Date: 8월 19, 2018
태그: Azure Resource Manager

Azure Resource Manager에서 Microsoft SQL Server 2014 장애 조치 (failover) 클러스터 배포
이 글에서는 Azure Resource Manager에서 SQL Server 장애 조치 (Failover) 클러스터를 배포하는 데 필요한 특정 단계에 대해 자세히 설명합니다. 기본 Azure 개념과 기본 SQL Server 장애 조치 (Failover) 클러스터 개념에 익숙하다고 가정합니다. Azure Resource Manager를 사용하여 Azure의 단일 영역에 2- 노드 SQL Server 장애 조치 (failover) 클러스터를 배포하는 것은 로켓 과학이 아닙니다. 이 기사에서 중점을 둘 내용은 Azure Resource Manager에 SQL Server 장애 조치 (Failover) 클러스터를 배포하는 데 대한 고유성입니다. 여전히 Azure Classic을 사용하고 있고 Classic의 SQL Server 장애 조치 (Failover) 클러스터를 배포해야하는 경우 Microsoft 기술 자료 "SQL Server 오류 해결 클러스터 인스턴스 (FCI)를 구성하는 방법"(영문)을 "단계별 : SQL Server # SQLSERVER #AZURE # SANLESS "시작하기 전에 Azure 가상 컴퓨터의 Windows Azure Article, SQL Server의 고 가용성 및 재해 복구에 대해 알아 보겠습니다. 이 기사에서는 모든 HA 옵션에 대해 설명합니다. 여기에는 AlwaysOn AG, 데이터베이스 미러링, 로그 전달, 백업 및 복원 및 마지막으로 장애 조치 (failover) 클러스터 인스턴스가 포함되었습니다. SQL Server Enterprise Edition 또는 기능 부족과 관련된 비용으로 인해 다른 옵션을 취소했다고 가정 할 때 최종 옵션 인 SQL Server AlwaysOn 장애 조치 클러스터 인스턴스 (FCI)에 중점을 두어 설명합니다. 이 기사를 읽으면 Azure에서 클러스터 인식 공유 저장소가 부족하여 SQL Server 장애 조치 (failover) 클러스터를 배포하는 데 장애가된다는 사실이 분명해집니다. 그러나이 기사에서 설명 된 몇 가지 대안이 있습니다. 우리는 SIOS DataKeeper를 사용하여 클러스터에서 사용할 저장소를 제공하는 데 집중할 것입니다. 그림 1 SQL Server 장애 조치 (failover) 클러스터에 대한 Microsoft의 지원 정책 https://azure.microsoft.com/en-us/documentation/articles/virtual-machines- windows-classic-sql-dr / [/ caption] DataKeeper Cluster Edition을 사용하면 프리미엄 디스크인지 표준 디스크인지에 관계없이 로컬로 연결된 저장소를 가져 와서 동기, 비동기 또는 혼합 또는 둘 모두로 복제 할 수 있습니다. 또는 더 많은 클러스터 노드. 또한 DataKeeper 볼륨 리소스는 실제 디스크 리소스 대신 Windows Server 장애 조치 (Failover) 클러스터링에 등록됩니다. 물리적 디스크 리소스와 같은 SCSI-3 예약을 제어하는 대신 DataKeeper 볼륨은 미러 방향을 제어하여 활성 노드가 항상 미러의 원본인지 확인합니다. SQL Server 및 장애 조치 (Failover) 클러스터링과 관련하여 보면 실제 디스크처럼 보이고 느끼고 냄새가 나며 실제 디스크 리소스와 동일한 방식으로 사용됩니다.
Azure Resource Manager에서 SQL Server 장애 조치 (failover) 클러스터를 배포하기위한 사전 요구 사항
- 이전에 Azure Portal을 사용해 왔으며 Azure IaaS에서 가상 시스템을 쉽게 배포 할 수 있습니다.
- SIOS DataKeeper의 라이센스 또는 평가판 라이센스를 취득한 경우
- SQL Server AlwaysOn 장애 조치 (Failover) 클러스터 인스턴스에 익숙합니다. 그렇지 않은 경우 https://msdn.microsoft.com/en-us/library/ms189134.aspx 문서를 검토하십시오.
개념 증명을위한 쉬운 방법
Azure Resource Manager에 익숙하다면 배포 템플릿을 사용하여 상호 연관된 Azure 리소스로 구성된 응용 프로그램을 신속하게 배포 할 수 있다는 것입니다. 이 템플릿 중 대부분은 Microsoft에서 개발 한 것으로 Github의 커뮤니티에서 "빠른 시작 템플릿"으로 쉽게 사용할 수 있습니다. 커뮤니티 회원은 템플릿을 확장하거나 자신의 템플릿을 GitHub에 게시 할 수 있습니다. SIOS Technology에서 게시 한 "SQL Server 2014 AlwaysOn 장애 조치 클러스터 인스턴스 (SIOS DataKeeper Azure 배포 템플릿 포함)"라는 제목의 템플릿 중 하나는 2 노드 SQL Server FCI를 새 Active Directory 도메인에 배포하는 프로세스를 완전히 자동화합니다. 이 템플릿을 배포하려면 템플릿의 "Azure 배포"버튼을 클릭하는 것만 큼 쉽습니다. 그림 2- 2 노드 SQL 클러스터를 신속하게 프로비저닝하기 위해 https://github.com/S![]() IOSDataKeeper/SIOSDataKeeper-SQL-Cluster를 방문하십시오 [/ caption] 에 클러스터 노드와 파일
IOSDataKeeper/SIOSDataKeeper-SQL-Cluster를 방문하십시오 [/ caption] 에 클러스터 노드와 파일 공유 감시 서버를 모두 추가해야합니다 (캡션 ID = "attachment_1724"align = "alignnone"width = "638"
공유 감시 서버를 모두 추가해야합니다 (캡션 ID = "attachment_1724"align = "alignnone"width = "638"
정적 IP 주소
각 VM을 프로비저닝 한 후에는 설정으로 이동하여 IP 주소가 정적이되도록 설정을 변경해야합니다. 클러스터 노드의 IP 주소가 변경되는 것을 원하지 않습니다. 그림 4 – 각 클러스터 노드가 정적 IP [/ caption]을 사용하는지 확인하십시오 [ca ption id = "attachment_1727"align = "alignnone"width = "306"
ption id = "attachment_1727"align = "alignnone"width = "306"
저장
Storage에 관한 한, Azure 가상 시스템에서 SQL Server의 성능 모범 사례를 참조하십시오. 어떤 경우 든 적어도 하나의 추가 디스크를 각 클러스터 노드에 추가해야합니다. DataKeeper는 기본 디스크, 고급 저장소 또는 저장소 풀에있는 여러 디스크로 구성된 저장소 풀을 사용할 수 있습니다. 각 클러스터 노드에 동일한 양의 저장소를 추가하고 동일하게 구성해야합니다. [캡션 id = "attachment_1730"align = "alignnone "width = "587"] 그림 5 – 각 클러스터 노드에 저장소를 추가해야합니다 [/ caption]
"width = "587"] 그림 5 – 각 클러스터 노드에 저장소를 추가해야합니다 [/ caption]
클러스터 만들기
위에서 설명한대로 두 클러스터 노드 (SQL1 및 SQL2)가 준비되어 기존 도메인에 추가되었다고 가정하면 클러스터를 만들 준비가 완료되었습니다. 클러스터를 만들기 전에 몇 가지 기능을 활성화해야합니다. 이러한 기능은 .NET Framework 3.5 및 장애 조치 (Failover) 클러스터링입니다. 이러한 기능은 두 클러스터 노드에서 모두 활성화해야합니다. 그림 6 – 두 클러스터 노드 모두에서 .Net Framework 3.5 및 장애  조치 (Failover) 클러스터링 기능 사용 [/ caption] 이러한 기능을 사용하도록 설정하면 준비가 완료된 것입니다 (캡션 ID = "attachment_1733"align = "alignnone"width = "660" 클러스터를 빌드하십시오. PowerShell과 GUI를 통해 수행 할 수있는 대부분의 단계가 나와 있습니다. 그러나이 첫 번째 단계에서는 PowerShell을 사용하여 클러스터를 만드는 것이 좋습니다. 장애 조치 (Failover) 클러스터 관리자 GUI를 사용하여 클러스터를 만들면 클러스터가 중복 IP 주소를 발행하면서 퇴사한다는 것을 알게 될 것입니다. 아주 자세히 설명하지 않고 Azure VM은 DHCP를 사용해야합니다. 우리가 Azure 포털에서 VM을 생성 할 때 "정적 IP"를 지정하면 일종의 DHCP 예약이 생성됩니다. 진정한 DHCP 예약은 DHCP 풀에서 해당 IP 주소를 제거하기 때문에 정확히 DHCP 예약이 아닙니다. 대신, Azure 포털에 정적 IP를 지정하면 VM이 요청할 때 해당 IP 주소를 계속 사용할 수 있으면 Azure가 해당 IP를 발급한다는 것을 의미합니다. 그러나 VM이 오프라인 상태이고 다른 호스트가 동일한 서브넷에서 온라인 상태가되면 동일한 IP 주소를 발급받을 수 있습니다. Azure가 DHCP를 구현 한 방식에는 또 다른 이상한 부작용이 있습니다. 호스트가 DHCP를 사용해야 할 때 Windows Server 장애 조치 (Failover) 클러스터 GUI를 사용하여 클러스터를 만들 때는 클러스터 IP 주소를 지정하는 옵션이 없습니다. 대신 DHCP를 사용하여 주소를 얻습니다. 이상한 점은 DHCP가 새로운 IP 주소를 요구하는 호스트와 동일한 IP 주소 인 중복 IP 주소를 발행한다는 것입니다. 클러스터는 일반적으로 완료되지만 이상한 오류가있을 수 있으며 실행을 위해 다른 노드에서 Windows Server 장애 조치 (Failover) 클러스터 GUI를 실행해야 할 수도 있습니다. 실행을 시작하면 클러스터 IP 주소를 현재 네트워크에서 사용되지 않는 주소로 변경하려고합니다. Powershell을 통해 간단히 클러스터를 만들고 클러스터 IP 주소를 PowerShell 명령의 일부로 지정하여 클러스터를 만들면 완전히 혼란을 피할 수 있습니다. 다음과 같이 New-Cluster 명령을 사용하여 클러스터를 만들 수 있습니다.
조치 (Failover) 클러스터링 기능 사용 [/ caption] 이러한 기능을 사용하도록 설정하면 준비가 완료된 것입니다 (캡션 ID = "attachment_1733"align = "alignnone"width = "660" 클러스터를 빌드하십시오. PowerShell과 GUI를 통해 수행 할 수있는 대부분의 단계가 나와 있습니다. 그러나이 첫 번째 단계에서는 PowerShell을 사용하여 클러스터를 만드는 것이 좋습니다. 장애 조치 (Failover) 클러스터 관리자 GUI를 사용하여 클러스터를 만들면 클러스터가 중복 IP 주소를 발행하면서 퇴사한다는 것을 알게 될 것입니다. 아주 자세히 설명하지 않고 Azure VM은 DHCP를 사용해야합니다. 우리가 Azure 포털에서 VM을 생성 할 때 "정적 IP"를 지정하면 일종의 DHCP 예약이 생성됩니다. 진정한 DHCP 예약은 DHCP 풀에서 해당 IP 주소를 제거하기 때문에 정확히 DHCP 예약이 아닙니다. 대신, Azure 포털에 정적 IP를 지정하면 VM이 요청할 때 해당 IP 주소를 계속 사용할 수 있으면 Azure가 해당 IP를 발급한다는 것을 의미합니다. 그러나 VM이 오프라인 상태이고 다른 호스트가 동일한 서브넷에서 온라인 상태가되면 동일한 IP 주소를 발급받을 수 있습니다. Azure가 DHCP를 구현 한 방식에는 또 다른 이상한 부작용이 있습니다. 호스트가 DHCP를 사용해야 할 때 Windows Server 장애 조치 (Failover) 클러스터 GUI를 사용하여 클러스터를 만들 때는 클러스터 IP 주소를 지정하는 옵션이 없습니다. 대신 DHCP를 사용하여 주소를 얻습니다. 이상한 점은 DHCP가 새로운 IP 주소를 요구하는 호스트와 동일한 IP 주소 인 중복 IP 주소를 발행한다는 것입니다. 클러스터는 일반적으로 완료되지만 이상한 오류가있을 수 있으며 실행을 위해 다른 노드에서 Windows Server 장애 조치 (Failover) 클러스터 GUI를 실행해야 할 수도 있습니다. 실행을 시작하면 클러스터 IP 주소를 현재 네트워크에서 사용되지 않는 주소로 변경하려고합니다. Powershell을 통해 간단히 클러스터를 만들고 클러스터 IP 주소를 PowerShell 명령의 일부로 지정하여 클러스터를 만들면 완전히 혼란을 피할 수 있습니다. 다음과 같이 New-Cluster 명령을 사용하여 클러스터를 만들 수 있습니다.
새 클러스터 -Name cluster1 -Node sql1, sql2 -StaticAddress 10.0.0.101 -NoStorage
클러스터 생성이 완료되면 다음 명령을 실행하여 클러스터 유효성 검사를 실행합니다.
테스트 클러스터
그림 7 – 클러스터 생성 및 클러스터 유효성 검사 명령의 출력 [/ caption]
파일 공유 감시 만들기
공유 저장소가 없기 때문에 두 클러스터 노드와 동일한 가용성 집합의 다른 서버에 파일 공유 감시를 만들어야합니다. 동일한 가용성 설정에두면 정해진 시간에 한 정족수의 투표 만 잃을 수 있습니다. 파일 공유 감시를 만드는 방법을 잘 모르는 경우이 문서 (http://www.howtonetworking.com/server/cluster12.htm)를 검토하십시오. 내 데모에서는 파일 공유 감시를 도메인 컨트롤러에 넣었습니다. 클러스터 쿼럼에 대한 철저한 설명은 https://blogs.msdn.microsoft.com/microsoft_press/2014/04/28/from-the-mvps-understanding-the-windows-server-failover-cluster-quorum- in-windows-server-2012-r2 / 있음
DataKeeper 설치
클러스터가 생성 된 후에 DataKeeper를 설치할 차례입니다. 사용자 지정 클러스터 리소스 유형을 클러스터에 등록 할 수 있도록 초기 클러스터를 만든 후에 DataKeeper를 설치하는 것이 중요합니다. 클러스터를 만들기 전에 DataKeeper를 설치했다면 설치를 다시 실행하고 복구 설치를 수행하기 만하면됩니다. [캡션 id = "attachment_1738"align = "align none"width = "514"] 그림 8 – 클러스터 생성 후 DataKeeper 설치 [/ caption] 설치하는 동안 모든 기본 옵션을 사용할 수 있습니다. 사용하는 서비스 계정은 도메인 계정이어야하며 클러스터의 각 노드에있는 로컬 관리자 그룹에 있어야합니다. 그림 9 – 서비스 계정은 각 노드의 Local Admins 그룹에있
none"width = "514"] 그림 8 – 클러스터 생성 후 DataKeeper 설치 [/ caption] 설치하는 동안 모든 기본 옵션을 사용할 수 있습니다. 사용하는 서비스 계정은 도메인 계정이어야하며 클러스터의 각 노드에있는 로컬 관리자 그룹에 있어야합니다. 그림 9 – 서비스 계정은 각 노드의 Local Admins 그룹에있 는 도메인 계정이어야합니다 [/ caption] DataKeeper가 설치되고 사용권이 부여 된 후에는 (캡션 ID = "attachment_1740"align = "alignnone"width = "511" 각 노드를 다시 부팅해야합니다.
는 도메인 계정이어야합니다 [/ caption] DataKeeper가 설치되고 사용권이 부여 된 후에는 (캡션 ID = "attachment_1740"align = "alignnone"width = "511" 각 노드를 다시 부팅해야합니다.
DataKeeper 볼륨 리소스 만들기
DataKeeper 볼륨 리소스를 생성하려면 DataKeeper UI를 시작하고 두 서버에 모두 연결해야합니다.  SQL1에 연
SQL1에 연 결 SQL2에
결 SQL2에  연결 각 서버에 연결되면 DataKeeper 볼륨을 만들 준비가 된 것입니다. 작업을 마우스 오른쪽 단추로 클릭하고 "작업 작성"을
연결 각 서버에 연결되면 DataKeeper 볼륨을 만들 준비가 된 것입니다. 작업을 마우스 오른쪽 단추로 클릭하고 "작업 작성"을  선택하십시오. 작업 이름과 설명을 입력하십시오.
선택하십시오. 작업 이름과 설명을 입력하십시오.  원본 서버, IP 및 볼륨을 선택하십시오. IP 주소는 복제 트래픽이 이동할지 여부입니다.
원본 서버, IP 및 볼륨을 선택하십시오. IP 주소는 복제 트래픽이 이동할지 여부입니다.  대상 서버를 선택하십시오.
대상 서버를 선택하십시오.  옵션을 선택하십시오. 두 VM이 동일한 지리적 영역에있는 우리의 목적을 위해 우리는 동기식 복제를 선택할 것입니다. 장거리 복제의 경우 비동기를 사용하고 일부 압축을 사용하고자 할 것입니다.
옵션을 선택하십시오. 두 VM이 동일한 지리적 영역에있는 우리의 목적을 위해 우리는 동기식 복제를 선택할 것입니다. 장거리 복제의 경우 비동기를 사용하고 일부 압축을 사용하고자 할 것입니다.  마지막 팝업에서 예를 클릭하면 장애 조치 클러스터링에서 사용 가능한 저장소에 새로운 DataKeeper 볼륨 리소스가 등록됩니다.
마지막 팝업에서 예를 클릭하면 장애 조치 클러스터링에서 사용 가능한 저장소에 새로운 DataKeeper 볼륨 리소스가 등록됩니다. 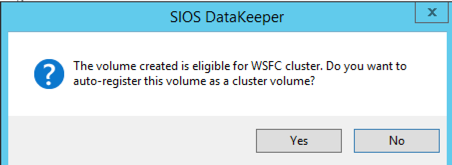 사용 가능한 저장소에 새 DataKeeper 볼륨 리소스가 표시됩니다.
사용 가능한 저장소에 새 DataKeeper 볼륨 리소스가 표시됩니다. 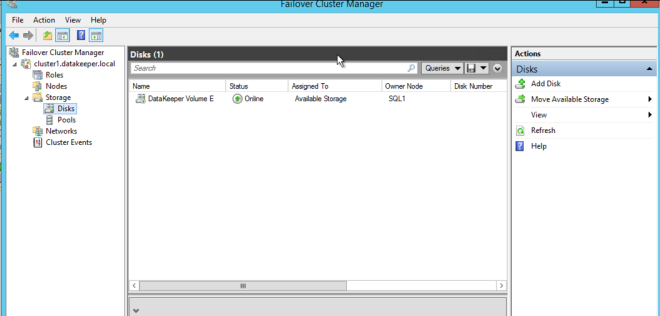
첫 번째 클러스터 노드 설치
이제 첫 번째 노드를 설치할 준비가되었습니다. 클러스터 설치는 이전에 빌드 한 다른 SQL 클러스터와 마찬가지로 진행됩니다. 나는 모든 스크린 샷을 복사하지 않았으며, 길을 따라 안내하는 몇 안되는 것들. 

 DataKeeper 볼륨 리소스는 마치 공유 디스크 인 것처럼 사용 가능한 디스크 리소스로 인식됩니다.
DataKeeper 볼륨 리소스는 마치 공유 디스크 인 것처럼 사용 가능한 디스크 리소스로 인식됩니다. 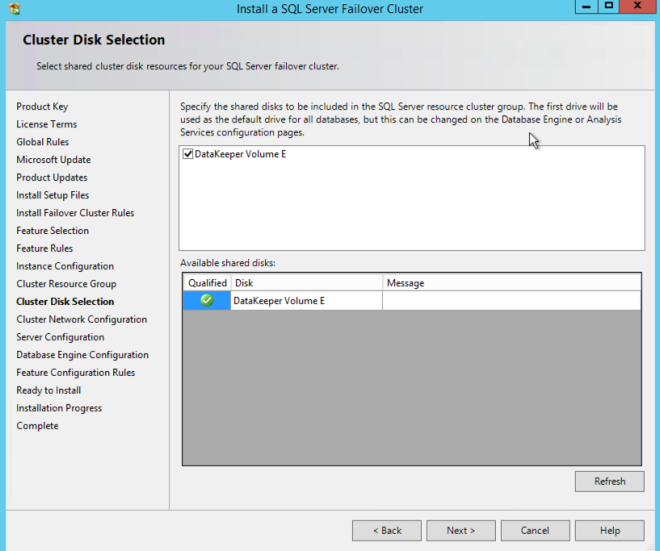 여기에서 선택한 IP 주소를 메모하십시오. 네트워크의 고유 한 IP 주소 여야합니다. 나중에 내부로드 밸런서를 만들 때이 동일한 IP 주소를 사용합니다.
여기에서 선택한 IP 주소를 메모하십시오. 네트워크의 고유 한 IP 주소 여야합니다. 나중에 내부로드 밸런서를 만들 때이 동일한 IP 주소를 사용합니다. 
두 번째 노드 추가
첫 번째 노드가 성공적으로 설치되면 "SQL Server 장애 조치 클러스터에 노드 추가"옵션을 사용하여 두 번째 노드에서 설치를 시작합니다. 다시 한번 말하지만 설치는 간단합니다. 다른 SQL 클러스터 설치와 마찬가지로 표준 모범 사례를 사용하십시오. 
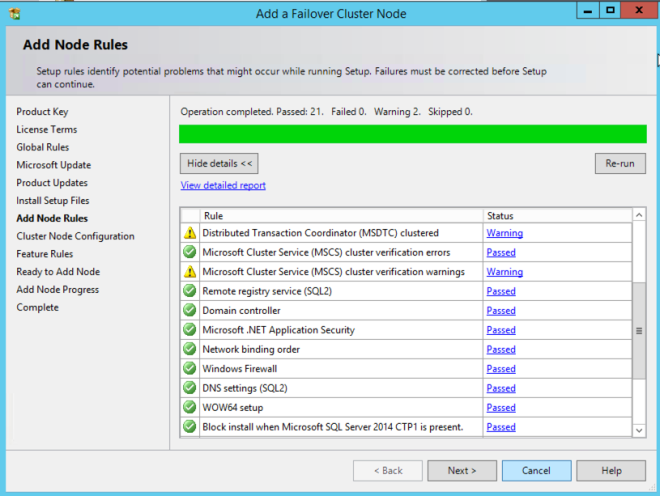
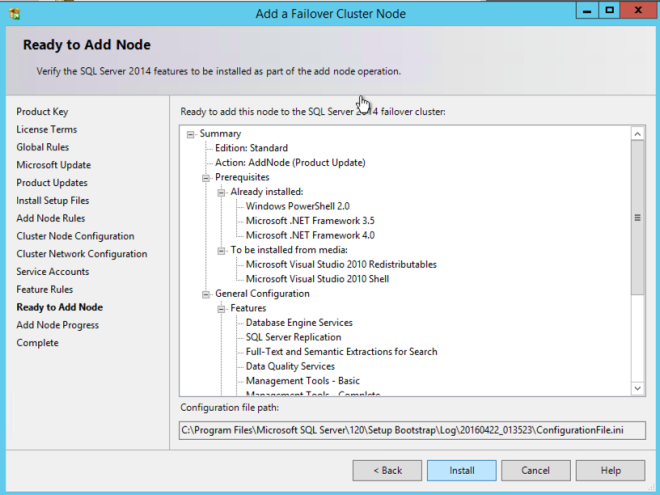

내부로드 밸런서 만들기
Azure의 장애 조치 클러스터링이 전통적인 인프라와 다른 점이 여기에 있습니다. Azure 네트워크 스택은 무상 ARPS를 지원하지 않으므로 클라이언트는 클러스터 IP 주소에 직접 연결할 수 없습니다. 대신 클라이언트는 내부 부하 분산 장치에 연결하고 활성 클러스터 노드로 리디렉션됩니다. 우리가해야 할 일은 내부로드 밸런서를 만드는 것입니다. 이 작업은 아래 그림과 같이 Azure Portal을 통해 수행 할 수 있습니다. 첫째, 새로드 밸런서 만들기 클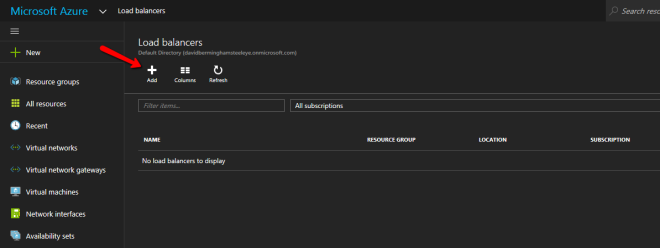 라이언트가 공용 인터넷을 통해 연결하는 경우 공용로드 밸런서를 사용할 수 있습니다. 그러나 고객이 동일한 vNet에 상주한다고 가정하면 내부 부하 분산 장치를 생성합니다. 여기서 중요한 점은 가상 네트워크가 클러스터 노드가 상주하는 네트워크와 동일하다는 것입니다. 또한 지정한 개인 IP 주소는 SQL 클러스터 리소스를 만드는 데 사용한 주소와 정확히 동일합니다.
라이언트가 공용 인터넷을 통해 연결하는 경우 공용로드 밸런서를 사용할 수 있습니다. 그러나 고객이 동일한 vNet에 상주한다고 가정하면 내부 부하 분산 장치를 생성합니다. 여기서 중요한 점은 가상 네트워크가 클러스터 노드가 상주하는 네트워크와 동일하다는 것입니다. 또한 지정한 개인 IP 주소는 SQL 클러스터 리소스를 만드는 데 사용한 주소와 정확히 동일합니다. 
 내부 부하 분산 장치 (ILB)를 만든 후에는 편집해야합니다. 우리가 할 첫 번째 일은 백엔드 풀을 추가하는 것입니다. 이 프로세스를 통해 SQL 클러스터 VM이 상주하는 가용성 세트를 선택하게됩니다. 그러나 실제 VM을 선택하여 백 엔드 풀에 추가 할 때는 파일 공유 감시를 선택하지 마십시오. SQL 트래픽을 파일 공유 감시로 리디렉션하고 싶지는 않습니다.
내부 부하 분산 장치 (ILB)를 만든 후에는 편집해야합니다. 우리가 할 첫 번째 일은 백엔드 풀을 추가하는 것입니다. 이 프로세스를 통해 SQL 클러스터 VM이 상주하는 가용성 세트를 선택하게됩니다. 그러나 실제 VM을 선택하여 백 엔드 풀에 추가 할 때는 파일 공유 감시를 선택하지 마십시오. SQL 트래픽을 파일 공유 감시로 리디렉션하고 싶지는 않습니다. 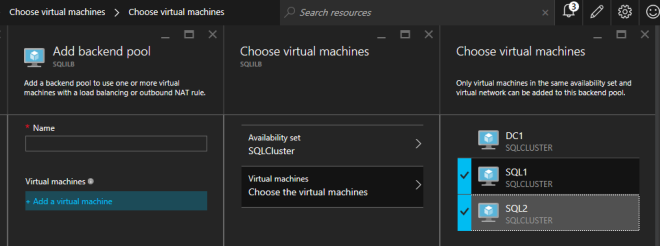
 다음으로 할 일은 프로브를 추가하는 것입니다. 우리가 추가 한 프로브는 포트 59999를 프로브합니다. 이 프로브는 클러스터에서 어떤 노드가 활성 상태인지 확인합니다.
다음으로 할 일은 프로브를 추가하는 것입니다. 우리가 추가 한 프로브는 포트 59999를 프로브합니다. 이 프로브는 클러스터에서 어떤 노드가 활성 상태인지 확인합니다. 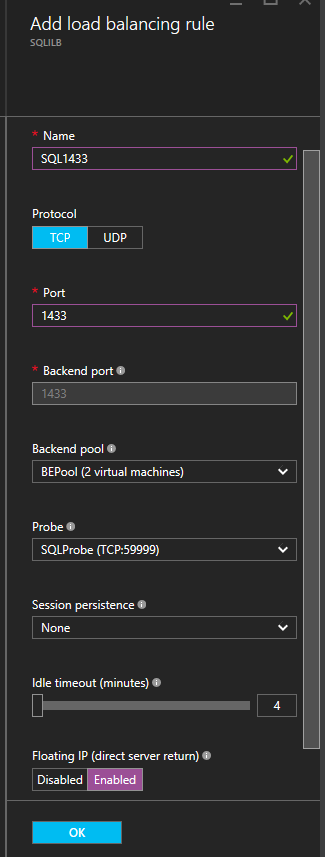 마지막으로 SQL Server 트래픽을 리디렉션하기위한로드 균형 조정 규칙이 필요합니다. 이 예에서는 포트 1433을 사용하는 SQL의 기본 인스턴스를 사용했습니다. 응용 프로그램 요구 사항에 따라 1434 또는 기타 규칙을 추가 할 수도 있습니다. 아래 스크린 샷에서 주목할 점은 Direct Server Return is Enabled입니다. 당신이 그 변화를 만들 었는지 확인하십시오.
마지막으로 SQL Server 트래픽을 리디렉션하기위한로드 균형 조정 규칙이 필요합니다. 이 예에서는 포트 1433을 사용하는 SQL의 기본 인스턴스를 사용했습니다. 응용 프로그램 요구 사항에 따라 1434 또는 기타 규칙을 추가 할 수도 있습니다. 아래 스크린 샷에서 주목할 점은 Direct Server Return is Enabled입니다. 당신이 그 변화를 만들 었는지 확인하십시오.
SQL Server IP 리소스 수정
Azure Resource Manager에서 SQL Server 장애 조치 (Failover) 클러스터를 배포하는 마지막 단계. 클러스터 노드 중 하나에서 다음 PowerShell 스크립트를 실행하십시오. 이렇게하면 클러스터 IP 주소가 ILB 프로브에 응답하고 클러스터 IP 주소와 ILB간에 IP 주소 충돌이 발생하지 않습니다. 받아 적기를 바랍니다; 사용자 환경에 맞게이 스크립트를 편집해야합니다. 서브넷 마스크는 255.255.255.255로 설정되어 있습니다. 실수가 아니므로 그대로 두십시오. 이것은 ILB와의 IP 주소 충돌을 피하기 위해 호스트 특정 라우트를 작성합니다.
# 변수 정의
$ ClusterNetworkName = ""
# 클러스터 네트워크 이름
(Windows Server 2012의 Get-ClusterNetwork를 사용하여 이름을 찾으십시오)
$ IPResourceName = ""
# IP 주소 자원 이름
$ ILBIP = ""
# 내부로드 밸런서 (ILB)의 IP 주소
가져 오기 모듈 장애 조치 클러스터
# Windows Server 2012 이상을 사용하는 경우 :
Get-ClusterResource $ IPResourceName | Set-ClusterParameter
-Multiple @ {Address = $ ILBIP; ProbePort = 59999; SubnetMask = "255.255.255.255";
네트워크 = $ ClusterNetworkName; EnableDhcp = 0}
# Windows Server 2008 R2를 사용하는 경우 다음을 사용하십시오.
#cluster res $ IPResourceName / priv enabledhcp = 0 address = $ ILBIP probeport = 59999
서브넷 마스크 = 255.255.255.255
결론
이제 SQL Server 장애 조치 (Failover) 클러스터 인스턴스가 작동해야합니다. Azure Resource Manager에서 SQL Server 장애 조치 (Failover) 클러스터를 배포하기위한 문제가 있습니까? Twitter @daveberm에서 나에게 도움을 청하면 기꺼이 도와 드리겠습니다. DataKeeper 평가 키가 필요하면 http://us.sios.com/clustersyourway/cta/14-day-trial에 양식을 작성하십시오. SIOS는 평가 키를 보내드립니다.