성 세트 또는 영역에 두 개의 노드가있는 3- 노드 구성과 개별 Azure 영역의 세 번째 노드로 구성됩니다. 한 가지 주목할만한 제한 사항은 데이터베이스 만 복제되고 다른 일부 수단으로 보호해야하는 전체 SQL 인스턴스가 아니라는 것입니다. 일부 데이터베이스 응용 프로그램의 경우 비용이 많이 드는 것 외에도 이러한 접근 방식에는 또 다른 단점이 있습니다. 응용 프로그램에 따라 IT 부서는 다른 모든 응용 프로그램에 대해 다른 HA 및 DR 조항을 구현해야합니다. 여러 HA / DR 솔루션을 사용하면 라이센스, 교육, 구현 및 지속적인 운영을 위해 복잡성과 비용이 크게 증가 할 수 있으므로 조직이 애플리케이션에 구속받지 않는 타사 솔루션을 선호하는 또 다른 이유가 있습니다.
타사 장애 조치 (Failover) 클러스터링 소프트웨어
애플리케이션에 독립적이며 플랫폼에 독립적 인 설계로 장애 조치 클러스터링 소프트웨어는 사설, 공용 및 하이브리드 클라우드 환경의 거의 모든 애플리케이션에 완벽한 HA 및 DR 솔루션을 제공 할 수 있습니다. 여기에는 Windows와 Linux가 모두 포함됩니다. 응용 프로그램에 의존하지 않으면 다양한 응용 프로그램에 대해 서로 다른 HA / DR 규정을 가질 필요가 없습니다. 플랫폼에 구속력이 없기 때문에 오류 도메인, 가용성 세트 및 영역, 지역 쌍 및 Azure 사이트 복구를 비롯하여 Azure 클라우드의 다양한 기능과 서비스를 활용할 수 있습니다. 완벽한 솔루션 인 소프트웨어에는 최소한 실시간 데이터 복제, 응용 프로그램 수준에서 장애를 감지 할 수있는 지속적인 모니터링 및 장애 조치 및 장애 복구 (failback and failback)를위한 구성 가능한 정책이 포함됩니다. 또한 대부분의 솔루션은 장애 조치 클러스터가 거의 모든 HA / DR 요구 사항을 충족시키기 위해 최소한의 데이터 손실 또는 20 초 미만의 복구 시간을 제공 할 수있는 다양한 부가 가치 기능을 제공합니다.
현실로 만들기
개별적으로 운영하든 콘서트에서 운영하든 네 가지 옵션 모두 DR 및 HA 보호의 연속성을 엔터프라이즈 애플리케이션의 전체 스펙트럼에 대해보다 효과적이고 저렴하게 만드는 역할을 할 수 있습니다. 여기에는 약간의 데이터 손실과 장기간의 가동 중단 시간을 허용 할 수있는 것부터 최소 5 분의 9의 가동 시간을 달성하기 위해 실시간 복구가 필요한 것까지 포함됩니다. 현실 세계에서 다음 클라우드 장애를 극복하기 위해 선택한 DR 및 / 또는 HA 조항에 따라 두 사이트에 두 개 이상의 노드가 분산되어 구성되어 있는지 확인하십시오. 또한 각 애플리케이션의 복구 시간 및 복구 지점 목표를 얼마나 만족시키는 지 반드시 이해하십시오. 모든 가능한 오류를 감지하는 데 필요한 수작업 프로세스의 필요성을 포함하여 존재할 수있는 제한 사항뿐만 아니라 응용 프로그램 연속성 및 데이터 무결성을 보장하는 방식으로 장애 조치를 유발합니다.
Jonathan Meltzer 정보
Jonathan Meltzer는 SIOS Technology의 제품 관리 담당 이사입니다. 그는 고객이 인적 자원 및 IT 자원을 관리, 변환 및 최적화 할 수 있도록 도와주는 소프트웨어 및 SaaS 제품에 대한 제품 관리 및 마케팅 분야에서 20 년 이상의 경력을 쌓았습니다. RTinsights에서 재현